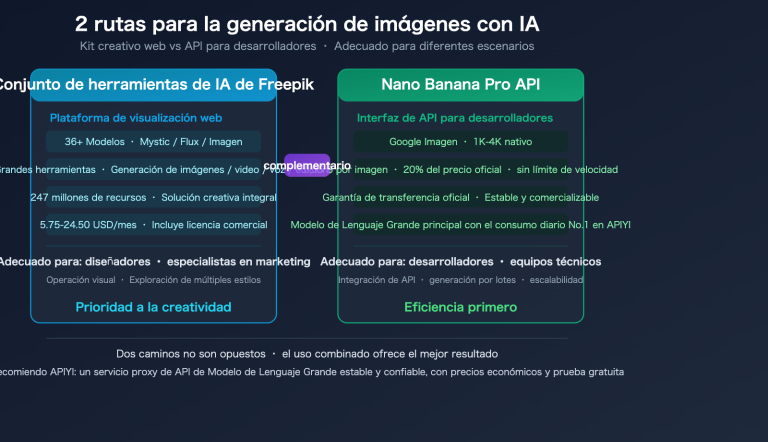
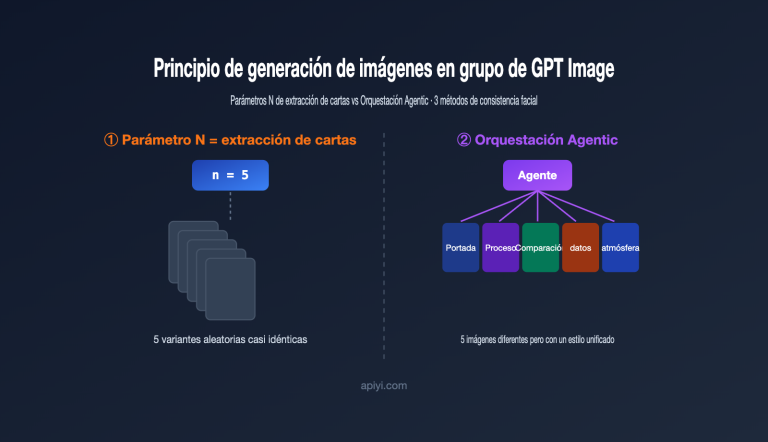
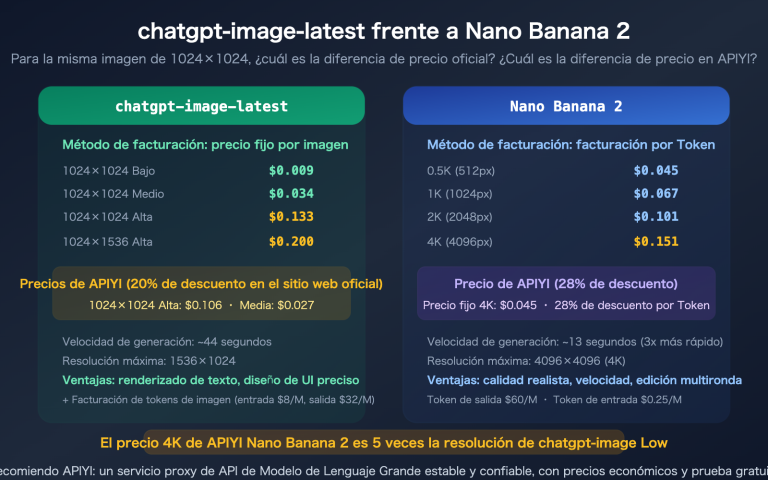
Nota del autor: He analizado sistemáticamente el valor práctico de gpt-image-2 en 6 áreas de negocio clave: comercio electrónico, UI/UX, publicidad, guiones gráficos (storyboards), agentes desarrolladores y localización de contenido, para ayudar a tu equipo a planificar su hoja de ruta tras la apertura de la API.
Si utilizas habitualmente la generación de imágenes por IA, probablemente habrás notado que hay un tipo de demanda que lleva mucho tiempo "estancada": imágenes de productos con etiquetas mal escritas, material publicitario que requiere correcciones manuales de texto o la imposibilidad de crear creatividades localizadas en todos los idiomas de una sola vez. Estos problemas no se deben a las capacidades del modelo, sino al techo de cristal de los modelos de imagen anteriores en cuanto a renderizado de texto, resolución y conocimiento del mundo.
Esto parece un problema antiguo, pero gpt-image-2 está rompiendo sistemáticamente estos techos. En este artículo, desglosaremos capa por capa los escenarios de aplicación de gpt-image-2: flujos de trabajo reales en 6 áreas de negocio, métodos de integración de API y lo que esto significa para tu equipo.
Valor central: Desde los escenarios hasta el código de implementación, tras leer este artículo entenderás qué negocios se beneficiarán primero de gpt-image-2 y sabrás cómo integrarlo en tus pipelines existentes desde el primer día en que se abra la API.

Puntos clave de los casos de uso de gpt-image-2
| Caso de uso | Valor principal | Puntos de dolor de modelos anteriores |
|---|---|---|
| Comercio electrónico y fotografía de producto | Imágenes de producto en 4K + texto preciso en el empaque | Etiquetas mal escritas, resolución insuficiente |
| Prototipos UI/UX | Mockups de alta fidelidad en segundos | Texto de botones/iconos desordenado |
| Publicidad y visuales principales | Fuentes de marca listas para publicar + 4K | Necesidad de corrección en PS |
| Storyboards y preproducción | Iteración en 3 segundos + conocimiento del mundo | Alto costo de reintento de planos |
| Pipeline de agentes para desarrolladores | Integración directa sin modificar el SDK | Generación inestable, difícil de automatizar |
| Localización de contenido | Sincronización CJK/RTL/Latín | Requiere maquetación manual para idiomas no ingleses |
Puntos en común de los casos de uso
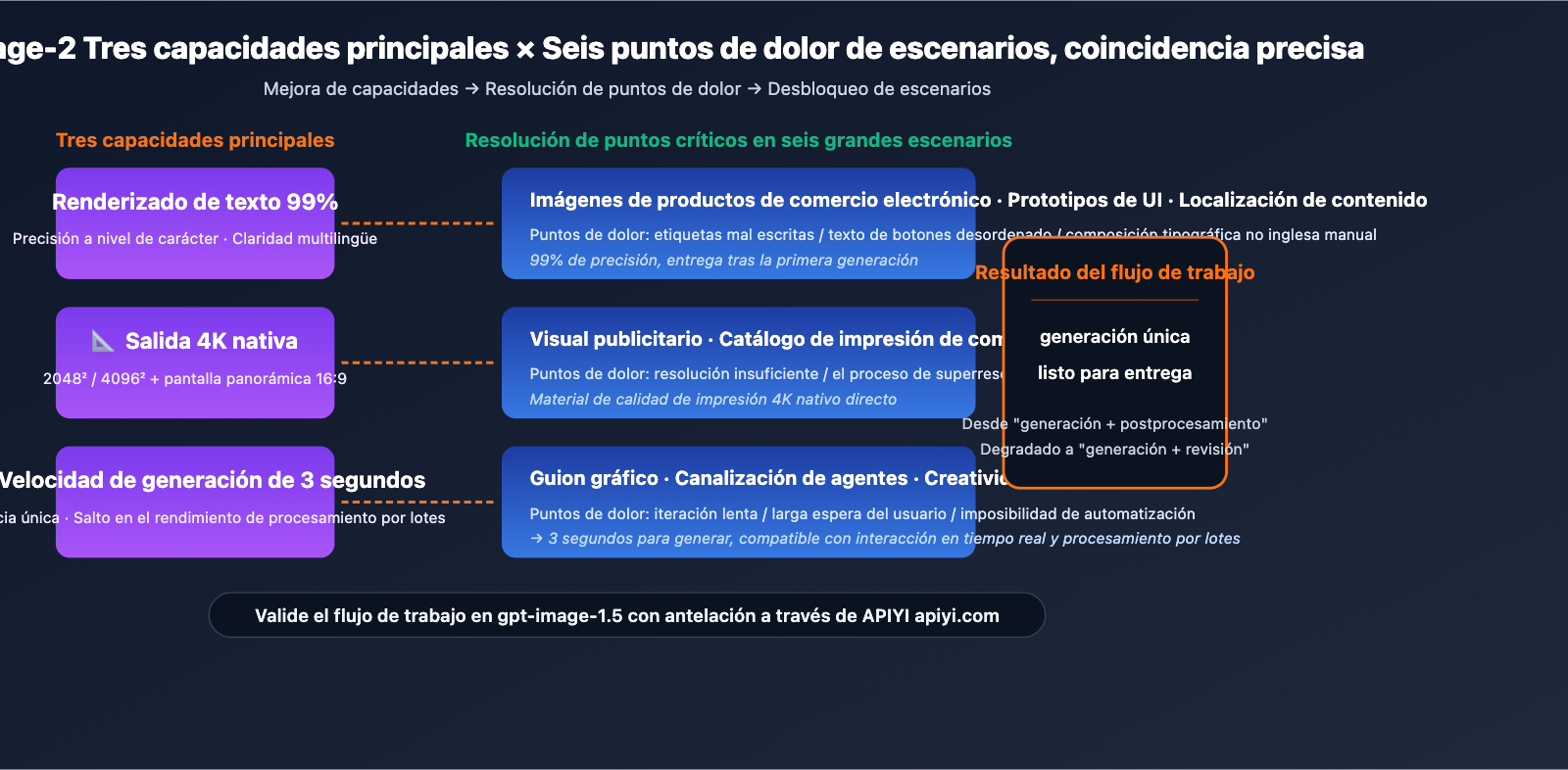
Lo que comparten estos 6 escenarios: El flujo de trabajo solía estar bloqueado por el "techo de cristal de los modelos de imagen anteriores en cuanto a renderizado de texto, resolución y conocimiento del mundo". Los tres pilares de gpt-image-2 (99% de precisión en texto, salida nativa en 4K y velocidad de generación de 3 segundos) abordan precisamente estos cuellos de botella.
¿Qué significa esto?: Estos escenarios, que antes requerían un flujo de trabajo de dos etapas (generación por IA + postprocesamiento manual), ahora con gpt-image-2 pueden simplificarse a entrega tras una sola generación, reduciendo la intervención humana de "reparación" a simplemente "revisión". La eficiencia en la producción de imágenes de los equipos experimentará un salto cualitativo.
Caso de uso 1 de gpt-image-2: Comercio electrónico y fotografía de producto
Descripción del escenario
Lo que más preocupa a los equipos de comercio electrónico es la consistencia de marca en las imágenes de productos por lotes: un mismo producto requiere decenas de contenidos A+ (imágenes de estantería, imágenes de estilo de vida, detalles, temas festivos). Antes, esto implicaba contratar fotógrafos profesionales o realizar múltiples retoques manuales de etiquetas y textos de empaque tras la generación con IA.
Cómo gpt-image-2 redefine el proceso
- Etiquetas legibles y empaques precisos: Con una precisión de texto del 99%, el nombre del producto, las especificaciones y las etiquetas de ingredientes se generan correctamente desde el primer intento.
- Escenarios de estantería realistas: El conocimiento del mundo permite que los fondos (cafeterías, cocinas, escritorios de oficina) se ajusten a la estética real de la marca.
- Resolución 4K lista para impresión: La salida de una sola imagen puede utilizarse directamente en catálogos impresos y contenido A+ de plataformas de comercio electrónico, eliminando pasos de superresolución.
Comparativa de flujos de trabajo
| Paso | IA tradicional | Flujo de trabajo con gpt-image-2 |
|---|---|---|
| Producción de 1 imagen principal | 3-5 reintentos + retoque en PS | 1 generación |
| Generación de 20 variantes | Aprox. 2-3 horas | Aprox. 10 minutos |
| Resolución para impresión | Requiere software de superresolución | Salida nativa en 4K |
| Precisión de etiquetas de marca | Requiere revisión manual | 99% de precisión automática |
Sugerencia de escenario: Los equipos de comercio electrónico pueden acceder a gpt-image-1.5 a través de APIYI (apiyi.com) para familiarizarse con la estructura de llamadas por lotes. El día del lanzamiento de gpt-image-2, solo tendrán que reemplazar el campo
modelpara disfrutar de la doble mejora: 4K y 99% de precisión en texto.
gpt-image-2 Caso de uso 2: Prototipos de UI / UX
Descripción del escenario
Los gerentes de producto y diseñadores necesitan mostrar rápidamente mockups de interfaces de aplicación de alta fidelidad a los interesados (stakeholders) en las etapas iniciales. Abrir Figma y empezar desde cero toma horas, y externalizar el diseño implica costes de comunicación elevados. Los modelos de imagen anteriores generaban capturas de pantalla de UI con textos de botones confusos e iconos desalineados, siendo prácticamente inservibles.
Cómo gpt-image-2 redefine el proceso
- Generación de mockups de alta fidelidad en segundos: 3 segundos de generación con texto preciso para que los borradores conceptuales estén "listos para usar".
- Precisión en texto, iconos y estructura de diseño: El texto de los botones, las etiquetas de navegación y las tablas de datos son claros y legibles.
- Aprobación de los interesados antes de abrir Figma: Reduce drásticamente el ciclo de toma de decisiones del producto.
Ejemplo de indicación (prompt) típico
A modern mobile banking app dashboard screen,
- Top navigation: "Accounts · Transfer · Pay · Invest"
- Account card showing balance "$12,847.50" with "Main Checking"
- Transaction list with 3 items: "Starbucks -$5.40", "Salary +$4,200", "Netflix -$15.99"
- Bottom tab bar: Home, Cards, Rewards, Settings
iOS-style, light mode, Apple system font
Al introducir esta indicación en gpt-image-2, el texto mencionado en la captura de pantalla generada se renderizará palabra por palabra con precisión, algo que ningún modelo de imagen anterior podía lograr.
gpt-image-2 Caso de uso 3: Publicidad y visuales principales
Descripción del escenario
Los materiales visuales principales del equipo de marketing (pósteres, banners, portadas de redes sociales) deben cumplir con una calidad de nivel publicitario: fuentes de marca correctas, integración natural del producto e iluminación de escena adecuada. El flujo de trabajo tradicional requiere la colaboración de fotógrafos, retocadores y diseñadores durante varios días.
Cómo gpt-image-2 redefine el proceso
- Fuentes de marca correctas: Una tasa de precisión del 99% significa que el eslogan, el nombre del producto y el texto del botón CTA quedan perfectos a la primera.
- Integración natural del producto: El conocimiento del mundo permite que el producto aparezca en escenarios de consumo reales, evitando esa sensación de "montaje flotante".
- Iluminación de escena adecuada: Los avances en realismo aseguran que los retratos, las manos y los reflejos coincidan con la iluminación fotográfica real.
- Salida 4K que elimina el paso de "escalado y reparación": Se puede omitir el paso de superresolución, que era esencial en la mayoría de las líneas de producción de marketing anteriores.
Tipos de publicidad más beneficiados
| Tipo de publicidad | Valor de gpt-image-2 |
|---|---|
| Feed de redes sociales | Imagen cuadrada 1:1 + texto CTA preciso |
| Miniaturas de YouTube | Nativo 16:9 + legible en monitores 4K |
| Publicidad exterior/LED | Salida directa de 4096×4096 para pantallas grandes |
| Pósteres impresos | Soporte nativo 4K para impresión A3/A2 |
| Encabezados de correo | Iteración rápida de múltiples versiones para pruebas AB |
Sugerencia de integración: Para las líneas de producción creativa publicitaria, se recomienda utilizar la interfaz unificada de APIYI (apiyi.com). El día del lanzamiento de gpt-image-2, no será necesario modificar el código de negocio, simplemente bastará con cambiar el nombre del modelo.
gpt-image-2 Aplicación 4: Storyboard y preproducción
Descripción del escenario
Los directores de cine, directores creativos de publicidad y creadores de animación necesitan iterar guiones gráficos rápidamente durante la fase de preproducción. El proceso tradicional implica que un ilustrador dibuje a mano según el guion, lo que toma horas por iteración; incluso con ayuda de IA, los modelos anteriores no eran lo suficientemente estables en cuanto a "consistencia facial" y "precisión de la escena".
Cómo redefine gpt-image-2 el proceso
- Iteración de guiones gráficos a alta velocidad: La velocidad de generación de 3 segundos permite a los directores ajustar el ritmo de las tomas en tiempo real y discutirlo cara a cara con guionistas o clientes.
- Precisión en ritmo, escenas o posición de personajes: Su conocimiento del mundo permite que escenas complejas como "estacionamiento subterráneo + noche lluviosa + protagonista bajo una farola" salgan bien a la primera.
- Menor costo de reintento: Se reduce de un promedio de 5-6 intentos para obtener una imagen utilizable a solo 1-2.
Cambios en el flujo de trabajo
Flujo de trabajo tradicional de storyboard:
Guion → Ilustrador dibuja a mano → Revisión del director → Modificación → Redibujo (3-5 rondas)
Tiempo: 1-2 semanas / episodio
Flujo de trabajo asistido por gpt-image-2:
Guion → Generación con gpt-image-2 (3 segundos) → Ajuste de indicación en tiempo real → Finalización
Tiempo: 1-2 días / episodio
Beneficio de eficiencia: El ciclo de preproducción puede comprimirse más del 80%, permitiendo dedicar el tiempo ahorrado a un diseño de tomas más detallado. Se recomienda procesar el guion gráfico de todo el episodio mediante la interfaz por lotes de APIYI (apiyi.com).
gpt-image-2 Aplicación 5: Herramientas para desarrolladores y tuberías de Agentes

Descripción del escenario
Cada vez más productos de IA necesitan generar contenido visual dinámico: Agentes educativos que generan capturas de pantalla de tutoriales, Agentes de juegos que generan conceptos de escenas, o Agentes de documentos que generan ilustraciones. Integrar modelos de imagen anteriormente requería modificar SDKs, gestionar cuentas de múltiples proveedores y lidiar con diferentes estructuras de API.
Cómo redefine gpt-image-2 el proceso
- Sin necesidad de modificar el SDK, integración directa: La estructura de parámetros de la API es totalmente compatible con gpt-image-1.5.
- Ideal para Agentes que necesitan renderizar interfaces de usuario, materiales de tutoriales o contenido visual bajo demanda en productos para usuarios.
- Compatibilidad nativa con OpenAI Agents SDK y AgentKit: La llamada a funciones (Function Calling) puede activar directamente la generación de imágenes.
Ejemplo minimalista de tubería de Agente
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def agent_generate_image(scene_description: str) -> str:
"""Herramienta del Agente: generar imagen de escena bajo demanda"""
response = client.images.generate(
model="gpt-image-1.5", # Cambiar a "gpt-image-2" tras el lanzamiento
prompt=scene_description,
size="1024x1024",
quality="high"
)
return response.data[0].url
image_url = agent_generate_image(
"Paso 3 del tutorial: el usuario hace clic en el botón 'Conectar clave API' en la configuración"
)
Ver código completo de integración del Agente (incluye Function Calling)
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
tools = [{
"type": "function",
"function": {
"name": "generate_image",
"description": "Generar una imagen para el paso actual del tutorial",
"parameters": {
"type": "object",
"properties": {
"prompt": {"type": "string", "description": "Descripción de la imagen"},
"size": {"type": "string", "enum": ["1024x1024", "1536x1024"]}
},
"required": ["prompt"]
}
}
}]
def generate_image(prompt: str, size: str = "1024x1024") -> str:
response = client.images.generate(
model="gpt-image-1.5",
prompt=prompt,
size=size,
quality="high"
)
return response.data[0].url
messages = [{"role": "user", "content": "Crear una imagen de tutorial para la configuración de la clave API"}]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools
)
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
image_url = generate_image(**args)
print(f"El agente produjo la imagen: {image_url}")
Consejo para desarrolladores: Utilice APIYI (apiyi.com) para integrarse unificadamente en el ecosistema de OpenAI; con una sola clave API puede invocar gpt-image-2, GPT-4o y todos los demás modelos, evitando tener que mantener cuentas de múltiples proveedores.
gpt-image-2 Caso de uso 6: Localización de contenido
Descripción del escenario
El principal desafío para las marcas que se expanden al extranjero y el comercio electrónico transfronterizo es que una misma idea creativa debe cubrir mercados multilingües: inglés, chino (simplificado y tradicional), japonés, coreano, árabe, español… En el pasado, el texto no inglés generado por IA solía aparecer distorsionado, lo que obligaba a los equipos de localización a realizar ajustes manuales uno por uno.
Cómo gpt-image-2 redefine el proceso
- Una misma idea creativa puede generar versiones en CJK, RTL y latín simultáneamente: basta con una indicación + un parámetro de idioma para obtener todas las versiones.
- Sin necesidad de maquetación manual: el renderizado de texto multilingüe se reduce de días a minutos.
- Ciclo de localización drásticamente acortado: pasamos de un flujo lineal de "aprobación en inglés → cola de traducción → recreación manual" a un proceso paralelo y por lotes.
Comparativa de eficiencia en localización
| Tipo de contenido | Localización tradicional | Localización con gpt-image-2 |
|---|---|---|
| Diseño de packaging | 5-7 días/idioma | 10 minutos/idioma |
| Anuncios en redes sociales | 2-3 días/idioma | 5 minutos/idioma |
| Capturas de tutoriales | 1-2 días/idioma | 3 minutos/idioma |
| Encabezados de correo | Medio día/idioma | 2 minutos/idioma |
Ejemplo de generación masiva multilingüe
# Definimos los idiomas y sus eslóganes
languages = {
"en": "Summer Sale — Up to 50% Off",
"zh": "夏季特惠 — 低至 5 折",
"ja": "サマーセール — 最大 50% オフ",
"ar": "تخفيضات الصيف — خصم حتى 50%"
}
for lang, slogan in languages.items():
# Creamos la indicación para cada idioma
prompt = f"E-commerce hero banner, product showcase with slogan '{slogan}', modern style"
url = generate_image(prompt, size="1536x1024")
print(f"[{lang}] {url}")
Sugerencia para equipos de localización: Utilicen la interfaz unificada de APIYI (apiyi.com) para procesar materiales multilingües de forma masiva. La plataforma ofrece cuotas de prueba gratuitas para verificar los efectos de renderizado en diferentes idiomas.
Comparativa de soluciones para casos de uso de gpt-image-2
| Escenario | Prioridad de lanzamiento | ROI esperado | Complejidad de integración |
|---|---|---|---|
| Imágenes de productos | ⭐⭐⭐⭐⭐ | Alto (ahorro en fotografía) | Baja |
| Prototipos UI/UX | ⭐⭐⭐⭐⭐ | Alto (acorta ciclos de decisión) | Baja |
| Visuales publicitarios | ⭐⭐⭐⭐ | Alto (ahorro en postproducción) | Media |
| Storyboards | ⭐⭐⭐ | Medio (eficiencia creativa) | Baja |
| Canalizaciones de agentes | ⭐⭐⭐⭐ | Medio (productización) | Media |
| Localización de contenido | ⭐⭐⭐⭐⭐ | Muy alto (de días a minutos) | Media |
Recomendaciones para la toma de decisiones
Planificar lanzamiento inmediato (listo para implementar desde el primer día): imágenes de productos, prototipos UI/UX y localización de contenido. Estos tres escenarios dependen en mayor medida de las tres actualizaciones principales de gpt-image-2 (texto/4K/multilingüe).
Migración a medio plazo (observar durante 2-4 semanas): visuales publicitarios y canalizaciones de agentes. Se recomienda esperar a que la API sea estable y los límites de velocidad estén claros antes de realizar un despliegue a gran escala.
Exploración de oportunidades: creación de storyboards. Ideal para equipos pequeños y creadores independientes, ya que la resistencia al cambio en el flujo de trabajo tradicional es menor.
Nota sobre la toma de decisiones: La prioridad específica depende de la estructura de tu equipo y el ritmo de tu negocio. Te sugerimos realizar pruebas piloto con gpt-image-1.5 en APIYI (apiyi.com) y evaluar el ROI con datos de negocio reales antes de decidir la escala de inversión tras el lanzamiento de gpt-image-2.
Preguntas frecuentes (FAQ)
Q1: ¿Para qué casos de uso es más adecuado gpt-image-2?
Los 6 escenarios principales con mayor prioridad son: imágenes de productos para comercio electrónico (4K + etiquetas precisas), prototipos de UI/UX (mockups de alta fidelidad), visuales publicitarios (calidad de nivel comercial), guiones gráficos (iteración rápida), tuberías de agentes para desarrolladores (sin necesidad de modificar el SDK) y localización de contenido (generación multilingüe en un solo paso). El denominador común es que las limitaciones de los modelos anteriores en cuanto a texto, resolución y conocimiento del mundo restringían estos escenarios, y gpt-image-2 resuelve estos tres problemas de forma sistemática.
Q2: ¿Cuándo debería empezar a prepararse un equipo de comercio electrónico para gpt-image-2?
Recomendamos configurar inmediatamente una tubería de generación por lotes en gpt-image-1.5 para familiarizarse con las plantillas de indicación, los parámetros de tamaño y las combinaciones de niveles de calidad. El día del lanzamiento de gpt-image-2, solo necesitará reemplazar el campo model para disfrutar de 4K y un 99% de precisión en el texto. Los equipos que se preparen con antelación podrán lanzar sus nuevas imágenes de producto 1 o 2 semanas antes que la competencia.
Q3: ¿Cuándo estará gpt-image-2 oficialmente disponible para entornos de producción?
Hasta el 17-04-2026, OpenAI no ha hecho un anuncio oficial, y los modelos con nombre en clave "tape" siguen en pruebas A/B en LM Arena. Basándonos en el ritmo histórico, se espera su lanzamiento entre finales de abril y mediados de mayo de 2026. Es posible que haya límites de tasa durante el lanzamiento inicial, por lo que recomendamos utilizar un servicio proxy de API como APIYI (apiyi.com) para evitar problemas de cuota durante el arranque en frío.
Q4: ¿Realmente puede reemplazar a Figma en escenarios de prototipado UI/UX?
No lo reemplaza, lo precede. gpt-image-2 es ideal para la fase de prueba de concepto previa a Figma: utilice mockups generados en segundos para que las partes interesadas tomen decisiones rápidas de "seguir/no seguir", evitando invertir horas en Figma creando borradores de alta fidelidad en una dirección equivocada. Una vez definida la dirección, Figma/Sketch siguen siendo las herramientas de entrega de diseño real.
Q5: ¿Cómo puedo integrar gpt-image-2 en mis agentes existentes mediante API?
Recomendamos realizar la integración a través de APIYI (apiyi.com) para lograr un cambio sin modificaciones el día del lanzamiento de gpt-image-2:
- Visite apiyi.com, registre una cuenta y obtenga su clave API.
- Configure la
base_urlenhttps://vip.apiyi.com/v1y utilice el SDK oficial de OpenAI. - Por ahora, utilice
model="gpt-image-1.5"para construir la invocación del modelo (Function Calling) del agente. - El día del lanzamiento de gpt-image-2, simplemente reemplace el modelo por
model="gpt-image-2".
APIYI lanza los nuevos modelos al mismo tiempo que OpenAI; sus claves API, saldo y facturación permanecen intactos, sin necesidad de registrar cuentas nuevas o cambiar el SDK.
Q6: ¿Qué debo tener en cuenta en escenarios de localización de contenido?
Tres detalles clave: (1) Proporcione el contenido textual en el idioma de destino directamente en la indicación, en lugar de pedirle al modelo que traduzca; (2) Para idiomas RTL (de derecha a izquierda) como el árabe o el hebreo, especifique claramente "diseño de derecha a izquierda" (right-to-left layout) en la indicación; (3) El texto CJK (chino, japonés, coreano) puede verse ligeramente borroso por debajo de una resolución de 1536×1024, por lo que recomendamos usar una salida 4K para escenas con texto crítico (compatible de forma nativa con gpt-image-2).
Q7: ¿Por qué escenario debería empezar un equipo pequeño con presupuesto limitado?
Recomendamos comenzar con prototipos de UI/UX y iteración de guiones gráficos. Estos dos escenarios requieren poca complejidad de integración y unas pocas decenas o cientos de invocaciones al mes pueden generar mejoras significativas en la eficiencia, permitiendo validar el ROI rápidamente. A medida que el negocio crezca, podrá expandirse a la generación masiva para comercio electrónico y la integración de tuberías de agentes.
Q8: ¿Qué escenarios no son adecuados para gpt-image-2?
Presentamos objetivamente las limitaciones en tres áreas: (1) Estilo artístico extremo: Midjourney sigue siendo más fuerte en direcciones estéticas específicas, mientras que gpt-image-2 se inclina más hacia el fotorrealismo; (2) Generación de video: este es un modelo de imagen; para video, utilice modelos especializados como Sora; (3) Contenido de texto muy largo: la precisión del texto disminuye en párrafos de más de 50 palabras por imagen; se recomienda generar por partes y luego unirlas.
Puntos clave de los escenarios de aplicación de gpt-image-2
- 6 escenarios principales: productos de comercio electrónico, prototipos de UI, visuales publicitarios, guiones gráficos, tuberías de agentes y localización de contenido.
- Denominador común: los puntos de dolor (texto/resolución/conocimiento del mundo) se corresponden exactamente con las tres mejoras de gpt-image-2.
- Mayor prioridad: comercio electrónico, prototipos de UI y localización, ya que dependen más de estas capacidades y ofrecen el ROI más evidente.
- Sin barreras de entrada: la estructura de la API es totalmente compatible con gpt-image-1.5; no es necesario modificar el SDK de las tuberías de agentes.
- Ruta de adopción: utilice APIYI (apiyi.com) para realizar pruebas con gpt-image-1.5 y cambie sin problemas el día del lanzamiento de la versión oficial.
Resumen
Perspectivas clave sobre los escenarios de aplicación de gpt-image-2:
- Impulsado por escenarios, no por tecnología: El valor real no reside simplemente en la "generación de imágenes por IA", sino en remodelar los flujos de trabajo que estaban estancados con modelos anteriores. Tareas que antes requerían múltiples personas y pasos, como imágenes de comercio electrónico, borradores de UI y materiales de localización, ahora pueden generarse y entregarse de una sola vez.
- Jerarquía de prioridades: Los escenarios de comercio electrónico, prototipos de UI y localización ofrecen el mayor valor inicial; la publicidad y las tuberías de agentes requieren una planificación a medio plazo; mientras que los guiones gráficos representan una gran oportunidad para equipos pequeños.
- La migración fluida es la ventaja principal: La compatibilidad de los parámetros de la API significa que puedes comenzar a construir tu tubería con gpt-image-1.5 hoy mismo, y el día que se lance gpt-image-2, solo tendrás que reemplazar el nombre del modelo para disfrutar de todas las mejoras.
Para la toma de decisiones del equipo, recomendamos integrar gpt-image-1.5 a través de APIYI (apiyi.com) de inmediato para probar 1 o 2 escenarios iniciales. Utiliza datos de negocio reales para establecer tu biblioteca de indicaciones y tuberías por lotes; así, cuando se lance gpt-image-2, estarás listo para aprovechar la ventaja competitiva desde el primer día.
Lecturas relacionadas
Si te interesa conocer más sobre los escenarios de aplicación de gpt-image-2, te recomendamos seguir leyendo:
- 📘 Análisis completo de las 8 mejoras principales: gpt-image-2 vs gpt-image-1.5 – Comprende las razones subyacentes del salto en capacidades.
- 📊 Guía completa de invocación de la API de gpt-image-1.5 – Domina las mejores prácticas para el modelo insignia actual.
- 🚀 Optimización de la invocación por lotes de la API de generación de imágenes en entornos de producción – Explora estrategias de tuberías por lotes, concurrencia y caché.
📚 Referencias
-
Análisis de casos de uso de MindStudio: Interpretación de las capacidades de GPT Image 2
- Enlace:
mindstudio.ai/blog/what-is-gpt-image-2 - Descripción: Recopilación sistemática de GPT Image 2 en escenarios como comercio electrónico, interfaz de usuario (UI) y marketing.
- Enlace:
-
Repositorio de ejemplos de EvoLinkAI en GitHub: awesome-gpt-image-2-prompts
- Enlace:
github.com/EvoLinkAI/awesome-gpt-image-2-prompts - Descripción: Colección de indicaciones probadas por la comunidad para retratos, pósteres, maquetas de UI y diseño de personajes.
- Enlace:
-
Documentación del SDK de agentes de OpenAI: Construcción de tuberías (pipelines) para agentes de generación de imágenes
- Enlace:
openai.github.io/openai-agents-python - Descripción: Especificaciones oficiales para la integración de la invocación de funciones (Function Calling) con la generación de imágenes.
- Enlace:
-
Análisis profundo de escenarios de ChatIMG: Capturas de pantalla web, plantillas de TikTok y maquetas de UI
- Enlace:
chatimg.ai/en/blog/gpt-image-2 - Descripción: Casos prácticos específicos para diseñadores y desarrolladores.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a participar en la sección de comentarios. Para más información, visita el centro de documentación de APIYI en docs.apiyi.com