Note de l'auteur : APIYI lance le modèle officiel inversé gpt-image-2-all, facturé 0,03 $ par invocation, sans limite de concurrence. Il prend en charge le texte vers image, la fusion multi-images et la modification par langage naturel, offrant les mêmes capacités de génération que la dernière version de ChatGPT sur le web. Cet article détaille comment l'intégrer.
En avril 2026, la version web de ChatGPT a commencé les tests A/B de sa nouvelle génération de capacités de génération d'images. Bien que les utilisateurs voient toujours l'étiquette "GPT Image 1.5" dans l'interface, certaines requêtes sont déjà traitées par le nouveau modèle. L'API officielle d'OpenAI n'a pas encore ouvert l'identifiant de modèle gpt-image-2. Tout service prétendant offrir un "appel API direct vers gpt-image-2" doit être vérifié avec prudence.
APIYI lance officiellement gpt-image-2-all via une solution d'inversion officielle, alignée sur les dernières capacités de génération d'images de la version web de ChatGPT, au tarif de 0,03 $ par invocation, sans limite de concurrence. Ce n'est pas une promesse en l'air, mais une interface de niveau production déjà prête à être appelée via des requêtes HTTP standard.
Valeur ajoutée : Après avoir lu cet article, vous maîtriserez les 3 points de terminaison API de gpt-image-2-all, les techniques de fusion multi-images, l'utilisation de la modification par langage naturel, et vous pourrez finaliser l'intégration en moins de 10 minutes.

Points clés de gpt-image-2-all
| Capacité | Description | Valeur |
|---|---|---|
| Alignement version web ChatGPT | Solution d'inversion synchrone avec les capacités officielles | Pas besoin d'attendre l'API d'OpenAI |
| Facturation à l'acte | 0,03 $/invocation, résolution/qualité/invite illimitées | Coûts transparents et prévisibles |
| Concurrence illimitée | Aucune limite sur le nombre de requêtes | Idéal pour les pipelines de traitement par lots |
| Fusion multi-images | Référence via "Image 1/Image 2/Image 3" dans l'invite | Cohérence faciale et de sujet |
| Modification par langage naturel | Édition conversationnelle sans masque | Seuil d'itération considérablement réduit |
Analyse du positionnement de gpt-image-2-all
Qu'est-ce qu'une "solution d'inversion officielle" ? Il s'agit d'une solution de service proxy API qui se connecte aux dernières capacités de génération d'images de la version web de ChatGPT via l'ingénierie inverse. Ce n'est pas la même interface que le gpt-image-2 qu'OpenAI pourrait ouvrir officiellement à l'avenir, mais les capacités du modèle sous-jacent sont identiques. Avant l'ouverture officielle de l'API, c'est la seule solution de niveau production capable d'appeler de manière stable les dernières capacités de génération d'images de ChatGPT.
Pourquoi s'intégrer dès maintenant ? Trois raisons concrètes : (1) La date de sortie officielle de gpt-image-2 par OpenAI est indéterminée (prévue entre fin avril et mi-mai 2026) ; (2) La période de lancement initial connaîtra inévitablement des problèmes de quotas et de démarrage à froid ; (3) En validant votre flux de travail sur gpt-image-2-all dès maintenant, il suffira de changer le nom du modèle pour une migration transparente lorsque la version officielle sera disponible.
Démarrage rapide avec gpt-image-2-all
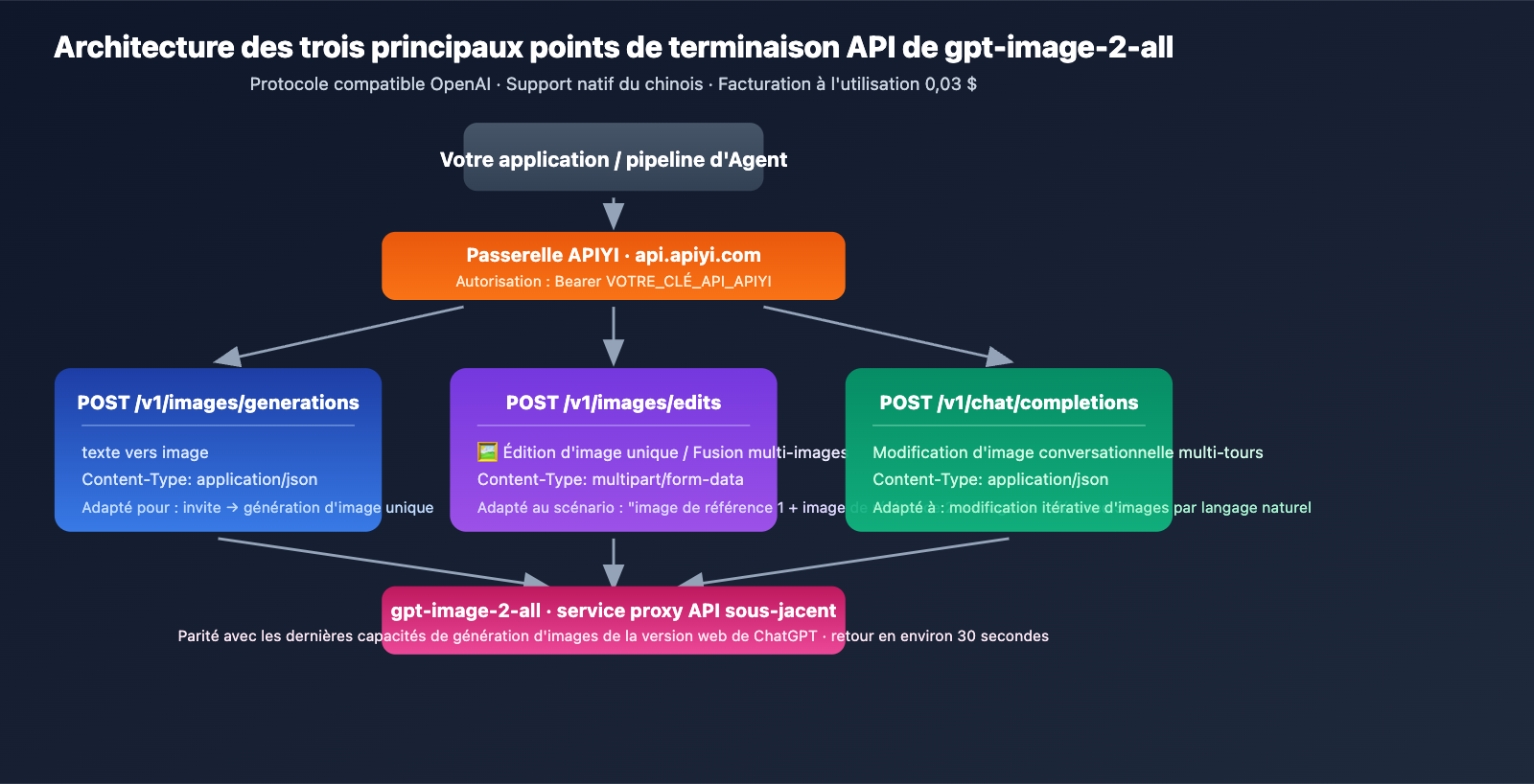
Trois points de terminaison API principaux
gpt-image-2-all propose trois points de terminaison pour couvrir l'ensemble des scénarios de génération d'images :
| Point de terminaison | Usage | Content-Type |
|---|---|---|
POST /v1/images/generations |
Texte vers image | application/json |
POST /v1/images/edits |
Édition d'image unique / Fusion multi-images | multipart/form-data |
POST /v1/chat/completions |
Modification conversationnelle multi-tours | application/json |
URL de base : https://api.apiyi.com (alternatives : b.apiyi.com, vip.apiyi.com)
Exemple minimaliste de texte vers image
import requests
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": "Bearer YOUR_APIYI_KEY",
"Content-Type": "application/json"
},
json={
"model": "gpt-image-2-all",
"prompt": "Format paysage 16:9, une tasse de café latte, étiquette sur la table avec l'inscription 'Morning Blend $4.50', lumière du matin traversant la fenêtre du café",
},
timeout=120
)
result = response.json()
print(result["data"][0]["url"])
Voir le code d’intégration complet (incluant gestion des erreurs, concurrence, fusion d’images et édition conversationnelle)
import requests
import time
from typing import Optional, List
API_KEY = "YOUR_APIYI_KEY"
BASE_URL = "https://api.apiyi.com"
def text_to_image(prompt: str, timeout: int = 120) -> Optional[str]:
"""Texte vers image : via le point de terminaison /v1/images/generations"""
for attempt in range(3):
try:
r = requests.post(
f"{BASE_URL}/v1/images/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "prompt": prompt},
timeout=timeout
)
if r.status_code == 200:
return r.json()["data"][0]["url"]
if r.status_code == 429:
time.sleep(2 ** attempt)
continue
except requests.Timeout:
continue
return None
def multi_image_fusion(prompt: str, image_paths: List[str]) -> Optional[str]:
"""Fusion multi-images : via le point de terminaison /v1/images/edits"""
files = [
("image[]", (f"img{i}.png", open(p, "rb"), "image/png"))
for i, p in enumerate(image_paths)
]
data = {"model": "gpt-image-2-all", "prompt": prompt}
r = requests.post(
f"{BASE_URL}/v1/images/edits",
headers={"Authorization": f"Bearer {API_KEY}"},
data=data,
files=files,
timeout=120
)
return r.json()["data"][0]["url"] if r.status_code == 200 else None
def conversational_edit(messages: List[dict]) -> Optional[str]:
"""Édition conversationnelle : via le point de terminaison /v1/chat/completions"""
r = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "messages": messages},
timeout=120
)
return r.json()["choices"][0]["message"]["content"] if r.status_code == 200 else None
url = text_to_image("Format portrait 9:16, affiche mobile, un café glacé, titre en haut 'Summer Sale 50% OFF'")
print(f"Généré : {url}")
fusion_url = multi_image_fusion(
"Place le personnage de l'image 1 dans la scène de plage de l'image 2, en gardant la tenue du personnage identique",
["person.png", "beach.png"]
)
print(f"Fusion : {fusion_url}")
Conseil d'intégration : Inscrivez-vous via APIYI apiyi.com pour obtenir un crédit de test. Une seule clé API prend en charge tous les modèles, y compris gpt-image-2-all, GPT-4o et Claude, évitant ainsi la gestion complexe de comptes multiples.
Analyse détaillée des fonctionnalités clés de gpt-image-2-all
Fonctionnalité 1 : Rendu de texte haute précision
Pour gpt-image-2-all, la stabilité du rendu de texte (chinois et anglais) est le point fort de la dernière capacité de génération d'images officielle de ChatGPT. Le texte sur les enseignes, les affiches et les infographies est généré correctement dès le premier essai, ce qui était difficile avec gpt-image-1.5.
Scénarios testés :
- Tableau de menu de café :
"Americano $4.00, Latte $4.50"précis au caractère près. - Emballage de produit : Liste d'ingrédients en mélange chinois/anglais claire et lisible.
- Maquette UI : Boutons et étiquettes de navigation rendus avec précision.
- Infographie : Titres, sous-titres et étiquettes de données clairement hiérarchisés.
Fonctionnalité 2 : Capacité de fusion multi-images
Via le point de terminaison /v1/images/edits, vous pouvez télécharger plusieurs images de référence simultanément et les citer directement dans votre invite en utilisant "image 1", "image 2", "image 3".
prompt = """
Place le produit de l'image 1 dans la scène de l'image 2,
utilise le style de couleur de l'image 3,
angle de vue légèrement en plongée,
détails 4K haute définition.
"""
Scénarios d'application :
| Scénario | Usage |
|---|---|
| Images e-commerce | Photo produit + Photo de scène → Synthèse réaliste |
| Cohérence faciale | Image originale du personnage + Nouvelle scène → Multi-angles |
| Transfert de style | Image de contenu + Image de style → Sortie stylisée |
| Système visuel de marque | Produit + LOGO + Palette de couleurs → Visuel unifié |
Fonctionnalité 3 : Modification en langage naturel (sans masque)
La plus grande avancée en termes d'efficacité est l'édition conversationnelle : plus besoin de dessiner des masques ou de sélectionner des zones, décrivez simplement vos besoins de modification en langage naturel.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Génère une vue extérieure d'un café, soleil de l'après-midi en oblique"},
]
},
{
"role": "assistant",
"content": "[Lien de l'image générée]"
},
{
"role": "user",
"content": "Change la météo pour de la pluie, en gardant le bâtiment intact"
}
]
Ce que cela signifie pour votre flux de travail : Le cycle passé de "générer → retoucher dans Photoshop → régénérer" devient une itération conversationnelle. Chaque ajustement ne nécessite que la description de la différence, sans avoir à réécrire l'invite complète.
Fonctionnalité 4 : Support natif du chinois
L'invite peut être rédigée directement en chinois, sans avoir besoin de traduire en anglais avant l'invocation. Pour les équipes de développement chinoises et les entreprises locales, c'est une expérience fluide et naturelle :
prompt = "Format portrait 9:16, couverture Xiaohongshu, une femme au visage oriental buvant un café, titre 'Week-end découverte · Le café secret dans les hutongs', style réaliste avec lumière douce"
Contrôle des dimensions et du format avec gpt-image-2-all
Remarques importantes
Le modèle gpt-image-2-all n'accepte pas les paramètres size, n, quality ou aspect_ratio. Si vous les transmettez, cela déclenchera une erreur de validation. Le contrôle des dimensions doit impérativement être effectué via la description textuelle dans l'invite.
Recommandations pour la rédaction de l'invite

| Ratio cible | Rédaction recommandée | Utilisation |
|---|---|---|
| 1:1 Carré | "1024×1024 carré" ou "Composition carrée 1:1" | Avatar réseaux sociaux |
| 16:9 Paysage | "Format paysage 16:9" ou "Large écran 16:9" | Miniature vidéo |
| 9:16 Portrait | "Format portrait 9:16" ou "Smartphone 9:16" | Vidéo courte / TikTok |
| 21:9 Ultra-large | "Bannière 21:9" ou "Écran ultra-large" | Bannière web |
| 4:3 Traditionnel | "Format paysage 4:3" | Diapositives |
| 3:4 Portrait | "Format portrait 3:4" | Image e-commerce |
Astuces clés
Placez la description du format au début de votre invite. Le modèle suit mieux les instructions placées en tête de prompt ; si vous le mettez à la fin, il risque de l'ignorer.
# ✅ Recommandé
prompt = "Format paysage 16:9, un Shiba Inu souriant sous un cerisier, style photographie douce"
# ❌ Non recommandé
prompt = "Un Shiba Inu souriant sous un cerisier, style photographie douce, format paysage 16:9"
Tarification et stratégie de concurrence de gpt-image-2-all
Règles de facturation
| Élément | Règle |
|---|---|
| Prix unitaire | 0,03 $ / requête |
| Unité de facturation | Par génération réussie |
| Pas de frais en cas d'échec | Aucune facturation pour les erreurs 401/4xx/5xx |
| Impact des paramètres | Aucun (indépendant de la résolution/qualité) |
| Limite de concurrence | Aucune (limitée naturellement par le solde du compte) |
Estimation des coûts typiques
| Scénario métier | Volume d'appels mensuel | Coût mensuel |
|---|---|---|
| Projet personnel | 500 requêtes | 15 $ |
| Petite équipe | 5 000 requêtes | 150 $ |
| E-commerce en masse | 50 000 requêtes | 1 500 $ |
| Pipeline à grande échelle | 500 000 requêtes | 15 000 $ |
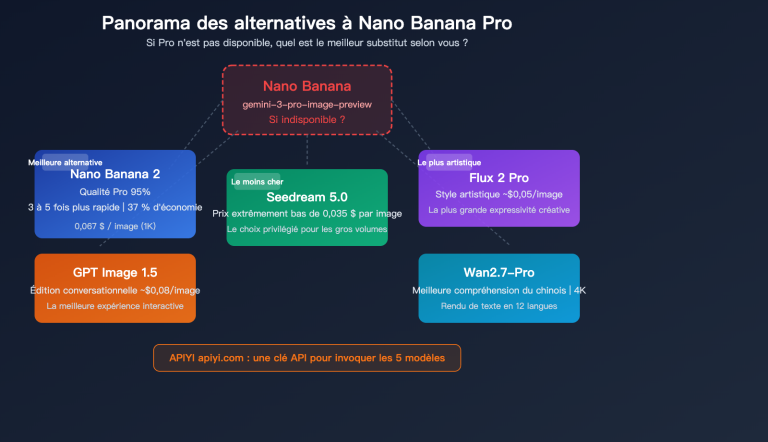
Conseil d'optimisation des coûts : Grâce à la gestion de compte unifiée d'APIYI (apiyi.com), vous pouvez router vos tâches vers le modèle le plus adapté parmi gpt-image-2-all, gpt-image-1.5 et Nano Banana Pro en fonction du type de tâche en temps réel, évitant ainsi de payer le prix fort pour tous vos scénarios.
Gestion des erreurs et bonnes pratiques pour gpt-image-2-all
Codes d'erreur courants et traitement
| Code d'état | Action à entreprendre |
|---|---|
| 401 | Vérifiez la validité de votre Authorization Bearer Token |
| 429 | Réessayez avec un backoff exponentiel (2s → 4s → 8s) |
| 5xx | Réessayez 1 à 2 fois, puis déclenchez une alerte si l'erreur persiste |
| Timeout | Timeout client recommandé ≥ 120 secondes |
Astuces de dépannage
Toutes les réponses incluent un en-tête request-id. En cas de problème, notez cet ID et transmettez-le au support technique d'APIYI pour permettre une localisation rapide dans les journaux côté serveur.
Fonctionnalités non prises en charge
- Sortie en flux (Streaming) :
stream=truen'est pas pris en compte, seule la réponse unique est supportée. - Sortie multi-images : Une seule requête renvoie 1 image. Pour obtenir plusieurs images, effectuez des appels concurrents.
- Paramètres par défaut du SDK OpenAI : Les paramètres
size/ninclus par défaut dans le SDK officiel déclencheront une erreur de validation. Il est recommandé d'utiliserrequestspour envoyer vos requêtes directement.
FAQ – Foire aux questions
Q1 : Qu’est-ce que gpt-image-2-all ?
gpt-image-2-all est un modèle via service proxy API proposé par APIYI, utilisant une solution d'ingénierie inverse pour accéder aux toutes dernières capacités de génération d'images de la version web de ChatGPT. Avant qu'OpenAI ne rende officielle l'API gpt-image-2, ce service offre un canal de production stable, identique aux performances de ChatGPT, et prend en charge trois scénarios clés : le texte vers image, la fusion multi-images et la modification d'images par langage naturel.
Q2 : Quelle est la différence entre gpt-image-2-all et le modèle officiel gpt-image-2 ?
Les capacités du modèle sous-jacent sont identiques, mais les méthodes d'interface diffèrent. L'API officielle d'OpenAI n'a pas encore ouvert l'ID de modèle gpt-image-2 (soyez prudent avec tout service prétendant offrir un accès API direct), alors que la version web de ChatGPT teste déjà ce nouveau modèle via des tests A/B. gpt-image-2-all fournit un canal d'invocation stable grâce à une solution d'ingénierie inverse. Une fois la version officielle disponible, il vous suffira de modifier le champ model pour migrer sans interruption vers l'interface officielle.
Q3 : Comment comprendre la tarification à 0,03 $ par requête ?
La facturation s'effectue par génération réussie, sans limite de résolution, de qualité ou de longueur d'invite. En comparaison avec l'estimation du prix officiel d'OpenAI pour gpt-image-2 (entre 0,15 $ et 0,20 $), gpt-image-2-all coûte environ 5 à 6 fois moins cher. Les requêtes échouées (erreurs d'authentification ou de paramètres) ne sont pas facturées, et il n'y a pas de limite stricte de concurrence (limitée uniquement par le solde de votre compte).
Q4 : Pourquoi la génération d’une image prend-elle 30 secondes ?
30 secondes est le temps de réponse moyen actuel de notre solution, ce qui est proche de la vitesse de la version web de ChatGPT. Une fois l'API officielle gpt-image-2 ouverte, on s'attend à une vitesse plus rapide (environ 3 secondes), mais en attendant, gpt-image-2-all est la seule solution permettant d'invoquer ces capacités de manière stable. Nous recommandons de régler le délai d'expiration (timeout) de votre client à ≥ 120 secondes pour éviter les erreurs de délai.
Q5 : Comment intégrer gpt-image-2-all ?
Trois étapes suffisent :
- Visitez APIYI sur apiyi.com pour créer un compte et obtenir une clé API.
- Configurez l'URL de base (Base URL) sur
https://api.apiyi.com. - Utilisez la bibliothèque
requestspour appeler le point de terminaison/v1/images/generations(le SDK officiel nécessite une requête HTTP personnalisée pour éviter les problèmes avec le paramètresize).
Documentation détaillée : docs.apiyi.com/api-capabilities/gpt-image-2-all/overview · Essai en ligne : imagen.apiyi.com
Q6 : Combien d’images de référence la fusion multi-images peut-elle supporter ?
Une seule requête /v1/images/edits prend en charge plusieurs images de référence. Chaque image doit être ≤ 10 Mo et au format PNG, JPG ou WebP. Dans votre invite, vous pouvez faire référence aux images via "image1", "image2", "image3", etc. Les tests montrent que la fusion de 3 à 5 images de référence offre les résultats les plus stables ; au-delà de 10 images, certains éléments peuvent être omis.
Q7 : Pourquoi ne puis-je pas utiliser le SDK officiel d’OpenAI pour l’appel ?
La méthode images.generate() du SDK officiel d'OpenAI envoie par défaut des paramètres comme size ou n, que gpt-image-2-all n'accepte pas (ce qui déclenche une erreur de validation). Solutions recommandées : (1) utiliser directement requests pour envoyer la requête HTTP ; (2) ou modifier le corps de la requête du SDK pour supprimer ces paramètres. Une fois la version officielle ouverte, le SDK sera compatible.
Q8 : Quelles sont les limitations connues de gpt-image-2-all ?
Voici les limitations actuelles :
- Sortie unique de 1 image : pour plusieurs images, effectuez des appels concurrents.
- Pas de streaming : retour unique, pas de flux (stream).
- Phase bêta : la stabilité est en cours d'optimisation, avec parfois de légères instabilités.
- Dépendance à l'ingénierie inverse : si les capacités web de ChatGPT sont modifiées, cela peut affecter brièvement le service.
- Conseil : pour les applications critiques, nous recommandons de configurer également gpt-image-1.5 ou Nano Banana Pro comme solution de secours.
Points clés de gpt-image-2-all
- Solution d'ingénierie inverse · Accès aux dernières capacités de ChatGPT : le seul canal de production avant l'ouverture de l'API officielle.
- 0,03 $ par requête · Concurrence illimitée : facturation à la réussite, coûts transparents, idéal pour les pipelines de traitement par lots.
- Trois points de terminaison pour tous les scénarios : texte vers image / fusion multi-images / modification conversationnelle.
- Chinois natif + rendu de texte haute précision : rendu stable des caractères chinois et anglais, pas besoin de traduire vos invites.
- Démarrage rapide : inscription sur APIYI (apiyi.com) → timeout de 120 secondes → appel direct via
requests.
Résumé
La valeur ajoutée de gpt-image-2-all :
- Combler le vide officiel : En attendant que OpenAI ouvre officiellement l'API
gpt-image-2, nous proposons une interface de qualité production pour invoquer de manière stable les dernières capacités de génération d'images de ChatGPT. - Coût nettement inférieur aux prévisions officielles : 0,03 $ par requête contre une estimation officielle de 0,15 $ à 0,20 $, offrant un avantage concurrentiel majeur pour les scénarios de traitement par lots.
- Conception pensée pour une migration fluide : Basé sur le protocole compatible OpenAI, il suffit de remplacer le nom du modèle lors de la sortie de la version officielle pour effectuer la transition.
Pour vos décisions d'équipe, nous recommandons d'intégrer immédiatement gpt-image-2-all via APIYI (apiyi.com) pour valider vos processus métier. Le tarif actuel de 0,03 $ par requête rend la validation à grande échelle quasi gratuite. Vous pourrez basculer vers le gpt-image-2 officiel dès sa sortie — les équipes qui anticipent dès maintenant bénéficieront d'un avantage produit significatif lors du lancement du nouveau modèle.
Expérience en ligne : imagen.apiyi.com · Documentation : docs.apiyi.com/api-capabilities/gpt-image-2-all/overview
Lectures complémentaires
Si gpt-image-2-all vous intéresse, nous vous recommandons de poursuivre avec ces lectures :
- 📘 Analyse complète des 8 améliorations majeures : gpt-image-2 vs gpt-image-1.5 – Pour comprendre les raisons fondamentales de ce saut technologique.
- 📊 Analyse complète des 6 scénarios d'application de gpt-image-2 – Pour maîtriser les chemins de déploiement métier concrets.
- 🚀 Comparaison approfondie : gpt-image-2 vs Nano Banana Pro – Pour choisir rationnellement le modèle le plus adapté.
📚 Références
-
Documentation officielle APIYI: Spécifications techniques complètes de gpt-image-2-all
- Lien :
docs.apiyi.com/api-capabilities/gpt-image-2-all/overview - Description : Documentation d'intégration officielle faisant autorité, incluant les paramètres, les codes d'erreur et les meilleures pratiques.
- Lien :
-
Playground en ligne APIYI: imagen.apiyi.com
- Lien :
imagen.apiyi.com - Description : Testez les résultats de génération d'images de gpt-image-2-all sans écrire une seule ligne de code.
- Lien :
-
Documentation officielle de l'API d'image OpenAI: API des derniers modèles d'image
- Lien :
openai.com/index/image-generation-api - Description : Comparez et découvrez les spécifications de l'API gpt-image-1.5 officielle d'OpenAI.
- Lien :
-
Observation des tests en niveaux de gris sur LM Arena: Informations divulguées sur GPT Image 2
- Lien :
mindstudio.ai/blog/what-is-gpt-image-2 - Description : Aperçu des capacités de la prochaine génération de modèles d'image.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter dans la section commentaires. Pour plus d'informations, visitez le centre de documentation APIYI sur docs.apiyi.com.