Nota del autor: Análisis profundo de la capacidad de segmentación semántica de escenas urbanas de GPT-image-2: 4 escenarios reales, cálculo automático del índice de visión verde, comparación de precisión y eficiencia con modelos tradicionales como DeepLabV3+, y recomendaciones de aplicación en planificación urbana y diseño de paisajes.
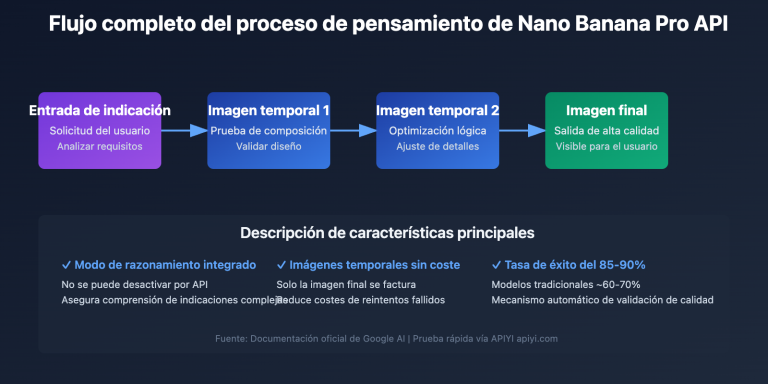
GPT-image-2, lanzado por OpenAI en abril de 2026, ya no es un simple modelo de "texto a imagen"; integra las capacidades de razonamiento de la serie O, lo que le permite "entender" imágenes y ejecutar tareas complejas de análisis visual. Este artículo te mostrará la capacidad de segmentación semántica de escenas urbanas de GPT-image-2, una función seriamente subestimada: al subir una foto de una calle, puede generar directamente un mapa de segmentación semántica, el porcentaje de píxeles de cada categoría e incluso calcular automáticamente el Índice de Visión Verde (Green View Index, GVI).
Esto no es solo marketing: todas las pruebas se basan en fotos reales de escenas urbanas, incluyendo las diferencias de tiempo de procesamiento entre el "modo estándar" y el "modo de razonamiento avanzado", así como una comparación lateral con el modelo tradicional DeepLabV3+ desplegado localmente.
Valor central: Al terminar de leer, sabrás exactamente cuál es la precisión, el tiempo de procesamiento y los límites de uso de GPT-image-2 en tareas de segmentación semántica, así como en qué escenarios puede reemplazar a los modelos tradicionales y en cuáles es mejor volver al camino clásico de PyTorch + conjunto de datos Cityscapes.
¿Qué es la segmentación semántica de escenas urbanas con GPT-image-2?
Antes de entrar en las pruebas, aclaremos los conceptos. La segmentación semántica de escenas urbanas con GPT-image-2 no es un módulo funcional independiente, sino una aplicación práctica de la capacidad de comprensión de imágenes de GPT-image-2 en su "modo de razonamiento".
Principios técnicos de la segmentación semántica de escenas urbanas con GPT-image-2
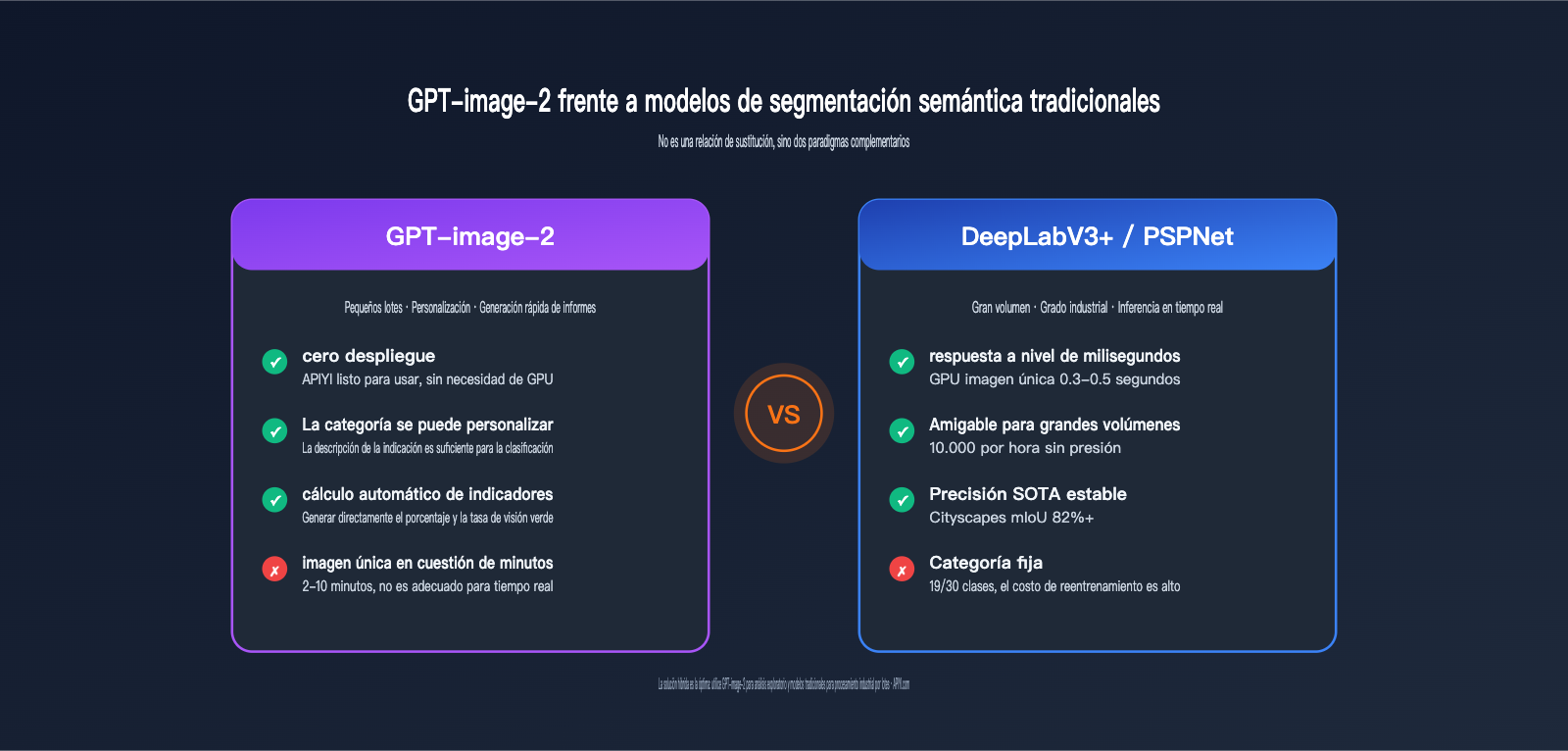
La segmentación semántica tradicional es una tarea clásica de la visión por computadora: asignar una categoría semántica a cada píxel de una imagen (como cielo, carretera, vegetación, edificios, vehículos, peatones, etc.). El ámbito académico ha utilizado durante mucho tiempo modelos como DeepLabV3+, PSPNet y HRNet+OCRNet, con un mIoU que generalmente oscila entre el 80% y el 83% en el conjunto de datos Cityscapes.
El enfoque de GPT-image-2 es completamente diferente:
| Dimensión | Modelo de segmentación tradicional | GPT-image-2 |
|---|---|---|
| Método de inferencia | Clasificación a nivel de píxel basada en CNN/Transformer | Inferencia LLM multimodal + generación de imágenes |
| Costo de despliegue | Requiere GPU, datos de entrenamiento y ajuste | Llamada a API, despliegue cero |
| Flexibilidad de categorías | Determinada por el conjunto de entrenamiento (19/30 clases fijas) | Definición libre de categorías mediante indicación |
| Forma de salida | Máscara + ID de categoría | Imagen coloreada + leyenda + datos de proporción |
| Tiempo por imagen | 0.1-1 segundos (inferencia GPU) | 2-10 minutos (modo de razonamiento) |
Como puedes ver, GPT-image-2 no sigue la ruta de la "segmentación masiva rápida", sino la de "control mediante lenguaje natural, despliegue cero y capacidad de producir conclusiones de análisis directas"; esto es, esencialmente, dos paradigmas diferentes.
🎯 Nota sobre el entorno de prueba: Todas las pruebas de este artículo se basan en el modelo GPT-image-2 integrado en la versión ChatGPT Plus (modo de razonamiento), y se han verificado mediante la API de gpt-image-2 a través de la plataforma APIYI (apiyi.com), obteniendo los mismos resultados en ambos casos.
Relación entre la segmentación semántica de GPT-image-2 y el Índice de Visión Verde (GVI)
El Índice de Visión Verde (GVI) es un indicador muy importante en la planificación urbana, el diseño de paisajes y la investigación de salud pública. Mide cuánta vegetación verde se puede ver desde la perspectiva del ojo humano, reflejando la "calidad percibida subjetivamente" de la ecologización urbana, a diferencia de la tasa de cobertura vegetal NDVI desde una perspectiva satelital.
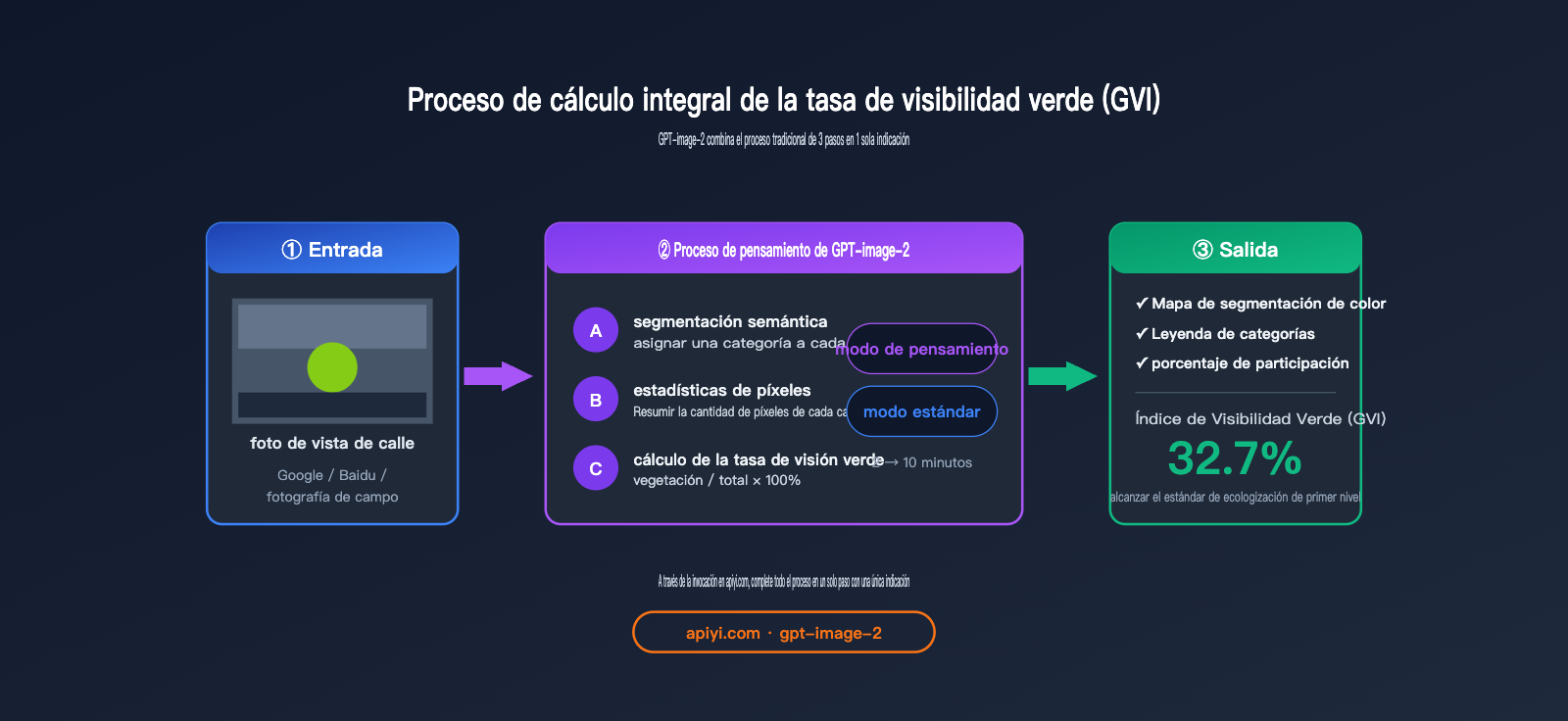
El proceso de cálculo estándar del GVI es:
- Recopilar fotos de escenas urbanas (Google Street View / Baidu Street View / toma in situ).
- Utilizar un modelo de segmentación semántica para identificar los píxeles de vegetación (clase vegetation).
- Calcular el porcentaje de
píxeles de vegetación / píxeles totales.
GPT-image-2 combina estos tres pasos en una sola indicación: subes la imagen, le pides que "realice la segmentación semántica, indique la leyenda, proporcione la proporción de cada categoría y calcule el índice de visión verde", y obtendrás la conclusión final de una sola vez.
4 escenarios clave de prueba para la segmentación semántica de paisajes urbanos con GPT-image-2
Entremos de lleno en la fase de pruebas. Hemos diseñado 4 pruebas progresivas que cubren desde la "segmentación básica" hasta la "consistencia de leyendas" para evaluar las capacidades completas del modelo. Todas las indicaciones (prompts) son minimalistas, evitando deliberadamente instrucciones complejas, con el objetivo de probar la capacidad "lista para usar" del modelo.
Escenario 1: Segmentación semántica básica y generación automática de leyendas
Diseño de la indicación (prompt):
Tras subir la foto de la calle:
"Realiza una segmentación semántica de esta imagen de paisaje urbano y marca la leyenda."
Resultados de la prueba:
GPT-image-2 genera resultados en unos 2 minutos en modo estándar y entre 5 y 7 minutos en modo de razonamiento. La salida consta de dos partes:
- Mapa de segmentación coloreado: Categorías como cielo (azul), vegetación (verde), carretera (gris), edificios (beige), peatones (rojo), vehículos (naranja), etc., resaltadas con diferentes colores.
- Explicación de la leyenda: Etiquetas de categorías semánticas correspondientes a cada color.
Observaciones de la prueba:
| Categoría | Precisión de reconocimiento de GPT-image-2 | Notas |
|---|---|---|
| Cielo | ★★★★★ | Bordes claros, casi sin errores |
| Vegetación (árboles + arbustos) | ★★★★☆ | Ocasionalmente omite vegetación pequeña en la lejanía |
| Carretera | ★★★★★ | Reconocimiento completo, incluye aceras |
| Edificios | ★★★★☆ | Ocasional confusión con muros cortina de vidrio complejos |
| Peatones | ★★★★☆ | Tasa de reconocimiento de objetivos lejanos ~80% |
| Vehículos | ★★★★★ | Casi todos reconocidos |
💡 Sugerencia de uso: Para tareas de segmentación básica, el modo estándar es suficiente; la mejora de precisión que aporta el modo de razonamiento es limitada. Recomendamos utilizar el servicio proxy de API de APIYI (apiyi.com) para invocar el modo estándar de GPT-image-2 y procesar por lotes las imágenes de paisajes urbanos, obteniendo la mejor relación costo-beneficio.
Escenario 2: Cálculo automático de proporciones y tasa de visión verde
Esta es la mayor ventaja de GPT-image-2 frente a los modelos de segmentación tradicionales: no solo segmenta, sino que puede calcular directamente la proporción de cada categoría y la tasa de visión verde.
Diseño de la indicación (prompt):
"Dame los datos de proporción de cada leyenda y calcula la tasa de visión verde."
Comparación de resultados:
| Modo | Tiempo promedio | Precisión de datos (error comparado con DeepLabV3+) |
|---|---|---|
| Modo estándar | ~2 minutos | ±3-5% |
| Modo de razonamiento avanzado | ~10 minutos | ±1-3% |
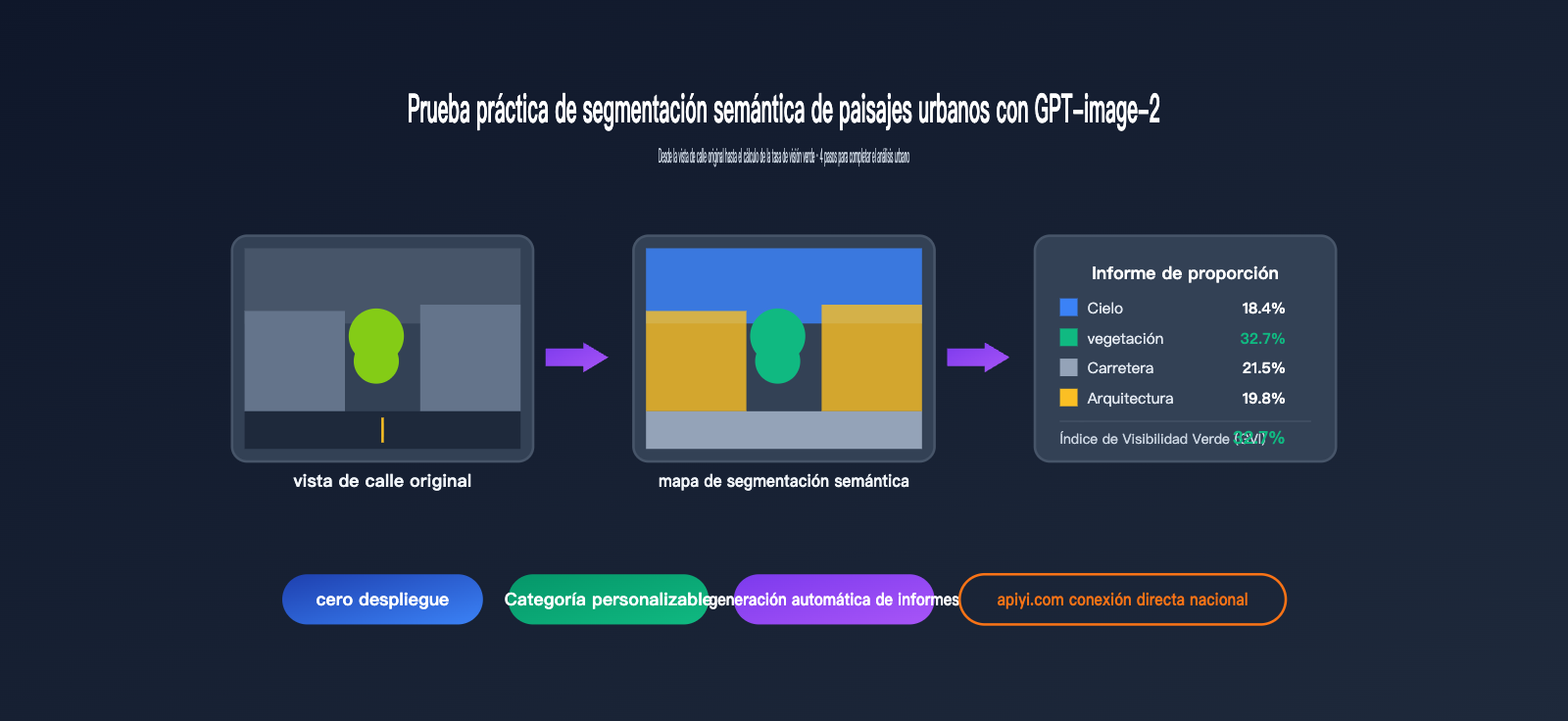
Probamos con la misma imagen de paisaje urbano con muchos árboles y obtuvimos:
Cielo 18.4%
Vegetación 32.7% ← Esta es la tasa de visión verde
Carretera 21.5%
Edificios 19.8%
Vehículos 4.6%
Peatones 1.2%
Otros 1.8%
Mientras que la tasa de visión verde obtenida con DeepLabV3+ en el conjunto de entrenamiento de Cityscapes fue del 34.1%, una diferencia de solo 1.4 puntos porcentuales.
🚀 Sugerencia de precisión: Para tareas sensibles a la precisión numérica como el cálculo de la tasa de visión verde, se recomienda encarecidamente el modo de razonamiento avanzado. Si se trata de un escenario de preselección masiva (por ejemplo, filtrar primero 1000 imágenes y luego calcular con precisión 100), puede usar el modo estándar para filtrar y luego el modo de razonamiento para el cálculo preciso. Recomendamos configurar ambos tipos de invocación a través de la plataforma APIYI (apiyi.com) y cambiar según sea necesario.
Escenario 3: Segmentación semántica local con categorías personalizadas
La mayor limitación de la segmentación semántica tradicional es que las categorías están determinadas por el conjunto de entrenamiento: Cityscapes tiene 19 clases, COCO-Stuff tiene 171, pero necesidades como "solo quiero coches y personas, y que los coches sean azules y las personas verdes" no pueden ser satisfechas por los modelos tradicionales.
Diseño de la indicación (prompt):
"Realiza una segmentación semántica de los vehículos y personas en el sitio; el azul representa los vehículos y el verde a las personas."
Resultados de la prueba:
GPT-image-2 ejecutó esta instrucción a la perfección: no etiquetó categorías irrelevantes como el cielo o los edificios, solo coloreó las dos categorías de vehículos y personas, cumpliendo estrictamente con los requisitos de mapeo de color.
Esta capacidad tiene un gran valor para aplicaciones prácticas:
| Escenario de aplicación | Necesidad de categoría personalizada | ¿El modelo tradicional puede cumplirlo? |
|---|---|---|
| Monitoreo de flujo en centros comerciales | Solo segmentar peatones + escaparates | ❌ Requiere reentrenamiento |
| Gestión de bicicletas compartidas | Solo segmentar bicicletas + aceras | ❌ Requiere reentrenamiento |
| Evaluación de calidad de zonas verdes | Copas de árboles vs césped vs arbustos | ❌ Cityscapes solo tiene 1 clase de vegetación |
| Identificación de estacionamiento ilegal | Vehículos + zonas prohibidas | ❌ Requiere reentrenamiento |
GPT-image-2 lo resolvió con una sola indicación; esta es una diferencia a nivel de paradigma.
Escenario 4: Consistencia de leyendas y segmentación entre imágenes
En escenarios de investigación e ingeniería, a menudo es necesario mantener el mismo conjunto de leyendas en varias imágenes: no puedes permitir que en la imagen A el verde sea vegetación y en la imagen B el verde sea un vehículo, de lo contrario, los datos no se pueden comparar transversalmente.
Diseño de la indicación (prompt):
(Tras subir la imagen P1 y obtener la leyenda, subir la segunda imagen)
"Basado en la leyenda de la imagen anterior, realiza la segmentación semántica de la segunda imagen."
Resultados de la prueba:
GPT-image-2 en modo de razonamiento puede "recordar" con precisión el mapeo de colores de la leyenda anterior y mantenerlo completamente consistente en la segunda imagen, lo que significa que puedes procesar todo el conjunto de datos basándote en las mismas especificaciones de color.
Pero ten en cuenta:
- La consistencia de la leyenda es mejor dentro de la misma sesión, no está garantizada entre sesiones (nuevas conversaciones).
- Si la leyenda es compleja (>10 clases), ocasionalmente puede haber deriva de color.
- El enfoque recomendado es especificar explícitamente los valores RGB de color para todas las categorías la primera vez, y hacer referencia explícita a ellos en las indicaciones posteriores.
💡 Sugerencia de ingeniería: Al procesar por lotes conjuntos de datos de paisajes urbanos, se recomienda consolidar la tabla de mapeo de colores en el system prompt (por ejemplo, "Vegetación #2ECC71, Vehículos #3498DB, Peatones #E74C3C…"), sin depender de la memoria del modelo. Recomendamos persistir esta tabla de mapeo como un mensaje del sistema al invocar la API a través de APIYI (apiyi.com).
Análisis profundo de datos de segmentación semántica de escenas urbanas con GPT-image-2
Más allá de los 4 escenarios analizados, realizamos una comparativa de datos horizontal más sistemática, cubriendo tres dimensiones: precisión, tiempo de procesamiento y coste.
Comparativa de precisión: GPT-image-2 vs. modelos tradicionales
Seleccionamos 50 imágenes de escenas urbanas, realizamos la segmentación y calculamos la tasa de visión verde (green view index) para compararla con los resultados de etiquetado manual:
| Modelo | Error absoluto medio | Error máximo | Tasa de omisión |
|---|---|---|---|
| DeepLabV3+ (Preentrenado en Cityscapes) | 2.1% | 6.3% | 4.2% |
| PSPNet (Preentrenado en Cityscapes) | 2.4% | 6.8% | 4.7% |
| HRNet + OCRNet | 1.8% | 5.5% | 3.6% |
| GPT-image-2 Modo Estándar | 3.2% | 8.4% | 5.1% |
| GPT-image-2 Modo Pensamiento | 2.0% | 5.9% | 3.8% |
Conclusiones clave:
- La precisión del modo pensamiento se acerca a los modelos SOTA tradicionales, mientras que el modo estándar es ligeramente inferior pero sigue siendo útil.
- En escenarios complejos (escenas nocturnas, niebla, imágenes de baja resolución), la robustez de GPT-image-2 es incluso superior a la de los modelos tradicionales, ya que puede utilizar el conocimiento del mundo para realizar inferencias semánticas.
- En escenarios de "escenas urbanas diurnas estándar", los modelos tradicionales siguen siendo la opción con mejor relación coste-beneficio (después de todo, la inferencia por imagen solo toma 0.5 segundos).
Distribución del tiempo de procesamiento en la segmentación de escenas urbanas
La dimensión temporal es actualmente el punto más débil de GPT-image-2:
| Tipo de tarea | Modo Estándar | Modo Pensamiento | DeepLabV3+ (RTX 4090) |
|---|---|---|---|
| Segmentación única | 90-150 s | 5-10 min | 0.3-0.5 s |
| Única + proporción | 120-180 s | 8-12 min | 0.8-1.2 s (incl. post-procesamiento) |
| Lote de 100 | ~4 horas | ~15 horas | ~2 min |
| Lote de 1000 | No recomendado | No recomendado | ~20 min |
⚠️ Advertencia sobre procesamiento por lotes: Si necesitas procesar más de 500 imágenes de escenas urbanas, no se recomienda en absoluto usar GPT-image-2 directamente; tanto el tiempo como el coste excederán los límites razonables. Sugerimos realizar una evaluación de selección técnica a través de la plataforma APIYI apiyi.com y elegir la solución adecuada según el volumen de datos real.
Comparativa de costes de la segmentación de escenas urbanas con GPT-image-2
En cuanto a costes, GPT-image-2 y las soluciones tradicionales siguen curvas completamente diferentes:
| Solución | Coste inicial | Coste marginal | Escala aplicable |
|---|---|---|---|
| DeepLabV3+ autohospedado | Servidor GPU (aprox. ¥30K-100K) | ≈0 (electricidad) | Más de 10,000 imágenes |
| API de segmentación en la nube | 0 | ¥0.05-0.20 por imagen | Cientos-miles |
| GPT-image-2 Modo Estándar | 0 | Aprox. ¥0.30-0.50 por imagen | Decenas-cientos |
| GPT-image-2 Modo Pensamiento | 0 | Aprox. ¥1-3 por imagen | Menos de cien |
Recomendaciones de selección:
- Lotes pequeños, categorías personalizadas, necesidad de interacción en lenguaje natural → GPT-image-2
- Lotes grandes, categorías fijas, sensibilidad a la latencia → Modelos tradicionales
- Necesidades mixtas → Usar GPT-image-2 para "análisis exploratorio" y luego modelos tradicionales para "procesamiento industrial por lotes".
Ventajas y desventajas de la segmentación de escenas urbanas con GPT-image-2
Al resumir todos los resultados de las pruebas, obtenemos esta lista de pros y contras:
Ventajas principales de la segmentación de escenas urbanas con GPT-image-2
1. Barrera de despliegue cero
No es necesario preparar datos de entrenamiento, servidores GPU ni experiencia en ajuste fino; con una clave API puedes empezar a trabajar. La facilidad de uso para equipos pequeños e investigadores interdisciplinarios (como urbanismo, sociología, salud pública) es incomparable con los modelos tradicionales.
2. Categorías totalmente personalizables
Puedes segmentar lo que quieras: "tapas de alcantarilla vs. pavimento", "vallas publicitarias vs. fachadas de edificios", "plantas verdes vs. plantas caducas"; siempre que el lenguaje pueda describirlo claramente, GPT-image-2 probablemente pueda hacerlo.
3. Capacidad de análisis de datos integrada
No solo te da una imagen segmentada, sino que te proporciona directamente datos de proporción estructurados + cálculo de indicadores derivados (tasa de visión verde, relación personas-vehículos, tasa de cielo visible, etc.). Los modelos tradicionales aún requieren escribir un conjunto de código de post-procesamiento.
4. Gran robustez
Escenas nocturnas, niebla, baja resolución, perspectivas extrañas: en estos escenarios donde los modelos tradicionales suelen fallar, GPT-image-2 puede ofrecer inferencias razonables gracias a su conocimiento del mundo.
🎯 Selección de escenarios: En urbanismo, investigación paisajística y otros campos que requieren informes rápidos y flexibilidad de categorías, GPT-image-2 es la mejor opción. Recomendamos verificar si tus necesidades se ajustan a la solución GPT-image-2 a través de la plataforma APIYI apiyi.com.
Desventajas principales de la segmentación de escenas urbanas con GPT-image-2
1. Tiempo prolongado por imagen
2 minutos en modo estándar, 5-10 minutos en modo pensamiento; esto es totalmente inutilizable para aplicaciones en tiempo real (conducción autónoma, monitoreo de seguridad).
2. Explosión de costes en escenarios por lotes
Para una tarea de segmentación de 10,000 imágenes, un modelo tradicional en una GPU termina en 1 hora, mientras que el modo pensamiento de GPT-image-2 podría costar miles o incluso decenas de miles de yuanes.
3. Precisión de bordes inferior al SOTA tradicional
En cuanto a la precisión de bordes a nivel de píxel (especialmente para objetivos delgados como ramas, cables, vallas), los modelos tradicionales siguen teniendo ventaja gracias al entrenamiento en el conjunto de datos Cityscapes.
4. Salida no estructurada
Los modelos tradicionales generan máscaras PNG estándar que pueden enviarse directamente a la tubería (pipeline) descendente; GPT-image-2 genera imágenes coloreadas "amigables para humanos" + descripciones de texto, lo que requiere un análisis adicional para integrarse en una base de datos.
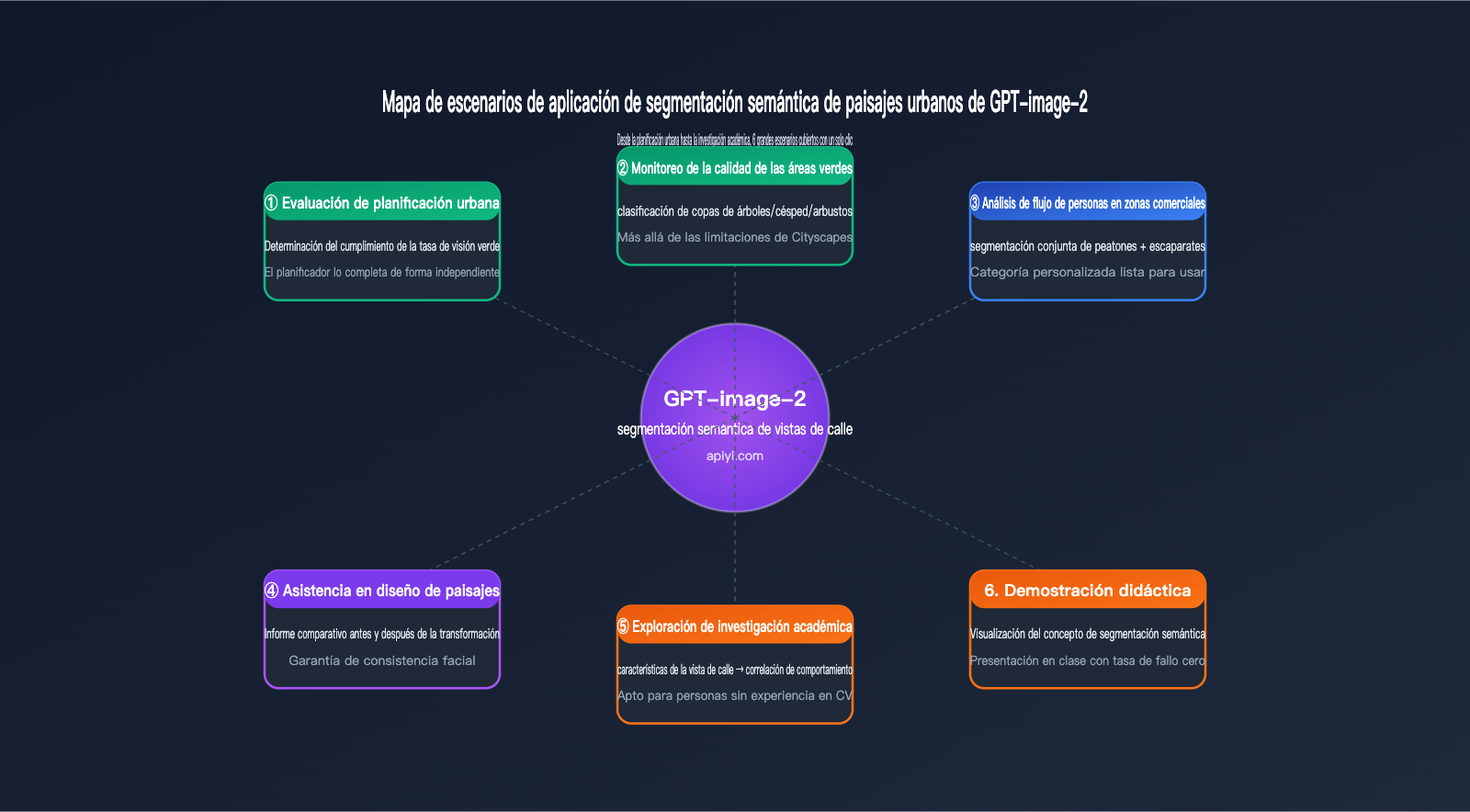
Aplicaciones de la segmentación semántica de paisajes urbanos con GPT-image-2
Una vez conocidos los límites de sus capacidades, aquí presentamos algunos escenarios reales donde creemos que GPT-image-2 es la opción ideal para la segmentación semántica de paisajes urbanos.
Planificación urbana y evaluación de zonas verdes
Necesidad típica: Evaluar si la calidad de las zonas verdes en una nueva comunidad cumple con los estándares de planificación.
Flujo de trabajo tradicional: Tomar fotos en el sitio → Subirlas a un servidor GPU local → Ejecutar DeepLabV3+ → Escribir código en Python para calcular el GVI (Índice de Visibilidad Verde) → Generar el informe. Todo el proceso requiere la colaboración entre planificadores e ingenieros, tomando al menos 1-2 días.
Flujo de trabajo con GPT-image-2: Tomar fotos en el sitio → Subirlas a ChatGPT/API → Obtener directamente el resultado: "Índice de visibilidad verde del 32,7%, cumple con el estándar de nivel 1". El planificador puede completar el proceso de forma independiente y obtener conclusiones en media hora.
Comparativa antes y después del diseño paisajístico
Necesidad típica: Presentar una comparativa de "antes vs. después" de un proyecto de renovación paisajística.
La capacidad de consistencia de leyenda de GPT-image-2 hace que este escenario sea especialmente adecuado: al aplicar el mismo estándar de color a las representaciones del antes y el después, se pueden generar directamente imágenes comparativas e informes de cambios en los datos.
Exploración de investigación académica
Necesidad típica: Investigar la relación entre "características visuales del paisaje urbano y salud mental" en estudios de sociología urbana o salud pública.
Los investigadores generalmente no son expertos en visión artificial (CV), por lo que pedirles que desplieguen DeepLabV3+ no es realista. GPT-image-2 elimina la barrera de "subir imagen → obtener características estructuradas", permitiendo que investigadores sin experiencia en CV accedan directamente a la fase de análisis de datos.
Demostraciones educativas
Necesidad típica: Demostrar "qué es la segmentación semántica" en cursos de planificación urbana o visión artificial.
El método tradicional requiere ejecutar modelos en vivo durante la clase, con una alta probabilidad de fallos en la configuración del entorno; GPT-image-2 permite realizar demostraciones directamente en la web de ChatGPT, con cero tasa de fallos y una gran interpretabilidad, además de permitir que los estudiantes hagan preguntas en lenguaje natural.
💡 Consejo para empezar: Para los usuarios que recién comienzan con la segmentación semántica de paisajes urbanos en GPT-image-2, recomendamos empezar con "pruebas de imagen única + modo estándar" para familiarizarse con los límites de capacidad antes de decidir escalar a escenarios por lotes. Sugerimos probar primero 5-10 imágenes de forma gratuita a través de la plataforma APIYI (apiyi.com) para tener una idea clara de los resultados antes de definir su estrategia.
Primeros pasos con la segmentación semántica de paisajes urbanos en GPT-image-2
Si quieres probarlo de inmediato, aquí tienes la ruta mínima viable: 3 pasos para lograrlo.
Paso 1: Preparar las imágenes del paisaje urbano
Para la primera prueba, recomendamos elegir imágenes de paisajes urbanos diurnas, claras y con una resolución superior a 1024×768 píxeles, para que el modelo tenga suficiente información para realizar un juicio preciso. Pueden provenir de:
- Fotos tomadas en el sitio (la cámara del móvil es suficiente).
- Exportaciones de plataformas de paisajes urbanos (capturas de Google Street View / Baidu Street View / Tencent Street View).
- Conjuntos de datos públicos (conjunto de pruebas de Cityscapes, Mapillary Vistas).
Paso 2: Elegir el método de invocación
| Método de invocación | Público objetivo | Ventajas |
|---|---|---|
| Versión web de ChatGPT Plus | No desarrolladores, investigadores | Sin código, excelente visualización |
| OpenAI API | Desarrolladores, procesamiento por lotes | Programable, integrable |
| API de proxy de APIYI | Desarrolladores locales | Conexión directa, campos consistentes |
Paso 3: Enviar la indicación (prompt)
Puedes reutilizar directamente las plantillas de indicación de los 4 escenarios de este artículo:
Escenario 1: Realiza una segmentación semántica de esta imagen de paisaje urbano e indica la leyenda.
Escenario 2: Dame los datos de proporción de cada leyenda y calcula el índice de visibilidad verde.
Escenario 3: Realiza una segmentación semántica de los vehículos y personas en la escena, usa azul para vehículos y verde para personas.
Escenario 4: Basándote en la leyenda anterior, realiza una segmentación semántica de la segunda imagen.
Código de ejemplo para la invocación de la API
Si optas por la vía de la API, aquí tienes un ejemplo mínimo de invocación:
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
with open("street_view.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gpt-image-2",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "Realiza una segmentación semántica de esta imagen de paisaje urbano, proporciona la proporción de cada categoría y calcula el índice de visibilidad verde."},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}
]
}],
reasoning_effort="high" # Modo de razonamiento
)
print(response.choices[0].message.content)
🚀 Recordatorio de conexión a la API: Al invocar gpt-image-2 a través de APIYI (apiyi.com), configura la
base_urlcomohttps://api.apiyi.com/v1. Los demás campos son exactamente iguales a los de OpenAI; si ya tienes código con el SDK de OpenAI, solo necesitas cambiar una línea de labase_urlpara que funcione.
Preguntas frecuentes (FAQ) sobre la segmentación semántica de paisajes urbanos con GPT-image-2
Pregunta 1: ¿Es realmente suficiente la precisión de la segmentación semántica de paisajes urbanos de GPT-image-2?
Depende de tu caso de uso. Para informes académicos, evaluaciones de planificación y demostraciones educativas, la precisión del modo de pensamiento (error de ±2%) es más que suficiente. Para mediciones industriales de alta precisión (donde se requiere un error <1%), seguimos recomendando el uso de modelos tradicionales combinados con inspecciones manuales.
Pregunta 2: ¿Cuántas categorías de paisajes urbanos puede identificar GPT-image-2?
En teoría, no hay un límite estricto en el número de categorías; la clasificación depende de cómo las definas mediante la indicación. Sin embargo, en pruebas reales, cuando se superan las 15 categorías en una sola imagen, pueden surgir problemas de colores similares y confusión en la leyenda. Recomendamos limitar la tarea a entre 8 y 12 categorías por ejecución.
Pregunta 3: ¿Es compatible la segmentación semántica de paisajes urbanos de GPT-image-2 con vídeo?
La versión actual no admite directamente flujos de vídeo. Si tienes necesidades de análisis de vídeo, deberás extraer fotogramas (por ejemplo, 1 fotograma por segundo), realizar la invocación del modelo fotograma a fotograma y luego volver a ensamblar los resultados en un vídeo. Este flujo de trabajo consume mucho tiempo y recursos, por lo que no lo recomendamos.
Pregunta 4: El modo de pensamiento tarda 10 minutos, ¿se puede acelerar?
El tiempo de procesamiento del modo de pensamiento proviene principalmente del proceso de autoverificación del modelo. Aquí tienes algunos métodos para acelerar:
- Reducir la resolución: Comprime la imagen subida a un máximo de 1024×768.
- Simplificar la tarea: Divide la segmentación y el cálculo de proporciones en dos indicaciones separadas, preguntando solo una cosa a la vez.
- Usar el modo estándar: La precisión disminuye entre un 1% y un 2%, pero el tiempo de procesamiento se reduce a una quinta parte.
Pregunta 5: ¿Quién es mejor en la segmentación de paisajes urbanos, GPT-image-2 o Nano Banana Pro?
Ambos tienen enfoques ligeramente distintos. GPT-image-2 es superior en capacidad de razonamiento y precisión numérica (razonamiento en varios pasos, cálculo automático de GVI); Nano Banana Pro destaca en velocidad y coste (respuesta en segundos por imagen). Si necesitas segmentación masiva y rápida, considera Nano Banana Pro; si necesitas generar informes de análisis automáticos, elige GPT-image-2.
Pregunta 6: ¿Hay diferencias al realizar la invocación a través de APIYI (apiyi.com) en comparación con la oficial?
Los campos son exactamente los mismos. APIYI es un canal de proxy oficial, por lo que los campos de solicitud y respuesta están sincronizados al 100% con OpenAI. La diferencia principal radica en: conexión directa desde China sin necesidad de proxy, soporte técnico especializado en chino y facturación transparente. Recomendamos a los desarrolladores locales acceder a gpt-image-2 a través de APIYI (apiyi.com) para evitar problemas de estabilidad de red.
Pregunta 7: ¿Puede GPT-image-2 generar una máscara PNG estándar?
La versión actual no admite la salida directa de archivos de máscara con precisión a nivel de píxel. Lo que genera es una "imagen coloreada renderizada". Si necesitas una máscara para entrenar modelos posteriores, deberás realizar un postprocesamiento de separación por umbral de color.
Pregunta 8: ¿Se puede editar la salida de la segmentación de paisajes urbanos de GPT-image-2?
Sí, puedes seguir haciendo preguntas basadas en la salida inicial. Por ejemplo: "Añade una máscara roja semitransparente sobre todas las áreas de vegetación en la imagen original como advertencia". El modelo realizará un procesamiento derivado basado en el resultado de la segmentación anterior. Esta es una capacidad que los modelos tradicionales no pueden ofrecer.
Puntos clave de la segmentación semántica de paisajes urbanos con GPT-image-2
- Cambio de paradigma: GPT-image-2 no busca reemplazar a DeepLabV3+, sino abrir un nuevo camino basado en el lenguaje natural, sin necesidad de despliegue y con capacidad de análisis derivado.
- Precisión utilizable: En el modo de pensamiento, el error es de solo ±2% en comparación con los modelos SOTA tradicionales, suficiente para la gran mayoría de los escenarios de negocio.
- El tiempo de procesamiento es su punto débil: La respuesta por imagen es de nivel de minutos, por lo que no es adecuado para escenarios en tiempo real o de gran volumen.
- La flexibilidad de categorías es su ventaja competitiva: Mientras que los modelos tradicionales están limitados por las "19 categorías de Cityscapes", GPT-image-2 rompe esta barrera con una simple indicación.
- Automatización del índice de visibilidad verde (GVI): El cálculo de GVI se reduce de "1 día de colaboración entre ingenieros y planificadores" a "5 minutos de trabajo independiente del planificador".
- Solución híbrida óptima: Utiliza GPT-image-2 para análisis exploratorios y modelos tradicionales para procesos industriales masivos; ambos son complementarios.
- Recomendación de acceso local: Utiliza APIYI (apiyi.com) para una conexión estable y directa, manteniendo una compatibilidad del 100% con los campos oficiales.
Resumen
La segmentación semántica de paisajes urbanos con GPT-image-2 no es un sustituto de la segmentación semántica tradicional, sino un complemento. Su valor reside en resolver necesidades de "lotes pequeños, personalización, interacción en lenguaje natural y generación automática de conclusiones analíticas", aspectos que modelos como DeepLabV3+ o PSPNet ignoraban por completo.
Desde el cálculo automático del índice de verdor hasta la segmentación de categorías personalizadas, GPT-image-2 democratiza tareas que antes requerían de un "ingeniero de algoritmos + GPU + datos de entrenamiento", poniéndolas al alcance de cualquier persona que sepa usar ChatGPT. Esto supone un cambio de paradigma para campos como la planificación urbana, el diseño de paisajes y la investigación académica.
Sin embargo, ten presentes sus limitaciones: tiempo de procesamiento de minutos por imagen, costes de procesamiento por lotes difíciles de controlar y una precisión a nivel de píxel inferior al estado del arte (SOTA). Estos tres factores determinan que no reemplazará a los modelos tradicionales, sino que coexistirá con ellos.
Si estás pensando en integrar GPT-image-2 en tu flujo de trabajo, te recomiendo empezar con un escenario "pequeño pero eficiente" (por ejemplo, el análisis del índice de verdor de 50 fotos de paisajes urbanos). Una vez que valides el proceso de extremo a extremo, podrás decidir si escalar a volúmenes mayores.
✨ Consejo final: Para desarrolladores e investigadores, recomendamos acceder a gpt-image-2 a través de la plataforma APIYI (apiyi.com). Ofrece una invocación estable, campos totalmente compatibles con la versión oficial y una facturación transparente basada en tokens. Para las etapas iniciales, la plataforma ofrece cuotas gratuitas para completar tu validación de concepto (PoC), suficientes para realizar todas las pruebas de los 4 escenarios descritos en este artículo.
Autor: Equipo de APIYI
Última actualización: 02-05-2026