title: "Analyse approfondie de Claude Opus 4.7 : Benchmark, performances et usage"
description: "Analyse des performances de Claude Opus 4.7 : SWE-bench, GPQA, et conseils pour l'invocation du modèle via APIYI."
Note de l'auteur : Analyse approfondie des benchmarks de Claude Opus 4.7 : 87,6 % sur SWE-bench Verified, 64,3 % sur SWE-bench Pro, 94,2 % sur GPQA Diamond, surpassant GPT-5.4 et Gemini 3.1 Pro. Guide pratique pour l'invocation du modèle inclus.
Anthropic a officiellement lancé Claude Opus 4.7 le 16 avril 2026, s'imposant en tête sur 7 des 10 benchmarks essentiels. Cet article propose une analyse détaillée des données fondamentales du benchmark de Claude Opus 4.7 et de ses cas d'usage réels.
Ceci n'est pas une simple reprise de la communication officielle. Toutes les données proviennent d'organismes de test indépendants tiers, mettant en lumière tant les points forts que les lacunes d'Opus 4.7, notamment dans des scénarios comme la recherche sur le Web.
Valeur ajoutée : Grâce à des données de benchmark réelles et à des retours d'expérience, découvrez si Claude Opus 4.7 vaut le changement et comment l'adopter à moindre coût.
💡 APIYI a intégré le modèle officiel Claude Opus 4.7. Bénéficiez d'un bonus de 10 % pour tout rechargement de 100 $ (soit une économie globale de 20 %), avec une compatibilité directe via l'interface OpenAI.

Points clés du benchmark de Claude Opus 4.7
| Benchmark | Score Opus 4.7 | vs Opus 4.6 | vs GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Verified | 87,6 % | 80,8 % (+6,8) | Gemini 3.1 Pro : 80,6 % ✅ Leader |
| SWE-bench Pro | 64,3 % | 53,4 % (+10,9) | GPT-5.4 : 57,7 % / Gemini : 54,2 % ✅ Leader |
| SWE-bench Multilingual | 80,5 % | 77,8 % (+2,7) | ✅ Leader en prog. multilingue |
| GPQA Diamond | 94,2 % | – | ✅ Référence en raisonnement scientifique |
| Terminal-Bench 2.0 | 69,4 % | – | ✅ Leader en usage terminal |
| OSWorld-Verified (Computer Use) | 78,0 % | 72,7 % (+5,3) | GPT-5.4 : 75,0 % ✅ Leader |
| MCP-Atlas (Appel d'outils) | +9,2 pts vs GPT-5.4 | – | ✅ Optimal pour agents |
| Vision multimodal | 98,5 % | – | ✅ Excellence en compréhension visuelle |
| BrowseComp (Recherche Web) | 79,3 % | – | GPT-5.4 : 89,3 % ❌ Retard |
Faits saillants du benchmark de Claude Opus 4.7
Anthropic a lancé Claude Opus 4.7 le 16 avril 2026, le positionnant comme le LLM le plus puissant actuellement disponible (selon VentureBeat). Dans 10 comparaisons directes face à GPT-5.4 et Gemini 3.1 Pro, Opus 4.7 sort vainqueur sur 7 points, avec une avance particulièrement marquée sur SWE-bench Pro.
Le chiffre le plus frappant est 64,3 % sur SWE-bench Pro : il s'agit du record actuel de l'industrie pour des tâches réelles de génie logiciel. Cela représente une avance de 6,6 points sur GPT-5.4 (57,7 %) et un bond significatif de 10,9 points par rapport à Opus 4.6 (53,4 %). Sur le benchmark d'appel d'outils MCP-Atlas, Opus 4.7 devance GPT-5.4 de 9,2 points, ce qui en fait un choix privilégié pour les scénarios d'IA agentique, tels que les workflows automatisés, les agents de génération de code et les tâches de raisonnement complexe.
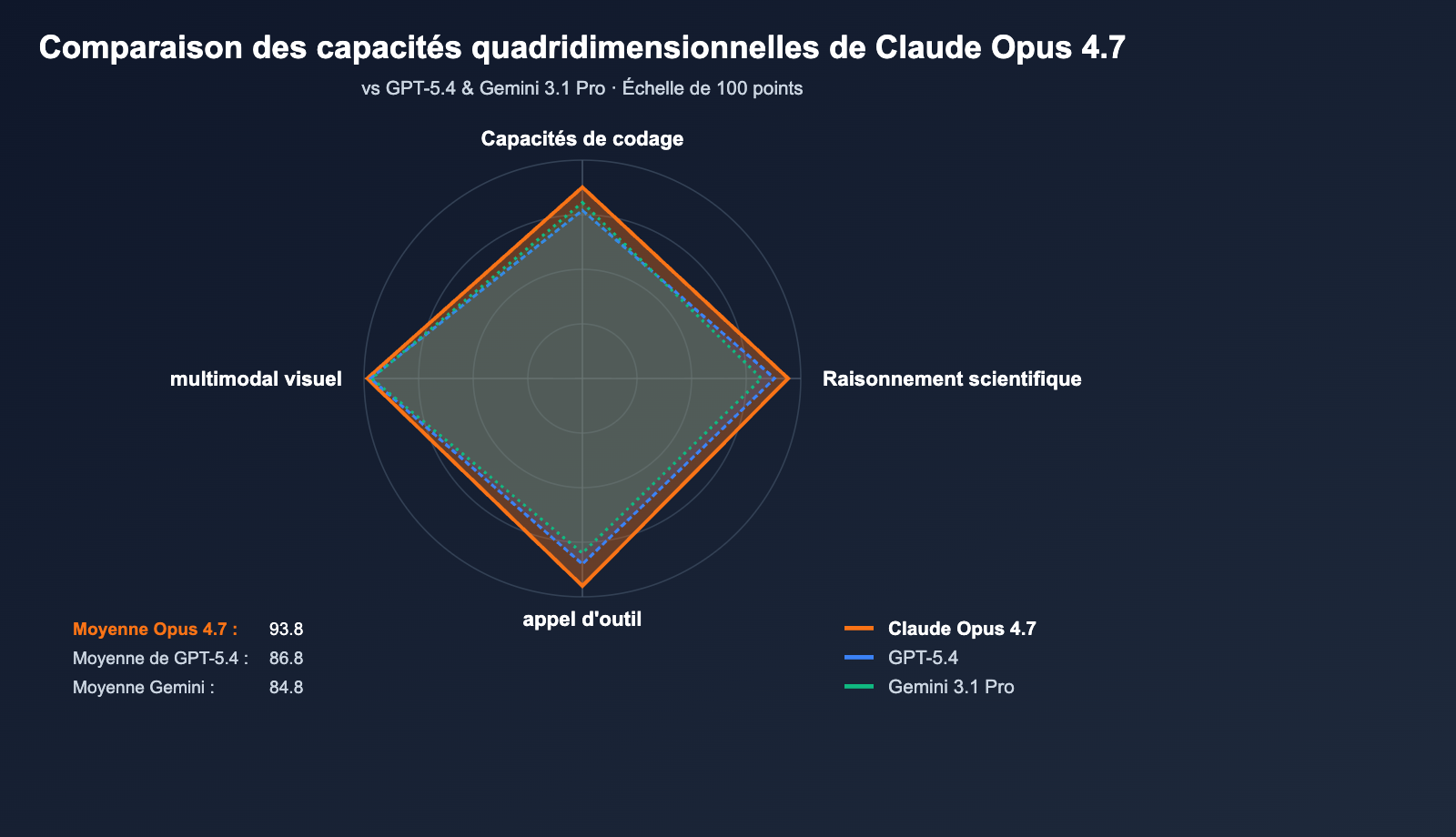
Analyse comparative : Claude Opus 4.7 face à ses prédécesseurs et concurrents
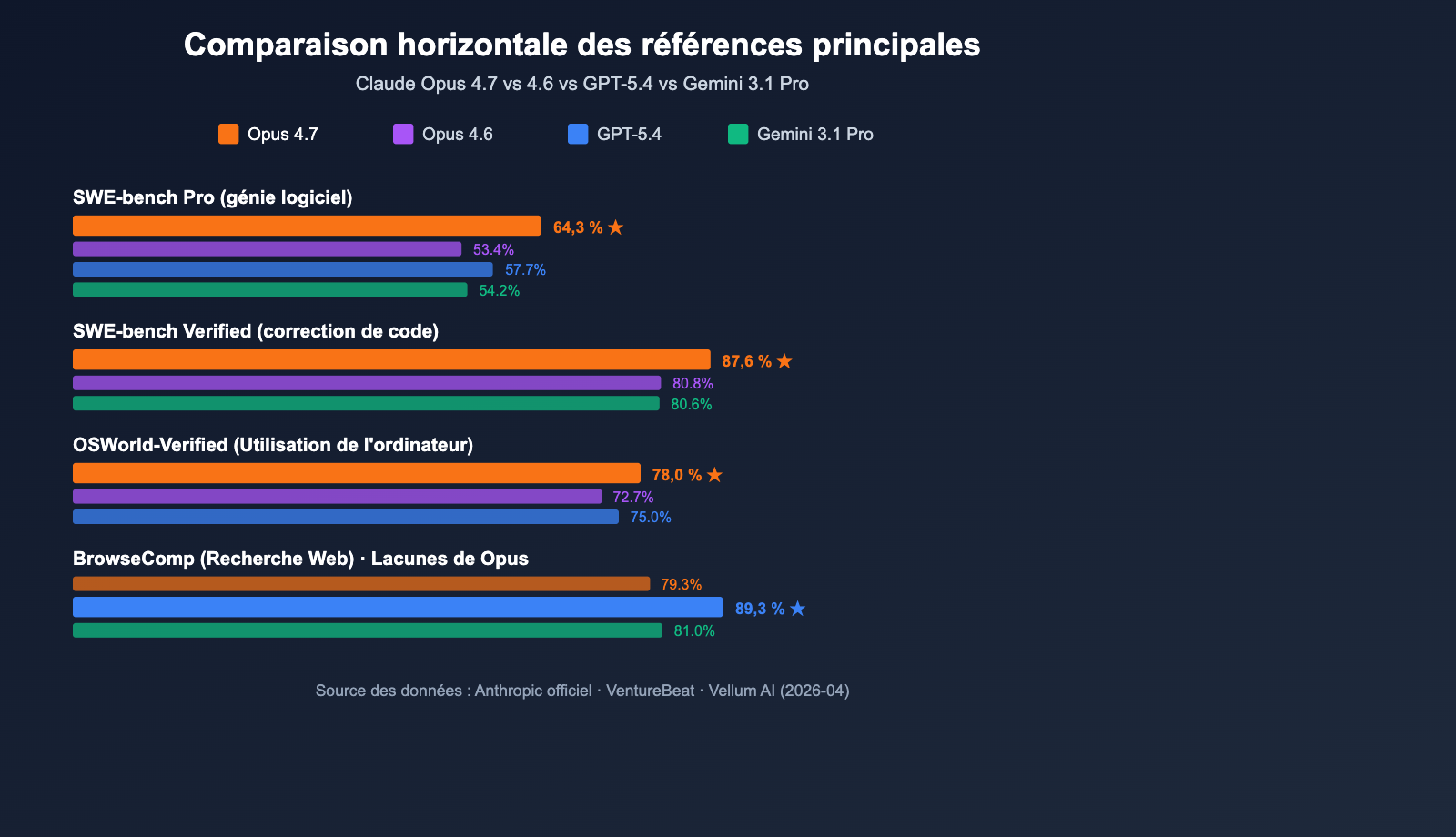
| Dimension | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Date de sortie | 16/04/2026 | Janv. 2026 | Mars 2026 | Févr. 2026 |
| Fenêtre de contexte | 1M tokens (tarif standard) | 200K | 400K | 1M |
| SWE-bench Pro | 64,3 % | 53,4 % | 57,7 % | 54,2 % |
| Agent / invocation du modèle | Le plus puissant | Bon | Puissant | Bon |
| Recherche Web (BrowseComp) | 79,3 % | 72 % | 89,3 % | 81 % |
| Vision multimodal | 98,5 % | 95 % | 97 % | 96,5 % |
| Prix API officiel | 5 $ / 25 $ (entrée/sortie par M tokens) | 5 $ / 25 $ | 4,5 $ / 22 $ | 4 $ / 20 $ |
| Réduction globale APIYI | Recharge 100 $ + 10 % offert ≈ 20 % de remise | Idem | Idem | Idem |
Analyse comparative (Claude Opus 4.7 vs autres modèles)
Claude Opus 4.7 vs GPT-5.4 : GPT-5.4 garde une longueur d'avance sur les scénarios de recherche Web BrowseComp (89,3 % contre 79,3 %). Cependant, il reste en retrait par rapport à Opus 4.7 sur SWE-bench Pro (57,7 %) et l'invocation du modèle (MCP-Atlas). En comparaison, Claude Opus 4.7 excelle dans les agents de programmation, la génération de code et l'exécution de tâches multi-étapes, ce qui le rend idéal pour les workflows de développeurs.
Claude Opus 4.7 vs Gemini 3.1 Pro : Gemini 3.1 Pro domine toujours sur la compréhension de longs textes et les scénarios vidéo multimodaux. Néanmoins, l'écart est notable sur les tests SWE-bench Verified (80,6 % contre 87,6 %) et SWE-bench Pro (54,2 % contre 64,3 %). Claude Opus 4.7 se détache nettement sur les tâches d'ingénierie logicielle, se positionnant comme la référence pour la programmation en environnement de production.
Claude Opus 4.7 vs Opus 4.6 : Opus 4.6 reste un choix stable pour les projets sensibles aux coûts. Toutefois, la version 4.7 marque un bond en avant en termes de capacités de programmation, de raisonnement agentique et de "Computer Use", tout en maintenant des prix API identiques. Pour les équipes traitant des tâches complexes et prolongées, la mise à jour vers la 4.7 est vivement recommandée.
Note sur les données : Les chiffres présentés proviennent des annonces officielles d'Anthropic, de VentureBeat, Vellum AI, Decrypt et d'autres institutions d'évaluation tierces. Vous pouvez vérifier ces performances via la plateforme APIYI apiyi.com.

Démarrage rapide avec Claude Opus 4.7
Exemple minimaliste
Voici la manière la plus simple d'invoquer Claude Opus 4.7 via APIYI, en utilisant l'interface compatible avec OpenAI :
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Écris une fonction Python pour effectuer un parcours en profondeur (in-order) d'un arbre binaire"}]
)
print(response.choices[0].message.content)
Voir le code complet (incluant l’invocation en mode xhigh Effort)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
Appelle Claude Opus 4.7, avec prise en charge du mode xhigh effort
Args:
prompt: Entrée utilisateur
effort_level: Niveau d'effort de raisonnement, au choix "low" / "medium" / "high" / "xhigh"
system_prompt: Invite système
max_tokens: Nombre maximum de jetons en sortie
Returns:
Contenu de la réponse du modèle
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Erreur : {str(e)}"
# Le mode xhigh est recommandé pour les tâches de programmation complexes
result = call_claude_opus_47(
prompt="Conçois et implémente un cache LRU, supportant les opérations get et put en O(1)",
effort_level="xhigh",
system_prompt="Tu es un ingénieur Python senior, produis un code alliant lisibilité et performance"
)
print(result)
Conseil : Obtenez un crédit de test gratuit via APIYI (apiyi.com) pour vérifier rapidement l'efficacité de Claude Opus 4.7 sur vos cas d'usage. La plateforme prend en charge une interface unique compatible OpenAI pour Opus 4.7, GPT-5.4 et Gemini 3.1 Pro, facilitant les comparaisons. Profitez de nos offres de recharge : 100 $ crédités avec bonus dès 10 %, soit une économie équivalente à 20 % sur les tarifs officiels.
Performances réelles et cas d'usage typiques de Claude Opus 4.7
4 scénarios cibles pour Claude Opus 4.7
- 🧑💻 Refactoring de code complexe : Avec 87,6 % au score SWE-bench Verified, il démontre une excellente compréhension du contexte multi-fichiers, idéal pour les architectures de dépôts de 100 000 lignes, les mises à jour de dépendances et le refactoring massif.
- 🤖 Flux de travail d'automatisation Agentique : Lead de 9,2 points sur GPT-5.4 pour les appels d'outils MCP-Atlas, parfait pour créer des agents d'automatisation de navigateur, de RPA ou de raisonnement multi-étapes.
- 🔬 Recherche scientifique et raisonnement : Ses 94,2 % au GPQA Diamond témoignent d'une capacité de raisonnement académique de niveau Master, idéale pour l'assistance à la rédaction scientifique, l'analyse de données et la vérification d'hypothèses.
- 🖥️ Automatisation de bureau (Computer Use) : Leader du secteur avec 78,0 % à OSWorld-Verified, adapté aux tests d'automatisation et manipulations d'interface utilisateur nécessitant la simulation de souris et clavier.
Scénarios déconseillés pour Claude Opus 4.7
- Recherche Web en temps réel : Avec 79,3 % sur BrowseComp, il est nettement distancé par les 89,3 % de GPT-5.4. Pour ces besoins, privilégiez GPT-5.4.
- Appels massifs à faible coût : Avec un prix de 25 $/M de tokens en sortie, nous recommandons Claude Haiku ou GPT-5.4-mini pour les applications de conversation courantes.
- Exigences de latence ultra-faible : La gamme Opus présente une latence de réponse plus élevée que les modèles Sonnet/Haiku ; soyez prudent lors de son utilisation dans des scénarios d'interaction en temps réel.
Estimation des prix et des coûts de Claude Opus 4.7
Tarification officielle vs Coûts globaux avec APIYI
| Élément | Prix officiel (Anthropic) | Prix APIYI (bonus de recharge inclus) |
|---|---|---|
| Jetons d'entrée | 5 $ / million de jetons | Même prix unitaire |
| Jetons de sortie | 25 $ / million de jetons | Même prix unitaire |
| Bonus de recharge | Aucun | 10 % et plus pour 100 $ |
| Remise équivalente globale | Aucune | Environ 20 % (plus le palier est élevé, plus le bonus augmente) |
| Méthodes de paiement | Carte bancaire USD uniquement | CNY, USD, et autres méthodes supportées |
| Devise de facturation | USD | Choix entre RMB / USD |
Note sur les coûts : Le nouveau tokenizer d'Opus 4.7 consomme environ 1 à 1,35 fois plus de jetons que celui de la version 4.6 lors du traitement de texte (selon le type de contenu). Bien que le prix unitaire officiel n'ait pas augmenté, le coût réel de la facture peut grimper de 20 à 30 %. Grâce aux bonus de recharge sur APIYI apiyi.com, vous pouvez compenser ces coûts cachés, rendant le coût d'utilisation réel équivalent, voire inférieur à l'ère de la version 4.6.
FAQ – Questions fréquentes
Q1 : Qu’est-ce que Claude Opus 4.7 ?
Claude Opus 4.7 est le Grand modèle de langage phare publié par Anthropic le 16 avril 2026. Il surpasse GPT-5.4 et Gemini 3.1 Pro sur plusieurs benchmarks, notamment en codage (SWE-bench Verified 87,6 %), en invocation d'outils par agent et en raisonnement scientifique (GPQA Diamond 94,2 %). Par rapport à Opus 4.6, il intègre un nouveau mode de raisonnement approfondi "xhigh effort", sans augmentation de prix officielle.
Q2 : Lequel est le meilleur entre Claude Opus 4.7 et GPT-5.4 ?
Tout dépend du cas d'usage. Opus 4.7 est nettement en tête pour la programmation (SWE-bench Pro 64,3 % contre 57,7 %), l'invocation d'outils (MCP-Atlas +9,2 points) et l'utilisation informatique (Computer Use : 78,0 % contre 75,0 %). En revanche, GPT-5.4 conserve l'avantage sur la recherche Web (BrowseComp 79,3 % contre 89,3 %). Privilégiez Opus 4.7 pour les flux de travail de développement et GPT-5.4 pour la recherche en ligne.
Q3 : Quand Claude Opus 4.7 a-t-il été publié ? Est-il disponible en Chine ?
La date de sortie officielle est le 16 avril 2026. Il est disponible via l'API Claude, Amazon Bedrock, Google Cloud Vertex AI et Microsoft Foundry. Les développeurs en Chine peuvent utiliser le modèle officiel via des plateformes d'agrégation comme APIYI apiyi.com, sans avoir besoin de demander un compte à l'étranger.
Q4 : Pour quels projets concrets Claude Opus 4.7 est-il le plus adapté ?
Il est particulièrement adapté aux scénarios suivants :
- Refactorisation de code complexe : compréhension du contexte entre plusieurs fichiers, migration de dépendances, ajustements d'architecture.
- Automatisation par agents : chaînes d'outils MCP, automatisation de navigateur, processus RPA.
- Recherche et analyse de données : raisonnement de niveau universitaire, vérification d'hypothèses, aide à la rédaction de thèses.
- Automatisation de bureau (Computer Use) : tests d'automatisation d'interface utilisateur, scripts de manipulation GUI.
Q5 : Comment appeler rapidement Claude Opus 4.7 via une API ?
Il est recommandé de passer par une plateforme d'agrégation compatible avec le protocole OpenAI. Trois étapes suffisent :
- Visitez APIYI apiyi.com pour créer un compte et obtenir votre clé API.
- Rechargez 100 $ pour bénéficier d'un bonus d'au moins 10 % (soit environ 20 % de remise globale), ou testez d'abord avec le crédit gratuit.
- Modifiez le
base_urlde votre SDK OpenAI parhttps://vip.apiyi.com/v1et indiquezclaude-opus-4-7comme modèle.
APIYI permet une intégration unifiée de modèles majeurs comme Claude Opus 4.7, GPT-5.4 et Gemini 3.1 Pro, facilitant ainsi les comparaisons et les basculements.
Q6 : Quelles sont les limites connues de Claude Opus 4.7 ?
Les principales limites sont :
- Consommation accrue de jetons : le nouveau tokenizer consomme 1 à 1,35 fois plus de jetons que la version 4.6, ce qui peut augmenter la facture de 20 à 30 %.
- Faiblesse en recherche Web : avec 79,3 % au score BrowseComp, il est en retrait par rapport à GPT-5.4 ; à éviter pour les recherches en temps réel.
- Latence de réponse : la série Opus présente une latence plus élevée que Sonnet/Haiku ; pour les applications de conversation en temps réel, privilégiez un modèle plus léger.
- Prix unitaire officiel élevé : à 5 $/25 $ par million de jetons, il est recommandé d'utiliser les bonus de recharge d'APIYI pour optimiser les coûts lors d'invocations massives.
Q7 : Quelle est la taille de la fenêtre de contexte de Claude Opus 4.7 ?
Claude Opus 4.7 prend en charge une fenêtre de contexte de 1 million (1M) de jetons, avec une tarification standard sans surcoût pour les contextes longs. Cela signifie que vous pouvez traiter en une seule requête un dépôt de code de taille moyenne, un long document technique ou le compte-rendu complet d'une réunion, ce qui équivaut à environ 750 000 caractères chinois ou 200 pages PDF.
Q8 : Qu’est-ce que le mode « xhigh Effort » et quand l’utiliser ?
Le mode "xhigh effort" est le niveau de raisonnement le plus élevé ajouté à Opus 4.7. Le modèle consacre plus de jetons et de temps à une réflexion multi-étapes et à l'auto-vérification. Il est recommandé de l'activer dans les cas suivants :
- Conception d'algorithmes complexes (ex: cache LRU, cohérence distribuée).
- Tâches de refactorisation touchant plusieurs fichiers.
- Raisonnement mathématique nécessitant une chaîne logique complexe.
- Revue de code critique et audit de vulnérabilités.
Pour les conversations quotidiennes ou l'écriture de CRUD simples, utilisez les modes high ou medium pour éviter une consommation inutile de jetons.
Points clés de Claude Opus 4.7
- 🏆 Leader sur 7 classements majeurs : SWE-bench Pro 64,3 %, Verified 87,6 %, GPQA 94,2 %, et une avance de 9,2 points sur GPT-5.4 dans le MCP-Atlas.
- 💡 Mode xhigh Effort : Nouveau mode de raisonnement de haut niveau, idéal pour les algorithmes complexes et la refactorisation multi-fichiers.
- 🚀 Idéal pour les scénarios d'agents : Domine largement en matière d'appel d'outils et d'utilisation informatique (Computer Use), faisant de lui le modèle de choix pour l'IA agentique.
- ⚠️ Lacunes en recherche Web : Un retard de 10 points sur GPT-5.4 dans BrowseComp ; pour les scénarios nécessitant une recherche en ligne, il est conseillé de comparer les modèles.
- 💰 Accès à prix réduit via APIYI : Le tarif officiel reste inchangé, mais en rechargeant via apiyi.com, vous bénéficiez d'un bonus de 10 % dès 100 $ de recharge, soit une réduction globale d'environ 20 %.
Résumé
Les données de benchmark de Claude Opus 4.7 mènent à une conclusion claire : c'est actuellement le modèle généraliste le plus puissant pour la programmation et les scénarios d'agents. Voici les points essentiels :
- Avance majeure en programmation : Avec 64,3 % sur SWE-bench Pro, il surpasse largement GPT-5.4 et Gemini 3.1 Pro, ce qui en fait le premier choix pour les tâches de code en production.
- Roi de l'appel d'outils pour agents : Une avance de 9,2 points sur MCP-Atlas et de 3 points sur le Computer Use, idéal pour les scénarios d'automatisation.
- Attention aux coûts réels : Le nouveau tokenizer entraîne une hausse implicite des coûts de 20 à 30 %, qu'il convient de compenser par les offres de recharge des plateformes agrégatrices.
Si votre travail se concentre sur la programmation par IA, le développement d'agents ou les tâches de raisonnement complexes, Claude Opus 4.7 mérite une adoption immédiate. Nous vous recommandons de l'essayer rapidement via APIYI (apiyi.com) : les modèles officiels y sont disponibles en temps réel, l'interface compatible OpenAI permet un remplacement en un clic, et le bonus de 10 % dès 100 $ de recharge vous permet de profiter d'une réduction de 20 %, tout en évitant les tracas liés aux comptes étrangers et aux paiements en dollars.
延伸阅读 Related Articles
Si le benchmark de Claude Opus 4.7 vous intéresse, nous vous recommandons de poursuivre votre lecture :
- 📘 Guide complet de l'invocation du modèle Claude Opus 4.7 via API – Découvrez l'utilisation complète du mode "High Effort", du "Prompt Caching" et de l'appel d'outils.
- 📊 Comparaison approfondie : GPT-5.4 vs Claude Opus 4.7 vs Gemini 3.1 Pro – Maîtrisez les critères de sélection des trois modèles phares selon les différents scénarios.
- 🚀 Protocole MCP et agents Claude Opus 4.7 en pratique – Explorez comment construire des flux de travail d'agents de niveau production avec Opus 4.7.
📚 Références
-
Annonce officielle d'Anthropic : Présentation du produit Claude Opus 4.7 et données de benchmark
- Lien :
anthropic.com/news/claude-opus-4-7 - Note : Source de données directe, incluant tous les résultats officiels des tests de référence.
- Lien :
-
Évaluation indépendante de VentureBeat : Analyse du retour d'Opus 4.7 à la première place des LLM généralistes
- Lien :
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - Note : Perspective tierce indépendante sur la comparaison globale entre Opus 4.7 et ses concurrents.
- Lien :
-
Analyse des benchmarks par Vellum AI : Décryptage point par point de la méthodologie et de la fiabilité des tests
- Lien :
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Note : Idéal pour les lecteurs techniques souhaitant approfondir les méthodes de tests de référence.
- Lien :
-
Documentation officielle de l'API Claude : Explications sur la fenêtre de contexte, la tarification et le tokenizer
- Lien :
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Note : Référence faisant autorité pour l'intégration et l'invocation, incluant un guide de migration.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter de votre expérience avec Claude Opus 4.7 dans les commentaires. Pour plus de ressources sur l'invocation du modèle, visitez le centre de documentation APIYI sur docs.apiyi.com.