Nota del autor: Análisis profundo de las 5 razones principales por las que el consumo de tokens en OpenClaw (Open WebUI) es anormalmente alto, incluyendo llamadas a la API ocultas en segundo plano, acumulación del historial de chat, etc., y ofrece soluciones de configuración optimizadas de aplicación inmediata.
"Solo pregunté '¿qué modelo eres?' y ¿por qué el Prompt Token supera los 10,000?" Esta es una duda real de muchos usuarios de OpenClaw. En este artículo, analizaremos desde un nivel técnico la causa raíz del consumo excesivo de tokens en OpenClaw y ofreceremos 5 soluciones de optimización listas para usar.
Valor principal: Al leer este artículo, entenderás por qué el consumo de tokens de OpenClaw supera con creces las expectativas y dominarás métodos de configuración específicos para reducir los costos de tokens entre un 60% y un 80%.
Puntos clave del consumo de tokens en OpenClaw
| Punto clave | Descripción | Nivel de impacto |
|---|---|---|
| Llamadas ocultas en segundo plano | Cada mensaje activa de 4 a 5 llamadas independientes a la API | ⭐⭐⭐⭐⭐ Máximo |
| Acumulación del historial de chat | Cada ronda de diálogo reenvía todos los mensajes históricos | ⭐⭐⭐⭐ Alto |
| Modelos de tareas no separados | Las tareas en segundo plano usan por defecto el modelo principal | ⭐⭐⭐⭐ Alto |
| Inyección de indicaciones del sistema | Inyección automática de descripciones de herramientas y contexto RAG | ⭐⭐⭐ Medio |
| Bug de duplicación de indicaciones | Superposición de indicaciones del sistema durante llamadas a herramientas de Agente | ⭐⭐⭐ Medio |
La causa raíz del alto consumo de tokens en OpenClaw
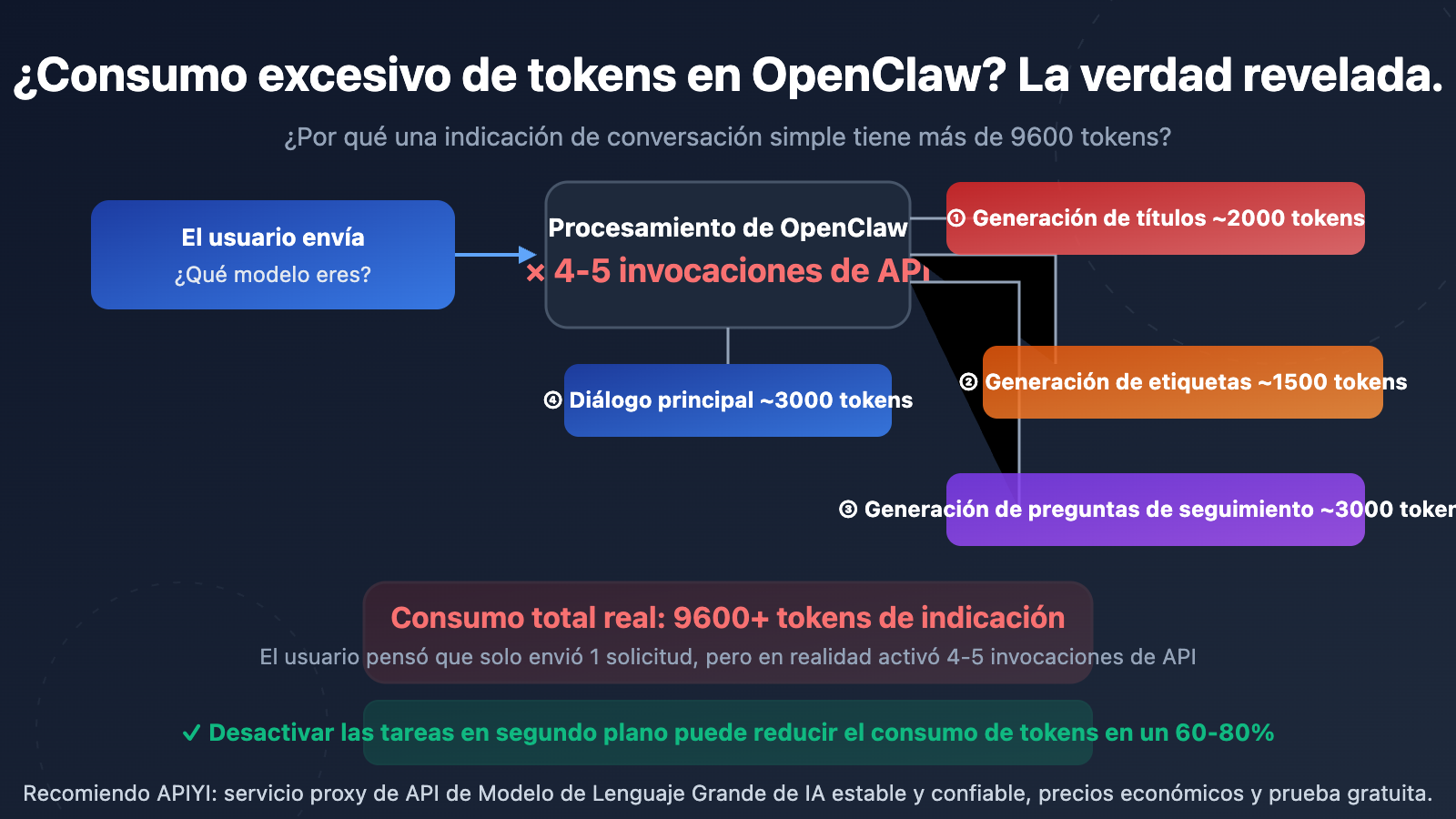
Muchos usuarios se sorprenden al ver las estadísticas de uso de la API: a pesar de haber hecho una pregunta tan simple como "¿qué modelo eres?", el Prompt Token llega a ser de 9,600 a 10,000+. Esto no es un problema de facturación del proveedor de la API, sino que se debe al diseño de la arquitectura de OpenClaw (Open WebUI).
La razón fundamental es: OpenClaw activa automáticamente múltiples llamadas a la API independientes en segundo plano cada vez que el usuario envía un mensaje. Estas llamadas son completamente invisibles para el usuario, pero cada una consume tokens reales.
Detalle de las 5 fuentes principales de consumo de tokens en OpenClaw
Fuente 1: Generación automática de títulos (Title Generation)
Después de que el usuario envía el primer mensaje, OpenClaw llama automáticamente a la API para generar un título de conversación de 3 a 5 palabras. Esta llamada envía el contenido del mensaje del usuario, consumiendo entre 1,500 y 2,000 Prompt Tokens.
Fuente 2: Generación automática de etiquetas (Tag Generation)
Al mismo tiempo, OpenClaw llama a la API para generar de 1 a 3 etiquetas de clasificación para la conversación. Esta es otra llamada independiente a la API que consume entre 1,000 y 1,500 Prompt Tokens.
Fuente 3: Sugerencia de preguntas de seguimiento (Follow-up Generation)
OpenClaw genera por defecto de 3 a 5 sugerencias de preguntas de seguimiento. Esta llamada utiliza la plantilla {{MESSAGES:END:6}}, que extrae los últimos 6 mensajes de la conversación como contexto, consumiendo entre 2,000 y 3,000 Prompt Tokens.
Fuente 4: Autocompletado (Autocomplete Generation)
Algunas versiones de OpenClaw también habilitan la función de autocompletado de entrada, prediciendo lo que el usuario podría escribir a continuación.
Fuente 5: La solicitud del chat principal
Finalmente, está la solicitud del chat principal que el usuario realmente ve, la cual incluye las indicaciones del sistema, el historial de chat y la entrada del usuario.
Guía rápida para optimizar el consumo de tokens en OpenClaw
Configuración minimalista: Desactivar tareas en segundo plano
Esta es la forma más rápida de optimizar: desactivar las llamadas a la API innecesarias en segundo plano mediante variables de entorno:
# Añade las variables de entorno en tu archivo docker-compose.yml
environment:
- ENABLE_TITLE_GENERATION=false
- ENABLE_TAGS_GENERATION=false
- ENABLE_FOLLOW_UP_GENERATION=false
- ENABLE_AUTOCOMPLETE_GENERATION=false
Ver los pasos completos para configurar mediante el panel de administración
Si no te resulta cómodo modificar las variables de entorno, también puedes realizar la configuración a través del panel de administración de OpenClaw:
- Inicia sesión en el panel de administración de OpenClaw.
- Ve a Settings → Tasks.
- Desactiva las siguientes opciones una por una:
- Title Generation (Generación de títulos) → Desactivar
- Tags Generation (Generación de etiquetas) → Desactivar
- Follow-up Generation (Generación de preguntas de seguimiento) → Desactivar
- Autocomplete Generation (Generación de autocompletado) → Desactivar
- Si no quieres desactivarlas por completo, puedes configurar el Task Model con un modelo económico (como
gpt-4o-mini). - Guarda los cambios y actualiza la página.
# Opción 2: No desactivar las funciones, pero usar un modelo económico para las tareas en segundo plano
environment:
- TASK_MODEL_EXTERNAL=gpt-4o-mini
De esta manera, las tareas en segundo plano seguirán funcionando (los títulos, etiquetas y preguntas de seguimiento se generarán automáticamente), pero utilizando un modelo de menor precio en lugar del modelo de chat principal que hayas elegido.
🎯 Sugerencia de optimización: Desactivar las tareas en segundo plano es el método más directo para reducir el consumo de tokens en OpenClaw. Si utilizas la API a través de APIYI (apiyi.com), estas optimizaciones reducirán significativamente tus costos de uso. APIYI ofrece una interfaz unificada para múltiples modelos, lo que facilita la configuración de diferentes Task Models.
Análisis de datos reales del consumo de tokens en OpenClaw
A continuación, se presentan datos reales de consumo de tokens reportados por usuarios, donde se puede apreciar claramente la gravedad del problema:
| Escenario de uso | Consumo de tokens esperado | Consumo de tokens real | Multiplicador |
|---|---|---|---|
| Pregunta simple "¿Qué modelo eres?" | ~200 | 9,600-10,269 | 50x |
| 5 rondas de conversación diaria | ~3,000 | ~45,000 | 15x |
| 30 rondas de conversación de programación | ~12,000 | 1,860,000 | 155x |
| Conversación tras subir un documento | ~5,000 | 600,000+ | 120x |
Los datos de la tabla anterior provienen de comentarios reales de usuarios en la comunidad de GitHub de Open WebUI. El caso extremo de 155 veces en 30 rondas de programación se debe principalmente a que la plantilla de generación de preguntas de seguimiento {{MESSAGES:END:6}} extrae los últimos 6 mensajes, y en las conversaciones de programación, un solo mensaje suele contener una gran cantidad de código.
Efecto acumulativo de las rondas de conversación en el consumo de tokens de OpenClaw
| Ronda de conversación | Consumo con configuración predeterminada | Consumo optimizado | Proporción de ahorro |
|---|---|---|---|
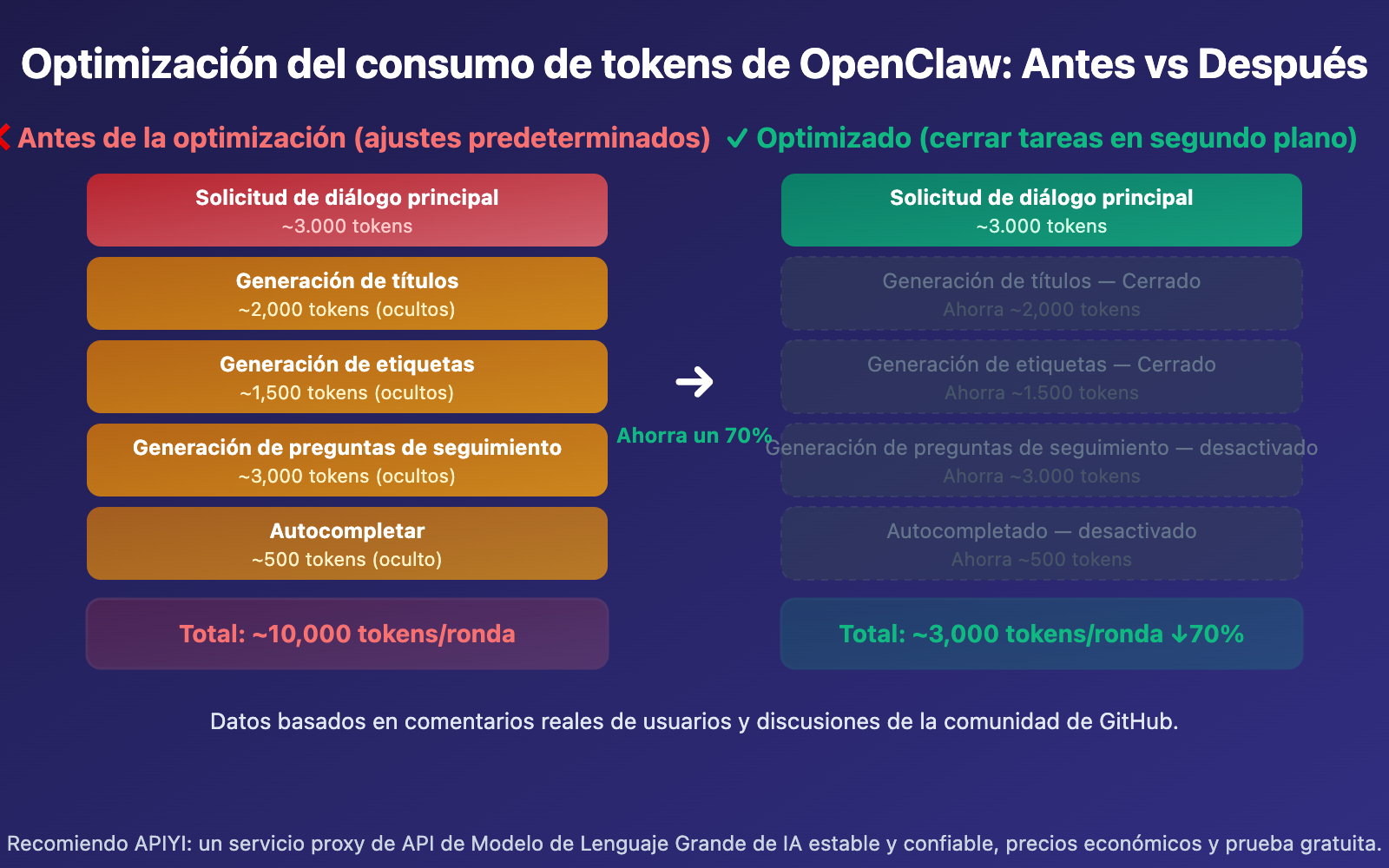
| Ronda 1 | ~10,000 | ~3,000 | 70% |
| Ronda 5 | ~50,000 | ~15,000 | 70% |
| Ronda 10 | ~150,000 | ~45,000 | 70% |
| Ronda 20 | ~500,000 | ~150,000 | 70% |
| Ronda 30 | ~1,200,000 | ~360,000 | 70% |
A medida que aumenta el número de rondas de conversación, el consumo de tokens crece de forma exponencial. Esto se debe a que en cada ronda se vuelve a enviar el historial completo de la conversación. Con la configuración predeterminada, este historial no solo se envía una vez en la conversación principal, sino que también se envía para la generación de títulos, etiquetas y preguntas de seguimiento.
🎯 Sugerencia de control de costos: En escenarios de conversaciones largas, el crecimiento del consumo de tokens es especialmente alarmante. Recomendamos realizar la invocación del modelo a través de APIYI (apiyi.com); la plataforma ofrece un panel detallado de estadísticas de uso para que puedas monitorear y optimizar tu consumo de tokens.
Comparativa de estrategias de optimización de consumo de tokens en OpenClaw

| Estrategia de optimización | Dificultad | Ahorro de Tokens | Impacto en funciones | Recomendación |
|---|---|---|---|---|
| Desactivar preguntas de seguimiento | Fácil | ~30% | No muestra preguntas sugeridas | ⭐⭐⭐⭐⭐ |
| Configurar modelo de tareas económico | Fácil | Coste de tareas baja 90% | Funciones intactas | ⭐⭐⭐⭐⭐ |
| Desactivar generación de títulos/etiquetas | Fácil | ~25% | Nombramiento manual de chats | ⭐⭐⭐⭐ |
| Mover RAG a la indicación del sistema | Media | Habilita caché | Sin impacto negativo | ⭐⭐⭐⭐ |
| Filtro de longitud de contexto | Media | Controla coste de chats largos | Posible pérdida de contexto previo | ⭐⭐⭐ |
🎯 Mejor práctica: Si no quieres perder ninguna funcionalidad, la Opción 2 (configurar un modelo de tareas económico) es la mejor elección. Las tareas en segundo plano siguen funcionando, pero utilizando modelos de bajo coste como
gpt-4o-mini. A través de APIYI (apiyi.com), puedes gestionar fácilmente las claves API de varios modelos; con una sola clave puedes invocar todos los modelos principales.
Preguntas frecuentes
P1: ¿Por qué el consumo de tokens en OpenClaw es tan diferente al de ChatGPT oficial?
ChatGPT oficial funciona mediante suscripción y no factura por token, por lo que no percibes el consumo. OpenClaw, en cambio, utiliza invocaciones de API donde cada token tiene un coste. Además, OpenClaw tiene tareas en segundo plano activadas por defecto, lo que hace que el consumo real sea entre 3 y 5 veces superior a las solicitudes visibles del usuario.
P2: ¿Se normalizará el consumo de tokens en OpenClaw tras desactivar las tareas en segundo plano?
Sí. Al desactivar la generación de títulos, etiquetas, preguntas de seguimiento y el autocompletado, cada mensaje solo activará una invocación de API (la conversación principal), reduciendo el consumo de tokens entre un 60% y un 80%. Si prefieres mantener estas funciones, puedes configurar un modelo económico (como gpt-4o-mini) específicamente para estas tareas a través de la plataforma APIYI (apiyi.com).
P3: ¿Cómo puedo monitorizar el consumo real de tokens en OpenClaw?
Te recomendamos las siguientes formas de monitorizar el consumo:
- Consulta el panel de estadísticas de uso en APIYI (apiyi.com) para ver los datos detallados de tokens de cada invocación de API.
- Revisa las estadísticas en la página "Usage" del panel de administración de OpenClaw.
- Presta atención a la proporción entre Prompt Tokens y Completion Tokens: si los del Prompt son muy superiores, significa que las tareas en segundo plano están consumiendo demasiado.
Resumen
Puntos clave sobre el alto consumo de tokens en OpenClaw:
- Las llamadas ocultas en segundo plano son la causa principal: Cada mensaje activa de 4 a 5 llamadas API independientes, aunque el usuario solo vea una.
- Configurar un modelo de tareas económico es la mejor solución: Usar
TASK_MODEL_EXTERNAL=gpt-4o-minipermite reducir el costo de las tareas en segundo plano en un 90% manteniendo la funcionalidad. - Especial atención a las conversaciones largas: El historial de chat se reenvía en cada llamada; una conversación de 30 rondas puede alcanzar más de 1 millón de tokens.
Con estos trucos de optimización, puedes reducir los costos de tokens de OpenClaw entre un 60% y un 80%, haciendo que el uso de la API sea mucho más rentable.
Te recomendamos gestionar tus invocaciones del modelo a través de APIYI (apiyi.com). La plataforma ofrece una interfaz unificada y estadísticas detalladas de uso para ayudarte a controlar con precisión el consumo de tokens y los costos.
📚 Referencias
-
Discusión sobre el consumo de tokens en Open WebUI: Debate en la comunidad de GitHub sobre el alto consumo de tokens.
- Enlace:
github.com/open-webui/open-webui/discussions/7281 - Descripción: Varios usuarios comparten datos reales de consumo de tokens y sus experiencias de optimización.
- Enlace:
-
Documentación de configuración de variables de entorno de Open WebUI: Referencia oficial para la configuración de variables de entorno.
- Enlace:
docs.openwebui.com/reference/env-configuration - Descripción: Incluye todas las variables de entorno configurables y sus valores predeterminados.
- Enlace:
-
Problemas de consumo de tokens en la generación de preguntas de seguimiento (Follow-up): La generación de preguntas de seguimiento consume el contexto completo.
- Enlace:
github.com/open-webui/open-webui/issues/15081 - Descripción: Análisis detallado de cómo las plantillas de generación de preguntas de seguimiento consumen grandes cantidades de tokens.
- Enlace:
-
Bug de duplicación de indicaciones del sistema: Las llamadas a herramientas agénticas provocan la superposición de indicaciones del sistema.
- Enlace:
github.com/open-webui/open-webui/issues/19169 - Descripción: Problema conocido que requiere especial atención al usar funciones de llamada a herramientas.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a debatir en la sección de comentarios. Para más información, visita el centro de documentación de APIYI en docs.apiyi.com.