Los modelos de incrustación (embedding) se han convertido en la piedra angular de los sistemas RAG, la búsqueda semántica y los sistemas de recomendación. Como la versión comercial más reciente de la serie Qwen3-Embedding, text-embedding-v4 se está consolidando como una opción clave para los desarrolladores gracias a sus 8 dimensiones vectoriales seleccionables (2048, 1536, 1024, 768, 512, 256, 128, 64) y sus resultados líderes en el benchmark multilingüe MTEB.
Sin embargo, muchos equipos se enfrentan a una duda común al implementar estos sistemas: ¿Qué es exactamente la dimensión vectorial? ¿Qué diferencia hay entre 2048 y 64 dimensiones? ¿Cómo debería elegir? Elegir la dimensión incorrecta puede significar, en el mejor de los casos, desperdiciar 30 veces el costo de almacenamiento y, en el peor, reducir la tasa de recuperación de 70 a 50 puntos.
Este artículo desglosa las diferencias entre las 8 dimensiones de text-embedding-v4 basándose en datos reales de MTEB/CMTEB, ofrece un marco de selección práctico y proporciona ejemplos completos de invocación del modelo mediante API.
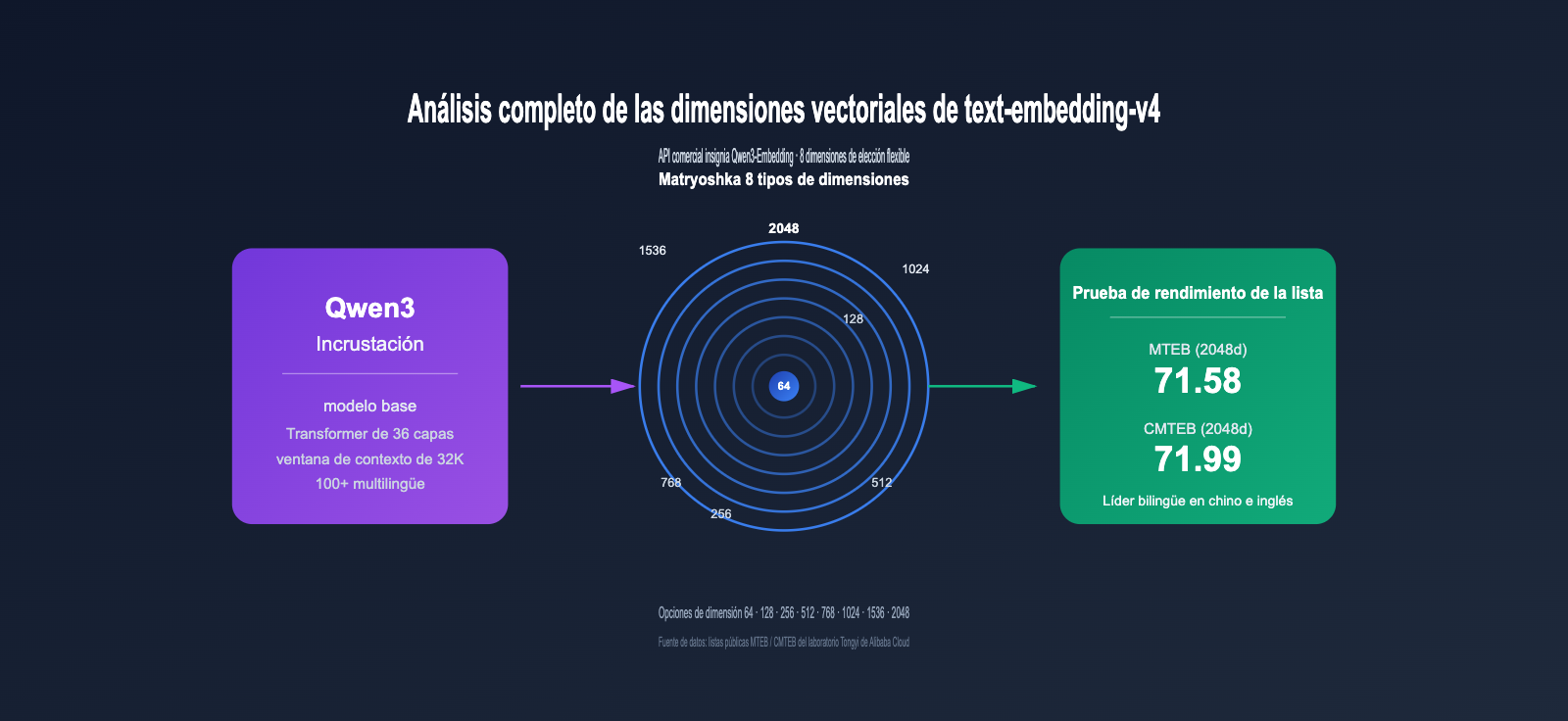
I. ¿Qué es text-embedding-v4?: El buque insignia comercial de Qwen3-Embedding
text-embedding-v4 es la última generación de modelos de incrustación de texto entrenados por el Laboratorio Tongyi de Alibaba sobre el Modelo de Lenguaje Grande base Qwen3, disponible a través de la plataforma DashScope. Pertenece a la serie Qwen3-Embedding, que ha ocupado constantemente los primeros puestos entre los modelos de código abierto en el benchmark multilingüe MTEB de 2026, obteniendo una puntuación alta de 80.68 en la subcategoría MTEB Code con Qwen3-Embedding-8B.
1.1 Características principales de text-embedding-v4
En comparación con la versión v3, text-embedding-v4 ha realizado mejoras significativas en las siguientes dimensiones:
| Dimensión de capacidad | text-embedding-v3 | text-embedding-v4 | Mejora |
|---|---|---|---|
| Puntuación global MTEB (1024 dim) | 63.39 | 68.36 | +4.97 |
| Recuperación MTEB (1024 dim) | 55.41 | 59.30 | +3.89 |
| Puntuación global CMTEB (1024 dim) | 68.92 | 70.14 | +1.22 |
| Recuperación CMTEB (1024 dim) | 73.23 | 73.98 | +0.75 |
| Dimensión vectorial máxima | 1024 | 2048 | Doble |
| Longitud máxima de entrada | 8K | 32K Tokens | 4× |
| Soporte multilingüe | 50+ | 100+ | Extensión significativa |
Como se puede observar, v4 no solo mejora notablemente en tareas generales (MTEB), sino que también presenta un avance considerable en tareas de recuperación en chino (CMTEB) y de código. Para los equipos que buscan la mayor precisión de recuperación, la versión de 2048 dimensiones de v4 es actualmente la mejor solución dentro del ecosistema de Alibaba.
💡 Sugerencia de prueba rápida: Si desea comparar de inmediato el rendimiento real entre v3 y v4, le recomendamos realizar la invocación del modelo a través de la plataforma APIYI (apiyi.com). La plataforma ya ha adaptado de forma unificada las especificaciones de interfaz de varios modelos de incrustación principales, permitiéndole cambiar entre diferentes modelos con el mismo código para una validación rápida.
1.2 Relación entre text-embedding-v4 y la serie de código abierto Qwen3-Embedding
Muchos desarrolladores confunden text-embedding-v4 (API comercial) con Qwen3-Embedding (pesos de código abierto). La relación es la siguiente:
- Serie de código abierto Qwen3-Embedding: Incluye tamaños de 0.6B / 4B / 8B, ofrece pesos en Hugging Face y permite despliegue local.
- text-embedding-v4: Basado en la misma pila tecnológica, pero con optimizaciones de ingeniería adicionales, refuerzo de datos y expansión multilingüe, disponible exclusivamente a través de la API de DashScope.
- Diferencia clave: La versión de código abierto requiere autogestionar la inferencia en GPU; la versión API se factura por Token y no requiere mantenimiento.
Para la gran mayoría de los equipos pequeños y medianos, utilizar la API es más rentable y menos complejo a nivel de ingeniería que gestionar su propia inferencia en GPU.
二、¿Qué es la dimensión vectorial?: Por qué hay tanta diferencia entre 64 y 2048
Para entender las 8 opciones de dimensión de text-embedding-v4, primero debemos aclarar el concepto fundamental de "dimensión vectorial".
2.1 La esencia de la dimensión vectorial: cuántos números comprimen un texto
Cuando introduces un fragmento de texto (por ejemplo, "cómo configurar la API de GPT-5") en un modelo de embedding, el modelo genera un vector compuesto por una serie de números de punto flotante, como este:
[0.0234, -0.1583, 0.7821, ..., -0.0091]
La longitud de esta cadena de números es la dimensión vectorial. Cuanto mayor sea la dimensión, significa que:
- La información semántica es más rica: cada dimensión puede capturar un rasgo semántico sutil.
- El costo de almacenamiento es mayor: un vector de 2048 dimensiones (float32) ocupa 8 KB, mientras que uno de 1024 ocupa 4 KB.
- El cálculo de recuperación es más lento: al duplicar la dimensión, el volumen de cálculo del producto escalar/coseno también se duplica aproximadamente.

2.2 Por qué text-embedding-v4 ofrece 8 dimensiones
Esto involucra una técnica clave: Aprendizaje de Representación Matryoshka (MRL).
Los modelos de embedding tradicionales solo pueden generar una dimensión fija. Por ejemplo, el ada-002 de OpenAI genera 1536 dimensiones fijas; o las usas todas, o haces una reducción de dimensionalidad PCA por tu cuenta (lo que conlleva una pérdida significativa de información).
La tecnología MRL permite que el modelo, durante el entrenamiento, distribuya la información según su importancia en diferentes intervalos dimensionales:
- Primeras 64 dimensiones: contienen la información semántica más central y crítica.
- Dimensiones 65-128: complementan rasgos semánticos secundarios.
- Dimensiones 129-256: añaden características más detalladas.
- …y así sucesivamente hasta la 2048.
Es como una muñeca rusa (matrioshka): cada capa es un vector completo que puede funcionar de forma independiente. Puedes truncar y usar arbitrariamente las primeras N dimensiones sin que la calidad caiga estrepitosamente.
🎯 Beneficio real de MRL: Según el artículo original de MRL y múltiples pruebas, usar 256 dimensiones en lugar de 2048 suele ahorrar 8 veces el almacenamiento y acelerar la recuperación entre 7 y 8 veces, manteniendo la pérdida de precisión por debajo del 5%. Esto es algo que el PCA tradicional no puede lograr.
III. Diferencias clave entre las 8 dimensiones de text-embedding-v4
A continuación, comparamos sistemáticamente las 8 dimensiones de text-embedding-v4 basándonos en los datos oficiales de los rankings MTEB / CMTEB.
3.1 Tabla de rendimiento por dimensión de text-embedding-v4
| Dimensión vectorial | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | Tamaño por vector | Escenario recomendado |
|---|---|---|---|---|---|---|
| 2048 | 71.58 | 61.97 | 71.99 | 75.01 | 8 KB | Precisión máxima |
| 1536 | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 KB | Compatibilidad con OpenAI |
| 1024 (predeterminado) | 68.36 | 59.30 | 70.14 | 73.98 | 4 KB | Equilibrio general |
| 768 | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 KB | Compatibilidad con BGE-base |
| 512 | 64.73 | 56.34 | 68.79 | 73.33 | 2 KB | Recuperación a pequeña/mediana escala |
| 256 | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 KB | Gran escala y alto rendimiento |
| 128 | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 B | Almacenamiento masivo |
| 64 | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 B | Compresión extrema |
💡 Los valores marcados con
*son estimaciones razonables basadas en la ley de decaimiento de MRL; los valores sin marcar provienen de los rankings públicos oficiales.
De la tabla podemos extraer tres conclusiones clave:
- 1024 dimensiones es la mejor relación costo-beneficio: tiene la mitad de dimensiones que 2048, pero la pérdida de rendimiento es mínima (MTEB aprox. -3.2 puntos), siendo la opción predeterminada recomendada por Alibaba.
- 2048 dimensiones ofrecen una ganancia notable: en comparación con 1024, el CMTEB Retrieval mejora 1 punto, lo que vale la pena para escenarios extremadamente sensibles a la precisión.
- Usar 64-128 dimensiones con precaución: la calidad de recuperación cae significativamente en dimensiones bajas, por lo que solo es adecuado para escenarios donde "es preferible ahorrar costos aunque se pierda algo de recuperación".
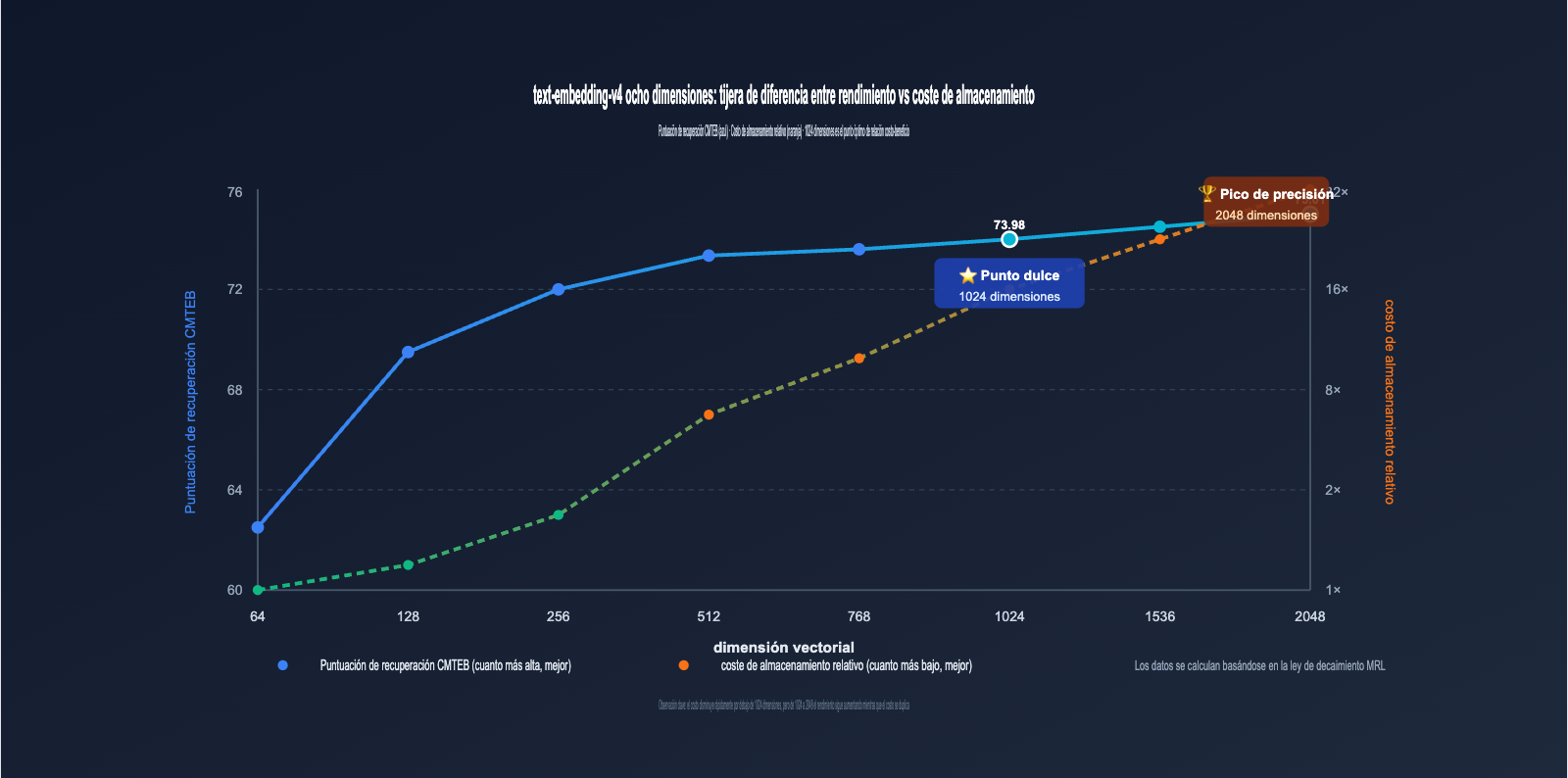
3.2 Ley de decaimiento de la pérdida de dimensión en text-embedding-v4
Al visualizar los datos de la tabla anterior, podemos observar una regla muy importante:
- 2048 → 1024 dimensiones: el MTEB solo cae 3.22 puntos (≈4.5%), pero el almacenamiento se reduce a la mitad ⭐️ Altamente recomendado.
- 1024 → 512 dimensiones: el MTEB cae 3.63 puntos (≈5.3%), el almacenamiento se reduce a la mitad nuevamente 👍 Aceptable.
- 512 → 256 dimensiones: el MTEB cae aprox. 2 puntos (≈3.0%), el almacenamiento se reduce a la mitad nuevamente ⚠️ Depende del escenario.
- 256 → 128 dimensiones: el MTEB cae aprox. 2.5 puntos (≈4.0%), sigue siendo utilizable ⚠️ Requiere pruebas exhaustivas.
- 128 → 64 dimensiones: el MTEB cae aprox. 2.5 puntos, pero el subítem de Retrieval cae estrepitosamente 6 puntos ❌ No recomendado para producción.
Esto demuestra que la "zona de decaimiento seguro" de MRL se encuentra principalmente por encima de las 256 dimensiones, mientras que las 64 dimensiones pertenecen a la zona de compresión extrema.
IV. El papel de las dimensiones vectoriales: 3 impactos principales
El impacto de las diferentes dimensiones en el sistema es integral, no se limita solo a la precisión de la recuperación. A continuación, desglosamos las 3 dimensiones más importantes.
4.1 Impacto de la dimensión vectorial en la precisión de la recuperación
La precisión es el aspecto más intuitivo. Tomemos como ejemplo un sistema RAG con 1 millón de documentos:
- Usando 2048 dimensiones: Tasa de recuperación Top-10 de aprox. 91%
- Usando 1024 dimensiones: Tasa de recuperación Top-10 de aprox. 88%
- Usando 256 dimensiones: Tasa de recuperación Top-10 de aprox. 84%
- Usando 64 dimensiones: Tasa de recuperación Top-10 de aprox. 75%
🎯 Sugerencia de selección: Si tu negocio es altamente sensible a la tasa de recuperación (como en búsquedas legales o consultas médicas), prioriza 1024 o 2048 dimensiones. Recomendamos ejecutar primero una comparativa de 1024 vs 2048 en la plataforma APIYI (apiyi.com) con el mismo conjunto de pruebas antes de tomar una decisión final.
4.2 Impacto de la dimensión vectorial en los costos de almacenamiento y recuperación
Este es el indicador que más preocupa en las implementaciones empresariales. Supongamos un sistema que almacena 100 millones de vectores:
| Dimensión vectorial | Almacenamiento total (float32) | Costo mensual (est.) | Latencia de consulta (est.) |
|---|---|---|---|
| 2048 dim. | 800 GB | Alto | Lento |
| 1024 dim. | 400 GB | Medio | Medio |
| 512 dim. | 200 GB | Bajo | Rápido |
| 256 dim. | 100 GB | Bajo | Muy rápido |
| 128 dim. | 50 GB | Muy bajo | Extremadamente rápido |
| 64 dim. | 25 GB | Muy bajo | Extremadamente rápido |
Como se puede observar, al reducir de 2048 a 256 dimensiones, el costo de almacenamiento se reduce a 1/8 y la velocidad de recuperación puede ser de 6 a 8 veces más rápida (dependiendo del algoritmo de índice ANN). Para escalas de datos superiores a los cien millones, la elección de la dimensión afecta directamente al orden de magnitud de los costos de infraestructura.
4.3 Impacto de la dimensión vectorial en la compatibilidad y costos de migración
Muchos equipos que migran desde OpenAI, BGE o Cohere hacia text-embedding-v4 temen que la incompatibilidad de dimensiones inutilice sus índices antiguos. Las 8 opciones de dimensiones de la v4 ofrecen una ruta de migración muy amigable:
| Modelo antiguo | Dimensión antigua | Dimensión recomendada para text-embedding-v4 | Notas de migración |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 dim. | Alineación de dimensiones, estructura reutilizable |
| OpenAI text-embedding-3-small | 1536 | 1536 dim. | Alineación total |
| OpenAI text-embedding-3-large | 3072 | 2048 dim. | Ligeramente menor, pero precisión superior |
| BGE-large | 1024 | 1024 dim. | Alineación total, reemplazo fluido |
| BGE-base | 768 | 768 dim. | Alineación total |
| Cohere embed-multilingual-v3 | 1024 | 1024 dim. | Alineación total |
| Modelo small autoentrenado | 256/512 | 256/512 dim. | Compatibilidad de dimensiones |
💼 Sugerencia de migración empresarial: Muchos sistemas antiguos de bases de datos vectoriales (Milvus / Qdrant / pgvector) tienen tablas creadas con dimensiones fijas. Lo ideal es seleccionar primero una versión de
text-embedding-v4con la misma dimensión que la antigua para un reemplazo fluido, y luego, según sea necesario, actualizar gradualmente a dimensiones mayores. Esta es la ruta de menor resistencia. En la documentación de APIYI (apiyi.com) también proporcionamos ejemplos de código para conectar con las bases de datos vectoriales más populares.
V. Primeros pasos con text-embedding-v4: Invocación de API y parámetros de dimensión
Una vez explicados los principios técnicos, vamos directo al código. A continuación, presentamos el ejemplo de invocación más conciso, cubriendo tanto el protocolo compatible con OpenAI como el protocolo nativo de DashScope.
5.1 Invocación de text-embedding-v4 usando el protocolo compatible con OpenAI
DashScope de Alibaba Cloud proporciona puntos de acceso compatibles con OpenAI, lo cual es ideal para equipos que ya tienen integraciones con OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Punto de acceso unificado de APIYI
)
# Invocar text-embedding-v4, especificando 1024 dimensiones
response = client.embeddings.create(
model="text-embedding-v4",
input="¿Cómo configurar la dimensión vectorial de text-embedding-v4?",
dimensions=1024 # Opcional: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"Dimensión: {len(vector)}") # Salida: Dimensión: 1024
print(f"Primeras 5 dimensiones: {vector[:5]}")
⚙️ Explicación de parámetros:
dimensionses el nuevo parámetro clave de la v4; aunque ya se soportaba desde la v3, en la v4 se ha extendido a 8 opciones. Si se omite este parámetro, se utilizan 1024 dimensiones por defecto.
5.2 Invocación por lotes: Concurrencia y límites de velocidad de text-embedding-v4
En entornos de producción reales, a menudo es necesario procesar datos por lotes. text-embedding-v4 admite hasta 25 entradas por solicitud:
texts = [
"El papel central de la dimensión vectorial es equilibrar precisión y costo",
"text-embedding-v4 admite 8 dimensiones, desde 64 hasta 2048",
"El aprendizaje de representación tipo Matryoshka es la tecnología clave",
# ... hasta 25 elementos
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"Número de vectores por lote: {len(vectors)}")
5.3 Codificación asimétrica para query y document
text-embedding-v4 admite funciones avanzadas no presentes en el protocolo estándar de OpenAI: distinguir entre la consulta de búsqueda (query) y el documento recuperado (document) mediante text_type, lo que mejora aún más la precisión. Esta función requiere el uso del protocolo nativo de DashScope o la encapsulación compatible de la plataforma APIYI:
# Codificación del lado del documento (al indexar)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["text-embedding-v4 ofrece 8 opciones de dimensiones vectoriales"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# Codificación del lado de la consulta (al buscar)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["¿Qué dimensiones admite v4?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 Valor de la codificación asimétrica: Tras distinguir la codificación entre query y document, la tasa de recuperación Top-1 suele mejorar entre 2 y 3 puntos en escenarios de consultas cortas y documentos largos. Recomendamos encarecidamente activar esta función en entornos de producción.
5.4 Integración de text-embedding-v4 con bases de datos vectoriales
La carga de vectores es un paso crítico para implementar un sistema RAG. A continuación, mostramos el flujo completo desde la incrustación de texto hasta la carga en Qdrant, una base de datos muy utilizada en la industria:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# Inicializar cliente
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# Clave: la dimensión de la colección debe coincidir con las dimensiones de embedding
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# Incrustación por lotes y carga
texts = ["text-embedding-v4 es el modelo de incrustación más reciente de Alibaba Tongyi", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ Recordatorio importante: El campo
sizede la base de datos vectorial debe coincidir estrictamente condimensions. Si deseas actualizar la dimensión más adelante, deberás recrear la colección y volver a realizar la incrustación completa.
5.5 Integración de text-embedding-v4 con LangChain / LlamaIndex
Los marcos de trabajo RAG más populares ya admiten la integración de embeddings mediante el protocolo compatible con OpenAI, y la configuración es muy sencilla:
# Ejemplo de integración con LangChain
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# Integración perfecta con bases de datos vectoriales de LangChain
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("¿Cómo elegir la dimensión?")
Al conectarse mediante el protocolo compatible con OpenAI, casi todos los proyectos RAG basados originalmente en OpenAI ada-002 o 3-large pueden migrarse a text-embedding-v4 sin cambiar una sola línea de código, bastando con modificar los parámetros model y base_url.
VI. Estrategia de selección de dimensiones para text-embedding-v4: 5 escenarios típicos
Ahora que ya dominas la teoría y las interfaces, aquí tienes un marco de trabajo que puedes aplicar directamente para elegir la configuración ideal.
6.1 Escenario A: RAG para bases de conocimiento empresariales (millones de documentos)
Requisito principal: Precisión de recuperación > Coste
Configuración recomendada:
- Dimensión: 1024 dimensiones (valor predeterminado, la mejor relación coste-beneficio)
- Habilitar codificación asimétrica query/document
- Base de datos vectorial compatible: Milvus / Qdrant / pgvector
- Re-ranking: Se recomienda integrar Qwen3-Reranker
6.2 Escenario B: Búsqueda de productos en e-commerce (decenas de millones de SKU)
Requisito principal: Velocidad de búsqueda > Precisión
Configuración recomendada:
- Dimensión: 512 dimensiones (equilibrio) o 256 dimensiones (velocidad máxima)
- Usar codificación de consulta (query) para títulos de productos y codificación de documento (document) para detalles
- Índice ANN recomendado: Combinación de HNSW + IVF
6.3 Escenario C: Deduplicación de similitud en logs masivos (cientos de millones de logs)
Requisito principal: Coste de almacenamiento > Precisión
Configuración recomendada:
- Dimensión: 128 dimensiones
- Combinar con cuantización binaria (Binary Quantization) para comprimir 32 veces más
- Las pruebas demuestran que la tasa de recuperación se mantiene por encima del 85%
6.4 Escenario D: Búsqueda de alta precisión (legal / médico)
Requisito principal: Precisión ante todo, baja sensibilidad al coste
Configuración recomendada:
- Dimensión: 2048 dimensiones
- Habilitar codificación asimétrica query/document
- Es imprescindible añadir un re-ranking con Reranker
6.5 Escenario E: Búsqueda local en dispositivos móviles / periféricos
Requisito principal: Uso de memoria < 50 MB
Configuración recomendada:
- Dimensión: 64 dimensiones o 128 dimensiones
- Combinar con cuantización int8 (comprime 4 veces más)
- Ideal para bases de conocimiento locales / asistentes de preguntas y respuestas offline
🎯 Consejo de decisión: Estos 5 escenarios cubren la gran mayoría de las necesidades reales. Nuestra recomendación: empieza con el valor predeterminado de 1024 dimensiones para probar tu conjunto de datos y, según tus necesidades reales de precisión, coste y velocidad, ajusta hacia arriba (2048) o hacia abajo (512/256/128). La plataforma APIYI (apiyi.com) permite cambiar los parámetros de dimensión con un solo clic, facilitando las pruebas A/B rápidas.
6.6 Proceso de toma de decisiones para la selección de dimensiones
Hemos destilado los escenarios anteriores en un flujo de trabajo ejecutable:
-
Paso 1: Evaluar el volumen de datos
- < 1 millón de registros → Se pueden usar dimensiones altas (1024+)
- 1 millón – 100 millones de registros → Dimensiones medias (256-1024)
-
100 millones de registros → Considerar obligatoriamente dimensiones bajas (128-512)
-
Paso 2: Evaluar la tolerancia a la precisión
- Sensible a cada 1% de tasa de recuperación → Elegir 2048
- Aceptable una caída del 5% en la recuperación → Empezar por 1024
- Aceptable una caída del 10% en la recuperación → Basta con 256-512
-
Paso 3: Evaluar las restricciones de hardware
- Búsqueda en GPU en la nube → Dimensiones altas permitidas
- Búsqueda solo en CPU → Mantener por debajo de 1024
- Dispositivos móviles / periféricos → Obligatorio 64-256 dimensiones + cuantización
-
Paso 4: Ejecutar pruebas de validación
- Seleccionar de 100 a 500 consultas reales del negocio como conjunto de evaluación
- Calcular la tasa de recuperación Top-10 bajo diferentes dimensiones
- Elegir la dimensión más baja justo antes del "punto de inflexión" de la tasa de recuperación
💡 Consejo de eficiencia: Este proceso implica múltiples invocaciones del modelo y cambios de parámetros. Se recomienda realizarlo en una plataforma de acceso unificado para obtener registros de solicitud completos y monitoreo de uso, facilitando la colaboración del equipo en la selección.
VII. Comparativa de text-embedding-v4 con los principales modelos de incrustación
Analicemos text-embedding-v4 en el contexto de la industria para facilitar tu elección técnica.
| Modelo | Proveedor | Dimensión máx. | Flexibilidad de dimensión | MTEB Global | Capacidad en chino | Longitud de contexto | Precio API |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | Alibaba Tongyi | 2048 | ⭐⭐⭐⭐⭐ (8 tipos) | 71.58 | Excelente | 32K | Medio |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (Cualquiera) | 64.6 | Medio | 8K | Alto |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (Cualquiera) | 62.3 | Medio | 8K | Bajo |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 tipos) | 70.3 | Fuerte | 128K | Medio-Alto |
| BGE-M3 | BAAI | 1024 | ⭐⭐ (Fijo) | 65.5 | Fuerte | 8K | Autohospedado |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 tipos) | 67.1 | Medio | 32K | Medio |
| Qwen3-Embedding-8B (Open Source) | Alibaba Tongyi | 4096 | ⭐⭐⭐⭐⭐ (Cualquiera) | 70.58 | Excelente | 32K | Autohospedado |
De esta tabla comparativa podemos extraer varias conclusiones clave:
- Escenarios bilingües (chino-inglés): La puntuación global CMTEB de 71.99 de text-embedding-v4 ocupa el primer lugar entre todas las API comerciales.
- Flexibilidad de dimensiones: Las 8 dimensiones recomendadas oficialmente por la v4 son más flexibles que las de la mayoría de los modelos, lo que facilita enormemente la migración.
- Relación coste-beneficio: El precio de la API de la v4 se sitúa en un nivel medio entre los modelos comerciales principales, pero su precisión compite directamente con text-embedding-3-large de OpenAI.
📌 Consejo de integración: Si tu equipo necesita utilizar varios modelos como OpenAI, Claude o Qwen simultáneamente, te recomendamos acceder a través de una plataforma de servicio proxy de API unificada como APIYI (apiyi.com). Esto evita la gestión de múltiples claves API y los problemas de acceso desde China. La documentación también incluye ejemplos de invocación del modelo en paralelo entre la v4 y otros modelos de incrustación principales.
VIII. Preguntas frecuentes (FAQ) sobre text-embedding-v4
Q1: ¿Cuál es la dimensión predeterminada de text-embedding-v4?
La dimensión predeterminada de text-embedding-v4 es 1024. Si no se pasa explícitamente el parámetro dimensions durante la invocación del modelo, se devolverá un vector de 1024 dimensiones. Esta es también la dimensión recomendada oficialmente por Alibaba por su mejor relación calidad-precio.
Q2: ¿Puedo actualizar un índice ya creado con 1024 dimensiones a 2048?
Es necesario reconstruir toda la base de datos vectorial. El mecanismo de "muñeca rusa" (MRL) garantiza que "tomar las primeras N dimensiones de un vector de alta dimensión" equivale a un "vector de baja dimensión", pero a la inversa, "rellenar con ceros un vector de baja dimensión para subirlo a una alta" es ineficaz. Al actualizar, se recomienda:
- Mantener el índice antiguo de 1024 dimensiones en servicio.
- Re-incrustar (re-embed) todos los documentos con las 2048 dimensiones de v4.
- Realizar un cambio de tráfico gradual (canary deployment) para verificar la mejora en la precisión.
- Desactivar el índice antiguo una vez completado el proceso.
Q3: ¿Se puede invocar text-embedding-v4 directamente desde China?
El punto de conexión (endpoint) oficial de text-embedding-v4 se encuentra en dashscope.aliyuncs.com (Beijing), por lo que la conexión es directa desde China. Los desarrolladores locales solo necesitan registrar una cuenta de Alibaba Cloud u obtener una clave API a través de plataformas de servicio proxy de API como APIYI (apiyi.com) para comenzar a usarlo, sin necesidad de configuraciones de red adicionales.
Q4: ¿Cómo elegir entre text-embedding-v4 y la versión de código abierto Qwen3-Embedding?
| Factor de decisión | Elegir versión API (v4) | Elegir versión Open Source (Qwen3-Embedding-8B) |
|---|---|---|
| Sensibilidad de datos | Sensibilidad media | Sensibilidad extrema (Finanzas/Salud) |
| Volumen mensual | < 1 mil millones de Tokens | > 1 mil millones de Tokens |
| Recursos GPU del equipo | Ninguno | Posee clúster A100/H100 |
| Capacidad de ingeniería | Equipos pequeños/medianos | Cuenta con equipo MLOps |
| Recomendación general | ✅ Recomendado: API v4 | ✅ Recomendado: Autodespliegue |
Q5: ¿El modelo arrojará un error si la configuración de dimensión es incorrecta?
text-embedding-v4 solo acepta valores dentro de [64, 128, 256, 512, 768, 1024, 1536, 2048]. Si se introducen otros valores (como 333 o 500), se producirá un error de parámetro. Si necesitas una dimensión no estándar, elige la dimensión oficial más cercana y realiza un truncamiento o relleno posteriormente.
Q6: ¿Cómo evaluar qué dimensión elegir para mi negocio?
Recomendamos un método de tres pasos:
- Establecer la línea base: Ejecuta el flujo de negocio con la dimensión predeterminada de 1024 y registra la tasa de recuperación (recall), la latencia y los costos de almacenamiento.
- Pruebas a la baja: Cambia sucesivamente a 512, 256 y 128 dimensiones, observando cuánto disminuye la tasa de recuperación.
- Encontrar el punto óptimo: Identifica la dimensión donde la "caída en la recuperación sea aceptable + el ahorro de costos sea máximo", que suele ser 256 o 512 dimensiones.
Q7: ¿Se liberará el código fuente de text-embedding-v4?
La estrategia actual de Alibaba es mantener la versión API y la versión de código abierto en paralelo: la API comercial de text-embedding-v4 se actualiza continuamente, beneficiándose de las últimas optimizaciones de ingeniería y aumento de datos; mientras que la versión de código abierto publica los pesos de la serie Qwen3-Embedding para la comunidad. Ambas comparten la misma tecnología pero tienen formatos de producto distintos; no se prevé que v4 se libere como código abierto por separado.
Q8: ¿Es siempre mejor una dimensión más alta?
No. La elección de la dimensión es, en esencia, un equilibrio entre precisión, almacenamiento y velocidad:
- A mayor dimensión → mayor techo de precisión, pero con rendimientos decrecientes.
- A mayor dimensión → los costos de almacenamiento y recuperación crecen de forma lineal o incluso superlineal.
- A mayor dimensión → la precisión de los índices ANN puede incluso disminuir debido a la maldición de la dimensionalidad.
Por experiencia, 256-1024 dimensiones es el rango de trabajo óptimo para la mayoría de los negocios. Superar las 1024 dimensiones solo vale la pena si existe una necesidad clara de mayor precisión.
Q9: ¿Cómo es el rendimiento de text-embedding-v4 en textos largos?
text-embedding-v4 admite una longitud de entrada máxima de 32K Tokens, pero el efecto de recuperación real disminuye a medida que aumenta la longitud del texto. Se recomienda seguir estos principios:
- Textos cortos (< 512 Tokens): Incrustar el párrafo completo directamente para obtener el mejor resultado.
- Longitud media (512-4K Tokens): Considerar la incrustación por bloques con ventana deslizante.
- Documentos largos (> 4K Tokens): Es obligatorio dividir (chunk) antes de incrustar; se recomienda un tamaño de bloque de 256-512 Tokens.
- Documentos extralargos: Se puede combinar con recuperación jerárquica (primero general, luego detallada) para mejorar la eficiencia.
Q10: ¿Se pueden mezclar diferentes dimensiones?
No. Todos los vectores en una misma base de datos o índice deben tener la misma dimensión; de lo contrario, el cálculo de similitud carecerá de sentido. Si el negocio realmente requiere una estrategia de "documentos de alta prioridad con 2048 dimensiones + documentos normales con 512", se recomienda crear dos colecciones independientes y gestionar la fusión de resultados en la capa de aplicación.
Q11: ¿Afecta el parámetro de dimensión a la facturación de la API?
La facturación de text-embedding-v4 se basa totalmente en el número de Tokens de entrada y no tiene relación con la dimensión de salida. Es decir, ya sea que elijas 64 o 2048 dimensiones, el costo de procesar 1000 Tokens de entrada es el mismo. Esto significa que puedes elegir dimensiones altas con confianza durante la fase de invocación de la API; la verdadera diferencia de costos se refleja principalmente en las etapas de almacenamiento y recuperación posteriores.
Q12: ¿Cómo manejar fallos en la incrustación o límites de tasa (rate limiting)?
Al invocar text-embedding-v4 en un entorno de producción, se recomienda implementar el siguiente manejo de robustez:
- Mecanismo de reintento: Implementar reintentos con retroceso exponencial para errores 5xx (se recomiendan 3 intentos).
- Manejo de límites de tasa: Monitorear errores 429; si ocurren, reducir la concurrencia o cambiar de canal de acceso.
- Tamaño de lote: Máximo 25 textos por solicitud; si se supera, dividir automáticamente en lotes.
- Configuración de tiempo de espera: Para incrustación de textos largos, se recomienda establecer un tiempo de espera superior a 60 segundos.
- Plan de degradación: Configurar un modelo de respaldo (como v3 de 1024 dimensiones) como medida de seguridad.
IX. Resumen: Puntos clave para la selección de dimensiones en text-embedding-v4
Repasando todo el artículo, los puntos más importantes sobre las 8 dimensiones vectoriales de text-embedding-v4 son:
- text-embedding-v4 es el buque insignia comercial de la serie Qwen3-Embedding, con un rendimiento líder en escenarios bilingües chino-inglés (MTEB 71.58 / CMTEB 71.99).
- Las 8 dimensiones son, en esencia, producto de la tecnología de "muñeca rusa" (Matryoshka); se pueden usar las primeras N dimensiones con una pérdida de calidad controlada.
- 1024 dimensiones es el valor predeterminado recomendado, logrando el equilibrio óptimo entre precisión y costo.
- 2048 dimensiones son adecuadas para escenarios de precisión extrema, mejorando 1 punto en la recuperación CMTEB frente a las 1024.
- 256-512 dimensiones son ideales para escenarios de escala media y sensibilidad al costo, siendo el punto óptimo práctico para la mayoría de los sistemas RAG.
- 64-128 dimensiones solo se recomiendan para dispositivos periféricos o almacenamiento extremo, requiriendo pruebas exhaustivas de la degradación de la tasa de recuperación.
- La elección de la dimensión no es una decisión definitiva, se recomienda encarecidamente ejecutar pruebas con el conjunto de datos del negocio antes de tomar la decisión final.
- Al migrar de otros modelos a v4, prioriza la versión con dimensiones alineadas para una transición fluida.
🎯 Recomendación final: Si estás seleccionando un modelo de incrustación para un nuevo proyecto, comienza directamente con text-embedding-v4 + 1024 dimensiones; si el negocio es altamente sensible a la tasa de recuperación, aumenta a 2048 dimensiones y añade un Reranker. Recomendamos acceder a través de la plataforma APIYI (apiyi.com), que ofrece una interfaz compatible con OpenAI, cambios de dimensión convenientes y documentación completa, lo que reduce significativamente los costos de ingeniería y permite que el equipo se concentre en optimizar los resultados del negocio en lugar de adaptar la API.
La tecnología de incrustación vectorial evoluciona rápidamente: desde la era de dimensiones fijas de OpenAI hasta la implementación de MRL en 8 dimensiones oficiales por parte de text-embedding-v4, los desarrolladores han ganado una flexibilidad sin precedentes. Dominar la esencia y las estrategias de selección de dimensiones vectoriales es una capacidad esencial para cualquier equipo que construya sistemas de RAG, búsqueda semántica o recomendación.
Autor: Equipo técnico de APIYI | Enfocados en la implementación práctica de modelos de lenguaje grandes (LLM). Para más contenido técnico, visita APIYI apiyi.com