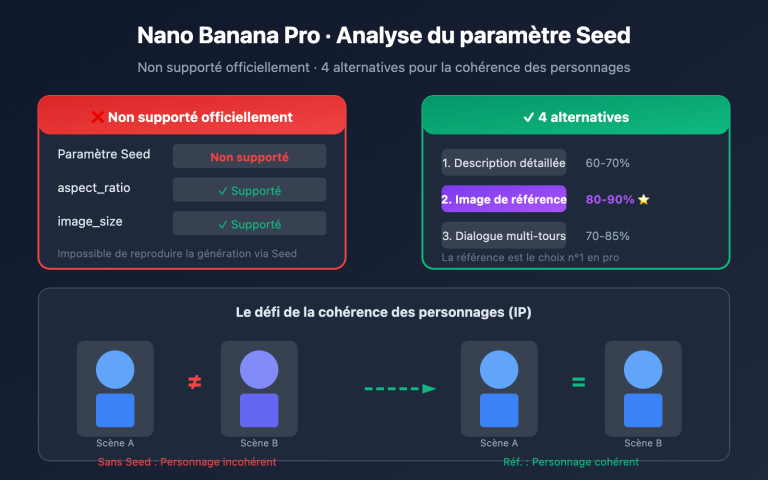
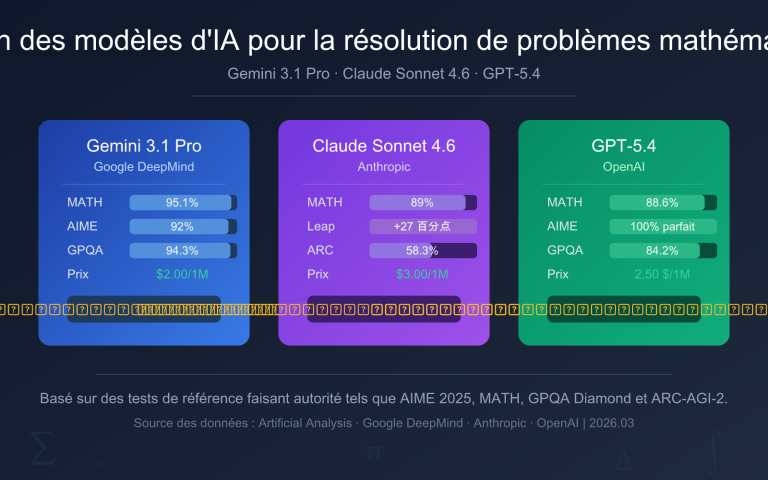
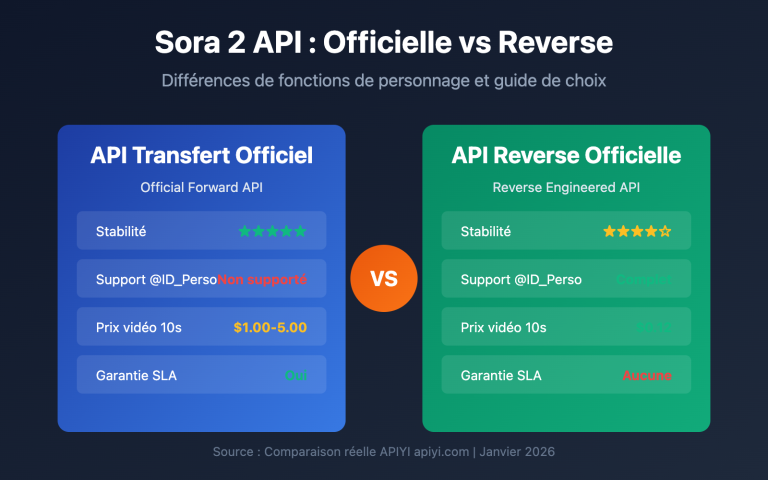
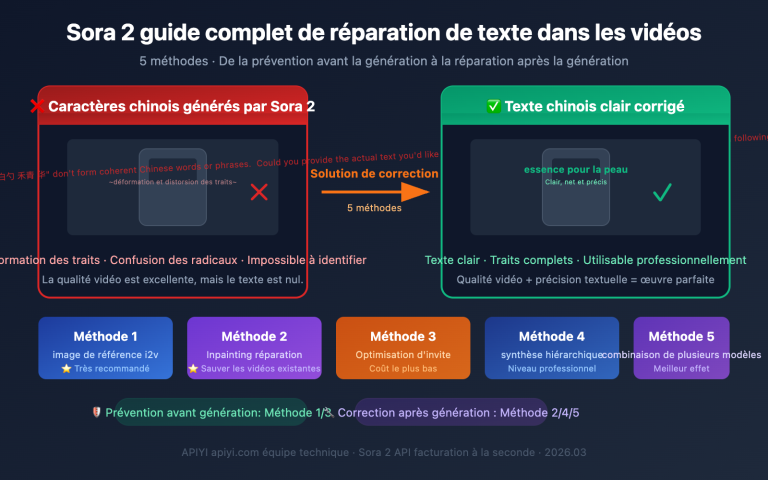
Note de l'auteur : Réponse à la question la plus fréquente des développeurs : les API de grands modèles de langage peuvent-elles accepter directement des PDF ? La réponse est que la grande majorité ne le supporte pas. Cet article détaille 3 solutions pratiques : l'extraction textuelle, la compréhension d'images et le traitement côté client.
"Est-ce que l'API du grand modèle de langage peut accepter directement un fichier PDF ?" — C'est l'une des questions les plus posées dans notre groupe de support client. Beaucoup de développeurs, habitués à la fonctionnalité "glisser-déposer de PDF pour discuter" dans les versions web de ChatGPT ou Claude, pensent que l'API fonctionne de la même manière.
La réalité est que : la grande majorité des API de grands modèles de langage ne supportent pas l'entrée directe de fichiers PDF. Même les principaux fournisseurs comme OpenAI et Anthropic ont des interfaces API dont le format d'entrée principal reste le texte et les images — le PDF n'est pas dans la liste des formats standard supportés. Plus important encore, les plateformes proxy API tierces comme APIYI ne supportent pas non plus l'envoi direct de PDF, car le protocole sous-jacent ne le permet tout simplement pas.
Mais ne vous inquiétez pas, le traitement des PDF dispose en réalité de 3 solutions éprouvées. Cet article vous aidera à comprendre les tenants et aboutissants pour choisir la méthode la plus adaptée à vos besoins.
Valeur clé : Après avoir lu cet article, vous comprendrez pourquoi les API de grands modèles de langage ne supportent pas les PDF, et comment utiliser 3 méthodes de prétraitement pour répondre efficacement à vos besoins d'entrée PDF.

Points clés pour l'entrée PDF dans les API de grands modèles de langage
| Point clé | Explication | Impact |
|---|---|---|
| Les API n'acceptent pas directement les PDF | Les entrées standard des API des principaux modèles (GPT, DeepSeek, Llama, Qwen, etc.) sont le texte et les images | Nécessite un flux de prétraitement en amont |
| Version web ≠ API | Le téléchargement de PDF sur les versions web de ChatGPT, Claude est un prétraitement frontal avant d'appeler l'API | Ne confondez pas l'expérience web avec les capacités de l'API |
| Les plateformes tierces ne supportent pas non plus | Les services proxy API comme APIYI transmettent le protocole API original ; si la couche basse ne supporte pas, la plateforme non plus | N'attendez pas de traitement PDF supplémentaire des plateformes proxy |
| 3 solutions de prétraitement sont matures et fiables | L'extraction textuelle, la compréhension d'image et le traitement côté client ont chacun leurs scénarios d'application | Choisir la bonne solution est plus pratique que de chercher une "API qui supporte les PDF" |
Pourquoi les API de grands modèles de langage ne supportent-elles pas l'entrée PDF ?
Beaucoup de développeurs sont perplexes : la version web permet clairement de télécharger un PDF, alors pourquoi l'API ne le permet-elle pas ? La raison est simple – la fonctionnalité "télécharger PDF" de la version web n'est pas le modèle lui-même qui traite le PDF, mais le frontend/backend qui effectue un prétraitement en coulisses :
- Extraction de texte : Le frontend extrait le texte du PDF, le convertit en texte brut, puis l'envoie au modèle.
- Rendu de page : Chaque page du PDF est rendue en image, et le modèle la comprend via ses capacités vision.
- Recherche RAG : Le contenu du PDF est vectorisé et stocké ; lors de la conversation, seuls les fragments pertinents sont récupérés et envoyés au modèle.
Ces étapes de prétraitement sont encapsulées dans les produits web, l'utilisateur n'en a pas conscience. Mais lorsque vous appelez directement l'API, vous devez effectuer ce prétraitement vous-même.
Aperçu rapide du support PDF des API de grands modèles de langage
| Modèle | Transmission directe de PDF via API | Formats d'entrée standard | Recommandation pour le traitement PDF |
|---|---|---|---|
| GPT-4o / GPT-4.1 | Non supporté | Texte + images (Base64) | Extraire d'abord le texte ou convertir en images |
| Claude | Partiellement supporté (Beta) | Texte + images | Il est recommandé de suivre un flux de prétraitement pour plus de stabilité |
| Gemini | Partiellement supporté | Texte + images | Il est recommandé de suivre un flux de prétraitement pour plus de contrôle |
| DeepSeek | Non supporté | Texte brut | Doit d'abord extraire le texte |
| Llama / Qwen | Non supporté | Texte (certains supportent les images) | Doit d'abord extraire le texte |
| APIYI et autres tiers | Non supporté | Transmet le protocole original | Nécessite un prétraitement autonome avant l'appel |
🎯 Note importante : Bien que la documentation officielle des API de Claude et Gemini mentionne la fonctionnalité d'entrée PDF, celle-ci présente des incertitudes en termes de compatibilité et de stabilité, et n'est pas supportée lors d'appels via des plateformes proxy tierces comme APIYI. Nous recommandons d'adopter uniformément la solution de prétraitement, qui offre la meilleure compatibilité et la plus grande stabilité.
Solution 1 de traitement PDF pour les API de grands modèles de langage : Extraction textuelle en amont
C'est la solution la plus universelle, la moins coûteuse et compatible avec tous les modèles. L'idée principale : Utiliser d'abord une bibliothèque Python pour convertir le PDF en Markdown ou en texte brut, puis envoyer le texte comme invite à l'API.
Comparaison des outils d'extraction textuelle PDF
| Outil | Vitesse | Scénario optimal | Caractéristiques |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/document | Extraction de texte générique + tableaux | Meilleur équilibre vitesse/qualité, sortie Markdown |
| pdfplumber | Moyenne | Extraction de données tabulaires | Précision élevée de l'extraction de tableaux au niveau des coordonnées |
| Marker-PDF | ~11s/document | Conversion avec fidélité des mises en page complexes | Meilleure conservation de la structure, vitesse lente |
| PyPDF2 | Rapide | PDF simples en texte brut | Léger, adapté à l'extraction basique |
Exemple de code pour l'extraction textuelle PDF
Voici la solution la plus couramment utilisée, extraire le texte du PDF puis l'envoyer à l'API d'un grand modèle de langage :
import pymupdf4llm
import openai
# Étape 1 : Conversion PDF en Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Étape 2 : Envoi du texte brut à n'importe quel grand modèle
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Veuillez résumer les points clés de ce rapport :\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Scénarios d'application : Contrats, articles, rapports, documents techniques, etc. – tout PDF principalement textuel. Tant que le PDF contient une couche de texte intégrée (pas un document scanné), l'extraction fonctionne bien.
Recommandation : La solution d'extraction textuelle est compatible avec tous les grands modèles de langage – GPT, Claude, DeepSeek, Llama, Qwen. Obtenez une clé API via APIYI apiyi.com, une seule clé permet d'appeler tous les modèles pour des tests comparatifs.
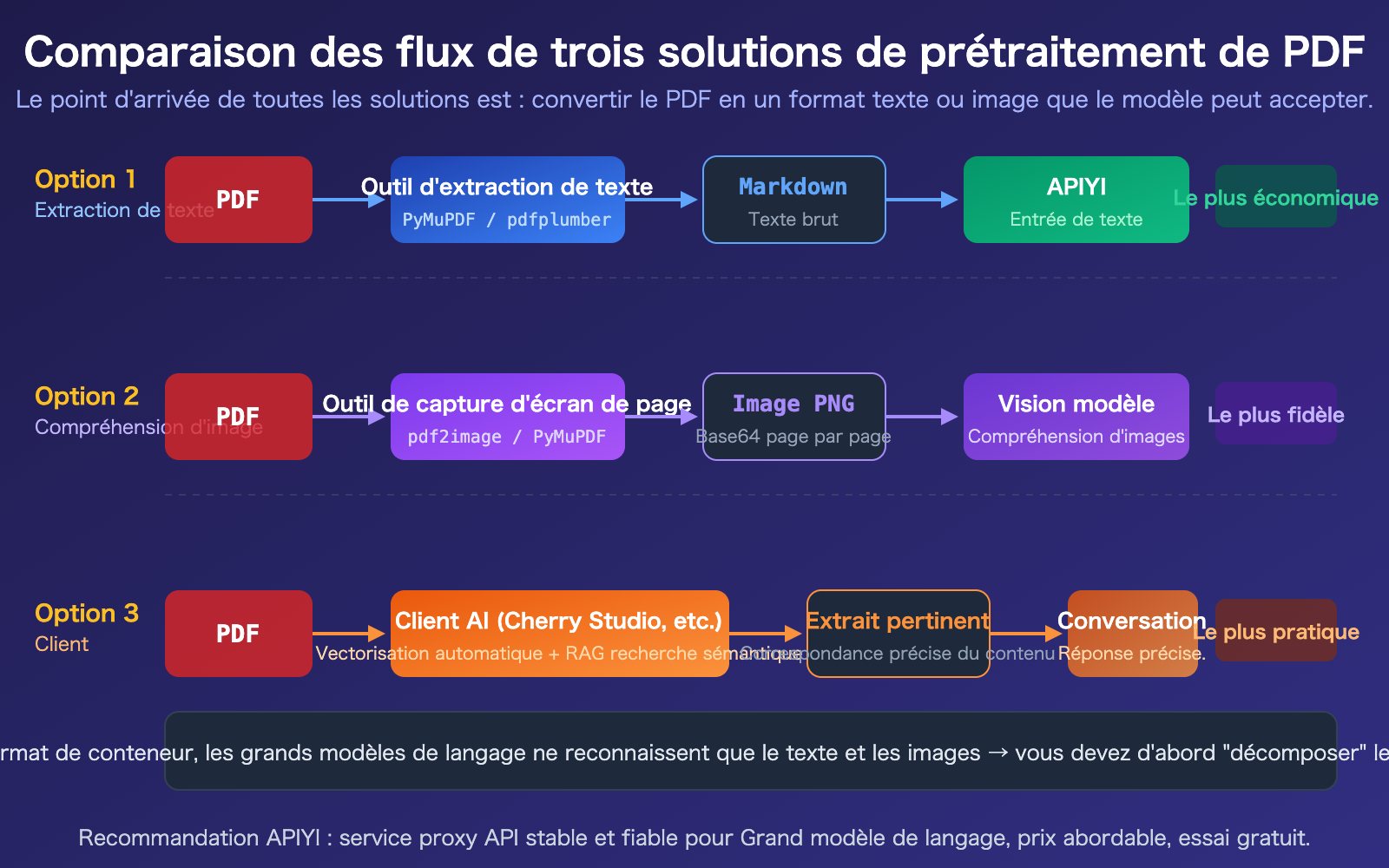
Solution 2 pour le traitement de PDF avec API de grand modèle de langage : Conversion en images + compréhension visuelle
Lorsqu'un PDF contient des graphiques, des documents scannés, des mises en page complexes ou d'autres informations visuelles, l'extraction de texte pur entraîne la perte de ces contenus. Dans ce cas, il est nécessaire de convertir chaque page du PDF en image et de la faire analyser par un modèle prenant en charge la vision par ordinateur.
Exemple de code pour convertir un PDF en images
import fitz # PyMuPDF
import base64
import openai
# Étape 1 : Convertir chaque page du PDF en image PNG
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
Voir le code complet : Envoyer les images à l’API Vision
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""Convertir un PDF en images et les envoyer à l'API Vision"""
doc = fitz.open(pdf_path)
# Construire un message multi-images (attention à limiter le nombre de pages pour éviter de dépasser le quota de tokens)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# Exemple d'utilisation
result = pdf_to_vision(
"financial_report.pdf",
"Analysez les graphiques de tendance dans ce rapport financier et résumez les données clés",
max_pages=5 # Limiter le nombre de pages, environ 765 tokens par page
)
print(result)
Cas d'utilisation : Rapports d'étude avec graphiques, documents scannés, factures, plans d'architecture ou tout PDF riche en informations visuelles.
Rappel sur les coûts : Chaque image de page consomme environ 765 tokens (résolution standard GPT-4o). Un PDF de 10 pages représente donc environ 7 650 tokens pour les images, auxquels s'ajoutent la question et la réponse, ce qui peut dépasser les 10 000 tokens. Il est crucial de limiter le nombre de pages.
🎯 Conseil pour maîtriser les coûts : N'envoyez pas toutes les pages d'un PDF en une seule fois. Utilisez d'abord la solution 1 pour extraire le texte et effectuer un premier tri, identifiez les pages clés, puis utilisez la solution 2 pour une analyse visuelle de ces pages spécifiques. Le tableau de bord d'utilisation d'APIYI (apiyi.com) permet de surveiller en temps réel la consommation de tokens.
Solution 3 pour le traitement de PDF avec API de grand modèle de langage : Utiliser un client IA
Si vous ne souhaitez pas écrire de code et avez simplement besoin de "poser des questions sur le contenu d'un PDF" dans le cadre d'une conversation quotidienne, utiliser un client IA est la solution la plus simple.
Comment les clients comme Cherry Studio traitent les PDF
Ces clients effectuent automatiquement le travail des solutions 1 et 2 :
- Vectorisation automatique : Extraction du contenu du PDF, découpage en segments et stockage dans une base de données vectorielle locale.
- Recherche sémantique : Lorsque vous posez une question, le client recherche d'abord les segments de contenu les plus pertinents.
- Envoi ciblé : Seuls les segments pertinents (et non l'intégralité du document) sont envoyés à l'API du grand modèle de langage.
- Économie de tokens : La technique RAG (Retrieval-Augmented Generation) réduit considérablement la quantité de contenu envoyée au modèle.
Points d'attention lors du traitement de PDF avec un client
- Configurer la clé API : Saisissez votre clé API d'APIYI (apiyi.com) dans le client pour accéder à tous les modèles avec une seule clé.
- Contrôler la taille des fichiers : La vectorisation de PDF très volumineux (plusieurs centaines de pages) peut prendre du temps, il est conseillé de les diviser avant traitement.
- Attention aux coûts en tokens : Bien que la RAG compresse le contenu, les documents longs peuvent tout de même générer des coûts significatifs.
- Choisir le modèle adapté : Utilisez des modèles économiques (comme GPT-4o-mini) pour des questions simples, et des modèles plus performants pour des analyses complexes.
Comparaison de 3 solutions de traitement PDF avec API de grands modèles de langage

| Solution | Coût en tokens | Support des graphiques | Difficulté de développement | Compatibilité des modèles | Scénario optimal |
|---|---|---|---|---|---|
| Extraction textuelle | Le plus bas (300-1500/page) | Non supporté | Moyenne | Tous les modèles | PDF texte pur, grands volumes |
| Compréhension d'image | Élevé (~765/page) | Support complet | Moyenne | Nécessite un modèle Vision | Graphiques, documents scannés |
| Traitement côté client | Moyen (compression RAG) | Dépend du client | Zéro code | Tous les modèles | Conversation quotidienne, sans développement |
Note de comparaison : Les trois solutions ne sont pas mutuellement exclusives. Dans les projets réels, elles sont souvent combinées. Par exemple, utilisez d'abord la solution 1 pour extraire le texte et effectuer un tri grossier, puis utilisez la solution 2 pour la compréhension d'image des pages clés. Avec APIYI apiyi.com, vous pouvez accéder de manière unifiée à tous les modèles.
Questions fréquentes
Q1 : Pourquoi ChatGPT Web peut-il télécharger des PDF, mais pas l’API ?
La fonctionnalité "Télécharger un PDF" de la version Web est un prétraitement effectué par le front-end du produit : il extrait le texte, rend les images, crée un index de recherche, puis appelle l'API sous-jacente. Le format d'entrée principal de l'API elle-même est le texte et les images. Le PDF, en tant que format de conteneur de document complexe, n'est pas pris en charge par défaut. Lorsque vous appelez l'API, vous devez effectuer ces étapes de prétraitement vous-même.
Q2 : Les plateformes proxy comme APIYI peuvent-elles traiter les PDF pour moi ?
Non. L'essence des plateformes proxy comme APIYI est de transmettre les requêtes API. Si le protocole sous-jacent ne prend pas en charge le PDF, la plateforme ne peut pas le traiter non plus. Vous devez effectuer le prétraitement du PDF (extraction de texte ou conversion en image) avant d'appeler l'API, puis envoyer le texte ou les images traitées via APIYI apiyi.com au grand modèle de langage.
Q3 : Comment contrôler les coûts en tokens lors du traitement des PDF ?
Quelques astuces pratiques :
- Privilégiez la solution 1 (extraction textuelle), c'est la moins chère.
- Traitez uniquement les pages nécessaires, ne transmettez pas tout le document en une fois.
- Utilisez la technologie RAG pour découper et rechercher, n'envoyez que les passages pertinents au modèle.
- Utilisez un modèle économique (comme GPT-4o-mini) pour les questions simples, et un modèle phare pour les analyses complexes.
- Surveillez la consommation en temps réel via le tableau de bord d'utilisation d'APIYI apiyi.com.
Résumé
Points essentiels concernant l'entrée PDF dans les API des grands modèles de langage :
- La grande majorité des API ne prennent pas en charge l'entrée PDF directe : L'entrée principale d'un grand modèle de langage est le texte et les images. Les PDF doivent être prétraités avant utilisation.
- Les plateformes tierces ne le prennent pas en charge non plus : Les plateformes proxy comme APIYI transmettent le protocole original et ne peuvent pas traiter les PDF en plus.
- 3 solutions à choisir selon les besoins : PDF en texte pur → extraction textuelle (la plus économique). PDF avec images → conversion en image pour la compréhension (la plus fidèle). Dialogue quotidien → client natif (le plus simple).
Ne vous perdez pas à chercher "quelle API prend en charge le PDF". Concentrez-vous plutôt sur le choix de la bonne méthode de prétraitement – c'est la bonne approche.
Nous vous recommandons d'obtenir un crédit gratuit via APIYI apiyi.com, de prétraiter votre PDF, puis d'utiliser une seule clé API pour tester et comparer tous les principaux modèles comme GPT, Claude, DeepSeek, etc.
📚 Références
-
Documentation PyMuPDF4LLM : Outil d'extraction de texte PDF
- Lien :
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Description : L'outil le plus rapide pour convertir un PDF en Markdown, recommandé en premier choix.
- Lien :
-
Documentation pdfplumber : Outil spécialisé pour l'extraction de tableaux
- Lien :
github.com/jsvine/pdfplumber - Description : L'outil offrant la plus grande précision pour extraire les données tabulaires des PDF.
- Lien :
-
Cherry Studio : Client IA open source
- Lien :
github.com/CherryHQ/cherry-studio - Description : Client gratuit qui prend en charge le glisser-déposer de PDFs dans la conversation, configurable avec APIYI comme backend.
- Lien :
-
Documentation de la plateforme APIYI : Accès unifié aux APIs des grands modèles
- Lien :
docs.apiyi.com - Description : Obtention de clés API, liste des modèles et exemples d'invocation.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : Bienvenue pour discuter dans les commentaires. Plus de ressources disponibles dans le centre de documentation APIYI à docs.apiyi.com.