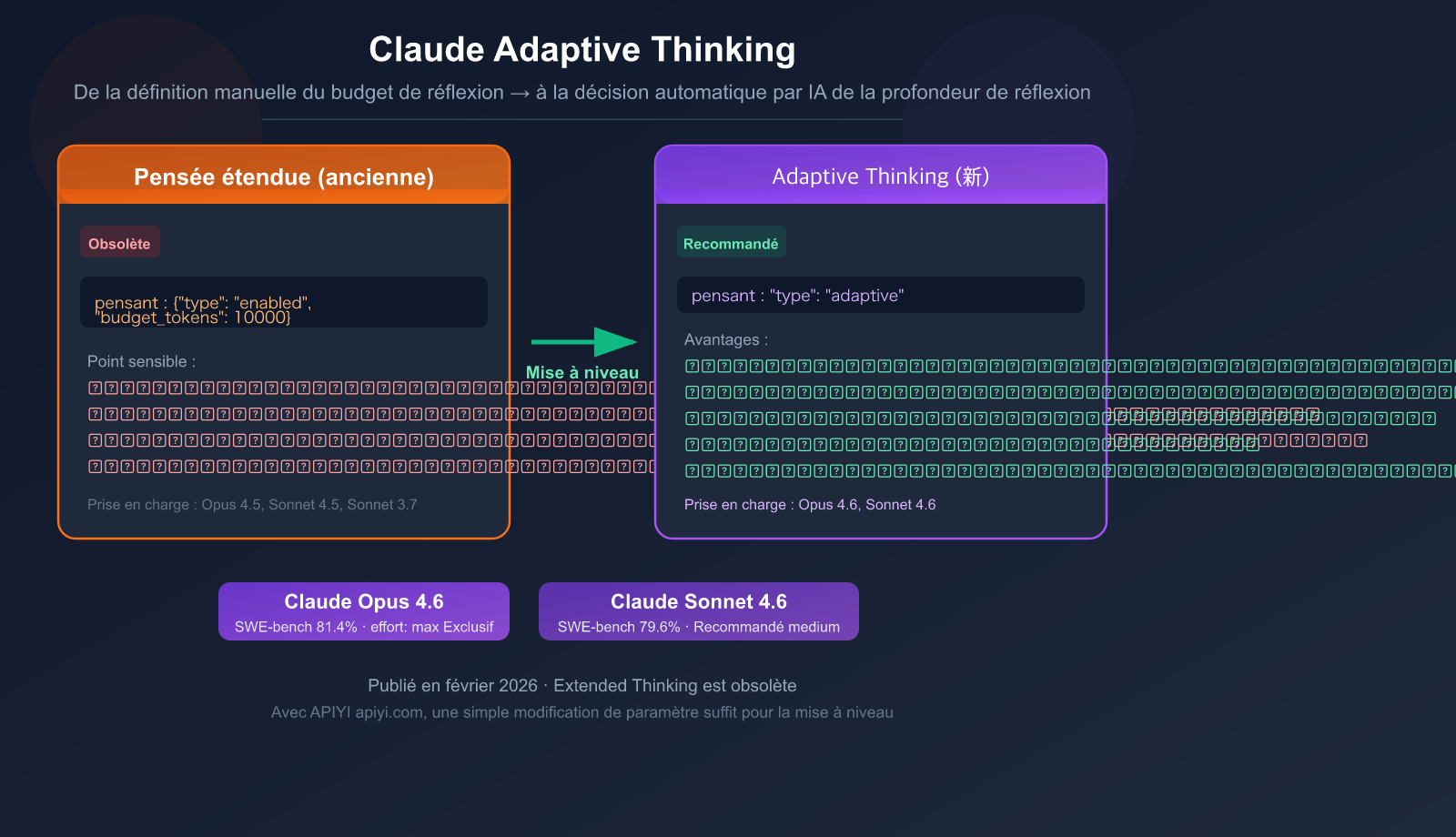
Si vous utilisez le mode Extended Thinking (Pensée étendue) de Claude, attention — il a été marqué comme Deprecated (obsolète) dans Claude 4.6. Il est remplacé par un mode plus intelligent : Adaptive Thinking (Pensée adaptative).
Changement fondamental : auparavant, vous deviez définir manuellement un budget de tokens pour la réflexion (budget_tokens). Désormais, Claude décide lui-même s'il doit réfléchir et à quel niveau de profondeur. Questions simples = réponse instantanée, questions complexes = raisonnement approfondi — le tout avec un seul paramètre.
Valeur clé : en lisant cet article, vous maîtriserez la méthode d'appel API pour Adaptive Thinking, les 4 améliorations majeures, la configuration du paramètre effort et un guide complet pour migrer depuis Extended Thinking.
Qu'est-ce qu'Adaptive Thinking : comprendre en une phrase
Extended Thinking (ancien mode) : Le développeur dit à Claude "Tu as un budget de 10 000 tokens pour réfléchir", et Claude utilise tout ce budget.
Adaptive Thinking (nouveau mode) : Claude évalue lui-même la complexité du problème et décide "s'il a besoin de réfléchir" et "à quel point il doit réfléchir".
# ❌ Ancien mode (Extended Thinking) - Obsolète
thinking={"type": "enabled", "budget_tokens": 10000}
# ✅ Nouveau mode (Adaptive Thinking) - Recommandé
thinking={"type": "adaptive"}
Aperçu rapide des informations clés
| Information | Détails |
|---|---|
| Nom de la fonctionnalité | Adaptive Thinking (Pensée adaptative) |
| Date de sortie | 5 février 2026 (publié avec Claude Opus 4.6) |
| Modèles supportés | Claude Opus 4.6, Claude Sonnet 4.6 |
| Paramètre API | thinking: {"type": "adaptive"} |
| Méthode de contrôle | Paramètre effort (remplace budget_tokens) |
| Statut | Méthode officiellement recommandée (Extended Thinking est obsolète) |
| Pensée entrelacée | Activée automatiquement (pas besoin d'en-tête beta) |
| Claude Code | Support natif, ajustable avec la commande /effort |
🎯 Conseil de migration : Si votre projet utilise encore Extended Thinking (
type: "enabled"), il est recommandé de migrer vers Adaptive Thinking dès que possible. En passant par la plateforme APIYI apiyi.com pour appeler les API de Claude Opus 4.6 ou Sonnet 4.6, il suffit de modifier un seul paramètre pour effectuer la migration.
Pensée adaptative vs Pensée étendue : 4 améliorations majeures

Amélioration 1 : Du "budget fixe" à la "décision dynamique"
C'est le changement le plus fondamental.
Problème de l'ancien mode : Vous deviez deviner une valeur pour budget_tokens. Si elle est trop basse, le raisonnement pour les problèmes complexes est insuffisant ; si elle est trop haute, vous gaspillez des tokens (et de l'argent) sur des problèmes simples.
# Ancien mode : Vous devinez combien de tokens de réflexion ce problème nécessite ?
thinking={"type": "enabled", "budget_tokens": 10000}
# Problème : Les problèmes simples utilisent aussi beaucoup de tokens de réflexion
Nouveau mode : Claude décide automatiquement en fonction de la complexité de chaque requête.
# Nouveau mode : Claude juge par lui-même
thinking={"type": "adaptive"}
# Problème simple : Pas de réflexion ou réflexion légère
# Problème complexe : Raisonnement approfondi
Impact réel : Pour les charges de travail mixtes "parfois simples, parfois complexes" (comme la revue de code – certaines PR ne modifient qu'un texte, d'autres impliquent une refonte de la concurrence), la Pensée Adaptative offre de meilleures performances globales et une meilleure efficacité des coûts qu'un budget fixe.
Amélioration 2 : Pensée entrelacée automatique (Interleaved Thinking)
Dans les flux de travail de type agent (Agentic), Claude doit réfléchir entre plusieurs appels d'outils.
Ancien mode : La pensée entrelacée nécessitait l'ajout manuel d'un en-tête beta, et n'était pas disponible sur Opus 4.5.
Nouveau mode : Lorsque la Pensée Adaptative est utilisée, la pensée entrelacée est activée automatiquement, sans configuration supplémentaire.
Requête utilisateur → Claude réfléchit → Appel de l'outil A → Claude réfléchit à nouveau → Appel de l'outil B → Réponse finale
C'est particulièrement important pour Claude Code et d'autres applications de type agent – l'IA peut "reconsidérer" après chaque appel d'outil, réduisant ainsi significativement les erreurs.
Amélioration 3 : Conversations multi-tours plus flexibles
Ancien mode : Dans une conversation multi-tours, le message assistant du tour précédent devait commencer par un bloc de pensée (thinking block), sinon une erreur survenait. Cela rendait la gestion des conversations complexe.
Nouveau mode : Cette limitation n'existe plus. La Pensée Adaptative est plus flexible dans les conversations multi-tours, car Claude peut choisir de ne pas réfléchir à certains tours.
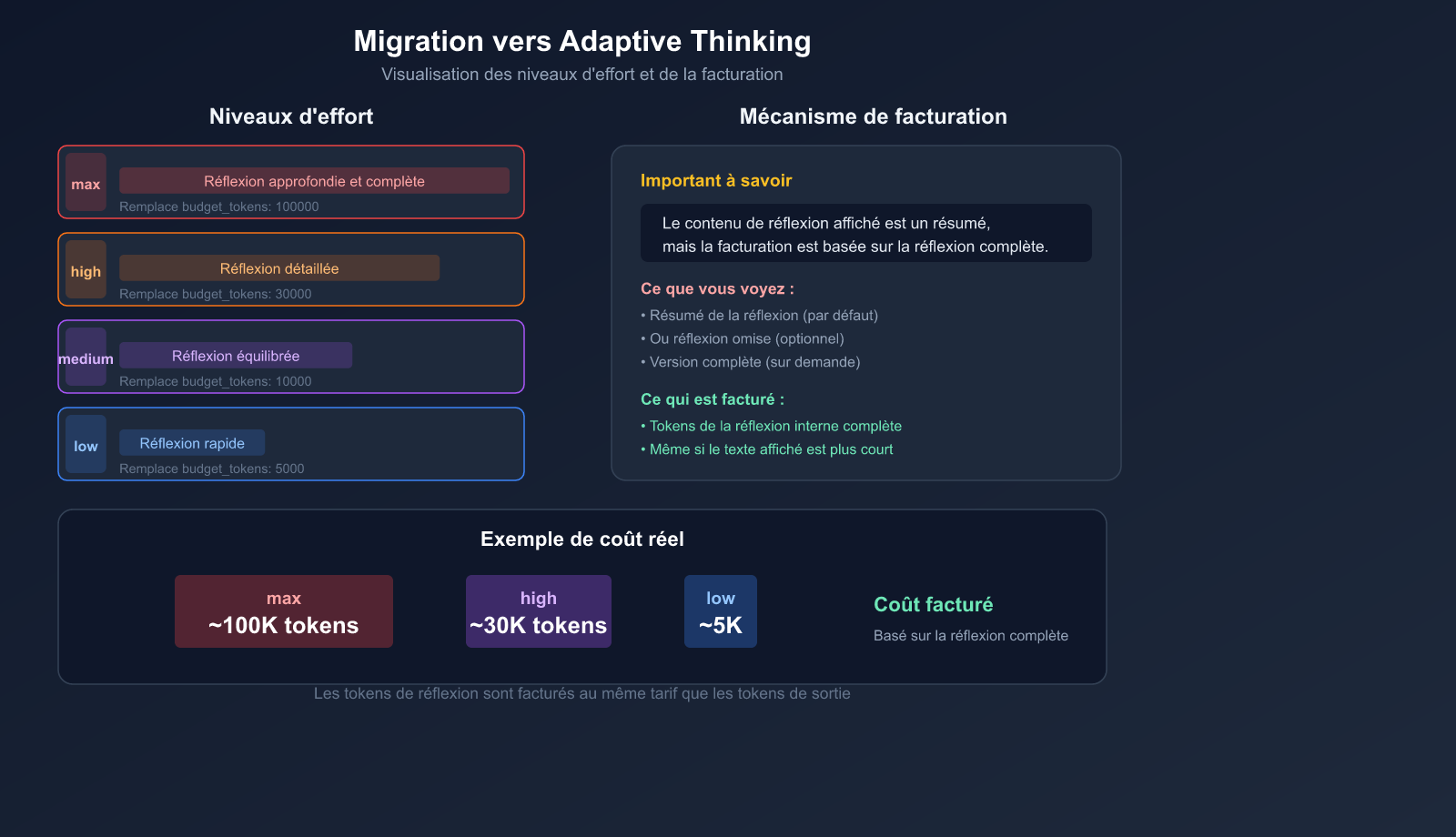
Amélioration 4 : Le paramètre effort remplace budget_tokens
effort est un signal de comportement et non une limite stricte, ce qui le rend plus adapté aux besoins réels que budget_tokens.
| Niveau d'Effort | Comportement | Scénarios d'utilisation | Modèles supportés |
|---|---|---|---|
max |
Toujours une réflexion profonde, sans contrainte | Raisonnement de plus haute difficulté | Opus 4.6 uniquement |
high (par défaut) |
Réfléchit presque toujours, raisonnement approfondi pour les problèmes complexes | Revue de code, conception d'architecture | Opus 4.6, Sonnet 4.6 |
medium |
Réflexion moyenne, peut sauter les problèmes simples | Développement quotidien, tâches générales | Opus 4.6, Sonnet 4.6 |
low |
Minimise la réflexion, priorité à la vitesse | Questions-réponses simples, vérifications de style | Opus 4.6, Sonnet 4.6 |
Important : Même avec un effort low, si le problème est suffisamment complexe, Claude choisira tout de même de réfléchir. L'effort est une suggestion, pas un ordre.
💡 Recommandation pour Sonnet 4.6 : Anthropic recommande officiellement d'utiliser par défaut un
effortmediumavec Sonnet 4.6, pour un meilleur équilibre entre vitesse, coût et qualité. Lors de l'appel via APIYI apiyi.com, il suffit d'ajouter le paramètreoutput_configà la requête.
Guide complet d'invocation d'API
Invocation de base : Adaptive Thinking la plus simple
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Point d'accès unifié APIYI
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "Explique l'impact du GIL de Python sur le multithreading"}
],
max_tokens=16000,
extra_body={
"thinking": {"type": "adaptive"}
}
)
print(response.choices[0].message.content)
Utilisation du SDK natif Anthropic
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com" # Point d'accès unifié APIYI
)
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16000,
thinking={"type": "adaptive"},
messages=[
{"role": "user", "content": "Vérifie ce code pour les conditions de concurrence..."}
]
)
# Analyse de la réponse : peut contenir un bloc thinking et un bloc text
for block in response.content:
if block.type == "thinking":
print(f"[Processus de réflexion] {block.thinking}")
elif block.type == "text":
print(f"[Répone] {block.text}")
Contrôle fin avec le paramètre effort
# Exemple avec le SDK Anthropic
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=16000,
thinking={"type": "adaptive"},
output_config={"effort": "medium"}, # Profondeur de réflexion moyenne
messages=[
{"role": "user", "content": "Quel est le problème avec ce code ?"}
]
)
Omettre le contenu de la réflexion pour réduire la latence
Si vous n'avez pas besoin de voir le processus de réflexion, vous pouvez utiliser display: "omitted" pour réduire la latence de transmission :
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16000,
thinking={
"type": "adaptive",
"display": "omitted" # Ne renvoie pas le texte de réflexion
},
messages=[...]
)
# Remarque : Les tokens de réflexion seront toujours facturés
Voir l’exemple complet de flux de travail pour la revue de code
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com"
)
def review_pr(diff_content, risk_level="medium"):
"""Revue de code adaptative en fonction du niveau de risque"""
# Risque élevé : Opus + high effort
# Risque faible : Sonnet + medium effort
if risk_level == "high":
model = "claude-opus-4-6"
effort = "high"
else:
model = "claude-sonnet-4-6"
effort = "medium"
response = client.messages.create(
model=model,
max_tokens=16000,
thinking={"type": "adaptive"},
output_config={"effort": effort},
system="""Vous êtes un expert senior en revue de code.
Analysez les modifications de code et classez-les par niveau de gravité :
🔴 Doit être corrigé (sécurité/logique)
🟡 Correction recommandée (qualité)
💡 Suggestion d'amélioration""",
messages=[
{"role": "user", "content": f"Revue :\n\n{diff_content}"}
]
)
thinking_text = ""
review_text = ""
for block in response.content:
if block.type == "thinking":
thinking_text = block.thinking
elif block.type == "text":
review_text = block.text
return {
"thinking": thinking_text,
"review": review_text,
"model": model,
"effort": effort,
"input_tokens": response.usage.input_tokens,
"output_tokens": response.usage.output_tokens
}
🚀 Démarrage rapide : Pour invoquer l'API Claude 4.6 via APIYI apiyi.com, il suffit d'ajouter
thinking: {"type": "adaptive"}à votre requête pour activer la réflexion adaptative. Aucune configuration supplémentaire n'est nécessaire, une seule ligne de code améliore les capacités de raisonnement de votre IA.
Paramètre Effort en pratique : configurations optimales pour différents scénarios
Guide de configuration par scénario
| Scénario | Modèle recommandé | Effort | Raison |
|---|---|---|---|
| Questions simples / Traduction | Sonnet 4.6 | low |
Pas besoin de raisonnement profond, priorité à la vitesse |
| Complétion de code / Formatage | Sonnet 4.6 | low |
Tâche de correspondance de motifs, pas besoin de réflexion |
| Revue de PR quotidienne | Sonnet 4.6 | medium |
Équilibre entre vitesse et profondeur d'analyse |
| Débogage de bug complexe | Opus 4.6 | high |
Nécessite un raisonnement transversal aux fichiers |
| Audit de vulnérabilité de sécurité | Opus 4.6 | high |
Ne doit pas manquer les problèmes à haut risque |
| Preuve mathématique / logique | Opus 4.6 | max |
Nécessite une profondeur de raisonnement extrême |
| Conception de solution d'architecture | Opus 4.6 | max |
Nécessite une considération complète des compromis |
Utilisation de effort dans Claude Code
Après la mise à jour de mars 2026, Claude Code a ajouté la commande /effort :
# Définir directement dans le terminal Claude Code
/effort medium # Codage quotidien
/effort high # Revues de code
/effort max # Conception d'architecture (uniquement Opus 4.6)
Cela permet aux développeurs d'ajuster la profondeur de réflexion de Claude en fonction de la tâche actuelle, sans modifier le code.
💰 Optimisation des coûts : Le paramètre
effortaffecte directement la consommation de tokens. Pour les tâches de codage quotidiennes, régler Sonnet 4.6 surmediumoulowpeut réduire significativement les coûts. L'invocation via la plateforme APIYI apiyi.com est plus avantageuse que le prix officiel, permettant des économies doublées en combinant avec le paramètreeffort.
Migration d'Extended Thinking vers Adaptive Thinking
Tableau de correspondance pour la migration
| Ancienne syntaxe (Extended Thinking) | Nouvelle syntaxe (Adaptive Thinking) |
|---|---|
thinking: {"type": "enabled", "budget_tokens": 5000} |
thinking: {"type": "adaptive"}, output_config: {"effort": "low"} |
thinking: {"type": "enabled", "budget_tokens": 10000} |
thinking: {"type": "adaptive"}, output_config: {"effort": "medium"} |
thinking: {"type": "enabled", "budget_tokens": 30000} |
thinking: {"type": "adaptive"}, output_config: {"effort": "high"} |
thinking: {"type": "enabled", "budget_tokens": 100000} |
thinking: {"type": "adaptive"}, output_config: {"effort": "max"} |
Ajout manuel de l'en-tête interleaved thinking beta |
Activé automatiquement, aucun en-tête requis |
Points d'attention pour la migration
1. Interruption du cache des invites
Lorsque vous passez du mode enabled au mode adaptive, les points d'arrêt du cache d'invites au niveau des messages deviennent invalides. Le cache des définitions système et des outils n'est pas affecté.
Recommandation : Migrez toutes vos requêtes vers le mode adaptive en une seule fois, plutôt que de les mélanger.
2. Le contenu de la réflexion est résumé par défaut
Le modèle Claude 4.6 retourne par défaut une version résumée du contenu de réflexion, et non le texte complet. Cela signifie que le bloc de réflexion que vous voyez est une version simplifiée.
- Version résumée (
display: "summarized") : Comportement par défaut - Version omise (
display: "omitted") : Ne retourne pas le texte de réflexion - Version complète : Nécessite de contacter l'équipe commerciale d'Anthropic pour l'activer
3. La facturation se base sur la réflexion complète
Que vous voyiez un résumé ou que le contenu soit omis, la facturation est basée sur le nombre de tokens de la réflexion interne complète. Ne pensez pas que le coût est moindre parce que le texte affiché est plus court.
4. Le pré-remplissage n'est plus pris en charge
Claude Opus 4.6 ne prend plus en charge le pré-remplissage des messages de l'assistant (prefill) – l'envoi d'un pré-remplissage retournera une erreur 400. Si vous avez besoin de contrôler le format de sortie, utilisez l'invite système ou les sorties structurées.
🎯 Conseil de migration : Il est recommandé de valider d'abord l'effet de la migration dans un environnement de test, en comparant notamment la différence de qualité de sortie entre le mode adaptive et les anciens
budget_tokensfixes. Grâce à APIYI apiyi.com, vous pouvez facilement effectuer des tests A/B – un même appel avec des configurations différentes.
Détails du mécanisme de facturation
Comment les tokens de réflexion sont facturés
Comprendre le mécanisme de facturation est essentiel pour contrôler les coûts.
| Élément facturable | Explication |
|---|---|
| Tokens d'entrée | Facturés normalement ($5/MTok pour Opus, $3/MTok pour Sonnet) |
| Tokens de réflexion | Facturés au prix des tokens de sortie ($25/MTok pour Opus, $15/MTok pour Sonnet) |
| Tokens de réponse textuelle | Facturés au prix des tokens de sortie |
| Tokens de génération de résumé | Non facturés en supplément |
| display: "omitted" | Les tokens de réflexion sont toujours facturés, ils ne sont simplement pas transmis |
Stratégies d'optimisation des coûts
Questions simples avec low effort → La réflexion peut être ignorée → Économie importante de tokens de sortie
↓
Coût réduit de 50-80%
Exemple pratique : Une même tâche de vérification de style de code
| Configuration | Tokens de réflexion | Tokens de réponse | Coût total (Sonnet) |
|---|---|---|---|
| effort: high | ~3000 | ~500 | ~$0.053 |
| effort: medium | ~800 | ~500 | ~$0.020 |
| effort: low | 0 (réflexion ignorée) | ~500 | ~$0.009 |
Pour des tâches simples, l'effort low est environ 83% moins cher que l'effort high.
💰 Astuce d'économie : Pour les scénarios de traitement par lots (par exemple, vérifier le style de 100 fichiers), définir l'effort sur
lowpermet de réaliser d'importantes économies. En utilisant l'API Claude 4.6 via APIYI apiyi.com, vous bénéficiez déjà de prix avantageux, et l'optimisation du paramètreeffortpermet une réduction de coût supplémentaire.
Questions fréquentes
Q1 : Peut-on mélanger Adaptive Thinking et Extended Thinking ?
Oui, mais ce n'est pas recommandé. Sur le modèle Claude 4.6, Extended Thinking (type: "enabled") est toujours disponible mais marqué comme Déprécié et sera supprimé dans les futures versions. Le mélange des deux modes peut également entraîner l'invalidation des points d'arrêt du cache d'invite. Il est conseillé de migrer uniformément vers Adaptive Thinking dès que possible. Le format des paramètres est entièrement compatible lors de l'appel via APIYI apiyi.com.
Q2 : Opus 4.5 prend-il en charge Adaptive Thinking ?
Non. Adaptive Thinking est uniquement pris en charge par Claude Opus 4.6 et Sonnet 4.6. Opus 4.5 nécessite toujours d'utiliser le mode type: "enabled" et de définir manuellement budget_tokens. Si vous avez besoin d'utiliser Adaptive Thinking, il est recommandé de passer aux modèles de la série 4.6. APIYI apiyi.com propose l'accès API à l'ensemble de la gamme des modèles 4.5 et 4.6.
Q3 : display: « omitted » permet-il vraiment d’économiser de l’argent ?
Non, cela n'économise pas d'argent. display: "omitted" permet simplement à l'API de ne pas renvoyer le texte de réflexion, réduisant ainsi la latence de transmission réseau. Cependant, les tokens de réflexion internes sont toujours générés et facturés. La véritable méthode pour économiser est de réduire le niveau d'effort (low ou medium) — cela amène Claude à ignorer ou réduire la réflexion sur des problèmes simples.
Q4 : Comment savoir si Claude a réfléchi lors d’une requête spécifique ?
Vérifiez si la réponse contient un bloc de contenu de type thinking. Si Claude estime qu'une réflexion n'est pas nécessaire, la réponse ne contiendra qu'un bloc text, sans bloc thinking. En mode Adaptive, le décompte des tokens dans le champ usage peut vous aider à déterminer combien de tokens ont été consommés par la réflexion.
Q5 : Comment utiliser Adaptive Thinking dans Claude Code ?
Claude Code utilise Adaptive Thinking par défaut lorsqu'il emploie Opus 4.6 ou Sonnet 4.6. Vous pouvez ajuster la profondeur de réflexion avec la commande /effort : /effort low (mode rapide), /effort medium (mode équilibré), /effort high (mode approfondi). La mise à jour de mars 2026 a également corrigé l'erreur "adaptive thinking is not supported" causée par des chaînes de modèle non standard.
Résumé : Adaptive Thinking est la mise à niveau centrale de Claude 4.6
Adaptive Thinking représente une évolution importante du mode de raisonnement de l'IA : elle passe de "le développeur devine combien l'IA doit réfléchir" à "l'IA décide elle-même combien elle doit réfléchir".
4 mises à niveau centrales :
- Décision dynamique : Réponses instantanées pour les questions simples, raisonnement approfondi pour les problèmes complexes
- Pensée entrelacée automatique : Raisonnement automatique entre les appels d'outils dans les flux de travail de type agent
- Conversation flexible en plusieurs tours : Pas besoin de commencer par un bloc de réflexion forcé
- Paramètre
effort: Une manière plus intuitive de contrôler la profondeur quebudget_tokens
Recommandation de migration : Passez de thinking: {"type": "enabled", "budget_tokens": N} à thinking: {"type": "adaptive"}, en utilisant output_config: {"effort": "..."} pour contrôler la profondeur.
Nous recommandons d'utiliser APIYI apiyi.com pour accéder rapidement aux API de Claude Opus 4.6 et Sonnet 4.6. Un simple changement de paramètre vous permet de bénéficier du raisonnement intelligent et de l'optimisation des coûts apportés par Adaptive Thinking.
Références
-
Documentation de l'API Claude – Adaptive Thinking : Guide technique officiel
- Lien :
platform.claude.com/docs/en/build-with-claude/adaptive-thinking
- Lien :
-
Documentation de l'API Claude – Paramètre Effort : Explication détaillée de la configuration
effort- Lien :
platform.claude.com/docs/en/build-with-claude/effort
- Lien :
-
Anthropic officiel – Claude Opus 4.6 : Annonce de publication
- Lien :
anthropic.com/news/claude-opus-4-6
- Lien :
-
Documentation de l'API Claude – Extended Thinking : Guide de la réflexion étendue précédente
- Lien :
platform.claude.com/docs/en/build-with-claude/extended-thinking
- Lien :
Auteur : Équipe APIYI | Pour maîtriser les dernières capacités de l'API Claude, visitez APIYI apiyi.com pour obtenir les interfaces API et le support technique de la gamme complète des modèles Claude 4.6.