LiteLLM y Claude Code son dos de las herramientas de desarrollo de IA más populares en 2025-2026, pero los desarrolladores suelen compararlas constantemente: ¿cuál es mejor? ¿Pueden sustituirse entre sí? ¿LiteLLM realmente admite la facturación de caché de la indicación? En este artículo comparamos LiteLLM y Claude Code, ofreciendo recomendaciones claras desde tres dimensiones: posicionamiento, límites de capacidad y soporte de facturación de caché.
Valor central: Al terminar de leer, sabrás si realmente debes elegir uno sobre el otro y cómo tomar la mejor decisión según el escenario.

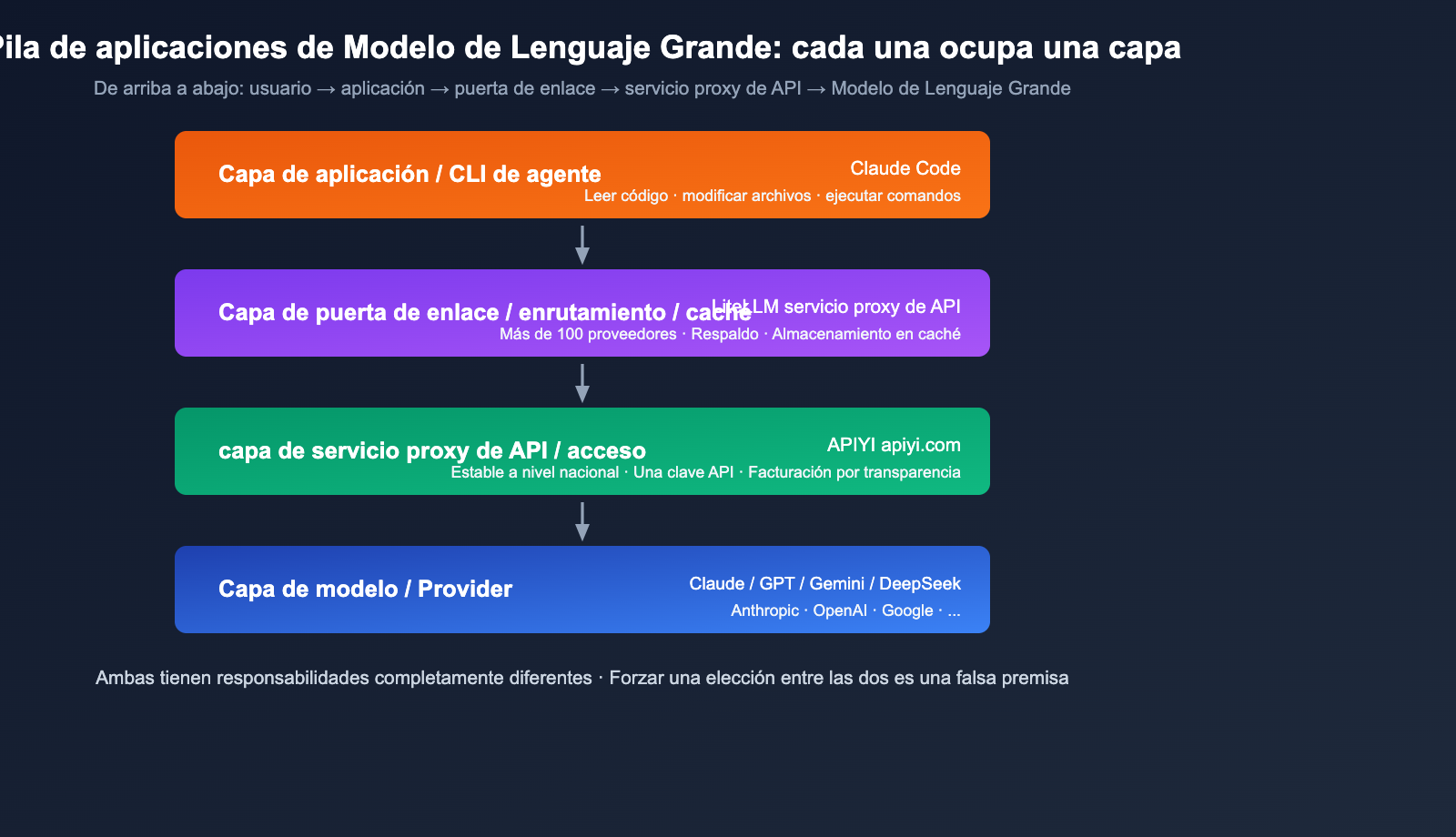
Diferencias clave entre LiteLLM y Claude Code
Muchos consideran a LiteLLM y Claude Code como competidores, pero en realidad tienen posicionamientos completamente distintos e incluso pueden combinarse. En una frase, la diferencia esencial es:
- LiteLLM = Puerta de enlace de LLM / capa de proxy, que permite invocar más de 100 modelos con un solo código.
- Claude Code = CLI de codificación con agentes oficial de Anthropic, enfocada en "usar Claude para modificar tu base de código".
| Dimensión de comparación | LiteLLM | Claude Code |
|---|---|---|
| Formato de producto | SDK de Python + Servidor Proxy | Herramienta de línea de comandos (CLI) |
| Posicionamiento central | Puerta de enlace de LLM / enrutamiento de modelos | Asistente de codificación con agentes |
| Modelos soportados | Más de 100 (OpenAI/Anthropic/Gemini/Bedrock/Vertex, etc.) | Solo familia Claude por defecto |
| Usuario típico | Ingenieros de plataforma, desarrolladores de aplicaciones de IA | Desarrolladores individuales, escenarios de codificación |
| ¿Es de código abierto? | ✅ Sí (BerriAI/litellm) | CLI de código cerrado |
| ¿Pueden sustituirse? | ❌ No | ❌ No |
| ¿Pueden combinarse? | ✅ Sí (LiteLLM detrás de Claude Code) | ✅ Sí (Claude Code con LiteLLM) |
| Mejor aliado | Combinado con APIYI (apiyi.com) para un proxy estable | Combinado con LiteLLM para cambiar el modelo subyacente |
💡 Conclusión rápida: Si te preguntas "¿cuál es mejor?", lo más probable es que necesites usar ambos: Claude Code como agente de codificación y LiteLLM como entrada unificada, accediendo a modelos internacionales a través de APIYI (apiyi.com). Ese es el stack tecnológico más común en 2026.
title: "LiteLLM vs Claude Code: 5 diferencias clave y guía de caché"
description: "Analizamos las diferencias fundamentales entre LiteLLM y Claude Code, y cómo aprovechar el almacenamiento en caché de prompts para optimizar costes."
5 diferencias clave entre LiteLLM y Claude Code
Diferencia 1: Posicionamiento (Gateway vs. CLI de Agente)
Posicionamiento de LiteLLM: Es un gateway de Modelos de Lenguaje Grande de código abierto, cuyo objetivo es "invocar cualquier modelo usando el formato compatible con OpenAI". Tiene dos formas:
- SDK de Python:
litellm.completion(model="..."), para que los desarrolladores lo usen en sus aplicaciones. - Servidor Proxy:
litellm --config config.yaml, ejecutado como un servicio independiente para compartir en equipo.
Posicionamiento de Claude Code: Es una CLI de codificación agente lanzada oficialmente por Anthropic, cuyo objetivo es "permitir que Claude lea tu código, lo modifique y ejecute comandos directamente en tu terminal". Es un producto de capa de aplicación que utiliza la API de Messages de Anthropic.
En resumen: LiteLLM es la "tubería", Claude Code es el "grifo instalado en la tubería".
Diferencia 2: Rango de modelos soportados
| Dimensión | LiteLLM | Claude Code |
|---|---|---|
| Soporte predeterminado | OpenAI, Anthropic, Google, Cohere, Bedrock, Azure, HuggingFace, Ollama, vLLM, etc. (más de 100) | Solo la serie Anthropic Claude (Opus / Sonnet / Haiku) |
| Endpoints personalizados | ✅ Cualquier endpoint compatible con OpenAI | ⚠️ A través de ANTHROPIC_BASE_URL conectado a LiteLLM |
| Modelos locales/chinos | ✅ DeepSeek / Qwen / Kimi / GLM, etc. | ❌ No soportado por defecto |
Ten en cuenta que Claude Code también puede usar otros modelos "indirectamente" configurando ANTHROPIC_BASE_URL hacia un Proxy de LiteLLM, pero esto es esencialmente LiteLLM haciendo el trabajo de traducción, lo que demuestra que ambos son complementarios.
Diferencia 3: Interfaz de usuario y experiencia de desarrollo
Experiencia de desarrollo con LiteLLM:
- SDK para que los desarrolladores de aplicaciones escriban código.
- Se puede integrar en cualquier proyecto de Python.
- Proporciona endpoints HTTP compatibles con OpenAI para frontend, Node.js y cURL.
Experiencia de desarrollo con Claude Code:
- Una CLI independiente, similar al comando
claude. - Conversa directamente con tu base de código en la terminal.
- Incluye herramientas integradas para lectura/escritura de archivos, ejecución de Bash, Git, etc.
- Experiencia optimizada de uso de herramientas (Tool Use), "pensando mientras modifica".
Diferencia 4: Costes de despliegue y mantenimiento
| Proyecto | LiteLLM | Claude Code |
|---|---|---|
| Instalación | pip install litellm |
npm i -g @anthropic-ai/claude-code |
| ¿Requiere servicio? | Sí, en modo Proxy | No, es una CLI local |
| ¿Requiere configuración YAML? | Sí, en modo Proxy | Generalmente no |
| Uso compartido | ✅ Un servicio Proxy para todo el equipo | ❌ Una CLI por persona |
| Facturación centralizada | ✅ Facturación unificada en la capa de gateway | ❌ Facturación por cuenta individual |
Diferencia 5: Ecosistema y capacidad de extensión
Ecosistema de LiteLLM:
- Logging: Langfuse, Helicone, Sentry, OpenTelemetry.
- Guardrails: Moderación de contenido integrada.
- Routing: Balanceo de carga, Fallback, limitación de tasa (rate limiting).
- Seguimiento de costes: Por modelo, usuario y clave API.
Ecosistema de Claude Code:
- Hooks: Ganchos de comandos personalizados.
- MCP: Conexión a herramientas externas mediante el Protocolo de Contexto de Modelo (Model Context Protocol).
- Integración IDE: VS Code, JetBrains.
- Vinculación estrecha con las capacidades de invocación de herramientas de Anthropic.
¿LiteLLM soporta la facturación con caché de prompts?

Esta es una de las preguntas que más preocupan a los desarrolladores. Conclusión directa: Sí, es compatible y es una funcionalidad de primer nivel.
Matriz de soporte
La documentación oficial de LiteLLM indica claramente que el almacenamiento en caché de prompts (prompt caching) es compatible de forma nativa con los siguientes 6 proveedores principales:
| Proveedor | Prefijo LiteLLM | Método de activación | Ventaja de precio |
|---|---|---|---|
| Anthropic | anthropic/ |
Explícito cache_control: {"type": "ephemeral"} |
Escritura 1.25x, lectura 0.1x (90% de descuento) |
| OpenAI | openai/ |
Caché automático (>1024 tokens) | 50% de descuento automático |
| Google AI Studio | gemini/ |
Explícito cache_control |
Conversión automática a Context Caching API |
| Vertex AI | vertex_ai/ |
Explícito cache_control |
Igual que el anterior |
| Bedrock | bedrock/ |
Disponible si el modelo lo soporta | Según precio del modelo |
| DeepSeek | deepseek/ |
Caché automático | Descuento automático |
Ejemplo de código: Caché de Anthropic
import litellm
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Eres un ingeniero Python senior... (system prompt largo)",
"cache_control": {"type": "ephemeral"}, # Clave: marcar para caché
}
],
},
{"role": "user", "content": "Por favor, revisa este código"},
],
)
# El uso de caché es visible en response.usage
print(response.usage)
# {
# "prompt_tokens": 1234,
# "cache_creation_input_tokens": 800, # Tokens escritos en caché
# "cache_read_input_tokens": 0, # En la segunda llamada será 800
# "completion_tokens": 256,
# }
🎯 Consejo práctico: El almacenamiento en caché de prompts de Anthropic es extremadamente rentable en escenarios con system prompts largos y contextos repetitivos; la lectura de caché cuesta solo el 10% del precio original. Recomendamos activarlo por defecto en agentes de flujo largo, RAG (Generación Aumentada por Recuperación) y revisión de código. Si deseas invocar Claude Opus 4.6 / Sonnet 4.6 de forma estable y disfrutar del descuento de caché, puedes conectarte a través de APIYI (apiyi.com), ya que la plataforma transmite íntegramente los campos de uso relacionados con la caché.
Auto-Inject Cache Control (Caché automático)
Si no quieres añadir cache_control manualmente a cada mensaje, LiteLLM ofrece inyección automática:
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[...],
cache_control_injection_points=[
{"location": "message", "role": "system"} # Aplicar caché automáticamente a todos los mensajes system
],
)
Esto es muy útil para integrar código antiguo: sin necesidad de modificar la estructura de los mensajes, puedes disfrutar de un 90% de descuento en caché.
"Trampas" y estado actual de la facturación de caché
LiteLLM tuvo un error a principios de 2024 (GitHub Issue #5443): el seguimiento de costes no distinguía correctamente entre cache_creation_input_tokens y cache_read_input_tokens, lo que provocaba desviaciones en la facturación. Sin embargo, en las versiones de 2025-2026, esto ha sido corregido oficialmente. Actualmente, LiteLLM calcula los costes en la función completion_cost() siguiendo estas reglas:
| Tipo de Token | Multiplicador de precio (relativo al precio de entrada) | Nota |
|---|---|---|
| Escritura en caché | 1.25x | La escritura tiene un pequeño coste adicional |
| Lectura de caché | 0.1x | La lectura cuesta solo el 10% |
| Entrada normal | 1.0x | Entrada estándar |
| Salida | Definido por el modelo | Tokens de salida |
🛡️ Nota importante: Si utilizas un servicio proxy de API, asegúrate de que este transmita correctamente los campos
cache_creation_input_tokensycache_read_input_tokens. De lo contrario, LiteLLM calculará el coste como una entrada normal. APIYI (apiyi.com) ya soporta completamente la transmisión de estos campos, permitiéndote obtener el descuento real de caché al usarlo con LiteLLM.
title: "Guía de escenarios: ¿Cuándo usar LiteLLM y cuándo Claude Code?"
Guía de escenarios: ¿Cuándo usar LiteLLM y cuándo Claude Code?
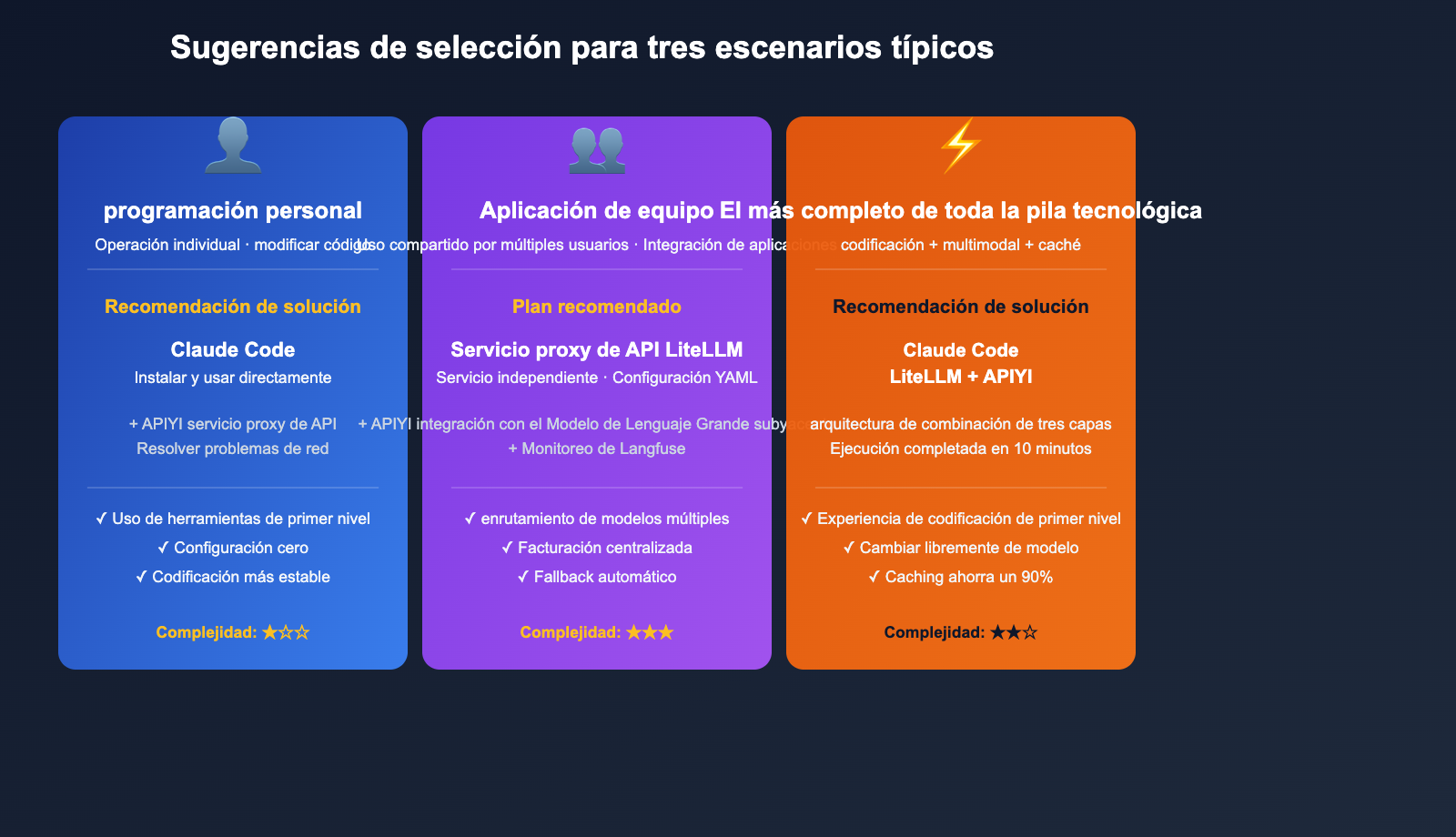
Escenario 1: Desarrollador individual, enfocado en programación
Recomendación: Usa Claude Code directamente.
La razón es sencilla: la experiencia de Claude en tareas de programación sigue siendo de primer nivel; el uso de herramientas es estable, las modificaciones de archivos son precisas y la gestión del contexto es excelente. Si trabajas solo y no necesitas cambiar de modelo, Claude Code es la opción más cómoda. Si tienes dificultades para acceder a la API oficial de Anthropic, puedes redirigir ANTHROPIC_BASE_URL al servicio proxy de API de APIYI (apiyi.com) para obtener una experiencia idéntica.
Escenario 2: Equipos que construyen aplicaciones de IA
Recomendación: LiteLLM Proxy + código de la aplicación.
Razón: Lo que necesitas es "facturación unificada + enrutamiento de múltiples modelos + Fallback", que es precisamente la capacidad central de LiteLLM Proxy. Claude Code es una herramienta CLI y no puede actuar como una puerta de enlace a nivel de aplicación.
Mejores prácticas:
- Ejecuta LiteLLM Proxy como un servicio independiente (puerto 4000).
- Conecta todos los modelos subyacentes de forma unificada a través de APIYI (apiyi.com).
- La capa de aplicación solo invoca a LiteLLM Proxy, utilizando nombres de modelos semánticos.
Escenario 3: Quieres la experiencia de Claude Code pero necesitas cambiar de modelo
Recomendación: Combinación de Claude Code + LiteLLM.
Esta es la combinación más potente. La configuración es muy sencilla:
# Iniciar LiteLLM Proxy (apuntando a múltiples modelos)
litellm --config litellm_config.yaml --port 4000
# Hacer que Claude Code pase a través de LiteLLM
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-litellm-master-xxxx
# Iniciar Claude Code con cualquier modelo
claude --model claude-opus-4-6
claude --model gpt-5 # La misma CLI, detrás está GPT-5
claude --model gemini-3-pro # La misma CLI, detrás está Gemini 3 Pro
💡 Valor de la combinación: Claude Code ofrece una experiencia de agente de programación de primer nivel, LiteLLM proporciona libertad de modelos y APIYI (apiyi.com) garantiza un servicio proxy de API estable. Los tres cumplen su función sin interferir entre sí, siendo la solución de "programación con IA full-stack" más pragmática para 2026.
Escenario 4: Despliegue de producción a nivel empresarial
Recomendación: LiteLLM Proxy + Langfuse + APIYI.
En entornos empresariales, Claude Code solo se utiliza como herramienta local para desarrolladores; el tráfico de producción real requiere:
- LiteLLM Proxy como puerta de enlace + limitación de tasa + Fallback.
- Langfuse / Helicone para registro (logging) y análisis de costes.
- APIYI (apiyi.com) para la conexión a modelos subyacentes y garantía de estabilidad.
Recomendaciones de decisión: LiteLLM vs Claude Code
La siguiente tabla de decisiones te ayudará a elegir la mejor opción en 30 segundos.
| Tus necesidades | Solución recomendada |
|---|---|
| Quiero que la IA modifique código en mi terminal | Claude Code |
| Quiero invocar múltiples modelos en aplicaciones Python | LiteLLM SDK |
| Mi equipo necesita un punto de entrada unificado para LLM | LiteLLM Proxy |
| Quiero cambiar el modelo subyacente de Claude Code | Claude Code + LiteLLM |
| Necesito una pasarela de LLM de nivel de producción | LiteLLM Proxy + monitoreo |
| El acceso a modelos extranjeros es inestable en mi región | Cualquiera + servicio proxy de API APIYI (apiyi.com) |
| Quiero ahorrar en tokens de Anthropic | LiteLLM + prompt caching |
🚀 Recomendación unificada: Independientemente de la herramienta que elijas, conectar la base a APIYI (apiyi.com) es la opción con mayor estabilidad. LiteLLM puede apuntar directamente a apiyi.com/v1 a través de
api_base, y Claude Code puede pasar indirectamente por LiteLLM hacia apiyi.com medianteANTHROPIC_BASE_URL. Ambas rutas han sido validadas por numerosos desarrolladores como estables y funcionales.
Preguntas frecuentes sobre LiteLLM vs Claude Code
Q1: ¿Puede LiteLLM reemplazar completamente a Claude Code?
No. LiteLLM es una pasarela de LLM y no cuenta con la cadena de herramientas de agente de Claude Code (leer tu repositorio, modificar archivos de forma autónoma, ejecutar Bash). Ambos resuelven problemas en niveles distintos; usar LiteLLM para reemplazar a Claude Code es como intentar usar una "fábrica de tuberías" para reemplazar una "cafetera".
Q2: ¿Puede Claude Code reemplazar completamente a LiteLLM?
Tampoco. Claude Code es una herramienta CLI, no una pasarela. No posee conceptos de nivel de pasarela como model_list, router_settings o fallbacks, y no puede ser invocado directamente por tu aplicación Python o servicio web. Si necesitas una "integración de IA a nivel de aplicación", Claude Code no te servirá.
Q3: ¿LiteLLM realmente admite la facturación de prompt caching de Anthropic?
Sí. Desde 2025, LiteLLM admite completamente cache_control: {"type": "ephemeral"}, la inyección automática de puntos de caché cache_control_injection_points, así como la transmisión de uso de cache_creation_input_tokens / cache_read_input_tokens y la facturación mediante completion_cost(). El error de cálculo de costos mencionado en el Issue #5443 ya ha sido corregido, por lo que puedes usarlo con total confianza en la versión actual.
Q4: ¿Cuánto dinero puedo ahorrar usando caché de Anthropic a través de LiteLLM?
Hasta un ~90%. Las reglas de precios de prompt caching de Anthropic son: el precio de escritura en caché es aproximadamente 1.25x el de entrada estándar, y el precio de lectura es aproximadamente 0.1x el de entrada estándar. En escenarios donde se reutilizan system prompts largos (como RAG, revisión de código o agentes de procesos largos), el ahorro real suele oscilar entre el 50% y el 90%. Si te conectas a través de APIYI (apiyi.com), este descuento por caché se reflejará íntegramente en tu factura.
Q5: ¿El rendimiento empeora si conecto Claude Code a GPT-5 mediante LiteLLM?
Habrá diferencias, pero no necesariamente empeorará. Las indicaciones de uso de herramientas (Tool Use) de Claude Code están optimizadas para Claude; al cambiar a GPT-5, el estilo de llamada a funciones y las acciones de edición de archivos podrían variar ligeramente. Se recomienda usar la serie Claude como modelo principal y otros modelos como respaldo para "inspiración o comparación". El mecanismo de respaldo (Fallback) de LiteLLM te permite degradar automáticamente a GPT-5 cuando Claude alcance sus límites de tasa.
Q6: ¿Cómo pueden los desarrolladores aprovechar al máximo Claude Code + LiteLLM + Anthropic Caching?
La solución más pragmática es una estructura de tres capas: Claude Code (CLI) → LiteLLM Proxy (puerto local 4000) → APIYI (apiyi.com) (servicio proxy). Claude Code apunta a LiteLLM a través de ANTHROPIC_BASE_URL, LiteLLM configura el modelo en el YAML como anthropic/claude-opus-4-6 y el api_base apunta a apiyi.com/v1. De esta manera, disfrutas de la experiencia de codificación de Claude Code, aprovechas la capacidad de enrutamiento de LiteLLM, resuelves problemas de red y facturación mediante APIYI, y conservas íntegramente el descuento por prompt caching.
Resumen
LiteLLM y Claude Code no son competidores, sino herramientas que operan en niveles de abstracción distintos: la "capa de puerta de enlace" (gateway) y la "capa de aplicación". Forzar una elección entre ambos es un falso dilema; la pregunta correcta es: ¿qué combinación se adapta mejor a tu escenario?
Volviendo a las dos preguntas iniciales de este artículo:
- ¿Cuál es mejor? — Depende del caso de uso. Para programación personal, usa Claude Code; para el desarrollo de aplicaciones, usa LiteLLM. Si necesitas ambos, utiliza la combinación de Claude Code + LiteLLM.
- ¿LiteLLM admite la facturación con caché? — Sí, cuenta con soporte completo que cubre a los 6 principales proveedores: Anthropic, OpenAI, Gemini, Vertex, Bedrock y DeepSeek, permitiendo ahorrar hasta un 90% en los costos de tokens de entrada.
🚀 Sugerencia de acción: Si hoy mismo quieres configurar un flujo de trabajo completo de "Claude Code + LiteLLM + Caching", el camino más rápido es: primero, regístrate en APIYI (apiyi.com) y obtén una clave API; segundo, configura un proxy local con LiteLLM y apunta el
api_baseaapiyi.com/v1; tercero, configura la variableANTHROPIC_BASE_URLen Claude Code para que apunte a tu instancia local de LiteLLM. Puedes tener todo el flujo funcionando en menos de 10 minutos y empezar a disfrutar de las ventajas de costos que ofrece el prompt caching.
Autor: Equipo de APIYI — Enfocados en proporcionar acceso estable a los principales Modelos de Lenguaje Grande para desarrolladores. Visita apiyi.com para más información.
Referencias
-
Documentación oficial de LiteLLM – Prompt Caching
- Enlace:
docs.litellm.ai/docs/completion/prompt_caching - Descripción: Matriz de soporte de caché para los 6 principales proveedores y ejemplos de código.
- Enlace:
-
Documentación oficial de LiteLLM – Auto-Inject Cache
- Enlace:
docs.litellm.ai/docs/tutorials/prompt_caching - Descripción: Inyección automática de
cache_control_injection_points.
- Enlace:
-
Documentación oficial de LiteLLM – Claude Code Quickstart
- Enlace:
docs.litellm.ai/docs/tutorials/claude_responses_api - Descripción: Configuración de
ANTHROPIC_BASE_URLy soporte para contexto de 1M.
- Enlace:
-
Documentación oficial de LiteLLM – Proveedor Anthropic
- Enlace:
docs.litellm.ai/docs/providers/anthropic - Descripción: Explicación de los campos
cache_creation_input_tokens/cache_read_input_tokens.
- Enlace:
-
GitHub Issue #5443 – Cálculo de costos de caché
- Enlace:
github.com/BerriAI/litellm/issues/5443 - Descripción: Historial de errores y correcciones en la facturación de caché.
- Enlace:
-
Repositorio principal de LiteLLM en GitHub
- Enlace:
github.com/BerriAI/litellm - Descripción: Código fuente, problemas (issues) y versiones más recientes.
- Enlace: