Was ist das Frustrierendste, wenn man heutzutage KI-Anwendungen entwickelt? Höchstwahrscheinlich dieses Szenario: Sie haben die 17. Version Ihrer Eingabeaufforderung erstellt, ein paar Testfälle durchlaufen lassen und das Gefühl, es läuft besser – doch sobald das System live geht, bringt ein völlig unerwarteter Edge-Case das Modell zum Absturz. Genau dieses Problem möchte OpenAI mit dem im Oktober 2025 veröffentlichten Cookbook-Artikel "Building resilient prompts using an evaluation flywheel" lösen.
Die OpenAI-Ingenieure Neel Kapse und der bekannte ML-Experte Hamel Husain führen darin das Kernkonzept des Evaluation Flywheel (Evaluierungs-Schwungrad) ein. Mit einer bewährten Methodik aus der qualitativen Sozialforschung heben sie die Entwicklung von KI-Anwendungen von einem „Prompt-and-Pray“-Ansatz (anpassen und hoffen) hin zu einer echten Ingenieursdisziplin. Dieser Artikel erläutert den OpenAI-Evaluierungs-Schwungrad-Rahmen auf verständliche Weise und zeigt Ihnen, wie Sie ihn in Ihren eigenen KI-Projekten umsetzen können.
🎯 Kurzübersicht: Das Cookbook nutzt einen realen „Wohnungsmiet-Assistenten“ als Fallbeispiel und zeigt den gesamten Workflow von der Fehleranalyse über den automatischen Grader bis zur CI-Integration. Die im Artikel erwähnten Evals-API- und Prompt-Optimizer-Tools sind fortgeschrittene Funktionen der OpenAI-Plattform, die über API-Proxy-Dienste wie APIYI (apiyi.com) direkt genutzt werden können. Entwickler können den Cookbook-Workflow somit problemlos übernehmen.
Fallbeispiel Wohnungsmiet-Assistent: Eine KI, die an Edge-Cases scheitert
Das im Cookbook gewählte Beispiel ist praxisnah: Ein KI-Assistent, der Mietern Fragen zu Wohnungsgrößen, Besichtigungsterminen und Einrichtungen beantwortet. Was zunächst wie ein gewöhnlicher Chatbot klingt, offenbart in der Produktionsumgebung die unterschiedlichsten Schwachstellen.
Die im Artikel aufgeführten Fehlerbeispiele sind äußerst repräsentativ und für viele Entwickler nachvollziehbar:
| Fehlertyp | Auswirkung | Konsequenz |
|---|---|---|
| Planungsfehler | Empfiehlt nicht existierende Besichtigungstermine | Mieter kommen umsonst, Beschwerderate steigt |
| Status-Chaos | Storniert bei Terminänderung den alten Termin nicht | Doppelbuchungen, verwirrte Vertriebsmitarbeiter |
| Layout-Fehler | Einrichtungslisten werden als unleserlicher Textblock ausgegeben | Schlechte User Experience, Informationen unbrauchbar |
| Defekte Links | Grundriss-Link führt zu 404-Fehler | Nutzer wandern zur Konkurrenz ab |
| Daten-Drift | Öffnungszeiten weichen von den tatsächlichen Daten ab | Irreführung der Nutzer, rechtliche Risiken |
Wer bereits KI-Anwendungen entwickelt hat, weiß: Solche Fehler entstehen nicht, weil man bei der Erstellung der Eingabeaufforderung nachlässig war, sondern weil man sich der potenziellen Probleme schlichtweg nicht bewusst war. Das Fractional-Team fasst dieses Phänomen im zugehörigen „Receipt Inspection“-Beispiel treffend zusammen: Das bloße Testen von „Happy Paths“ findet niemals die Long-Tail-Bugs der Produktionsumgebung. Man muss einen systematischen Kreislauf aus „Fehlersammlung → Mustererkennung → automatisierte Messung“ etablieren.
Genau diesen Kreislauf soll das Evaluierungs-Schwungrad schließen.
Die Kerndefinition des OpenAI-Evaluierungs-Schwungrads: Ingenieursdisziplin statt „Prompt-and-Pray“
Das Cookbook definiert das Evaluierungs-Schwungrad prägnant: Ein kontinuierlicher iterativer Prozess, der bloßes Raten durch strukturierte Ingenieursdisziplin ersetzt. Es besteht aus drei Phasen und dreht sich wie ein echtes Schwungrad – mit jeder Umdrehung wird das System widerstandsfähiger.
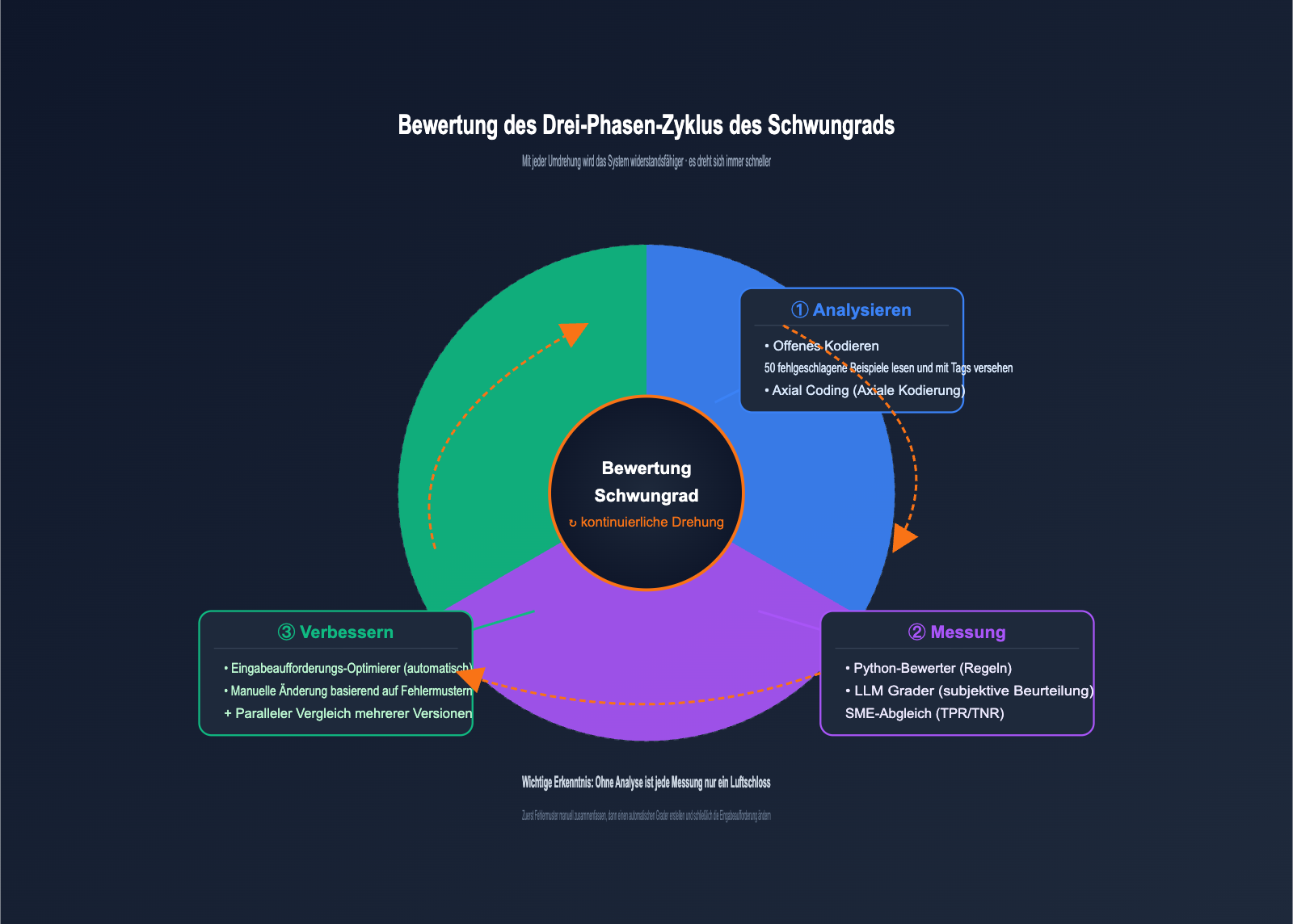
Die Aufgaben der drei Phasen sind klar definiert und adressieren jeweils ein spezifisches Problem:
| Phase | Kernproblem | Hauptaktivität | Output |
|---|---|---|---|
| Analyze (Analyse) | "Warum schlägt es fehl?" | Manuelle Prüfung von Fehlern, Identifikation von Mustern | Fehlerkategorien + Verteilung |
| Measure (Messung) | "Wie schwerwiegend ist der Fehler?" | Erstellung von Grader, Ausführung des Datensatzes | Quantifizierbare Metriken + Baseline |
| Improve (Verbesserung) | "Wie behebe ich es?" | Anpassung der Eingabeaufforderung, erneute Evaluierung | Neue Version + Metrikvergleich |
Viele Teams überspringen die Analyse-Phase und stürzen sich direkt auf die automatische Evaluierung – dies ist der häufigste Grund für das Scheitern des Evaluierungs-Schwungrads. Automatisierte Messungen ohne qualitative Analyse sind Luftschlösser, da man schlicht nicht weiß, was man eigentlich misst. Dies ist die zentrale Erkenntnis des Cookbooks und unterscheidet es von gewöhnlichen Tutorials zu Evaluierungen.
💡 Analogie: Das Evaluierungs-Schwungrad ähnelt dem PDCA-Zyklus, den Produktmanager kennen, bietet jedoch eine konkrete Methodik für das Prompt-Engineering. Analyze entspricht der "Problemanalyse", Measure der "Quantifizierung" und Improve der "Problemlösung" – alle drei Schritte sind unverzichtbar. Wir empfehlen, bei der Nutzung der OpenAI Evals API über APIYI erst die Analyse-Phase solide abzuschließen, bevor die Messung gestartet wird.
OpenAI Evaluierungs-Schwungrad Phase 1: Die Zwei-Schritte-Annotation der Analyse
Die Analyse-Phase wird oft übersehen, ist aber der kritischste Teil. Das Cookbook schlägt hier eine professionelle Methode vor: Open Coding (Offene Kodierung) → Axial Coding (Axiale Kodierung). Diese Methode stammt aus der qualitativen Sozialforschung und ist einer der bewährtesten Ansätze zur Analyse unstrukturierter Textdaten.
Schritt 1: Open Coding ist simpel: Lesen Sie 50 fehlerhafte Beispiele, ohne voreingenommene Kategorien, und versehen Sie jeden Fehler mit einem beschreibenden Label. Beispiele:
- "Empfohlener Besichtigungstermin existiert nicht"
- "Einrichtungsliste ist ein unleserlicher Textblock"
- "Terminänderung hat ursprünglichen Termin nicht storniert"
- "Antwort bezieht sich auf falsche Wohnungsgröße"
- "Link zum Grundriss funktioniert nicht"
Achten Sie darauf, in diesem Schritt bewusst keine saubere Kategorisierung anzustreben. Beschreiben Sie einfach ehrlich, was Sie sehen. Open Coding ist wie das Schreiben von Notizen – bleiben Sie offen, denn eine zu frühe Kategorisierung führt zum Verlust von Randphänomenen.
Schritt 2: Axial Coding bringt Struktur hinein. Hier fassen Sie die losen Labels aus dem ersten Schritt zu aussagekräftigen, übergeordneten Kategorien zusammen. Das Cookbook schlägt folgende Kategorien vor:
- Probleme bei der Terminplanung (Zusammenfassung: falsche Zeit, nicht storniert, Doppelbuchung) → 35 % der Fehler
- Formatierungsfehler (Zusammenfassung: Layout-Fehler, defekte Links) → 10 % der Fehler
- Genauigkeit der Daten (Zusammenfassung: falsche Öffnungszeiten, falsche Maße) → X % der Fehler
Axial Coding ist wie das Erstellen eines Inhaltsverzeichnisses, das Ihnen eine "Landkarte" der Fehler liefert. Die 35 % zeigen Ihnen sofort, wo der höchste ROI für eine Fehlerbehebung liegt.
| Annotationsmethode | Ziel | Denkweise | Output |
|---|---|---|---|
| Open Coding | Entdeckung | Offen, keine Vorannahmen | 50+ beschreibende Labels |
| Axial Coding | Strukturierung | Induktiv, Kategorien bilden | 5-8 übergeordnete Fehlerkategorien |
🔧 Praxistipp: Entwickler können für die Analyse-Phase ihre Produktionslogs über den API-Proxy-Dienst (z. B. APIYI) direkt an die Dataset-Annotationsoberfläche der Evals API anbinden, ohne ein eigenes Backend zu schreiben. Nutzen Sie Feedback-Typen für das Open Coding und Label-Typen für das Axial Coding – der Prozess bleibt identisch mit dem Cookbook.
Phase 2 des OpenAI-Evaluierungs-Flywheels: Auswahl der zwei Grader-Typen für „Measure“ (Messung)
In der Analyse-Phase haben Sie bereits gelernt, „wie ein Fehler aussieht“. In der Measure-Phase geht es nun darum, diese Fehler in automatisierten Prüfcode zu übersetzen. Das Cookbook bietet hier einen Leitfaden für die Auswahl von zwei Arten von Gradern – ein Punkt, an dem viele Ingenieure häufig ins Stolpern geraten.
| Grader-Typ | Einsatzszenario | Vorteile | Nachteile |
|---|---|---|---|
| Python Grader | Deterministische Regeln (Strings, Regex, API-Validierung) | Stabiles Ergebnis, keine Halluzinationen, keine zusätzlichen Kosten | Subjektive Dimensionen schwer kodierbar |
| LLM Grader | Subjektive Beurteilung (Formatierung, semantische Ausrichtung, Qualität der Schlussfolgerung) | Flexibel, bewertet schwer kodierbare Dimensionen | Erfordert SME-Abgleich, verursacht Token-Kosten |
Am Beispiel eines Wohnungsassistenten lässt sich der Einsatz beider Grader-Typen gut verdeutlichen:
- „Liegt die empfohlene Zeit innerhalb des verfügbaren Zeitfensters?“ → Python Grader (Datenbank- oder API-Abfrage)
- „Ist die Liste der Ausstattungsmerkmale ansprechend formatiert?“ → LLM Grader (Bewertung auf einer Skala von 0–10)
- „Ist der Link zum Grundriss erreichbar?“ → Python Grader (HEAD-Request)
- „Entspricht der Tonfall der Markenidentität?“ → LLM Grader (Bewertung basierend auf einem Rubrik-System)
Das Cookbook betont eine entscheidende technische Praxis: LLM Grader müssen durch SME (Subject Matter Expert, Fachexperten) validiert werden. Man sollte sich nicht blind auf die Bewertung von GPT-4o verlassen. Die konkrete Methode besteht darin, die Daten in Trainings-, Validierungs- und Testsets zu unterteilen und dabei zwei Metriken zu prüfen:
- High TPR (True Positive Rate, Richtig-Positiv-Rate): Erkennt tatsächliche Fehler zuverlässig.
- High TNR (True Negative Rate, Richtig-Negativ-Rate): Führt nicht zu Fehlalarmen bei korrekten Beispielen.
Sich nur auf die Genauigkeit zu verlassen, kann durch eine hohe Baseline täuschen. Ein Abgleich beider Metriken ist zwingend erforderlich. Dies ist der entscheidende Punkt, um „LLM-as-Judge“ von einem „sieht gut aus“-Status auf ein professionelles Niveau zu heben.
📊 Validierungsprozess: SME annotiert 100 Beispiele als Ground Truth → LLM Grader bewertet dieselben Beispiele → Berechnung von TPR / TNR → Anpassung des Grader-Prompts, bis beide Metriken die Zielwerte erreichen. Dieser Prozess wird auf der Evals-Plattform von apiyi.com nativ unterstützt, da die Evals-API vollständig mit dem offiziellen OpenAI-Protokoll kompatibel ist.
Phase 3 des OpenAI-Evaluierungs-Flywheels: Experimente auf zwei Schienen für „Improve“ (Verbesserung)
In der dritten Phase können Sie endlich damit beginnen, Ihre Prompts anzupassen. Das Cookbook schlägt zwei parallele Verbesserungswege vor, die sich nicht ausschließen, sondern ergänzen.
Weg 1: Automatische Optimierung durch Prompt Optimizer
Die OpenAI-Plattform verfügt über ein integriertes Prompt-Optimizer-Tool. Sie geben einen Satz fehlerhafter Beispiele und den ursprünglichen Prompt ein, und das Tool testet automatisch verschiedene Strategien (Hinzufügen von Few-Shot-Beispielen, Chain-of-Thought, Anpassung der Anweisungsreihenfolge usw.) und bewertet die Ergebnisse mit Ihrem Grader. Dieser Weg ist zeitsparend und eignet sich hervorragend für erste explorative Schritte.
Weg 2: Manuelle Prompt-Anpassung basierend auf Fehlermustern
Basierend auf den in der Analyse-Phase identifizierten Fehlermustern nehmen Ingenieure gezielte manuelle Anpassungen am Prompt vor. Beispiele:
- Fehler bei der Besichtigungsplanung → Erzwingen eines Schrittes zur „Überprüfung des Verfügbarkeitsplans“ im Prompt.
- Fehlerhaftes Layout → Verwendung von XML-Tags zur expliziten Formatvorgabe.
- Terminänderung nicht storniert → Hinzufügen einer Zustandslogik („Erst stornieren, dann neu buchen“).
Der Vorteil des manuellen Weges ist die Präzision. Sie wissen genau, welche Änderung welches Fehlermuster adressiert, was das Debugging deutlich transparenter macht.
Nachdem beide Wege durchlaufen wurden, verfügen Sie über N verschiedene Prompt-Versionen. Hier kommt der wichtigste Schritt der Improve-Phase: Führen Sie alle Versionen mit demselben Grader-Set auf demselben Datensatz aus und wählen Sie die Version mit den besten Metriken. Überspringen Sie diesen Schritt nicht, denn Menschen neigen dazu, ihre eigenen Prompts „subjektiv gut“ zu finden – nur die Zahlen können diese Voreingenommenheit korrigieren.
Sobald alle Versionen getestet wurden, ist eine Runde des Flywheels abgeschlossen. Sie werden neue Fehlermuster entdecken (da das System besser geworden ist und nun tiefere Edge-Cases zum Vorschein kommen), und kehren dann zur Analyse-Phase für die nächste Runde zurück. Das ist der Kern des Begriffs „Flywheel“ – es bleibt nie stehen, dreht sich immer schneller und wird mit jeder Umdrehung robuster.
Der wesentliche Unterschied zwischen resilienten und fragilen Eingabeaufforderungen
Der Begriff Resilient Prompt (resiliente Eingabeaufforderung), der im Titel verwendet wird, ist ein entscheidendes Konzept. Das Cookbook definiert ihn wie folgt: Eine Eingabeaufforderung, die für alle möglichen Eingaben qualitativ hochwertige Antworten liefert. Das klingt einfach, stellt jedoch einen extrem hohen technischen Standard dar.

Die Unterschiede zwischen Resilienz und Fragilität zeigen sich in fünf Dimensionen:
| Vergleichsdimension | Fragile Eingabeaufforderung | Resiliente Eingabeaufforderung |
|---|---|---|
| Eingaberobustheit | Stürzt bei Wortänderung ab | Stabil bei synonymen Änderungen |
| Randfälle | Seltsame Ausgaben oder Halluzinationen | Elegante Degradierung oder menschlicher Eingriff |
| Beobachtbarkeit | Blackbox, Fehler nur ratbar | Vollständiger Grader zur Lokalisierung |
| Produktionsreife | Demo-Leistung ≠ Produktionsleistung | Durchläuft vollständigen Bewertungszyklus |
| Weiterentwickelbarkeit | Korrektur von A zerstört B | Automatische Regressionsabsicherung |
Ingenieure haben oft das intuitive Gefühl, dass eine Eingabeaufforderung "schon passen wird", aber in der Produktionsumgebung treten Probleme mit einer Wahrscheinlichkeit von 0,1 % auf – was bei Millionen von Aufrufen 1000 Vorfällen entspricht. Der technische Wert einer resilienten Eingabeaufforderung liegt nicht darin, die Leistung von 80 % auf 90 % zu heben, sondern von 99 % auf 99,9 %.
🚀 Hinweis zur Anbindung: Um eine Eingabeaufforderung auf 99,9 % Resilienz zu bringen, muss der Bewertungszyklus automatisiert werden. Dies erfordert eine stabile Nutzung der OpenAI Evals API und von Prompt-Optimizer-Tools. Wir empfehlen die Nutzung einer API-Proxy-Dienst-Plattform wie apiyi.com für OpenAI-Schnittstellen, da diese vollständig mit dem offiziellen Standard kompatibel sind und inländische IDC-Knoten eine unterbrechungsfreie Durchführung langwieriger Bewertungsprozesse garantieren.
CI/CD-Integration und Produktionsüberwachung für den OpenAI-Bewertungszyklus
Der letzte vom Cookbook betonte Schritt ist: Den Bewertungszyklus zu einer täglichen technischen Disziplin machen. Die Umsetzung erfolgt in zwei Bereichen:
Erster Bereich: CI/CD-Integration
Binden Sie die Grader-Suite in die CI-Pipeline ein, sodass bei jeder Änderung der Eingabeaufforderung automatisch eine Bewertung durchgeführt wird. Wenn die Metriken unter einen Schwellenwert fallen, wird die Zusammenführung des Pull Requests automatisch blockiert. Dieser Schritt macht die "Bewertung" von einer Forschungsaktivität zu einer täglichen Entwicklungsaufgabe und ist das Zeichen für die echte Industrialisierung von Eingabeaufforderungen.
| CI-Schwellenwerttyp | Empfohlene Einstellung | Erläuterung |
|---|---|---|
| Gesamtgenauigkeit | Verschlechterung ≤ 1 % | Verhindert allgemeine Regression |
| Wichtige Grader | Verschlechterung ≤ 0,5 % | Strenge Kontrolle kritischer Fehlermuster |
| Erkennung neuer Muster | Warnung statt Blockierung | Fördert das Entdecken neuer Probleme |
| Latenz P95 | Anstieg ≤ 10 % | Kosten- und Erlebnissteuerung |
Zweiter Bereich: Produktionsüberwachung
Neben der CI muss in der Produktionsumgebung kontinuierlich stichprobenartig geprüft werden, um "wild auftretende Fehlermuster" zu finden, die nicht im CI-Set enthalten sind. Diese neuen Muster werden in das Bewertungsset aufgenommen, um den Zyklus weiter voranzutreiben.
Die praktische Vorgehensweise besteht darin, Produktionsprotokolle zu einem bestimmten Prozentsatz (z. B. 1 %) zu erfassen und mit denselben Gradern zu prüfen. Bei anomalen Metriken erfolgt eine manuelle Analyse. Neu entdeckte Fehlermuster werden nach einer Open Coding- und Axial Coding-Analyse in den Testdatensatz integriert, und der Zyklus beginnt von vorn.
Dieser Kreislauf sorgt dafür, dass Ihr System für Eingabeaufforderungen immer resilienter wird, anstatt nach der Bereitstellung zu stagnieren. Dies ist die zentrale technische Disziplin, die das Cookbook allen KI-Ingenieuren mit auf den Weg gibt.
5 praktische Erkenntnisse aus dem OpenAI-Evaluierungs-Flywheel für Entwickler
Nachdem ich das Cookbook durchgearbeitet habe, habe ich 5 Erkenntnisse destilliert, die für Entwickler im chinesischsprachigen Raum von direktem Nutzen sind:
Erkenntnis 1: Beginnen Sie mit der Analyse, nicht mit der Messung
Viele Teams konfigurieren sofort Grader und optimieren Metriken, ohne vorher eine manuelle Analyse durchgeführt zu haben. Das führt dazu, dass der Grader keine echten Fehlerquellen misst – die Zahlen sehen zwar gut aus, aber die Nutzer beschweren sich weiterhin. Starten Sie keine automatisierte Evaluierung, bevor Sie nicht 50 Beispiele manuell per Open Coding analysiert haben.
Erkenntnis 2: Überlassen Sie das Open Coding nicht dem GPT
Open Coding muss von Menschen durchgeführt werden, da GPT bei der Induktion dazu neigt, Ihre Labels mit Verzerrungen aus den Trainingsdaten zu kontaminieren. Der früheste Zeitpunkt für den Einsatz eines LLMs ist nach dem Axial Coding bei der Implementierung des Graders. Die „Entdeckungsphase“ der Analyse bleibt menschliches Territorium.
Erkenntnis 3: Python-Grader haben Vorrang vor LLM-Gradern
Solange Sie eine Anforderung mit deterministischen Regeln abdecken können, sollten Sie keinen LLM-Grader verwenden. Die Gründe: Stabilität, geringere Kosten und keine Notwendigkeit für ein Alignment durch Fachexperten (SME). LLM-Grader sollten für subjektive Dimensionen reserviert bleiben, die sich nicht durch Regeln erfassen lassen.
Erkenntnis 4: Verknüpfen Sie Metriken mit geschäftlichen Auswirkungen
35 % Planungsfehler, 10 % Formatierungsfehler – diese Prozentsätze sind erst dann für Entscheidungen wertvoll, wenn sie in „Nutzerabwanderungsrate“ oder „Beschwerdequote“ umgerechnet werden. Die Metrik an sich ist bedeutungslos; erst die geschäftlichen Konsequenzen verleihen ihr Gewicht.
Erkenntnis 5: Automatisieren Sie das Flywheel als Prozess, nicht als einmaliges Projekt
Der ROI einer einzelnen Flywheel-Runde ist vielleicht nicht sofort riesig, aber der langfristige Zinseszinseffekt ist enorm. Integrieren Sie Grader als CI-Aufgaben, automatisieren Sie die Produktionsstichproben und richten Sie bei neuen Fehlermustern automatische Alarme ein, damit das Flywheel rund um die Uhr von selbst läuft.
Python-Code-Gerüst für die Implementierung des OpenAI-Evaluierungs-Flywheels
Obwohl das Cookbook hauptsächlich den UI-Workflow der OpenAI-Plattform demonstriert, unterstützt die Evals-API auch den programmatischen Aufruf. Das folgende Python-Code-Gerüst zeigt, wie man die Evals-API nutzt, um Grader zu erstellen und Evaluierungen durchzuführen – ideal für Entwickler, die einen codebasierten Workflow bevorzugen:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # Wechsel zum APIYI-Gateway
api_key="Ihr APIYI-Schlüssel"
)
# 1. Evaluierungsaufgabe erstellen (Grader-Sammlung definieren)
eval_cfg = await client.evals.create(
name="leasing_assistant_v1",
data_source_config={
"type": "stored_completions",
"metadata": {"version": "v1"}
},
testing_criteria=[
{ # Beispiel für einen Python-Grader
"type": "string_check",
"name": "tour_time_valid",
"input": "{{sample.output}}",
"operation": "eq",
"reference": "{{item.expected_time}}"
},
{ # Beispiel für einen LLM-Grader
"type": "score_model",
"name": "format_quality",
"model": "gpt-4o",
"input": "{{sample.output}}",
"instructions": "Bewerten Sie die Klarheit der Formatierung auf einer Skala von 0-10"
}
]
)
# 2. Evaluierungslauf starten
run = await client.evals.runs.create(
eval_id=eval_cfg.id,
name="baseline_run",
data_source={"type": "completions"}
)
# 3. Evaluierungsergebnisse abrufen
result = await client.evals.runs.retrieve(eval_id=eval_cfg.id, run_id=run.id)
print(f"Erfolgsquote: {result.report_url}")
Dieser Code enthält drei wichtige Punkte. Erstens die Umstellung der base_url, die entscheidend für die Stabilität Ihrer Evaluierungsaufgaben ist. Zweitens das testing_criteria-Array, mit dem Sie alle Grader in einem Durchgang konfigurieren können. Drittens ist die Evals-API asynchron; bei großen Datensätzen kann die Evaluierung einige Minuten bis zu einer Stunde dauern, daher sollten Sie Warte- und Wiederholungslogiken in Ihrem Programm einplanen.
FAQ zum OpenAI-Evaluierungs-Flywheel
F1: Worin unterscheidet sich das Evaluierungs-Flywheel von Plattformen wie LangSmith oder Weights & Biases?
Die Positionierung ist unterschiedlich. LangSmith konzentriert sich primär auf die "Toolisierung der Evaluierung", während das Evaluierungs-Flywheel die "Methodik der Evaluierung" adressiert. Ersteres zeigt Ihnen das "Wie" der Implementierung, Letzteres das "Warum" des Denkprozesses. Beide können kombiniert werden, um die Methodik durch die entsprechenden Werkzeuge zu stützen.
F2: Sind 50 Fehlerbeispiele ausreichend oder zu wenig?
In der Phase des "Open Coding" reichen 50 Beispiele aus, da das Ziel darin besteht, Muster zu erkennen, anstatt eine erschöpfende Statistik zu erstellen. Die Anzahl der für die "Measure"-Phase benötigten Stichproben hängt von der Fehlerquote ab: Bei einer Fehlerquote von 5 % sind 1.000 Beispiele erforderlich, um ein stabiles Konfidenzintervall für die Metriken zu erhalten; bei einer Fehlerquote von 30 % reichen bereits 200 aus.
F3: Kann der Prompt Optimizer die manuelle Optimierung vollständig ersetzen?
Nein. Automatisierte Tools sind hervorragend für lokale Optimierungen auf Basis bekannter Grader geeignet, können jedoch geschäftliche Einschränkungen (wie z. B. die implizite Regel: "Der Kunde verlangt, dass jede Antwort nicht länger als 80 Zeichen ist") nur schwer erfassen. Die Kombination aus manueller Anpassung und automatischer Optimierung ist die bewährte Methode.
F4: Ist der Modellaufruf der Evals API in China stabil?
Direkte Verbindungen zu OpenAI bei lang laufenden Aufgaben (Evaluierungen dauern oft Minuten bis Stunden) führen häufig zu Verbindungsabbrüchen. Wir empfehlen die Nutzung von API-Proxy-Diensten wie apiyi.com. Die dortigen IDC-Knoten sind speziell für langlebige Verbindungen optimiert, wodurch die Abbruchrate bei Evaluierungsaufgaben signifikant gesenkt wird.
F5: Für welche Teamgröße ist das Evaluierungs-Flywheel geeignet?
Es eignet sich für Projekte von Einzelpersonen bis hin zu 100-köpfigen Teams. Der einzige Unterschied liegt in der Frequenz, mit der sich das Flywheel dreht. Ein Einzelprojekt dreht sich vielleicht alle zwei Wochen, während große Teams tägliche oder sogar stündliche Iterationen erreichen können. Entscheidend ist die Disziplin, nicht die Größe.
F6: Wer ist Hamel Husain und warum findet dieses Cookbook so viel Beachtung?
Hamel ist ein einflussreicher Pädagoge in der Machine-Learning-Community, der seit Langem bewährte technische Verfahren für LLM-Anwendungen fördert. Dieses Cookbook ist das erste Mal, dass OpenAI systematisch qualitative Forschungsmethoden (wie Open Coding) in das Prompt-Engineering einführt, weshalb es in der Branche intensiv diskutiert wird.
Fazit
Der wahre Wert der OpenAI-Evaluierungs-Flywheel-Methodik liegt darin, der chinesischsprachigen KI-Ingenieur-Community die Standardantwort auf die Frage zu liefern, was "professionelles Prompt-Engineering" ausmacht. Es ist kein spezifisches Werkzeug, sondern eine technische Disziplin, die die Prompt-Entwicklung von einer "Gefühlssache" in eine "nachvollziehbare Ingenieurspraxis" verwandelt.
Wenn Sie die Phasen Analyze → Measure → Improve fest in Ihren Entwicklungsprozess integrieren, entwickelt sich Ihre KI-Anwendung von einem "Demo-Modell, das ganz nett aussieht" zu einem Produkt, das Sie bedenkenlos in die Produktion bringen und mit einer SLA garantieren können. Hinter diesem Upgrade steht ein geschlossener Kreislauf, in dem Fehler systematisch gesammelt, Muster strukturiert zusammengefasst und Verbesserungen automatisch durch Metriken validiert werden.
Wenn Sie eine beliebige prompt-gesteuerte KI-Anwendung entwickeln, empfehlen wir dringend, dieses Flywheel aufzubauen. Nutzen Sie für den Modellaufruf der Evals API und des Prompt Optimizers Plattformen wie apiyi.com. Mit einer einfachen Anpassung der base_url lässt sich der gesamte Cookbook-Prozess ohne Sorgen um die Netzwerkstabilität umsetzen.
Wenn Sie das "Flywheel" in Ihr Muskelgedächtnis aufnehmen, wird Ihr Prompt ab heute widerstandsfähiger.
📌 Autor: APIYI Team — Wir verfolgen langfristig die technischen Praxisbeispiele der multimodalen APIs von OpenAI, Anthropic und Google. Weitere Analysen zu Cookbook-Praxisbeispielen und Anleitungen zur Evals API finden Sie im APIYI-Dokumentationszentrum unter apiyi.com.