最近、開発者の友人から「gpt-image-2 は CSV や Excel ファイルを読み込んで画像を生成できるの?TikTok で画像モデルを使って PPT を生成している人を見たんだけど、ファイル情報を読み込めるか試してみたい」という質問を受けました。答えはシンプルで、「できません」。OpenAI が 2026 年 4 月にリリースした gpt-image-2 は、テキストプロンプトと画像の 2 種類の入力しか受け付けません。CSV や Excel を読み込むことも、PPTX や PDF ファイルを出力することもできません。
しかし、これは「道が閉ざされている」という意味ではありません。ファイルの内容をテキストとして抽出し、ファイルのページを画像としてスクリーンショットを撮り、それを gpt-image-2 に渡して画像生成を行うのが、現在の主流なワークフローです。本記事では、gpt-image-2 のファイルアップロードに関する能力の境界線と、5 つの回避策を明確に解説し、クライアントが「不可能だ」と思っていた要望を実現するお手伝いをします。

gpt-image-2 のファイルアップロード対応状況:入力はテキストと画像のみ
まず公式の境界線を明確にしておきましょう。以降のすべての解決策は、この境界線に基づいています。OpenAI の開発者ドキュメントによると、gpt-image-2(スナップショット gpt-image-2-2026-04-21)はネイティブなマルチモーダル画像生成モデルであり、モーダルサポート表に明確に入出力範囲が記載されています。
| モーダルタイプ | 入力サポート | 出力サポート | 説明 |
|---|---|---|---|
| テキスト (text) | ✅ 対応 | ❌ 非対応 | プロンプトとして使用。日本語や中国語など多言語対応 |
| 画像 (image) | ✅ 対応 | ✅ 対応 | 編集/参照用に入力。PNG/JPEG/WebPで出力 |
| 音声 (audio) | ❌ 非対応 | ❌ 非対応 | 画像生成とは無関係 |
| 動画 (video) | ❌ 非対応 | ❌ 非対応 | 画像生成とは無関係 |
| ドキュメント (CSV/Excel/PDF/Word/PPT) | ❌ 非対応 | ❌ 非対応 | 直接アップロード不可、ファイル出力も不可 |
簡単に言えば、gpt-image-2 は GPT-4 のような「汎用的な頭脳」ではなく、画像生成と編集に特化したモデルです。そのため、OpenAI は CSV/Excel/PDF の解析機能を持たせていません。Excel のバイナリデータを送信しても、API は 400 エラーを返します。もしプロジェクトで安定した高 RPM の gpt-image-2 呼び出し環境が必要な場合は、APIYI (apiyi.com) のような API 中継サービスを利用することをお勧めします。このプラットフォームではモデルの入力検証やパラメータ制限がドキュメント化されており、初心者がミスを犯しにくい設計になっています。
🎯 核心的な認識: gpt-image-2 の能力の境界線は「テキスト + 画像 → 画像」です。全能の Agent だと思わないでください。ファイル関連のニーズは外部ツールで補完し、中継層(APIYI など)で呼び出しの安定性を確保し、ビジネス層でデータの前処理を行う必要があります。
クライアントが求める「PPT 生成」と「ファイル生図」が別物である理由
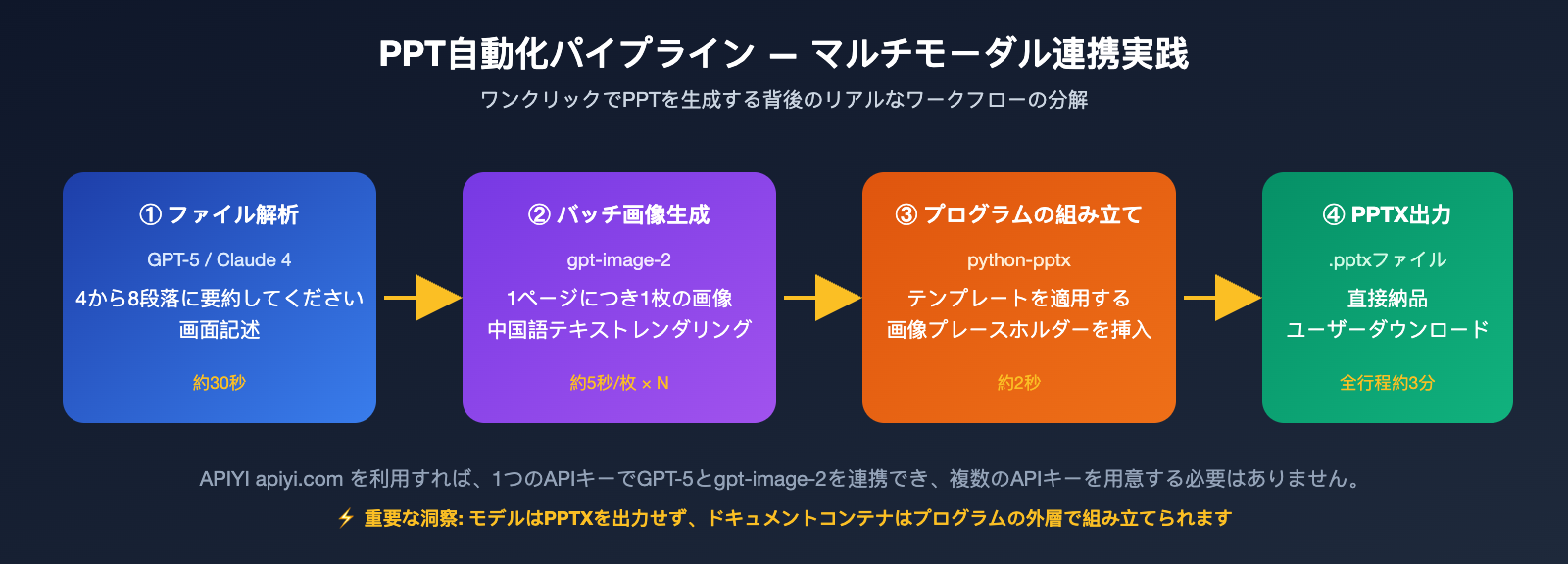
多くのクライアントは「AI によるワンクリック PPT 生成」と「モデルによるファイル読み込み画像生成」を混同していますが、これらは全く異なるワークフローです。TikTok や小紅書で見かける PPT 自動化の事例は、ほぼすべてが多段階のパイプラインです。まず大規模言語モデルでデータを文案に要約し、次に画像モデルで各ページの挿絵を生成し、最後にプログラムで PPTX に組み立てています。
画像生成を担当する中間工程が、通常は gpt-image-2 のようなモデルです。モデルは受け取ったテキストプロンプトと参照画像だけを見ており、そのソースが Excel なのか Notion なのかは認識していません。この点を理解すれば、後述する 5 つの解決策も自然と理解できるはずです。
前世代 gpt-image-1 との比較
多くのユーザーから「ファイルが送信できないなら、gpt-image-2 は gpt-image-1 と何が違うのか」という質問を受けます。その違いは非常に重要で、「スクリーンショットを入力して画像生成する」という手法が通用するかどうかを直接左右します。新バージョンでは、テキストレンダリング、参照画像の枚数、推論能力が大幅に向上しています。
| 能力の次元 | gpt-image-1 | gpt-image-2 |
|---|---|---|
| 最大参照画像数 | 4 枚 | 16 枚(実測では 4 枚以下を推奨) |
| テキストレンダリング | 英語は良好、日中韓は誤字が多い | 日中韓、ヒンディー語、ベンガル語などの多言語精度が大幅向上 |
| 推論能力 | なし | thinking モード内蔵、複雑なレイアウトを処理可能 |
| 知識のカットオフ | 2024 年初頭 | 2025 年 12 月 |
| 出力解像度 | 最大 1024×1024 | 最大 3840×2160 (4K) |
つまり、以前 gpt-image-1 で「スクリーンショットを元にスタイルを変更する」という処理がうまくいかなかった場合、gpt-image-2 で再度試す価値は十分にあります。特に、日本語のポスターや PPT の内ページなど、正確なテキストレンダリングが必要な場面では顕著です。
gpt-image-2 でファイルから画像を生成する5つのワークフロー
以下の5つの手法は、データソースや活用シーンに応じて使い分けることができます。ファイルの種類、出力形式、自動化の度合いに合わせて最適なものを選んでください。ここでは、軽量なものから順に紹介します。
手法1: ファイルをテキストプロンプトに変換し、gpt-image-2 に直接入力する
CSV、Excel、JSON、プレーンテキストなどの構造化データに適しています。まずスクリプト(pandas、openpyxlなど)でファイルを読み込み、ヘッダーや主要な行、統計指標を自然言語の記述に変換して、prompt として /v1/images/generations を呼び出します。例えば、売上データを「2026年第1四半期の3大エリア売上棒グラフ。華東1200万、華北980万、華南760万。ダークなビジネススタイルで」といったプロンプトにまとめます。
この手法の利点はシンプルで、画像入力が不要な点です。欠点はプロンプトに入れられる情報量に限りがあることです。gpt-image-2 は数値の再現性は高いものの完璧ではないため、プロンプト内で各棒の数値を明示しないと、モデルが視覚的なバランスを優先して高さを再調整してしまうことがあります。
手法2: ファイルのページをスクリーンショットし、参照画像として入力する
PDF、PPT、Webレポートなど、「すでに画像として完成しているコンテンツ」に適しています。対象ページをPNG形式に変換し(macOSのプレビュー、pdftoppm、Puppeteerなどのツールを使用)、/v1/images/edits エンドポイントに image パラメータとしてアップロードします。併せてプロンプトで「レイアウトを維持し、英語のタイトルを中国語に変更、棒グラフをApple風のデザインに」といった指示を出します。
gpt-image-2 は2026年版において最大16枚の参照画像を受け付けますが、公式およびコミュニティの検証では、メインの参照画像1枚+スタイル参照画像1〜2枚に留めるのが推奨されています。枚数が増えるとモデルの注意力が分散するためです。各画像は1.5MB以内に抑えるのが望ましく、これを超えると入力トークンの消費が大幅に増加します。
手法3: データを先に可視化し、gpt-image-2 で美化する
「正確さと美しさ」の両方を追求するデータ可視化シーンに適しています。まず matplotlib、ECharts、Excel などのツールでデータを描画してPNGとして書き出し、その基礎画像を gpt-image-2 に入力します。プロンプトには「データポイントの位置と数値を維持し、グラフのスタイルをダークでネオンハイライトのインフォグラフィック風に変更」と記述します。
これは現在、データグラフとAIによる美化を組み合わせる最も安定した手法です。数値の正確性は確実な描画ライブラリが保証し、視覚スタイルは gpt-image-2 が再構築するという、それぞれの得意分野を活かした構成です。このプロセスを大量に実行する場合は、APIYI (apiyi.com) を通じて gpt-image-2 を呼び出すことをお勧めします。APIYI は 5000 RPM の高並列処理に対応した上流アカウントプールを備えており、1日あたり数千〜数万枚の画像生成タスクに最適です。

手法4: LLM + gpt-image-2 のデュアルモデルパイプライン
長文レポート、契約書の要約、製品コピーなど、複雑な内容や意味の理解が必要なファイルに適しています。まず GPT-4 シリーズや Claude 4 を使ってファイルを読み込み、4〜8個の画面描写を抽出してから、ループ処理で gpt-image-2 を呼び出し、必要な枚数の画像を生成します。
この手法の鍵は、「意味の理解」と「画像生成」を切り離すことにあります。LLM が「このページには何を描くべきか」を指示し、gpt-image-2 が「そのプロンプトに従って描画する」という役割分担です。このパイプライン全体は APIYI (apiyi.com) 上で同じ API キーを使用して統合できるため、SDK の切り替えやキー管理の手間を省けます。
手法5: バッチ生成後のプログラムによる PPT/ポスター合成
これは「ワンクリックで PPT 作成」といった事例の裏側にある仕組みです。モデル自体は PPTX ファイルを出力しませんが、各ページの画像を生成し、Python の python-pptx やフロントエンドの PptxGenJS を使って、PPT テンプレートの指定位置に画像を配置することができます。
一言で言えば、PPT は本質的に複数の画像で構成されたプレゼンテーション資料です。gpt-image-2 が「画像」の問題を解決し、python-pptx が「ドキュメントコンテナ」の問題を解決します。一般的な構成例としては、表紙に4K高品質画像、本文ページに1536×1024の中品質画像、目次や遷移ページに低品質のラフ画を使用し、quality パラメータでコストを最適化します。20ページの PPT であれば約20〜30回のモデル呼び出しが必要ですが、APIYI の 5000 RPM 中継チャネルを使えば、数分で完了します。
| 手法 | 適用ファイルタイプ | 工程量 | 出力品質 | 推奨シーン |
|---|---|---|---|---|
| 手法1 テキスト変換 | CSV/Excel/JSON | 低 | 中 | シンプルなグラフ、スタイル化されたイラスト |
| 手法2 スクリーンショット入力 | PDF/PPT/Web | 低 | 中高 | レイアウトの書き換え、スタイル変換 |
| 手法3 可視化プリレンダリング | CSV/Excel | 中 | 高 | データグラフの美化 |
| 手法4 LLM+gpt-image-2 | 長文レポート/コピー | 中高 | 高 | コンテンツカード、チュートリアル画像 |
| 手法5 バッチPPT合成 | 任意 | 高 | 高 | プレゼン資料の自動化 |
API呼び出しコード例:ファイル内容をgpt-image-2の入力に変換する方法
概念をコードレベルに落とし込むと、より直感的になります。以下は、Excelファイルをテキストプロンプトに変換し、それを呼び出して対応する可視化グラフを生成する、最小構成のPythonサンプルです。APIYI(apiyi.com)を統一された中継ゲートウェイとして使用するため、base_urlを書き換えるだけで、SDKの他の記述は公式と完全に同じです。
from openai import OpenAI
import pandas as pd
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Excelファイルを読み込み、地域ごとの売上合計を算出
df = pd.read_excel("sales_q1.xlsx")
summary = df.groupby("region")["sales"].sum().to_dict()
# データをテキストプロンプトに変換
prompt_text = (
f"2026年Q1の地域別売上棒グラフを作成してください。"
f"データ: {summary}, "
f"ダークなビジネススタイル、純白のタイトル、データラベルを明確に表示。"
)
# モデル呼び出し
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt_text,
size="1536x1024",
quality="high"
)
# 画像を保存
img_b64 = resp.data[0].b64_json
with open("sales_chart.png", "wb") as f:
f.write(base64.b64decode(img_b64))
コードの考え方は非常にシンプルです。ビジネス層でExcelを解析してテキスト記述に変換し、モデル層はテキストのみを受け取るという構成です。画像から画像生成(方案二)を行う場合は、client.images.generateをclient.images.editに置き換え、image=open("page.png", "rb")を通じて画像を入力してください。
| パラメータ | 取扱範囲 | 説明 |
|---|---|---|
model |
gpt-image-2 / gpt-image-2-mini |
mini版は高速かつ低コスト |
size |
1024×1024 / 1536×1024 / 1024×1536 / カスタム | 最長辺 ≤ 3840px、各辺は16の倍数であること |
quality |
low / medium / high / auto | 高品質ほど時間がかかり、トークン消費も増える |
n |
1–4 | 一度の生成枚数。大量生成時はループ処理を推奨 |
response_format |
png(デフォルト) / jpeg / webp | gpt-image-2はPDF/PPTX出力非対応 |
🎯 コード実装のアドバイス: このフローを素早く実行するには、まずAPIYI(apiyi.com)でアカウントを作成し、
base_urlをhttps://api.apiyi.com/v1に設定することをお勧めします。これにより、統一されたインターフェースでgpt-image-2、GPT-5、Claude 4シリーズを同時に呼び出せるため、各社ごとに個別に接続する手間が省けます。

ユーザーがよく陥る4つの落とし穴と回避策
5つの手法を理解した上で、実際に導入する際に直面しがちな細かな問題について、サポート窓口によく寄せられる4つのケースをまとめました。
落とし穴1:base64エンコードしたCSVをプロンプトに含める
「CSVファイルをbase64文字列に変換してプロンプトに含めれば、モデルが勝手にデコードしてくれるだろう」と考える方がいますが、これは全く機能しません。gpt-image-2はコードを実行せず、文字列をデータとして認識もしません。単にbase64文字列を無意味な記号の羅列として扱い、文字化けした画像が出力されるだけです。正しい方法は、ビジネス層でCSVを解析し、自然言語の記述に変換することです(手法1を参照)。
落とし穴2:gpt-image-2に「Excelと全く同じグラフ」を期待する
モデルは視覚的な一貫性やスタイル化には長けていますが、ピクセル単位の完全再現は別物です。厳密な表が必要な場合は、EChartsやmatplotlibで正確なグラフを作成(手法3)し、その見た目をgpt-image-2で美化するという組み合わせ戦略を推奨します。プロンプトだけで100行のデータを正確に描写させることは、現時点では困難です。
落とし穴3:SVGやPDFなどのベクター形式での出力を求める
gpt-image-2の出力形式はPNG、JPEG、WebPの3種類のビットマップ形式のみであり、SVGやPDF、AIなどのベクター形式には対応していません。ベクター画像が必要な場合は、Stable Diffusionとvectorizer.aiを組み合わせるか、GPT-5にSVGコードを生成させる方法をとってください。モデルを選択する前に出力形式を確認することで、手戻りを防げます。
落とし穴4:同じ参照画像を繰り返し送信し、トークン消費が激増する
gpt-image-2は入力されたすべての画像を高忠実度で処理するため、プロンプトを微調整しただけでも、リクエストのたびにinputトークンが再計算されます。クライアント側で参照画像をキャッシュするか、previous_response_idを使用して対話形式の編集(Responses API)を行い、前回の画像コンテキストを再利用することをお勧めします。
もう一点の注意点として、出力サイズが256×256のサムネイルであっても、参照画像が4Kであれば、inputトークンは4K分として課金されます。ローカルで参照画像を長辺1024px程度に圧縮してからアップロードするだけで、inputトークンを60%以上節約できます。これは大量処理を行う際に最も見落としがちなコスト管理ポイントです。
| エラー現象 | 原因 | 推奨される解決策 |
|---|---|---|
| 400 invalid_request_error | 画像以外のバイナリ(CSV/Excel)をアップロード | 外層でファイルをテキストまたはスクリーンショットに変換 |
| 文字が文字化けする | base64文字列をプロンプトとして使用 | 解析後の自然言語記述に変更 |
| 表データが不正確 | プロンプトで正確な表を描画しようとしている | 手法3の可視化プリレンダリングに変更 |
| SVG出力が欲しい | モデルがベクター形式非対応 | GPT-5を使用してSVGコードを生成 |
| トークン消費が予想以上 | 大サイズの参照画像を繰り返し送信 | 1.5MB以内に圧縮し、キャッシュを有効化 |
よくある質問 FAQ
Q1: gpt-image-2 は本当に PDF をアップロードできないのですか?
PDF を直接アップロードすることはできません。ただし、pdftoppm を使用して各ページを PNG に変換し、画像として入力することは可能です。「PDF の内容を理解して画像を生成する」必要がある場合は、まず GPT-5 で PDF を読み取って内容を要約し、その説明文を gpt-image-2 に渡すことをお勧めします。この組み合わせは、APIYI (apiyi.com) であれば 1 つの API キーで完結できます。
Q2: ファイルに機密データが含まれている場合、そのままモデルに送信しても安全ですか?
ファイルのテキスト変換処理は自身のサーバー上で行われるため、モデルに送信されるのは最終的なプロンプトのテキストのみです。テキスト変換時にマスキング処理を行うことも可能です。APIYI (apiyi.com) のような API 中継サービスを利用する場合、インターフェース上でユーザーのプロンプトや返答内容を保存しないことが明記されているため、直接外部のプロキシを通すよりもコンプライアンス面で制御しやすくなります。
Q3: TikTok などで見かける「ワンクリック PPT 生成」ツールは gpt-image-2 を使っていますか?
使っているものもあれば、そうでないものもあります。一般的なロジックは、「大規模言語モデルが原稿を作成」→「画像生成モデル(gpt-image-2 / Nano Banana Pro / Flux)が挿絵を作成」→「バックエンドで python-pptx を使って組み立てる」という流れです。gpt-image-2 は文字のレンダリング、特に中国語の描画に優れているため、PPT 内の挿絵作成に適しています。
Q4: Excel をアップロードできるという話を聞いたのですが?
それは Excel のスクリーンショットを画像としてアップロードしているだけであり、本質的には画像入力です。モデルが Excel の構造を理解しているわけではありません。もしスクリーンショット内の数字がぼやけていれば、モデルもそのぼやけた状態を模写することしかできません。
Q5: gpt-image-2 と gpt-image-2-mini はどちらを選ぶべきですか?
mini 版は高速かつ低コストであるため、大量のドラフト作成やサムネイル生成に適しています。正式な配布物には標準版を使用してください。両バージョンの入力制限は全く同じ(どちらもドキュメントファイルは非対応)ですので、model パラメータのモデル ID を切り替えるだけでよく、SDK の書き換えは不要です。
まとめ
gpt-image-2 は CSV/Excel/PPT ファイルの直接アップロードに対応しておらず、PPTX/PDF ファイルの出力も行いません。これはモデルの能力の境界線であり、パラメータ設定の問題ではありません。この境界線を理解した上で、ファイルを事前に処理(テキスト化、スクリーンショット化、あるいは先に可視化してから装飾するなど)すれば、「ファイル入力が必要そうに見える」ニーズのほとんどに対応可能です。TikTok で見かける「ワンクリック PPT 生成」「Excel からポスター作成」「PDF のスタイル変更」といったツールは、本質的にこのような多段階パイプラインのエンジニアリングの組み合わせです。モデルによる推論とデータ加工の役割分担を明確にすれば、どのようなニーズも実現可能です。
実装時の核心はただ一つ、「モデル層はモデルが得意なことだけを行い、データ層は外部で事前に処理しておく」ことです。完全なパイプラインを構築したい場合、APIYI (apiyi.com) で GPT-5(テキスト理解担当)と gpt-image-2(画像生成担当)を同時に利用することをお勧めします。1 つの API キーで全プロセスを完結でき、5000 RPM の高並列処理能力により大量のタスクもスムーズに処理できるため、モデルごとに複数のキーや SDK を管理する必要はありません。
著者について: APIYI チームは、マルチモデル集約接続および高並列推論インフラストラクチャに特化しており、日々大量の画像生成 API 呼び出しに関するご相談を承っています。本記事は OpenAI 公式ドキュメントおよび実際の顧客からの問い合わせに基づき整理したものです。gpt-image-2 の接続ソリューションについては、ぜひ APIYI (apiyi.com) をご覧ください。