إذا كنت تعمل مؤخرًا على تطبيقات الذكاء الاصطناعي، فما هو أكثر شيء يسبب لك الإحباط؟ على الأرجح هو هذا السيناريو: قمت بتعديل الموجه (prompt) للمرة السابعة عشرة، وبعد تشغيل بضع حالات اختبار شعرت بتحسن الأداء، ولكن بمجرد إطلاقه، قام المستخدمون بضرب التطبيق بحالة استثنائية (edge case) لم تتوقعها أبدًا، مما أدى إلى انهيار النظام. هذه هي المشكلة التي سعت OpenAI لحلها بشكل جذري في مقالها المنشور في أكتوبر 2025 ضمن "كتاب الطبخ" (Cookbook) بعنوان "بناء موجهات مرنة باستخدام عجلة تقييم دوارة" (Building resilient prompts using an evaluation flywheel).
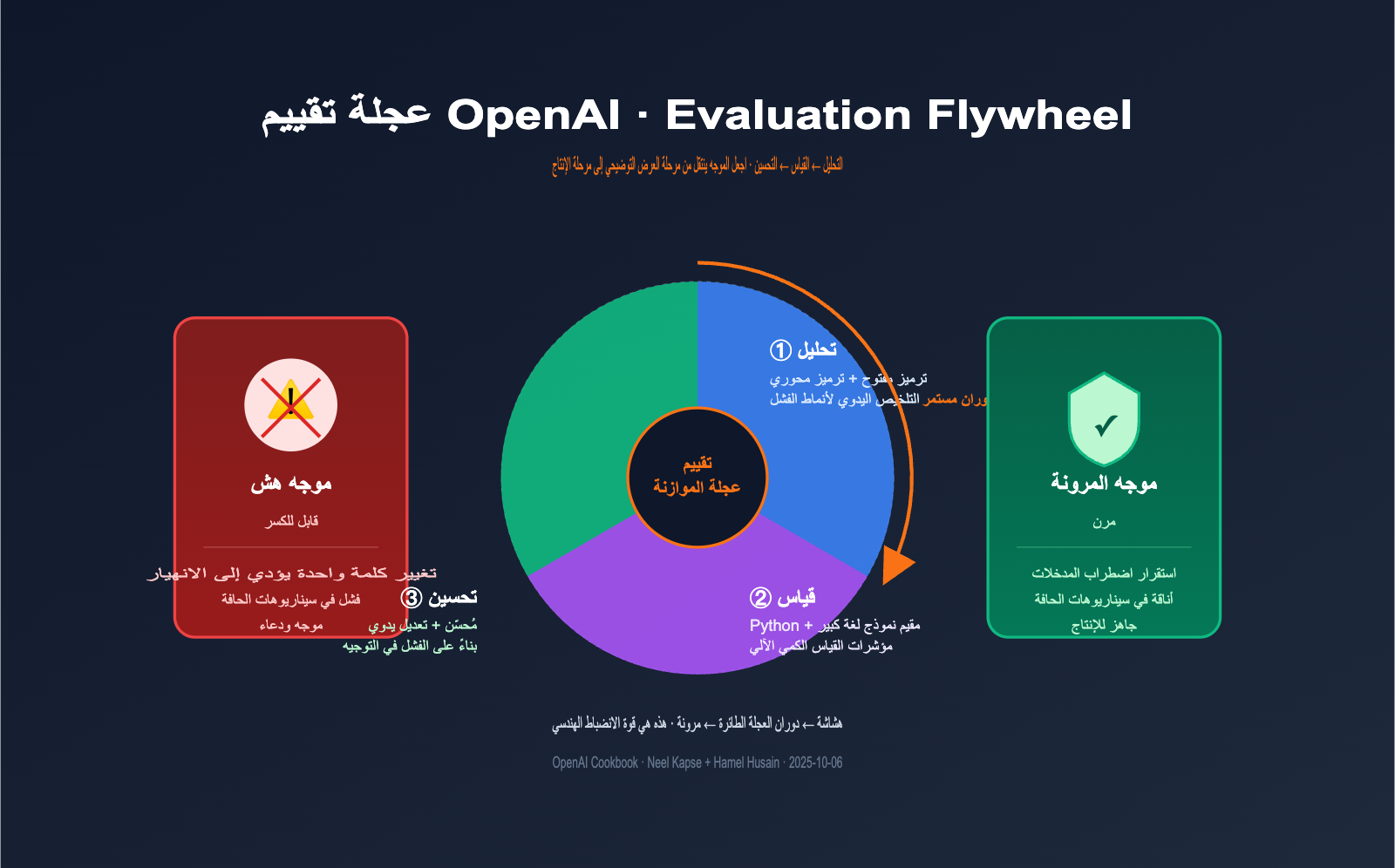
في هذا المقال، طرح مهندس OpenAI "نيل كابس" (Neel Kapse) مع خبير تعلم الآلة الشهير "هامل حسين" (Hamel Husain) المفهوم الجوهري المسمى عجلة التقييم (Evaluation Flywheel). حيث استخدما منهجية ناضجة مستمدة من البحوث النوعية في علم الاجتماع لتحويل تطوير تطبيقات الذكاء الاصطناعي من أسلوب "التعديل ثم الدعاء" (prompt-and-pray) إلى "الانضباط الهندسي". سنقوم في هذا المقال بشرح إطار عمل عجلة تقييم OpenAI بأبسط منظور ممكن، لمساعدتك في تحديد كيفية تطبيقه في مشاريعك الخاصة.
🎯 جولة سريعة: يستخدم كتاب الطبخ (cookbook) حالة واقعية لـ "مساعد ذكاء اصطناعي لتأجير الشقق" كنموذج توضيحي، حيث يعرض سير العمل الكامل بدءًا من تحليل الفشل، وصولاً إلى أداة التقييم التلقائي (grader)، وحتى التكامل مع خط أنابيب CI. الأدوات المذكورة في المقال مثل Evals API و Prompt Optimizer هي قدرات متقدمة في منصة OpenAI، ويمكنك استدعاؤها مباشرة عبر خدمات وكيل API مثل APIYI (apiyi.com). يمكن للمطورين العرب اتباع خطوات كتاب الطبخ بدقة لتنفيذ هذا المسار بنجاح.
حالة دراسية لمساعد تأجير الشقق: تطبيق ذكاء اصطناعي حقيقي تعثر بسبب سيناريوهات جانبية
الحالات المختارة في "كتاب الطبخ" (Cookbook) قريبة جداً من واقعنا اليومي: مساعد ذكاء اصطناعي يساعد المستأجرين في الإجابة على أسئلتهم، بما في ذلك استفسارات متكررة حول مساحة الشقق، حجز مواعيد المعاينة، والتعريف بالمرافق. قد يبدو الأمر للوهلة الأولى مجرد روبوت خدمة عملاء عادي، لكن بمجرد وضعه في بيئة الإنتاج الفعلية، تظهر أخطاء غريبة وغير متوقعة.
حالات الفشل المذكورة في المقال نموذجية للغاية، وكل واحدة منها تجعلك تشعر وكأنك مررت بها:
| نوع الفشل | المظهر الفعلي | العواقب |
|---|---|---|
| خطأ في الجدولة | اقتراح فترات معاينة غير متاحة | ضياع وقت المستأجر، ارتفاع معدل الشكاوى |
| اضطراب الحالة | عدم إلغاء الموعد الأصلي عند تعديله | حجز مزدوج في نفس الفترة، تضارب في خيوط المبيعات |
| انهيار التنسيق | تحول قائمة المرافق إلى كتلة نصية متداخلة | تجربة مستخدم سيئة، تعذر استهلاك المعلومات |
| روابط تالفة | روابط مخططات الوحدات السكنية تعطي خطأ 404 | فقدان المستخدمين لصالح المنافسين |
| انحراف البيانات | تعارض أوقات العمل المجابة مع البيانات الحقيقية | تضليل المستخدم، مخاطر قانونية |
إذا كنت قد عملت على أي تطبيق ذكاء اصطناعي من قبل، فأنت تعلم أن هذه المشكلات ليست ناتجة عن إهمال متعمد أثناء كتابة "الموجه" (Prompt)، بل لأنك لم تكن تتوقع حدوثها من الأساس. وقد لخص فريق Fractional هذه الظاهرة بشكل دقيق في حالة "فحص الإيصالات" (Receipt Inspection) المرفقة: إن تشغيل بضعة مسارات مثالية (happy paths) لن يكشف أبداً عن أخطاء "الذيل الطويل" (long tail bugs) في بيئة الإنتاج؛ بل يجب بناء حلقة مغلقة منهجية تتضمن "جمع حالات الفشل ← استنتاج الأنماط ← القياس التلقائي".
هذه الحلقة المغلقة هي جوهر المشكلة التي تحاول "عجلة التقييم" حلها.
التعريف الجوهري لعجلة تقييم OpenAI: الانضباط الهندسي بدلاً من "التخمين والموجهات"
يقدم كتاب الطبخ تعريفاً موجزاً لعجلة التقييم: عملية تكرارية مستمرة تستبدل التخمين بانضباط هندسي منظم. تتكون العجلة من ثلاث مراحل، تدور باستمرار كعجلة حقيقية، ومع كل دورة يزداد النظام مرونة وقوة.

مسؤوليات المراحل الثلاث واضحة جداً، حيث تعالج كل منها مشكلة محددة:
| المرحلة | المشكلة الجوهرية | الأنشطة الرئيسية | المخرجات |
|---|---|---|---|
| التحليل (Analyze) | "لماذا حدث الفشل؟" | مراجعة يدوية لعينات الفشل، استنتاج أنماط الفشل | قائمة تصنيف الفشل + نسبتها |
| القياس (Measure) | "ما مدى خطورة الفشل؟" | إنشاء أداة تقييم (grader)، تشغيل مجموعة البيانات | مؤشرات كمية + خط أساس (baseline) |
| التحسين (Improve) | "كيف نصلح الأمر؟" | تعديل الموجه، إعادة تشغيل التقييم | إصدار جديد + مقارنة المؤشرات |
تتخطى العديد من الفرق مرحلة "التحليل" وتنتقل مباشرة إلى التقييم التلقائي، وهذا هو السبب الأكثر شيوعاً لفشل عجلة التقييم. إن القياس التلقائي بدون تحليل نوعي ليس سوى بناء في الهواء، لأنك ببساطة لا تعرف ما الذي تقيسه. هذه هي الرؤية الأكثر أهمية في كتاب الطبخ هذا، وهي ما يميزه عن دروس التقييم العادية.
💡 فهم بالقياس: تشبه عجلة التقييم دورة (PDCA) التي يعرفها مديرو المنتجات، ولكن عند تطبيقها على هندسة الموجهات، فإنها تكتسب منهجية محددة. التحليل يقابل "البحث عن المشكلة"، والقياس يقابل "تحديد حجم المشكلة"، والتحسين يقابل "إصلاح المشكلة"، ولا يمكن الاستغناء عن أي من هذه الخطوات الثلاث. ننصح عند تشغيل التقييم عبر APIYI.com باستخدام OpenAI Evals API، بالتأكد من إتمام مرحلة التحليل بشكل متقن قبل البدء في القياس.
المرحلة الأولى من عجلة تقييم OpenAI: طريقة التصنيف المكونة من خطوتين في مرحلة التحليل (Analyze)
تعد مرحلة التحليل هي الحلقة الأكثر أهمية والأكثر تجاهلاً في عجلة التقييم. يقدم دليل OpenAI (Cookbook) هنا منهجية احترافية للغاية: الترميز المفتوح (Open Coding) ← الترميز المحوري (Axial Coding). هذه المنهجية مستمدة من البحوث النوعية في علم الاجتماع، وقد أثبتت كفاءتها على مدى عقود كواحدة من أكثر النماذج نضجاً لتحليل بيانات النصوص غير المهيكلة.
الخطوة الأولى: الترميز المفتوح (Open Coding)، عملها بسيط ومباشر: اقرأ 50 عينة فاشلة، ولا تضع أي تصنيفات مسبقة، بل ضع ملصقاً وصفياً لكل فشل. على سبيل المثال:
- "تم اقتراح وقت معاينة غير موجود"
- "قائمة المرافق عبارة عن كتلة نصية غير منظمة"
- "تعديل الموعد لم يلغِ الموعد الأصلي"
- "تمت الإجابة بمقاسات لا تخص هذه الشقة"
- "رابط مخطط الشقة لا يعمل"
لاحظ أن هذه الخطوة تتعمد عدم السعي وراء تنظيم التصنيفات، فكل ما تحتاجه هو وصف ما تراه بصدق. يشبه الترميز المفتوح تدوين ملاحظات القراءة؛ حيث تكون الأفكار حرة وغير مقيدة، لأن التصنيف المبكر قد يجعلك تفقد القدرة على ملاحظة الأنماط الهامشية.
الخطوة الثانية: الترميز المحوري (Axial Coding)، هنا تبدأ الهيكلة، حيث تقوم بدمج الملصقات المبعثرة من الخطوة الأولى في تصنيفات عليا ذات معنى. التصنيفات المقترحة في الدليل هي:
- مشاكل جدولة المعاينة (دمج: وقت خاطئ، عدم إلغاء، حجز مزدوج) ← تمثل 35% من حالات الفشل.
- أخطاء التنسيق (دمج: انهيار التنسيق، روابط معطلة) ← تمثل 10% من حالات الفشل.
- مشاكل دقة البيانات (دمج: خطأ في ساعات العمل، خطأ في المقاسات) ← تمثل نسبة معينة من حالات الفشل.
يشبه الترميز المحوري تنظيم جدول المحتويات، مما يتيح لك رؤية "خريطة تضاريس" الفشل. الرقم (35%) يخبرك فوراً بالفئة التي يجب إصلاحها أولاً، لأنها توفر أعلى عائد على الاستثمار (ROI).
| طريقة التصنيف | الهدف | العقلية | المخرجات |
|---|---|---|---|
| الترميز المفتوح | الاكتشاف (Discovery) | حر، بدون تصنيفات مسبقة | 50+ ملصق وصفي |
| الترميز المحوري | الهيكلة (Structure) | الاستقراء، بناء التصنيفات | 5-8 فئات فشل عليا |
🔧 نصيحة عملية: يمكن للمطورين عند تنفيذ مرحلة التحليل ربط سجلات الإنتاج مباشرة بواجهة تصنيف البيانات في منصة Evals عبر خدمة وكيل API (مثل apiyi.com)، دون الحاجة لكتابة خلفية برمجية خاصة. استخدم نوع "Feedback" لملصقات الترميز المفتوح، ونوع "Label" للترميز المحوري، لتتوافق العملية تماماً مع دليل OpenAI.
المرحلة الثانية من عجلة تقييم OpenAI: اختيار نوعين من المقيمين (Grader) في مرحلة القياس (Measure)
بعد أن عرفت في مرحلة التحليل "كيف يبدو الفشل"، تأتي مرحلة القياس لتحويل هذه الإخفاقات إلى أكواد فحص تلقائية. يقدم الدليل هنا دليلاً لاختيار نوعين من المقيمين، وهو أمر يخلط فيه المهندسون غالباً.
| نوع المقيم (Grader) | سيناريو الاستخدام | المميزات | العيوب |
|---|---|---|---|
| مقيم Python | القواعد الحتمية (السلاسل النصية، Regex، التحقق من API) | نتائج مستقرة، لا هلوسة، تكلفة إضافية صفرية | لا يمكنه تقييم الأبعاد الذاتية |
| مقيم LLM | الأحكام الذاتية (جمال التنسيق، توافق المعنى، جودة الاستنتاج) | مرن، يقيم أبعاداً يصعب برمجتها | يحتاج لضبط مع خبير (SME)، تكلفة Token |
بالعودة لمثال مساعد الشقق، لكل نوع من المقيمين مجاله:
- "هل الوقت المقترح ضمن فترات التوفر الحقيقية؟" ← مقيم Python (فحص قاعدة البيانات أو API).
- "هل قائمة المرافق منسقة بشكل جميل؟" ← مقيم LLM (تقييم من 0-10).
- "هل رابط مخطط الشقة قابل للوصول؟" ← مقيم Python (طلب HEAD).
- "هل نبرة الإجابة تتوافق مع هوية العلامة التجارية؟" ← مقيم LLM (تقييم بناءً على معايير محددة).
يؤكد الدليل على ممارسة هندسية بالغة الأهمية: يجب ضبط مقيم LLM من قبل خبير في المجال (SME)، ولا ينبغي الوثوق بتقييم GPT-4o بشكل أعمى. الطريقة المحددة هي تقسيم البيانات إلى (تدريب/تحقق/اختبار)، وفحص مؤشرين في آن واحد:
- معدل الإيجابيات الحقيقية المرتفع (High TPR): القدرة على اكتشاف الفشل الحقيقي.
- معدل السلبيات الحقيقية المرتفع (High TNR): عدم ظلم العينات الصحيحة.
النظر إلى الدقة وحدها قد يخدعك، لذا يجب موازنة المؤشرين معاً. هذه النقطة هي الفاصل بين جعل "LLM-as-Judge" يبدو وكأنه يعمل، وبين كونه يعمل فعلياً.
📊 عملية التحقق: يقوم خبير (SME) بتصنيف 100 عينة كحقيقة أساسية (ground truth) ← يقوم مقيم LLM بتقييم نفس العينات ← حساب TPR / TNR ← تعديل موجه (prompt) المقيم حتى تتحقق المؤشرات. تدعم منصة Evals في apiyi.com هذه العملية بشكل أصلي، لأنها متوافقة تماماً مع بروتوكولات OpenAI الرسمية.
المرحلة الثالثة من عجلة تقييم OpenAI: تجارب المسار المزدوج للتحسين (Improve)
في المرحلة الثالثة، يمكنك أخيرًا البدء في تعديل الموجه (Prompt). يقدم دليل OpenAI مسارين متوازيين للتحسين، وهما ليسا خيارين متنافيين، بل يكملان بعضهما البعض.
المسار الأول: التحسين التلقائي باستخدام Prompt Optimizer
توفر منصة OpenAI أداة "مُحسِّن الموجه" (Prompt Optimizer) مدمجة. يمكنك تزويدها بمجموعة من الأمثلة الفاشلة والموجه الأصلي، وستقوم تلقائيًا بتجربة سلسلة من استراتيجيات إعادة الصياغة (مثل إضافة أمثلة قليلة few-shot، أو إضافة سلسلة أفكار chain-of-thought، أو تعديل ترتيب التعليمات، إلخ)، ثم تقييم نتائج التحسين باستخدام أداة التقييم (Grader) الخاصة بك. ميزة هذا المسار هي توفير الجهد، وهو مناسب كخطوة استكشافية أولية.
المسار الثاني: التعديل اليدوي للموجه بناءً على أنماط الفشل
بناءً على أنماط الفشل المحددة التي تم تلخيصها في مرحلة التحليل (Analyze)، يقوم المهندسون بتعديل الموجه يدويًا وبشكل مستهدف. على سبيل المثال:
- خطأ في جدولة معاينة العقارات ← إضافة خطوة إجبارية في الموجه لـ "التحقق من الجدول الزمني المتاح".
- انهيار التنسيق ← استخدام وسوم XML لتحديد تنسيق المخرجات بوضوح.
- عدم إلغاء الموعد المعدل ← إضافة تعليمات "آلة الحالة" (State Machine) لـ "الإلغاء أولاً ثم الحجز".
تكمن ميزة المسار اليدوي في الدقة؛ فأنت تعرف بالضبط أي تغيير يستهدف أي نمط فشل، مما يمنحك وضوحًا أثناء تصحيح الأخطاء (debug).
بعد الانتهاء من كلا المسارين، سيكون لديك عدة نسخ مرشحة للموجه. وهنا تأتي الخطوة الأكثر أهمية في مرحلة التحسين: تشغيل جميع النسخ على نفس مجموعة البيانات باستخدام نفس أداة التقييم (Grader)، واختيار النسخة ذات المؤشرات الأفضل. لا يمكن تخطي هذه الخطوة، لأن البشر لديهم انحياز طبيعي للثقة المفرطة في تعديلاتهم الخاصة، والشيء الوحيد الذي يمكنه تصحيح هذا الانحياز هو الأرقام.
بعد تشغيل جميع النسخ، تكون قد أتممت دورة واحدة من "عجلة التقييم". ستكتشف أنماط فشل جديدة (لأن النظام أصبح أفضل، مما يكشف عن حالات حافة أكثر تعقيدًا)، ثم تعود إلى مرحلة التحليل لبدء الدورة التالية. هذا هو جوهر مصطلح "عجلة التقييم"؛ فهي لا تتوقف، بل تزداد سرعة ومرونة مع كل دورة.
الفرق الجوهري بين الموجه المرن (Resilient Prompt) والموجه الهش
مفهوم "الموجه المرن" (Resilient Prompt) المذكور في العنوان هو مفهوم حيوي للغاية، ويعرفه دليل OpenAI بأنه: الموجه الذي يمكنه تقديم استجابات عالية الجودة عبر جميع المدخلات الممكنة. قد يبدو هذا بسيطًا، لكنه في الواقع معيار هندسي عالٍ جدًا.

تتجلى الاختلافات بين المرونة والهشاشة في خمسة أبعاد:
| بُعد المقارنة | الموجه الهش | الموجه المرن |
|---|---|---|
| قوة المدخلات | ينهار بتغيير كلمة واحدة | مستقر حتى مع إعادة الصياغة المرادفة |
| حالات الحافة | مخرجات غريبة أو هلوسة | تدهور أنيق أو تحويل للبشر |
| القابلية للملاحظة | صندوق أسود، التخمين فقط عند الخطأ | أداة تقييم كاملة لتحديد المواقع |
| الاعتماد في الإنتاج | أداء العرض لا يساوي أداء الإنتاج | اجتياز حلقة تقييم كاملة |
| القابلية للتطور | تعديل A يفسد B | حماية تلقائية عبر الاختبارات التراجعية |
في حدس المهندسين، قد يبدو الموجه "جيدًا بما يكفي"، ولكن عند وضعه في بيئة الإنتاج، ستظهر مشكلات بنسبة 0.1%؛ قد تبدو هذه النسبة ضئيلة، لكنها تعني 1000 حادثة في مليون استدعاء. القيمة الهندسية للموجه المرن ليست في رفع الأداء من 80% إلى 90%، بل في رفعه من 99% إلى 99.9%.
🚀 نصيحة للربط: للوصول بالموجه إلى مرونة بنسبة 99.9%، يجب أتمتة حلقة التقييم، وهذا يتطلب استدعاءً مستقرًا لـ OpenAI Evals API وأداة Prompt Optimizer. نوصي باستخدام منصات مثل apiyi.com لخدمات وكيل API لـ OpenAI، حيث تتزامن الواجهات تمامًا مع الرسمية، وتضمن عقد مراكز البيانات المحلية عدم انقطاع مهام التقييم الطويلة.
تكامل CI/CD ومراقبة الإنتاج في حلقة تقييم OpenAI
يؤكد دليل OpenAI في نهايته على خطوة حاسمة: تحويل حلقة التقييم إلى انضباط هندسي يومي. يتطلب هذا التنفيذ العملي شقين:
الشق الأول: تكامل CI/CD
ربط مجموعة أدوات التقييم (Grader) بخط أنابيب CI، بحيث يتم تشغيل التقييم تلقائيًا مع كل تغيير في "الموجه". إذا تراجع الأداء عن العتبة المحددة، يتم حظر دمج طلب السحب (PR) تلقائيًا. هذه الخطوة تحول "التقييم" من مجرد نشاط بحثي إلى ممارسة تطوير يومية، وهي العلامة الفارقة في تحويل هندسة الموجهات إلى عملية هندسية حقيقية.
| نوع عتبة CI | الإعداد الموصى به | التوضيح |
|---|---|---|
| الدقة الإجمالية | تراجع ≤ 1% | منع التراجع العام في الأداء |
| مقياس التقييم الرئيسي | تراجع ≤ 0.5% | رقابة صارمة على أنماط الفشل عالية الأولوية |
| اكتشاف أنماط جديدة | تحذير دون حظر | تشجيع اكتشاف مشكلات جديدة |
| زمن الاستجابة P95 | نمو ≤ 10% | التحكم في التكلفة وتجربة المستخدم |
الشق الثاني: مراقبة الإنتاج
إلى جانب CI، يجب أخذ عينات مستمرة من بيئة الإنتاج لاكتشاف "أنماط الفشل البرية" التي لا تغطيها مجموعة اختبارات CI. تُضاف هذه الأنماط الجديدة لاحقًا إلى مجموعة التقييم لدفع الحلقة للدوران في دورتها التالية.
تتمثل الممارسة العملية في أخذ عينات من سجلات الإنتاج بنسبة معينة (مثل 1%)، وتشغيل نفس أدوات التقييم عليها، ثم استخراج النتائج التي تظهر مؤشرات غير طبيعية للتحليل البشري. بعد معالجة أنماط الفشل المكتشفة حديثًا عبر "الترميز المفتوح" (Open Coding) ثم "الترميز المحوري" (Axial Coding)، تُضاف إلى مجموعة الاختبار، وتستمر الحلقة في الدوران.
هذه الدورة تجعل نظام "الموجه" الخاص بك أكثر مرونة باستمرار، بدلاً من أن يتوقف عن التطور بعد النشر. هذا هو الانضباط الهندسي الجوهري الذي يقدمه الدليل لكل مهندس ذكاء اصطناعي.
5 دروس عملية للمطورين من حلقة تقييم OpenAI
بعد قراءة الدليل بعمق، استخلصت 5 دروس ذات أهمية مباشرة للمطورين العرب:
الدرس الأول: ابدأ بالتحليل (Analyze)، لا بالقياس (Measure)
تبدأ العديد من الفرق مباشرة بإعداد أدوات التقييم ومطاردة الأرقام، متجاوزة مرحلة التحليل البشري. يؤدي هذا إلى قياس أدوات التقييم لأشياء لا تمثل أنماط الفشل الحقيقية، فتكون الأرقام مبهرة بينما لا تزال شكاوى المستخدمين مستمرة. لا تبدأ التقييم التلقائي قبل إجراء 50 عملية "ترميز مفتوح" (Open Coding) يدويًا.
الدرس الثاني: لا تترك مرحلة "الترميز المفتوح" لنموذج GPT
يجب أن يقوم البشر بمرحلة "الترميز المفتوح"، لأن نموذج اللغة الكبير سيلوث تصنيفاتك بتحيزات بيانات التدريب الموجودة لديه. الوقت المناسب لإشراك النموذج هو بعد مرحلة "الترميز المحوري" (Axial Coding) عند تنفيذ أدوات التقييم؛ فمرحلة "الاكتشاف" في التحليل هي حكر على البشر.
الدرس الثالث: أدوات التقييم البرمجية (Python Grader) أولاً، ثم المعتمدة على الذكاء الاصطناعي
طالما يمكنك تغطية الحالة بقواعد برمجية محددة، فلا تستخدم أدوات التقييم المعتمدة على نماذج اللغة الكبيرة (LLM Grader). الأسباب ثلاثة: الاستقرار، التكلفة، وعدم الحاجة لمواءمة الخبراء (SME). اترك أدوات التقييم المعتمدة على الذكاء الاصطناعي للأبعاد الذاتية التي لا يمكن تغطيتها بالقواعد.
الدرس الرابع: اربط المؤشرات بالتأثير التجاري
35% مشكلات في الجدولة، 10% مشكلات في التنسيق—يجب تحويل هذه النسب إلى "معدل فقدان المستخدمين" أو "معدل الشكاوى" لتكون ذات قيمة في اتخاذ القرار. المؤشرات بحد ذاتها لا معنى لها، بل العواقب التجارية المترتبة عليها هي المهمة.
الدرس الخامس: اجعل الحلقة أوتوماتيكية، لا مشروعًا لمرة واحدة
قد لا يكون العائد على الاستثمار (ROI) لدورة واحدة من الحلقة مرتفعًا بشكل مذهل، لكن العائد التراكمي على المدى الطويل كبير جدًا. اجعل أدوات التقييم مهام CI، واجعل أخذ عينات الإنتاج مهمة مجدولة، واجعل اكتشاف الأنماط الجديدة تنبيهًا تلقائيًا، لتعمل الحلقة وتدور ذاتيًا على مدار الساعة.
هيكل كود Python لمحاكاة "عجلة تقييم OpenAI" محلياً
على الرغم من أن دليل OpenAI (Cookbook) يركز بشكل أساسي على سير عمل واجهة المستخدم لمنصة OpenAI، إلا أن الاستدعاء البرمجي لـ Evals API مدعوم أيضاً. يوضح هيكل كود Python التالي كيفية استدعاء Evals API لإنشاء مقيم (Grader) وتشغيل التقييم، وهو مناسب للمطورين الذين يفضلون سير العمل البرمجي:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # التبديل إلى بوابة APIYI الرسمية
api_key="مفتاح API الخاص بك من APIYI"
)
# 1. إنشاء مهمة تقييم (تعريف مجموعة المقيمين)
eval_cfg = await client.evals.create(
name="leasing_assistant_v1",
data_source_config={
"type": "stored_completions",
"metadata": {"version": "v1"}
},
testing_criteria=[
{ # مثال لمقيم Python
"type": "string_check",
"name": "tour_time_valid",
"input": "{{sample.output}}",
"operation": "eq",
"reference": "{{item.expected_time}}"
},
{ # مثال لمقيم نموذج لغة كبير (LLM Grader)
"type": "score_model",
"name": "format_quality",
"model": "gpt-4o",
"input": "{{sample.output}}",
"instructions": "قيم وضوح تنسيق المخرجات من 0 إلى 10"
}
]
)
# 2. تشغيل التقييم
run = await client.evals.runs.create(
eval_id=eval_cfg.id,
name="baseline_run",
data_source={"type": "completions"}
)
# 3. سحب نتائج التقييم
result = await client.evals.runs.retrieve(eval_id=eval_cfg.id, run_id=run.id)
print(f"معدل النجاح: {result.report_url}")
يحتوي هذا الكود على ثلاث نقاط رئيسية: الأولى هي تبديل base_url؛ فهذا السطر يحدد قدرتك على تشغيل مهام التقييم الطويلة بثبات داخل البلاد. الثانية هي مصفوفة testing_criteria؛ حيث يمكنك تكوين جميع المقيمين في مصفوفة واحدة وتشغيلهم دفعة واحدة. الثالثة هي أن Evals API تعمل بشكل غير متزامن (Asynchronous)، لذا قد يستغرق تشغيل التقييم على مجموعات بيانات كبيرة من بضع دقائق إلى عشرات الدقائق، ويجب أن يتعامل برنامجك مع الانتظار وإعادة المحاولة.
الأسئلة الشائعة حول "عجلة تقييم OpenAI"
س1: هل هناك فرق بين "عجلة التقييم" ومنصات التقييم مثل LangSmith أو Weights&Biases؟
التوجه مختلف. يركز LangSmith بشكل أساسي على "أدوات التقييم"، بينما تعالج "عجلة التقييم" منهجية التقييم. الأول يخبرك بكيفية التنفيذ، بينما يخبرك الثاني بكيفية التفكير. يمكن استخدام كليهما معاً، حيث تعمل الأدوات كحامل للمنهجية.
س2: هل 50 عينة فاشلة كافية؟ أليس هذا العدد قليلاً جداً؟
في مرحلة الترميز المفتوح (Open Coding)، يكفي 50 عينة لأن الهدف هو اكتشاف الأنماط وليس حصر الإحصائيات. أما في مرحلة القياس (Measure)، فيعتمد عدد العينات المطلوب على معدل الفشل: إذا كان معدل الفشل 5%، فستحتاج إلى 1000 عينة للحصول على مؤشرات موثوقة؛ أما إذا كان معدل الفشل 30%، فتكفي 200 عينة.
س3: هل يمكن لـ Prompt Optimizer (محسن الموجهات) أن يحل محل التعديل اليدوي تماماً؟
لا. الأدوات التلقائية بارعة في التحسين المحلي بناءً على مقيمين معروفين، لكنها لا تجيد فهم قيود العمل (مثل القاعدة الضمنية التي تطلب ألا تتجاوز كل استجابة 80 حرفاً). الجمع بين التعديل اليدوي والتحسين التلقائي هو الممارسة الأفضل.
س4: هل استدعاء Evals API مستقر داخل البلاد؟
الاتصال المباشر بـ OpenAI غالباً ما يؤدي إلى إعادة تعيين الاتصال عند تشغيل مهام طويلة (التي تستغرق عادةً من بضع دقائق إلى ساعات). ننصح باستخدام بوابة OpenAI مثل apiyi.com، حيث تم تحسين عقد مراكز البيانات المحلية للاتصالات طويلة الأمد، مما يقلل بشكل كبير من معدل انقطاع مهام التقييم.
س5: ما هو حجم الفريق المناسب لاستخدام "عجلة التقييم"؟
تناسب الجميع، من مشاريع الفرد الواحد إلى الفرق المكونة من 100 شخص. الفرق يكمن فقط في وتيرة دوران العجلة؛ فقد يدور مشروع الفرد الواحد دورة كل أسبوعين، بينما يمكن للفرق الكبيرة تحقيق تكرار يومي أو حتى كل ساعة. المفتاح هو بناء الانضباط، وليس الحجم.
س6: من هو Hamel Husain، ولماذا يحظى هذا الدليل بكل هذا الاهتمام؟
Hamel هو معلم ذو تأثير كبير في مجتمع تعلم الآلة، ويعمل منذ فترة طويلة على تعزيز أفضل الممارسات الهندسية لتطبيقات نماذج اللغة الكبيرة. هذا الدليل هو المرة الأولى التي تقدم فيها OpenAI رسمياً منهجية البحث النوعي (مثل Open Coding) إلى هندسة الموجهات، ولهذا السبب هناك الكثير من النقاشات حوله في الصناعة.
ملخص
تكمن القيمة الحقيقية لمنهجية عجلة تقييم OpenAI (OpenAI Evals Flywheel) في أنها قدمت لمجتمع مهندسي الذكاء الاصطناعي الناطقين بالعربية الإجابة النموذجية على سؤال: "كيف يمكن تنفيذ هندسة الموجه (Prompt Engineering) بشكل احترافي؟". إنها ليست مجرد أداة محددة، بل هي انضباط هندسي يحول تطوير الموجه من "حرفة تعتمد على الحدس" إلى "ممارسة هندسية منهجية".
من خلال دمج مراحل التحليل (Analyze)، والقياس (Measure)، والتحسين (Improve) في دورة حياة التطوير، يرتقي تطبيق الذكاء الاصطناعي الخاص بك من مجرد "نموذج تجريبي يبدو جيداً" إلى منتج "جاهز للإنتاج وموثوق لاتفاقيات مستوى الخدمة (SLA)". خلف هذا الارتقاء تكمن حلقة مغلقة متكاملة، حيث يتم جمع حالات الفشل بشكل منهجي، وتصنيف الأنماط هيكلياً، والتحقق من التحسينات عبر قياسات آلية.
إذا كنت تعمل على أي تطبيق ذكاء اصطناعي يعتمد على الموجهات، فنحن نوصي بشدة ببناء هذه العجلة. نقترح استخدام منصات وكيل API لـ OpenAI مثل APIYI (عبر apiyi.com) لاستدعاء واجهات Evals API ومُحسّن الموجهات (Prompt Optimizer) مباشرة؛ حيث يمكنك تشغيل كامل مسار العمل (cookbook) بمجرد تغيير سطر واحد في base_url دون القلق بشأن مشاكل استقرار الشبكة.
اجعل هذه "العجلة" جزءاً من ذاكرتك العضلية، وسيبدأ موجهك من اليوم في اكتساب المرونة والقوة.
📌 المؤلف: فريق APIYI — نتابع عن كثب الممارسات الهندسية لواجهات برمجة التطبيقات متعددة الوسائط من OpenAI وAnthropic وGoogle. لمزيد من التحليلات العملية حول الـ cookbook وأدلة الوصول إلى Evals API، تفضل بزيارة مركز التوثيق على apiyi.com.