ملاحظة من المؤلف: نستعرض في هذا المقال القيمة العملية لنموذج gpt-image-2 عبر 6 مجالات عمل رئيسية: التجارة الإلكترونية، تصميم واجهة وتجربة المستخدم (UI/UX)، الإعلانات، القصص المصورة (Storyboard)، وكلاء المطورين (Developer Agents)، وتوطين المحتوى، وذلك لمساعدة الفرق على تخطيط مسار التنفيذ بعد إتاحة واجهة البرمجة (API).
إذا كنت تستخدم أدوات توليد الصور بالذكاء الاصطناعي بانتظام، فربما لاحظت أن هناك فئة من الاحتياجات تظل "عالقة" باستمرار؛ مثل صور المنتجات التي تحتوي على نصوص مكتوبة بشكل خاطئ، أو المواد الإعلانية التي تتطلب إصلاحاً يدوياً للنصوص، أو صعوبة إنشاء نسخ محلية بلغات متعددة دفعة واحدة. هذه الاحتياجات ليست مشكلة في قدرات النموذج، بل هي سقف طموح نماذج الصور المبكرة في مجالات دقة عرض النصوص، الدقة العالية، والمعرفة العامة بالعالم.
قد يبدو هذا كأنه مشكلة قديمة، لكن gpt-image-2 يعمل على كسر هذه الحواجز بشكل منهجي. سنقوم في هذا المقال بتفكيك سيناريوهات تطبيق gpt-image-2، بدءاً من سير العمل الفعلي في 6 مجالات تجارية، وصولاً إلى طرق الربط عبر API، وما يعنيه ذلك لفريقك.
القيمة الجوهرية: من السيناريوهات إلى كود التنفيذ، ستفهم بعد قراءة هذا المقال أي الأعمال ستستفيد أولاً من gpt-image-2، وستعرف كيفية دمجه في خطوط العمل الحالية فور إتاحة الـ API.

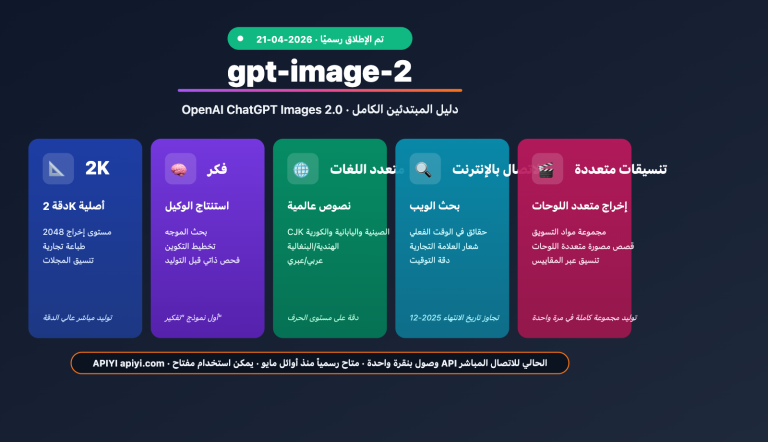
النقاط الجوهرية لحالات استخدام gpt-image-2
| حالة الاستخدام | القيمة الجوهرية | عيوب النماذج القديمة |
|---|---|---|
| التجارة الإلكترونية وتصوير المنتجات | صور منتجات بدقة 4K + نصوص تغليف دقيقة | أخطاء في الملصقات، دقة منخفضة |
| نماذج UI/UX الأولية | إنتاج نماذج عالية الدقة في ثوانٍ | تداخل نصوص الأزرار والأيقونات |
| الإعلانات والرؤية البصرية | خطوط تجارية جاهزة للنشر + دقة 4K | الحاجة لتعديل الرؤية البصرية بـ Photoshop |
| لوحات القصة (Storyboard) | تكرار في 3 ثوانٍ + معرفة عالمية | تكلفة عالية لإعادة رسم المشاهد |
| خطوط أنابيب وكيل المطورين | تكامل مباشر دون تعديل SDK | صعوبة الأتمتة بسبب عدم استقرار التوليد |
| توطين المحتوى | دعم متزامن للغات CJK/RTL/اللاتينية | الحاجة لتنسيق يدوي للغات غير الإنجليزية |
القواسم المشتركة لحالات الاستخدام
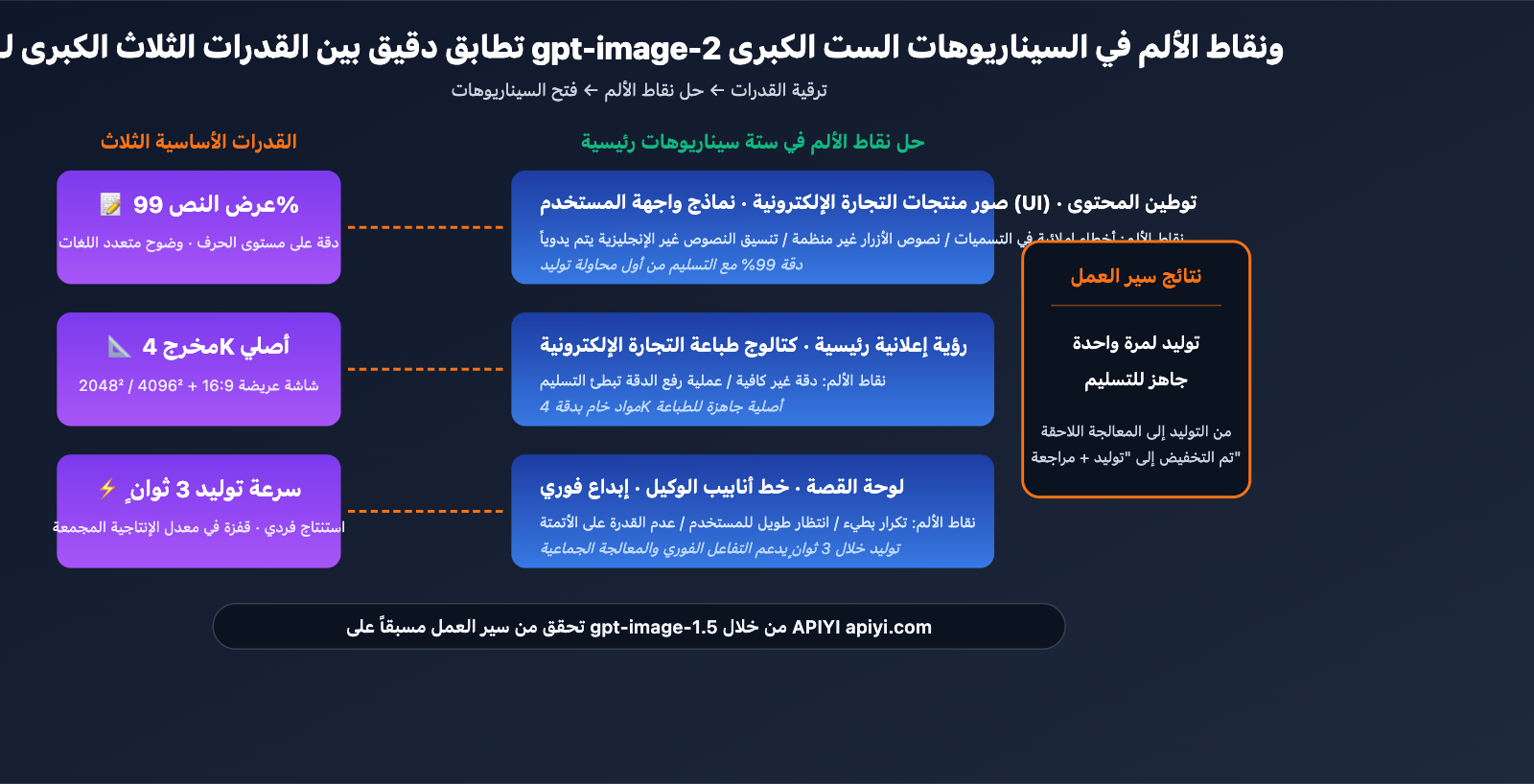
القاسم المشترك بين هذه السيناريوهات الستة: كانت سير العمل تعاني سابقاً من "عقبات النماذج القديمة في عرض النصوص، الدقة، والمعرفة العالمية"، بينما تتصدى القدرات الثلاث الرئيسية لـ gpt-image-2 (دقة نصوص بنسبة 99%، مخرجات بدقة 4K أصلية، وسرعة توليد خلال 3 ثوانٍ) لهذه الاختناقات بدقة متناهية.
ماذا يعني هذا: كانت هذه السيناريوهات تتطلب سابقاً سير عمل من مرحلتين: توليد بالذكاء الاصطناعي + معالجة يدوية لاحقة. أما مع gpt-image-2، فقد أصبح من الممكن التسليم من خلال توليد واحد فقط، حيث يتحول التدخل البشري من "إصلاح" إلى "مراجعة". سيشهد إنتاج الصور داخل الفرق قفزة نوعية في الكفاءة.
gpt-image-2 سيناريو التطبيق الأول: التجارة الإلكترونية وتصوير المنتجات
وصف السيناريو
أكبر تحدٍ يواجه فرق التجارة الإلكترونية هو اتساق العلامة التجارية في صور المنتجات الضخمة: فكل منتج يحتاج إلى عشرات الصور من نوع A+ (صور العرض، صور نمط الحياة، صور التفاصيل، صور المناسبات). في السابق، كان الخيار إما الاستعانة بمصورين محترفين أو الاعتماد على الذكاء الاصطناعي مع الاضطرار لتعديل الملصقات ونصوص التغليف مراراً وتكراراً.
كيف يعيد gpt-image-2 صياغة هذا المجال
- ملصقات مقروءة وتغليف دقيق: بفضل دقة النصوص التي تصل إلى 99%، يتم إنشاء أسماء المنتجات، والمواصفات، وملصقات المكونات بشكل صحيح من المرة الأولى.
- مشاهد واقعية للعرض: المعرفة العالمية للنموذج تجعل الخلفيات (مقاهي، مطابخ، مكاتب) متوافقة مع هوية العلامة التجارية الحقيقية.
- دقة 4K جاهزة للطباعة: المخرجات الفردية يمكن استخدامها مباشرة في كتالوجات الطباعة ومحتوى A+ على منصات التجارة الإلكترونية، مما يوفر الحاجة لخطوات رفع الدقة الإضافية.
مقارنة سير العمل
| الخطوة | الذكاء الاصطناعي التقليدي | سير عمل gpt-image-2 |
|---|---|---|
| إنتاج صورة رئيسية واحدة | 3-5 محاولات + تعديل النصوص بـ PS | إنشاء من المرة الأولى |
| إنشاء 20 نسخة متنوعة | حوالي 2-3 ساعات | حوالي 10 دقائق |
| دقة بجودة الطباعة | تتطلب برمجيات رفع الدقة | دقة 4K أصلية مباشرة |
| دقة ملصقات العلامة التجارية | تتطلب مراجعة يدوية | دقة تلقائية تصل لـ 99% |
نصيحة للمستخدمين: يمكن لفرق التجارة الإلكترونية الوصول إلى gpt-image-1.5 مسبقاً عبر خدمة وكيل API من APIYI (apiyi.com)، للتعرف على هيكلية الاستدعاء الجماعي، وعند إطلاق gpt-image-2، ما عليك سوى استبدال حقل
modelللاستمتاع بترقية مزدوجة: دقة 4K ودقة نصوص تصل إلى 99%.
gpt-image-2 سيناريو التطبيق الثاني: نماذج واجهة المستخدم (UI / UX)
وصف السيناريو
يحتاج مديرو المنتجات والمصممون في المراحل المبكرة إلى عرض نماذج أولية (Mockups) عالية الدقة لواجهات التطبيقات أمام أصحاب المصلحة. البدء من الصفر على Figma يستغرق ساعات، بينما الاستعانة بمصممين خارجيين تزيد من تكاليف التواصل. في السابق، كانت النماذج التي تولدها نماذج الصور تعاني من نصوص أزرار مشوشة وأيقونات غير متناسقة، مما يجعلها غير قابلة للاستخدام تقريباً.
كيف يعيد gpt-image-2 صياغة هذا المجال
- إنتاج نماذج عالية الدقة في ثوانٍ: إنشاء خلال 3 ثوانٍ مع نصوص دقيقة تجعل المسودات الأولية "جاهزة للاستخدام فوراً".
- دقة عالية في النصوص والأيقونات وهيكل التخطيط: نصوص الأزرار، تسميات التنقل، وجداول البيانات تظهر بوضوح تام.
- الحصول على موافقة أصحاب المصلحة قبل فتح Figma: تقليص كبير في دورة اتخاذ القرار بشأن المنتج.
مثال على موجه (Prompt) نموذجي
A modern mobile banking app dashboard screen,
- Top navigation: "Accounts · Transfer · Pay · Invest"
- Account card showing balance "$12,847.50" with "Main Checking"
- Transaction list with 3 items: "Starbucks -$5.40", "Salary +$4,200", "Netflix -$15.99"
- Bottom tab bar: Home, Cards, Rewards, Settings
iOS-style, light mode, Apple system font
بعد إدخال هذا الموجه إلى gpt-image-2، ستظهر النصوص المذكورة أعلاه في لقطة الشاشة بدقة حرفية — وهو أمر لم تكن تستطيع القيام به أي من نماذج الصور السابقة.
gpt-image-2 سيناريو التطبيق الثالث: الإعلانات والرؤية البصرية الرئيسية
وصف السيناريو
يجب أن تلبي المواد البصرية الرئيسية لفرق التسويق (الملصقات، لافتات الويب Banner، أغلفة وسائل التواصل الاجتماعي) جودة مستوى النشر: خطوط العلامة التجارية صحيحة، دمج المنتج بشكل طبيعي، وإضاءة المشهد متقنة. تتطلب العمليات التقليدية تعاون المصور + خبير تعديل الصور + المصمم لعدة أيام.
كيف يعيد gpt-image-2 صياغة هذا المجال
- خطوط العلامة التجارية الصحيحة: دقة تصل إلى 99% تعني أن الشعارات، أسماء المنتجات، ونصوص أزرار الدعوة لاتخاذ إجراء (CTA) تظهر بشكل صحيح من المرة الأولى.
- دمج المنتج بشكل طبيعي: بفضل المعرفة العالمية، يظهر المنتج في سيناريوهات استهلاكية واقعية، بعيداً عن الصور المركبة التي تبدو "معلقة" أو غير واقعية.
- إضاءة مشهد متقنة: التحسن في الواقعية يجعل الصور الشخصية، وتفاصيل اليد، والانعكاسات تتوافق مع إضاءة التصوير الفوتوغرافي الحقيقية.
- مخرجات بدقة 4K تغني عن "الإصلاح بالتكبير": يمكن حذف خطوة "الرفع الفائق للدقة" (Upscaling) التي كانت ضرورية في معظم مسارات العمل التسويقية سابقاً.
أنواع الإعلانات الأكثر استفادة
| نوع الإعلان | قيمة gpt-image-2 |
|---|---|
| منشورات التواصل الاجتماعي | صور مربعة 1:1 + دقة نصوص CTA |
| صور مصغرة لـ YouTube | دقة أصلية 16:9 + وضوح عالٍ على شاشات 4K |
| إعلانات خارجية/LED | مخرجات مباشرة بدقة 4096×4096 للشاشات الكبيرة |
| الملصقات المطبوعة | دعم دقة 4K الأصلية للطباعة بمقاسات A3/A2 |
| ترويسة البريد الإلكتروني | تكرار سريع لإصدارات متعددة لاختبارات AB |
نصيحة الربط: يُنصح باستخدام واجهة APIYI (apiyi.com) الموحدة لمسارات العمل الإبداعية الإعلانية. عند إطلاق gpt-image-2، لن تحتاج إلى تعديل كود العمل الخاص بك، يكفي فقط تبديل اسم النموذج.
gpt-image-2 سيناريو التطبيق الرابع: لوحة القصة (Storyboard) والإنتاج الأولي
وصف السيناريو
يحتاج مخرجو الأفلام، ومديرو الإبداع الإعلاني، وصناع الرسوم المتحركة إلى تكرار لوحات القصة (Storyboard) بسرعة في مرحلة ما قبل الإنتاج. العملية التقليدية تعتمد على قيام الرسامين بالرسم اليدوي بناءً على السيناريو، حيث يستغرق التعديل الواحد ساعات؛ وحتى مع مساعدة الذكاء الاصطناعي، كانت النماذج السابقة تفتقر إلى الاستقرار في "اتساق الشخصيات" و"دقة المشهد".
كيف يعيد gpt-image-2 صياغة هذا المجال
- تكرار سريع للوحات القصة: سرعة توليد تصل إلى 3 ثوانٍ تتيح للمخرج تعديل إيقاع اللقطات في الوقت الفعلي، ومناقشة التفاصيل وجهاً لوجه مع كاتب السيناريو أو العميل.
- إصابة إيقاع اللقطة، المشهد، أو وضعية الشخصيات: المعرفة العالمية تجعل المشاهد المركبة مثل "مرآب سيارات تحت الأرض + ليلة ممطرة + بطل يقف تحت عمود إنارة" تظهر بدقة من المرة الأولى.
- تكلفة إعادة محاولة أقل: انخفاض عدد المحاولات من متوسط 5-6 مرات للحصول على صورة قابلة للاستخدام، إلى 1-2 مرة فقط.
تغيرات مسار العمل
مسار عمل لوحة القصة التقليدي:
السيناريو ← رسم يدوي ← مراجعة المخرج ← تعديل ← إعادة رسم (دورة من 3-5 مرات)
الوقت المستغرق: 1-2 أسبوع / حلقة
مسار عمل بمساعدة gpt-image-2:
السيناريو ← توليد عبر gpt-image-2 (3 ثوانٍ) ← تعديل الموجه (prompt) من قبل المخرج فوراً ← اعتماد النسخة النهائية
الوقت المستغرق: 1-2 يوم / حلقة
كفاءة العائد: يمكن ضغط دورة الإنتاج الأولي بنسبة تزيد عن 80%، مما يتيح وقتاً إضافياً لتصميم لقطات أكثر دقة. يُنصح بمعالجة لوحات القصة للحلقة كاملة عبر واجهات الربط الجماعي في APIYI (apiyi.com).
gpt-image-2 سيناريوهات التطبيق الخامسة: أدوات المطورين وخطوط أنابيب الوكيل (Agent)

وصف السيناريو
تحتاج المزيد والمزيد من منتجات الذكاء الاصطناعي إلى توليد محتوى مرئي ديناميكي: وكلاء (Agents) التعليم الذين ينشئون لقطات شاشة تعليمية، وكلاء الألعاب الذين ينشئون مفاهيم المشاهد، ووكلاء المستندات الذين ينشئون صوراً توضيحية. في السابق، كان دمج نماذج الصور يتطلب تعديل حزم تطوير البرمجيات (SDK)، والتعامل مع حسابات متعددة لموردين مختلفين، والتعامل مع هياكل API متنوعة.
كيف يعيد gpt-image-2 صياغة المشهد
- لا حاجة لتعديل SDK، اتصال مباشر بالتكاملات الحالية: هيكل معلمات API متوافق تماماً مع gpt-image-1.5.
- مناسب للوكلاء الذين يحتاجون إلى عرض واجهات المستخدم، أو مواد تعليمية، أو محتوى مرئي عند الطلب داخل منتجات المستخدم.
- متوافق أصلاً مع OpenAI Agents SDK و AgentKit: يمكن لـ Function Calling (استدعاء الوظائف) تشغيل توليد الصور مباشرة.
مثال مبسط لخط أنابيب الوكيل (Agent Pipeline)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def agent_generate_image(scene_description: str) -> str:
"""أداة الوكيل: توليد صور المشاهد عند الطلب"""
response = client.images.generate(
model="gpt-image-1.5", # استبدله بـ "gpt-image-2" بعد الإطلاق
prompt=scene_description,
size="1024x1024",
quality="high"
)
return response.data[0].url
image_url = agent_generate_image(
"Step 3 of the tutorial: user clicks 'Connect API Key' button in settings"
)
عرض كود التكامل الكامل للوكيل (يتضمن Function Calling)
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
tools = [{
"type": "function",
"function": {
"name": "generate_image",
"description": "توليد صورة لخطوة تعليمية حالية",
"parameters": {
"type": "object",
"properties": {
"prompt": {"type": "string", "description": "وصف الصورة"},
"size": {"type": "string", "enum": ["1024x1024", "1536x1024"]}
},
"required": ["prompt"]
}
}
}]
def generate_image(prompt: str, size: str = "1024x1024") -> str:
response = client.images.generate(
model="gpt-image-1.5",
prompt=prompt,
size=size,
quality="high"
)
return response.data[0].url
messages = [{"role": "user", "content": "إنشاء صورة تعليمية لإعداد مفتاح API"}]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools
)
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
image_url = generate_image(**args)
print(f"الوكيل أنتج الصورة: {image_url}")
نصيحة للمطورين: استخدم APIYI (apiyi.com) للاتصال الموحد بنظام OpenAI البيئي، حيث يكفي مفتاح API واحد لاستدعاء gpt-image-2 و GPT-4o وجميع النماذج الأخرى، مما يغنيك عن صيانة حسابات موردين متعددين.
gpt-image-2 سيناريو التطبيق السادس: توطين المحتوى
وصف السيناريو
تتمثل نقطة الألم الأساسية للعلامات التجارية العالمية والتجارة الإلكترونية العابرة للحدود في أن فكرة إبداعية واحدة تحتاج إلى تغطية أسواق متعددة اللغات: الإنجليزية، الصينية (المبسطة والتقليدية)، اليابانية، الكورية، العربية، الإسبانية، إلخ. في الماضي، كانت النصوص غير الإنجليزية التي يتم إنشاؤها بواسطة الذكاء الاصطناعي غالبًا ما تظهر بشكل مشوه، مما كان يضطر فرق التوطين إلى إعادة تنسيقها يدويًا واحدة تلو الأخرى.
كيف يعيد gpt-image-2 صياغة العملية
- إمكانية إنشاء نسخ CJK (الصينية واليابانية والكورية)، وRTL (من اليمين لليسار)، واللاتينية لنفس الفكرة في وقت واحد: يكفي استخدام موجه واحد + معلمات اللغة للحصول على المخرجات بجميع اللغات.
- لا حاجة للتنسيق اليدوي: يتم اختصار عملية عرض النصوص متعددة اللغات من أيام إلى دقائق.
- تقليص دورة التوطين بشكل كبير: التحول من العملية الخطية "اعتماد النسخة الإنجليزية ← انتظار الترجمة ← إعادة التصميم اليدوي" إلى عملية دفع متوازية.
مقارنة كفاءة التوطين
| نوع المحتوى | التوطين التقليدي | توطين gpt-image-2 |
|---|---|---|
| تصميم تغليف المنتج | 5-7 أيام/لغة | 10 دقائق/لغة |
| إعلانات وسائل التواصل | 2-3 أيام/لغة | 5 دقائق/لغة |
| لقطات الشاشة التعليمية | 1-2 يوم/لغة | 3 دقائق/لغة |
| ترويسة البريد الإلكتروني | نصف يوم/لغة | 2 دقيقة/لغة |
مثال على الإنشاء الجماعي متعدد اللغات
languages = {
"en": "Summer Sale — Up to 50% Off",
"zh": "夏季特惠 — 低至 5 折",
"ja": "サマーセール — 最大 50% オフ",
"ar": "تخفيضات الصيف — خصم حتى 50%"
}
# حلقة تكرارية لإنشاء الصور لكل لغة
for lang, slogan in languages.items():
prompt = f"E-commerce hero banner, product showcase with slogan '{slogan}', modern style"
url = generate_image(prompt, size="1536x1024")
print(f"[{lang}] {url}")
نصيحة فريق التوطين: يمكنك معالجة المواد متعددة اللغات بشكل جماعي من خلال الواجهة الموحدة لـ APIYI (apiyi.com)، حيث توفر المنصة رصيد اختبار مجاني للتحقق من جودة عرض النصوص بمختلف اللغات.
مقارنة حلول سيناريوهات تطبيق gpt-image-2
| السيناريو | أولوية الإطلاق | العائد المتوقع على الاستثمار (ROI) | تعقيد الربط |
|---|---|---|---|
| صور منتجات التجارة الإلكترونية | ⭐⭐⭐⭐⭐ | مرتفع (توفير تكاليف التصوير) | منخفض |
| نماذج UI/UX الأولية | ⭐⭐⭐⭐⭐ | مرتفع (تقليص دورة اتخاذ القرار) | منخفض |
| الإعلانات المرئية | ⭐⭐⭐⭐ | مرتفع (توفير تكاليف ما بعد الإنتاج) | متوسط |
| إنتاج لوحات القصة (Storyboard) | ⭐⭐⭐ | متوسط (كفاءة إبداعية) | منخفض |
| خط أنابيب الوكيل (Agent) | ⭐⭐⭐⭐ | متوسط (تحويل المنتج) | متوسط |
| توطين المحتوى | ⭐⭐⭐⭐⭐ | مرتفع جداً (من أيام إلى دقائق) | متوسط |
توصيات اتخاذ القرار بشأن الأولويات
التخطيط للإطلاق الفوري (يمكن التبديل في يوم الإصدار): صور منتجات التجارة الإلكترونية، نماذج UI/UX الأولية، وتوطين المحتوى؛ حيث تعتمد هذه الفئات الثلاث بشكل أكبر على الترقيات الأساسية الثلاث لـ gpt-image-2 (النصوص/دقة 4K/تعدد اللغات).
الترحيل متوسط المدى (مراقبة لمدة 2-4 أسابيع): الإعلانات المرئية، وخط أنابيب الوكيل؛ يُنصح بالانتظار حتى استقرار واجهة برمجة التطبيقات (API) وتحديد قيود السرعة بوضوح قبل الإطلاق على نطاق واسع.
الاستكشاف القائم على الفرص: إنتاج لوحات القصة؛ مناسب للفرق الصغيرة والمبدعين المستقلين، حيث تكون مقاومة تغيير سير العمل التقليدي أقل.
ملاحظة القرار: تعتمد الأولوية المحددة على هيكل فريقك وإيقاع عملك. يُنصح بتجربة gpt-image-1.5 أولاً عبر APIYI (apiyi.com)، وتقييم العائد على الاستثمار باستخدام بيانات عمل حقيقية قبل اتخاذ قرار بشأن حجم الاستثمار بعد إصدار gpt-image-2.
الأسئلة الشائعة (FAQ)
س1: ما هي أفضل سيناريوهات التطبيق لنموذج gpt-image-2؟
هناك 6 سيناريوهات رئيسية لها الأولوية القصوى: صور منتجات التجارة الإلكترونية (بدقة 4K + تسميات دقيقة)، نماذج واجهة المستخدم/تجربة المستخدم (نماذج أولية عالية الدقة)، الرؤية البصرية للإعلانات (جودة جاهزة للنشر)، لوحات القصة (تكرار سريع)، خطوط أنابيب وكلاء المطورين (بدون الحاجة لتعديل SDK)، وتوطين المحتوى (توليد متعدد اللغات في خطوة واحدة). القاسم المشترك هو أن النماذج السابقة كانت مقيدة بمشكلات في النص/الدقة/المعرفة بالعالم، بينما يعالج gpt-image-2 هذه النقاط الثلاث بشكل منهجي.
س2: متى يجب على فرق التجارة الإلكترونية البدء في الاستعداد لـ gpt-image-2؟
نوصي بالبدء فوراً في بناء خط أنابيب التوليد بالجملة على gpt-image-1.5، والتعرف على قوالب الموجهات (Prompts)، ومعلمات الأبعاد، ومستويات الجودة. في يوم إطلاق gpt-image-2، ستحتاج فقط إلى استبدال حقل model للاستمتاع بدقة 4K ودقة نصية تصل إلى 99%. الفرق التي تستعد مسبقاً يمكنها إطلاق صور منتجاتها الجديدة قبل المنافسين بأسبوع أو أسبوعين.
س3: متى سيكون gpt-image-2 متاحاً رسمياً لبيئة الإنتاج؟
حتى تاريخ 17-04-2026، لم تعلن OpenAI رسمياً عن ذلك، ولا تزال نماذج سلسلة "tape" قيد اختبار A/B على منصة LM Arena. بناءً على وتيرة الإصدارات التاريخية، من المتوقع الإطلاق في الفترة ما بين أواخر أبريل إلى منتصف مايو 2026. قد تكون هناك قيود على المعدل (Rate Limits) في فترة الإطلاق الأولي، لذا نوصي باستخدام خدمة وكيل API مثل APIYI (apiyi.com) لتجنب مشكلات حصص التشغيل الأولية.
س4: هل يمكن لسيناريوهات نماذج واجهة المستخدم/تجربة المستخدم أن تحل محل Figma حقاً؟
لا تحل محله، بل تسبقه. يعد gpt-image-2 مناسباً لمرحلة إثبات المفهوم قبل Figma؛ حيث يمكنك استخدام نماذج أولية في ثوانٍ لاتخاذ قرار سريع (Go/No-Go) من قبل أصحاب المصلحة، وتجنب قضاء ساعات في Figma لإنشاء تصاميم عالية الدقة في اتجاه خاطئ. بمجرد تحديد الاتجاه، يظل Figma/Sketch هو أداة تسليم التصميم الفعلية.
س5: كيف يمكن ربط gpt-image-2 بالوكلاء (Agents) الحاليين عبر API؟
نوصي بالربط عبر APIYI (apiyi.com) لتحقيق انتقال سلس بدون تعديلات في يوم إطلاق gpt-image-2:
- قم بزيارة apiyi.com لتسجيل حساب والحصول على مفتاح API.
- اضبط
base_urlعلىhttps://vip.apiyi.com/v1واستخدم SDK الرسمي لـ OpenAI. - حالياً، استخدم
model="gpt-image-1.5"لبناء استدعاء وظائف الوكيل (Agent Function Calling). - في يوم إطلاق gpt-image-2، استبدل فقط
model="gpt-image-2".
تقوم APIYI بتوفير النماذج الجديدة بالتزامن مع OpenAI، مع بقاء مفتاح API والرصيد والفواتير كما هي، دون الحاجة لتسجيل حساب جديد أو تغيير الـ SDK.
س6: ما الذي يجب مراعاته في سيناريوهات توطين المحتوى؟
ثلاث تفاصيل أساسية: (1) قدم محتوى النص باللغة المستهدفة مباشرة في الموجه (Prompt) بدلاً من جعل النموذج يترجمه؛ (2) بالنسبة للغات التي تكتب من اليمين إلى اليسار (RTL) مثل العربية والعبرية، يجب تحديد "right-to-left layout" بوضوح في الموجه؛ (3) قد تظهر نصوص لغات شرق آسيا (CJK) ضبابية قليلاً تحت دقة 1536×1024، لذا نوصي باستخدام مخرجات 4K للنصوص المهمة (وهو ما يدعمه gpt-image-2 أصلاً).
س7: من أي سيناريو يجب أن تبدأ الفرق الصغيرة ذات الميزانية المحدودة؟
نوصي بالبدء بسيناريوهات نماذج واجهة المستخدم/تجربة المستخدم وتكرار لوحات القصة؛ فهذه السيناريوهات تتطلب تعقيداً منخفضاً في الربط، ويمكن أن تحقق تحسناً كبيراً في الكفاءة من خلال بضع عشرات إلى مئات الاستدعاءات شهرياً، مما يسهل التحقق من العائد على الاستثمار (ROI). بعد نمو العمل، يمكنك التوسع إلى التوليد بالجملة للتجارة الإلكترونية وتكامل خطوط أنابيب الوكلاء.
س8: ما هي السيناريوهات غير المناسبة لـ gpt-image-2؟
نوضح بصدق قيود ثلاث فئات: (1) الأسلوب الفني البحت: لا يزال Midjourney أقوى في اتجاهات جمالية معينة، بينما يميل gpt-image-2 أكثر نحو الواقعية؛ (2) توليد الفيديو: هذا نموذج صور، إذا كنت بحاجة إلى فيديو يرجى استخدام نماذج متخصصة مثل Sora؛ (3) المحتوى النصي الطويل جداً: تنخفض دقة النص للفقرات التي تزيد عن 50 كلمة في الصورة الواحدة، لذا نوصي بالتوليد المجزأ ثم الدمج.
النقاط الرئيسية لتطبيقات gpt-image-2
- 6 سيناريوهات إطلاق أولية: منتجات التجارة الإلكترونية، نماذج واجهة المستخدم، الرؤية البصرية للإعلانات، لوحات القصة، خطوط أنابيب الوكلاء، توطين المحتوى.
- القاسم المشترك: نقاط الألم في النماذج السابقة (النص/الدقة/المعرفة بالعالم) تتوافق بدقة مع ترقيات gpt-image-2 الثلاث.
- الأولوية القصوى: التجارة الإلكترونية، نماذج واجهة المستخدم، التوطين؛ لأنها الأكثر اعتماداً على القدرات الثلاث، والأكثر وضوحاً في العائد على الاستثمار.
- سهولة الربط: هيكل API متوافق تماماً مع gpt-image-1.5، ولا حاجة لتعديل SDK في خطوط أنابيب الوكلاء.
- مسار البدء: استخدم APIYI (apiyi.com) للربط بـ gpt-image-1.5 كتمهيد، ثم انتقل بسلاسة في يوم الإصدار الرسمي.
ملخص
الرؤى الجوهرية لحالات استخدام gpt-image-2:
- التركيز على السيناريوهات لا على التقنية: القيمة الحقيقية لا تكمن في "توليد الصور بالذكاء الاصطناعي" فحسب، بل في إعادة صياغة سير العمل الذي كان معطلاً بسبب النماذج القديمة؛ فالمواد التي كانت تتطلب جهوداً جماعية وخطوات متعددة في التجارة الإلكترونية، وتصاميم واجهات المستخدم (UI)، والمواد المترجمة محلياً، أصبحت الآن قابلة للإنتاج والتسليم في خطوة واحدة.
- ترتيب الأولويات: توفر سيناريوهات التجارة الإلكترونية، ونماذج واجهات المستخدم الأولية، والتعريب أعلى قيمة فورية؛ بينما تتطلب سيناريوهات الإعلانات وخطوط أنابيب الوكلاء (Agent pipelines) تخطيطاً متوسط المدى، في حين تمثل لوحات القصة (Storyboards) فرصة ذهبية للفرق الصغيرة.
- الانتقال السلس هو الميزة الأساسية: توافق معاملات (Parameters) الـ API يعني أنه يمكنك اليوم البدء في بناء خطوط العمل باستخدام gpt-image-1.5، وبمجرد إطلاق gpt-image-2، ستتمكن من الاستفادة من كافة الترقيات بمجرد استبدال اسم النموذج.
بالنسبة لقرارات الفريق، نوصي بالبدء فوراً في تجربة سيناريو أو اثنين من السيناريوهات ذات الأولوية عبر APIYI (apiyi.com) باستخدام gpt-image-1.5، وبناء مكتبة للموجهات (Prompts) وخطوط أنابيب المعالجة الجماعية باستخدام بيانات عمل حقيقية، لتكون جاهزاً للانطلاق بكامل قوتك فور صدور gpt-image-2.
مقالات ذات صلة
إذا كنت مهتماً بحالات استخدام gpt-image-2، نوصي بمتابعة القراءة حول المواضيع التالية:
- 📘 تحليل شامل للترقيات الثمانية في gpt-image-2 مقارنة بـ gpt-image-1.5 – لفهم الأسباب الكامنة وراء القفزة في القدرات.
- 📊 دليل استدعاء API الكامل لـ gpt-image-1.5 – لإتقان أفضل الممارسات للنموذج الرائد الحالي.
- 🚀 تحسين استدعاءات API الجماعية في بيئة الإنتاج لتوليد الصور – لاستكشاف استراتيجيات المعالجة الجماعية، والتزامن، والتخزين المؤقت.
📚 المراجع
-
تحليل سيناريوهات تطبيق MindStudio: قراءة في قدرات سيناريو GPT Image 2
- الرابط:
mindstudio.ai/blog/what-is-gpt-image-2 - الوصف: تنظيم منهجي لقدرات gpt-image-2 في مجالات التجارة الإلكترونية، واجهات المستخدم (UI)، والتسويق.
- الرابط:
-
مستودع أمثلة EvoLinkAI على GitHub: awesome-gpt-image-2-prompts
- الرابط:
github.com/EvoLinkAI/awesome-gpt-image-2-prompts - الوصف: مجموعة من الموجهات (prompts) التي اختبرها المجتمع في مجالات الصور الشخصية، الملصقات، نماذج واجهات المستخدم، وتصميم الشخصيات.
- الرابط:
-
وثائق OpenAI Agents SDK: بناء خط أنابيب (Pipeline) لتوليد الصور
- الرابط:
openai.github.io/openai-agents-python - الوصف: المعايير الرسمية لدمج استدعاء الدوال (Function Calling) مع توليد الصور.
- الرابط:
-
تحليل عميق لسيناريوهات ChatIMG: لقطات شاشة الويب، قوالب TikTok، ونماذج واجهات المستخدم (UI Mockup)
- الرابط:
chatimg.ai/en/blog/gpt-image-2 - الوصف: دراسات حالة عملية مصممة خصيصاً للمصممين والمطورين.
- الرابط:
الكاتب: الفريق التقني لـ APIYI
للنقاش التقني: نرحب بمشاركاتكم في قسم التعليقات، وللمزيد من الموارد يمكنكم زيارة مركز توثيق APIYI عبر الرابط docs.apiyi.com