Anmerkung des Autors: Eine tiefgehende Analyse der Feldstruktur, des contents-Array-Aufbaus, des thoughtSignature-Mechanismus und der praktischen Implementierung der API für die Bilderzeugung in Multi-Turn-Dialogen mit Nano Banana Pro (gemini-3-pro-image-preview).
Viele Entwickler stehen bei der ersten Integration von Nano Banana Pro vor demselben Rätsel: Im Web-Interface von gemini.google.com kann man kontinuierlich nachhaken („Ändere den Hintergrund in Abenddämmerung“, „Füge noch eine Katze hinzu“), und das Modell erinnert sich perfekt an das vorherige Bild. Doch beim Aufruf der offiziellen API wirkt das Modell, als hätte es einen Gedächtnisverlust. Der Grund dafür ist, dass die Gemini-API selbst zustandslos ist; der Multi-Turn-Kontext muss vom Aufrufer manuell konstruiert werden. Dieser Artikel erläutert die zugrunde liegenden Felder der Nano Banana Pro API für die Bilderzeugung, die Implementierung via Python SDK und REST sowie den entscheidenden thoughtSignature-Mechanismus. So bauen Sie in drei Schritten eine flüssige, kontextbezogene Bilderzeugung wie im Web-Interface.
Kernnutzen: Nach der Lektüre dieses Artikels beherrschen Sie den korrekten Aufbau des contents-Arrays, können Multi-Turn-Workflows für „Bearbeitung basierend auf dem vorherigen Bild“ in Ihren Anwendungen umsetzen und vermeiden die drei typischen Fallen: „Bild vergessen“, „Token-Verschwendung“ und „Signatur-Verlust“.
Kernpunkte der Multi-Turn-Bilderzeugung mit Nano Banana Pro
| Punkt | Beschreibung | Wert |
|---|---|---|
| API zustandslos | Die Schnittstelle gemini-3-pro-image-preview speichert keine Historie |
Multi-Turn-Kontext muss vom Aufrufer verwaltet werden |
| contents-Array | Abwechselnde Rollen (User/Model), bei jeder Anfrage die gesamte Historie mitsenden | Eine Anfrage reicht aus, damit das Modell den Dialog „sieht“ |
| Bild-Rückübertragung | Zuvor generierte Bilder müssen als inline_data in contents zurückgegeben werden |
Das Modell bearbeitet das Bild weiter, statt es neu zu erstellen |
| thoughtSignature | Verschlüsselte Denksignatur zur Beibehaltung des Schlussfolgerungskontexts | Wichtige Bearbeitungsbefehle werden nicht vergessen |
| SDK-Automatisierung | Das chat-Objekt des offiziellen Python SDK verwaltet die Historie automatisch |
Migration von REST spart bis zu 80 % Code |
Der wesentliche Unterschied zwischen Multi-Turn-Bilderzeugung und Web-Agent
gemini.google.com ist eine von Google entwickelte Agenten-Anwendung. Sie verwaltet im Frontend einen vollständigen „Dialogzustand“ (einschließlich Text jeder Runde, generierter Bilder und Denksignaturen). Jedes Mal, wenn Sie eine neue Nachricht eingeben, packt dieser Agent die gesamte Historie zusammen und sendet sie an das zugrunde liegende Modell. Genau deshalb ist die Web-Erfahrung so flüssig – der Agent übernimmt die gesamte „Gedächtnisarbeit“.
Wenn Sie jedoch direkt die generateContent-API aufrufen, erhalten Sie eine „nackte“ Schnittstelle für Modellaufrufe. Jeder HTTP-Request ist eine unabhängige Schlussfolgerung; das Modell hat keine Vorstellung von Ihren vorherigen Dialogen. Um die Multi-Turn-Erfahrung der Webseite zu reproduzieren, müssen Sie im Grunde selbst einen Agenten in Ihrem Code implementieren – indem Sie die User-Nachrichten der Historie und die Modellantworten (inklusive Bilder und Signaturen) gemäß den Spezifikationen in contents einfügen und dann die Anfrage stellen.
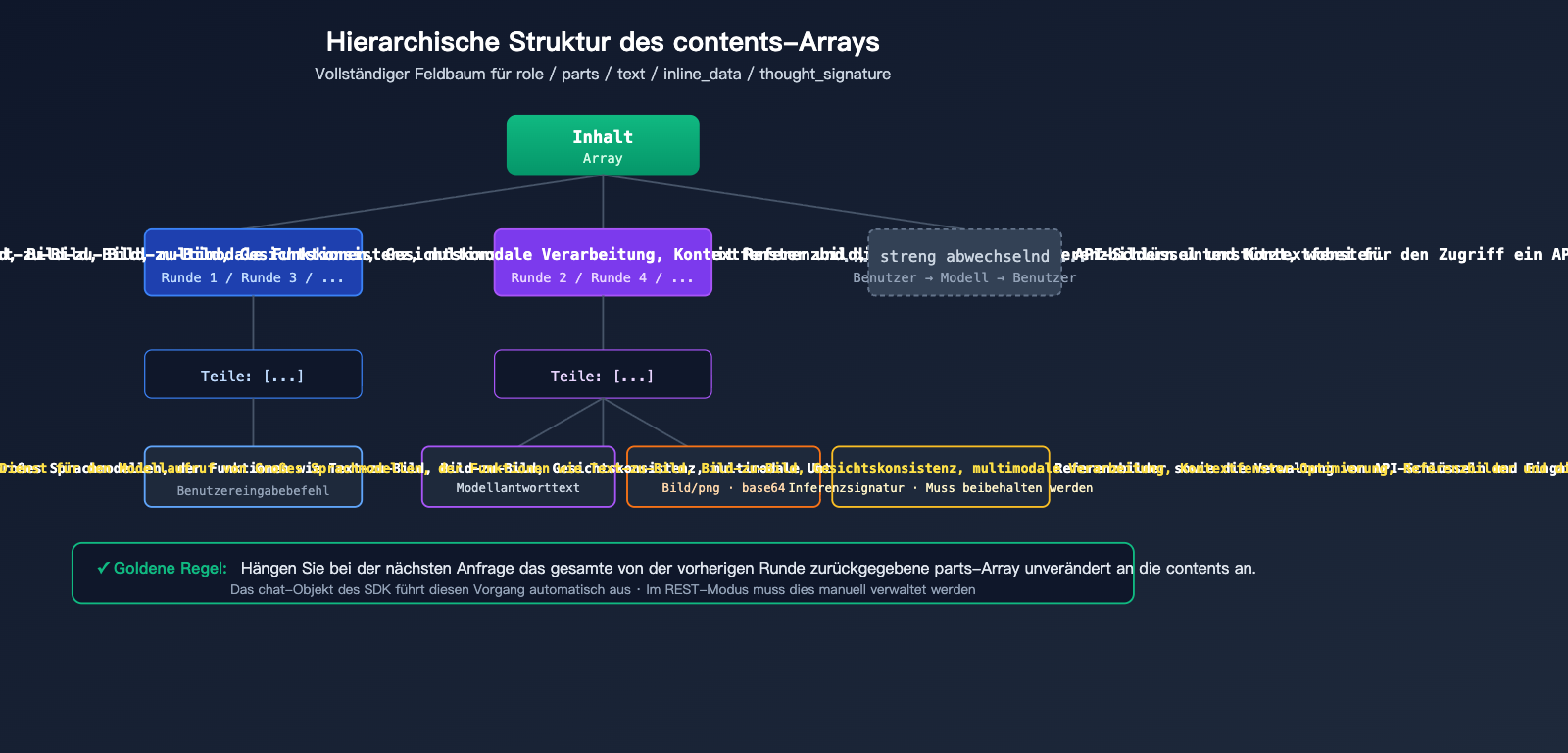
Nano Banana Pro: Detaillierte Feldstruktur für die Bilderzeugung in Multi-Turn-Dialogen
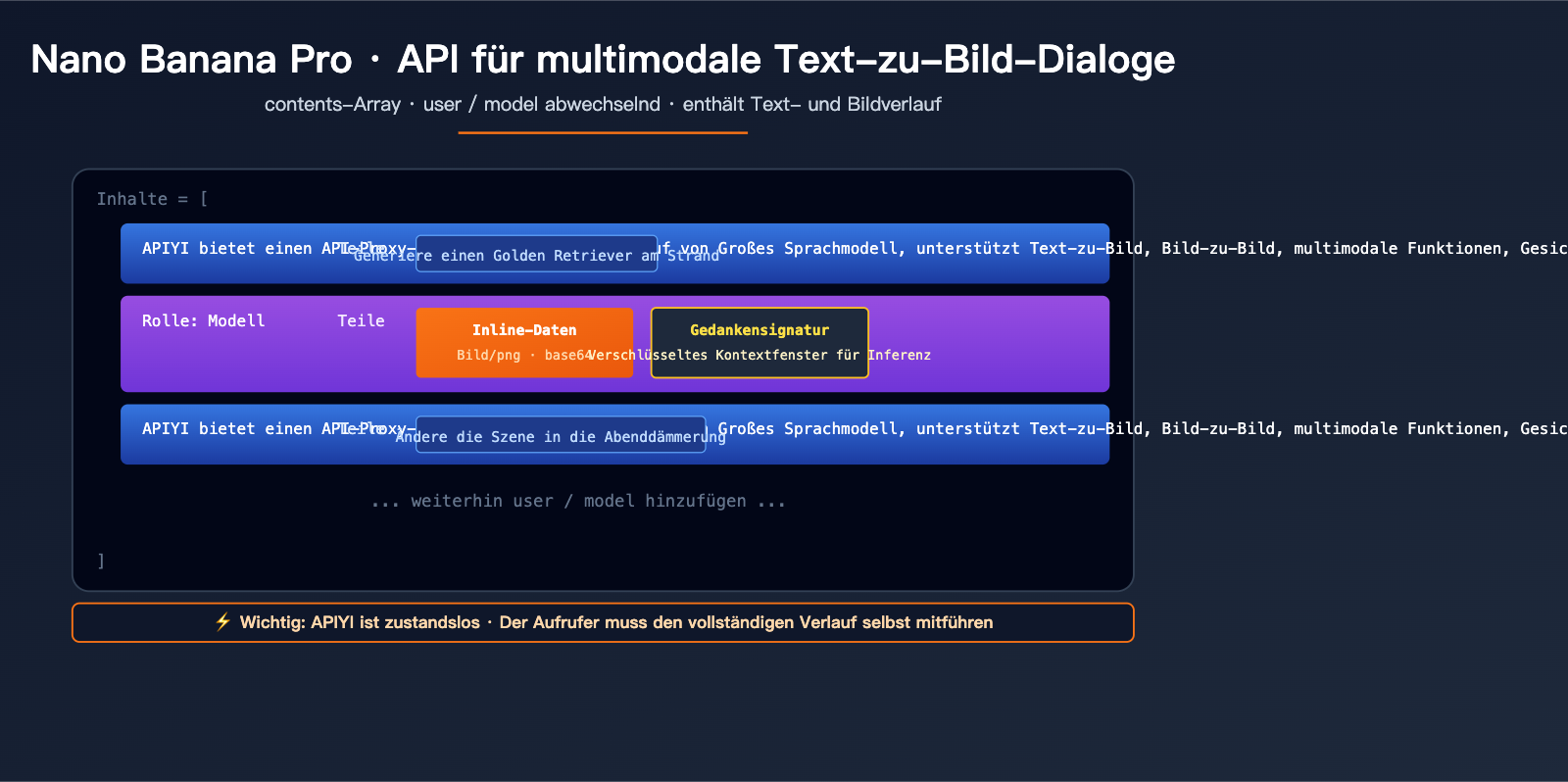
Der Kernstandard des contents-Arrays
contents ist das Standardfeld der Gemini API zur Darstellung des Dialogverlaufs. Es handelt sich um ein JSON-Array, wobei jedes Element einen Sprecherbeitrag repräsentiert:
| Feld | Typ | Beschreibung |
|---|---|---|
role |
string | "user" oder "model", muss strikt abwechselnd erfolgen |
parts |
array | Inhaltsfragmente des Beitrags, können Text/Bilder/Signaturen mischen |
parts[].text |
string | Textinhalt, z. B. Anweisungen oder Dialoge |
parts[].inline_data.mime_type |
string | Bildformat, normalerweise "image/png" |
parts[].inline_data.data |
string | Base64-kodierte Bilddaten |
parts[].thought_signature |
string | Kryptografische Signatur des Modells (erscheint nur bei der Rolle model) |
Ein vollständiger Request-Body für einen Dialog mit zwei Runden sieht so aus:
{
"contents": [
{"role": "user", "parts": [{"text": "Generiere einen Golden Retriever, der am Strand rennt"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<Base64-Daten des ersten Bildes>"}},
{"thought_signature": "<Kryptografische Signatur>"}
]},
{"role": "user", "parts": [{"text": "Ändere die Szene in die Abenddämmerung"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
Zwei Methoden für die Bildübermittlung
In der zweiten Runde muss das Modell das in der ersten Runde generierte Bild „sehen“ können. Nano Banana Pro unterstützt zwei Methoden zur Übermittlung:
# Methode 1: inline_data mit eingebettetem Base64 (geeignet für kleine Bilder, einfach und direkt)
{
"inline_data": {
"mime_type": "image/png",
"data": base64.b64encode(image_bytes).decode()
}
}
# Methode 2: file_data zur Referenzierung von Ressourcen, die über die Files API hochgeladen wurden (geeignet für große Bilder oder Wiederverwendung)
{
"file_data": {
"mime_type": "image/png",
"file_uri": "files/abc123xyz"
}
}
Wichtiger Hinweis:
inline_dataist die gängigste Methode für direkte Aufrufe und eignet sich für einmalige Szenarien. Dasfile_data-Referenzmodell ist ideal, wenn dasselbe große Bild über mehrere Runden hinweg wiederverwendet werden soll, da es die Größe des Request-Bodys und den Upload-Aufwand erheblich reduziert.
Nano Banana Pro: Schnelleinstieg in die Multi-Turn-Bilderzeugung
Minimalistisches Beispiel (automatische Verwaltung durch das Python SDK)
Wenn Sie das offizielle Python SDK verwenden, benötigen Sie für die einfachste Implementierung nur 10 Zeilen:
from google import genai
client = genai.Client(api_key="IHR_API_SCHLUESSEL")
chat = client.chats.create(model="gemini-3-pro-image-preview")
# Erste Runde: Initiales Bild generieren
r1 = chat.send_message("Generiere einen Golden Retriever, der am Strand rennt")
# Zweite Runde: Bearbeitung basierend auf dem ersten Bild (das chat-Objekt führt die Historie automatisch mit)
r2 = chat.send_message("Ändere die Szene in die Abenddämmerung und füge eine fliegende Möwe hinzu")
# Dritte Runde: Weitere Änderungen hinzufügen
r3 = chat.send_message("Ändere die Farbe des Hundes in Dunkelbraun")
Das chat-Objekt verwaltet intern die vollständige contents-Liste (einschließlich der thoughtSignature jeder Runde), sodass sich Entwickler nicht um die Details der Felder kümmern müssen. Jeder send_message-Aufruf verpackt automatisch den gesamten Verlauf.
Vollständiges Beispiel für den Aufruf über die OpenAI-kompatible Schnittstelle anzeigen
Wenn Sie Nano Banana Pro über eine OpenAI-kompatible Plattform wie APIYI (apiyi.com) aufrufen, können Sie das OpenAI SDK direkt wiederverwenden:
import openai
import base64
client = openai.OpenAI(
api_key="IHR_API_SCHLUESSEL",
base_url="https://vip.apiyi.com/v1"
)
# Führen Sie eine lokale messages-Liste (entspricht dem Konzept von contents)
messages = [
{"role": "user", "content": "Generiere einen Golden Retriever, der am Strand rennt"}
]
# Erste Runde
response1 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
img1_url = response1.choices[0].message.content # Bild-URL oder Base64 extrahieren
# Modellantwort zur Historie hinzufügen
messages.append({"role": "assistant", "content": img1_url})
# Zweite Runde: Neue Anweisung hinzufügen
messages.append({"role": "user", "content": "Ändere die Szene in die Abenddämmerung"})
response2 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
# Dritte Runde weiter ergänzen...
messages.append({"role": "assistant", "content": response2.choices[0].message.content})
messages.append({"role": "user", "content": "Füge eine fliegende Möwe hinzu"})
response3 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
Wichtiger Punkt: Im OpenAI-kompatiblen Modus entspricht das messages-Array dem nativen contents-Feld. Die Rolle wird von "model" zu "assistant" geändert, was die Plattform automatisch konvertiert.
Empfehlung: Für Szenarien mit mehreren Bearbeitungsrunden wird empfohlen, das
chat-Objekt des SDKs zu verwenden oder eine lokalemessages-Liste zu führen, um ein manuelles Zusammenfügen dercontentszu vermeiden. Sie können sich bei APIYI (apiyi.com) für ein kostenloses Guthaben registrieren, um das SDK zunächst zu testen, bevor Sie REST-Optimierungen vornehmen.
title: "Nano Banana Pro: Manuelle REST-Konstruktion für Multi-Turn-Dialoge mit Bilderzeugung"
Nano Banana Pro: Manuelle REST-Konstruktion für Multi-Turn-Dialoge mit Bilderzeugung
Reine REST-Implementierung ohne SDK-Abhängigkeit
In bestimmten Szenarien (z. B. API-Proxy-Dienst, ComfyUI-Knoten oder Low-Code-Plattformen) ist die Verwendung des offiziellen SDKs nicht möglich, weshalb REST-Anfragen direkt konstruiert werden müssen. Hier ist der vollständige curl-Aufruf:
# Erste Runde: Bilderzeugung durch reinen Textbefehl
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "Generiere ein Bild eines Golden Retrievers, der am Strand rennt"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
# Die Antwort enthält: parts[0].inline_data.data (base64-Bild)
# sowie parts[0].thought_signature
Bei der zweiten Anfrage muss die gesamte Modellantwort der ersten Runde (einschließlich Bild und Signatur) unverändert wieder in die contents eingefügt werden:
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "Generiere ein Bild eines Golden Retrievers, der am Strand rennt"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<base64 aus der ersten Runde>"}},
{"thought_signature": "<Signatur aus der ersten Runde>"}
]},
{"role": "user", "parts": [{"text": "Ändere die Szene in die Abenddämmerung"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
Vergleich der drei Aufrufmodi
| Aufrufmethode | Historienverwaltung | Geeignete Szenarien | Lernaufwand |
|---|---|---|---|
Offizielles Python SDK (chat-Objekt) |
Automatisch | Backend-Dienste, Notebook-Experimente | ⭐ Sehr gering |
| OpenAI-kompatible Schnittstelle (messages-Array) | Halbautomatisch | Migration bestehender OpenAI-Projekte | ⭐⭐ Gering |
| Natives REST (contents-Array) | Manuell | ComfyUI, Low-Code, sprachübergreifend | ⭐⭐⭐ Mittel |
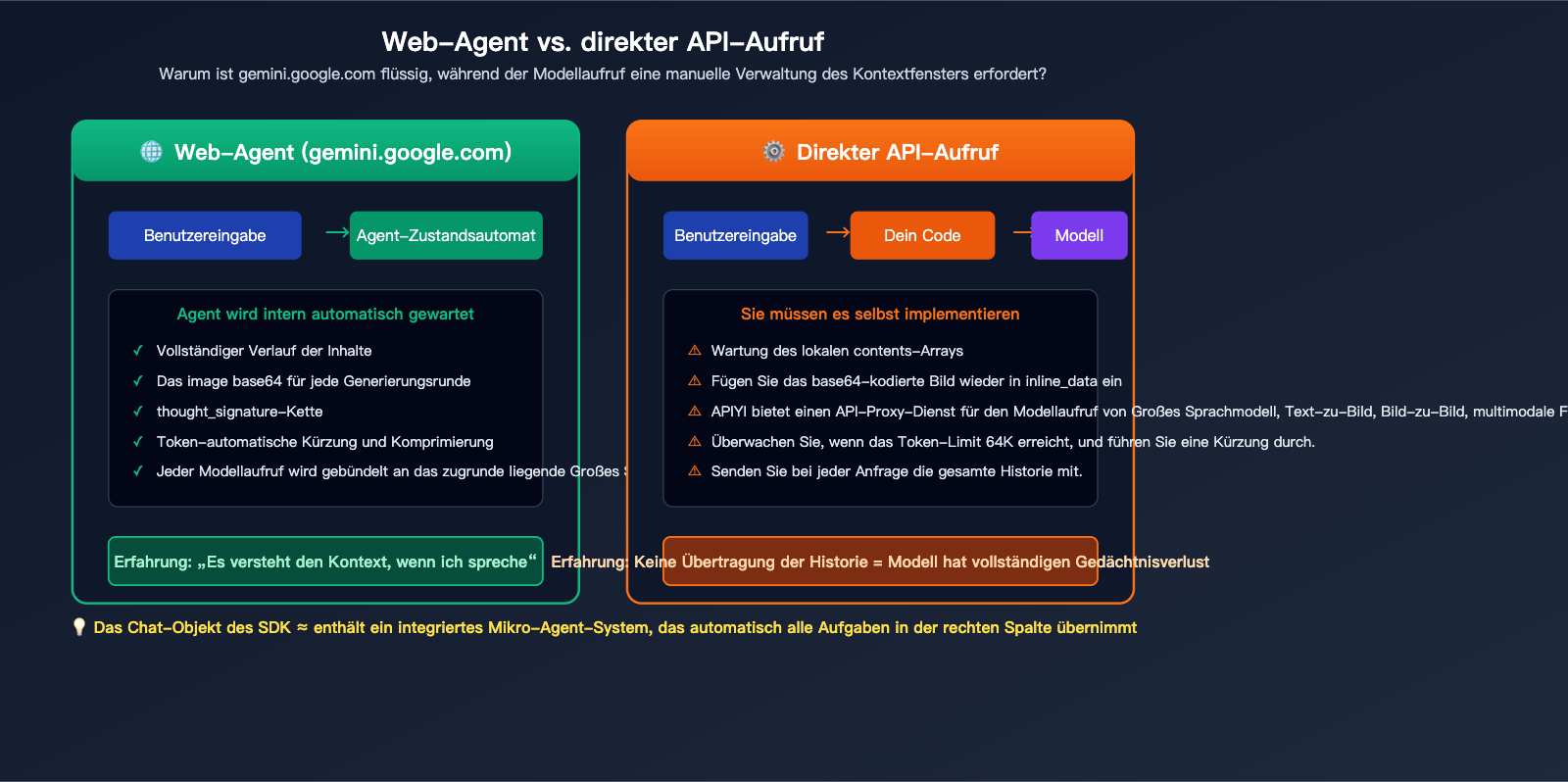
Datenhinweis: Die obige Grafik zeigt die wesentlichen Unterschiede zwischen der automatischen Agenten-Verwaltung und der manuellen API-Verwaltung. Auf der Plattform APIYI (apiyi.com) können Sie die tatsächlichen Leistungsunterschiede beider Aufrufmethoden direkt vergleichen.
Nano Banana Pro: thoughtSignature-Mechanismus für die Bilderzeugung in Multi-Turn-Dialogen
Was ist thoughtSignature?
thoughtSignature ist die mit der Gemini 3-Serie eingeführte „verschlüsselte Denksignatur“. Es handelt sich um eine kompakte Kodierung des internen Schlussfolgerungszustands des Modells. Sie ist für Menschen nicht lesbar, ermöglicht es dem Modell jedoch, den Kontext in der nächsten Runde schnell wiederherzustellen. Die konkreten Vorteile:
- Bewahrung von Detailentscheidungen: Wenn das Modell beispielsweise in der ersten Runde beschließt, einen hellen Farbton zu verwenden, übernimmt es diesen Stil in der zweiten Runde über die Signatur.
- Verbesserte Konsistenz: Charaktere, Szenen und Bildkompositionen bleiben bei mehrstufigen Bearbeitungen stabil.
- Token-Einsparung: Es ist nicht mehr nötig, in der Eingabeaufforderung wiederholt „Stil beibehalten“ zu fordern.
Wann muss die Signatur mitgeführt werden?
| Szenario | Signatur erforderlich? |
|---|---|
| Einmalige Anfrage (einzelne Bilderzeugung) | ❌ Nein |
| Multi-Turn-Bearbeitung (Änderung basierend auf dem letzten Bild) | ✅ Ja, zwingend |
| Wiederherstellung des Verlaufs über Sitzungen hinweg | ✅ Ja, zwingend (muss lokal gespeichert werden) |
| Nur Text-Dialog (keine Bilder) | ✅ Ja, für die Kontinuität der Schlussfolgerung |
Praxis: Code-Muster zur manuellen Verwaltung der Signatur
import requests
import base64
import json
API_BASE = "https://vip.apiyi.com/v1beta"
MODEL = "gemini-3-pro-image-preview"
HEADERS = {
"x-goog-api-key": "YOUR_API_KEY",
"Content-Type": "application/json"
}
class NanoBananaChat:
"""Minimaler Chat-Client zur manuellen Verwaltung von contents + signature"""
def __init__(self):
self.contents = []
def send(self, text: str, attach_image_b64: str = None) -> dict:
# Konstruktion der User-Nachricht für diese Runde
user_parts = [{"text": text}]
if attach_image_b64:
user_parts.append({
"inline_data": {"mime_type": "image/png", "data": attach_image_b64}
})
self.contents.append({"role": "user", "parts": user_parts})
# Anfrage senden
resp = requests.post(
f"{API_BASE}/models/{MODEL}:generateContent",
headers=HEADERS,
json={
"contents": self.contents,
"generationConfig": {"responseModalities": ["TEXT", "IMAGE"]}
}
).json()
# Modell-Antwort (inkl. Signatur) unverändert an contents anhängen
model_parts = resp["candidates"][0]["content"]["parts"]
self.contents.append({"role": "model", "parts": model_parts})
return model_parts
# Anwendungsbeispiel
chat = NanoBananaChat()
parts1 = chat.send("Erstelle ein Bild eines Golden Retrievers, der am Strand rennt")
parts2 = chat.send("Ändere die Szene in die Abenddämmerung") # Überträgt automatisch Verlauf und Signatur
parts3 = chat.send("Füge noch eine fliegende Möwe hinzu")
Optimierungstipp: Bei der Anbindung über APIYI (apiyi.com) leitet die Plattform das Feld
thought_signaturetransparent weiter. Entwickler müssen lediglich sicherstellen, dass das gesamtemodel parts-Array wieder ancontentsangehängt wird; um den Inhalt der Signatur selbst muss man sich nicht kümmern.
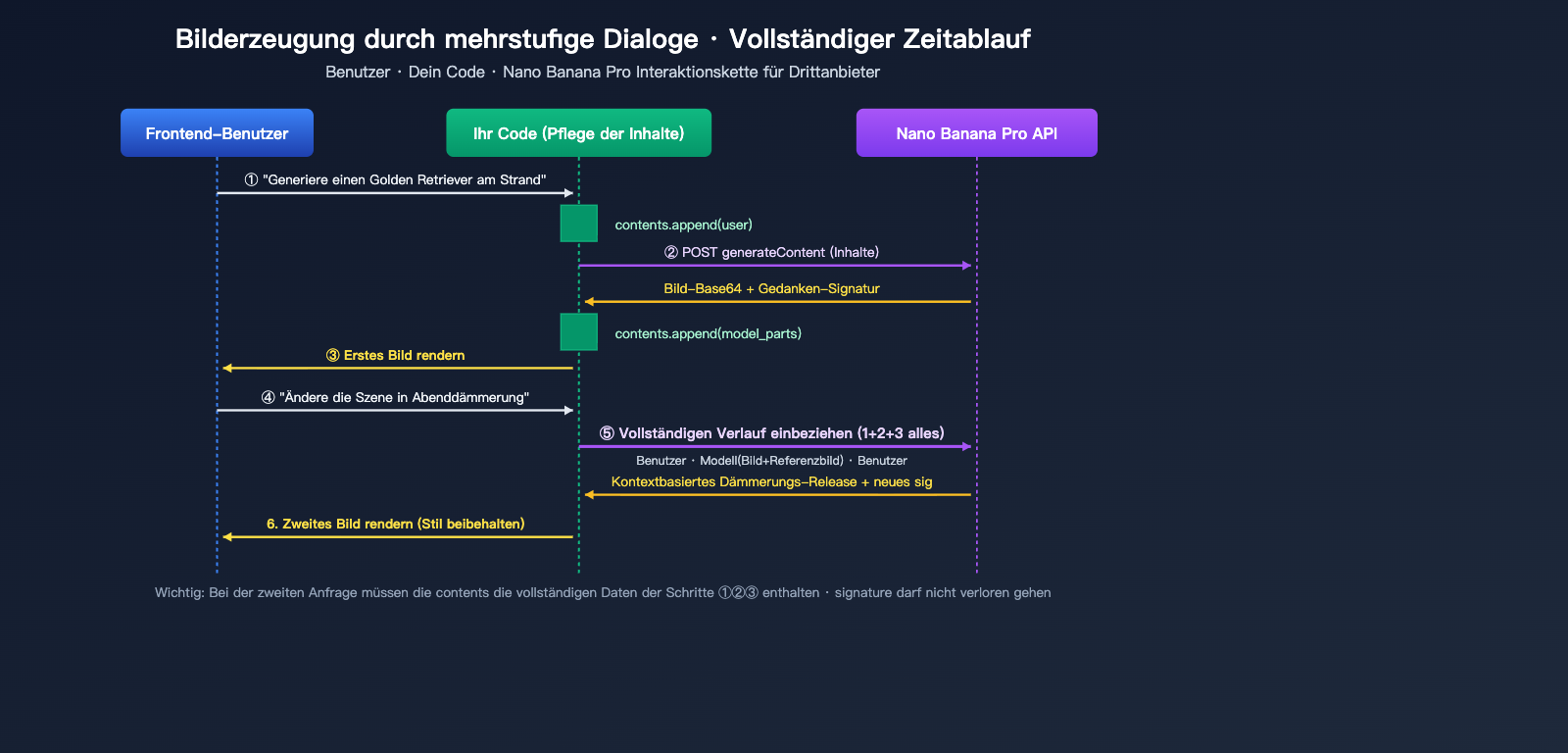
Nano Banana Pro: Praxisbeispiele für die Bilderzeugung in Multi-Turn-Dialogen
Szenario 1: Progressives Branding-Design
Eine häufige Anforderung im Marketing: Basierend auf einem Produktkonzept sollen Texte, Farben und Layout schrittweise angepasst werden. Der Vorteil der Multi-Turn-API zur Bilderzeugung liegt darin, dass Sie nur die „inkrementellen Änderungen“ beschreiben müssen, anstatt das gesamte Bild jedes Mal neu zu definieren:
chat = client.chats.create(model="gemini-3-pro-image-preview")
chat.send_message("Entwirf ein Kaffee-Markenplakat mit dunkelblauem Farbverlauf, das Produktbild soll links platziert werden")
chat.send_message("Ändere den Titeltext in „Awaken Your Morning“")
chat.send_message("Füge unten rechts einen Platzhalter für einen QR-Code hinzu")
chat.send_message("Gestalte den Gesamtstil etwas moderner und entferne die dekorativen Verzierungen")
Szenario 2: Multi-Turn-Bearbeitung basierend auf Referenzbildern
Nano Banana Pro unterstützt bis zu 14 Referenzbilder pro Anfrage. In Kombination mit Multi-Turn-Dialogen lassen sich leistungsstarke Workflows für die Bildfusion erstellen:
# Hochladen eines Porträts + eines Referenzbildes für Kleidung
chat.send_message([
"Kleide die Person aus dem ersten Bild mit der Kleidung aus dem zweiten Bild ein",
{"inline_data": {"mime_type": "image/png", "data": person_b64}},
{"inline_data": {"mime_type": "image/png", "data": outfit_b64}}
])
# Anschließende Feinabstimmung
chat.send_message("Ändere den Ausschnitt in einen V-Ausschnitt")
chat.send_message("Ändere den Hintergrund in ein schlichtes Grau")
Szenario 3: Wiederherstellung der Historie über Sitzungen hinweg
Wenn ein Benutzer die Seite im Frontend schließt und später zurückkehrt, um das Gespräch fortzusetzen, muss das contents-Array in einer Datenbank persistiert werden:
import json
# Speichern
with open(f"sessions/{user_id}.json", "w") as f:
json.dump(chat.get_history(), f)
# Wiederherstellen
with open(f"sessions/{user_id}.json") as f:
history = json.load(f)
restored_chat = client.chats.create(
model="gemini-3-pro-image-preview",
history=history
)
restored_chat.send_message("Mach weiter wie bisher, aber mach den Hintergrund etwas heller")
Einschränkungen des Kontextfensters
| Ressource | Limit |
|---|---|
| Eingabe-Kontext | 64K Token |
| Ausgabe-Kontext | 32K Token |
| Max. Referenzbilder pro Anfrage | 14 Bilder |
| Empfohlene Dialogrunden | Maximal 8-10 Runden |
| Max. Auflösung pro Bild | 2K (Standard 1K) |
Empfehlung für Szenarien: Wenn ein Dialog 8-10 Runden überschreitet, empfiehlt es sich, die frühere Historie aktiv zu „kürzen“ oder durch eine Zusammenfassung mittels Großem Sprachmodell zu ersetzen, da die Token-Anzahl sonst schnell das 64K-Limit erreicht. Implementieren Sie in Produktionsumgebungen unbedingt einen Token-Zähler, um frühzeitig Entscheidungen zur Kürzung auf Client-Seite zu treffen.
Häufig gestellte Fragen (FAQ)
Q1: Ich rufe die API direkt auf und habe keinen Kontext. Wie implementiere ich einen kontinuierlichen Dialog wie in der Webversion?
Die API ist zustandslos. Ihr Code muss ein lokales contents-Array (oder das chat-Objekt im SDK) verwalten. Bei jeder Anfrage muss die vollständige Historie (einschließlich Benutzereingaben, vom Modell generierten Bildern und thought_signature) mitgesendet werden, damit das Modell sich an den vorherigen Dialog „erinnert“. Am einfachsten geht dies mit client.chats.create() aus dem offiziellen Python-SDK, das die Verwaltung automatisch übernimmt.
Q2: Welche Felder muss ich für das in der vorherigen Runde generierte Bild übergeben?
Das Bild muss als inline_data (base64-kodiert + mime_type) in das parts-Array der „Modell-Rolle“ der vorherigen Runde eingefügt werden. Stellen Sie unbedingt sicher, dass auch die vom Modell zurückgegebene thought_signature mit übertragen wird. Bei der Nutzung von API-Proxy-Diensten wie APIYI (apiyi.com), die OpenAI-kompatibel sind, übernimmt die Plattform das Mapping dieser Felder automatisch; Entwickler müssen lediglich die Standard-Messages-Liste pflegen.
Q3: Muss die thoughtSignature zwingend übertragen werden? Was passiert, wenn nicht?
Es wird dringend empfohlen, sie zu übertragen. Ohne sie könnte das Modell bei der Multi-Turn-Bearbeitung wichtige Entscheidungen der vorherigen Runde (wie Stil, Farbgebung oder Komposition) „vergessen“, was dazu führt, dass jede Runde wie eine komplette Neuerstellung wirkt. Die offizielle Dokumentation weist ausdrücklich darauf hin, dass die Signatur in Multi-Turn-Szenarien beibehalten werden muss. Das SDK erledigt dies automatisch; im REST-Modus müssen die Modell-Parts manuell vollständig an die contents angehängt werden.
Q4: Was tun, wenn die Historie zu lang wird? Gibt es eine Fehlermeldung bei über 64K Token?
Ja, bei Überschreitung der 64K Eingabe-Token wird die Anfrage abgelehnt. Gängige Optimierungsstrategien:
- Kürzung: Behalten Sie nur die letzten 4-6 Runden bei.
- Downsampling von Bildern: Übertragen Sie historische Bilder in 1K statt 2K Auflösung.
- Zusammenfassungen: Nutzen Sie ein Großes Sprachmodell, um die ersten Runden in eine kurze Textbeschreibung zu komprimieren.
- Segmentierte Sitzungen: Starten Sie bei einem Themenwechsel aktiv eine neue Sitzung.
Q5: Wie kann ich die Multi-Turn-Bilderzeugung von Nano Banana Pro schnell testen?
Wir empfehlen Aggregator-Plattformen wie APIYI (apiyi.com), die Gemini-Modelle unterstützen, für eine schnelle Validierung:
- Registrieren Sie ein Konto, um einen API-Schlüssel und ein kostenloses Guthaben zu erhalten.
- Wählen Sie das Modell
gemini-3-pro-image-preview. - Führen Sie mit dem Beispiel-Python-Code aus diesem Artikel 3-5 aufeinanderfolgende Bearbeitungsrunden durch.
- Vergleichen Sie die Konsistenz der Ausgaben jeder Runde, um zu beurteilen, ob sie Ihren geschäftlichen Anforderungen entspricht.
Zusammenfassung
Die Kernpunkte der Nano Banana Pro API für die Bilderzeugung in Multi-Turn-Dialogen:
- Zustandslosigkeit: Die API speichert keine Historie; der Aufrufer muss das
contents-Array zwingend selbst verwalten. - Rollenwechsel: Die Rollen
userundmodelmüssen strikt abwechseln. Jede Runde kannpartsmit einer Mischung aus Text, Bild und Signatur enthalten. - Bildrückführung: Das in der vorherigen Runde generierte Bild muss als
inline_datazurückgegeben werden, da das Modell es sonst nicht „sieht“. - Signaturmechanismus: Die
thought_signatureist entscheidend für die Konsistenz über mehrere Runden hinweg und muss im REST-Modus manuell mitgeführt werden. - SDK-Vereinfachung: Das
chat-Objekt des offiziellen Python-SDKs verwaltet all diese Details automatisch.
Für Entwickler, die schnell eine Web-Erfahrung implementieren möchten, ist der beste Weg die Nutzung des chat-Objekts des offiziellen SDKs oder der Messages-Modus der OpenAI-kompatiblen Schnittstelle, um die Komplexität manueller REST-Aufrufe zu vermeiden.
Wir empfehlen den Zugriff auf die Nano Banana Pro Multi-Turn-Bilderzeugungsfunktionen über APIYI (apiyi.com). Die Plattform unterstützt sowohl native Gemini-Felder als auch den OpenAI-kompatiblen Modus, bietet kostenlose Testkontingente und ermöglicht eine schnelle Validierung der Multi-Turn-Bearbeitung sowie eine reibungslose Migration bestehender Projekte.
📚 Referenzen
-
Offizielle Dokumentation zur Gemini API Bilderzeugung: Maßgebliche Anleitung für die Bilderzeugung in Multi-Turn-Dialogen.
- Link:
ai.google.dev/gemini-api/docs/image-generation - Hinweis: Enthält Spezifikationen für das
contents-Feld sowie vollständige Beispiele für das Python-SDK und REST.
- Link:
-
Modellkarte für Gemini 3 Pro Image Preview: Informationen zu Modellfähigkeiten und Einschränkungen.
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3-pro-image-preview - Hinweis: Wichtige Parameter wie Kontextfenster, Auflösung und Anzahl der Referenzbilder.
- Link:
-
Google AI Developers Forum – Multi-turn Nano Banana: Praxisbeispiele aus der Community.
- Link:
discuss.ai.google.dev/t/multi-turn-nano-banana-example - Hinweis: Best Practices für Multi-Turn-Dialoge, diskutiert von echten Entwicklern.
- Link:
-
Dokumentation zu Vertex AI Gemini 3 Pro Image: Referenz für den Unternehmenseinsatz.
- Link:
docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-pro-image - Hinweis: Enthält fortgeschrittene Nutzungsmöglichkeiten für
thought_signatureundfile_data-Referenzen.
- Link:
-
APIYI Nano Banana Pro Integrationsdokumentation: Schneller Einstieg für Entwickler.
- Link:
help.apiyi.com - Hinweis: Enthält Beispiele für die OpenAI-kompatible Schnittstelle sowie die native Gemini-Schnittstelle.
- Link:
Autor: APIYI Technical Team
Technischer Austausch: Teilen Sie gerne Ihre praktischen Erfahrungen mit der Bilderzeugung in Multi-Turn-Dialogen in den Kommentaren. Weitere Konfigurationstipps für Nano Banana Pro finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com.