Baru-baru ini, saya sering ditanya oleh klien pengembang mengenai masalah yang cukup umum: "Kenapa saya memanggil gpt-image-2 untuk membuat satu gambar 1024×1024 butuh waktu lebih dari 200 detik? Apakah saya terkena limit kecepatan?" Setelah saya memeriksa kodenya, ternyata parameternya diatur ke quality="high" dan size="1536x1024" secara default. Jadi, waktu 235 detik per gambar sebenarnya adalah performa yang normal.

gpt-image-2 adalah model gambar generasi baru yang dirilis secara resmi oleh OpenAI pada 21 April 2026. Model ini pertama kalinya membawa kemampuan penalaran seri O (pemikiran agen) ke dalam alur pembuatan gambar—artinya, permintaan dengan quality="high" akan melalui empat tahap lengkap: "memahami—merencanakan—menghasilkan—memeriksa", yang memakan waktu 30–50 kali lebih lama daripada quality="low". Artikel ini didasarkan pada pengalaman pemanggilan produksi nyata untuk menjelaskan tiga parameter paling krusial, agar Anda bisa menemukan keseimbangan optimal antara kualitas gambar dan kecepatan.
Tabel Referensi Cepat Parameter Pemanggilan gpt-image-2
Mari kita langsung ke kesimpulannya. Tabel di bawah ini mencakup semua parameter penting dalam SDK Python OpenAI untuk gpt-image-2 beserta pengaruhnya terhadap waktu tunggu dan biaya. Saat melakukan optimasi, disarankan untuk merujuk pada tabel ini.
| Parameter | Nilai Opsional | Default | Dampak Waktu | Dampak Biaya |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
Sangat Besar | Sangat Besar |
size |
1024x1024 / 1536x1024 / 1024x1536 / lainnya ≤ 2K |
1024x1024 |
Besar | Sedang |
output_format |
png / jpeg / webp |
png |
Kecil | Tidak ada |
output_compression |
0–100 (hanya untuk jpeg/webp) | 100 | Sangat Kecil | Tidak ada |
n |
1–10 | 1 | Sebanding dengan n | Sebanding dengan n |
background |
transparent / opaque / auto |
auto |
Kecil | Tidak ada |
prompt |
string | Wajib | Kompleksitas memengaruhi waktu penalaran | Memengaruhi token input |
Logika inti untuk memahami tabel ini adalah: quality dan size adalah penentu utama—keduanya secara langsung menentukan jalur penalaran mana yang diambil model, berapa banyak token yang dihasilkan, dan berapa banyak daya komputasi visual yang dikonsumsi. output_format dan output_compression hanyalah masalah lapisan serialisasi; mengubahnya tidak akan mempercepat proses Anda.
🎯 Saran Utama: Jika bisnis Anda memungkinkan, ubah
quality="auto"menjadilowataumediumsecara eksplisit. Langkah ini saja biasanya bisa menekan waktu tunggu dari skala menit menjadi detik. Saat memanggilgpt-image-2melalui APIYI (apiyi.com), semua parameter ini diteruskan secara native, dengan perilaku yang sama persis seperti endpoint resmi OpenAI.
2 Parameter Kunci yang Mempengaruhi Waktu Pemrosesan gpt-image-2: quality dan size
Untuk memahami mengapa perbedaan antara high dan low bisa mencapai puluhan kali lipat, kita harus memahami alur eksekusi gpt-image-2. Inilah perbedaan paling mendasar antara model ini dengan pendahulunya, gpt-image-1.
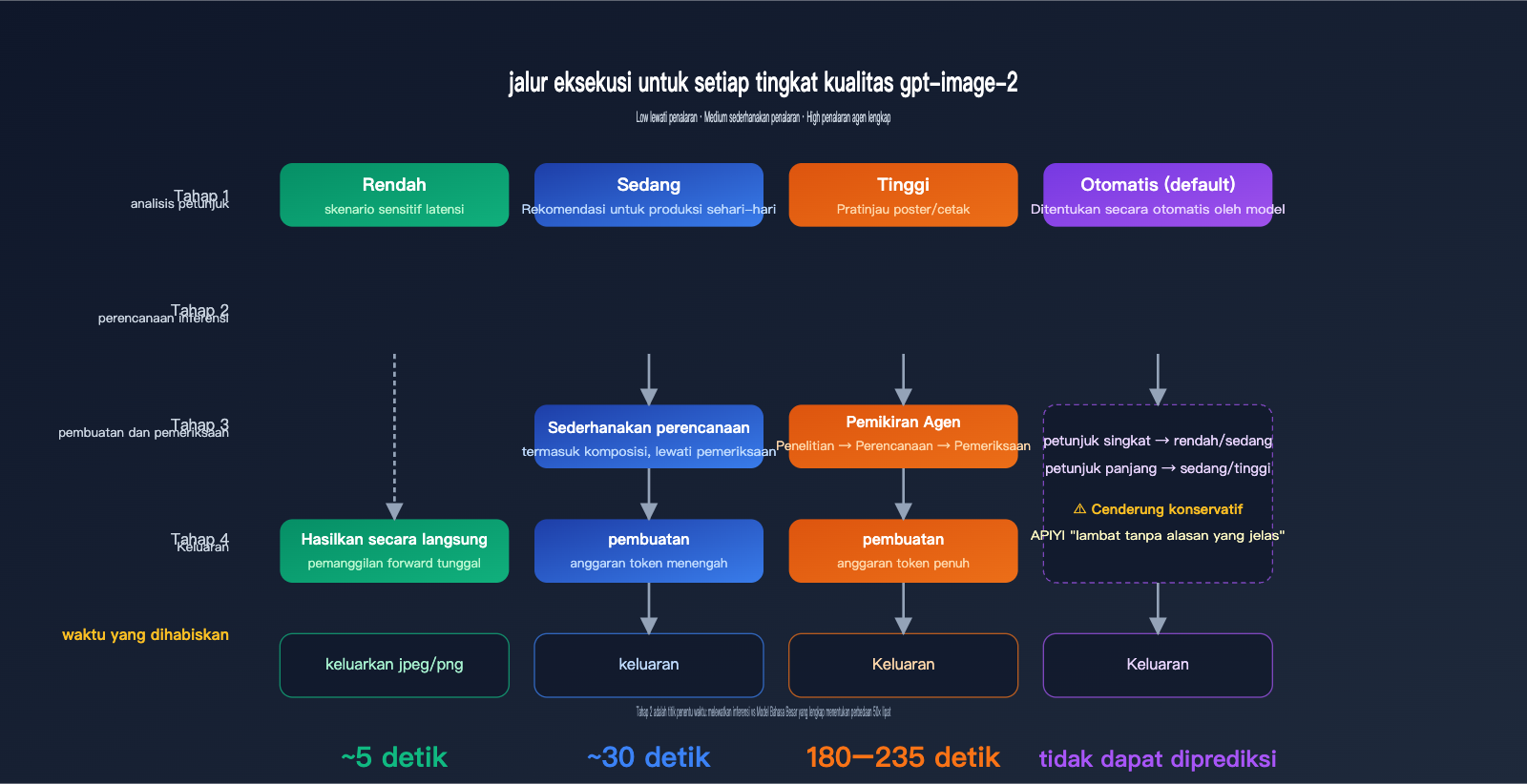
Mekanisme Kerja Parameter quality
Dokumentasi resmi gpt-image-2 menyatakan dengan jelas bahwa quality="low" dirancang untuk skenario yang sensitif terhadap latensi, memberikan respons dalam hitungan detik dengan kualitas visual yang masih dapat diterima. Sementara itu, quality="high" mengaktifkan rantai pemikiran (Agentic Chain of Thought) yang lengkap—model akan merencanakan komposisi, tata letak teks, dan logika pencahayaan secara internal sebelum mulai menggambar. Tahap penalaran ini tidak terlihat oleh mata manusia, namun memakan sekitar 70–80% dari total waktu pemrosesan.
quality="medium" adalah pilihan jalan tengah; ia mempertahankan perencanaan versi sederhana tetapi melewati tahap pengecekan detail. Jika Anda tidak menentukan parameter, quality="auto" akan memilih secara otomatis berdasarkan kompleksitas petunjuk. Namun, berdasarkan pengujian, model cenderung memilih medium atau high secara konservatif, itulah sebabnya banyak pengembang salah mengira bahwa "pengaturan default itu lambat".
Mekanisme Kerja Parameter size
gpt-image-2 secara native mendukung tiga ukuran standar: 1024x1024, 1536x1024, dan 1024x1536, ditambah opsi auto. Model ini juga mendukung ukuran kustom selama total piksel tidak melebihi 2K (2560×1440 = sekitar 3,69 juta piksel). Jika melebihi ambang batas ini, model akan masuk ke area eksperimental dengan stabilitas hasil yang menurun.
Jumlah piksel secara langsung menentukan jumlah token visual. 1024×1024 menghasilkan sekitar 1024 token visual, 1536×1024 naik menjadi sekitar 1536 token, dan seterusnya. Penggandaan jumlah token berarti waktu penalaran dan pembuatan gambar juga berlipat ganda, begitu pula dengan biaya output.
| Ukuran Standar | Total Piksel | Token Visual (Estimasi) | Relatif Waktu | Skenario Penggunaan |
|---|---|---|---|---|
1024x1024 |
1.05M | ~1024 | 1.0× | Umum, media sosial, thumbnail |
1536x1024 |
1.57M | ~1536 | 1.5× | Banner, sampul artikel |
1024x1536 |
1.57M | ~1536 | 1.5× | Poster, konten vertikal |
| Kustom ≤ 2K | Hingga 3.69M | Hingga ~3686 | 2–3× | Pratinjau cetak resolusi tinggi |
🎯 Saran Ukuran: Dalam produksi nyata, disarankan menggunakan
1024x1024untuk 95% permintaan, dan hanya beralih ke seri 1536 jika memerlukan rasio khusus seperti banner atau poster. Saat melakukan pemanggilan melalui APIYI (apiyi.com), Anda dapat menggunakan ukuran kustom apa pun, namun pastikan tetap di bawah 2K untuk menjaga stabilitas.
Efek Kopling Kedua Parameter
quality dan size memiliki hubungan perkalian, bukan penjumlahan. Kombinasi high + 1536x1024 jauh lebih lambat daripada low + 1024x1024, bukan hanya beberapa kali lipat, melainkan puluhan kali lipat. Hal ini sangat krusial dalam skenario konkuren—Anda mungkin berpikir menjalankan 10 permintaan secara bersamaan bisa selesai dalam 1 detik, padahal kenyataannya mungkin butuh 200 detik untuk menyelesaikan 10 gambar, yang akan menyebabkan klien HTTP Anda mengalami timeout.
Hal yang lebih tersembunyi adalah adanya kopling implisit antara quality dan kompleksitas petunjuk. Pada pengaturan high, petunjuk sederhana ("a red apple") mungkin memakan waktu sekitar 100 detik, sedangkan petunjuk kompleks ("kota cyberpunk di malam hari saat hujan, papan neon, rasio sinematik, interaksi 6 karakter") bisa menembus 230 detik atau lebih. Tahap penalaran model akan memperluas anggaran token secara dinamis sesuai jumlah elemen dalam skenario. Jadi, semakin kompleks petunjuknya, semakin lambat pengaturan high, dan semakin tinggi harganya.
🎯 Saran Penulisan Petunjuk: Untuk pengaturan
high, disarankan untuk membatasi petunjuk di bawah 200 kata dan menempatkan elemen inti di 50 kata pertama. Deskripsi yang bertele-tele tidak selalu meningkatkan hasil, justru akan memperpanjang waktu penalaran. Aturan ini juga berlaku saat melakukan pemanggilan melalui APIYI (apiyi.com), karena lapisan proksi API meneruskan petunjuk secara utuh, sehingga perilaku model tetap konsisten dengan versi resmi.
Perbandingan Waktu Proses dan Harga untuk Setiap Tingkat Kualitas gpt-image-2
Tabel di bawah ini berasal dari data aktual yang kami kumpulkan di platform APIYI (apiyi.com) di berbagai rentang waktu dan tingkat kompleksitas prompt yang berbeda. Data mungkin sedikit berfluktuasi tergantung pada waktu, prompt, dan jaringan, namun skala besarnya dapat dipercaya.
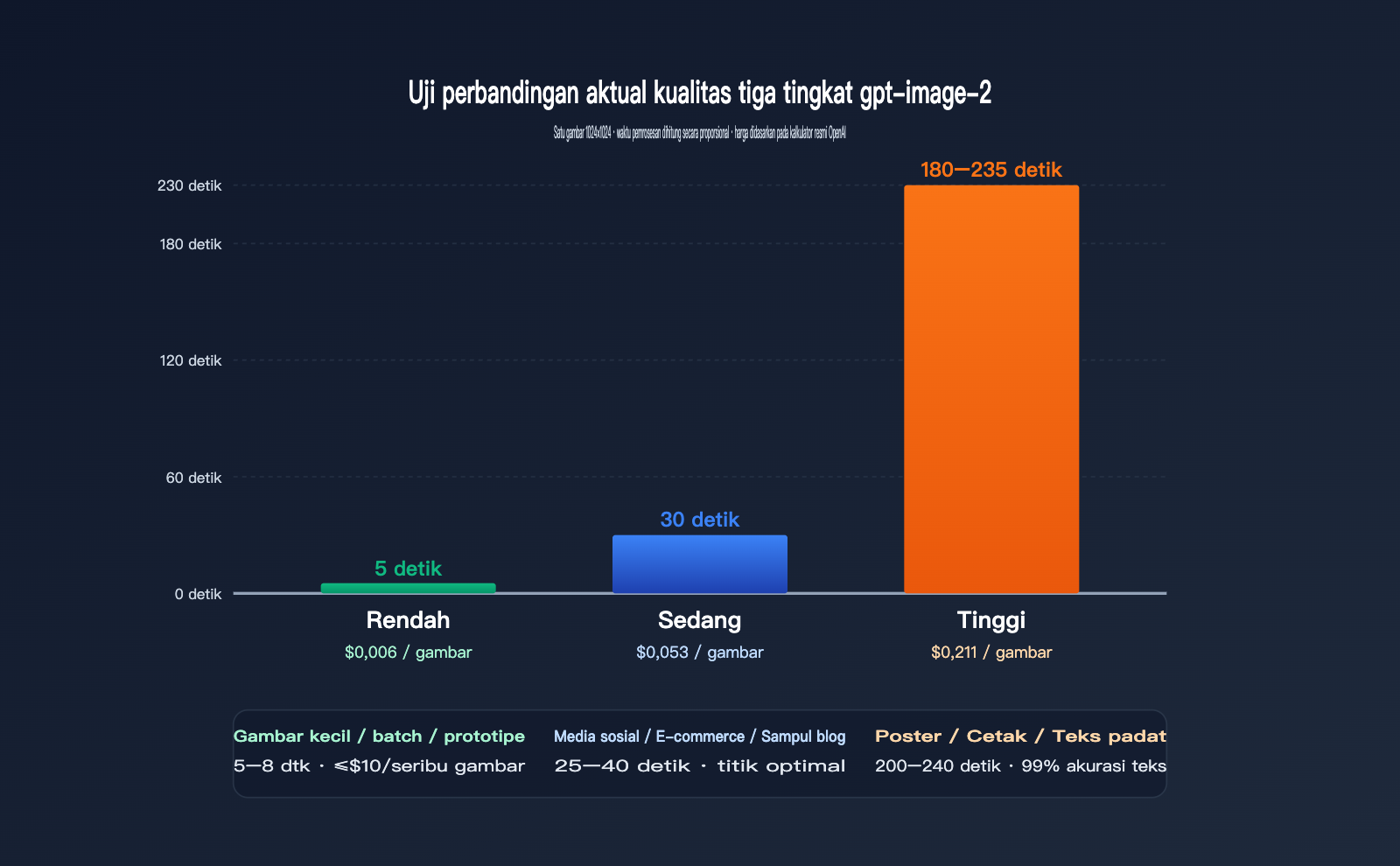
Data Aktual 1024×1024 per Gambar
| Kualitas | Rata-rata Waktu | Harga (USD/Gambar) | Ketepatan Visual | Ketepatan Teks | Skenario Penggunaan |
|---|---|---|---|---|---|
low |
3–8 detik | $0,006 | Sedang | Biasa | Thumbnail, batch, uji prototipe |
medium |
20–40 detik | $0,053 | Tinggi | Baik | Media sosial, e-commerce, sampul blog |
high |
150–235 detik | $0,211 | Sangat Tinggi | Sangat Tinggi (99%+) | Poster, cetak, teks padat |
Terlihat hubungan non-linear yang sangat jelas: dari low ke medium harga naik 9 kali lipat, namun waktu hanya naik 5 kali lipat; dari medium ke high harga naik 4 kali lipat, namun waktu naik 6–7 kali lipat. Dengan kata lain, biaya marjinal untuk kualitas high dibayar dengan "waktu tunggu".
Jika bisnis Anda tidak benar-benar membutuhkan ketepatan teks 99% (seperti ilustrasi murni, desain abstrak, atau gambar konsep), gunakan medium saja, lebih hemat uang dan waktu. Hanya skenario yang membutuhkan ketepatan teks dan detail tinggi seperti poster, desain IP, atau pratinjau cetak yang layak mendapatkan waktu tunggu 200 detik untuk kualitas high.
🎯 Saran Estimasi Biaya: Sebelum meluncurkan ke lingkungan produksi, disarankan untuk mencoba 100 gambar low/medium/high di APIYI apiyi.com, buat laporan A/B internal mengenai distribusi waktu, harga, dan kualitas gambar, baru kemudian tentukan tingkat mana yang akan digunakan untuk lalu lintas utama. Menghabiskan kuota selama seminggu tidak akan melebihi $30, namun bisa mencegah SLA Anda hancur akibat permintaan yang lambat setelah peluncuran.
Perbedaan Waktu antara 1024×1024 vs 1536×1024
Untuk tingkat medium yang sama, 1024×1024 rata-rata memakan waktu 25 detik, sedangkan 1536×1024 rata-rata 38 detik, dan 1024×1536 juga sekitar 38 detik. Perbedaan ini sesuai dengan rasio 1,5 kali lipat dari jumlah token visual. Namun, pada tingkat high, perbedaan ini akan diperbesar—high + 1024×1024 sekitar 180 detik, sedangkan high + 1536×1024 mudah menembus 240 detik, bahkan lebih lama pada jam sibuk.
Rentang Fluktuasi Aktual untuk Kualitas High
Perlu diingat bahwa waktu proses untuk kualitas high bukanlah nilai konstan, melainkan distribusi yang cukup lebar. Kami mengambil sampel 200 permintaan high + 1024×1024, yang tercepat 145 detik, terlambat 280 detik, dan median sekitar 195 detik. Fluktuasi ini berasal dari dua faktor: pertama, anggaran inferensi yang dipicu oleh kompleksitas prompt, dan kedua, perbedaan beban pada backend OpenAI di waktu yang berbeda. Oleh karena itu, kualitas high tidak boleh menggunakan pemanggilan sinkron yang memblokir—harus dibuat sebagai tugas asinkron, di mana frontend menerima ID tugas terlebih dahulu, dan backend melakukan polling atau memberikan notifikasi balik kepada pengguna.
Kesalahpahaman Umum: Resolusi Lebih Tinggi Berarti Kualitas Lebih Baik
Banyak pengembang secara intuitif berpikir bahwa semakin tinggi resolusi, semakin baik kualitas gambarnya, sehingga mereka secara default memilih seri 1536. Ini sebenarnya keliru. Kualitas gambar gpt-image-2 pada 1024×1024 sudah sangat memadai dengan pemanfaatan piksel yang optimal; beralih ke seri 1536 hanya mengubah rasio aspek, detail yang benar-benar ditampilkan di layar tidak bertambah. Kecuali Anda memang membutuhkan komposisi lanskap/potret, mempertahankan 1024×1024 adalah pilihan yang paling hemat.
Contoh Lengkap Pemanggilan gpt-image-2 dengan Python SDK
Berikut adalah tiga bagian kode mulai dari pemanggilan dasar hingga enkapsulasi tingkat produksi yang bisa Anda gunakan sesuai kebutuhan. Semua contoh didasarkan pada Python SDK resmi OpenAI, dengan base_url yang diarahkan ke APIYI apiyi.com, sehingga perilakunya sama persis dengan endpoint resmi.
Contoh Dasar: Pembuatan Gambar dari Teks
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="Kota cyberpunk di malam hari saat hujan, papan neon, rasio aspek film",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
Kode ini cukup untuk menjalankan fungsi, tetapi ada jebakan—quality="high" + timeout default hampir pasti akan gagal. Timeout HTTP default dari Python SDK OpenAI adalah 600 detik, terdengar cukup, tetapi banyak pengguna yang membungkusnya dengan requests/httpx dan menetapkan timeout 60 detik, yang akan menyebabkan ReadTimeout saat melakukan permintaan massal dengan kualitas high.
Contoh Produksi: Timeout Eksplisit dan Percobaan Ulang
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
Pengalaman praktis:
timeout=300adalah nilai aman untuk kualitas high, mencakup 99% permintaan; jika Anda yakin menggunakan low/medium, Anda bisa menurunkannya ke 60.max_retries=2menggunakan exponential backoff bawaan SDK, yang jauh lebih stabil daripada mencoba melakukan retry manual.output_format="jpeg"+output_compression=85biasanya dapat membuat file 60–70% lebih kecil daripada PNG, dengan perbedaan kualitas yang sulit dibedakan oleh mata, sangat direkomendasikan untuk thumbnail Web.
🎯 Saran Timeout: Saat memanggil melalui APIYI apiyi.com, platform telah melakukan keep-alive untuk permintaan dengan waktu proses lama, namun timeout pada SDK klien harus diatur sendiri dan tidak boleh mengandalkan nilai default. Untuk kualitas high, disarankan minimal 240 detik, sedangkan untuk low bisa diperketat ke 30 detik agar permintaan yang macet tidak memblokir connection pool.
Contoh Batch: Pembuatan Asinkron dan Konkurensi
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["kucing", "anjing", "burung", "ikan", "kelinci"] * 4))
Konkurensi adalah teknik terpenting untuk pembuatan gambar dalam jumlah besar. Kualitas low membutuhkan 5 detik per gambar, 20 gambar secara serial memakan waktu 100 detik; dengan 5 jalur konkurensi hanya butuh 20 detik. Namun, pastikan untuk mengunci kualitas di low atau medium—konkurensi pada kualitas high hanya akan menyebabkan timeout massal yang tidak sebanding dengan hasilnya.
Rekomendasi Parameter gpt-image-2 untuk Berbagai Skenario Bisnis
Setelah memahami data teoritis, mari kita terapkan pada skenario nyata. Berikut adalah kombinasi parameter optimal yang telah kami susun untuk kebutuhan bisnis dengan frekuensi tinggi.
| Skenario Bisnis | quality | size | output_format | Estimasi Waktu | Harga Satuan |
|---|---|---|---|---|---|
| Gambar Utama E-commerce, Banner | medium | 1024×1024 | jpeg+85 | 25–35 dtk | $0.053 |
| Gambar Media Sosial/Xiaohongshu | medium | 1024×1536 | jpeg+85 | 30–40 dtk | ~$0.06 |
| Sampul Artikel, Header Blog | medium | 1536×1024 | webp+90 | 30–40 dtk | ~$0.06 |
| Poster, Pratinjau Cetak | high | 1024×1536 | png | 200–240 dtk | ~$0.21 |
| Subtitle/Sampul PPT | high | 1536×1024 | png | 200–240 dtk | ~$0.21 |
| Thumbnail, Uji Prototipe | low | 1024×1024 | jpeg+75 | 3–8 dtk | $0.006 |
| Sketsa Massal, Papan Inspirasi | low | 1024×1024 | jpeg+75 | 3–8 dtk × N | $0.006 × N |
| Pembuatan Gambar Instan AI | low | 1024×1024 | webp+85 | 5–10 dtk | $0.006 |
Skenario 1: E-commerce dan Media Sosial — Medium adalah Titik Manisnya
Gambar utama e-commerce dan konten media sosial sangat sensitif terhadap waktu (pengguna tidak bisa menunggu 4 menit setelah mengunggah produk), namun tetap membutuhkan hasil yang jernih dan menarik. Medium adalah pilihan terbaik. Dengan waktu produksi sekitar 30 detik dan biaya 5 sen, menjalankan 1.000 gambar per hari hanya memakan biaya $53.
Skenario 2: Poster dan Pratinjau Cetak — Bayar Waktu untuk High
Poster atau sampul yang mengandung banyak teks, tata letak kompleks, dan kebutuhan konsistensi wajah karakter memerlukan kemampuan penalaran Agentic dari tingkat high. Jangan mencoba memangkas waktu di sini; berikan petunjuk "berbasis tugas" di sisi front-end—beri tahu pengguna untuk memeriksa kembali 3–5 menit setelah pengiriman.
Skenario 3: Produksi Massal dan Prototipe — Wajib Low
Untuk skenario yang mengharuskan "membuat 10.000 sketsa dalam semalam", Anda wajib menggunakan tingkat low, tanpa kompromi. Dengan kombinasi konkurensi asinkron dan kompresi jpeg+75, satu node GPU dapat menghasilkan throughput yang sangat besar.
Skenario 4: Interaksi Pengguna Instan — Wajib Low atau Medium
Untuk skenario di mana pengguna sedang menunggu, seperti chatbot, pembuatan gambar dalam asisten AI, atau balasan otomatis layanan pelanggan, jangan pernah menggunakan high. Jika pengguna menunggu 4 menit, setidaknya 50% dari mereka akan melakukan refresh atau pergi, yang akan merusak pengalaman pengguna. Disarankan untuk menetapkan tingkat low dengan animasi "memuat…", sehingga pengguna mendapatkan hasil dalam 5–8 detik. Jika kualitas dirasa kurang, tambahkan tombol "optimasi HD" untuk memicu pembuatan ulang dengan tingkat medium.
Skenario 5: Moderasi Konten dan Pembuatan Ulang Kepatuhan
Untuk pembuatan ulang setelah diblokir oleh kebijakan konten OpenAI, disarankan untuk mencoba prompt baru dengan tingkat low terlebih dahulu untuk menguji apakah lolos moderasi. Setelah dipastikan lolos, baru tingkatkan ke medium/high untuk hasil akhir. Strategi dua tahap ini meminimalkan biaya kegagalan moderasi dan menghindari pemborosan waktu 200 detik pada tingkat high hanya untuk mendapati bahwa gambar tetap diblokir.
🎯 Strategi Campuran: Banyak sistem produksi menggunakan "pembuatan dua tingkat"—pertama gunakan tingkat low untuk membuat pratinjau instan bagi pengguna, dan setelah pengguna memilih, gunakan tingkat high untuk membuat hasil akhir. Strategi ini sangat mulus diimplementasikan pada APIYI (apiyi.com) karena satu kunci API mencakup semua tingkat quality, tanpa perlu mengganti akun.
Pertanyaan Umum (FAQ)
Q1: Mengapa permintaan tingkat high saya selalu timeout?
SDK Python OpenAI memiliki timeout default 600 detik, yang secara teori cukup. Namun, banyak framework (FastAPI, Flask, Celery) menambahkan timeout mereka sendiri di lapisan luar. Periksa pengaturan waktu di seluruh rantai pemanggilan; disarankan untuk memberikan setidaknya 300 detik untuk seluruh alur tingkat high. Jika menggunakan httpx, pastikan untuk mengatur httpx.Timeout(300.0) secara eksplisit.
Q2: Berapa nilai output_compression yang paling tepat?
Untuk format JPEG, 85 adalah titik manisnya—perbedaan dengan 100 hampir tidak terlihat oleh mata telanjang, namun ukuran file bisa berkurang 30–40%. Untuk format WebP, 90 juga merupakan nilai yang umum digunakan. Di bawah 70, akan muncul blok warna yang jelas, terutama pada area latar belakang gradien. Parameter ini tidak memengaruhi waktu pembuatan, hanya memengaruhi serialisasi output akhir.
Q3: Apakah ada perbedaan antara memanggil gpt-image-2 melalui APIYI (apiyi.com) dan endpoint resmi?
Parameter dan perilakunya sepenuhnya diteruskan, termasuk quality, size, output_format, output_compression, n, background, dan semua bidang lainnya. Perbedaannya adalah APIYI (apiyi.com) menyediakan node berkecepatan tinggi yang dapat diakses dari dalam negeri, penagihan terpadu, dan pembayaran sesuai pemakaian tanpa konsumsi minimum, sehingga lebih ramah bagi pengembang lokal.
Q4: Bisakah parameter n mengembalikan beberapa gambar sekaligus?
Bisa, gpt-image-2 mendukung n=1 hingga n=10. Namun perlu diingat—total waktu untuk beberapa gambar adalah sekitar 0,7–0,9 kali dari satu gambar dikalikan n (tidak sepenuhnya paralel), dan total harga dihitung n kali lipat. Jika Anda membutuhkan "serangkaian karakter yang konsisten", gunakan n=4 agar model melakukan inferensi sekaligus, karena gpt-image-2 dapat menjaga konsistensi wajah dalam satu inferensi tunggal.
Q5: Tingkat apa yang sebenarnya digunakan jika quality="auto"?
Dalam pengujian, auto cenderung memilih medium atau high, tergantung pada panjang dan kompleksitas prompt. Prompt pendek ("a cat") kemungkinan besar menggunakan low/medium, sedangkan prompt panjang (termasuk karakter, pemandangan, teks, gaya) kemungkinan besar menggunakan high. Untuk lingkungan produksi, disarankan untuk menentukannya secara eksplisit, jangan mengandalkan penilaian implisit auto.
Q6: Mana yang lebih baik kualitasnya, 1024×1536 atau 1536×1024?
Total piksel keduanya sama (sekitar 1,57 juta), sehingga kualitasnya pada dasarnya sama. Perbedaannya hanya pada rasio aspek—layar vertikal (1024×1536) cocok untuk poster, potret seluruh tubuh, dan konten seluler; layar horizontal (1536×1024) cocok untuk spanduk, pemandangan, dan sampul PC. Pilih berdasarkan kebutuhan komposisi, tidak memengaruhi kecepatan atau harga.
Q7: Bisakah saya melewati inferensi dan langsung menggunakan model dasar?
Tidak bisa, penalaran Agentic pada gpt-image-2 adalah bagian dari arsitektur model dan tidak dapat dimatikan. Jika Anda hanya membutuhkan pembuatan gambar cepat ala SD tradisional tanpa rendering teks dan penalaran, disarankan menggunakan tingkat low, yang akan melewati rantai inferensi lengkap. Atau pertimbangkan nano-banana-pro dari Google; tingkat cepatnya bahkan lebih cepat daripada gpt-image-2 low, dan model ini juga sudah tersedia di APIYI (apiyi.com).
🎯 Saran Kolaborasi Multi-Model: Sistem pembuatan gambar yang matang biasanya tidak hanya menggunakan satu model. Disarankan untuk menggunakan nano-banana-pro untuk pratinjau cepat (respons 5 detik), gpt-image-2 medium untuk alur gambar utama, dan gpt-image-2 high untuk skenario premium. Ketiga model tersebut berbagi kunci API yang sama di APIYI (apiyi.com) dengan penagihan sesuai pemakaian, menjadikannya kombinasi akses API gambar paling hemat biaya di tahun 2026.
Kesimpulan: Anggap parameter sebagai sakelar performa, bukan sekadar dekorasi
Filosofi desain gpt-image-2 sangat berbeda dari model gambar generasi sebelumnya—model ini menjadikan inferensi sebagai langkah inti dalam pembuatan gambar. Oleh karena itu, quality bukan lagi sekadar opsi "kualitas gambar bagus atau buruk", melainkan sakelar untuk menentukan "seberapa dalam jalur inferensi yang akan ditempuh". Dengan memahami hal ini, Anda akan mengerti mengapa API yang sama bisa memiliki rentang waktu pemrosesan hingga 50 kali lipat, mulai dari 5 detik hingga 235 detik.
Dalam praktiknya, kami menyarankan untuk menjadikan "pemilihan parameter" sebagai langkah pertama dalam desain bisnis Anda: tentukan terlebih dahulu berapa lama latensi yang dapat ditoleransi oleh skenario Anda, seberapa tinggi kualitas gambar yang dibutuhkan, dan berapa batas atas biaya per unit, kemudian periksa tabel untuk memilih quality dan size yang sesuai. Menentukan parameter ini sejak awal jauh lebih efisien daripada melakukan optimasi setelah aplikasi diluncurkan.
🎯 Saran Akhir: Saat mulai mengintegrasikan gpt-image-2, kami sarankan untuk melakukan pengujian perbandingan pada tiga tingkat (low/medium/high) melalui APIYI apiyi.com. Berikan skor pada waktu pemrosesan aktual dan kualitas gambar yang dihasilkan sebelum menentukan parameter untuk trafik utama Anda. Menggunakan satu token untuk mengakses ketiga tingkat tersebut, dengan sistem pembayaran sesuai penggunaan (pay-as-you-go) dan tanpa biaya minimum, adalah cara paling efisien untuk mengintegrasikan API gambar di tahun 2026.
— Tim Teknis APIYI | Terus memantau dinamika model pembuatan gambar, lihat tutorial mendalam lainnya di pusat bantuan APIYI apiyi.com