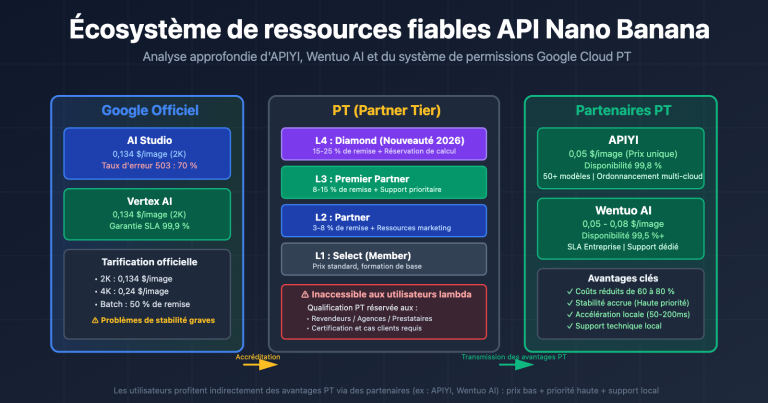
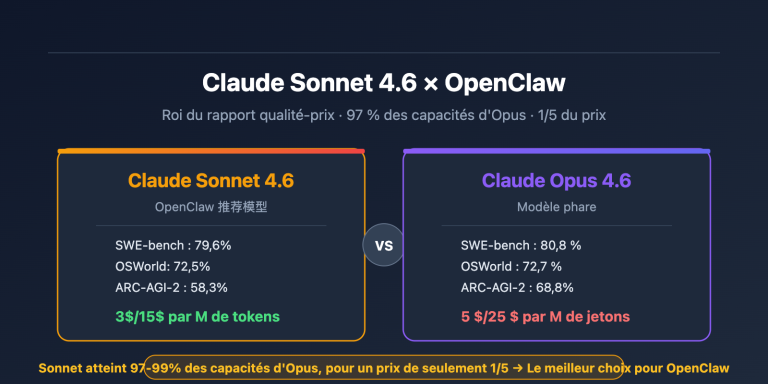
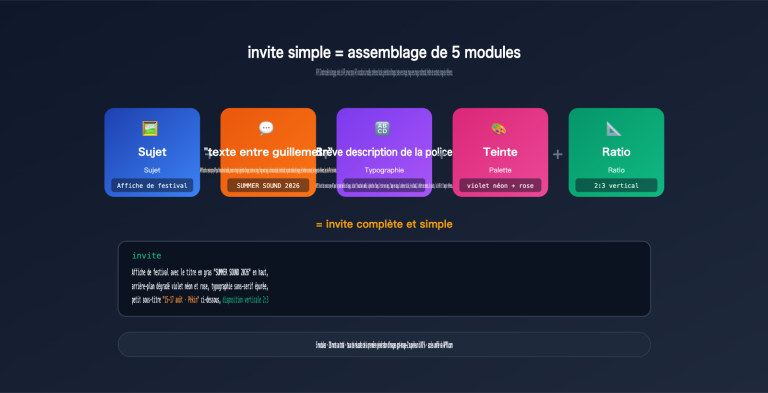
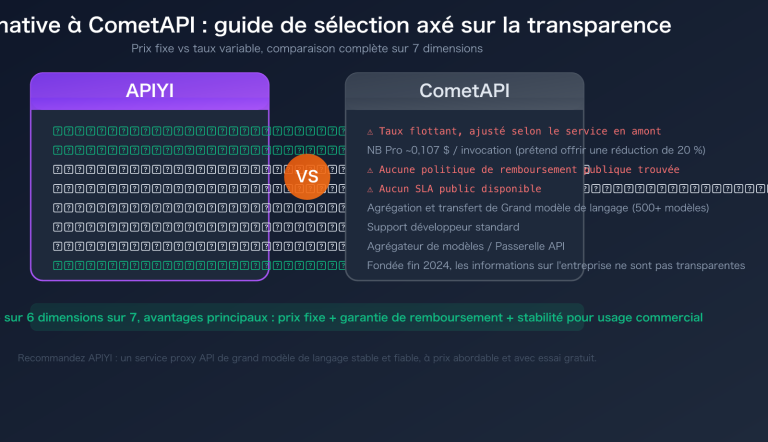
Lorsque vous devez traiter des dizaines de milliers de descriptions de produits, d'étiquetages de données, de modérations de contenu ou de tâches de vectorisation en une nuit, les appels API synchrones standards sont à la fois lents et coûteux. OpenAI /v1/batches et le mode Batch de Google Gemini apportent la même réponse : téléchargez un fichier JSONL, obtenez tous les résultats de manière asynchrone dans les 24 heures, et bénéficiez d'une réduction directe de 50 %.
Cependant, dans la pratique, les plateformes de transfert (agrégateurs d'API) ne prennent généralement pas en charge les appels directs /v1/batches, car leur modèle de facturation est incompatible avec le mécanisme de règlement asynchrone des jetons (tokens) des interfaces de traitement par lots officielles. Cela signifie que si vous souhaitez profiter de la réduction officielle de 50 % et de la haute concurrence pour des milliards de jetons, vous devez utiliser un compte officiel + une clé API officielle. Pour les développeurs, le moyen le plus simple est de passer par un service de recharge d'API officiel professionnel — adresse de commande : api-sparkle-charge.lovable.app, ou visitez AI 代充网 : ai.daishengji.com pour consulter la grille tarifaire complète.
Cet article, basé sur la documentation officielle en anglais d'OpenAI et de Google AI, synthétise les spécifications techniques, les mécanismes de facturation et la mise en œuvre pratique des deux API de traitement par lots, tout en proposant un guide de choix scénarisé pour les services de recharge.

Valeur fondamentale de l'API de traitement par lots : pourquoi ouvrir un compte officiel
L'API de traitement par lots (Batch API) est une interface dédiée conçue par OpenAI et Google pour les scénarios à gros volume et non temps réel. Sa logique d'échange fondamentale est la suivante : vous renoncez à la certitude d'une réponse en temps réel en échange d'une réduction de prix de 50 % et de limites de débit plus élevées.
Différences essentielles entre l'API synchrone et le traitement par lots
Le tableau ci-dessous compare les paramètres clés des deux modes d'appel :
| Dimension | API synchrone | API de traitement par lots |
|---|---|---|
| Latence de réponse | Niveau seconde | Jusqu'à 24 heures |
| Prix par jeton | Prix standard | 50 % de réduction (-50 %) |
| Limite par requête | 1 élément | 50 000 éléments (OpenAI) / 2 Go JSONL (Gemini) |
| Limite de débit | RPM/TPM strict | Quota indépendant plus élevé |
| Nouvelle tentative | Gérée par l'appelant | Réessai automatique au niveau de l'interface |
| Cache d'invite | Fenêtre de 5-10 minutes | Partage de l'invite système dans le lot pour économiser |
💡 Conseil d'intégration : L'API de traitement par lots doit être appelée à l'aide d'un compte et d'une clé officiels ; les plateformes d'agrégation ne peuvent pas transmettre les tâches asynchrones
/v1/batches. Nous vous recommandons de passer commande directement via le service de recharge officiel api-sparkle-charge.lovable.app pour obtenir immédiatement la remise de 50 % sur le traitement par lots, et d'utiliser les capacités de règlement multidevises de AI 代充网 (ai.daishengji.com) pour recharger votre compte en une minute.
Quels scénarios sont les plus adaptés au traitement par lots ?
Selon la documentation officielle et les pratiques des développeurs de premier plan, les scénarios suivants permettent les économies les plus significatives :
- Étiquetage/Classification de données : 100 000 analyses de sentiment de commentaires, coûtent ~500 $ en appel synchrone, contre ~250 $ en traitement par lots.
- Génération de descriptions de produits : Expansion massive de références e-commerce (SKU), généralement traitée par lots pendant la nuit.
- Résumé/Vectorisation de documents : Traitement de bases de connaissances à grande échelle.
- Évaluation de modèles (eval) : Exécution de jeux de tests, insensible au temps de réponse.
- Modération de contenu : Filtrage massif de contenus générés par les utilisateurs (UGC).
- Génération par lots d'embeddings : Construction de bases de données vectorielles.
Spécifications techniques de l'API Batch d'OpenAI (/v1/batches)
Le point de terminaison /v1/batches d'OpenAI est devenu une référence du secteur depuis son lancement en 2024. Sa philosophie de conception repose sur la réutilisation intégrale du corps de requête des interfaces synchrones, ce qui rend la migration vers le traitement par lots extrêmement simple pour les développeurs.
Contraintes et quotas principaux
| Élément | Valeur | Remarques |
|---|---|---|
| Fenêtre d'exécution | 24 heures | Actuellement limité à 24h |
| Limite par lot | 50 000 requêtes | Au-delà, divisez en plusieurs lots |
| Taille max. du fichier | 200 Mo | Basé sur du JSONL encodé en UTF-8 |
| Points de terminaison | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
Hors images/audio |
| Réduction tarifaire | -50% | 50 % de remise sur tous les modèles pris en charge |
| Quota de débit | Indépendant | N'impacte pas le TPM synchrone |
Exemple de format de fichier JSONL
OpenAI exige que chaque ligne du fichier téléchargé soit un objet JSON distinct, contenant quatre champs : custom_id, method, url et body :
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Vous êtes un expert en classification de produits"}, {"role": "user", "content": "iPhone 17 Pro 256 Go"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Vous êtes un expert en classification de produits"}, {"role": "user", "content": "Sony WH-1000XM6"}]}}
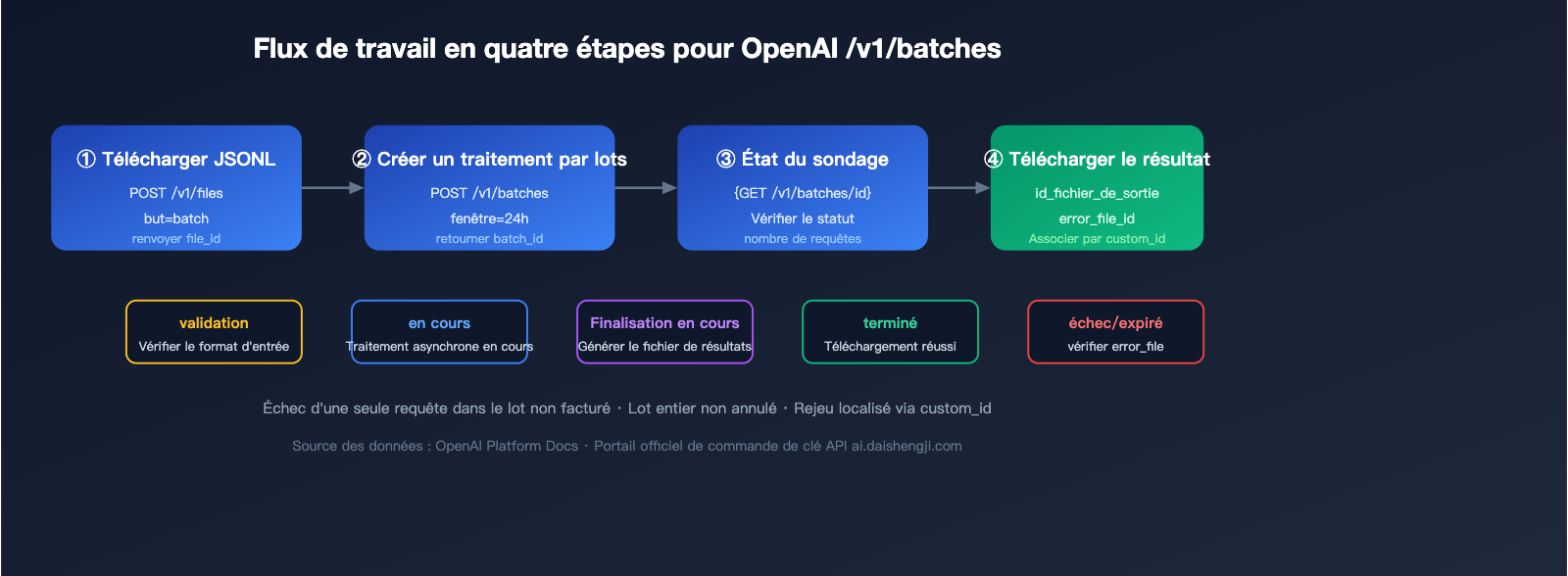
Quatre étapes pour effectuer un appel de traitement par lots OpenAI
Étape 1 : Télécharger le fichier JSONL
from openai import OpenAI
client = OpenAI(api_key="sk-clé-officielle") # Clé officielle obtenue via un service de recharge
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
Étape 2 : Créer la tâche de traitement par lots
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
Étape 3 : Interroger le statut
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
Étape 4 : Télécharger les résultats
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)
🎯 Conseils pour la clé API : Le traitement par lots d'OpenAI nécessite obligatoirement une clé officielle native
sk-*. Les clés de services proxy (hub-*ousk-proxy-*) ne permettent pas d'appeler/v1/batches. Pour obtenir rapidement un quota officiel, vous pouvez passer par un service de recharge : api-sparkle-charge.lovable.app prend en charge les recharges pour les comptes officiels OpenAI/Anthropic/Google avec un délai de 5 à 30 minutes, ou consultez ai.daishengji.com pour découvrir différentes offres promotionnelles.
Spécifications techniques du mode Batch de Gemini
Le mode Batch de Gemini, lancé par Google en 2025, suit une approche similaire à celle d'OpenAI, mais se montre plus audacieux sur deux points : la taille des fichiers et l'adaptation aux modèles.
Contraintes et quotas principaux
| Élément | Valeur | Remarques |
|---|---|---|
| Fenêtre de traitement | Jusqu'à 24 heures | Pas de SLA strict |
| Taille max. par fichier | 2 Go | Environ 10 fois celle d'OpenAI |
| Modèles pris en charge | gemini-2.5-pro / flash / flash-lite | Inclut Gemini 3 Pro Image |
| Réduction tarifaire | -50% | 50% de remise sur les tokens d'entrée et de sortie |
| Points de terminaison | generateContent / embedContent |
Identiques à l'interface synchrone |
| Version Vertex AI | Déploiement régional pris en charge | Scénarios de conformité en entreprise |
Exemple de format JSONL pour Gemini
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "Rédige un argumentaire de vente de 30 mots pour ce produit : iPhone 17 Pro 256 Go"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "Rédige un argumentaire de vente de 30 mots pour ce produit : Sony WH-1000XM6"}]}]}}
Exemple d'invocation de batch Gemini
from google import genai
client = genai.Client(api_key="AIza-clé-officielle")
# Téléchargement du fichier
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# Création du travail de traitement par lots
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# Récupération des résultats
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Conseil pour le rechargement Gemini : La capacité de traitement par lots de Gemini n'est disponible que pour les comptes payants natifs de Google AI Studio ou Vertex AI ; elle n'est pas accessible avec les quotas gratuits. Si vous ne pouvez pas lier une carte bancaire internationale dans votre région, vous pouvez utiliser le canal de recharge officiel Gemini sur ai.daishengji.com pour activer rapidement votre quota payant, ou passer commande directement sur api-sparkle-charge.lovable.app.
Comparaison et prise de décision : API Batch OpenAI vs Gemini
Lors du choix d'une solution pour un projet, les développeurs hésitent souvent entre les deux. Le tableau suivant compare les dimensions clés :
| Critère | OpenAI Batch | Gemini Batch | Scénario recommandé |
|---|---|---|---|
| Limite de requêtes par lot | 50 000 | 2 Go JSONL (~100k+) | Gemini pour les très gros volumes |
| Taille max. par fichier | 200 Mo | 2 Go | Gemini pour les très gros volumes |
| Qualité de réponse (FR) | Série gpt-4o/4.1 robuste | gemini-2.5-pro équilibré | GPT pour le raisonnement complexe |
| Support multimodal | Texte/Embeddings | Texte/Génération d'images | Gemini pour les images en masse |
| Réutilisation du cache | prompt caching | implicit context caching | OpenAI pour les systèmes à prompts fixes |
| Complexité de facturation | Simple et claire | Distinction par niveau de modèle | OpenAI pour l'audit financier |
| Maturité de la doc | Très mature | En évolution constante | OpenAI pour une mise en œuvre rapide |

Conseils de sélection par scénario
- Traitement par lots d'e-commerce (SKU) : gpt-4o-mini Batch, le meilleur rapport qualité-prix.
- Contenu mixte texte-image multimodal : Gemini 2.5 Pro Batch, pour un pipeline unifié.
- Construction d'embeddings à grande échelle : OpenAI text-embedding-3-small Batch.
- Conformité entreprise multi-régions : Vertex AI Gemini Batch.
Optimisation approfondie de la réutilisation et de la mise en cache des invites système
Les utilisateurs demandent souvent : "Si chaque requête dans un traitement par lots (batch) contient la même invite système, est-il possible de ne payer qu'une seule fois ?" C'est une question fréquente mais souvent mal comprise.
La vérité sur la facturation des invites dans les traitements par lots d'OpenAI
L'API /v1/batches d'OpenAI ne déduplique pas automatiquement les invites système identiques. Cependant, combinée au mécanisme de Prompt Caching, lorsque le préfixe de la conversation est identique au sein d'un lot, les jetons d'entrée mis en cache (Cached input tokens) bénéficient d'une réduction supplémentaire de 50 %. En cumulant cela avec la réduction de 50 % du traitement par lots, on peut atteindre une réduction théorique allant jusqu'à 75 %.
Conditions d'application :
- Le préfixe du corps de la requête doit être strictement identique (y compris les rôles, les définitions d'outils et le texte).
- La longueur du préfixe doit être ≥ 1024 jetons (512 jetons pour certains modèles).
- Le seuil de mise en cache doit être atteint dans une fenêtre de 24 heures.
La mise en cache implicite du contexte chez Gemini
Le mode Batch de Gemini prend nativement en charge la mise en cache implicite du contexte (Implicit Context Caching). Lorsque le préfixe d'une requête est répété, le système crée automatiquement un cache sans gestion manuelle de cached_content. La partie correspondant au cache est facturée au tarif de mise en cache de Gemini (environ 25 % du prix initial), auquel s'ajoute la réduction de 50 % du mode Batch, permettant d'atteindre jusqu'à 87,5 % d'économie.
Estimation des coûts : Traitement par lots + Mise en cache
Supposons 100 000 requêtes, chacune partageant 2000 jetons d'invite système + 500 jetons d'entrée utilisateur + 300 jetons de sortie :
| Solution | Coût par requête | Coût total estimé | Économies |
|---|---|---|---|
| Appel synchrone (sans cache) | 0,0028 $ | 280 $ | Base |
| Synchrone + Prompt Caching | 0,0018 $ | 180 $ | -36 % |
| Traitement par lots (50 % off) | 0,0014 $ | 140 $ | -50 % |
| Batch + Caching | 0,0009 $ | 90 $ | -68 % |
⚡ Conseil pour économiser : Lorsque vous combinez la même invite système, le même modèle et des tâches nocturnes, utilisez impérativement la combinaison "Traitement par lots + Prompt Caching". Pour activer ces optimisations sur un compte officiel, vérifiez votre stratégie de facturation. Lors d'une commande via le service de recharge api-sparkle-charge.lovable.app, vous pouvez ajouter une note "Besoin d'activer la remise batch + cache", et le système vous attribuera automatiquement le meilleur tarif.
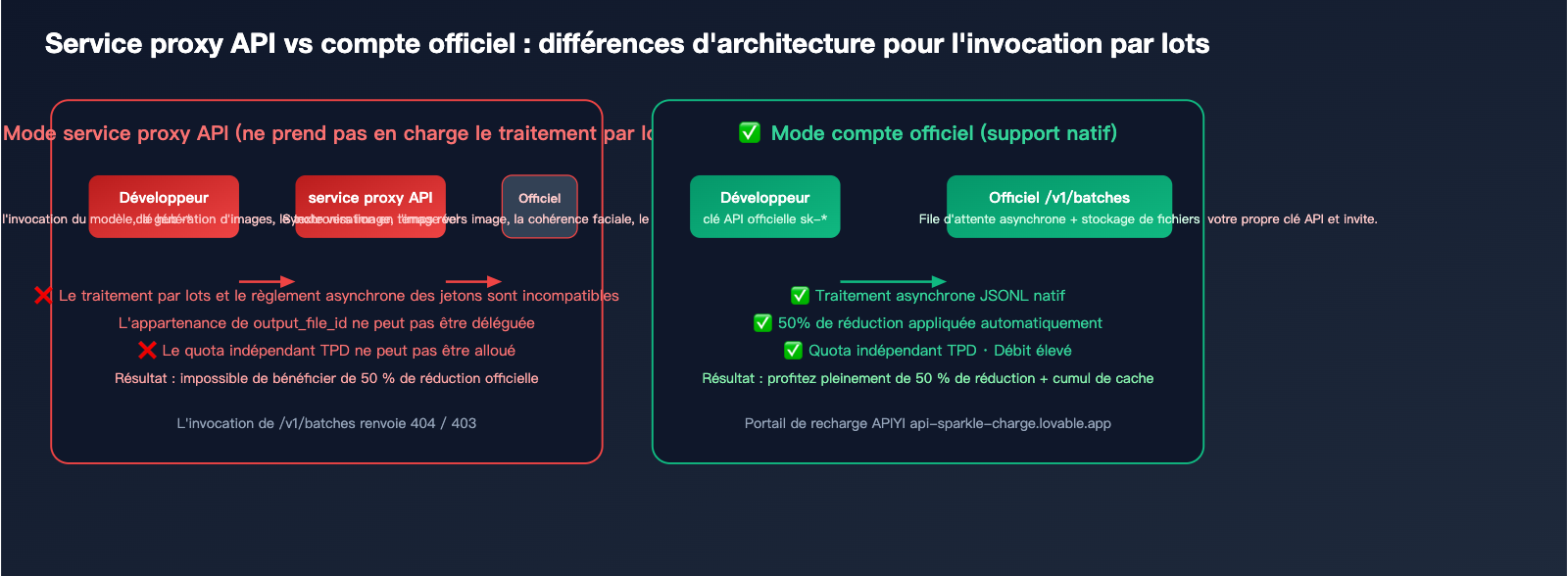
Pourquoi les services proxy API ne supportent-ils pas le traitement par lots ? Analyse technique
Beaucoup d'utilisateurs ne comprennent pas pourquoi les plateformes d'API proxy ne supportent généralement pas /v1/batches. Voici les raisons techniques :
Raison n°1 : Incompatibilité du modèle de facturation
Les services proxy facturent à l'invocation réelle (coût officiel × marge), tandis que le traitement par lots est facturé en une fois après 24 heures. Cela oblige le service proxy à avancer des fonds importants, ce qui expose la plateforme à des risques financiers et de change.
Raison n°2 : Chaîne de transmission des jetons non transparente
Le output_file_id renvoyé par l'interface de traitement par lots est un objet du système de fichiers officiel. Pour qu'un service proxy puisse le gérer, il devrait répliquer l'intégralité du système de stockage et de bande passante, et il est difficile de transférer la propriété des liens de téléchargement.
Raison n°3 : Quotas de débit indépendants
L'interface de traitement par lots dispose de son propre quota TPD (Tokens Per Day), totalement isolé du TPM/RPM synchrone. Le service proxy ne peut pas anticiper les besoins quotidiens de chaque utilisateur final, ce qui rend une redistribution équitable très complexe.
Solution : Ouvrir un compte officiel via un service de recharge
La solution la plus propre est de permettre à l'utilisateur de détenir directement son propre compte officiel :
- Technique : Contourne toutes les restrictions des services proxy et permet un accès natif à toutes les capacités de
/v1/batches. - Conformité : La facturation, la conformité et les remboursements passent par les canaux officiels.
- Efficacité : Plus besoin de diviser les flux entre synchrone et asynchrone pour le traitement par lots.
- Coût : Le service de recharge ne prélève qu'une commission raisonnable, et les 50 % de réduction du traitement par lots sont intégralement conservés.
C'est là que réside la proposition de valeur principale de api-sparkle-charge.lovable.app et d'ai.daishengji.com : vous aider à obtenir des comptes et des clés API officiels de première main, pour que vous puissiez pleinement profiter des économies offertes par le traitement par lots.
Mise en pratique : Classification par lots de 100 000 questions de service client (exemple complet)
Voici un exemple technique prêt à l'emploi pour classer les intentions de 100 000 questions de service client historiques.
Étape 1 : Construction de l'entrée au format JSONL
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions est une liste de 100 000 éléments
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "Classez la question de l'utilisateur parmi : billing/tech/sales/other, ne renvoyez que le mot de la catégorie"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
Étape 2 : Fractionnement selon la limite de 200 Mo
# Lorsque les 100 000 lignes dépassent potentiellement 200 Mo, divisez le fichier par tranches de 40 000
# Avec Gemini, aucune division n'est nécessaire, la limite est de 2 Go
Étape 3 : Soumission et suivi
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
Étape 4 : Consolidation des résultats
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
Estimation des coûts : 100 000 × ~600 jetons × tarif Batch gpt-4o-mini ≈ 6-9 $, soit une économie de 6-9 $ par rapport à un appel synchrone.
Foire aux questions (FAQ)
Q1 : Une clé API de service proxy API peut-elle appeler /v1/batches ?
Non. Les clés renvoyées par les services proxy (généralement préfixées par hub-, sk-proxy- ou un préfixe personnalisé) ne prennent en charge que les points de terminaison synchrones comme /v1/chat/completions. L'interface de traitement par lots dépend du système de fichiers et des files d'attente de tâches asynchrones des comptes officiels ; vous devez utiliser une clé API officielle sk-*. Si vous avez besoin d'une clé officielle, vous pouvez passer commande via api-sparkle-charge.lovable.app, ou consulter ai.daishengji.com pour découvrir différentes options de comptes officiels.
Q2 : La réduction de 50 % de Gemini Batch s'applique-t-elle à tous les modèles ?
Actuellement, Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite et Gemini 3 Pro Image bénéficient tous de la réduction de 50 % sur le traitement par lots, avec une réduction équivalente sur les jetons d'entrée et de sortie. Les comptes de niveau gratuit (Free Tier) ne peuvent pas utiliser le traitement par lots ; un compte payant est requis. Les comptes officiels payants activés via nos services sont prêts à l'emploi.
Q3 : Que faire si une tâche de traitement par lots échoue ? Les frais sont-ils remboursés ?
La stratégie est identique pour les deux fournisseurs : les requêtes individuelles ayant échoué ne sont pas facturées, et le lot n'est pas annulé. OpenAI inclut les entrées en échec avec un champ error dans le fichier output_file, et error_file_id regroupe toutes les erreurs ; Gemini fournit les détails de l'erreur lorsque state=JOB_STATE_FAILED. Vous pouvez rejouer les entrées échouées directement en vous basant sur le custom_id.
Q4 : Le Prompt Caching est-il déclenché lors du traitement par lots ?
Oui. La documentation d'OpenAI indique clairement que lorsqu'une requête Batch atteint des jetons d'entrée mis en cache (Cached Input Tokens), elle bénéficie d'une réduction supplémentaire de 50 % sur les jetons mis en cache après application de la réduction Batch de 50 % (soit 25 % du prix initial). Pour une mise en œuvre réelle, assurez-vous que le préfixe des requêtes au sein du lot est strictement identique et atteint la longueur minimale de cache.
Q5 : Les comptes officiels fournis par les services de recharge sont-ils sécurisés ? Puis-je les recharger moi-même par la suite ?
Les services de recharge officiels (comme api-sparkle-charge.lovable.app) fournissent des comptes officiels dont vous avez la pleine propriété. Les informations de connexion et les moyens de paiement peuvent être modifiés par vos soins, et vous pourrez recharger le compte ultérieurement avec votre propre carte bancaire internationale ou Apple Pay. Le site ai.daishengji.com propose divers forfaits, prend en charge les factures et répond aux besoins de conformité des entreprises.
Résumé
L'API de traitement par lots (Batch API) est le levier d'économie le plus sous-estimé pour l'ingénierie IA en 2026 : une simple ligne completion_window="24h" suffit à diviser vos coûts par deux. Cependant, elle impose une contrainte technique stricte : vous devez utiliser un compte et une clé API officiels. Les plateformes de service proxy API ne peuvent pas prendre en charge cette fonctionnalité en raison de leurs limitations d'architecture de facturation.
Pour les équipes gérant des tâches hors ligne à grande échelle, la stratégie la plus rentable consiste à ouvrir un compte officiel et à optimiser les coûts en combinant cela avec le Prompt Caching. Les services de recharge de clé API officiels sont le moyen le plus simple pour les développeurs francophones de profiter de cet avantage : passez commande sur api-sparkle-charge.lovable.app et consultez la grille tarifaire complète sur ai.daishengji.com. Commandez en 5 minutes et recevez vos crédits en 30 minutes pour bénéficier immédiatement d'une réduction de 50 % sur vos traitements par lots.
📌 Signature de l'auteur : Cet article a été rédigé par l'équipe technique d'APIYI (apiyi.com). Le contenu est basé sur la documentation officielle d'OpenAI Platform et de Google AI for Developers. Les prix et quotas sont conformes aux politiques officielles en vigueur au 14/04/2026. Accès aux services de recharge : api-sparkle-charge.lovable.app / ai.daishengji.com