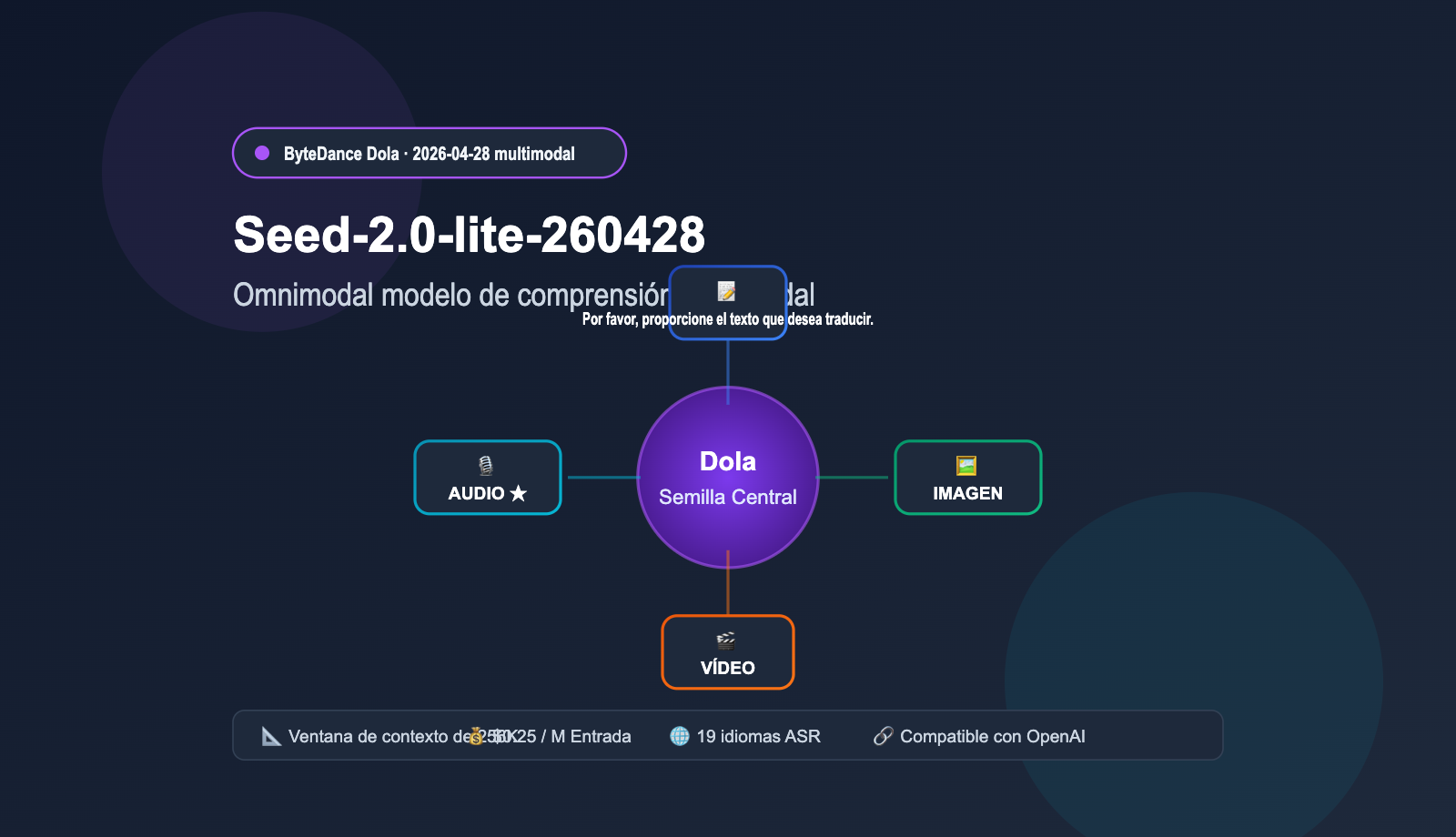
Una actualización que todo desarrollador debería tener en el radar: la familia de modelos base Dola de ByteDance lanzó el 28 de abril de 2026 su primer modelo de comprensión "Omnimodal", el Seed-2.0-lite-260428, que admite de forma nativa la entrada de cuatro modalidades: video, imagen, audio y texto. Este es el primer modelo de la familia Dola Seed capaz de "ver y oír" simultáneamente, además de haber recibido mejoras en tareas de agentes, programación (coding) e interfaces gráficas (GUI). Este artículo, basado en las especificaciones oficiales de BytePlus ModelArk, los benchmarks públicos de ByteDance Seed y las pruebas de integración realizadas a través de APIYI (apiyi.com), explica en detalle las capacidades del modelo, los pormenores de la comprensión de audio y sus escenarios de aplicación típicos.
I. ¿Qué es Seed-2.0-lite-260428?: Posicionamiento central y puntos de actualización
Seed-2.0-lite-260428 es una iteración importante de ByteDance Seed lanzada el 28 de abril de 2026. El modelo base sigue utilizando el Seed-2.0-Lite lanzado a principios de marzo, pero por primera vez incorpora la "entrada de audio" como una capacidad nativa, llevando esta línea de productos a una etapa verdaderamente "omnimodal". El número 260428 en el nombre del modelo corresponde a la fecha de lanzamiento (28 de abril de 2026).
1.1 El primer modelo omnimodal de la familia Dola de ByteDance
En la familia Dola Seed anterior, las capacidades de texto y las capacidades multimodales estaban separadas en diferentes ramas. Seed-2.0-lite-260428 unifica el razonamiento de video, imagen, audio y texto en un mismo modelo, lo que significa que puede "ver escenas de video" y "escuchar contenido de audio" simultáneamente, realizando juicios conjuntos y búsquedas temporales basadas en ello. Esta arquitectura unificada es crucial para aplicaciones de tipo agente, ya que muchas tareas reales (como la moderación de video, el resumen de reuniones o el control de calidad en atención al cliente) requieren naturalmente un razonamiento multimodal.
1.2 Resumen de las especificaciones principales del modelo
La siguiente tabla resume los parámetros principales de Seed-2.0-lite-260428 en BytePlus ModelArk, facilitando que los lectores determinen rápidamente si se ajusta a las necesidades de su negocio.
| Especificación | Parámetro |
|---|---|
| ID del modelo API | seed-2-0-lite-260428 |
| Familia de modelos | ByteDance Seed / Dola |
| Fecha de lanzamiento | 28-04-2026 |
| Ventana de contexto | 262,144 tokens (aprox. 256K) |
| Salida máxima | 131,072 tokens (aprox. 128K) |
| Modalidades de entrada | Texto + Imagen + Video + Audio |
| Precio de entrada | $0.25 / M tokens |
| Precio de salida | $2.00 / M tokens |
| Compatibilidad de interfaz | API compatible con OpenAI |
II. Las 4 capacidades clave de comprensión multimodal de Seed-2.0-lite-260428
La capacidad multimodal del modelo no consiste simplemente en "conectar" diversas entradas, sino en realizar un razonamiento conjunto a través de una representación unificada. La documentación oficial resume sus capacidades principales en cuatro ejes.
2.1 Razonamiento conjunto de audio y video con recuperación temporal
El modelo puede analizar simultáneamente la información visual y auditiva de un video, determinando con precisión si lo que se "ve" coincide con lo que se "escucha". Por ejemplo, puede identificar si las expresiones faciales de una persona en un video coinciden con su tono emocional, o si los movimientos de los objetos en pantalla corresponden a los efectos de sonido correctos. Esta capacidad de alineación audiovisual es extremadamente útil en escenarios como la moderación de videos y la detección de deepfakes.
2.2 Descomposición profunda de video y seguimiento temporal prolongado
Para videos largos, Seed-2.0-lite-260428 permite extraer pistas clave a través de múltiples segmentos temporales, rastreando continuamente el progreso de personas y eventos. Realiza razonamientos de varios pasos entre múltiples fotogramas para reconstruir las relaciones de los eventos y el contexto del comportamiento. A diferencia de los métodos tradicionales que describen fotograma a fotograma, su capacidad de "comprensión temporal prolongada" es ideal para tareas como la revisión de videos de vigilancia o como asistente de edición de documentales.
2.3 Capacidades mejoradas de Agente y codificación
El modelo posee una capacidad de ejecución estable y confiable en tareas complejas de larga duración, además de capacidades de desarrollo full-stack profundo. Esto significa que los desarrolladores pueden integrarlo en marcos de trabajo de Agentes para ejecutar un ciclo completo que incluya planificación, invocación de herramientas, revisión de pasos históricos y generación de código, sin necesidad de dividir la tarea entre varios modelos distintos.
2.4 Interfaz unificada para la comprensión de GUI y ejecución de operaciones
La capacidad de GUI se integra en una única interfaz; el modelo no solo puede comprender capturas de pantalla (botones, formularios, menús), sino también emitir instrucciones de operación (coordenadas de clic, entrada de texto). Esto supone una mejora directa en las capacidades para pruebas automatizadas, Agentes de escritorio y aplicaciones de tipo RPA.
III. Análisis profundo de la capacidad de comprensión de audio de Seed-2.0-lite-260428
El audio es la mayor capacidad diferenciadora de esta actualización, por lo que merece un análisis detallado. El modelo ha obtenido resultados impresionantes en varios puntos de referencia (benchmarks) de audio líderes en la industria.
3.1 Resultados en puntos de referencia de audio principales
La siguiente tabla resume los resultados oficiales publicados por ByteDance Seed, abarcando tres dimensiones: reconocimiento de voz (ASR), comprensión del lenguaje hablado y voz en entornos reales.
| Benchmark | Tipo de tarea | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | ASR inglés (limpio) | 1.07 WER |
| LibriSpeech test-other | ASR inglés (ruido) | 2.17 WER |
| WenetSpeech test-net | ASR chino (web) | 4.47 WER |
| WenetSpeech test-meeting | ASR reuniones chino | 5.31 WER |
| Fleurs (15 idiomas) | ASR multilingüe | 74.70 |
| MMSU | Comprensión oral | 86.54 |
| WildSpeech | Voz en entorno real | 75.81 |
Un WER de 1.07 en LibriSpeech test-clean ya se sitúa en el nivel más alto de la industria, superando los resultados equivalentes del Whisper large-v3 público; las puntuaciones en MMSU y WildSpeech también son ligeramente superiores a los datos públicos de Gemini 3.1 Pro, lo que demuestra que el modelo alcanza un nivel de buque insignia convencional en términos de "comprensión", y no solo de "dictado".
3.2 Transcripción en 19 idiomas y traducción mutua en 14 idiomas
La documentación oficial indica que el modelo admite la transcripción de voz en 19 idiomas y la traducción mutua entre 14 idiomas, destacando la traducción bidireccional entre chino e inglés como un área de optimización prioritaria. Esto significa que, para una misma grabación de una reunión multilingüe, el modelo puede generar subtítulos y traducciones en un idioma unificado, ideal para equipos transfronterizos, atención al cliente de comercio electrónico internacional, entre otros.
3.3 Más allá de la "transcripción": emociones, sonidos ambientales y detalles musicales
A diferencia de los modelos ASR tradicionales, Seed-2.0-lite-260428 puede capturar información semántica que va más allá del "contenido textual": fluctuaciones emocionales del hablante (ira, duda, entusiasmo), sonidos del entorno (cristales rotos, aplausos, bocinas de autos) y detalles musicales (ritmo, instrumentos, estilo). Estas dimensiones tienen un valor directo para negocios como el control de calidad en atención al cliente, la moderación de contenido y la recomendación musical.
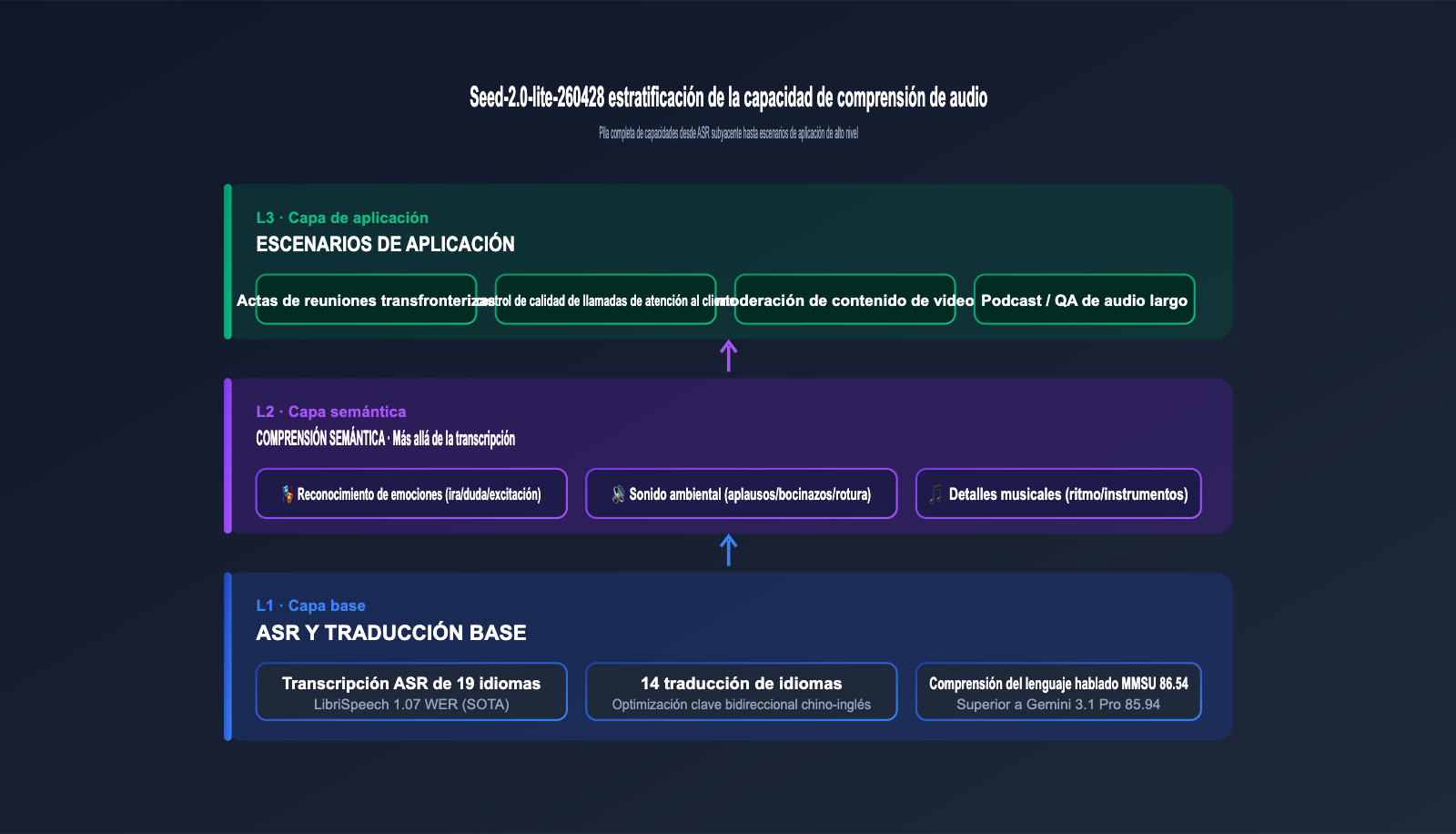
🎯 Sugerencia de integración: En escenarios que requieren la sinergia de "audio + texto", como actas de reuniones transfronterizas, control de calidad de atención al cliente y moderación de contenido de video, recomendamos invocar Seed-2.0-lite-260428 directamente a través de APIYI apiyi.com. Con un solo
base_urlpodrá obtener los beneficios duales del razonamiento multimodal y una ventana de contexto de 256K, sin necesidad de construir su propia infraestructura de procesamiento de voz.
IV. Comparativa de Seed-2.0-lite-260428 frente a los principales modelos multimodales
Para determinar la posición de este modelo en 2026, la mejor forma es compararlo directamente con los modelos multimodales insignia de la misma época, como GPT-4o y Gemini 3 Pro.
4.1 Comparativa de capacidades de los modelos multimodales líderes
| Dimensión | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| Entrada de texto | ✓ | ✓ | ✓ |
| Entrada de imagen | ✓ | ✓ | ✓ |
| Entrada de video | ✓ | ✓ | ✓ |
| Entrada de audio | ✓ | ✓ | ✓ |
| Ventana de contexto | 262K | 128K | 1M |
| Precio de entrada / M | $0.25 | $2.50 | $1.25 |
| Precio de salida / M | $2.00 | $10.00 | $10.00 |
| Reconocimiento de emociones en audio | ✓ | ✓ | ✓ |
| Optimización de audio en chino | Alta (optimizado con WenetSpeech) | Estándar | Estándar |
Como se puede observar, la ventaja principal de Seed-2.0-lite-260428 es su combinación de "precio + audio en chino + ventana de contexto larga de 256K", lo que lo hace destacar en términos de rentabilidad para tareas como el procesamiento de audio y video multilingüe o el resumen de reuniones extensas. Por su parte, GPT-4o y Gemini 3 Pro siguen manteniendo la ventaja en capacidades integrales en inglés y en amplitud de ecosistema, siendo ideales para escenarios de uso general.

🎯 Recomendación de selección: Si tu negocio se centra principalmente en el procesamiento de audio y video en chino y eres sensible a los costos, Seed-2.0-lite-260428 es actualmente una opción con una relación calidad-precio extremadamente alta. Si tu enfoque es principalmente en inglés o en la generación creativa multilingüe intensiva, puedes acceder a estos tres modelos insignia a través de la puerta de enlace unificada de APIYI (apiyi.com) y realizar el enrutamiento según el escenario.
V. Guía rápida para invocar Seed-2.0-lite-260428 a través de APIYI
El modelo es totalmente compatible con la interfaz de estilo OpenAI, lo que hace que el costo de migración sea extremadamente bajo. A continuación, presentamos un ejemplo mínimo de invocación para convertir un segmento de imagen o audio en una descripción estructurada.
5.1 Ejemplo mínimo de interfaz compatible con OpenAI
from openai import OpenAI
# Configuración del cliente con APIYI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
# Invocación del modelo para análisis multimodal
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Por favor, describe el contenido, la emoción y el sonido de fondo de este audio."},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
Al apuntar la base_url al punto de acceso unificado de APIYI (apiyi.com) y cambiar el parámetro model, puedes invocar Seed-2.0-lite-260428 junto con otros modelos multimodales utilizando el mismo SDK, sin necesidad de reescribir el código de tu aplicación.
5.2 Escenarios de aplicación típicos para Seed-2.0-lite-260428
La siguiente tabla resume varios escenarios típicos y los beneficios que obtienen de la característica de "inferencia unificada de audio + video + texto" de este modelo.
| Escenario de aplicación | Capacidad clave | Valor de negocio |
|---|---|---|
| Minutas de reuniones transfronterizas | ASR en 19 idiomas + traducción en 14 idiomas + ventana de contexto de 256K | Generación de minutas bilingües con un clic |
| Control de calidad de llamadas de atención al cliente | Reconocimiento de emociones + detección de ruido ambiental + análisis de audio largo | Marcado automático de ira/interrupciones/exceso de tiempo |
| Moderación de contenido de video | Inferencia conjunta de audio y video + seguimiento temporal prolongado | Identificación sincronizada de escenas peligrosas y sonidos sospechosos |
| QA de podcasts / videos largos | Ventana de contexto de 256K + transcripción de audio | Preguntas y respuestas directas sobre horas de contenido de audio |
| Automatización de agentes de escritorio | Comprensión de GUI + invocación de herramientas | Ejecución de flujos de trabajo complejos entre aplicaciones |
VI. Preguntas frecuentes sobre Seed-2.0-lite-260428
6.1 ¿Cómo debo completar el campo "model" al realizar la invocación de la API?
Simplemente completa el campo con seed-2-0-lite-260428. Ten en cuenta que el separador es un guion, no un guion bajo; el sufijo 260428 es el número de versión (28 de abril de 2026), no lo omitas, de lo contrario podrías ser redirigido a una versión anterior. Puedes consultar la lista de modelos en el panel de control de APIYI (apiyi.com) para asegurarte de estar alineado con el lanzamiento más reciente.
6.2 ¿Qué formatos y duraciones de audio son compatibles?
El modelo sigue la convención del campo input_audio al estilo OpenAI, siendo compatible con los formatos comunes MP3, WAV, M4A y FLAC. La duración máxima y la frecuencia de muestreo específicas dependen de la documentación oficial de ModelArk; se recomienda que la entrada única no supere los 30 minutos para garantizar la estabilidad de la inferencia. Los audios extremadamente largos pueden segmentarse antes de procesarlos y luego combinar los resultados.
6.3 ¿Cuál es la diferencia con Seed-2.0-Lite sin el sufijo 260428?
La versión sin sufijo es la primera generación de Seed-2.0-Lite lanzada el 10 de marzo, la cual solo admite texto, imágenes y video; la versión 260428 es la actualización multimodal completa lanzada el 28 de abril, que añade entrada de audio y capacidades de inferencia conjunta de audio y video. Si tu negocio utiliza audio, debes usar la versión con sufijo.
6.4 ¿La facturación se basa en tokens o en la duración del audio?
El modelo se factura de forma unificada por tokens; el audio se codifica internamente como tokens antes de participar en el cálculo. El precio actual es de $0.25 por millón de tokens de entrada y $2.00 por millón de tokens de salida. La cantidad de tokens correspondientes a un segmento de audio se puede consultar en el "Historial de facturación" del panel de control de APIYI, lo que facilita la estimación y optimización de costos.
6.5 ¿Es compatible con salida en streaming y llamadas a funciones (Function Call)?
Es totalmente compatible. Seed-2.0-lite-260428 admite los campos stream=true y tools del protocolo estándar de Chat Completions de OpenAI, por lo que puede integrarse directamente en marcos de trabajo convencionales como LangChain, LangGraph y OpenAI Agents SDK sin necesidad de modificaciones especiales.
VII. Conclusión: Los modelos omnimodales llevan a las aplicaciones multimodales a la era de la "inferencia unificada"
El valor de Seed-2.0-lite-260428 no reside simplemente en "añadir una capacidad de audio", sino en su capacidad para unificar el procesamiento de vídeo, imagen, audio y texto bajo un mismo modelo. Para aquellas empresas que operan de forma inherentemente multimodal (reuniones, atención al cliente, moderación de contenido, análisis de vídeo, automatización de agentes), esta "inferencia unificada" supone una simplificación arquitectónica real: ya no es necesario combinar tres modelos distintos para ASR, visión y texto, ni preocuparse por la pérdida de contexto entre modelos.
Desde la perspectiva de los costes y los escenarios en chino, este modelo ofrece una ventaja competitiva muy clara entre los modelos insignia actuales. Su precio de $0,25 por millón de tokens de entrada hace que el procesamiento de audio y vídeo a gran escala sea viable a nivel de ingeniería, y su ventana de contexto de 256K es suficiente para cubrir escenarios de audio y vídeo de larga duración.
Si necesitas invocar de forma unificada Seed-2.0-lite-260428 junto con otros modelos multimodales insignia bajo una misma base_url, puedes visitar la documentación oficial de APIYI en apiyi.com para consultar los ejemplos de integración completos y la lista de modelos disponibles.
Autor: Equipo de APIYI — Proporcionamos servicios de servicio proxy de API y enrutamiento multimodelo estables y eficientes para desarrolladores de IA en todo el mundo. Para más detalles, visita apiyi.com