Cuando necesitas procesar decenas de miles de descripciones de productos, etiquetado de datos, moderación de contenido o tareas de vectorización durante la noche, las invocaciones de API estándar son lentas y costosas. /v1/batches de OpenAI y el Modo Batch de Google Gemini ofrecen la misma solución: subes un archivo JSONL, recibes todos los resultados de forma asíncrona en un plazo de 24 horas y el precio se reduce a la mitad (50% de descuento).
Sin embargo, en la práctica, las plataformas de agregación de API (servicios proxy de API) generalmente no admiten la conexión directa a /v1/batches debido a que sus modelos de facturación son incompatibles con el mecanismo de liquidación de tokens asíncrono de las interfaces de procesamiento por lotes oficiales. Esto significa que, si deseas disfrutar del descuento oficial del 50% y de la capacidad de alta concurrencia de cientos de millones de tokens, debes realizar la invocación utilizando una cuenta oficial + clave API oficial. Para los desarrolladores, la ruta más conveniente es realizar un pedido a través de servicios profesionales de recarga oficial de API: api-sparkle-charge.lovable.app, o visitar AI 代充网: ai.daishengji.com para consultar la lista de precios completa.
Este artículo, basado en la documentación oficial en inglés de OpenAI y Google AI, sistematiza las especificaciones técnicas, los mecanismos de facturación y la implementación práctica de ambas API de procesamiento por lotes, además de ofrecer una guía de selección de escenarios para servicios de recarga.
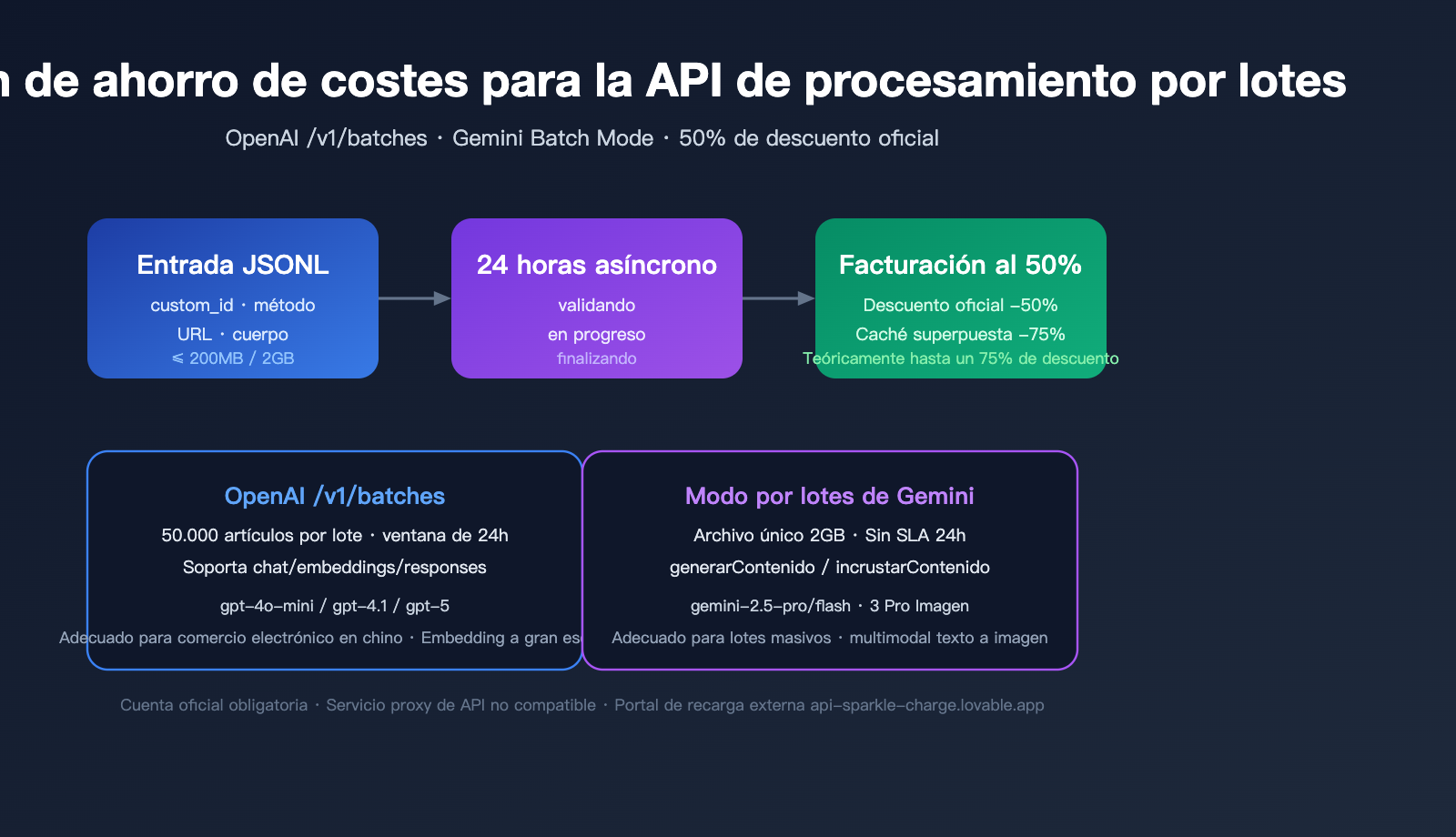
Valor central de la API de procesamiento por lotes: por qué vale la pena abrir una cuenta oficial
La API de procesamiento por lotes (Batch API) es una interfaz dedicada diseñada por OpenAI y Google para escenarios de gran volumen y baja latencia en tiempo real. Su lógica de intercambio central es: renuncias a la determinación de una respuesta en tiempo real a cambio de un descuento del 50% en el precio oficial y límites de tasa más altos.
Diferencias esenciales entre la API de procesamiento por lotes y la API síncrona
La siguiente tabla compara los parámetros clave de ambos modos de invocación:
| Dimensión | API Síncrona | API de Procesamiento por Lotes |
|---|---|---|
| Latencia de respuesta | Nivel de segundos | Hasta 24 horas |
| Precio por Token | Precio estándar | 50% de descuento (-50%) |
| Límite por solicitud | 1 unidad | 50,000 unidades (OpenAI) / 2GB JSONL (Gemini) |
| Límite de tasa | RPM/TPM estricto | Cuota independiente más alta |
| Reintento de fallos | Gestión propia | Reintento automático en capa de interfaz |
| Caché de indicación | Ventana de 5-10 min | La indicación del sistema compartida ahorra recursos |
💡 Consejo de integración: La API de procesamiento por lotes debe invocarse utilizando una cuenta y clave nativas oficiales; las plataformas de agregación no pueden transmitir tareas asíncronas
/v1/batches. Recomendamos realizar pedidos directamente a través del servicio de recarga oficial api-sparkle-charge.lovable.app para obtener inmediatamente el descuento del 50%, y utilizar la capacidad de liquidación multidivisa de AI 代充网 ai.daishengji.com para completar la recarga de la cuenta en 1 minuto.
Escenarios más adecuados para el procesamiento por lotes
Según la documentación oficial y la experiencia de desarrolladores líderes, los siguientes escenarios son los que generan un mayor ahorro:
- Etiquetado/clasificación de datos: Análisis de sentimiento de 100,000 comentarios; la invocación síncrona cuesta ~$500, mientras que el procesamiento por lotes cuesta solo ~$250.
- Generación de descripciones de productos: Ampliación masiva de SKU de comercio electrónico, que generalmente se completa en un lote durante la noche.
- Resumen/vectorización de documentos: Procesamiento de bases de conocimiento a gran escala.
- Evaluación de modelos (eval): Ejecución de conjuntos de pruebas donde la puntualidad no es crítica.
- Moderación de contenido: Filtrado masivo de contenido generado por el usuario (UGC).
- Generación masiva de Embedding: Construcción de bases de datos vectoriales.
title: Especificaciones técnicas de la Batch API de OpenAI (/v1/batches)
Especificaciones técnicas de la Batch API de OpenAI (/v1/batches)
El endpoint /v1/batches de OpenAI es el estándar de la industria y ha operado con estabilidad desde su lanzamiento en 2024. Su filosofía de diseño consiste en reutilizar completamente el cuerpo de solicitud de la interfaz síncrona, lo que reduce drásticamente el coste de migración para los desarrolladores que pasan de procesos síncronos a procesamiento por lotes.
Restricciones y cuotas principales
| Ítem | Valor | Nota |
|---|---|---|
| Ventana de finalización | 24 horas | Actualmente solo admite 24h |
| Límite por lote | 50,000 solicitudes | Si se excede, dividir en múltiples lotes |
| Límite por archivo | 200 MB | Basado en JSONL UTF-8 |
| Endpoints admitidos | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
No incluye imágenes/audio |
| Descuento | -50% | 50% de descuento en todos los modelos admitidos |
| Bucket de tasa especial | Independiente | No consume TPM (tokens por minuto) síncrono |
Ejemplo de formato de archivo JSONL
OpenAI requiere que cada línea del archivo subido sea un objeto JSON independiente que contenga cuatro campos: custom_id, method, url y body:
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Eres un experto en clasificación de productos"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Eres un experto en clasificación de productos"}, {"role": "user", "content": "Sony WH-1000XM6"}]}}
Cuatro pasos para completar una invocación de modelo en lote de OpenAI
Paso 1: Subir el archivo JSONL
from openai import OpenAI
client = OpenAI(api_key="sk-clave-oficial") # Clave oficial obtenida por recarga
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
Paso 2: Crear la tarea de procesamiento por lotes
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
Paso 3: Consultar el estado
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
Paso 4: Descargar los resultados
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)
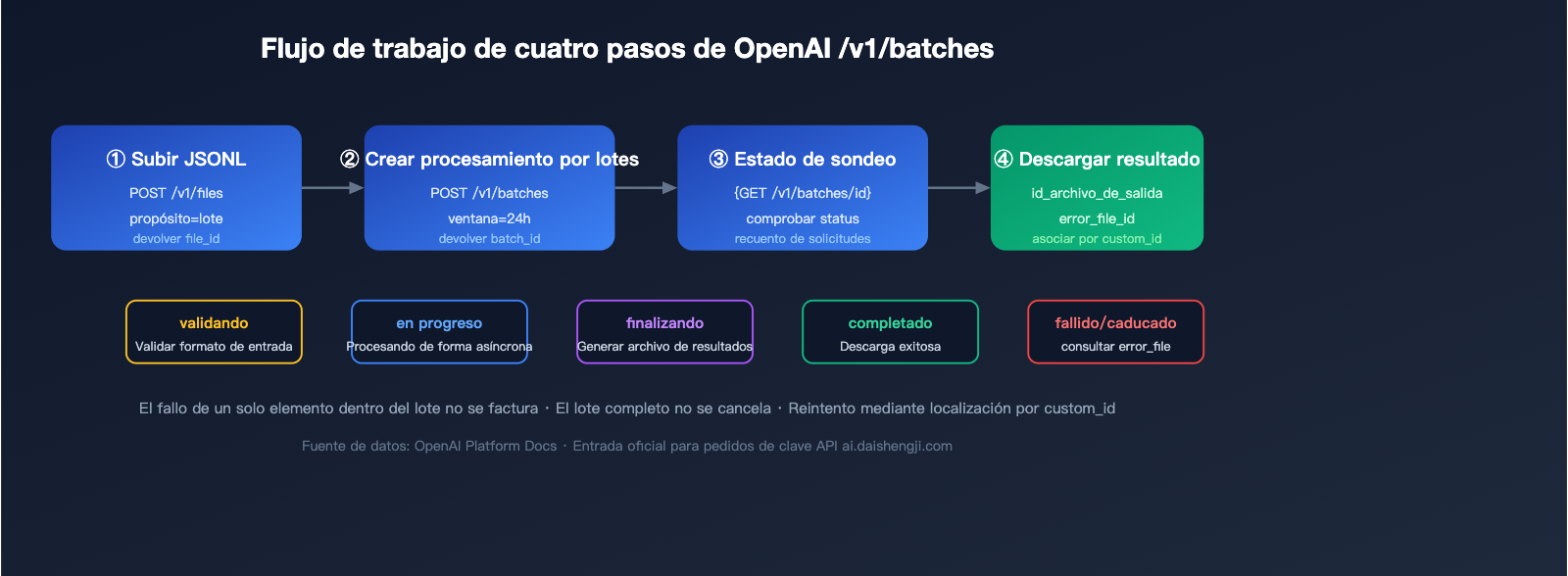
🎯 Consejo para obtener la clave API: La Batch API de OpenAI requiere obligatoriamente una clave nativa oficial sk-; las claves de servicios proxy (hub- o sk-proxy-*) no pueden invocar
/v1/batches. Si necesitas obtener cuotas oficiales rápidamente, puedes hacer tu pedido a través de servicios de recarga: api-sparkle-charge.lovable.app admite recargas para cuentas oficiales de OpenAI/Anthropic/Google, con acreditación en 5-30 minutos. También puedes consultar distintas combinaciones de ofertas en el sitio ai.daishengji.com.
Especificaciones técnicas de Gemini Batch Mode
Lanzado por Google en 2025, Gemini Batch Mode sigue una línea similar a la de OpenAI, pero es más ambicioso en cuanto al tamaño de los archivos y la adaptabilidad de los modelos.
Restricciones y cuotas principales
| Proyecto | Valor | Descripción |
|---|---|---|
| Ventana de finalización | Hasta 24 horas | Sin SLA estricto |
| Límite de tamaño por archivo | 2 GB | Aprox. 10 veces más que OpenAI |
| Modelos admitidos | gemini-2.5-pro / flash / flash-lite | Incluye Gemini 3 Pro Image |
| Descuento en precio | -50% | 50% de descuento en tokens de entrada y salida |
| Endpoints compatibles | generateContent / embedContent |
Los mismos que en la interfaz síncrona |
| Versión Vertex AI | Admite despliegue regional | Escenarios de cumplimiento empresarial |
Ejemplo de formato JSONL para Gemini
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "Escribe un punto de venta de 30 palabras para el siguiente producto: iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "Escribe un punto de venta de 30 palabras para el siguiente producto: Sony WH-1000XM6"}]}]}}
Ejemplo de invocación de Gemini Batch
from google import genai
client = genai.Client(api_key="AIza-clave-oficial")
# Subir archivo
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# Crear trabajo de procesamiento por lotes (Batch)
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# Obtener resultados
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Consejo sobre recargas de Gemini: La capacidad de procesamiento por lotes de Gemini solo está disponible en cuentas de pago nativas de Google AI Studio o Vertex AI; no está disponible dentro de los créditos gratuitos. Si en tu región no puedes vincular una tarjeta de crédito internacional, puedes realizar una recarga rápida a través del canal oficial de Gemini en ai.daishengji.com o realizar un pedido directo en api-sparkle-charge.lovable.app.
Decisión entre la API Batch de OpenAI y Gemini
A la hora de elegir una herramienta para un proyecto real, los desarrolladores suelen dudar entre ambas. La siguiente tabla compara las dimensiones clave:
| Elemento | OpenAI Batch | Gemini Batch | Escenario recomendado |
|---|---|---|---|
| Límite de solicitudes | 50,000 entradas | JSONL de 2GB (~100,000+) | Elegir Gemini para volumen masivo |
| Tamaño por archivo | 200 MB | 2 GB | Elegir Gemini para archivos grandes |
| Calidad de respuesta (Chino) | Serie gpt-4o/4.1 es mejor | gemini-2.5-pro es equilibrado | Elegir GPT para razonamiento en chino |
| Soporte multimodal | Texto/Embeddings | Texto/generación de imágenes | Elegir Gemini para imágenes por lotes |
| Reutilización de caché | prompt caching | implicit context caching | Elegir OpenAI para términos de sistema iguales |
| Complejidad de facturación | Simple y clara | Requiere distinguir niveles | Elegir OpenAI para auditorías financieras |
| Madurez de documentación | La más madura | En iteración continua | Elegir OpenAI para despliegue rápido |

Sugerencias de selección basadas en escenarios
- Procesamiento por lotes de SKU de comercio electrónico en chino: gpt-4o-mini Batch, la mejor relación coste-beneficio.
- Imagen y texto multimodal cruzado: Gemini 2.5 Pro Batch, canal unificado.
- Construcción de embeddings masivos: OpenAI text-embedding-3-small Batch.
- Cumplimiento empresarial en múltiples regiones: Vertex AI Gemini Batch.
Optimización profunda de la reutilización y caché de indicaciones del sistema
Los usuarios suelen preguntar: "¿Si cada solicitud en un procesamiento por lotes (batch) contiene la misma indicación del sistema, se puede facturar solo una vez?". Esta es una pregunta frecuente pero fácil de malinterpretar.
La verdad sobre la facturación de indicaciones en el procesamiento por lotes de OpenAI
La API /v1/batches de OpenAI no elimina automáticamente los duplicados de las indicaciones del sistema. Sin embargo, al combinarla con el mecanismo de Prompt Caching, cuando el prefijo de la conversación es idéntico y consecutivo dentro del lote, los tokens de entrada en caché reciben un descuento adicional del 50%. Al sumarse al 50% del procesamiento por lotes, teóricamente se puede alcanzar un descuento de hasta el 75% (un cuarto del precio original).
Condiciones específicas para que sea efectivo:
- El prefijo del cuerpo de la solicitud debe ser estrictamente idéntico (incluyendo roles, definiciones de herramientas y texto).
- La longitud del prefijo debe ser ≥ 1024 tokens (512 tokens en algunos modelos).
- Alcanzar el umbral de acierto de caché dentro de una ventana de 24 horas.
Caché de contexto implícito de Gemini
El modo Batch de Gemini admite de forma nativa el Caché de contexto implícito. Cuando el prefijo de la solicitud se repite, el sistema crea automáticamente una caché sin necesidad de gestionar manualmente cached_content. La parte que acierta en la caché se liquida según los precios de caché de Gemini (aprox. 25% del precio original), y al sumarle el 50% del Batch, el costo puede reducirse hasta un 12.5%.
Cálculo de costos combinando procesamiento por lotes + caché
Supongamos 100,000 solicitudes, cada una compartiendo 2000 tokens de indicación del sistema + 500 tokens de entrada del usuario + 300 tokens de salida:
| Esquema | Costo por unidad | Estimación costo total | Ahorro |
|---|---|---|---|
| Invocación síncrona (sin caché) | $0.0028 | $280 | Base |
| Síncrona + Prompt Caching | $0.0018 | $180 | -36% |
| Procesamiento por lotes (50% desc.) | $0.0014 | $140 | -50% |
| Lotes + Caching | $0.0009 | $90 | -68% |
⚡ Consejo para ahorrar: Cuando se cumplan simultáneamente las condiciones de: misma indicación del sistema + mismo modelo + tareas nocturnas, asegúrate de usar la combinación "Procesamiento por lotes + Prompt Caching". Para habilitar estas optimizaciones en cuentas oficiales, es necesario confirmar la estrategia de facturación. Al realizar un pedido en el servicio de recarga api-sparkle-charge.lovable.app, puedes añadir una nota indicando "necesito activar el descuento de batch + cache" y se te asignará automáticamente el nivel de precio más óptimo.
Por qué el servicio proxy de API no admite procesamiento por lotes: análisis técnico
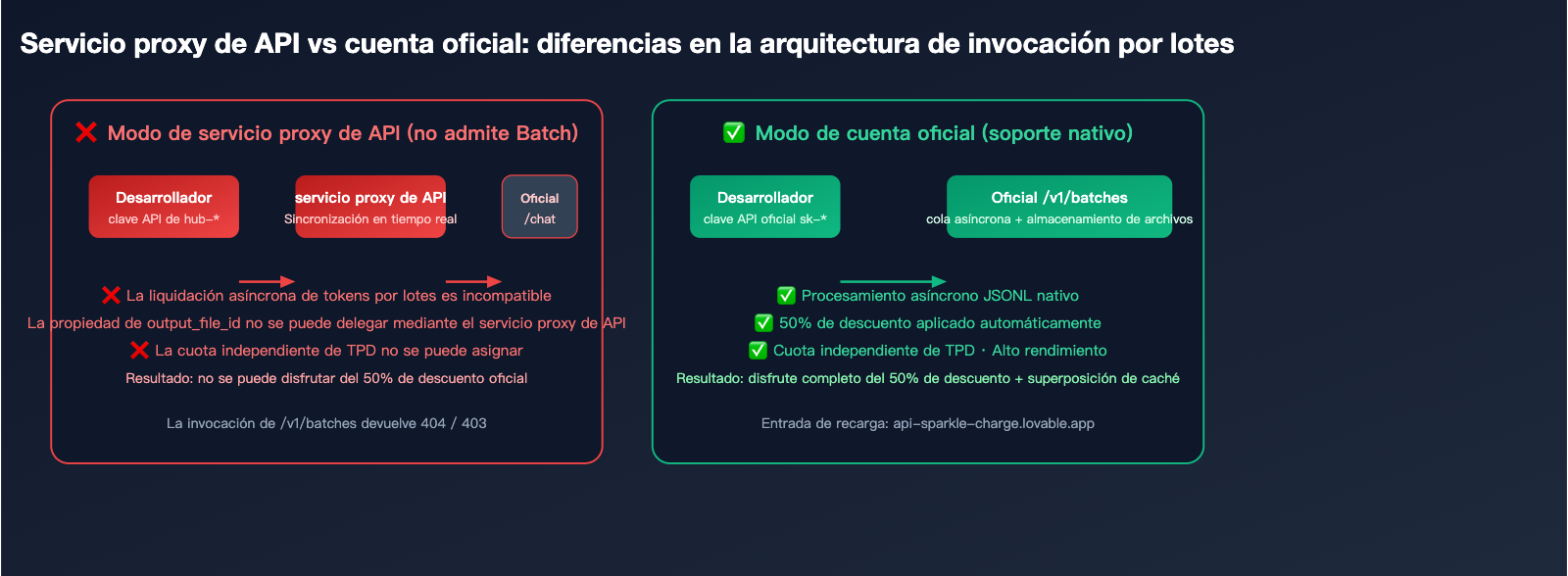
Muchos usuarios no entienden por qué las plataformas de API de terceros (servicio proxy de API) generalmente no admiten /v1/batches. Esto debe explicarse desde el nivel de arquitectura técnica:
Razón fundamental 1: Incompatibilidad del modelo de facturación
El servicio proxy de API basa su facturación en invocaciones en tiempo real (costo oficial × 1.x de margen), mientras que el procesamiento por lotes se liquida una sola vez después de 24 horas, lo que requiere que el servicio proxy asuma un gran riesgo financiero de pago por adelantado y riesgo cambiario.
Razón fundamental 2: Cadena de transmisión de tokens no transparente
El output_file_id devuelto por la interfaz de procesamiento por lotes es un objeto del sistema de archivos oficial. Si el servicio proxy quisiera actuar como intermediario, tendría que replicar todo el sistema de almacenamiento y ancho de banda de archivos, y es difícil cambiar la propiedad de los enlaces de descarga.
Razón fundamental 3: Cuotas de velocidad independientes
La interfaz de procesamiento por lotes tiene una cuota de TPD (Tokens por día) independiente, totalmente aislada del TPM/RPM síncrono. El servicio proxy no puede estimar las necesidades de cuota diaria de cada usuario final, por lo que es difícil realizar una redistribución razonable.
Solución: Abrir una cuenta oficial mediante recarga
La solución más limpia es permitir que el usuario posea directamente una cuenta oficial:
- Nivel técnico: Evita todas las restricciones del servicio proxy, acceso nativo a todas las capacidades de
/v1/batches. - Nivel de cumplimiento: La facturación, el cumplimiento y los reembolsos se gestionan a través de los canales oficiales.
- Nivel de eficiencia: No es necesario realizar una división síncrona/asíncrona en escenarios de procesamiento por lotes.
- Nivel de costo: El servicio de recarga solo cobra una tarifa de gestión razonable, manteniendo intacto el descuento del 50% del procesamiento por lotes.
Esta es precisamente la propuesta de valor central de api-sparkle-charge.lovable.app y ai.daishengji.com: ayudarte a obtener cuentas y claves oficiales de primera mano, permitiendo que los beneficios del ahorro por procesamiento por lotes se materialicen por completo.
Caso práctico: Clasificación por lotes de 100 000 preguntas de atención al cliente (ejemplo completo)
A continuación, presento un ejemplo técnico listo para usar: cómo realizar la clasificación de intenciones de 100 000 registros históricos de atención al cliente.
Paso 1: Construcción de la entrada JSONL
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions es una lista de 100 000 elementos
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "Clasifica la pregunta del usuario en: billing/tech/sales/other, devuelve solo la palabra de la categoría"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
Paso 2: División según el límite de 200 MB
# Cuando las 100 000 entradas superen los 200 MB, divide el archivo cada 40 000 registros
# Si usas Gemini, no hace falta dividir, ya que el límite es de 2 GB
Paso 3: Envío y monitorización
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
Paso 4: Consolidación de resultados
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
Estimación de costes: 100 000 × ~600 tokens × precio de Batch de gpt-4o-mini ≈ $6-9, ahorrando un 50% en comparación con la invocación del modelo síncrona.
Preguntas frecuentes (FAQ)
P1: ¿Puede una clave API de un servicio proxy de API invocar /v1/batches?
No. Las claves devueltas por un servicio proxy de API (que suelen comenzar con hub-, sk-proxy- o prefijos personalizados) solo admiten puntos finales síncronos como /v1/chat/completions. La interfaz de procesamiento por lotes depende del sistema de archivos y las colas de tareas asíncronas de la cuenta oficial, por lo que es obligatorio usar una clave API oficial sk-*. Si necesitas una clave oficial, puedes realizar un pedido a través de api-sparkle-charge.lovable.app o visitar AI 代充网 ai.daishengji.com para ver diferentes opciones de cuentas oficiales.
P2: ¿El descuento del 50% de Gemini Batch se aplica a todos los modelos?
Actualmente, Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite y Gemini 3 Pro Image disfrutan del descuento del 50% en procesamiento por lotes, reduciendo a la mitad tanto los tokens de entrada como los de salida. Las cuentas de nivel gratuito (Free Tier) no pueden usar el procesamiento por lotes; es necesario tener una cuenta de pago. Las cuentas oficiales de pago obtenidas mediante servicios de recarga están listas para usar desde el primer momento.
P3: ¿Qué ocurre si una tarea de procesamiento por lotes falla? ¿Se reembolsa el coste?
La estrategia es la misma para ambos proveedores: las solicitudes individuales fallidas no se cobran y el lote completo no se cancela. En el output_file de OpenAI, las entradas fallidas contendrán un campo error, y el error_file_id agrupará todos los errores; Gemini proporciona detalles del error cuando el estado es state=JOB_STATE_FAILED. Puedes volver a procesar las entradas fallidas directamente utilizando el custom_id.
P4: ¿Se activa el almacenamiento en caché de la indicación (Prompt Caching) en el procesamiento por lotes?
Sí. La documentación de OpenAI especifica que cuando las solicitudes Batch alcanzan los tokens de entrada almacenados en caché, se aplica un descuento adicional del 50% sobre el descuento del 50% del Batch (es decir, un 25% del precio original). Para que esto funcione, debes asegurarte de que el prefijo de las solicitudes dentro del lote sea estrictamente idéntico y alcance la longitud mínima de caché.
P5: ¿Son seguras las cuentas oficiales de los servicios de recarga? ¿Puedo recargarlas yo mismo después?
Los servicios de recarga legítimos (como api-sparkle-charge.lovable.app) entregan cuentas oficiales de propiedad total; puedes modificar la información de inicio de sesión y los métodos de pago vinculados a tu gusto, y posteriormente realizar recargas tú mismo usando tarjetas de crédito internacionales o Apple Pay. AI 代充网 ai.daishengji.com ofrece varios paquetes, admite facturación y es apto para informes de gastos corporativos, cumpliendo con los requisitos de cumplimiento normativo.
Resumen
La API de procesamiento por lotes (Batch API) es la palanca de ahorro más subestimada para la implementación de ingeniería de IA en 2026: una sola línea con completion_window="24h" puede reducir a la mitad toda tu cadena de costes. Sin embargo, impone un requisito estricto al cliente: es obligatorio usar cuentas y claves API nativas oficiales; las plataformas de servicio proxy de API no pueden gestionarlo debido a las limitaciones de su arquitectura de facturación.
Para los equipos con tareas masivas offline, la ruta más económica es abrir directamente una cuenta oficial y aplicar una optimización profunda combinándola con Prompt Caching. El servicio de recarga oficial de API es la forma más sencilla para que los desarrolladores accedan a este beneficio: puedes realizar tu pedido en api-sparkle-charge.lovable.app, y consultar la lista completa de precios en ai.daishengji.com. Con pedidos en 5 minutos y acreditación en 30, podrás capitalizar de inmediato ese 50% de descuento en procesamiento por lotes.
📌 Créditos del autor: Este artículo ha sido preparado por el equipo técnico de APIYI (apiyi.com), basándose en la documentación oficial en inglés de OpenAI Platform y Google AI for Developers. Los precios y cuotas están sujetos a las políticas oficiales vigentes al 14-04-2026. Enlace para pedidos de recarga: api-sparkle-charge.lovable.app / ai.daishengji.com