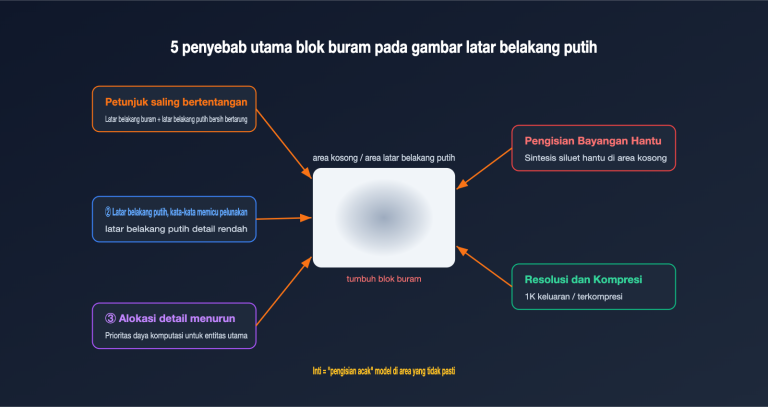
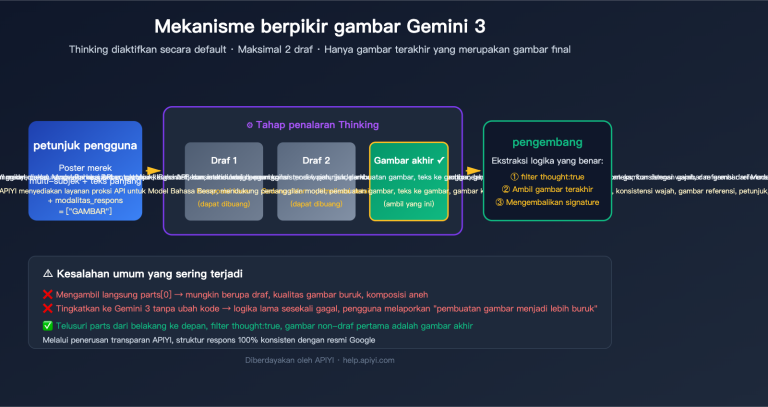
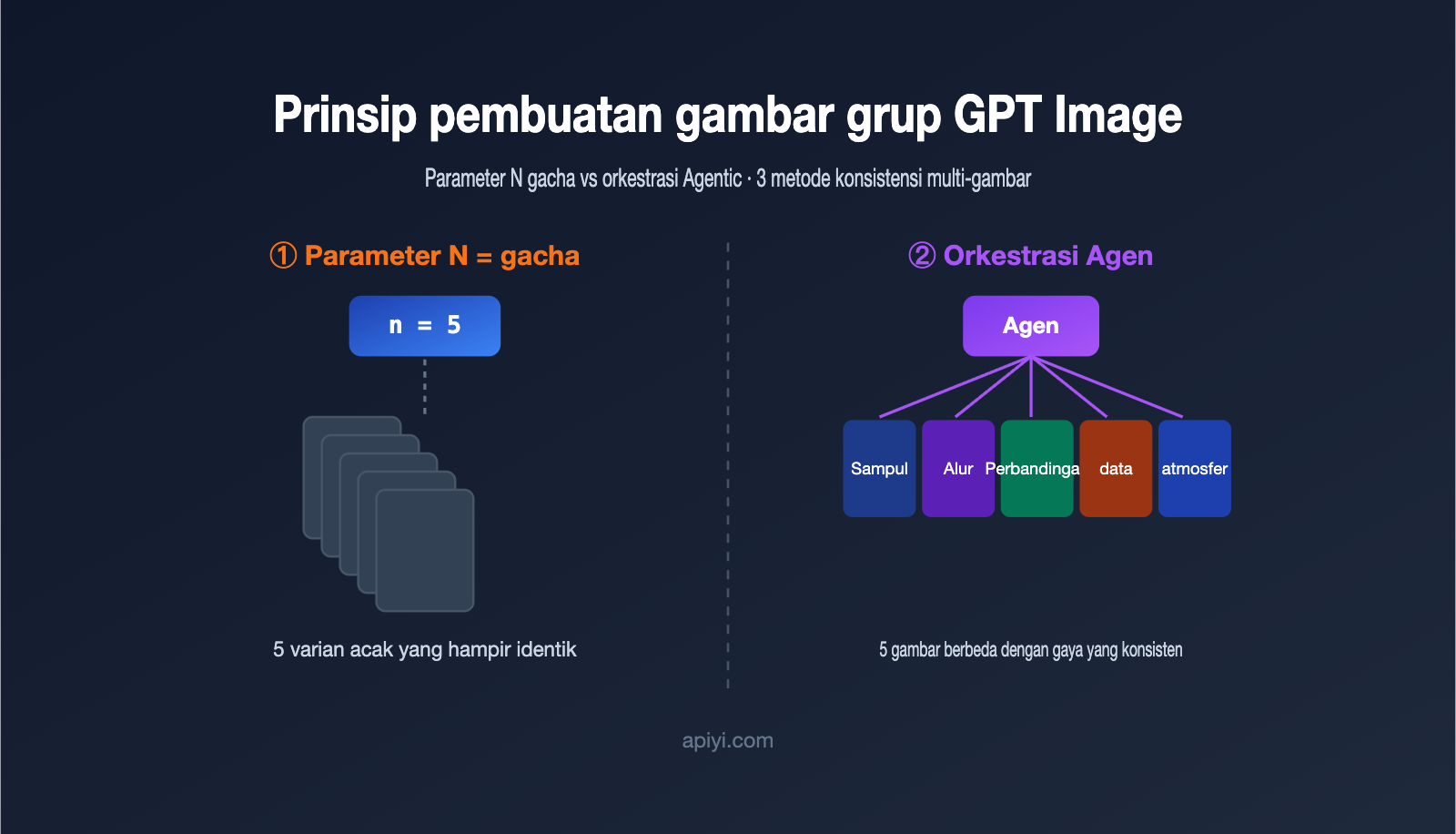
Banyak orang yang baru pertama kali menggunakan ChatGPT versi web sering kali memiliki anggapan yang keliru: mereka pikir dengan mengunggah PDF atau memberikan satu kalimat perintah, AI akan langsung "klik" dan menghasilkan 5 gambar dengan gaya yang seragam. Namun, begitu beralih ke API dan mengatur parameter n ke 5, hasilnya justru 5 gambar yang mirip-mirip, seperti sedang melakukan gacha. Mengapa model yang sama bisa memberikan hasil yang sangat berbeda?
Artikel ini tidak akan memberikan jawaban standar, melainkan membedah masalah yang sering kami temui dalam dukungan pelanggan. Kami akan menjelaskan dua jalur teknis yang sangat berbeda di balik pembuatan gambar GPT, mengapa parameter n tidak bisa menghasilkan "kumpulan gambar" yang sebenarnya, dan langkah praktis yang bisa Anda ambil jika ingin mengimplementasikan konsistensi multi-gambar sendiri melalui API.
I. Dua Jalur Teknis Pembuatan Gambar GPT
Untuk memahami hal ini, kita harus mengakui premis yang sering terlewatkan: "menghasilkan banyak gambar sekaligus" dan "menghasilkan serangkaian gambar yang memiliki hubungan logis" adalah dua hal yang berbeda. Yang pertama hanyalah kuantitas massal, sedangkan yang kedua adalah apa yang disebut orang sebagai "kumpulan gambar" yang sebenarnya.
Dalam implementasi teknis, GPT Image memiliki dua jalur. Jalur pertama adalah pengambilan sampel massal di tingkat model, yaitu parameter n pada API: dengan petunjuk dan input yang sama, model melakukan pengambilan sampel secara paralel untuk menghasilkan beberapa hasil. Jalur kedua adalah orkestrasi agen di tingkat aplikasi, di mana sebuah Agen (entitas cerdas) memahami kebutuhan, memecahnya menjadi beberapa tugas kecil, memanggil kemampuan pembuatan gambar secara terpisah, dan akhirnya menggabungkannya menjadi satu set.
Tabel berikut merinci perbedaan inti antara kedua jalur tersebut:
| Dimensi | Parameter n API (Sampel Massal) | Orkestrasi Agen (Tingkat Aplikasi) |
|---|---|---|
| Hakikat | Pengambilan sampel acak berulang dengan petunjuk yang sama | Pembuatan independen setelah memecah kebutuhan |
| Isi per gambar | Hampir sama, hanya ada variasi acak | Berbeda-beda, namun subjeknya terkait |
| Memahami "set" | Tidak, murni konkuren | Ya, memiliki logika perencanaan |
| Biaya | Harga per gambar × N | Akumulasi biaya pemanggilan berulang |
| Sumber konsistensi | Petunjuk + seed acak | Gambar referensi + batasan petunjuk terpadu |
| Skenario khas | Memilih satu gambar yang memuaskan | Ilustrasi seri, pelengkap PPT, buku cerita |
Singkatnya, parameter n berfungsi untuk "memberikan saya beberapa pilihan", sedangkan pembuatan gambar dalam satu set membutuhkan "memberikan saya serangkaian konten berdasarkan satu tema". Inilah sebabnya mengapa saat memanggil API secara langsung untuk meniru pengalaman versi web, hasilnya terasa kurang maksimal. Jika Anda ingin memverifikasi performa kedua jalur ini, Anda bisa menggunakan kunci API yang sama di APIYI (apiyi.com) untuk mengujinya, sehingga menghemat biaya berpindah-pindah platform.
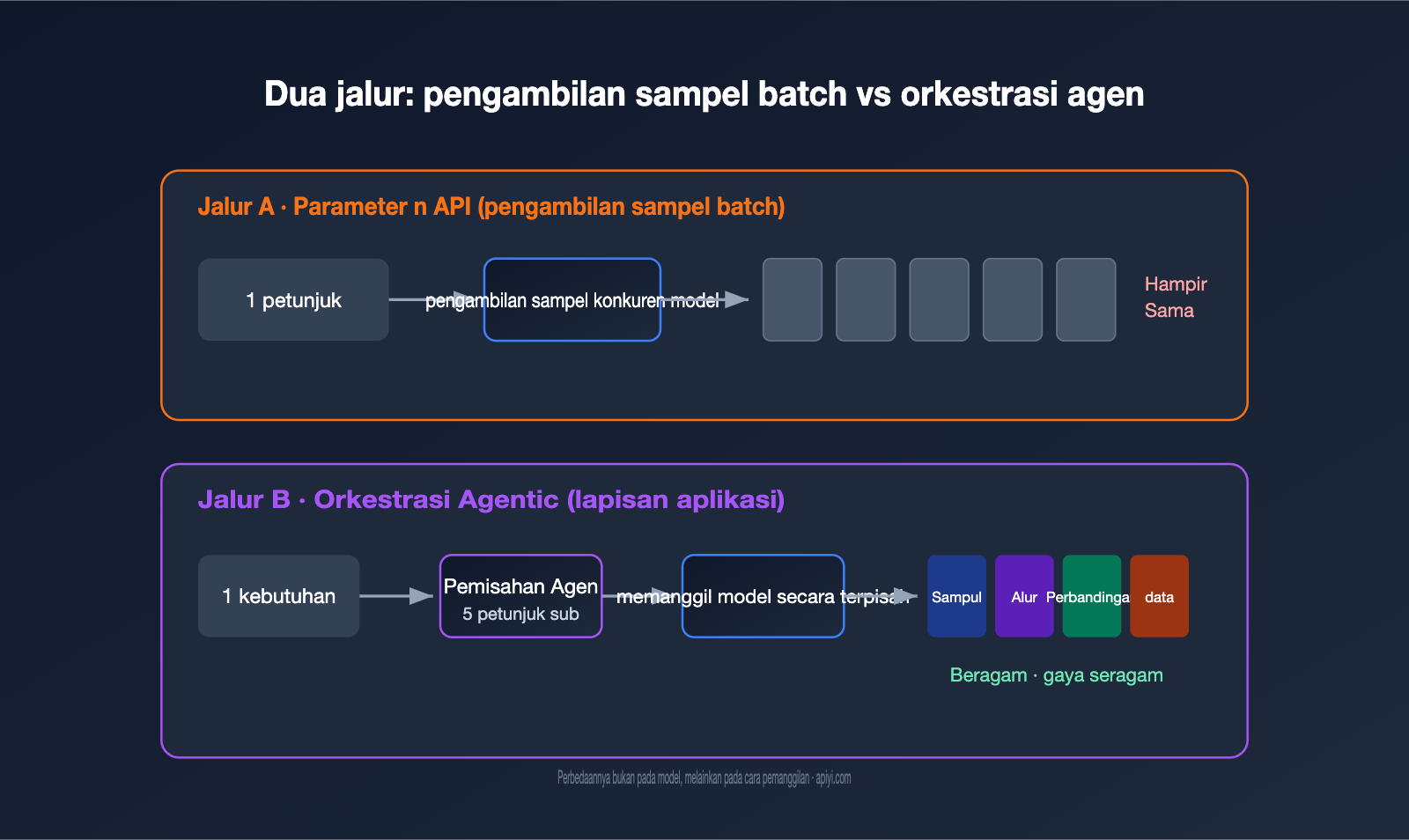
二、为什么 API 的 n 参数做不出真正的组图
很多开发者的第一反应是:既然要 5 张图,那把 n 设成 5 不就行了?实际跑一遍就会发现,出来的 5 张图往往是「同一个东西的 5 个微小变体」,而不是「一组互相配合的图」。
原因在于 n 参数的工作机制。它并不会改变你的 petunjuk,而是用同一个 petunjuk 再跑几遍,靠模型生成过程中的随机采样制造差异。OpenAI 开发者社区里有一句很贴切的描述:这些图来自「同一输入下随机采样产生的变化」(random sampling variations)。换句话说,这就是抽卡——同样的卡池,抽 5 次,卡面相似、稀有度随机。
这带来两个直接后果。其一,你无法在一次调用里表达「第一张画封面、第二张画流程、第三张画对比」这种结构化需求,因为 petunjuk 只有一个。其二,费用是线性叠加的:n=5 就是按 5 张图计费,而不是打包优惠。
下表用一个具体场景说明这个差异,假设你想为一篇文章生成 5 张不同用途的配图。
| 需求 | 用 n=5 的结果 | 你真正想要的 |
|---|---|---|
| 封面图 | 5 张都是封面候选 | 1 张封面 |
| 流程图 | 拿不到 | 1 张流程图 |
| 对比图 | 拿不到 | 1 张对比图 |
| 数据图 | 拿不到 | 1 张数据图 |
| 配图 | 拿不到 | 1 张氛围图 |
结论很清楚:n 参数适合「我要一张好图,多给几个候选让我挑」,不适合「我要一套内容不同的组图」。理解了这一点,就不会再纠结于「为什么 API 出不来网页版那种效果」——因为你用错了工具。想低成本验证 n 参数的抽卡特性,APIYI apiyi.com 支持按调用量计费,跑几组对比实验花不了多少钱。
三、网页版组图背后的 Agentic 编排原理
那 ChatGPT 网页版凭什么能「一个 PDF 出 5 张图」?答案就是上面提到的第二条路径——Agentic 编排,而这恰好是 2026 年 4 月发布的 GPT Image 2 / ChatGPT Images 2.0 带来的关键升级。
按照 OpenAI 的官方定位,GPT Image 2 是首个把「推理能力」内置进图像模型的版本:它在动笔之前会先研究、规划、推理图像结构(proactively researches, plans, and reasons),这套机制在网页端被称为 Thinking 模式。所以当你丢进去一份 PDF,模型不是简单地「读图」,而是先理解文档讲了什么、需要几张图、每张图分别承担什么角色,再逐张生成。
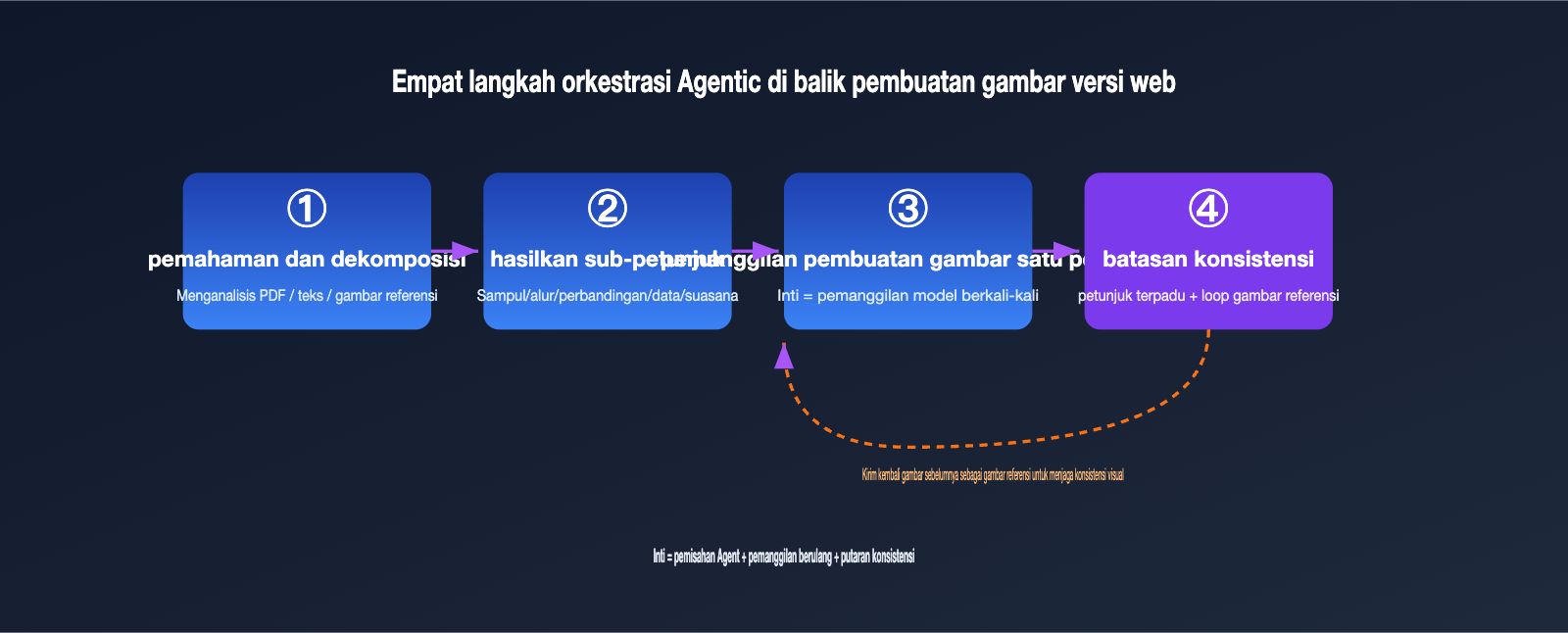
把这个过程翻译成工程语言,大致是四步:
- 理解与拆解:Agent 解析输入(文本、PDF、参考图),判断需要几张图、每张图的主题。
- 生成子 petunjuk:为每张图各写一条独立的 petunjuk,例如「整体架构图」「关键流程图」「数据对比图」。
- 逐张调用生图:对每条子 petunjuk 分别调用底层生图能力,本质上是多次 pemanggilan model。
- 一致性约束:在每条 petunjuk 里注入统一的风格描述,并把前面生成的图作为参考图传给后面,保证整组视觉统一。
学术界也在用类似思路。多智能体框架(如视频生成里的 ViMax、文生图里的 Maestro)会把一个大需求拆成多个细粒度的视觉子问题,并行生成、择优选取,再把前一帧或前一张图作为后续生成的参考,以此维持角色和场景的连贯。GPT Image 2 的过人之处,是把这套原本要工程师手搭的编排,收进了模型自身的推理回路里。
这里也藏着真正的难点:多次独立调用天然会漂移。每一张图都是一次新的随机采样,角色长相、配色、画风都可能跑偏。这就是我们和客户聊到的那个核心问题——「如何保持视觉一致性」,它比「如何出多张图」难得多。下一节就专门讲怎么对付它。
四、用 API 复刻组图:3 种实现多图一致性的方法
如果你不想依赖网页版,而是要在自己的产品里实现 GPT Image 组图生成,那就得自己搭那套编排逻辑,核心是用工程手段把「视觉一致性」补回来。结合实践,我们总结出三种由浅入深、可以叠加使用的方法。
方法一:统一提示词约束(角色描述表)。 最低成本的做法,是为整组图写一段固定的「风格 DNA」,每次调用都原样附在提示词里。比如「统一采用扁平插画风格、主色为深蓝与琥珀色、人物为短发女性工程师」。社区里把这种固定描述叫 character bible(角色圣经),描述越具体,跨图一致性越高。
方法二:参考图传递(image-to-image)。 把已经生成满意的第一张图,作为参考图传给后续每一次调用。GPT Image 2 在编辑/参考场景下可接收多张参考图(官方文档标注最多可达 16 张,具体以平台实测为准),这让「以图定调」成为组图一致性的主力手段。它的效果通常比纯文字描述更稳,尤其是角色长相这类细节。
方法三:Agent 编排 + 参考图回环。 把前两种结合进一个循环:先生成第一张作为基准图,后续每张都带着基准图 + 统一提示词去生成,必要时把上一张也一起作为参考。这就是网页版 Thinking 模式在做的事,只是你把它显式地写进了代码。
下面是一段精简的编排示例,演示「先出基准图,再带着参考图生成系列图」的骨架逻辑。
from openai import OpenAI
# base_url 指向 APIYI, 统一管理多模型密钥
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "扁平插画风格,主色深蓝与琥珀,人物为短发女工程师" # 角色描述表
shots = ["封面:人物站在数据中心前", "流程:人物在白板画架构", "总结:人物竖起大拇指"]
# 1. 先生成基准图,锁定整组风格
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. 后续每张都带统一风格约束(进阶可叠加 base 作为参考图传入 edits 接口)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
为了帮你快速选择,下表对比三种方法的特点与适用场景。
| 方法 | 一致性强度 | 实现成本 | 适用场景 |
|---|---|---|---|
| 统一提示词约束 | 中 | 低 | 风格统一即可,角色不严格 |
| 参考图传递 | 高 | 中 | 同一角色/产品反复出镜 |
| Agent 编排回环 | 最高 | 高 | 绘本、系列插画、品牌物料 |
三种方法可以叠加:用提示词定基调,用参考图锁角色,用编排控结构。我们建议先从「统一提示词 + 参考图」起步,跑通后再上完整编排。在 APIYI apiyi.com,gpt-image-2、gpt-image-1.5 等模型共用同一个 base_url 和密钥,方便你在不改代码的情况下切换模型做一致性对比测试。

五、GPT Image 组图生成的成本与模型选择
组图意味着多次调用,成本会被放大,所以选对模型很关键。目前 GPT Image 系列在生产环境常用的有几档,定位各有侧重。
| 模型 | 定位 | 是否支持推理编排 | 适合的组图场景 |
|---|---|---|---|
| gpt-image-2 | 旗舰,内置推理 | 是(Thinking) | 高质量系列物料、含文字海报 |
| gpt-image-1.5 | 上一代旗舰 | 部分 | 质量与成本平衡的批量出图 |
| gpt-image-1 | 经典稳定 | 否 | 风格简单的常规配图 |
| gpt-image-1-mini | 轻量低价 | 否 | 大批量、对质量要求不高 |
关于费用要有个清醒认识:组图是「按张数累加」计费的。以 1024×1024 为例,不同质量档位单张价格大致从几毫美元到两毫多美元不等(具体以官方与平台实时报价为准),一组 5 张图就是 5 张的钱。如果你要批量生产上千张,成本会很可观,提前估算很有必要。
我们的建议是:草稿阶段用 mini 或低质量档快速验证构图与一致性,定稿阶段再用 gpt-image-2 出高质量终图。这种「低成本试错 + 高质量定稿」的组合,能在保证效果的同时把账单压下来。APIYI apiyi.com 提供统一的用量看板,组图调用花了多少、用了哪个模型一目了然,适合需要控制成本的团队。
VI. FAQ Pertanyaan Umum
Q1: Apakah API benar-benar tidak bisa menghasilkan sekumpulan gambar yang berbeda sekaligus?
Tidak bisa, parameter n tidak bisa diandalkan untuk ini. n hanyalah pengambilan sampel acak (seperti gacha) dari petunjuk yang sama, sehingga kontennya hampir identik. Pembuatan sekumpulan gambar yang sebenarnya harus dilakukan melalui orkestrasi di lapisan aplikasi: memecah kebutuhan, melakukan pemanggilan model berkali-kali, lalu menerapkan batasan konsistensi.
Q2: Teknologi canggih apa yang digunakan ChatGPT versi web untuk menghasilkan sekumpulan gambar?
Bukan teknologi canggih, melainkan GPT Image 2 yang sudah menyematkan penalaran Agentic. Sebelum membuat gambar, ia akan merencanakan "berapa banyak gambar yang dibutuhkan dan apa yang harus digambar di setiap gambar", lalu membuatnya satu per satu. Pada dasarnya, ini tetap merupakan pemanggilan model berkali-kali, hanya saja proses perencanaannya tidak terlihat oleh pengguna.
Q3: Apa cara paling efektif untuk menjaga konsistensi antar gambar?
Dalam praktiknya, penggunaan gambar referensi adalah yang paling stabil: jadikan gambar pertama yang memuaskan sebagai gambar referensi untuk setiap pemanggilan berikutnya. Tingkat kemiripan karakter dan skema warna akan jauh lebih tinggi dibandingkan hanya menggunakan deskripsi teks. Tambahkan juga deskripsi gaya yang tetap untuk hasil yang lebih optimal. Anda bisa langsung mencobanya menggunakan antarmuka gambar referensi gpt-image-2 di APIYI apiyi.com.
Q4: Apakah pembuatan sekumpulan gambar akan sangat mahal?
Tergantung pada jumlah gambar, resolusi, dan tingkat kualitasnya, karena biayanya dihitung per gambar. Disarankan untuk menggunakan model ringan untuk draf dan model unggulan untuk hasil akhir, serta pantau pengeluaran melalui dasbor penggunaan di platform.
Q5: Model mana yang paling hemat biaya untuk membuat sekumpulan gambar?
Untuk kualitas dan rendering teks, pilih gpt-image-2; untuk menyeimbangkan biaya, pilih gpt-image-1.5; untuk kebutuhan massal dengan standar rendah, gunakan gpt-image-1-mini. Saat menggunakan antarmuka yang sama, beralih antar model hampir tidak memakan biaya tambahan.
VII. Kesimpulan
Kembali ke pertanyaan awal: model yang sama, API terasa seperti gacha, sementara versi web bisa menghasilkan sekumpulan gambar. Perbedaannya bukan pada modelnya, melainkan pada cara pemanggilan. Parameter n adalah pengambilan sampel massal di lapisan model untuk memberikan "beberapa kandidat", sedangkan pembuatan sekumpulan gambar GPT Image yang sebenarnya adalah orkestrasi Agentic di lapisan aplikasi, yang dicapai melalui pemecahan kebutuhan, pemanggilan model berulang, dan batasan konsistensi.
Dalam hal ini, konsistensi antar gambar selalu menjadi bagian tersulit. Untungnya, kita memiliki tiga alat bantu yang praktis: deskripsi karakter terpadu untuk menentukan nada, penggunaan gambar referensi untuk mengunci karakter, dan orkestrasi agen untuk mengontrol struktur. Kombinasi ketiganya hampir bisa menyamai pengalaman versi web. Nilai dari GPT Image 2 terletak pada kemampuannya menyematkan orkestrasi ini ke dalam alur penalaran model, sehingga pengguna biasa pun bisa menikmatinya.
Topik ini mungkin tidak memiliki jawaban standar, ini lebih merupakan berbagi pengalaman—semoga bisa membantu Anda menghindari kesalahan yang tidak perlu. Jika Anda ingin mencoba setiap metode yang dibahas, APIYI apiyi.com menyediakan antarmuka terpadu dan dasbor penggunaan untuk model seperti gpt-image-2 dan gpt-image-1.5. Ini adalah titik awal yang mudah untuk bereksperimen dengan pembuatan gambar dan membandingkan biaya. Detail integrasi lebih lanjut dapat dilihat di pusat bantuan help.apiyi.com.
Artikel ini disusun oleh tim teknis APIYI berdasarkan praktik dukungan pelanggan. Spesifikasi model dan harga harap merujuk pada informasi resmi dan platform yang diperbarui secara real-time.