title: Nano Banana Pro 多轮对话出图 API 深度解析:从字段构造到上下文实战
description: 深入解析 Nano Banana Pro (gemini-3-pro-image-preview) 的多轮对话出图机制。本文详细拆解 contents 数组构造、thoughtSignature 机制及 API 调用实战,助你轻松实现类似网页版的流畅上下文编辑体验。
作者注:深度解析 Nano Banana Pro (gemini-3-pro-image-preview) 多轮对话出图 API 的字段结构、contents 数组构造、thoughtSignature 机制与代码实战。
很多开发者第一次接入 Nano Banana Pro 都会遇到同一个困惑:在 gemini.google.com 网页端可以连续追问「把背景换成黄昏」「再加一只猫」,模型完美记得上一张图;但调用官方 API 时,模型却像断片一样什么都不记得。原因是 Gemini API 本身是无状态的,多轮上下文必须由调用方手动构造。本文将彻底讲清 Nano Banana Pro 多轮对话出图 API 的底层字段、Python SDK 与 REST 两套实现,以及关键的 thoughtSignature 机制,帮你 3 步搭建出像网页版一样流畅的上下文出图体验。
核心价值: 读完本文,你将掌握 contents 数组的正确构造方式、能在自己的应用里实现「基于上一张图继续编辑」的多轮工作流,并避免「图片忘记」「token 浪费」「signature 丢失」三大典型坑。

Nano Banana Pro 多轮对话出图 核心要点
| 要点 | 说明 | 价值 |
|---|---|---|
| API 无状态 | gemini-3-pro-image-preview 接口本身不记得任何历史 | 多轮上下文需调用方主动维护 |
| contents 数组 | user/model 角色交替,每次请求携带完整历史 | 一次请求即可让模型「看到」过往对话 |
| 图片回传 | 之前生成的图片需以 inline_data 形式塞回 contents | 模型据此进行持续编辑而非重新生成 |
| thoughtSignature | 加密的思考签名,跨轮保留推理上下文 | 关键编辑指令不会被遗忘 |
| SDK 自动化 | 官方 Python SDK 的 chat 对象自动管理历史 |
从 REST 直接迁移可省 80% 代码 |
多轮对话出图 与 网页版 Agent 的本质区别
gemini.google.com 是 Google 官方搭建的 Agent 应用,它在前端帮你维护了一份完整的「对话状态」(包含每轮的文本、生成的图片、思考签名),每次你输入新消息时,这个 Agent 会把所有历史一次性打包发送给底层模型。这就是为什么网页端体验如此流畅——所有「记忆」工作都被 Agent 包揽了。
而当你直接调用 generateContent API 时,你拿到的是「赤裸」的模型调用接口。每次 HTTP 请求都是一次独立的推理,模型对你之前的对话毫无概念。要复现网页版的多轮体验,本质上就是在你的代码里自己实现一个 Agent——把历史 user 消息、model 响应(含图片和签名)按规范填入 contents,再发起请求。
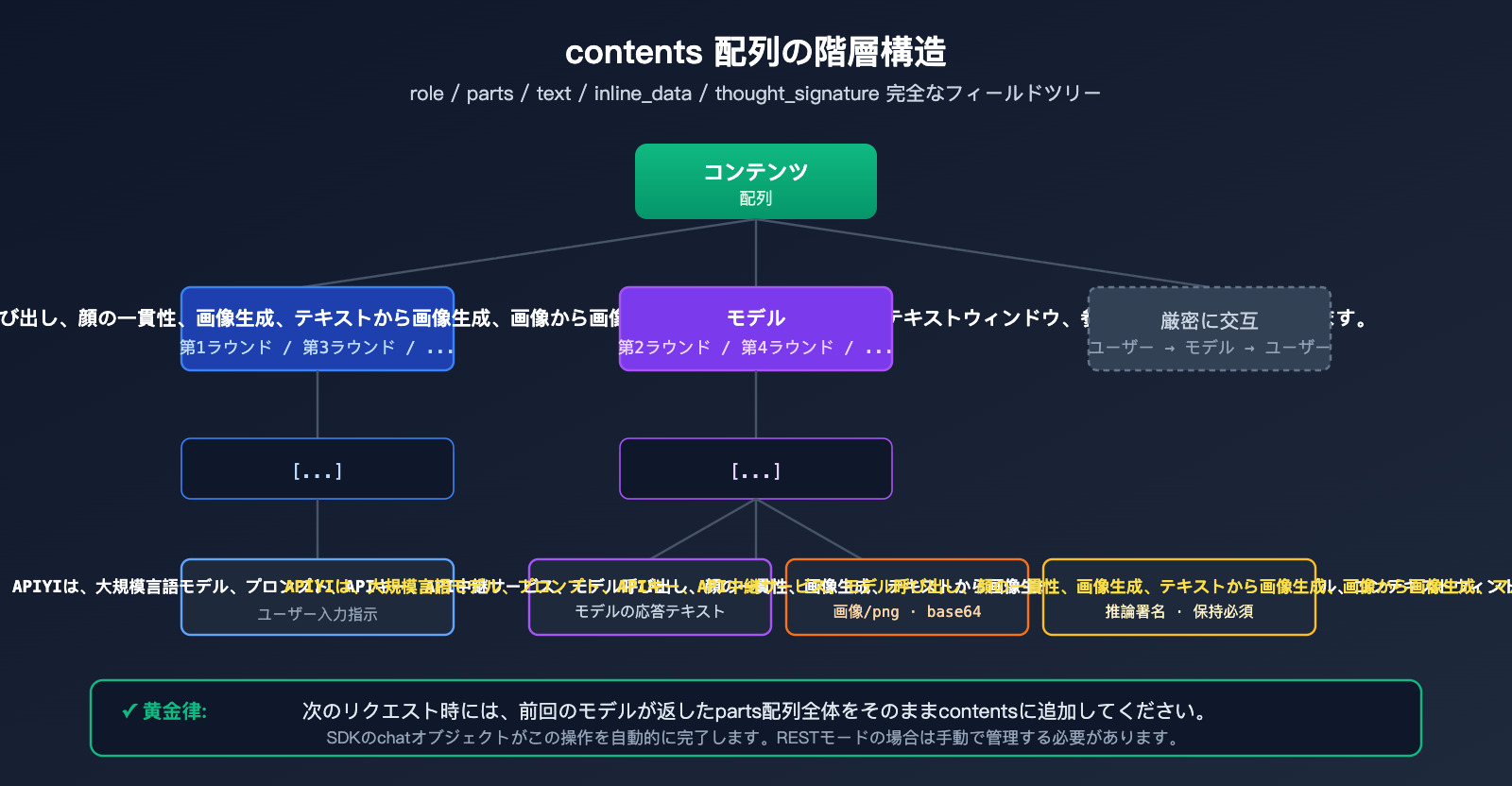
Nano Banana Pro マルチターン対話による画像生成:フィールド構造の詳細解説
contents 配列の基本仕様
contents は Gemini API における対話履歴を表現するための標準フィールドであり、各要素が1回の発言を表す JSON 配列です。
| フィールド | 型 | 説明 |
|---|---|---|
role |
string | "user" または "model"。厳密に交互である必要があります |
parts |
array | 発言の内容断片。テキスト、画像、署名を混在可能 |
parts[].text |
string | 指示や対話などのテキスト内容 |
parts[].inline_data.mime_type |
string | 画像形式。通常は "image/png" |
parts[].inline_data.data |
string | 画像の base64 エンコードデータ |
parts[].thought_signature |
string | モデルが生成した暗号化署名(model ロールでのみ出現) |
完全な2ターン対話のリクエストボディは以下のようになります:
{
"contents": [
{"role": "user", "parts": [{"text": "砂浜を走るゴールデンレトリバーを生成して"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<1回目の生成画像のbase64>"}},
{"thought_signature": "<暗号化署名>"}
]},
{"role": "user", "parts": [{"text": "シーンを夕暮れ時に変更して"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
画像を送信する2つの方法
2回目のリクエストにおいて、モデルは1回目に生成された画像を「認識」できなければなりません。Nano Banana Pro は以下の2つの送信方法をサポートしています:
# 方法1:inline_data による base64 直接埋め込み(小規模な画像に適しており、シンプルで直感的)
{
"inline_data": {
"mime_type": "image/png",
"data": base64.b64encode(image_bytes).decode()
}
}
# 方法2:file_data による Files API アップロード済みリソースの参照(大きな画像や再利用に適している)
{
"file_data": {
"mime_type": "image/png",
"file_uri": "files/abc123xyz"
}
}
重要なヒント:
inline_dataは直接呼び出しを行う際に最も一般的な方法で、単発のシナリオに適しています。一方、file_data参照モードは、同じ大きな画像を複数ターンで再利用する場合に適しており、リクエストボディのサイズとアップロードのオーバーヘッドを大幅に削減できます。
Nano Banana Pro マルチターン対話による画像生成:クイックスタート
シンプルな例(Python SDK による自動管理)
公式の Python SDK を使用する場合、わずか10行で実装可能です:
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
chat = client.chats.create(model="gemini-3-pro-image-preview")
# 1ターン目:初期画像を生成
r1 = chat.send_message("砂浜を走るゴールデンレトリバーを生成して")
# 2ターン目:1枚目の画像をベースに編集(chat オブジェクトが履歴を自動保持)
r2 = chat.send_message("シーンを夕暮れ時に変更して、飛んでいるカモメを1羽追加して")
# 3ターン目:さらに修正を追加
r3 = chat.send_message("犬の色を濃い茶色に変えて")
chat オブジェクトは内部で完全な contents リスト(各ターンの thoughtSignature を含む)を管理しているため、開発者がフィールドの詳細を気にする必要はありません。send_message を呼び出すたびに、履歴が自動的にパッケージ化されて送信されます。
OpenAI 互換インターフェースの呼び出し例を表示
APIYI (apiyi.com) のような OpenAI 互換プラットフォームを使用して Nano Banana Pro を呼び出す場合は、OpenAI SDK をそのまま流用できます:
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# ローカルで messages リスト(contents の概念に相当)を管理
messages = [
{"role": "user", "content": "砂浜を走るゴールデンレトリバーを生成して"}
]
# 1ターン目
response1 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
img1_url = response1.choices[0].message.content # 画像URLまたはbase64を抽出
# モデルの応答を履歴に追加
messages.append({"role": "assistant", "content": img1_url})
# 2ターン目:新しい指示を追加
messages.append({"role": "user", "content": "シーンを夕暮れ時に変更して"})
response2 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
# 3ターン目以降も同様に追加...
messages.append({"role": "assistant", "content": response2.choices[0].message.content})
messages.append({"role": "user", "content": "飛んでいるカモメを1羽追加して"})
response3 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
重要なポイント: OpenAI 互換モードでは、messages 配列はネイティブの contents と同等です。role フィールドは "model" から "assistant" に変更されますが、プラットフォーム層で自動的に変換されます。
推奨: マルチターン編集のシナリオでは、SDK の
chatオブジェクトを使用するか、ローカルでmessagesリストを管理することをお勧めします。これにより、毎回手動でcontentsを連結する手間を省けます。APIYI (apiyi.com) で無料枠を登録し、まずは SDK で動作を確認してから REST API の最適化を検討してみてください。
description: "Nano Banana ProのREST APIを使用したマルチターン対話での画像生成方法を解説。SDKを使わずに直接リクエストを構築する手順と、API呼び出しの仕組みを詳しく説明します。"
Nano Banana Pro マルチターン対話での画像生成:RESTによる手動構築
SDKに依存しない純粋なREST実装
サーバーサイドの中継、ComfyUIノード、ローカル開発環境など、公式SDKが利用できない環境では、直接RESTリクエストを構築する必要があります。以下に完全なcurl呼び出し例を示します。
# 第1ターン:テキストプロンプトによる画像生成
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "砂浜を走るゴールデンレトリバーを生成して"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
# レスポンスには以下が含まれます: parts[0].inline_data.data (base64画像)
# および parts[0].thought_signature
第2ターンのリクエストでは、第1ターンのモデルレスポンス全体(画像と署名を含む)をそのまま contents に含める必要があります。
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "砂浜を走るゴールデンレトリバーを生成して"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<第1ターンで返されたbase64>"}},
{"thought_signature": "<第1ターンで返されたsignature>"}
]},
{"role": "user", "parts": [{"text": "シーンを夕暮れ時に変更して"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
3つの呼び出しモード比較
| 呼び出し方式 | 履歴管理 | 適したシナリオ | 学習コスト |
|---|---|---|---|
公式 Python SDK (chat オブジェクト) |
自動 | バックエンドサービス、Notebook実験 | ⭐ 最低 |
| OpenAI 互換インターフェース (messages 配列) | 半自動 | 既存のOpenAIプロジェクトからの移行 | ⭐⭐ 低い |
| ネイティブ REST (contents 配列) | 完全手動 | ComfyUI、ローコード、クロス言語 | ⭐⭐⭐ 中程度 |

データに関する注記: 上図は、エージェントによる自動管理とAPIによる手動管理の核心的な違いを示しています。APIYI (apiyi.com) プラットフォームを通じて、これら2つの呼び出し方式の実際のパフォーマンスの違いを直接比較できます。
Nano Banana Pro マルチターン対話による画像生成と thoughtSignature メカニズム
thoughtSignature とは
thoughtSignature は、Gemini 3 シリーズで導入された「暗号化思考署名」です。これはモデル自身の内部推論状態をコンパクトにエンコードしたもので、人間が読むことはできませんが、モデルが次のターンでこれを使用することでコンテキストを迅速に復元できます。主な役割は以下の通りです。
- 詳細な意思決定の保持: 例えば、第1ターンでモデルが「淡い色調」を採用すると決定した場合、第2ターンでは署名を通じてこのスタイルを継承します。
- 一貫性の向上: キャラクター、シーン、構図をマルチターンの編集プロセス全体で安定させます。
- トークンの節約: プロンプト内で「元のスタイルを維持して」と繰り返し指示する必要がなくなります。
署名(signature)が必須となるケース
| シーン | 署名の保持が必要か |
|---|---|
| 単発の独立したリクエスト(一回限りの生成) | ❌ 不要 |
| マルチターン編集(直前の画像を基に修正) | ✅ 必須 |
| セッションを跨いだ履歴の復元 | ✅ 必須(自身で永続化が必要) |
| テキストのみの対話(画像なし) | ✅ 必須(推論の連続性を維持するため) |
実践:署名を手動管理するコードパターン
import requests
import base64
import json
API_BASE = "https://vip.apiyi.com/v1beta"
MODEL = "gemini-3-pro-image-preview"
HEADERS = {
"x-goog-api-key": "YOUR_API_KEY",
"Content-Type": "application/json"
}
class NanoBananaChat:
"""contents + signature を手動管理する極小チャットクライアント"""
def __init__(self):
self.contents = []
def send(self, text: str, attach_image_b64: str = None) -> dict:
# 今回のユーザーメッセージを構築
user_parts = [{"text": text}]
if attach_image_b64:
user_parts.append({
"inline_data": {"mime_type": "image/png", "data": attach_image_b64}
})
self.contents.append({"role": "user", "parts": user_parts})
# リクエストの送信
resp = requests.post(
f"{API_BASE}/models/{MODEL}:generateContent",
headers=HEADERS,
json={
"contents": self.contents,
"generationConfig": {"responseModalities": ["TEXT", "IMAGE"]}
}
).json()
# モデルの応答(署名を含む)をそのまま contents に追加
model_parts = resp["candidates"][0]["content"]["parts"]
self.contents.append({"role": "model", "parts": model_parts})
return model_parts
# 使用例
chat = NanoBananaChat()
parts1 = chat.send("砂浜を走るゴールデンレトリバーを生成して")
parts2 = chat.send("シーンを夕暮れ時に変更して") # 履歴と署名が自動的に引き継がれる
parts3 = chat.send("さらに飛んでいるカモメを追加して")
最適化のヒント: APIYI (apiyi.com) を経由して接続する場合、プラットフォーム層が
thought_signatureフィールドをそのまま透過的に伝送します。開発者は「モデルの parts 配列全体を contents に追加し直す」ことさえ守れば、署名の具体的な内容を気にする必要はありません。
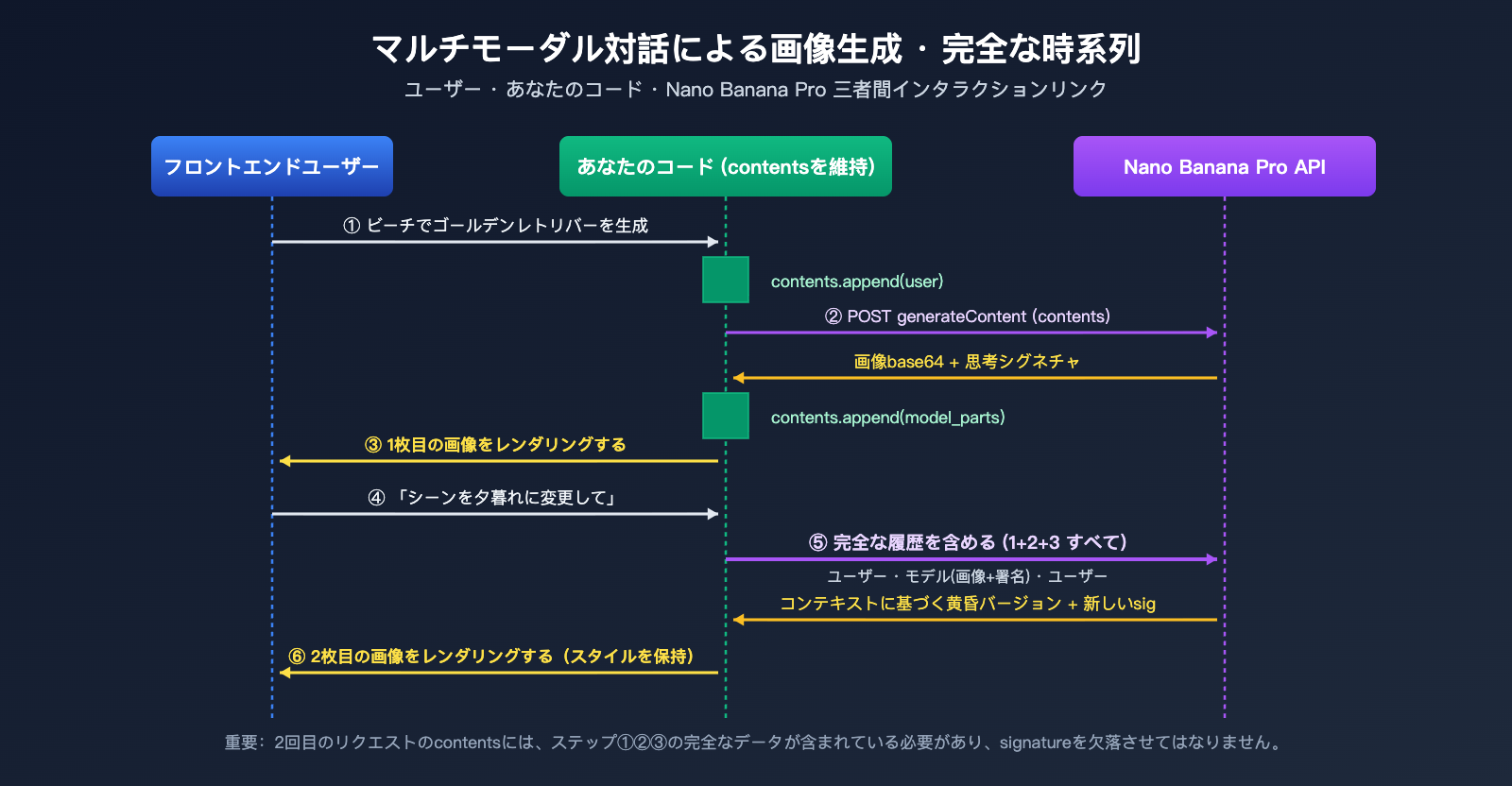
Nano Banana Pro マルチターン対話による画像生成:実践シナリオ
シナリオ 1:段階的なブランド画像デザイン
マーケティングチームでよくあるニーズ:製品コンセプト画像を基に、テキスト、配色、レイアウトを段階的に調整する。マルチターン対話型画像生成APIの強みは、毎回「増分的な変化」を記述するだけでよく、画像全体を最初から説明し直す必要がない点です。
chat = client.chats.create(model="gemini-3-pro-image-preview")
chat.send_message("深青色のグラデーション背景のコーヒーブランドのポスターをデザインして。左側に製品画像を配置して")
chat.send_message("タイトル文を「Awaken Your Morning」に変更して")
chat.send_message("右下にQRコード用のプレースホルダーを追加して")
chat.send_message("全体的にもっとモダンなスタイルにして、装飾的な花柄の枠は削除して")
シナリオ 2:参照画像を基にしたマルチターン編集
Nano Banana Pro は、1回のリクエストで最大14枚の参照画像をサポートしています。マルチターン対話と組み合わせることで、強力な画像融合ワークフローを構築できます。
# 人物の画像 + 服装の参照画像をアップロード
chat.send_message([
"1枚目の画像の人に、2枚目の画像の服を着せて",
{"inline_data": {"mime_type": "image/png", "data": person_b64}},
{"inline_data": {"mime_type": "image/png", "data": outfit_b64}}
])
# その後の微調整
chat.send_message("襟元をVネックに変更して")
chat.send_message("背景をシンプルなグレーに変更して")
シナリオ 3:セッションを跨いだ履歴の復元
ユーザーがフロントエンドでページを閉じた後に再度開き、前回の対話を継続したい場合は、contents 配列をデータベースに永続化する必要があります。
import json
# 保存
with open(f"sessions/{user_id}.json", "w") as f:
json.dump(chat.get_history(), f)
# 復元
with open(f"sessions/{user_id}.json") as f:
history = json.load(f)
restored_chat = client.chats.create(
model="gemini-3-pro-image-preview",
history=history
)
restored_chat.send_message("続きから、背景をもっと明るくして")
コンテキストウィンドウの制限
| リソース | 制限 |
|---|---|
| 入力コンテキスト | 64K トークン |
| 出力コンテキスト | 32K トークン |
| 1リクエストあたりの最大参照画像数 | 14枚 |
| 推奨される履歴ターン数 | 8〜10ターン以内 |
| 画像の最大解像度 | 2K (デフォルトは1K) |
シナリオのアドバイス: 対話が8〜10ターンを超えた場合は、古い履歴を「切り捨てる」か、LLMによる要約に置き換えることをお勧めします。そうしないと、トークン数が急速に64Kの上限に達してしまいます。本番環境では必ずトークンカウンターを導入し、クライアント側で事前に切り捨ての判断を行ってください。
よくある質問
Q1: APIを直接呼び出すとコンテキストがありません。Web版のような連続した対話を実現するにはどうすればよいですか?
APIはステートレスであるため、コード側で contents 配列(またはSDK内の chat オブジェクト)をローカルで保持する必要があります。リクエストのたびに、完全な履歴(ユーザーのテキスト、モデルが生成した画像、thought_signatureを含む)を送信することで、モデルは以前の対話を「記憶」します。最も簡単な方法は、公式Python SDKの client.chats.create() を使用することです。これにより、SDKが自動的に管理してくれます。
Q2: 前のターンで生成された画像は、次のターンでどのフィールドに渡すべきですか?
画像を inline_data 形式(base64エンコード + mime_type)にして、「前のターンの model ロール」の parts 配列に含める必要があります。同時に、モデルが返した thought_signature も必ず一緒に送り返してください。APIYI (apiyi.com) などのOpenAI互換インターフェースを使用する場合、プラットフォームがこれらのフィールドマッピングを自動的に処理するため、開発者は標準的な messages リストを管理するだけで済みます。
Q3: thoughtSignature は必須ですか?送信しないとどうなりますか?
送信を強く推奨します。送信しない場合、モデルは複数ターンの編集時に前のターンの重要な決定事項(スタイル、配色、構図など)を「忘れて」しまい、毎回ゼロから生成し直すような挙動になる可能性があります。公式ドキュメントでは、複数ターンのシナリオにおいて signature を保持することが明記されています。SDKはこれを自動的に処理しますが、RESTモードの場合は、model parts を手動で contents に完全に追加する必要があります。
Q4: 履歴が長すぎる場合はどうすればよいですか?トークンが64Kを超えるとエラーになりますか?
はい、64Kの入力トークンを超えると拒否されます。一般的な最適化戦略は以下の通りです:
- 切り詰め: 直近の4~6ターンのみを保持する
- 画像のダウンサンプリング: 過去の画像は2Kではなく1K解像度で送信する
- 要約による代替: LLMを使用して、初期の対話を短いテキストの要約に圧縮する
- セッションの分割: 対話のトピックが切り替わる際に、新しいセッションを積極的に開始する
Q5: Nano Banana Pro の複数ターン画像生成効果を素早くテストするには?
Geminiモデルをサポートしている APIYI (apiyi.com) のような統合プラットフォームを使用して検証することをお勧めします:
- アカウントを登録し、APIキーと無料枠を取得する
gemini-3-pro-image-previewモデルを選択する- 本記事のPython SDKサンプルコードを使用して、3~5ターンの編集を連続して実行する
- 各ターンの出力の一貫性を比較し、ビジネス要件を満たしているか判断する
まとめ
Nano Banana Pro の複数ターン対話型画像生成APIの重要なポイント:
- ステートレスな本質: APIは履歴を一切記憶しないため、呼び出し側で
contents配列を管理する必要がある - ロールの交互: user と model を厳密に交互に配置し、各ターンの parts にはテキスト、画像、signature を混在させることができる
- 画像の送り返し: 前のターンで生成された画像は
inline_data形式で戻す必要があり、そうしないとモデルは画像を「認識」できない - 署名メカニズム:
thought_signatureは複数ターンの整合性の鍵であり、RESTモードでは手動で含める必要がある - SDKによる簡略化: 公式Python SDKの
chatオブジェクトは、上記すべての詳細を自動的に管理できる
Web版のような体験を素早く実現したい開発者にとって、最適なルートは公式SDKの chat オブジェクトまたはOpenAI互換インターフェースの messages モードを使用することです。これにより、RESTを手動で構築する複雑さを回避できます。
Nano Banana Pro の複数ターン対話型画像生成機能を利用するには、APIYI (apiyi.com) を通じた接続を推奨します。このプラットフォームは、GeminiネイティブフィールドとOpenAI互換モードの両方に対応しており、無料のテスト枠も提供しているため、複数ターンの編集効果を素早く検証し、既存のプロジェクトへスムーズに移行することが可能です。
📚 参考資料
-
Gemini API 画像生成公式ドキュメント: マルチターン対話による画像生成の権威ある解説
- リンク:
ai.google.dev/gemini-api/docs/image-generation - 説明:
contentsフィールドの仕様、Python SDK および REST API の完全なサンプルコードを掲載
- リンク:
-
Gemini 3 Pro Image Preview モデルカード: モデルの能力と制限に関する説明
- リンク:
ai.google.dev/gemini-api/docs/models/gemini-3-pro-image-preview - 説明: コンテキストウィンドウ、解像度、参照画像の数などの主要パラメータ
- リンク:
-
Google AI Developers Forum – Multi-turn Nano Banana: コミュニティによる実践例
- リンク:
discuss.ai.google.dev/t/multi-turn-nano-banana-example - 説明: 開発者コミュニティで議論されたマルチターン対話のベストプラクティス
- リンク:
-
Vertex AI Gemini 3 Pro Image ドキュメント: エンタープライズ向けデプロイメントの参考資料
- リンク:
docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-pro-image - 説明:
thought_signatureやfile_data参照を活用した高度な利用方法
- リンク:
-
APIYI Nano Banana Pro 接続ドキュメント: 国内開発者向けのクイックスタートガイド
- リンク:
help.apiyi.com - 説明: OpenAI互換インターフェースおよびGeminiネイティブインターフェースの両方に対応したサンプルを提供
- リンク:
著者: APIYI 技術チーム
技術交流: マルチターン対話による画像生成で遭遇した実践的な問題があれば、ぜひコメント欄で共有してください。Nano Banana Pro の詳細な設定テクニックについては、APIYI ドキュメントセンター(docs.apiyi.com)をご覧ください。