À seulement un jour de la conférence Google I/O 2026, Google ne parvient plus à garder ses secrets. Le Gemini 3.2 Flash a été déniché par des développeurs le 5 mai dernier, directement depuis l'application iOS Gemini et Google AI Studio, tandis que l'interface "Liquid Glass" (verre liquide) prévue pour le web a également été dévoilée en avance. Parmi les scénarios les plus impressionnants capturés par les testeurs internationaux, on note : la génération de 2200 lignes de code fonctionnel en une seule invite, ou encore la création d'une démo interactive du bureau Windows 98 à partir d'une simple instruction. Sur de nombreuses tâches de codage, il surpasse même son prédécesseur phare, le Gemini 3.1 Pro.
Cet article, basé sur les informations disponibles en anglais au 18 mai 2026, analyse les points clés de cette fuite : spécifications techniques, capacités de codage, stratégie tarifaire, interface, signaux liés aux agents et impact pour les développeurs, tout en proposant des recommandations pour une éventuelle migration.
Valeur ajoutée : 3 minutes pour comprendre la puissance réelle et le potentiel disruptif du Gemini 3.2 Flash, et savoir si vous devez préparer vos projets techniques avant l'annonce officielle lors de l'I/O.

Aperçu des informations clés sur Gemini 3.2 Flash
Avant même que Google ne publie son article de blog officiel, la version ayant fuité a déjà été testée en profondeur par les développeurs. Le tableau ci-dessous résume les faits vérifiables au 18 mai 2026.
| Élément | Détails |
|---|---|
| Date de découverte | 5 mai 2026, via l'application iOS Gemini et Google AI Studio (test A/B) |
| Lancement officiel prévu | Google I/O 2026, discours principal du 19-20 mai |
| Positionnement | Modèle intermédiaire de la série Flash, visant les capacités de codage du Gemini 3.1 Pro |
| Prix d'entrée | 0,25 $ / million de jetons (identique au Gemini 3.1 Flash-Lite) |
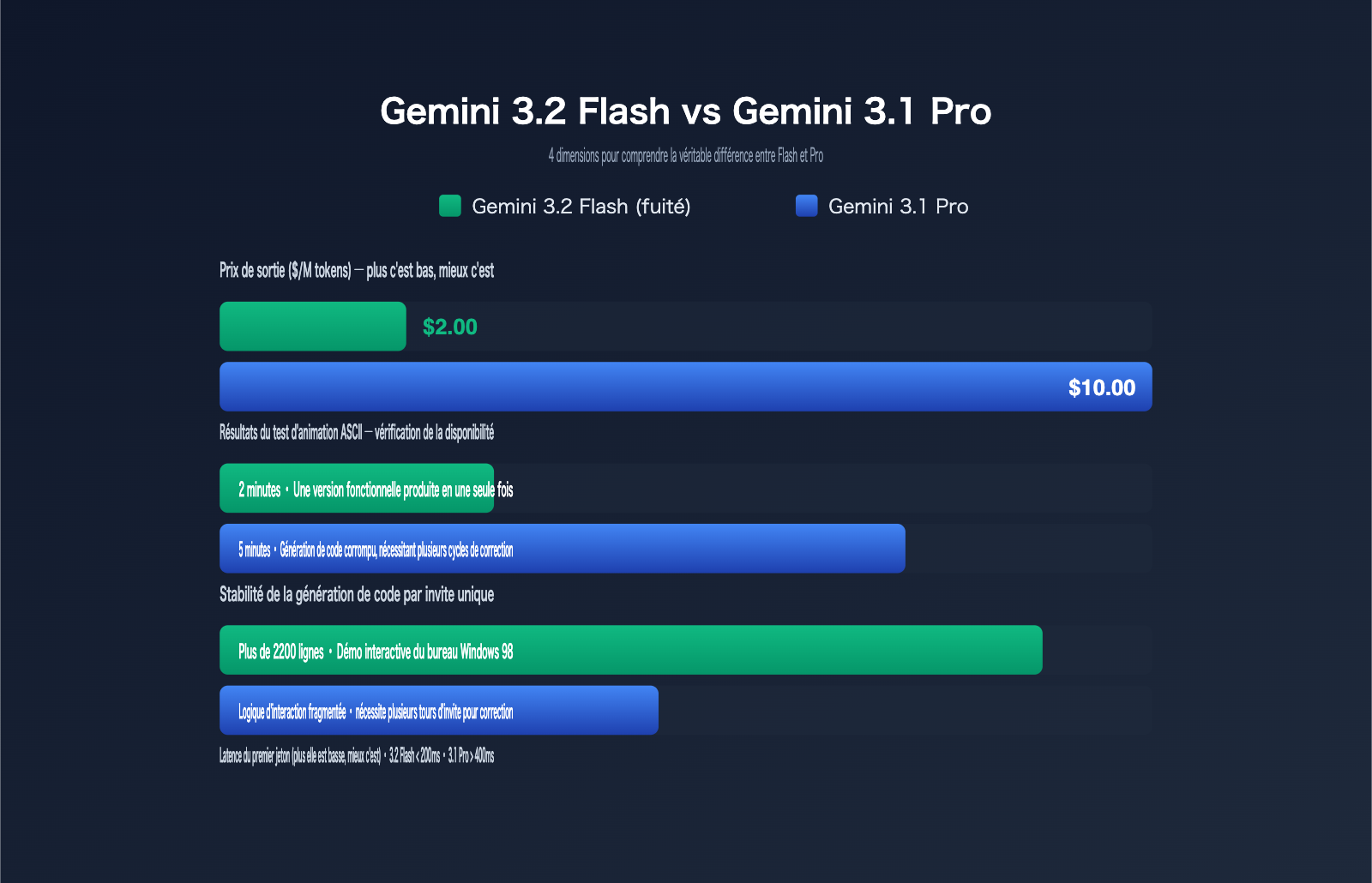
| Prix de sortie | 2,00 $ / million de jetons (soit 33 % de moins que les 3,00 $ du Gemini 3 Flash) |
| Fenêtre de contexte | Estimée à 1M de jetons (non confirmé officiellement) |
| Date limite de connaissances | Estimée à janvier 2026 |
| Latence de réponse | Inférieure à 200 ms sur certaines invites |
| Interface utilisateur | "Liquid Glass", avec champ de saisie en forme de pilule |
| Nouveautés | Apparition d'un onglet "Agents (Beta)" sur iOS |
Deux chiffres méritent une attention particulière : la réduction drastique du prix de sortie et le fait que ses performances ciblent non pas la génération précédente de Flash, mais le 3.1 Pro. Ces deux éléments détermineront l'impact réel sur votre pile technologique.
🎯 Conseil pour une vérification rapide : Avant l'ouverture de l'API officielle, nous vous recommandons de réserver vos accès à la série Gemini sur APIYI (apiyi.com). En uniformisant votre
base_url, il vous suffira de modifier le champmodelpour tester le 3.2 Flash avec vos scénarios réels dès le soir de l'I/O.
Analyse des capacités de codage de Gemini 3.2 Flash : une montée en gamme impressionnante
Ce qui a le plus surpris les développeurs lors de cette fuite, c'est la capacité du modèle Flash à "dépasser sa catégorie" sur les tâches de codage. La communauté internationale a réalisé de nombreux tests en aveugle via le mode Canvas d'AI Studio, et la conclusion est unanime : dans les scénarios de génération d'interfaces utilisateur (UI), de SVG complexes et d'HTML Canvas, Gemini 3.2 Flash surpasse désormais régulièrement Gemini 3.1 Pro.
Comparaison des trois scénarios de codage pour Gemini 3.2 Flash
Le tableau ci-dessous résume les résultats des trois tests comparatifs les plus cités par la communauté, basés sur des échantillons publics issus de LM Arena et d'AI Studio.
| Tâche de test | Gemini 3 Flash | Gemini 3.1 Pro | Gemini 3.2 Flash |
|---|---|---|---|
| Animation de ville ASCII en HTML plein écran | Code non fonctionnel | ~5 min, code corrompu | ~2 min, version directement fonctionnelle |
| Génération en une seule invite d'une démo bureau Windows 98 | Coque statique uniquement | Logique interactive fragmentée, nécessite des corrections | ~2200 lignes de code en une fois, fenêtres et menus interactifs |
| Illustration vectorielle SVG complexe | Chemins erronés, couleurs décalées | Visuellement correct, nécessite des ajustements | Visuellement correct, zéro erreur dès la première sortie |
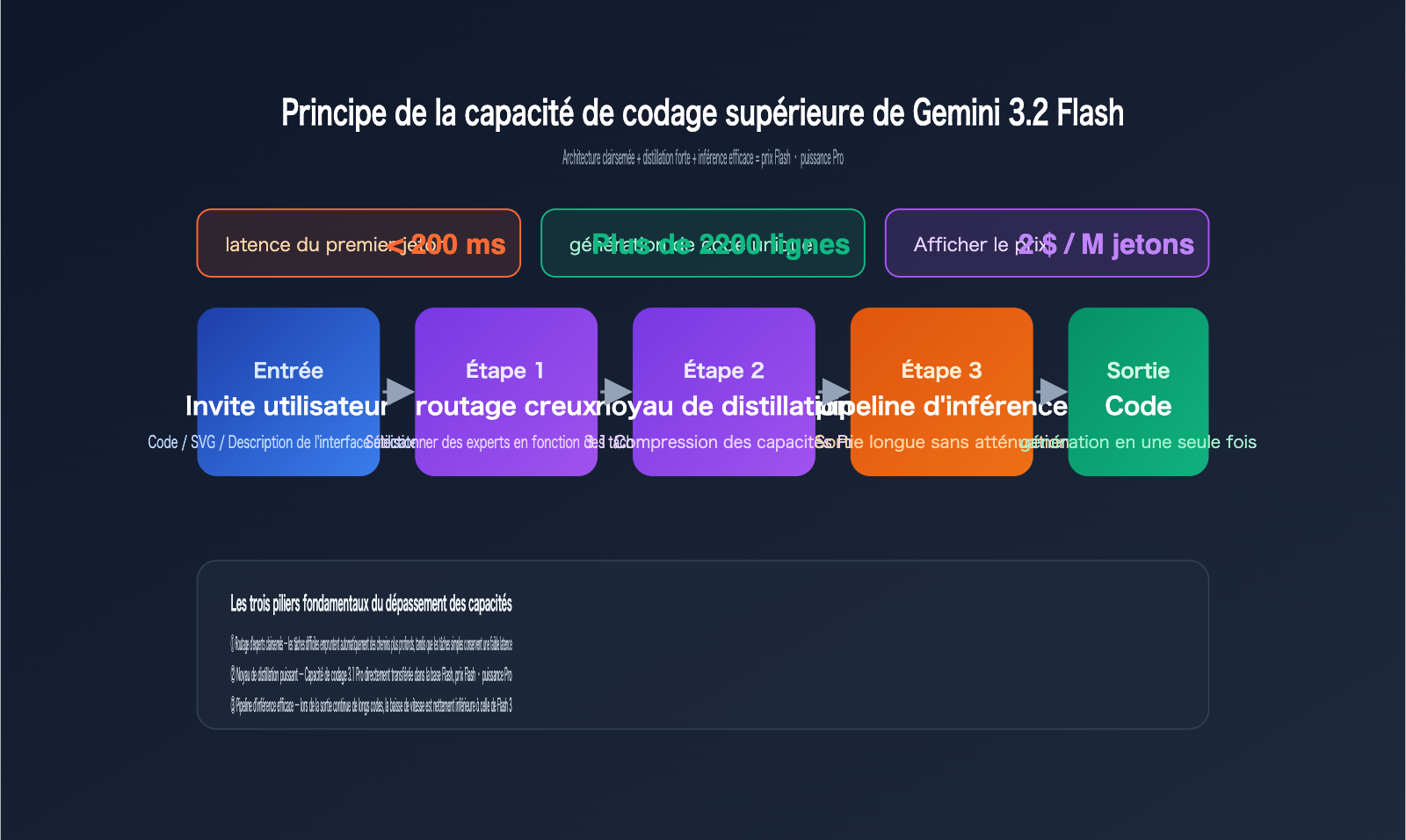
Ces trois tâches partagent un point commun : elles exigent que le modèle réalise, en une seule inférence, une "planification structurelle combinée à une génération de code longue". C'était précisément le point faible des modèles Flash par le passé. La stabilité de la version 3.2 Flash dans ces scénarios de sortie longue prouve que ses fondations ont été considérablement renforcées en termes de cohérence de contexte et de respect de la syntaxe.
Pourquoi Gemini 3.2 Flash est-il si performant ?
D'après les indices techniques disponibles, ce bond en avant ne provient pas d'une simple augmentation du nombre de paramètres, mais d'une optimisation technique globale. Les analyses internationales pointent vers quatre axes :
- Une distillation IA plus agressive : les capacités du 3.1 Pro ont été directement distillées dans une base Flash plus petite et plus rapide.
- Optimisation de l'architecture creuse : le routage des experts est plus précis, évitant de solliciter l'ensemble du modèle pour générer du code long.
- Système de routage interne amélioré : les tâches complexes empruntent automatiquement des chemins d'inférence plus profonds, tandis que les tâches simples conservent une latence minimale.
- Pipeline d'inférence efficace : la latence du premier jeton (token) est maintenue sous les 200 ms, avec une dégradation de vitesse très faible lors des sorties longues.
Pour les développeurs, le ressenti est immédiat : pour écrire un composant React/Vue, exécuter une requête SQL ou générer du code de visualisation fonctionnel, Flash peut désormais devenir votre premier choix par défaut, ne repassant au Pro que pour des besoins de raisonnement lourd ou de planification complexe en plusieurs étapes.
🚀 Conseil de test : Pour vérifier immédiatement les capacités de codage réelles de la version 3.2 Flash, nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) via une interface compatible OpenAI. Nous suggérons de préparer un ensemble d'invites "lourdes" (comme du HTML long, des SVG complexes, ou la réécriture de fichiers de code complets) et d'utiliser le même script pour comparer la qualité et la stabilité des résultats entre le 3.2 Flash et le 3.1 Pro.
Stratégie de tarification et estimation des coûts de Gemini 3.2 Flash
La série Flash a toujours été l'arme tarifaire de Google pour contrer la concurrence, et la version 3.2 Flash pousse ce concept à un nouveau sommet. Avec un prix de sortie de 2,00 $ par million de tokens, son coût unitaire pour des scénarios courants de codage ou de génération de textes longs se rapproche du niveau "mini" de GPT-5.5 Instant, tout en offrant des capacités proches de la version Pro.
Comparaison des prix : Gemini 3.2 Flash et la gamme Gemini
Le tableau ci-dessous compare les prix de la gamme Gemini actuellement visibles dans AI Studio. Toutes les données proviennent de pages publiques ou de métadonnées ayant fuité ; les tarifs de la version Pro sont basés sur la tarification standard de Vertex AI.
| Modèle | Entrée ($/M) | Sortie ($/M) | Cas d'usage |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | 0,25 | 1,50 | Tâches par lots à haute concurrence et faible coût |
| Gemini 3 Flash | 0,50 | 3,00 | Chat standard / Code moyen |
| Gemini 3.2 Flash (fuite) | 0,25 | 2,00 | Génération de code long / UI complexe / SVG |
| Gemini 3.1 Pro | 1,25 | 10,00 | Raisonnement complexe / Planification multi-étapes |
On constate que le 3.2 Flash s'aligne sur le prix d'entrée du Flash-Lite, tout en réduisant le prix de sortie d'un tiers par rapport au 3 Flash, alors qu'il rivalise en capacités avec le 3.1 Pro (facturé 10 $ par million de tokens en sortie). Pour une tâche de code complexe générant 1 million de tokens, l'utilisation du 3.2 Flash permet d'économiser environ 80 % par rapport au 3.1 Pro. Ces quatre modèles sont disponibles sur APIYI (apiyi.com) via une interface unifiée compatible avec OpenAI, permettant de répartir dynamiquement le trafic métier au sein d'un même projet sans avoir à réintégrer des SDK pour chaque niveau de performance.
Estimation des coûts mensuels pour Gemini 3.2 Flash
Pour rendre ces chiffres plus concrets, prenons un scénario métier réel : supposons que vous développiez un outil d'assistance à la programmation par IA, traitant en moyenne 5 000 requêtes de génération de code par jour, avec une moyenne de 1 000 tokens en entrée et 3 000 tokens en sortie.
| Modèle choisi | Coût journalier ($) | Coût mensuel ($) | Remarques |
|---|---|---|---|
| Gemini 3.1 Pro | 156,25 | 4 687,50 | Raisonnement puissant, mais surdimensionné pour le code |
| Gemini 3 Flash | 47,50 | 1 425,00 | Solution standard actuelle |
| Gemini 3.2 Flash (estimé) | 31,25 | 937,50 | Performances proches du Pro, coût réduit |
💰 Conseil d'optimisation des coûts : Pour les projets sensibles au budget, envisagez d'appeler les API de la gamme Gemini via la plateforme APIYI (apiyi.com). Elle propose une facturation à l'usage et un pool de crédits unifié, idéal pour permettre aux petites et moyennes équipes d'intégrer rapidement le 3.2 Flash dès sa sortie, sans avoir à gérer les factures de multiples fournisseurs.
L'interface "Liquid Glass" et les signaux Agents de Gemini 3.2 Flash
Le modèle n'est pas la seule surprise de cette fuite. Apparaissant simultanément avec Gemini 3.2 Flash, on découvre une nouvelle interface utilisateur baptisée "Liquid Glass" par les développeurs, ainsi qu'un onglet masqué "Agents (Beta)". Ces deux éléments en disent plus sur la stratégie globale de Google pour la conférence I/O 2026 que le modèle lui-même.
Points clés de l'interface web de Gemini 3.2 Flash
"Liquid Glass" marque un changement de style majeur par rapport au design plat précédent, se caractérisant par :
- Une zone de saisie d'invite en forme de pilule avec des reflets dégradés doux.
- Une couche d'arrière-plan translucide qui pulse au rythme de la conversation.
- Un sélecteur de modèle déplacé dans un menu déroulant en haut à gauche, mettant en évidence l'action de "changement de modèle".
- Des bulles de dialogue utilisant un contraste plus élevé avec des espaces blancs, et des blocs de code longs développés par défaut.
Cette interface place la "possibilité de changer de modèle" à un endroit visuellement stratégique, préparant le terrain pour la matrice de modèles de la gamme Gemini : l'utilisateur est éduqué par défaut à "choisir un modèle en fonction de la tâche", ce qui est parfaitement aligné avec la philosophie des plateformes d'agrégation multi-fournisseurs.
Ce que Gemini 3.2 Flash et Agents (Beta) suggèrent sur la stratégie agentique
Plus intéressant encore pour les développeurs, l'application Gemini sur iOS présente un onglet inachevé "Agents (Beta)". Si l'on considère les investissements continus de Google au cours de l'année écoulée dans Gemini CLI, Agent Builder et Vertex AI Agent, on peut raisonnablement en déduire que l'I/O 2026 mettra en avant une ligne directrice axée sur les agents. Gemini 3.2 Flash sera très probablement positionné comme le "cerveau par défaut des agents" : assez rapide pour supporter des boucles multi-étapes et assez économique pour gérer une consommation élevée de tokens.
🎯 Conseil d'architecture : Si vous développez votre propre framework d'agents, nous vous suggérons d'utiliser APIYI (apiyi.com) pour placer la gamme Gemini derrière la même couche d'orchestration que les modèles Claude et GPT. Une fois le 3.2 Flash officiellement disponible, il vous suffira de modifier le champ
modelpour vérifier s'il surpasse vos solutions actuelles en tant que "cerveau d'agent", évitant ainsi d'être verrouillé par un seul fournisseur.
Exemple d'intégration et interface unifiée pour Gemini 3.2 Flash
Bien que l'API officielle de la version 3.2 Flash ne soit pas encore publique, ses spécifications d'interface devraient être parfaitement alignées avec la série Gemini 3.x. Voici un exemple minimaliste utilisant l'interface unifiée d'APIYI, conçu pour que le passage à la version 3.2 Flash ne nécessite quasiment aucune modification.
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.2-flash", # À remplacer par l'ID officiel une fois disponible
messages=[
{"role": "user", "content": "Crée un bureau Windows 98 interactif en HTML + Canvas sur une seule page"}
],
)
print(response.choices[0].message.content)
Voir le code complet avec streaming et gestion des erreurs
from openai import OpenAI
from openai import APIError, RateLimitError
import time
client = OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
PROMPT = """Crée une démo de bureau Windows 98 interactif en HTML + Canvas sur une seule page.
Exigences : fenêtres déplaçables, menu Démarrer fonctionnel en bas à gauche, et icônes de bureau cliquables pour ouvrir des fenêtres."""
def call_gemini_3_2_flash(prompt: str, retries: int = 3):
for attempt in range(retries):
try:
stream = client.chat.completions.create(
model="gemini-3.2-flash",
messages=[{"role": "user", "content": prompt}],
stream=True,
max_tokens=8192,
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
return
except RateLimitError:
time.sleep(2 ** attempt)
except APIError as e:
print(f"\n[Erreur API] {e}")
return
if __name__ == "__main__":
call_gemini_3_2_flash(PROMPT)
La force de cette approche réside dans le découplage entre base_url et model : pour passer de Flash à Pro, il suffit de modifier une seule ligne. Le reste du code métier, la gestion des erreurs et la logique de streaming restent identiques, ce qui est idéal pour effectuer des évaluations A/B dès la sortie du modèle.
Analyse de l'impact de Gemini 3.2 Flash pour les développeurs et l'industrie
Si cette fuite a suscité autant de discussions dans la communauté des développeurs, ce n'est pas simplement parce qu'un nouveau modèle "Flash" est apparu. C'est parce qu'il brise le dogme tacite selon lequel "Flash est bon marché mais limité aux tâches simples, tandis que Pro est coûteux mais indispensable pour le code complexe".
Impact sur les développeurs indépendants et les petites équipes
Pour les développeurs indépendants sensibles au budget, le 3.2 Flash est un véritable tournant. Des tâches qui nécessitaient auparavant le modèle Pro pour être stables — comme la génération de code complet ou les visualisations complexes — peuvent désormais être traitées par Flash, ce qui pourrait réduire les coûts mensuels de 50 % à 80 %.
Pour les petites équipes, cela ouvre de nouvelles possibilités produit : des fonctionnalités comme les assistants de programmation IA, les plateformes de développement low-code ou les générateurs de rapports automatisés, autrefois trop coûteuses à exploiter, peuvent désormais être intégrées comme des capacités permanentes et réactives.
Impact sur les grandes équipes et les architectures multimodèles
Pour les grandes équipes utilisant déjà des architectures multimodèles, le 3.2 Flash ne remplacera pas immédiatement le modèle Pro, mais il forcera une optimisation de la stratégie de routage. La couche de routage devra choisir dynamiquement entre Flash et Pro selon la nature de la tâche, plutôt que d'utiliser un modèle unique pour tout. Cela impose des exigences plus élevées en matière de passerelle d'API, de facturation unifiée et de journalisation.
Concrètement, les grandes équipes devraient anticiper sur trois points : premièrement, mettre en place un suivi précis des tokens pour distinguer la consommation réelle entre Flash et Pro ; deuxièmement, découpler les invites (prompts) des modèles via un système de templates ; et troisièmement, préparer un mécanisme de basculement progressif pour migrer les modules métier lors du lancement officiel du 3.2 Flash, limitant ainsi les risques en production.
Impact sur la concurrence
Le même jour, OpenAI a lancé GPT-5.5 Instant, axé sur la "réduction des hallucinations et le renforcement de la véracité". Cela crée une opposition directe avec la stratégie de Google : OpenAI mise sur des scénarios verticaux à haute valeur ajoutée, tandis que Google parie sur le codage grand public et les agents. De son côté, Anthropic n'a pas encore réagi, mais la "prime à la performance" dont bénéficiait la série Claude pour le code sera désormais sous pression face aux tarifs agressifs de la gamme Flash.
FAQ sur Gemini 3.2 Flash
Q1 : Quand l’API de Gemini 3.2 Flash sera-t-elle officiellement disponible ?
Selon les fuites et le rythme habituel des conférences Google I/O, il est fort probable que Gemini 3.2 Flash soit officiellement annoncé lors de la keynote de l'I/O 2026, les 19 et 20 mai, et rendu disponible via Vertex AI et AI Studio le jour même ou le lendemain. Les plateformes d'agrégation tierces intègrent généralement ces nouveautés sous 24 à 48 heures. Je vous conseille de surveiller les annonces de nouveaux modèles sur APIYI (apiyi.com) pour pouvoir les tester immédiatement via une interface unifiée.
Q2 : Gemini 3.2 Flash va-t-il remplacer Gemini 3.1 Pro ?
Pas totalement, du moins pas à court terme. Le modèle 3.2 Flash surpasse son prédécesseur sur des tâches comme le codage, la génération de longs scripts ou le travail sur SVG / Canvas. Cependant, pour le raisonnement sur de longues chaînes, la planification complexe en plusieurs étapes ou les scénarios financiers/juridiques exigeant une rigueur causale stricte, le modèle Pro reste plus fiable. La stratégie la plus pertinente est le routage par tâche : utilisez 3.2 Flash pour le code et l'UI, et gardez 3.1 Pro pour le raisonnement profond et les décisions à haut risque. Il suffit de gérer la distribution des modèles au niveau de votre passerelle API sans avoir à réécrire votre logique métier.
Q3 : La génération de 2200 lignes de code par Gemini 3.2 Flash est-elle réelle ?
La démonstration d'un bureau Windows 98 en 2200 lignes, qui circule dans la communauté des développeurs, provient d'échantillons de tests réalisés avec le mode Canvas d'AI Studio. Ce qui est confirmé par des recoupements indépendants, c'est que la stabilité de 3.2 Flash pour générer de très longs blocs de code fonctionnels en une seule invite est nettement supérieure à celle de 3 Flash et 3.1 Pro. Bien qu'il faille attendre l'ouverture officielle de l'API pour une reproduction complète, cette avancée en matière de "stabilité de sortie longue" a été validée par plusieurs testeurs indépendants.
Q4 : Quelle est la taille de la fenêtre de contexte de Gemini 3.2 Flash ?
Bien qu'aucune donnée officielle ne soit disponible dans les métadonnées ayant fuité, tout porte à croire, au vu des spécifications de la série Gemini 3.x, que 3.2 Flash conservera une fenêtre de contexte de 1M de tokens. C'est un point crucial pour le traitement de dépôts de code volumineux, de documents complets ou de transcriptions vidéo, et c'est ce qui permet physiquement cette capacité à générer plus de 2000 lignes de code de manière stable.
Q5 : Comment les développeurs peuvent-ils accéder au plus vite à Gemini 3.2 Flash ?
Dès sa sortie, le moyen le plus fiable pour les développeurs est de passer par une plateforme d'agrégation accessible localement. Nous recommandons d'utiliser APIYI (apiyi.com) pour accéder à Gemini 3.2 Flash. La plateforme utilise une interface compatible avec OpenAI, ce qui permet de réutiliser votre code existant sans effort : il suffit de modifier les champs base_url et model. Vous pourrez ainsi invoquer Gemini, Claude ou GPT au sein d'un même projet, facilitant grandement les évaluations comparatives et les changements de modèle.
Conclusion : Ce que signifie l'exposition anticipée de Gemini 3.2 Flash
Pour revenir à notre remarque initiale : "La conférence n'a pas encore eu lieu, mais Google ne peut plus rien cacher". Depuis le lancement discret sur AI Studio le 5 mai, la communauté a décortiqué Gemini 3.2 Flash sous toutes ses coutures : ID de modèle, interface Liquid Glass, étiquettes Agents et démos de code. Ce n'est pas seulement une fuite de produit, c'est l'envoi de trois signaux clairs :
- Le positionnement "Flash" monte en gamme : Google redéfinit la hiérarchie des modèles en combinant "bas prix et haute capacité de codage".
- La stratégie des Agents se précise : 3.2 Flash est pressenti pour devenir le socle par défaut des applications agentiques.
- La valeur de l'agrégation multi-modèles est décuplée : ceux qui peuvent intégrer et évaluer les modèles le plus rapidement gagneront un avantage compétitif majeur.
Pour les développeurs, l'enjeu n'est pas de parier sur les détails de l'annonce lors de l'I/O, mais de préparer dès maintenant une infrastructure technique unifiée pour l'accès, l'évaluation et la facturation. Ainsi, dès que 3.2 Flash sera disponible, vous pourrez lancer vos tests de charge immédiatement. Nous vous recommandons d'utiliser APIYI (apiyi.com) pour valider rapidement les performances et obtenir des données réelles sur vos cas d'usage dès le soir de la keynote, plutôt que d'attendre les benchmarks de la communauté.
Auteur : L'équipe technique APIYI — Spécialisée dans l'ingénierie des API de grands modèles de langage. Pour en savoir plus sur les coûts et les performances des modèles Gemini, Claude et GPT dans des scénarios métier réels, visitez APIYI (apiyi.com) pour accéder aux derniers rapports d'évaluation et à des crédits de test gratuits.