Nota del autor: Análisis profundo de las 6 razones del alto consumo de tokens en OpenClaw, con estrategias de optimización probadas para reducir los costos de API entre un 60% y 80%. Incluye planes de ahorro con bonificaciones de recarga en APIYI.
"1.8 millones de tokens en un mes, una factura de 3600 dólares" —— Esta es la experiencia real del blogger tecnológico Federico Viticci usando OpenClaw. Aunque OpenClaw es de código abierto y gratuito, la velocidad de consumo de tokens ha tomado por sorpresa a muchos usuarios. En este artículo, analizaremos a fondo las 6 razones principales por las que OpenClaw agota tus tokens y te daremos una guía práctica de ahorro.
Valor principal: Al terminar de leer, entenderás los principios técnicos detrás del alto consumo de OpenClaw, dominarás 6 métodos de optimización efectivos y descubrirás cómo reducir tus costos por debajo del 90% del precio oficial mediante las promociones de APIYI.
Datos clave del consumo de tokens en OpenClaw
| Tipo de usuario | Tokens/mes promedio | Costo/mes promedio | Escenario típico |
|---|---|---|---|
| Ligero | 5M – 20M | $10-30 | Consultas diarias, tareas simples |
| Moderado | 20M – 50M | $30-70 | Flujos de trabajo automatizados |
| Pesado | 50M – 200M | $70-150+ | Asistente 24/7 |
| Caso extremo | 180M+ | $3600+ | Prueba real del blogger de MacStories |
¿Por qué OpenClaw consume tantos tokens?
OpenClaw (antes conocido como Clawdbot/Moltbot) es el proyecto de asistente de IA de código abierto más popular de 2026, con más de 135,000 estrellas en GitHub. Es increíblemente potente: puede conectarse a más de 12 plataformas de mensajería, controlar el navegador, ejecutar comandos de Shell y automatizar tareas diarias. Sin embargo, detrás de este poder se esconde un consumo de tokens asombroso.
Muchos usuarios configuran OpenClaw con entusiasmo y, al día siguiente, se quedan helados al ver la factura de la API: decenas o incluso cientos de dólares. Algunos han reportado "quemar 200 dólares en un día" debido a tareas automatizadas que entraron en un bucle infinito.
Entender por qué se consumen los tokens es el primer paso para optimizar los costos.
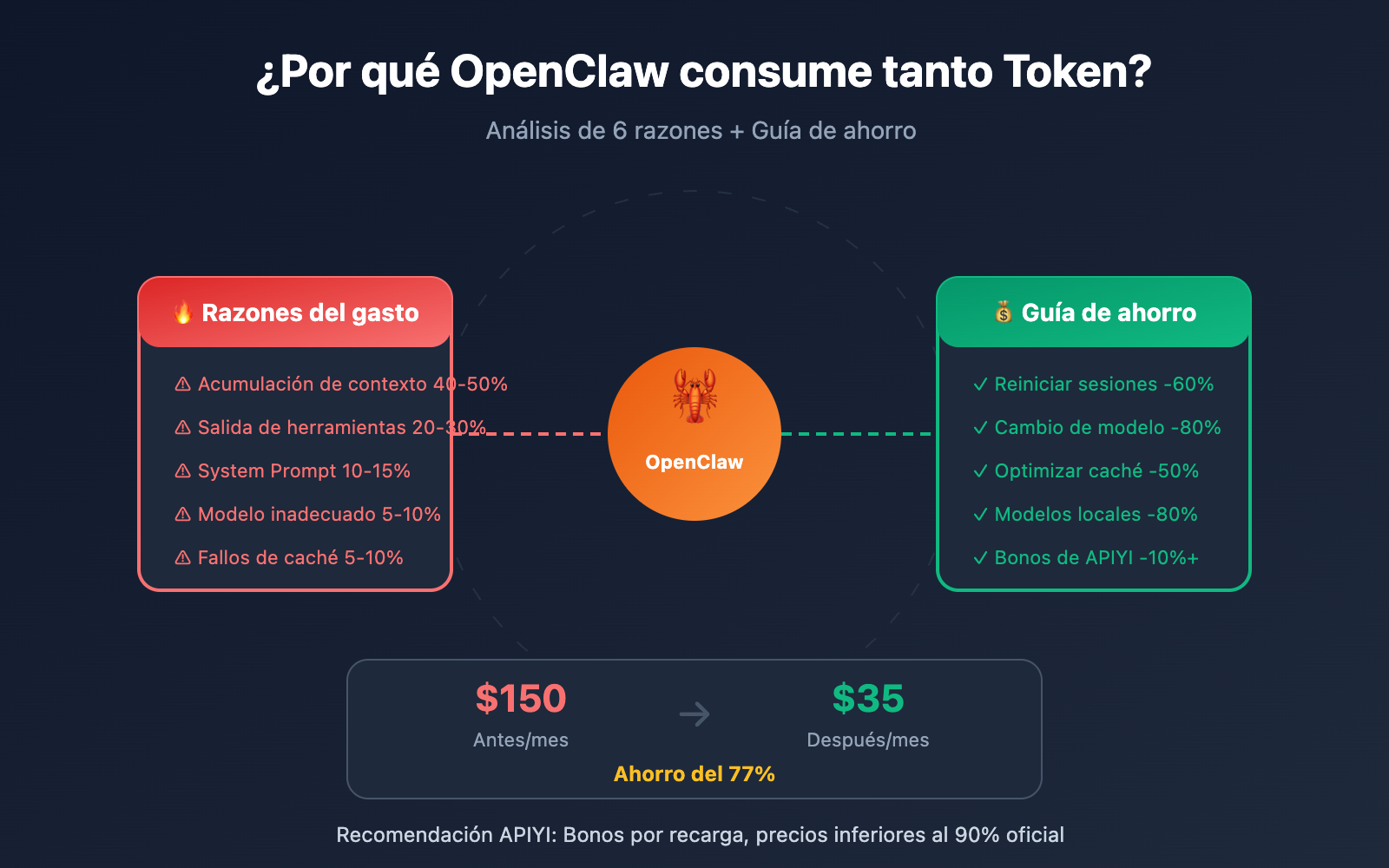
Las 6 razones principales del gasto en OpenClaw
| Razón | % de consumo | Explicación técnica | Nivel de optimización |
|---|---|---|---|
| Acumulación de contexto | 40-50% | El historial de la sesión crece sin parar | ⭐⭐⭐⭐⭐ |
| Salida de herramientas | 20-30% | JSON grandes o logs guardados en el historial | ⭐⭐⭐⭐ |
| System Prompt | 10-15% | Se envía repetidamente en cada petición | ⭐⭐⭐ |
| Inferencia multivuelta | 10-15% | Tareas complejas requieren múltiples llamadas | ⭐⭐ |
| Elección de modelo | 5-10% | Opus es 25 veces más caro que Haiku | ⭐⭐⭐⭐⭐ |
| Fallos de caché | 5-10% | La caché expira y se vuelve a facturar | ⭐⭐⭐⭐ |
Análisis profundo de las causas del consumo de tokens en OpenClaw
Causa 1: Acumulación continua de la ventana de contexto
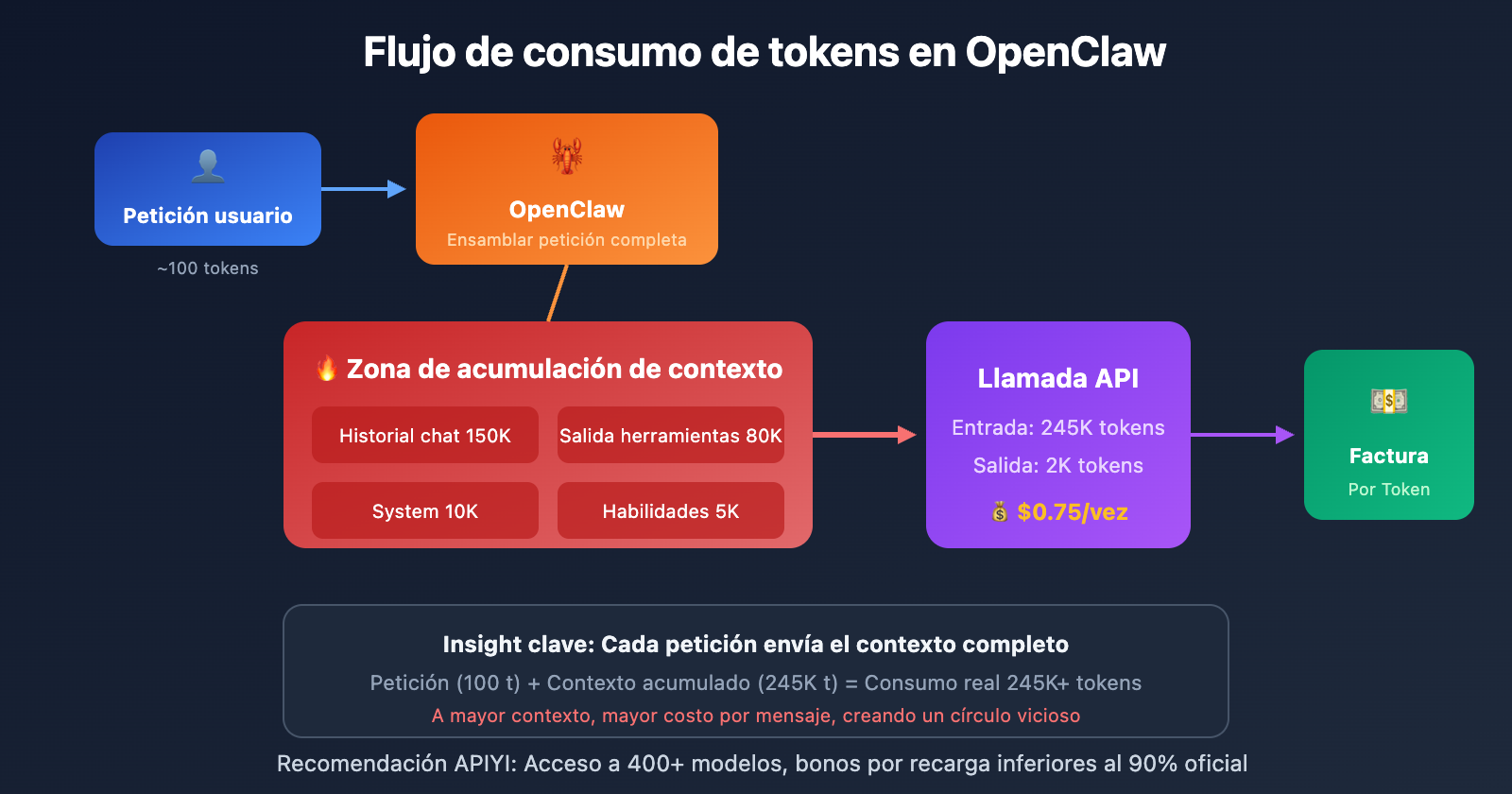
Este es el mayor "agujero negro de gastos" de OpenClaw. Cada vez que conversas con OpenClaw, todo el historial de mensajes se guarda en archivos JSONL dentro del directorio .openclaw/agents.main/sessions/.
El problema es: en cada nueva solicitud, OpenClaw envía el historial completo de la sesión al modelo de IA.
Un usuario comentó que el contexto de su sesión principal ya ocupaba entre el 56% y el 58% de una ventana de 400K, lo que significa:
- Incluso para hacer una pregunta sencilla, se procesan más de 200,000 tokens de contexto en caché.
- Cada interacción genera un
cacheReadde cientos de miles de tokens. - Cuanto más larga es la sesión, el costo crece de forma exponencial.
# Ver el consumo de tokens de la sesión actual
openclaw /status
# Ejemplo de resultado:
# 🤖 Model: claude-sonnet-4
# 📊 Context: 234,567 / 400,000 tokens (58.6%)
# 💰 Estimated cost this session: $12.34
Causa 2: Almacenamiento ilimitado de salidas de herramientas
OpenClaw guarda todas las salidas de las llamadas a herramientas en el registro de la sesión. El problema surge cuando ejecutas lo siguiente:
| Operación peligrosa | Tamaño de salida | Consecuencia |
|---|---|---|
config.schema |
Decenas de miles de tokens | Un JSON gigante se guarda en el contexto |
status --all |
Miles de tokens | Registro completo del estado del sistema |
Recorrido de directorios find |
Decenas de miles de tokens | Se almacena la lista de todos los archivos |
| Exportación de logs | Decenas de miles de tokens | El log completo entra en el registro |
Un desarrollador compartió: "Solo le pedí a OpenClaw que me ayudara a ver la estructura del proyecto; recorrió todo el directorio y generó una lista de archivos de miles de líneas que se guardó en la sesión. Después de eso, en cada mensaje, toda esa información inútil se reenviaba al modelo".
Causa 3: Reenvío del System Prompt en cada llamada
OpenClaw utiliza una indicación del sistema (System Prompt) compleja que incluye:
- Configuración de la personalidad principal.
- Lista de herramientas disponibles.
- Reglas de restricción de seguridad.
- Configuración de preferencias del usuario.
Esta indicación suele tener entre 5,000 y 10,000 tokens y se envía en cada llamada a la API. Aunque Anthropic ofrece Prompt Caching (donde los aciertos de caché solo cuestan el 10%), el caché tiene un límite de TTL:
| Proveedor | TTL de caché | Consecuencia al expirar |
|---|---|---|
| Anthropic | 5 minutos | Se factura de nuevo a precio completo |
| OpenAI | 1 hora | Invalida automáticamente |
Si no lo usas de forma continua, cada "arranque en frío" te costará el precio total.
Causa 4: Razonamiento multivuelta en tareas complejas
La potencia de OpenClaw reside en su capacidad para completar tareas complejas de forma autónoma, pero esto implica más llamadas a la API:
Usuario: Ayúdame a organizar mis correos de hoy y crea tareas pendientes.
Proceso interno de OpenClaw:
1. Llama al Skill de correo para obtener la lista → Consume tokens
2. Analiza el contenido de cada correo → Consume tokens
3. Determina la prioridad y categoría → Consume tokens
4. Llama al Skill de Todoist para crear tareas → Consume tokens
5. Genera un informe de resumen → Consume tokens
Consumo real: 5-10 llamadas a la API, cada una con el contexto completo.
Causa 5: Selección inadecuada del modelo
Muchos usuarios utilizan por defecto Claude Opus 4.5 o Sonnet 4.5, pero no todas las tareas requieren un Modelo de Lenguaje Grande de primer nivel:
| Modelo | Precio de entrada | Precio de salida | Escenario de uso |
|---|---|---|---|
| Claude Opus 4.5 | $15/M | $75/M | Razonamiento complejo, escritura creativa |
| Claude Sonnet 4.5 | $3/M | $15/M | Tareas diarias, generación de código |
| Claude Haiku 4.5 | $1/M | $5/M | Preguntas simples, conversión de formatos |
| Gemini 3.0 Flash | $0.075/M | $0.30/M | Procesamiento por lotes, sensible al costo |
¡La diferencia de precio es de hasta 25 veces! Usar Opus para preguntar "¿cómo está el clima hoy?" es un desperdicio total.
Causa 6: Heartbeat y tareas en segundo plano
La función Heartbeat de OpenClaw permite que la IA se "despierte" activamente para ejecutar tareas programadas. Sin embargo, muchos usuarios no saben que:
- Cada activación del Heartbeat es una llamada completa a la API.
- Si se configura mal, podría activarse cada pocos minutos.
- Cada activación arrastra el contexto completo de la sesión.
Un usuario comentó: "Configuré una revisión de correo cada 5 minutos y, al final del día, solo el Heartbeat había consumido 50 dólares".
6 grandes estrategias para optimizar tokens en OpenClaw
Estrategia 1: Reiniciar sesiones periódicamente (Ahorro 40-60%)
Este es el método más efectivo. Cuando el contexto de la sesión se infle, reinícialo sin dudar:
# Método 1: Reiniciar dentro de la conversación
openclaw "reset session"
# Método 2: Eliminar archivos de sesión
rm -rf ~/.openclaw/agents.main/sessions/*.jsonl
# Método 3: Usar el comando /compact para comprimir
openclaw /compact
Mejor práctica: Reinicia la sesión cada vez que termines una tarea independiente; no permitas que el contexto se acumule indefinidamente.
Estrategia 2: Aislar operaciones de gran salida (Ahorro 20-30%)
Nunca ejecutes comandos que puedan generar una gran salida en la sesión principal:
# ❌ Incorrecto: Ejecutar en la sesión principal
openclaw "mostrar la configuración completa del sistema"
# ✅ Correcto: Usar una sesión de depuración independiente
openclaw --session debug "mostrar la configuración completa del sistema"
# Luego, copia solo el fragmento necesario a la sesión principal
Estrategia 3: Configurar cambio inteligente de modelo (Ahorro 50-80%)
Selecciona automáticamente el modelo según la complejidad de la tarea:
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4",
"fallback": "anthropic/claude-haiku-4"
}
}
},
"routing": {
"simple_queries": "haiku",
"complex_tasks": "sonnet",
"critical_decisions": "opus"
}
}
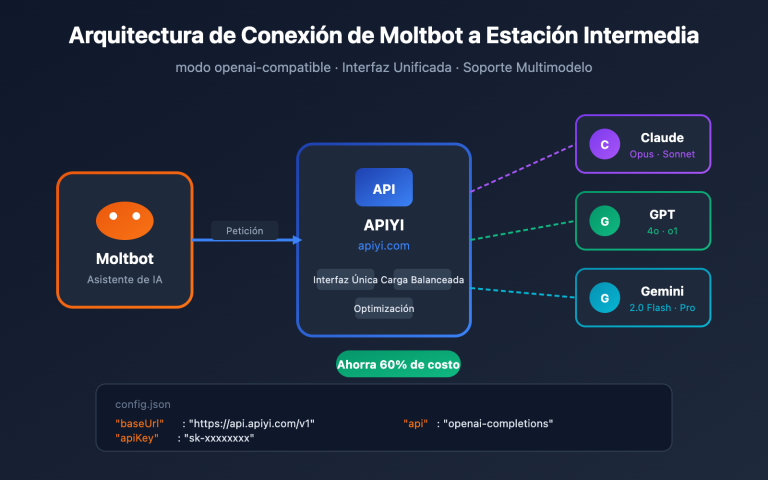
🎯 Consejo de ahorro: Usa Haiku o Gemini Flash para tareas diarias y cambia a Sonnet/Opus solo para razonamientos complejos. A través de APIYI (apiyi.com) puedes acceder a más de 400 Modelos de Lenguaje Grande con una interfaz unificada para cambiar de forma flexible y encontrar la combinación con mejor relación costo-beneficio.
Estrategia 4: Activar optimización de caché (Ahorro 30-50%)
Aprovecha al máximo el mecanismo de Prompt Caching:
{
"agents": {
"defaults": {
"cache-ttl": 3600,
"temperature": 0.2
}
}
}
Trucos clave:
- Configura una temperatura baja (0.2) para aumentar la tasa de aciertos de caché.
- Configura el intervalo de Heartbeat para que sea ligeramente menor al TTL del caché, manteniendo el caché "caliente".
- Usa servicios intermediarios como OpenRouter que soporten almacenamiento en caché.
Estrategia 5: Limitar la ventana de contexto (Ahorro 20-40%)
Controla activamente el tamaño del contexto:
{
"agents": {
"defaults": {
"contextTokens": 50000,
"compaction": "aggressive"
}
}
}
Limitar el contexto a 50K-100K en lugar de los 400K por defecto puede reducir drásticamente el costo de cada solicitud.
Estrategia 6: Usar modelos locales como respaldo (Ahorro 60-80%)
Configura modelos locales a través de Ollama para manejar tareas sencillas:
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://localhost:11434",
"models": ["llama3.3", "qwen2.5"]
}
}
},
"routing": {
"simple_queries": "ollama/llama3.3"
}
}
Los modelos locales tienen costo cero de API, lo que los hace ideales para conversiones de formato simples, consultas de información y otras tareas básicas.
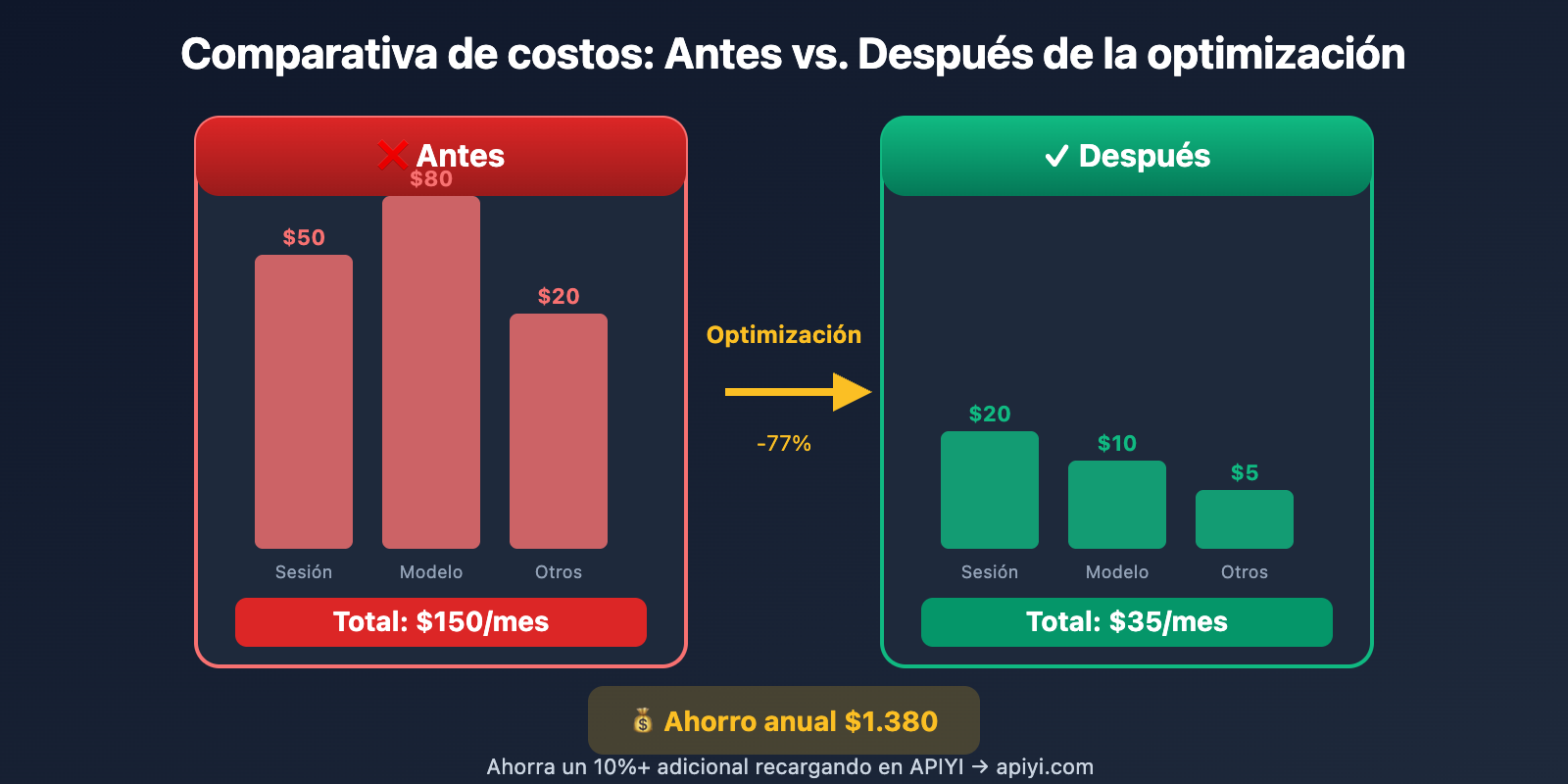
Comparativa real de optimización de costos en OpenClaw
| Ítem de optimización | Costo antes | Costo después | Porcentaje de ahorro |
|---|---|---|---|
| Gestión de sesiones | $50/mes | $20/mes | 60% |
| Cambio de modelo | $80/mes | $25/mes | 69% |
| Optimización de caché | $40/mes | $20/mes | 50% |
| Respaldo local | $30/mes | $5/mes | 83% |
| Optimización integral | $150/mes | $35/mes | 77% |
Datos reales: Un usuario intensivo logró reducir su costo mensual promedio de $150 a $35 mediante una optimización integral, lo que representa un ahorro superior al 75%.
Reduce costos aún más con APIYI
Incluso después de aplicar todas las optimizaciones anteriores, el costo de las llamadas a la API sigue siendo el gasto principal en OpenClaw. En este punto, elegir el proveedor de API adecuado se vuelve fundamental.
Promoción de bonos por recarga en APIYI
APIYI (apiyi.com) ofrece una interfaz unificada para más de 400 Modelos de Lenguaje Grande. Sus precios son equivalentes a los oficiales, pero puedes bajarlos aún más aprovechando sus promociones de recarga:
| Monto de recarga | Proporción de bono | Saldo real acreditado | Descuento equivalente |
|---|---|---|---|
| $20 | 5% | $21 | 5% de dto. |
| $50 | 8% | $54 | 7% de dto. |
| $100 | 10% | $110 | 9% de dto. |
| $200 | 12% | $224 | 11% de dto. |
| $500+ | 15% | $575+ | 13% de dto. |
Hagamos cuentas: Si consumes $100 al mes en APIs, al recargar $100 en APIYI obtienes un bono del 10%, lo que equivale a ahorrar $10 mensuales. Al año, eso suma $120, suficiente para cubrir una suscripción a Claude Pro.
Otras ventajas de APIYI
| Ventaja | Descripción | Valor para usuarios de OpenClaw |
|---|---|---|
| 400+ modelos | Acceso centralizado a todos los modelos principales | Flexibilidad para cambiar y encontrar la mejor relación calidad-precio |
| Interfaz unificada | Formato compatible con OpenAI | Integración fluida y sin complicaciones con OpenClaw |
| Saldo en tiempo real | Estadísticas de consumo precisas al centavo | Monitoreo constante de tus costos |
| Sin cuotas mensuales | Pago por uso (pay-as-you-go) | Control total y flexible sobre tus gastos |
| Estable y confiable | Equilibrio de carga en múltiples nodos | Disponibilidad garantizada 24/7 |
Configuración de APIYI como backend de OpenClaw
{
"models": {
"providers": {
"apiyi": {
"type": "openai",
"baseUrl": "https://vip.apiyi.com/v1",
"apiKey": "YOUR_APIYI_KEY",
"models": [
"claude-sonnet-4",
"claude-haiku-4",
"gpt-4o-mini",
"deepseek-v3"
]
}
}
},
"agents": {
"defaults": {
"model": "apiyi/claude-sonnet-4"
}
}
}
Una vez completada la configuración, todas las llamadas a la API de OpenClaw se enrutarán a través de APIYI, permitiéndote disfrutar de los beneficios de sus bonos por recarga.
Preguntas frecuentes
Q1: ¿Puedo ahorrar dinero usando la suscripción de Claude Pro/Max con OpenClaw?
No, y además hacerlo infringe los Términos de Servicio de Anthropic. La suscripción a Claude Pro/Max está limitada exclusivamente al uso directo a través de la interfaz oficial y no puede utilizarse para llamadas a la API de terceros. OpenClaw debe utilizar una API Key bajo el modelo de pago por uso. Por esta razón, los bonos por recarga de APIYI son especialmente valiosos: representan la única vía legal y conforme para ahorrar dinero.
Q2: ¿Cómo puedo monitorear el consumo de tokens en tiempo real?
OpenClaw incluye comandos de monitoreo integrados:
# Ver el estado actual
openclaw /status
# Activar la visualización del uso en cada respuesta
openclaw /usage full
Combinando esto con el saldo en tiempo real y el desglose de consumo en el panel de APIYI, puedes controlar con precisión a dónde va cada centavo.
Q3: ¿Cuánto puedo ahorrar usando Gemini o Deepseek?
En comparación con Claude Sonnet, la diferencia de costos es enorme:
| Modelo | Precio de entrada (Input) | Comparación de costos |
|---|---|---|
| Claude Sonnet 4.5 | $3/M | Referencia |
| Gemini 1.5 Flash | $0.075/M | 40 veces más barato |
| Deepseek V3 | $0.27/M | 11 veces más barato |
A través de APIYI (apiyi.com), puedes acceder a todos estos modelos desde un solo lugar y cambiar entre ellos de forma flexible con una interfaz unificada.
Resumen
Estas son las 6 razones principales por las que OpenClaw consume tokens:
- Acumulación de contexto: El historial de la sesión crece sin límite, siendo el mayor agujero negro de costos.
- Almacenamiento de salidas de herramientas: Los resultados extensos se guardan en el registro y se reenvían en cada interacción.
- Indicación del sistema (System Prompt): Las indicaciones complejas se reenvían cada vez; si el caché expira, se factura a precio completo.
- Razonamiento multivuelta: Las tareas complejas requieren múltiples llamadas a la API.
- Selección inadecuada del modelo: Usar Opus para tareas que Haiku podría resolver.
- Heartbeat frecuente: Las tareas en segundo plano consumen tokens de forma constante.
Estrategias clave para ahorrar:
- Reinicia las sesiones periódicamente para controlar el tamaño del contexto.
- Realiza un cambio inteligente de modelo: usa modelos económicos para tareas sencillas.
- Recarga a través de APIYI (apiyi.com) para obtener bonos adicionales, consiguiendo precios efectivos por debajo del costo oficial.
Te recomendamos visitar APIYI (apiyi.com) para registrar una cuenta. La plataforma ofrece una interfaz unificada para más de 400 modelos y promociones de recarga, permitiendo que tu OpenClaw sea tan potente como económico.
📚 Referencias
⚠️ Nota sobre el formato de los enlaces: Todos los enlaces externos utilizan el formato
Nombre del recurso: domain.com. Esto facilita copiarlos pero evita que sean clicables para prevenir la pérdida de autoridad SEO.
-
Documentación de uso de tokens de OpenClaw: Guía oficial de consumo
- Enlace:
docs.openclaw.ai/token-use - Descripción: Reglas de facturación de tokens y comandos de monitoreo.
- Enlace:
-
GitHub Issue #1594: Discusión sobre el problema de acumulación de contexto
- Enlace:
github.com/openclaw/openclaw/issues/1594 - Descripción: Análisis profundo de la comunidad sobre el problema del "consumo excesivo de tokens".
- Enlace:
-
Página de precios de Anthropic: Precios oficiales de la API de Claude
- Enlace:
anthropic.com/pricing - Descripción: Precios actualizados de cada modelo y descuentos por uso de caché.
- Enlace:
-
Reportaje de Fast Company: Análisis de costos de OpenClaw
- Enlace:
fastcompany.com/91484506/what-is-clawdbot-moltbot-openclaw - Descripción: Cobertura mediática sobre los problemas de altos costos en OpenClaw.
- Enlace:
-
Sitio oficial de APIYI: Acceso integral a más de 400 modelos
- Enlace:
apiyi.com - Descripción: Promociones de recarga con saldo de regalo, con precios un 10% inferiores a los oficiales.
- Enlace:
Autor: Equipo técnico
Intercambio técnico: Te invitamos a participar en la sección de comentarios. Para más estrategias de ahorro, puedes visitar la comunidad técnica de APIYI en apiyi.com.