Catatan Penulis: Interpretasi mendalam konten inti makalah teknis Kimi K2.5, menjelaskan secara detail arsitektur MoE dengan parameter 1T, konfigurasi 384 pakar, mekanisme atensi MLA, serta memberikan persyaratan perangkat keras untuk penerapan lokal dan perbandingan solusi akses API.
Ingin tahu detail teknis Kimi K2.5? Artikel ini, berdasarkan makalah teknis resmi Kimi K2.5, akan menginterpretasikan secara sistematis arsitektur MoE triliunan parameter, metode pelatihan, dan hasil pengujian benchmark-nya, serta menjelaskan secara rinci persyaratan perangkat keras untuk penerapan lokal.
Nilai Inti: Setelah membaca artikel ini, Anda akan menguasai parameter teknis inti Kimi K2.5, prinsip desain arsitektur, serta kemampuan untuk memilih skema penerapan terbaik berdasarkan kondisi perangkat keras.
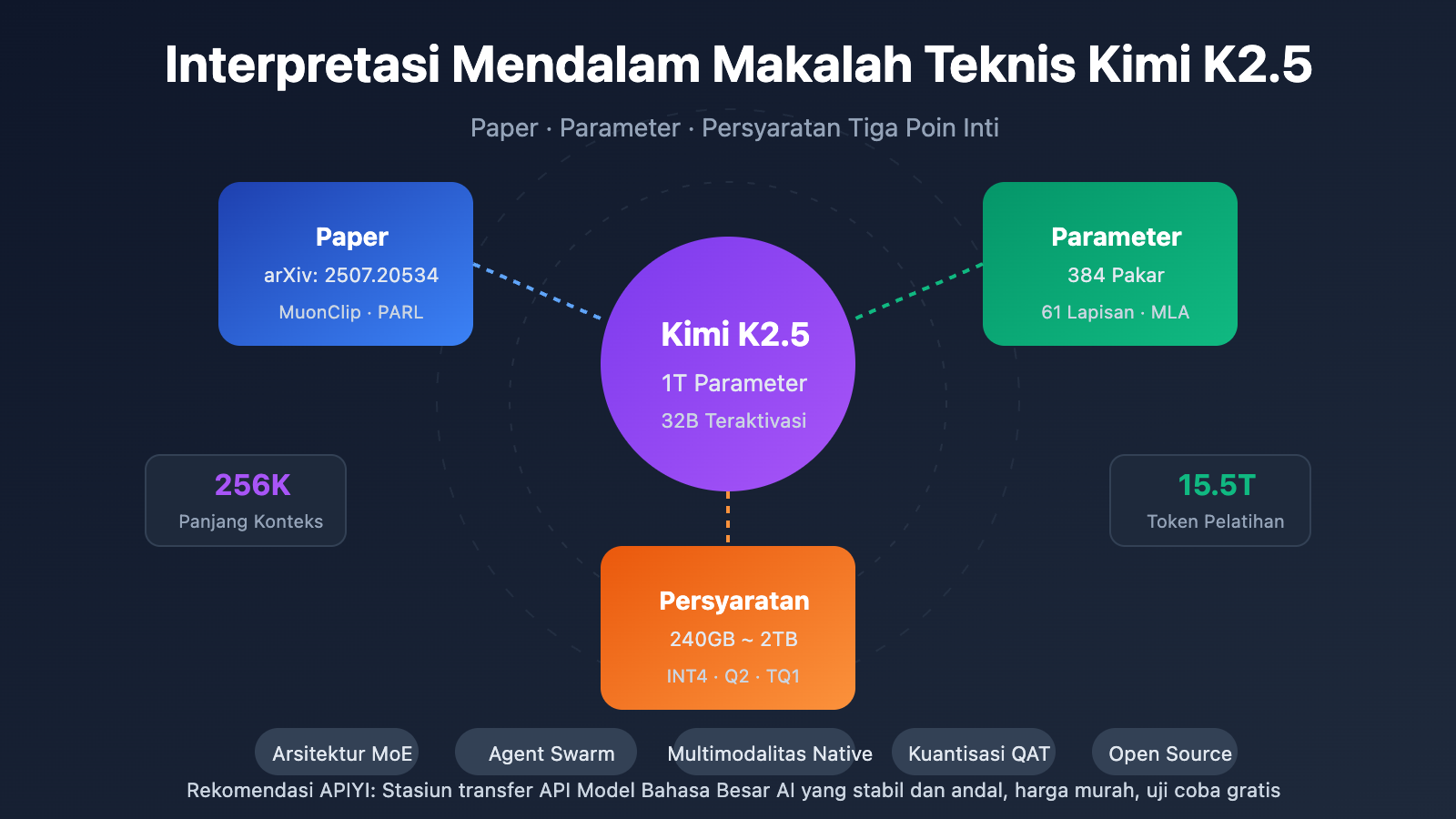
Poin Inti Makalah Teknis Kimi K2.5
| Poin | Detail Teknis | Nilai Inovasi |
|---|---|---|
| MoE Triliunan Parameter | Total 1T parameter, 32B parameter aktif | Hanya mengaktifkan 3.2% saat inferensi, efisiensi sangat tinggi |
| Sistem 384 Pakar | Memilih 8 pakar + 1 pakar bersama per Token | 50% lebih banyak pakar daripada DeepSeek-V3 |
| Atensi MLA | Multi-head Latent Attention | Mengurangi KV Cache, mendukung konteks 256K |
| Pengoptimal MuonClip | Pelatihan efisien token, nol Loss Spike | Pelatihan 15.5T Token tanpa lonjakan loss |
| Multimodalitas Native | MoonViT 400M pengkode visi | Pelatihan campuran visi-teks 15T |
Latar Belakang Makalah Kimi K2.5
Makalah teknis Kimi K2.5 dirilis oleh tim Moonshot AI, dengan nomor arXiv 2507.20534. Makalah ini merinci evolusi teknis dari Kimi K2 ke K2.5, dengan kontribusi inti meliputi:
- Arsitektur MoE Ultra-Sparse: Konfigurasi 384 pakar, 50% lebih banyak daripada 256 pakar milik DeepSeek-V3.
- Optimasi Pelatihan MuonClip: Menyelesaikan masalah Loss Spike dalam pelatihan skala besar.
- Paradigma Agent Swarm: Metode pelatihan PARL (Parallel-Agent Reinforcement Learning).
- Fusi Multimodal Native: Mengintegrasikan kemampuan visi-bahasa sejak tahap pra-pelatihan.
Makalah tersebut menunjukkan bahwa seiring dengan semakin langkanya data manusia berkualitas tinggi, efisiensi Token menjadi koefisien kunci dalam penskalaan Model Bahasa Besar, yang mendorong penerapan pengoptimal Muon dan pembuatan data sintetis.

Spesifikasi Parameter Lengkap Kimi K2.5
Parameter Arsitektur Inti
| Kategori Parameter | Nama Parameter | Nilai | Keterangan |
|---|---|---|---|
| Skala | Total Parameter | 1T (1,04 Triliun) | Ukuran model lengkap |
| Skala | Parameter Aktif | 32B | Penggunaan aktual per inferensi |
| Struktur | Jumlah Layer | 61 Layer | Termasuk 1 layer Dense |
| Struktur | Dimensi Tersembunyi | 7168 | Dimensi backbone model |
| MoE | Jumlah Ahli (Experts) | 384 | 128 lebih banyak dari DeepSeek-V3 |
| MoE | Ahli Aktif | 8 + 1 Bersama | Routing Top-8 |
| MoE | Dimensi Tersembunyi Ahli | 2048 | Dimensi FFN setiap ahli |
| Atensi | Jumlah Head Atensi | 64 | Setengah dari DeepSeek-V3 |
| Atensi | Tipe Mekanisme | MLA | Multi-head Latent Attention |
| Lainnya | Ukuran Kosakata | 160K | Mendukung multibahasa |
| Lainnya | Panjang Konteks | 256K | Pemrosesan dokumen sangat panjang |
| Lainnya | Fungsi Aktivasi | SwiGLU | Transformasi non-linear yang efisien |
Interpretasi Desain Parameter Kimi K2.5
Mengapa memilih 384 ahli?
Analisis Scaling Law dalam makalah penelitian menunjukkan bahwa terus meningkatkan performa sparse dapat memberikan peningkatan kinerja yang signifikan. Tim meningkatkan jumlah ahli dari 256 pada DeepSeek-V3 menjadi 384, guna meningkatkan kemampuan representasi model.
Mengapa mengurangi head atensi?
Untuk mengurangi biaya komputasi saat inferensi, jumlah head atensi dikurangi dari 128 menjadi 64. Dikombinasikan dengan mekanisme MLA, desain ini secara signifikan mengurangi penggunaan memori KV Cache sambil tetap mempertahankan performa.
Keunggulan Mekanisme Atensi MLA:
MHA Tradisional: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = Jumlah Layer, H = Jumlah Head, D = Dimensi, B = Batch, C = Dimensi Kompresi
MLA melalui kompresi ruang laten dapat mengurangi KV Cache sekitar 10 kali lipat, sehingga memungkinkan pemrosesan konteks 256K.
Parameter Encoder Visual
| Komponen | Parameter | Nilai |
|---|---|---|
| Nama | MoonViT | Encoder visual yang dikembangkan sendiri |
| Jumlah Parameter | – | 400M |
| Fitur | Pooling Spasial-Temporal | Mendukung pemahaman video |
| Metode Integrasi | Fusi Native | Integrasi selama fase pre-training |
Persyaratan Perangkat Keras Deployment Kimi K2.5
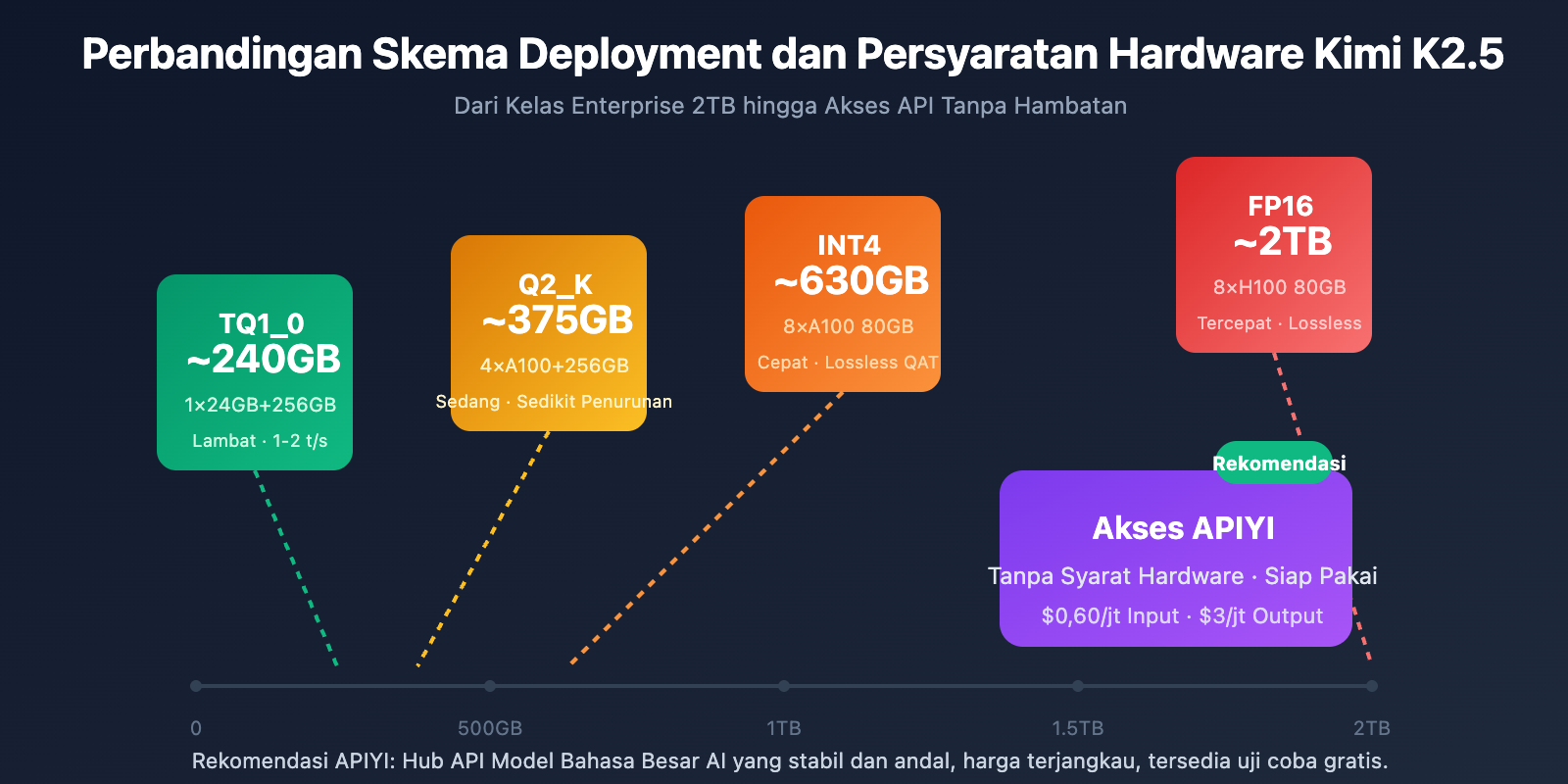
Persyaratan Perangkat Keras Deployment Lokal
| Presisi Kuantisasi | Kebutuhan Penyimpanan | Hardware Minimum | Kecepatan Inferensi | Penurunan Presisi |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | Tercepat | Tidak ada |
| INT4 (QAT) | ~630GB | 8×A100 80GB | Cepat | Hampir lossless |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | Sedang | Sedikit |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | Lambat (1-2 t/s) | Signifikan |
Penjelasan Detail Kimi K2.5 Requirements
Deployment Kelas Enterprise (Direkomendasikan)
Konfigurasi Hardware: 2× NVIDIA H100 80GB atau 8× A100 80GB
Kebutuhan Penyimpanan: 630GB+ (Kuantisasi INT4)
Ekspektasi Performa: 50-100 tokens/s
Skenario Penggunaan: Lingkungan produksi, layanan konkurensi tinggi
Deployment Kompresi Ekstrem
Konfigurasi Hardware: 1× RTX 4090 24GB + 256GB Memori Sistem
Kebutuhan Penyimpanan: 240GB (Kuantisasi 1.58-bit)
Ekspektasi Performa: 1-2 tokens/s
Skenario Penggunaan: Pengujian riset, verifikasi fungsional
Catatan: Layer MoE sepenuhnya dialihkan (offload) ke RAM, sehingga kecepatannya lambat
Mengapa membutuhkan memori sebanyak itu?
Meskipun arsitektur MoE hanya mengaktifkan 32B parameter untuk setiap inferensi, model tetap perlu menyimpan parameter 1T secara lengkap di memori agar dapat melakukan routing secara dinamis ke ahli yang tepat berdasarkan input. Ini adalah karakteristik bawaan dari model MoE.
Solusi Lebih Praktis: Akses API
Bagi sebagian besar pengembang, ambang batas perangkat keras untuk melakukan deployment Kimi K2.5 secara lokal sangatlah tinggi. Menggunakan akses API adalah pilihan yang lebih praktis:
| Solusi | Biaya | Keunggulan |
|---|---|---|
| APIYI (Rekomendasi) | $0,60/jt Input, $3/jt Output | Antarmuka terpadu, pergantian berbagai model, kuota gratis |
| API Resmi | Sama seperti di atas | Fitur paling lengkap, pembaruan tercepat |
| Lokal 1-bit | Biaya Hardware + Listrik | Lokalisasi data |
Saran Deployment: Kecuali jika ada persyaratan lokalisasi data yang ketat, disarankan untuk menggunakan APIYI (apiyi.com) untuk mengakses Kimi K2.5 guna menghindari investasi perangkat keras yang mahal.
Hasil Benchmark Paper Kimi K2.5
Evaluasi Kemampuan Inti
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | Keterangan |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | Kompetisi matematika (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | Kompetisi matematika (avg@32) |
| GPQA-Diamond | 87.6% | – | – | Penalaran ilmiah (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | Perbaikan kode |
| SWE-Bench Multi | 73.0% | – | – | Kode multibahasa |
| HLE-Full | 50.2% | – | – | Penalaran komprehensif (dengan alat) |
| BrowseComp | 60.2% | 54.9% | 24.1% | Interaksi web |
| MMMU-Pro | 78.5% | – | – | Pemahaman multimodal |
| MathVision | 84.2% | – | – | Matematika visual |
Data dan Metode Pelatihan
| Tahap | Volume Data | Metode |
|---|---|---|
| Pra-pelatihan K2 Base | 15.5T tokens | Pengoptimal MuonClip, nol Loss Spike |
| Kelanjutan Pra-pelatihan K2.5 | 15T campuran visi-teks | Fusi multimodal native |
| Pelatihan Agent | – | PARL (Parallel Agent Reinforcement Learning) |
| Pelatihan Kuantisasi | – | QAT (Quantization-Aware Training) |
Paper ini secara khusus menekankan bahwa pengoptimal MuonClip membuat seluruh proses pra-pelatihan 15.5T Token sama sekali tidak mengalami Loss Spike. Ini merupakan terobosan penting dalam pelatihan model dengan skala triliunan parameter.
Contoh Akses Cepat Kimi K2.5
Kode Pemanggilan Minimalis
Melalui platform APIYI, Anda bisa memanggil Kimi K2.5 hanya dengan 10 baris kode:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 在 apiyi.com 获取
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "解释 MoE 架构的工作原理"}]
)
print(response.choices[0].message.content)
Lihat Kode Pemanggilan Mode Thinking
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking 模式 - 深度推理
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "你是 Kimi,请详细分析问题"},
{"role": "user", "content": "证明根号2是无理数"}
],
temperature=1.0, # Thinking 模式推荐
top_p=0.95,
max_tokens=8192
)
# 获取推理过程和最终答案
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"推理过程:\n{reasoning}\n")
print(f"最终答案:\n{answer}")
Saran: Dapatkan kuota uji coba gratis melalui APIYI apiyi.com untuk merasakan kemampuan penalaran mendalam mode Thinking dari Kimi K2.5.
Pertanyaan Umum
Q1: Di mana saya bisa mendapatkan paper teknis Kimi K2.5?
Paper teknis resmi untuk seri Kimi K2 dipublikasikan di arXiv dengan nomor 2507.20534, dan dapat diakses melalui arxiv.org/abs/2507.20534. Laporan teknis Kimi K2.5 tersedia di blog resmi kimi.com/blog/kimi-k2-5.html.
Q2: Apa persyaratan minimum (requirements) untuk deployment lokal Kimi K2.5?
Skema kompresi ekstrem membutuhkan: 1 unit GPU dengan VRAM 24GB + RAM sistem 256GB + ruang penyimpanan 240GB. Namun, pada konfigurasi ini kecepatan inferensi hanya 1-2 token/detik. Konfigurasi yang direkomendasikan adalah 2×H100 atau 8×A100, menggunakan kuantisasi INT4 untuk mencapai performa kelas produksi.
Q3: Bagaimana cara cepat memverifikasi kemampuan Kimi K2.5?
Tidak perlu deployment lokal, Anda bisa melakukan pengujian cepat melalui API:
- Kunjungi APIYI apiyi.com untuk mendaftar akun.
- Dapatkan API Key dan kuota gratis.
- Gunakan contoh kode dalam artikel ini, isi nama model dengan
kimi-k2.5. - Rasakan kemampuan penalaran mendalam dari mode Thinking.
Kesimpulan
Poin-poin inti dari paper teknis Kimi K2.5:
- Inovasi Inti Kimi K2.5 Paper: Arsitektur MoE dengan 384 pakar + MLA Attention + pengoptimalkan MuonClip, mewujudkan pelatihan puncak tanpa kehilangan (lossless) pada parameter triliunan.
- Parameter Kunci Kimi K2.5: Total 1T parameter, 32B parameter aktif, 61 layer, konteks 256K, dengan hanya 3,2% parameter yang diaktifkan di setiap inferensi.
- Persyaratan Deployment Kimi K2.5: Ambang batas deployment lokal cukup tinggi (minimal 240GB+), sehingga akses melalui API adalah pilihan yang lebih praktis.
Kimi K2.5 sudah tersedia di APIYI apiyi.com. Disarankan untuk memverifikasi kemampuan model melalui API secara cepat guna mengevaluasi kesesuaiannya dengan skenario bisnis Anda.
Referensi
⚠️ Penjelasan Format Tautan: Semua tautan eksternal menggunakan format
Nama Referensi: domain.com, memudahkan untuk disalin tetapi tidak dapat diklik secara langsung untuk menghindari hilangnya bobot SEO.
-
Makalah arXiv Kimi K2: Laporan teknis resmi, menjelaskan arsitektur dan metode pelatihan secara mendalam
- Tautan:
arxiv.org/abs/2507.20534 - Keterangan: Dapatkan detail teknis lengkap dan data eksperimen
- Tautan:
-
Blog Teknis Kimi K2.5: Laporan teknis resmi K2.5 yang dirilis
- Tautan:
kimi.com/blog/kimi-k2-5.html - Keterangan: Pelajari tentang Agent Swarm dan kemampuan multimodal
- Tautan:
-
Model Card HuggingFace: Bobot model dan instruksi penggunaan
- Tautan:
huggingface.co/moonshotai/Kimi-K2.5 - Keterangan: Unduh bobot model, lihat panduan deployment
- Tautan:
-
Panduan Deployment Lokal Unsloth: Tutorial mendalam tentang deployment kuantisasi
- Tautan:
unsloth.ai/docs/models/kimi-k2.5 - Keterangan: Pelajari persyaratan perangkat keras untuk berbagai presisi kuantisasi
- Tautan:
Penulis: Tim Teknis
Diskusi Teknis: Selamat berdiskusi tentang detail teknis Kimi K2.5 di kolom komentar. Untuk bedah model lebih lanjut, silakan kunjungi komunitas teknis APIYI apiyi.com