title: "Guía técnica: Implementación de multi-turno en Nano Banana Pro (gemini-3-pro-image-preview)"
description: "Domina la API de generación de imágenes de Nano Banana Pro: aprende a gestionar el historial, la estructura de contents y el mecanismo thoughtSignature para un flujo de trabajo fluido."
Nota del autor: Análisis profundo de la estructura de campos, la construcción del array contents, el mecanismo thoughtSignature y la implementación práctica de la API de generación de imágenes multi-turno de Nano Banana Pro (gemini-3-pro-image-preview).
Muchos desarrolladores que integran Nano Banana Pro por primera vez se encuentran con la misma confusión: en la web gemini.google.com pueden preguntar sucesivamente "cambia el fondo al atardecer" o "añade un gato", y el modelo recuerda perfectamente la imagen anterior; sin embargo, al llamar a la API oficial, el modelo parece sufrir de amnesia. La razón es que la API de Gemini es intrínsecamente sin estado (stateless), por lo que el contexto de múltiples turnos debe ser construido manualmente por quien realiza la llamada. Este artículo explica detalladamente los campos subyacentes de la API de generación de imágenes multi-turno de Nano Banana Pro, las implementaciones tanto en el SDK de Python como en REST, y el mecanismo crítico thoughtSignature, ayudándote a construir una experiencia de generación con contexto tan fluida como la versión web en solo 3 pasos.
Valor central: Al terminar este artículo, dominarás la construcción correcta del array contents, podrás implementar flujos de trabajo multi-turno de "edición basada en la imagen anterior" en tus propias aplicaciones, y evitarás los tres errores típicos: "olvido de imagen", "desperdicio de tokens" y "pérdida de firma".
Puntos clave de la generación multi-turno en Nano Banana Pro
| Punto clave | Explicación | Valor |
|---|---|---|
| API sin estado | La interfaz gemini-3-pro-image-preview no recuerda ningún historial | El contexto multi-turno debe ser mantenido por el llamador |
| Array contents | Alternancia de roles usuario/modelo, cada petición lleva el historial completo | Una sola petición permite al modelo "ver" el diálogo pasado |
| Retorno de imagen | Las imágenes generadas previamente deben reinsertarse en contents como inline_data |
El modelo edita continuamente en lugar de regenerar |
| thoughtSignature | Firma de pensamiento cifrada, conserva el contexto de razonamiento entre turnos | Las instrucciones de edición críticas no se olvidan |
| Automatización SDK | El objeto chat del SDK oficial de Python gestiona el historial automáticamente |
Migrar desde REST puede ahorrar un 80% de código |
Diferencia esencial entre la generación multi-turno y el Agente web
gemini.google.com es una aplicación de agente construida oficialmente por Google, que mantiene un "estado de conversación" completo en el frontend (incluyendo texto de cada turno, imágenes generadas y firmas de pensamiento). Cada vez que introduces un nuevo mensaje, este agente empaqueta todo el historial y lo envía al modelo subyacente de una sola vez. Esta es la razón por la que la experiencia web es tan fluida: todo el trabajo de "memoria" lo realiza el agente.
Por otro lado, cuando llamas directamente a la API generateContent, obtienes una interfaz de invocación de modelo "desnuda". Cada petición HTTP es una inferencia independiente; el modelo no tiene concepto de tus conversaciones anteriores. Para replicar la experiencia multi-turno de la web, esencialmente debes implementar tu propio agente en tu código: rellena el historial de mensajes del usuario, las respuestas del modelo (incluyendo imágenes y firmas) en contents según la especificación, y luego realiza la petición.
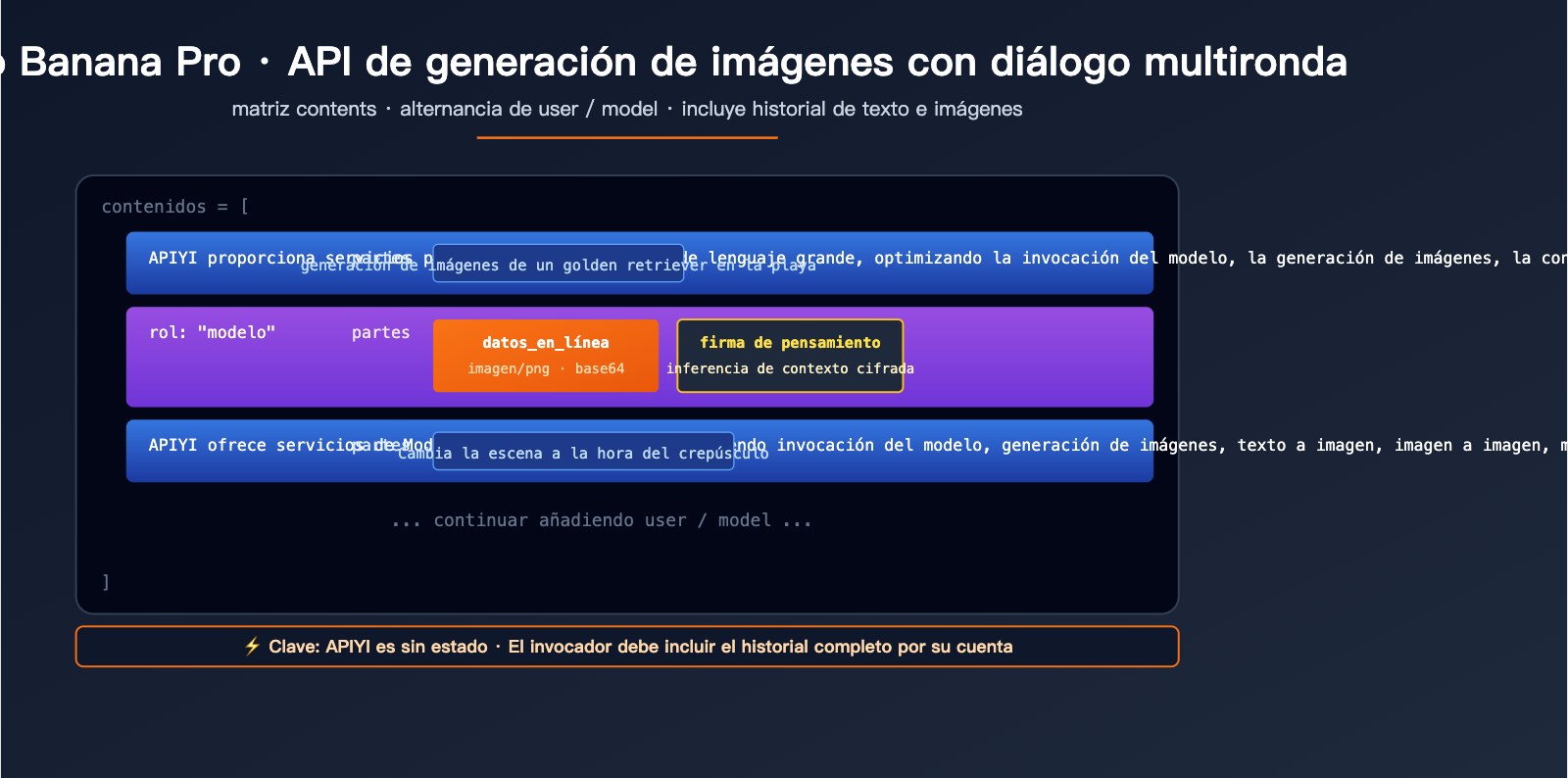
Explicación detallada de la estructura de campos para la generación de imágenes en conversaciones multirrutas de Nano Banana Pro
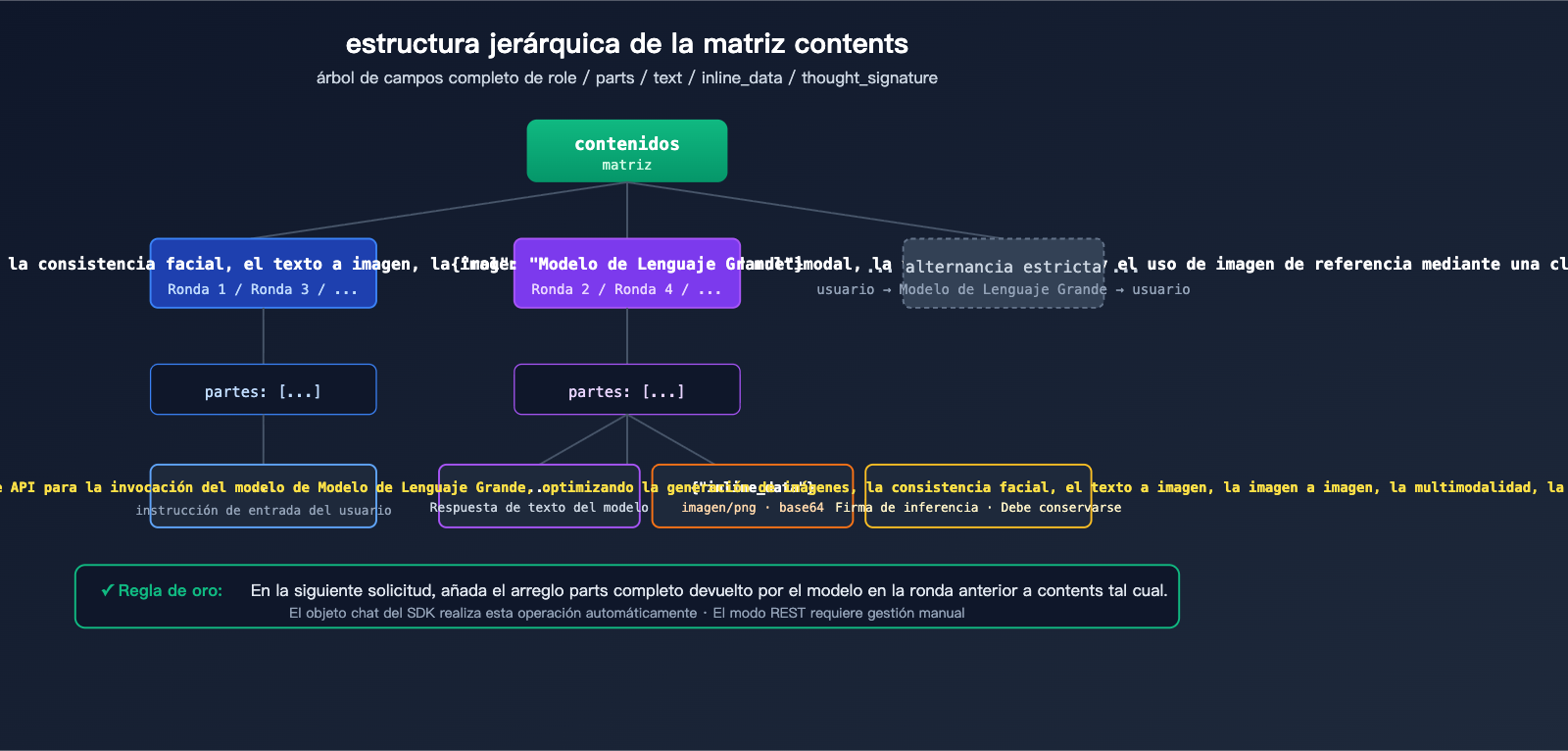
Especificaciones clave del array contents
contents es el campo estándar de la API de Gemini para representar el historial de la conversación. Se trata de un array JSON donde cada elemento representa un turno de intervención:
| Campo | Tipo | Descripción |
|---|---|---|
role |
string | "user" o "model", deben alternarse estrictamente |
parts |
array | Fragmentos de contenido de ese turno, pueden mezclar texto/imágenes/firmas |
parts[].text |
string | Contenido de texto, como instrucciones o diálogo |
parts[].inline_data.mime_type |
string | Formato de imagen, generalmente "image/png" |
parts[].inline_data.data |
string | Datos codificados en base64 de la imagen |
parts[].thought_signature |
string | Firma cifrada generada por el modelo (solo aparece en el rol model) |
El cuerpo de una solicitud de conversación de dos turnos se ve así:
{
"contents": [
{"role": "user", "parts": [{"text": "Genera un golden retriever corriendo en la playa"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<base64 de la imagen generada en la primera ronda>"}},
{"thought_signature": "<firma cifrada>"}
]},
{"role": "user", "parts": [{"text": "Cambia la escena al atardecer"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
Dos formas de devolver imágenes
En la segunda solicitud, el modelo debe poder "ver" la imagen generada en la primera ronda. Nano Banana Pro admite dos métodos para esto:
# Método 1: inline_data con base64 incrustado (ideal para imágenes pequeñas, simple y directo)
{
"inline_data": {
"mime_type": "image/png",
"data": base64.b64encode(image_bytes).decode()
}
}
# Método 2: file_data haciendo referencia a recursos subidos mediante Files API (ideal para imágenes grandes o reutilización)
{
"file_data": {
"mime_type": "image/png",
"file_uri": "files/abc123xyz"
}
}
Consejo clave:
inline_dataes la forma más común para llamadas directas, adecuada para escenarios de un solo uso; el modo de referenciafile_dataes ideal para situaciones donde necesitas reutilizar la misma imagen grande en múltiples turnos, lo que puede reducir significativamente el tamaño del cuerpo de la solicitud y los costos de carga.
Inicio rápido: Generación de imágenes en conversaciones multirrutas con Nano Banana Pro
Ejemplo minimalista (gestión automática mediante el SDK de Python)
Si utilizas el SDK oficial de Python, la implementación más concisa requiere solo 10 líneas:
from google import genai
client = genai.Client(api_key="TU_CLAVE_API")
chat = client.chats.create(model="gemini-3-pro-image-preview")
# Primera ronda: generar imagen inicial
r1 = chat.send_message("Genera un golden retriever corriendo en la playa")
# Segunda ronda: editar basándose en la primera imagen (el objeto chat lleva el historial automáticamente)
r2 = chat.send_message("Cambia la escena al atardecer y añade una gaviota volando")
# Tercera ronda: añadir más modificaciones
r3 = chat.send_message("Cambia el color del perro a marrón oscuro")
El objeto chat mantiene internamente la lista completa de contents (incluyendo el thoughtSignature de cada ronda), por lo que el desarrollador no necesita preocuparse por los detalles de los campos. Cada send_message empaquetará y enviará el historial automáticamente.
Ver ejemplo completo de llamada a la interfaz compatible con OpenAI
Si utilizas plataformas compatibles con OpenAI como APIYI (apiyi.com) para invocar a Nano Banana Pro, puedes reutilizar directamente el SDK de OpenAI:
import openai
import base64
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# Mantén una lista local de messages (el concepto equivalente a contents)
messages = [
{"role": "user", "content": "Genera un golden retriever corriendo en la playa"}
]
# Primera ronda
response1 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
img1_url = response1.choices[0].message.content # Extraer URL de imagen o base64
# Añadir la respuesta del modelo al historial
messages.append({"role": "assistant", "content": img1_url})
# Segunda ronda: añadir nueva instrucción
messages.append({"role": "user", "content": "Cambia la escena al atardecer"})
response2 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
# Continuar con la tercera ronda...
messages.append({"role": "assistant", "content": response2.choices[0].message.content})
messages.append({"role": "user", "content": "Añade una gaviota volando"})
response3 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
Punto clave: En el modo compatible con OpenAI, el array messages es equivalente al contents nativo; el campo role cambia de "model" a "assistant", y la plataforma realizará la conversión automáticamente.
Sugerencia: Para escenarios de edición multirrutas, se recomienda utilizar el objeto
chatdel SDK o mantener una lista local demessagespara evitar la concatenación manual decontentsen cada paso. Puedes registrarte en APIYI (apiyi.com) para obtener una cuota gratuita, probar el flujo con el SDK y luego considerar la optimización mediante REST.
Construcción manual de REST para generación de imágenes en múltiples turnos con Nano Banana Pro
Implementación REST pura sin depender de SDK
En ciertos escenarios (como proxies de servidor, nodos de ComfyUI o plataformas de código bajo), no es posible utilizar el SDK oficial, por lo que es necesario construir las solicitudes REST directamente. A continuación, se muestra la llamada curl completa:
# Primera ronda: generación de imagen mediante instrucción de texto
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "Genera un golden retriever corriendo en la playa"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
# La respuesta contendrá: parts[0].inline_data.data (imagen en base64)
# Y también parts[0].thought_signature
En la segunda ronda de la solicitud, es obligatorio incluir toda la respuesta del modelo de la primera ronda (incluyendo la imagen y la firma) de vuelta en contents:
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "Genera un golden retriever corriendo en la playa"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<base64 devuelto en la primera ronda>"}},
{"thought_signature": "<signature devuelta en la primera ronda>"}
]},
{"role": "user", "parts": [{"text": "Cambia la escena al atardecer"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
Comparativa de tres modos de invocación
| Método de llamada | Gestión del historial | Escenario ideal | Curva de aprendizaje |
|---|---|---|---|
SDK oficial de Python (objeto chat) |
Automática | Servicios backend, experimentos en Notebook | ⭐ Muy baja |
Interfaz compatible con OpenAI (array messages) |
Semiautomática | Migración de proyectos OpenAI existentes | ⭐⭐ Baja |
REST nativo (array contents) |
Manual total | ComfyUI, código bajo, multiplataforma | ⭐⭐⭐ Media |
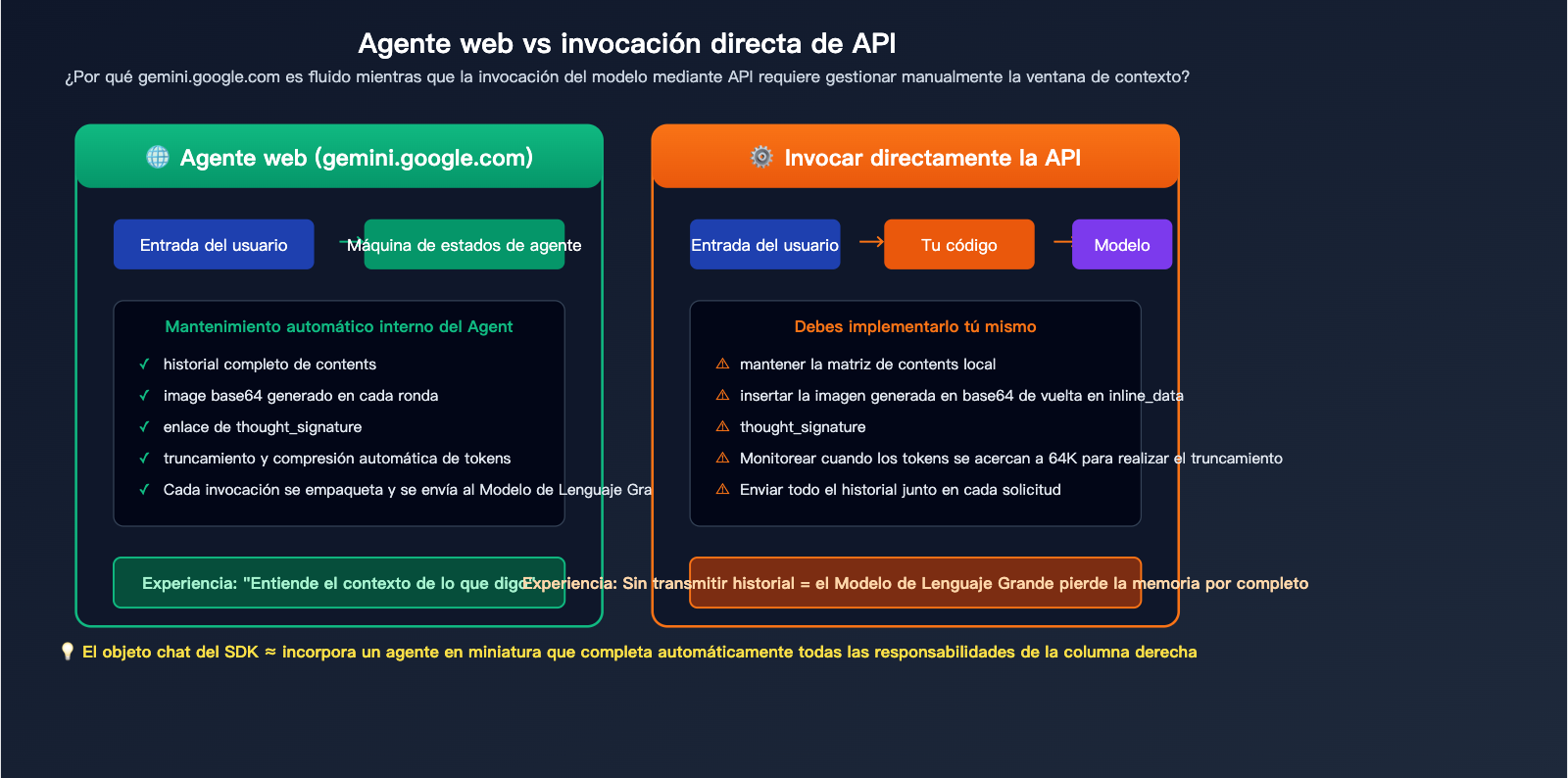
Nota sobre los datos: La imagen superior muestra la diferencia fundamental entre la gestión automática de un Agente frente a la gestión manual mediante API. Puedes comparar el rendimiento real de ambos métodos de invocación a través de la plataforma APIYI (apiyi.com).
Mecanismo thoughtSignature en la generación de imágenes por turnos de Nano Banana Pro
¿Qué es thoughtSignature?
thoughtSignature es la "firma de pensamiento cifrada" introducida en la serie Gemini 3. Se trata de una codificación compacta del estado de razonamiento interno del modelo; aunque no es legible para los humanos, el modelo puede utilizarla en la siguiente ronda para recuperar el contexto rápidamente. Sus funciones principales son:
- Preservar decisiones detalladas: Por ejemplo, si en la primera ronda el modelo "decide" usar tonos claros, mediante la firma heredará este estilo en la segunda ronda.
- Mejorar la consistencia: Mantiene la estabilidad de los personajes, escenarios y composición a lo largo de las ediciones en múltiples turnos.
- Ahorrar tokens: Evita tener que repetir constantemente "mantén el estilo original" en la indicación.
¿Cuándo es obligatorio incluir la firma?
| Escenario | ¿Es obligatorio incluir la firma? |
|---|---|
| Solicitud independiente de un solo turno (generación única) | ❌ No es necesario |
| Edición multironda (modificación basada en la imagen anterior) | ✅ Obligatorio |
| Recuperación de historial entre sesiones | ✅ Obligatorio (debe persistirse manualmente) |
| Conversación solo de texto (sin imágenes) | ✅ Obligatorio, para la continuidad del razonamiento |
En la práctica: Patrón de código para gestionar manualmente la firma
import requests
import base64
import json
API_BASE = "https://vip.apiyi.com/v1beta"
MODEL = "gemini-3-pro-image-preview"
HEADERS = {
"x-goog-api-key": "TU_CLAVE_API",
"Content-Type": "application/json"
}
class NanoBananaChat:
"""Cliente de chat minimalista que mantiene manualmente contents + signature"""
def __init__(self):
self.contents = []
def send(self, text: str, attach_image_b64: str = None) -> dict:
# Construir el mensaje de usuario de esta ronda
user_parts = [{"text": text}]
if attach_image_b64:
user_parts.append({
"inline_data": {"mime_type": "image/png", "data": attach_image_b64}
})
self.contents.append({"role": "user", "parts": user_parts})
# Realizar la solicitud
resp = requests.post(
f"{API_BASE}/models/{MODEL}:generateContent",
headers=HEADERS,
json={
"contents": self.contents,
"generationConfig": {"responseModalities": ["TEXT", "IMAGE"]}
}
).json()
# Añadir la respuesta del modelo (incluida la firma) tal cual a contents
model_parts = resp["candidates"][0]["content"]["parts"]
self.contents.append({"role": "model", "parts": model_parts})
return model_parts
# Ejemplo de uso
chat = NanoBananaChat()
parts1 = chat.send("Genera un golden retriever corriendo en la playa")
parts2 = chat.send("Cambia el escenario a la hora del atardecer") # Lleva automáticamente el historial y la firma
parts3 = chat.send("Añade una gaviota volando")
Sugerencia de optimización: Al conectarte a través de APIYI (apiyi.com), la plataforma transmitirá el campo
thought_signaturetal cual; los desarrolladores solo deben asegurarse de "añadir todo el array de partes del modelo de vuelta a contents", sin necesidad de preocuparse por el contenido específico de la firma.
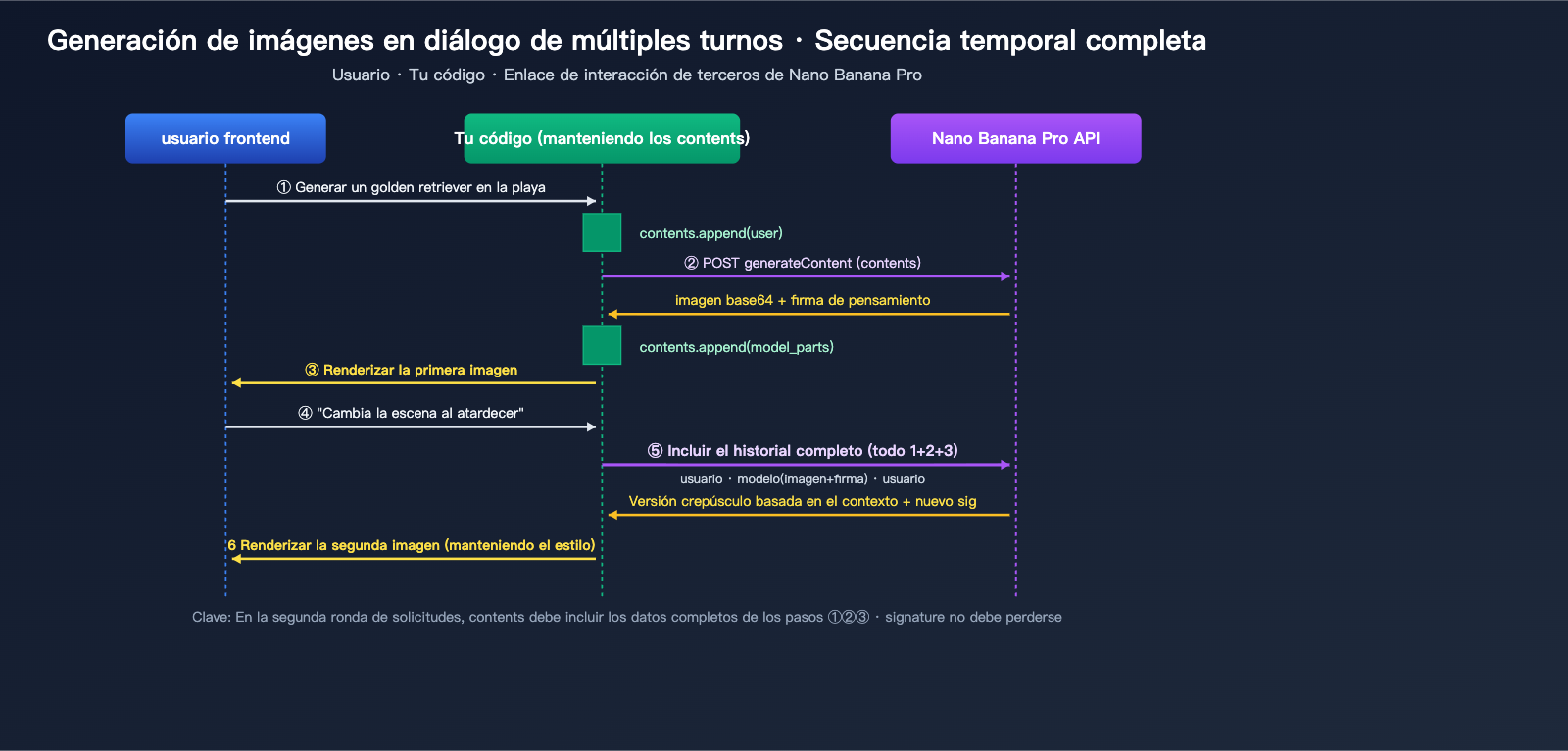
Casos de uso prácticos: Generación de imágenes en conversaciones multironda con Nano Banana Pro
Escenario 1: Diseño de marca progresivo
Una necesidad común en los equipos de marketing: a partir de una imagen conceptual del producto, ajustar gradualmente el texto, la combinación de colores y el diseño. La ventaja de la API de generación de imágenes en conversaciones multironda es que solo necesitas describir los "cambios incrementales" en cada paso, sin tener que describir toda la imagen desde cero:
chat = client.chats.create(model="gemini-3-pro-image-preview")
chat.send_message("Diseña un póster de marca de café con un fondo degradado azul oscuro, coloca la imagen del producto a la izquierda")
chat.send_message("Cambia el texto del título a «Awaken Your Morning»")
chat.send_message("Añade un marcador de posición para un código QR en la esquina inferior derecha")
chat.send_message("Haz que el estilo general sea un poco más moderno y elimina los bordes decorativos")
Escenario 2: Edición multironda basada en imágenes de referencia
Nano Banana Pro admite hasta 14 imágenes de referencia por solicitud. Al combinar esto con conversaciones multironda, puedes construir flujos de trabajo de fusión de imágenes muy potentes:
# Subir una imagen de una persona + una imagen de referencia de ropa
chat.send_message([
"Haz que la persona de la primera imagen vista la ropa de la segunda imagen",
{"inline_data": {"mime_type": "image/png", "data": person_b64}},
{"inline_data": {"mime_type": "image/png", "data": outfit_b64}}
])
# Ajustes posteriores
chat.send_message("Cambia el cuello a un escote en V")
chat.send_message("Cambia el fondo a un gris sencillo")
Escenario 3: Recuperación del historial entre sesiones
Si el usuario cierra la página en el frontend y vuelve a abrirla, y desea continuar la conversación anterior, es necesario persistir la matriz contents en la base de datos:
import json
# Guardar
with open(f"sessions/{user_id}.json", "w") as f:
json.dump(chat.get_history(), f)
# Recuperar
with open(f"sessions/{user_id}.json") as f:
history = json.load(f)
restored_chat = client.chats.create(
model="gemini-3-pro-image-preview",
history=history
)
restored_chat.send_message("Continuando con lo anterior, haz el fondo un poco más brillante")
Límites de la ventana de contexto
| Recurso | Límite |
|---|---|
| Contexto de entrada | 64K tokens |
| Contexto de salida | 32K tokens |
| Máximo de imágenes de referencia por solicitud | 14 imágenes |
| Rondas de historial recomendadas | No más de 8-10 rondas |
| Resolución máxima por imagen | 2K (predeterminado 1K) |
Sugerencia de escenario: Cuando la conversación supere las 8-10 rondas, se recomienda "truncar" activamente el historial anterior o reemplazarlo con un resumen del Modelo de Lenguaje Grande, de lo contrario, los tokens se acercarán rápidamente al límite de 64K. En entornos de producción, asegúrate de incluir un contador de tokens para tomar decisiones de truncamiento en el cliente con antelación.
Preguntas frecuentes
Q1: Si llamo a la API directamente sin contexto, ¿cómo logro la conversación continua como en la versión web?
La API no tiene estado, por lo que tu código debe mantener una matriz contents local (o el objeto chat dentro del SDK). Cada solicitud debe enviar el historial completo (incluyendo el texto del usuario, las imágenes generadas por el modelo y la thought_signature) para que el modelo "recuerde" la conversación previa. La forma más sencilla es usar client.chats.create() del SDK oficial de Python, donde el SDK gestiona esto automáticamente.
Q2: ¿Qué campos debo enviar en la siguiente ronda para las imágenes generadas en la ronda anterior?
Debes incluir la imagen en forma de inline_data (codificación base64 + mime_type) dentro de la matriz parts del "rol de modelo de la ronda anterior". Al mismo tiempo, asegúrate de incluir también la thought_signature devuelta por el modelo. Si utilizas interfaces compatibles con OpenAI como APIYI (apiyi.com), la plataforma gestionará automáticamente estas asignaciones de campos, y el desarrollador solo necesita mantener la lista estándar de messages.
Q3: ¿Es obligatorio enviar la thoughtSignature? ¿Qué pasa si no la envío?
Se recomienda encarecidamente enviarla. Si no lo haces, el modelo podría "olvidar" decisiones clave de la ronda anterior (como el estilo, la combinación de colores o la composición) durante la edición multironda, haciendo que cada vez parezca una generación nueva. La documentación oficial indica claramente que la firma debe conservarse en escenarios multironda. El SDK lo maneja automáticamente; en modo REST, debes añadir manualmente los parts del modelo de vuelta a contents.
Q4: ¿Qué hago si el historial es demasiado largo? ¿Dará error si los tokens superan los 64K?
Sí, las solicitudes que superen los 64K tokens de entrada serán rechazadas. Estrategias de optimización comunes:
- Truncamiento: Mantener solo las últimas 4-6 rondas del historial.
- Submuestreo de imágenes: Enviar las imágenes del historial a una resolución de 1K en lugar de 2K.
- Resumen alternativo: Usar un Modelo de Lenguaje Grande para comprimir las rondas anteriores en una descripción de texto.
- Sesiones segmentadas: Iniciar una nueva sesión cuando cambie el tema de la conversación.
Q5: ¿Cómo puedo probar rápidamente el efecto de generación multironda de Nano Banana Pro?
Se recomienda utilizar plataformas de agregación que admitan modelos Gemini, como APIYI (apiyi.com), para una verificación rápida:
- Registra una cuenta para obtener una clave API y saldo gratuito.
- Selecciona el modelo
gemini-3-pro-image-preview. - Utiliza el código de ejemplo del SDK de Python de este artículo para realizar 3-5 rondas de edición consecutivas.
- Compara la coherencia de la salida en cada ronda para determinar si cumple con tus necesidades comerciales.
Resumen
Puntos clave de la API de generación de imágenes por diálogo multironda de Nano Banana Pro:
- Naturaleza sin estado: La API no recuerda ningún historial; el emisor de la llamada debe mantener el arreglo
contents. - Alternancia de roles: Los roles
userymodeldeben alternarse estrictamente, y cada ronda departspuede combinar texto, imagen y firma. - Reenvío de imágenes: La imagen generada en la ronda anterior debe incluirse mediante
inline_data, de lo contrario el Modelo de Lenguaje Grande no podrá "verla". - Mecanismo de firma:
thought_signaturees la clave para la consistencia en múltiples rondas; en modo REST, debe incluirse manualmente. - Simplificación mediante SDK: El objeto
chatdel SDK oficial de Python gestiona automáticamente todos los detalles mencionados anteriormente.
Para los desarrolladores que buscan implementar rápidamente una experiencia web, la mejor ruta es utilizar el objeto chat del SDK oficial o el modo de mensajes de la interfaz compatible con OpenAI, evitando así la complejidad de construir manualmente las solicitudes REST.
Recomendamos acceder a las capacidades de generación de imágenes por diálogo multironda de Nano Banana Pro a través de APIYI (apiyi.com). La plataforma admite tanto la invocación con campos nativos de Gemini como el modo compatible con OpenAI, ofrece cuotas de prueba gratuitas y facilita la verificación rápida de los efectos de edición multironda, permitiendo una migración fluida de proyectos existentes.
📚 Referencias
-
Documentación oficial de generación de imágenes de la API de Gemini: Guía autorizada sobre la generación de imágenes en diálogos multironda.
- Enlace:
ai.google.dev/gemini-api/docs/image-generation - Descripción: Incluye especificaciones del campo
contents, ejemplos completos con el SDK de Python y REST.
- Enlace:
-
Ficha técnica del modelo Gemini 3 Pro Image Preview: Descripción de las capacidades y limitaciones del modelo.
- Enlace:
ai.google.dev/gemini-api/docs/models/gemini-3-pro-image-preview - Descripción: Parámetros clave como la ventana de contexto, resolución y cantidad de imágenes de referencia.
- Enlace:
-
Foro de desarrolladores de Google AI – Multi-turn Nano Banana: Ejemplos prácticos de la comunidad.
- Enlace:
discuss.ai.google.dev/t/multi-turn-nano-banana-example - Descripción: Mejores prácticas para diálogos multironda discutidas por desarrolladores reales.
- Enlace:
-
Documentación de Vertex AI Gemini 3 Pro Image: Referencia para despliegue a nivel empresarial.
- Enlace:
docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-pro-image - Descripción: Incluye usos avanzados de
thought_signaturey referencias afile_data.
- Enlace:
-
Documentación de acceso a Nano Banana Pro de APIYI: Guía de inicio rápido para desarrolladores.
- Enlace:
help.apiyi.com - Descripción: Incluye ejemplos de modo dual para la interfaz compatible con OpenAI y la interfaz nativa de Gemini.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a compartir en la sección de comentarios los problemas prácticos que hayas encontrado en la generación de imágenes por diálogo multironda. Para más trucos de configuración de Nano Banana Pro, visita el centro de documentación de APIYI en docs.apiyi.com.