Comparaison des fonctionnalités des deux formats d'appel de l'API Claude
| Caractéristique | Format natif Anthropic | Mode de compatibilité OpenAI |
|---|---|---|
| Prompt Caching (Cache) | ✅ Entièrement supporté | ❌ Non supporté |
| Traitement de documents PDF | ✅ Supporté | ❌ Non supporté |
| Citations (Références) | ✅ Supporté | ❌ Non supporté |
| Extended Thinking (Sortie complète) | ✅ Supporté | ⚠️ Support partiel (impossible de voir la réflexion) |
| Streaming (Flux) | ✅ Supporté | ✅ Supporté |
| Tool Use (Utilisation d'outils) | ✅ Supporté | ✅ Supporté |
| Vision (Compréhension d'images) | ✅ Supporté | ✅ Supporté |
| Sorties structurées | ✅ Supporté (mode strict) | ❌ Paramètre strict ignoré |
Pourquoi le mode de compatibilité OpenAI ne supporte pas le cache Claude
Le mode de compatibilité OpenAI est conçu pour tester et comparer les capacités des modèles, et non pour une utilisation intensive en production :
- Différences de protocole : Le paramètre
cache_controlest un champ natif de l'API Messages d'Anthropic, qui n'a pas d'équivalent dans le format chat completions d'OpenAI. - Limitations architecturales : La couche de compatibilité doit convertir le format OpenAI vers le format Anthropic ; lors de ce processus, les informations de contrôle du cache sont perdues.
- Priorités d'Anthropic : Anthropic a déclaré que la priorité de la couche de compatibilité est inférieure à la fiabilité et à l'intégrité fonctionnelle de l'API Claude native.
💡 Conseil important : Si votre activité dépend du prompt caching pour contrôler les coûts, vous devez utiliser le format natif Messages API d'Anthropic, et non le mode de compatibilité OpenAI.
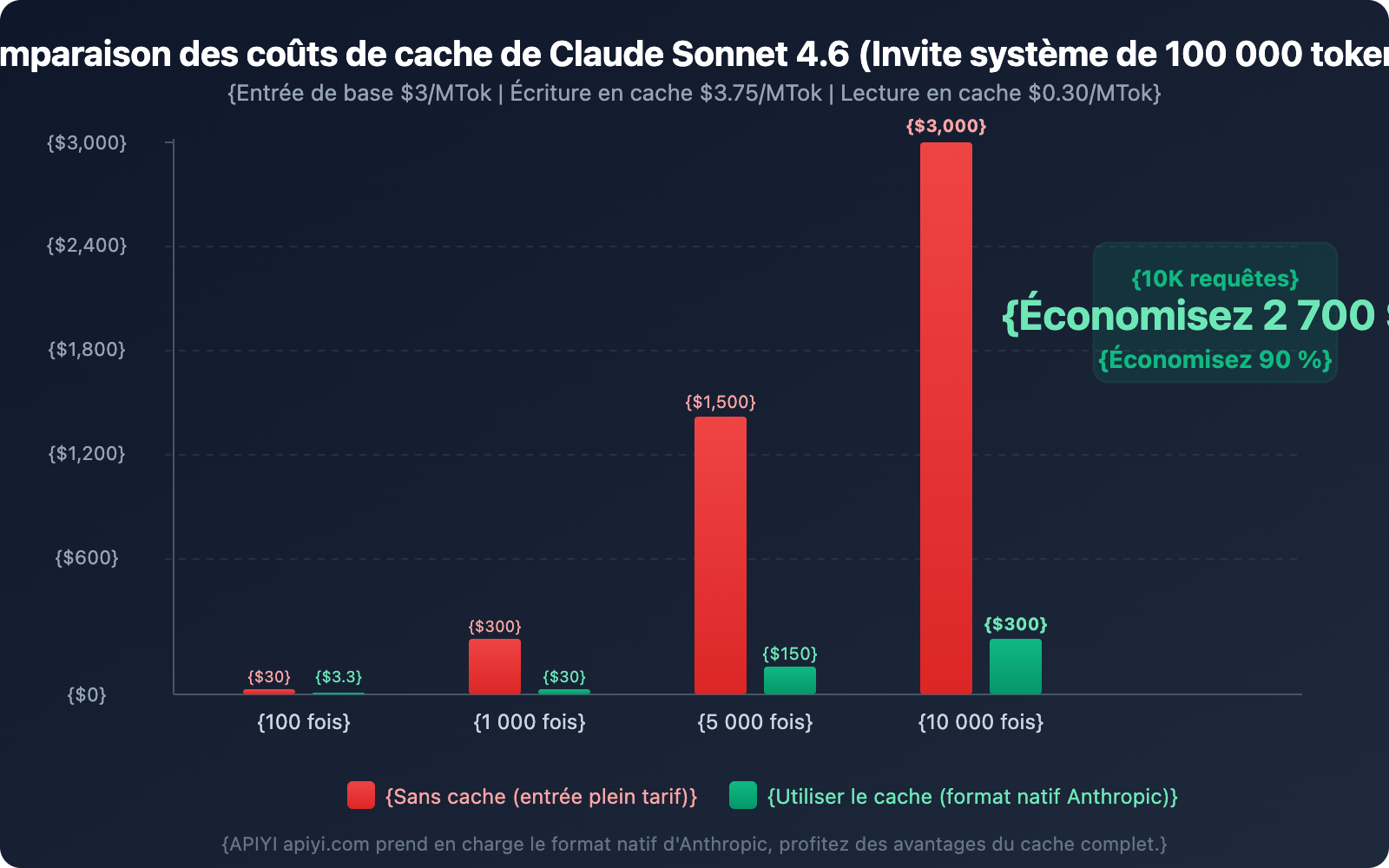
Détails de la tarification du Claude Prompt Caching : économisez jusqu'à 90 % de coûts
La structure tarifaire du prompt caching de Claude est son principal atout : le prix de lecture d'un cache touché (hit) ne représente que 10 % du prix d'entrée de base.
Comparaison des prix du cache pour les modèles Claude
| Modèle | Entrée de base | Écriture cache 5 min | Écriture cache 1 h | Lecture cache | Sortie |
|---|---|---|---|---|---|
| Claude Opus 4.6 | 5 $/MTok | 6,25 $/MTok | 10 $/MTok | 0,50 $/MTok | 25 $/MTok |
| Claude Sonnet 4.6 | 3 $/MTok | 3,75 $/MTok | 6 $/MTok | 0,30 $/MTok | 15 $/MTok |
| Claude Sonnet 4.5 | 3 $/MTok | 3,75 $/MTok | 6 $/MTok | 0,30 $/MTok | 15 $/MTok |
| Claude Haiku 4.5 | 1 $/MTok | 1,25 $/MTok | 2 $/MTok | 0,10 $/MTok | 5 $/MTok |
MTok = Million de Tokens. Source des données : Page de tarification officielle d'Anthropic (février 2026)
Règles de calcul de la tarification du cache Claude
La tarification du cache suit 3 règles de multiplication simples :
- Écriture cache 5 minutes : Prix d'entrée de base × 1,25
- Écriture cache 1 heure : Prix d'entrée de base × 2,0
- Lecture cache (hit) : Prix d'entrée de base × 0,1
Prenons l'exemple de Claude Sonnet 4.6, en supposant que vous ayez une invite système de 100 000 tokens :
| Scénario | Coût d'entrée par requête | Coût total pour 10 000 requêtes |
|---|---|---|
| Sans cache | 0,30 $ | 3 000 $ |
| Première requête (écriture cache) | 0,375 $ | Coût unique |
| Requêtes suivantes (cache hit) | 0,03 $ | 300 $ |
| Ratio d'économie | Environ 90 % |
💰 Optimisation des coûts : Pour les scénarios réutilisant la même invite système, l'utilisation de la plateforme APIYI (apiyi.com) pour appeler l'API Claude au format natif Anthropic permet de tirer pleinement parti du prompt caching et de réaliser jusqu'à 90 % d'économies.
Code pratique pour le Claude Prompt Caching : invocation au format natif Anthropic
Voici des exemples de code concrets pour montrer comment activer correctement le prompt caching de Claude.
Exemple d'appel de base : format natif Anthropic + Extended Thinking
curl https://api.apiyi.com/v1/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-VOTRE_CLÉ_API" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 16000,
"stream": false,
"thinking": {
"type": "enabled",
"budget_tokens": 10000
},
"messages": [
{
"role": "user",
"content": "Combien font 27 * 453 ?"
}
]
}'
Ceci est un appel de base au format natif Anthropic utilisant la fonctionnalité Extended Thinking. Voyons maintenant comment activer le prompt caching par-dessus.
Mode cache automatique : la manière la plus simple d'activer le cache Claude
Le cache automatique est le moyen le plus simple d'activer le prompt caching de Claude — il suffit d'ajouter le champ cache_control au niveau supérieur du corps de la requête :
curl https://api.apiyi.com/v1/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-VOTRE_CLÉ_API" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"cache_control": {"type": "ephemeral"},
"system": "Tu es un assistant spécialisé en documentation technique, aidant les utilisateurs à comprendre les méthodes d'utilisation et les meilleures pratiques des modèles d'IA. Tes réponses doivent être précises, concises et pratiques.",
"messages": [
{"role": "user", "content": "Quelles sont les principales caractéristiques de Claude Sonnet 4.6 ?"},
{"role": "assistant", "content": "Claude Sonnet 4.6 est un modèle haute performance lancé par Anthropic..."},
{"role": "user", "content": "Quelle est la taille de sa fenêtre de contexte ?"}
]
}'
En mode cache automatique, le système place automatiquement un point d'arrêt de cache sur le dernier bloc de contenu mis en cache. Dans une conversation à plusieurs tours, le point de cache avance automatiquement à mesure que la conversation s'allonge.
Mode cache explicite : contrôle précis du contenu mis en cache par Claude
Pour les scénarios nécessitant un contrôle fin du comportement du cache, vous pouvez placer cache_control sur des blocs de contenu spécifiques :
📄 Déplier pour voir l’exemple complet de code pour le cache explicite
curl https://api.apiyi.com/v1/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-VOTRE_CLÉ_API" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": "Tu es un assistant d'analyse de documents juridiques, expert dans l'analyse des clauses contractuelles et des risques juridiques."
},
{
"type": "text",
"text": "[Insérez ici le texte intégral d'un contrat juridique de 50 pages... environ 100 000 tokens de contenu]",
"cache_control": {"type": "ephemeral"}
}
],
"messages": [
{
"role": "user",
"content": "Veuillez analyser les clauses clés et les risques potentiels de ce contrat."
}
]
}'
Dans cet exemple, une grande quantité de documents juridiques est marquée comme contenu à mettre en cache. La première requête écrira dans le cache, et toutes les questions suivantes sur ce même document posées dans les 5 minutes toucheront le cache, ne coûtant que 10 % des frais de lecture.
Cache longue durée d'une heure : extension de la durée du cache Claude
Si la durée de cache par défaut de 5 minutes ne suffit pas, vous pouvez opter pour un cache d'une heure :
"cache_control": {"type": "ephemeral", "ttl": "1h"}
Le cache d'une heure est adapté pour :
- Les tâches de longue durée dans les workflows d'agents (dépassant 5 minutes)
- Les scénarios où l'intervalle entre les conversations utilisateur peut dépasser 5 minutes
- Les scénarios nécessitant une meilleure utilisation des limites de taux (les hits de cache ne sont pas décomptés des rate limits)
🚀 Démarrage rapide : Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour tester rapidement la fonctionnalité de prompt caching de Claude. La plateforme prend entièrement en charge le format natif de l'API Messages d'Anthropic, y compris le paramètre
cache_control, permettant de valider l'intégration en seulement 5 minutes.
Surveillance et débogage des performances du Prompt Caching de Claude
Une fois le cache activé, vous devez surveiller son efficacité via le champ usage dans la réponse de l'API.
Champs clés dans la réponse de cache de Claude
{
"usage": {
"input_tokens": 50,
"cache_creation_input_tokens": 100000,
"cache_read_input_tokens": 0,
"output_tokens": 500
}
}
| Champ | Signification |
|---|---|
input_tokens |
Nombre de tokens d'entrée après le point d'arrêt du cache |
cache_creation_input_tokens |
Nombre de tokens écrits dans le cache lors de cet appel |
cache_read_input_tokens |
Nombre de tokens lus depuis le cache |
output_tokens |
Nombre de tokens de sortie |
Formule de calcul du total des tokens d'entrée :
total_input = cache_read_input_tokens + cache_creation_input_tokens + input_tokens
Dépannage des causes courantes d'échec du cache (Cache Miss) de Claude
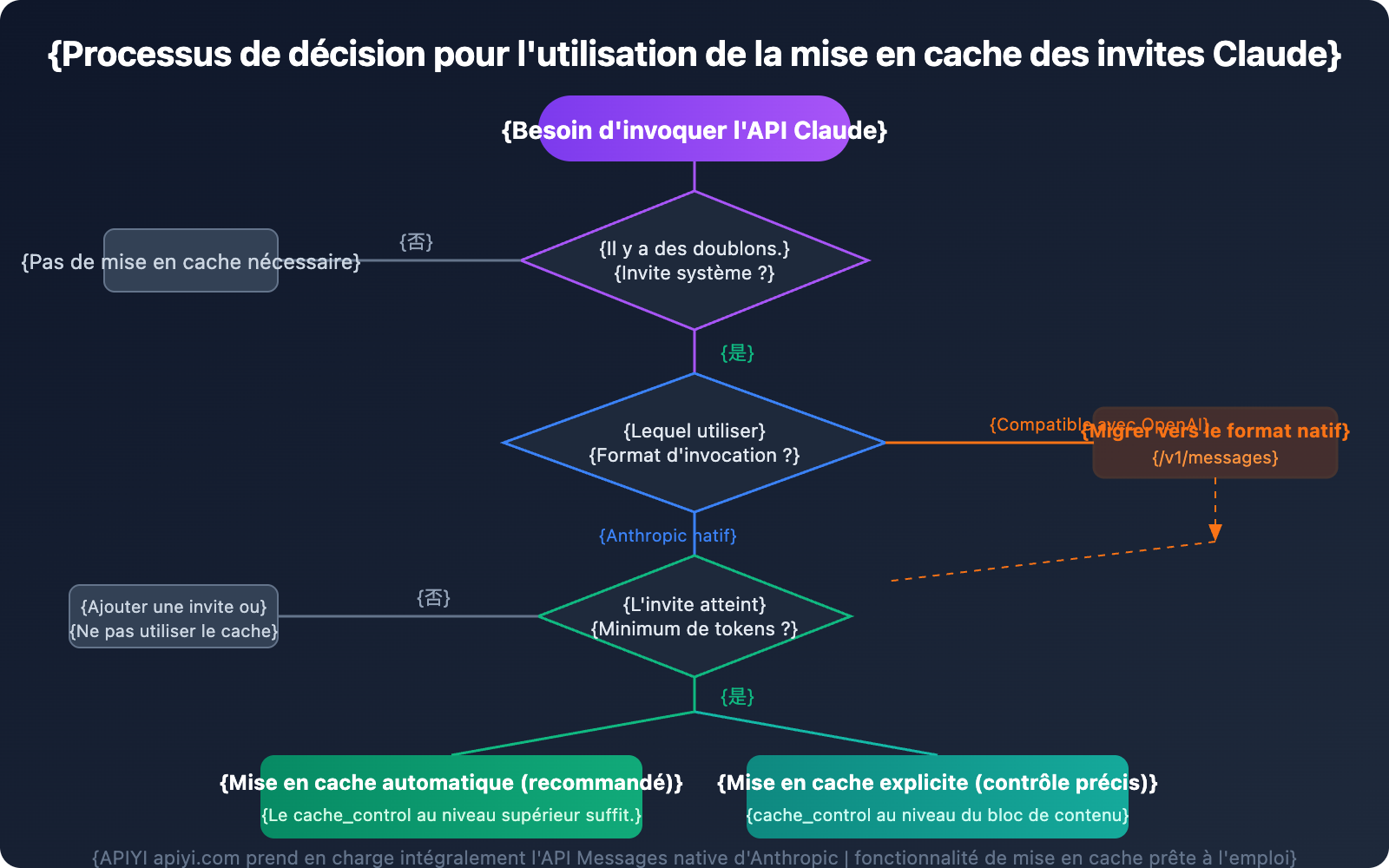
Si vous constatez que le cache n'est jamais utilisé, vérifiez les points suivants :
- Format d'appel incorrect : Utilisation du mode compatible OpenAI au lieu du format natif Anthropic.
- Contenu incohérent : La correspondance du cache nécessite un préfixe d'invite 100 % identique.
- Tokens insuffisants : Le nombre minimum de tokens requis pour la mise en cache par le modèle n'est pas atteint.
- Expiration par délai d'attente : Plus de 5 minutes d'inactivité entraînent l'expiration du cache.
- Modification des paramètres : Changement de
tool_choice, du contenu de l'image ou des paramètres de réflexion (thinking).
Exigences minimales de tokens de cache par modèle Claude
| Série de modèles | Nombre minimum de tokens mis en cache |
|---|---|
| Claude Opus 4.6 / Opus 4.5 | 4 096 tokens |
| Claude Sonnet 4.6 / Sonnet 4.5 / Sonnet 4 / Opus 4.1 / Opus 4 | 1 024 tokens |
| Claude Haiku 4.5 | 4 096 tokens |
| Claude Haiku 3.5 / Haiku 3 | 2 048 tokens |
Si votre invite ne contient pas le nombre minimum de tokens, même si vous avez marqué cache_control, cela ne fonctionnera pas — la requête sera traitée normalement mais ne sera pas mise en cache.
🎯 Astuce de débogage : Lors de l'invocation du modèle Claude via la plateforme APIYI (apiyi.com), vous pouvez rapidement déterminer si le cache est effectif grâce au champ
usagede la réponse. Sicache_read_input_tokensest à 0 et quecache_creation_input_tokensest également à 0, cela signifie que la fonction de cache n'est pas correctement activée.
FAQ sur le Claude Prompt Caching
Q1 : Puis-je utiliser le cache en appelant Claude via le mode de compatibilité OpenAI ?
Non. C'est une limitation explicitement déclarée par Anthropic. Le mode de compatibilité OpenAI (point de terminaison /v1/chat/completions) ne prend pas en charge le prompt caching. Vous devez impérativement utiliser le format natif de l'API Messages d'Anthropic (point de terminaison /v1/messages) pour bénéficier de la mise en cache.
Via la plateforme APIYI (apiyi.com), vous pouvez utiliser les deux formats pour appeler l'API Claude. Si vous avez besoin de la fonction de cache, choisissez simplement le point de terminaison /v1/messages.
Q2 : L'écriture en cache de Claude est plus chère que l'entrée standard, est-ce que ça en vaut vraiment la peine ?
Absolument. L'écriture en cache ne coûte que 25 % de plus que l'entrée de base (avec un TTL de 5 minutes), mais une récupération (cache hit) ne coûte que 10 % du prix initial. Dès que le même contenu est utilisé plus de 2 fois, vous rentrez dans vos frais et commencez à réaliser des économies. Prenons l'exemple d'une invite système (system prompt) de 100 000 tokens :
- Sans cache : 0,30 $ par appel (Sonnet 3.5/3.7)
- Écriture en cache : 0,375 $ (uniquement la première fois)
- Lecture du cache : 0,03 $ (pour chaque appel suivant)
- Vous commencez à économiser dès le 2ème appel.
Q3 : Comment migrer du format OpenAI vers le format natif Anthropic dans mon code ?
Voici les points clés du changement :
- Point de terminaison :
/v1/chat/completions→/v1/messages - En-tête (Header) : Ajouter
anthropic-version: 2023-06-01 - Format du message : La structure du tableau
messagesest globalement similaire. - Invite système : Extraire le contenu de
messagespour le placer dans un champ indépendant nommésystem. - Ajouter le paramètre
cache_control.
La plateforme APIYI (apiyi.com) prend en charge les deux points de terminaison. Lors de la migration, il vous suffit de modifier le chemin de la requête et le format, sans avoir besoin de changer votre clé API.
Q4 : Le cache Claude peut-il être partagé entre plusieurs requêtes ?
Le cache est partagé au sein d'un même Workspace (depuis le 5 février 2025, l'isolation est passée du niveau organisation au niveau Workspace). Le cache n'est jamais partagé entre différentes organisations.
Q5 : Peut-on cumuler le cache et l'API Batch ?
Oui. L'API Batch offre déjà une réduction de 50 %, et les multiplicateurs de prix du cache s'appliquent par-dessus cette base. La combinaison des deux permet d'atteindre une optimisation maximale des coûts. Pour les traitements par lots, il est recommandé d'utiliser un TTL de cache d'une heure pour maximiser le taux de réussite (hit rate).
Résumé : Les 3 points essentiels de la facturation du Claude Prompt Caching
D'après notre analyse, voici les 3 points clés à retenir concernant la facturation du prompt caching de Claude :
- Format natif Anthropic uniquement : La fonction de cache n'est disponible que sur le point de terminaison
/v1/messages. Le mode de compatibilité OpenAI (/v1/chat/completions) ne la supporte pas. - Le coût d'un hit n'est que de 10 % : Bien que la première écriture coûte 25 % de plus, chaque hit suivant ne coûte qu'un dixième du prix de base. Le retour sur investissement est atteint dès le 2ème appel.
- La méthode d'appel est cruciale : Utilisez le paramètre
cache_control: {"type": "ephemeral"}et assurez-vous de respecter le seuil minimum de tokens requis par le modèle pour la mise en cache.
Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour tester toutes les fonctionnalités du prompt caching de Claude. La plateforme supporte intégralement l'API Messages native d'Anthropic, vous aidant à utiliser les modèles Claude au meilleur coût.
Références
-
Documentation officielle d'Anthropic sur le Prompt Caching : Détails sur la fonctionnalité de mise en cache de l'API Claude
- Lien :
platform.claude.com/docs/en/build-with-claude/prompt-caching
- Lien :
-
Page de tarification officielle d'Anthropic : Tarification des modèles Claude et du cache
- Lien :
platform.claude.com/docs/en/about-claude/pricing
- Lien :
-
Documentation de compatibilité du SDK OpenAI : Explications sur les limitations des fonctionnalités en mode compatibilité
- Lien :
platform.claude.com/docs/en/api/openai-sdk
- Lien :
📝 Auteur : Équipe APIYI | Équipe technique APIYI, spécialisée dans l'intégration d'API de grands modèles de langage et le partage de connaissances techniques. Visitez apiyi.com pour découvrir plus de tutoriels techniques.