title: gpt-image-2 実践ガイド:6つのビジネスシナリオで活用するAI画像生成の未来
description: gpt-image-2がどのように电商、UI/UX、広告などのビジネス現場の課題を解決するかを解説。API活用によるワークフローの効率化と、次世代画像生成モデルの可能性を徹底解剖します。
作者注: gpt-image-2 が持つ、EC、UI/UX、広告、ストーリーボード、開発者エージェント、コンテンツローカライズという 6 つの主要ビジネスシナリオにおける実戦的価値を体系的に整理しました。API 公開後のチームの導入計画にお役立てください。
AI 画像生成を日常的に利用している方なら、「ある種の問題」が長年解決されずに停滞していることに気づいているはずです。ラベルのスペルが間違った製品画像、手作業で文字を修正しなければならない広告素材、全言語版のローカライズを一度に作成できない不便さ。これらはモデルの能力不足というより、初期の画像モデルが抱えていた文字レンダリング、解像度、世界知識の限界によるものです。
一見すると古くからの課題ですが、gpt-image-2 はこれらの限界を体系的に打ち破ろうとしています。 本記事では、gpt-image-2 の応用シナリオを階層ごとに分解し、6 つのビジネス領域におけるリアルなワークフロー、API 接続方法、そしてそれがあなたのチームにとって何を意味するのかを解説します。
核心的価値: シナリオから実装コードまで、本記事を読めばどの業務が gpt-image-2 から最も恩恵を受けるかを完全に理解でき、API 公開初日に既存のパイプラインへ統合する方法がわかります。

gpt-image-2 応用シナリオの要点
| 応用シナリオ | 核心的価値 | 初期モデルの課題 |
|---|---|---|
| EC・製品撮影 | 4K 製品画像 + 正確なパッケージ文字 | ラベルの誤字、解像度不足 |
| UI/UX プロトタイプ | 数秒で高精度モックアップ作成 | ボタンの文字/アイコンの乱れ |
| 広告・メインビジュアル | 広告用ブランドフォント + 4K | PSでの修正が必須 |
| ストーリーボード・制作準備 | 3秒での反復 + 世界知識 | 分割画面の再試行コストが高い |
| 開発者エージェントパイプライン | SDK変更不要で直接統合 | 生成が不安定で自動化困難 |
| コンテンツローカライズ | CJK/RTL/ラテン文字の同期 | 英語以外は手動レイアウトが必要 |
応用シナリオの共通点
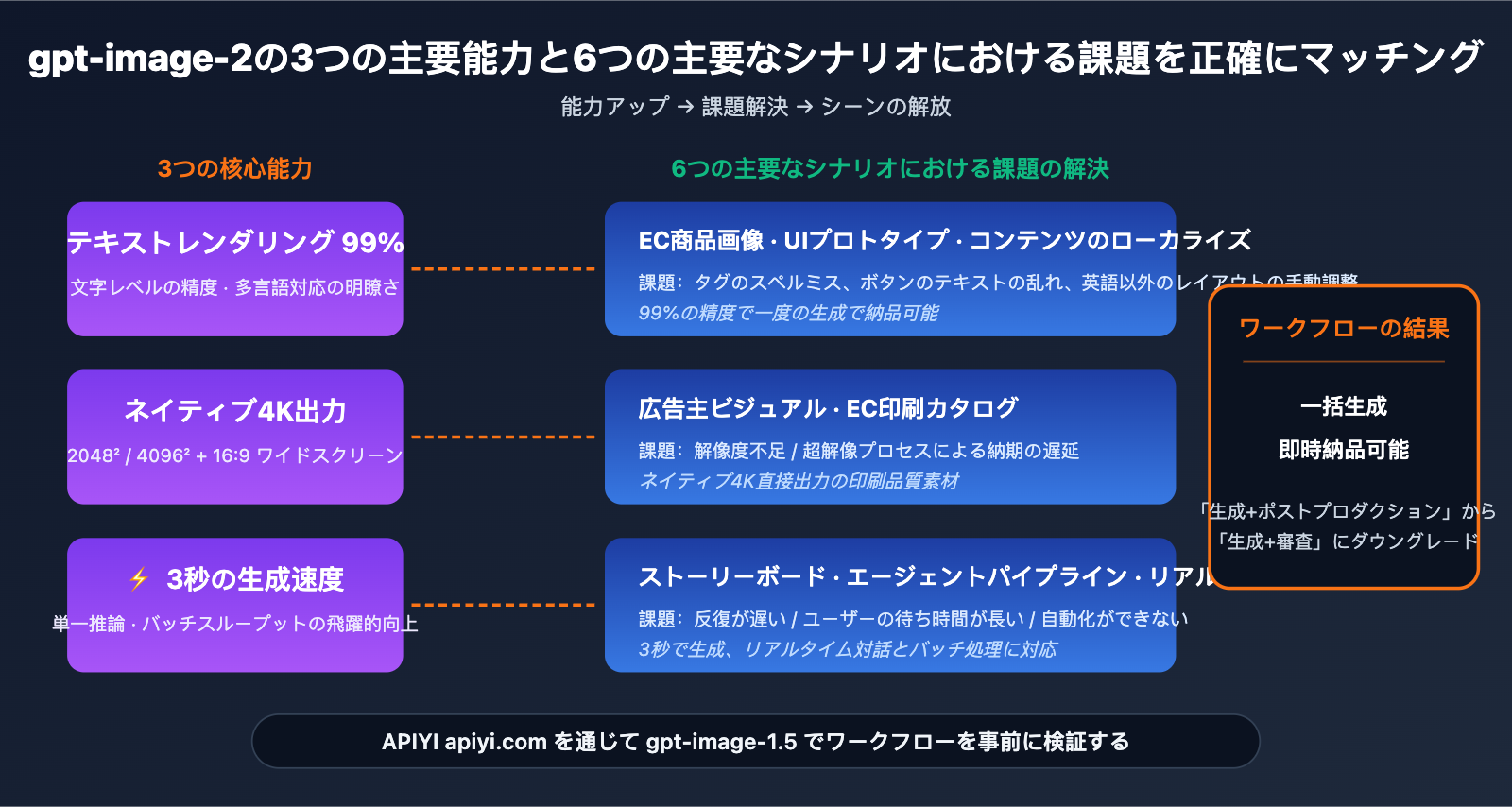
これら 6 つのシナリオに共通していること: ワークフローが「初期の画像モデルにおける文字レンダリング、解像度、世界知識の限界」によって阻害されていました。gpt-image-2 の 3 つのハード指標(99% の文字精度、4K ネイティブ出力、3 秒の生成速度)は、まさにこれら 3 つのボトルネックを正確に解消します。
これが意味すること: これまで「AI 生成 + 人の手による修正」という 2 段階のワークフローを必要としていたシナリオが、gpt-image-2 の登場により「一度の生成で納品可能」になり、人の介入は「修正」から「確認」へとレベルダウンします。チームの画像制作効率は飛躍的に向上するでしょう。
gpt-image-2 の活用事例 1:Eコマースと商品撮影
シーンの概要
Eコマースチームにとって最大の悩みは、大量の商品画像におけるブランドの一貫性です。同一商品に対して、A+コンテンツ(商品棚画像、シーン画像、詳細画像、季節限定テーマ画像など)を数十枚生成する必要があり、これまではプロのカメラマンに依頼するか、AIで生成した後にラベルやパッケージの文字を何度も修正する必要がありました。
gpt-image-2 による変革
- ラベルの可読性とパッケージの正確性: 99%の文字精度により、商品名、仕様、成分ラベルを一度の生成で正確に出力します。
- リアルな商品棚のシーン: 世界的な知識ベースにより、背景(カフェ、キッチン、デスクなど)がブランドのトーンに合ったリアルなものになります。
- 印刷に耐えうる4K解像度: 出力された画像は、カタログやEコマースサイトのA+コンテンツにそのまま使用できるため、超解像処理の手間を省けます。
ワークフローの比較
| ステップ | 従来のAI生成 | gpt-image-2 ワークフロー |
|---|---|---|
| メイン画像1枚の作成 | 3〜5回の再試行 + Photoshopでの修正 | 1回の生成で完了 |
| 20枚のバリエーション生成 | 約2〜3時間 | 約10分 |
| 印刷用解像度 | 超解像ソフトによる処理が必要 | ネイティブ4Kで直接出力 |
| ブランドラベルの正確性 | 人手による校正が必要 | 約99%自動で正確 |
活用アドバイス: Eコマースチームは、APIYI (apiyi.com) を通じて事前に gpt-image-1.5 を導入し、バッチ呼び出しの構造に慣れておくことをお勧めします。gpt-image-2 がリリースされた当日、
modelフィールドを書き換えるだけで、4K解像度と99%の文字精度というダブルのアップグレードを即座に享受できます。
gpt-image-2 の活用事例 2:UI / UX プロトタイプ
シーンの概要
プロダクトマネージャーやデザイナーは、プロジェクトの初期段階でステークホルダーに対し、高精細なアプリ画面のモックアップを迅速に提示する必要があります。Figmaを開いてゼロから作成すると数時間かかり、外部のデザイン会社に依頼するとコミュニケーションコストがさらに高くなります。従来の画像生成モデルでは、UIスクリーンショット内のボタンの文字が崩れたり、アイコンがずれたりして、実用には程遠い状態でした。
gpt-image-2 による変革
- 数秒で高精細なモックアップを作成: 3秒の生成と正確な文字出力により、コンセプト案を「即座に」使用可能にします。
- 文字、アイコン、レイアウト構造の正確性: ボタンのコピー、ナビゲーションラベル、データテーブルなどが鮮明で読みやすくなります。
- デザイナーがFigmaを開く前にステークホルダーの承認を獲得: プロダクトの意思決定サイクルを大幅に短縮します。
プロンプトの例
現代的なモバイルバンキングアプリのダッシュボード画面、
- 上部ナビゲーション: "Accounts · Transfer · Pay · Invest"
- アカウントカード: 残高 "$12,847.50"、「Main Checking」の表示
- 取引リスト(3項目): "Starbucks -$5.40", "Salary +$4,200", "Netflix -$15.99"
- 下部タブバー: Home, Cards, Rewards, Settings
iOSスタイル、ライトモード、Appleシステムフォント
このプロンプトを gpt-image-2 に入力すると、生成されたスクリーンショット内の文字は一字一句正確にレンダリングされます。これは、これまでの画像生成モデルでは実現できなかったことです。
gpt-image-2 活用シーン 3:広告およびメインビジュアル
シーンの概要
マーケティングチームが作成するメインビジュアル素材(ポスター、バナー、SNSカバー画像)は、広告出稿レベルの品質が求められます。ブランドフォントの正確さ、製品の自然な馴染み方、そしてシーンに合ったライティングが不可欠です。従来のプロセスでは、フォトグラファー、レタッチャー、デザイナーが数日かけて共同作業を行う必要がありました。
gpt-image-2 による変革
- ブランドフォントの正確性: 99% の精度により、スローガン、製品名、CTAボタンのテキストを一度で正確に生成します。
- 製品の自然な馴染み方: 豊富な世界知識により、製品が「浮いている」ような合成感ではなく、実際の消費シーンに自然に溶け込んだ画像を生成します。
- シーンに適したライティング: 写実性の向上により、ポートレート、手元の描写、反射などが実際の写真撮影のような光の表現に適合します。
- 4K出力で「アップスケーリング」の手間を削減: 従来のマーケティング制作フローで必須だった超解像処理の工程を省略できます。
最も恩恵を受ける広告タイプ
| 広告タイプ | gpt-image-2 の価値 |
|---|---|
| SNSフィード広告 | 1:1の正方形画像 + CTAテキストの正確性 |
| YouTubeサムネイル | 16:9のネイティブ生成 + 4Kモニターでの視認性 |
| 屋外/LED広告 | 4096×4096の解像度で大型スクリーンへ直接出力可能 |
| 印刷用ポスター | ネイティブ4K対応でA3/A2印刷にも耐えうる品質 |
| メールヘッダー | 複数パターンの迅速な生成によるABテストの効率化 |
導入のアドバイス: 広告クリエイティブのパイプラインには、APIYI (apiyi.com) の統一インターフェース経由での呼び出しを推奨します。gpt-image-2 がリリースされた当日、ビジネス側のコードを書き換えることなく、モデル名を切り替えるだけで即座に利用可能です。
gpt-image-2 活用シーン 4:ストーリーボードとプリプロダクション
シーンの概要
映画監督、クリエイティブディレクター、アニメーション制作者にとって、プリプロダクション段階での分鏡(絵コンテ)の迅速な反復は非常に重要です。従来のプロセスでは、絵師が脚本に基づいて手描きしており、1回の修正に数時間を要していました。AIを活用する場合でも、これまでのモデルでは「キャラクターの一貫性」や「シーンの正確性」が安定しないという課題がありました。
gpt-image-2 による変革
- 高速な絵コンテ作成: 3秒という生成速度により、監督はリアルタイムでカットのテンポを調整しながら、脚本家やクライアントと直接議論を進めることができます。
- カットのテンポ、シーン、人物配置の正確性: 世界知識により、「地下駐車場 + 雨の夜 + 街灯の下に立つ主人公」といった複雑なシーンも一発で正確に生成します。
- 試行コストの削減: 平均5〜6回の生成でようやく1枚使えるレベルだったものが、1〜2回で完結するようになります。
ワークフローの変化
従来のストーリーボードワークフロー:
脚本 → 絵師による手描き → 監督確認 → 修正 → 再描画 (3〜5回ループ)
所要時間: 1〜2週間 / 話
gpt-image-2 を活用したワークフロー:
脚本 → gpt-image-2 で生成 (3秒) → 監督がリアルタイムでプロンプトを調整 → 決定稿
所要時間: 1〜2日 / 話
効率化のメリット: プリプロダクションの期間を80%以上短縮でき、浮いた時間をより緻密なカット設計に充てることができます。APIYI (apiyi.com) のバッチ処理インターフェースを利用して、エピソード全体の絵コンテを一括で処理することをおすすめします。
gpt-image-2 アプリケーションシナリオ 5: 開発者ツールと Agent パイプライン

シナリオの説明
AI製品において、動的な視覚コンテンツ生成のニーズがますます高まっています。教育用Agentがチュートリアルのスクリーンショットを生成したり、ゲームAgentがシーンのコンセプトアートを作成したり、ドキュメントAgentが挿絵を生成したりするケースです。これまでは、画像生成モデルを統合するためにSDKの修正や、複数のベンダーアカウントの管理、異なるAPI構造への対応が必要でした。
gpt-image-2 による変革
- SDKの修正不要で、既存の統合環境にそのまま接続可能: APIのパラメータ構造は gpt-image-1.5 と完全互換です。
- ユーザー製品内でのUIレンダリング、チュートリアル素材、オンデマンドの視覚コンテンツ生成が必要なAgentに最適です。
- OpenAI Agents SDK、AgentKit とネイティブ互換: Function Calling を通じて直接画像生成をトリガーできます。
Agent パイプラインのシンプルな例
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def agent_generate_image(scene_description: str) -> str:
"""Agentツール: 必要に応じてシーンの挿絵を生成"""
response = client.images.generate(
model="gpt-image-1.5", # リリース後は "gpt-image-2" に切り替え
prompt=scene_description,
size="1024x1024",
quality="high"
)
return response.data[0].url
image_url = agent_generate_image(
"チュートリアルのステップ3: 設定画面で 'APIキーを接続' ボタンをクリックするユーザー"
)
Agent統合コードの全体を確認する (Function Callingを含む)
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
tools = [{
"type": "function",
"function": {
"name": "generate_image",
"description": "現在のチュートリアルステップ用の画像を生成する",
"parameters": {
"type": "object",
"properties": {
"prompt": {"type": "string", "description": "画像の詳細説明"},
"size": {"type": "string", "enum": ["1024x1024", "1536x1024"]}
},
"required": ["prompt"]
}
}
}]
def generate_image(prompt: str, size: str = "1024x1024") -> str:
response = client.images.generate(
model="gpt-image-1.5",
prompt=prompt,
size=size,
quality="high"
)
return response.data[0].url
messages = [{"role": "user", "content": "APIキー設定用のチュートリアル画像を生成して"}]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools
)
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
image_url = generate_image(**args)
print(f"Agentが生成した画像: {image_url}")
開発者へのアドバイス: APIYI (apiyi.com) を使用してOpenAIエコシステムに統一的に接続しましょう。1つのAPIキーで gpt-image-2 や GPT-4o などの全モデルを呼び出せるため、複数のベンダーアカウントを管理する手間が省けます。
gpt-image-2 アプリケーションシナリオ 6: コンテンツのローカライズ
シナリオの説明
海外展開するブランドや越境ECにとっての大きな課題は、1つのクリエイティブを多言語市場(英語、中国語(簡体・繁体)、日本語、韓国語、アラビア語、スペイン語など)に対応させることです。これまで、AIが生成する非英語テキストは誤字や崩れが多く、ローカライズチームが手作業で修正・レイアウトする必要がありました。
gpt-image-2 による変革
- 同一のクリエイティブからCJK、RTL、ラテン言語バージョンを同時に生成可能: 1つのプロンプトと言語パラメータで全言語版を出力できます。
- 手作業でのレイアウト修正が不要: 多言語テキストのレンダリングにかかる時間を数日から数分に短縮します。
- ローカライズサイクルの大幅短縮: 「英語で確定 → 翻訳待ち → 手作業で再制作」というリニアなプロセスから、並行処理によるバッチ処理へと進化します。
ローカライズ効率の比較
| コンテンツの種類 | 従来のローカライズ | gpt-image-2 によるローカライズ |
|---|---|---|
| 製品パッケージデザイン | 5-7日/言語 | 10分/言語 |
| SNS広告 | 2-3日/言語 | 5分/言語 |
| チュートリアル画像 | 1-2日/言語 | 3分/言語 |
| メールヘッダー | 半日/言語 | 2分/言語 |
多言語バッチ生成の例
languages = {
"en": "Summer Sale — Up to 50% Off",
"zh": "夏季特惠 — 低至 5 折",
"ja": "サマーセール — 最大 50% オフ",
"ar": "تخفيضات الصيف — خصم حتى 50%"
}
for lang, slogan in languages.items():
prompt = f"E-commerce hero banner, product showcase with slogan '{slogan}', modern style"
url = generate_image(prompt, size="1536x1024")
print(f"[{lang}] {url}")
ローカライズチームへのアドバイス: APIYI (apiyi.com) の統一インターフェースを通じて多言語素材をバッチ処理しましょう。プラットフォームでは、各言語のレンダリング効果を検証するための無料テスト枠を提供しています。
gpt-image-2 アプリケーションシナリオの比較
| シナリオ | 優先度 | 予想 ROI | 導入の複雑さ |
|---|---|---|---|
| EC商品画像 | ⭐⭐⭐⭐⭐ | 高(撮影コスト削減) | 低 |
| UI/UXプロトタイプ | ⭐⭐⭐⭐⭐ | 高(意思決定サイクルの短縮) | 低 |
| 広告メインビジュアル | ⭐⭐⭐⭐ | 高(レタッチ作業の削減) | 中 |
| ストーリーボード制作 | ⭐⭐⭐ | 中(クリエイティブ効率) | 低 |
| Agentパイプライン | ⭐⭐⭐⭐ | 中(製品化) | 中 |
| コンテンツローカライズ | ⭐⭐⭐⭐⭐ | 極めて高い(数日→数分) | 中 |
優先度決定のヒント
即時導入を計画すべき(リリース当日に切り替え可能): EC商品画像、UI/UXプロトタイプ、コンテンツローカライズ。これら3つのシナリオは、gpt-image-2の3つの主要なアップグレード(文字描画/4K解像度/多言語対応)への依存度が最も高いためです。
中期的な移行(2〜4週間様子見): 広告メインビジュアル、Agentパイプライン。APIの安定性やレート制限が明確になってから大規模に展開することをお勧めします。
試験的な探索: ストーリーボード制作。小規模チームや個人クリエイターに適しており、従来のワークフローからの移行障壁が低いためです。
決定のポイント: 具体的な優先度は、チーム構成やビジネスのペースによって異なります。まずは APIYI (apiyi.com) を通じて gpt-image-1.5 で試験運用を行い、実際のビジネスデータでROIを評価してから、gpt-image-2 リリース後の投資規模を決定することをお勧めします。
よくある質問 (FAQ)
Q1: gpt-image-2 はどのようなアプリケーションシナリオに最適ですか?
6つの主要シナリオで優先度が高くなります:EC商品画像(4K + 正確なラベル)、UI/UXプロトタイプ(高精細モックアップ)、広告メインビジュアル(広告品質)、ストーリーボード(高速イテレーション)、開発者向けAgentパイプライン(SDK変更不要)、コンテンツローカライズ(多言語一括生成)。共通点は、従来のモデルでは文字描画、解像度、世界知識の面で限界があったシナリオであり、gpt-image-2がそれらを体系的に解決している点です。
Q2: ECチームはいつから gpt-image-2 の準備を始めるべきですか?
今すぐ gpt-image-1.5 を使ってバッチ生成パイプラインを構築し、プロンプトテンプレート、サイズパラメータ、品質設定の組み合わせに慣れておくことをお勧めします。gpt-image-2 がリリースされたら、model フィールドを書き換えるだけで、4K解像度と99%の文字精度を享受できます。事前に準備しているチームは、競合他社より1〜2週間早く新しい製品画像を公開できるでしょう。
Q3: gpt-image-2 はいつ正式に本番環境で利用可能になりますか?
2026年4月17日現在、OpenAIからの公式発表はまだありません。LM Arena上のtapeシリーズのコードネームモデルがA/Bテスト中であることから、2026年4月下旬から5月中旬のリリースが予想されます。リリース初期はレート制限がかかる可能性があるため、APIYI (apiyi.com) のようなAPI中継サービスを利用して、コールドスタート時の制限問題を回避することをお勧めします。
Q4: UI/UXプロトタイプ作成で本当に Figma を置き換えられますか?
置き換えるのではなく、前段階として活用します。gpt-image-2 は Figma を使う前のコンセプト検証段階に適しています。数秒でモックアップを作成し、ステークホルダーと迅速にGo/No-Goの意思決定を行うことで、Figmaで何時間もかけて間違った方向性の高精細デザインを作成するリスクを回避できます。方向性が決まった後は、Figma/Sketch が実際の設計ツールとして最適です。
Q5: APIを通じて gpt-image-2 を既存の Agent に統合するには?
APIYI (apiyi.com) を経由して接続することで、gpt-image-2 リリース当日にコード変更なしで切り替えが可能です:
- apiyi.com でアカウントを作成し、APIキーを取得します。
base_urlをhttps://vip.apiyi.com/v1に設定し、OpenAI公式SDKを使用します。- 現在は
model="gpt-image-1.5"を使用してAgentの関数呼び出し(Function Calling)を構築します。 - gpt-image-2 リリース当日に
model="gpt-image-2"に書き換えるだけです。
APIYIはOpenAIと同期して新モデルを導入するため、既存のキー、残高、請求情報はそのままで、新しいアカウント作成やSDKの入れ替えは不要です。
Q6: コンテンツローカライズの際に注意すべき点は?
3つの重要なポイントがあります:(1) プロンプト内でモデルに翻訳させるのではなく、ターゲット言語のテキストを直接指定する。(2) アラビア語やヘブライ語などのRTL(右から左へ書く)言語は、プロンプトで「right-to-left layout」と明示する。(3) 日本語・中国語・韓国語(CJK)の文字は、解像度が1536×1024以下だと少しぼやける可能性があるため、重要なテキストが含まれる場合は4K出力(gpt-image-2でネイティブサポート)を推奨します。
Q7: 予算が限られている小規模チームはどのシナリオから始めるべきですか?
UI/UXプロトタイプ と ストーリーボードのイテレーション から始めることをお勧めします。これらは導入の複雑さが低く、月間数十〜数百回の呼び出しでも効率化を実感でき、ROIを迅速に検証できるためです。ビジネスの成長に合わせて、ECのバッチ生成やAgentパイプラインの統合へと拡大していくのが良いでしょう。
Q8: gpt-image-2 に向かないシナリオはありますか?
以下の3つの限界を理解しておく必要があります:(1) 極めて芸術的なスタイル: 特定の美的方向性においては Midjourney の方が依然として強力であり、gpt-image-2 はより写実的な表現に向いています。(2) 動画生成: これは画像生成モデルです。動画が必要な場合は Sora などの専用モデルを使用してください。(3) 長文テキスト: 1枚の画像内に50文字以上の段落が含まれると精度が低下するため、分割して生成し、後で結合することをお勧めします。
gpt-image-2 の活用シーン:重要ポイント
- 6つの主要活用シーン: EC商品画像、UIプロトタイプ、広告メインビジュアル、ストーリーボード、エージェントパイプライン、コンテンツのローカライズ
- 共通する核心: 3つの課題(テキスト描写・解像度・世界知識)が、gpt-image-2の3つのアップグレードと正確に対応
- 優先度最高: EC、UIプロトタイプ、ローカライズ。これらは3つの能力への依存度が最も高く、ROI(投資対効果)が最も顕著です
- 導入のハードルはゼロ: API構造はgpt-image-1.5と完全互換。エージェントパイプラインのSDK修正は不要です
- 導入パス: APIYI (apiyi.com) を通じてgpt-image-1.5で先行検証を行い、正式版リリース当日にシームレスな切り替えが可能
まとめ
gpt-image-2 の活用シーンにおける核心的な洞察:
- 技術主導ではなくシーン主導: 真の価値は「AIによる画像生成」そのものではなく、従来のモデルでは停滞していたワークフローの再構築にあります。これまで複数人・複数工程を要していたEC画像、UIデザイン、ローカライズ素材が、今後は一度の生成で完結します。
- 優先度の階層化: EC、UIプロトタイプ、ローカライズの3つが最も高い初期価値を持ちます。広告やエージェントパイプラインは中期的な計画が必要であり、ストーリーボードは小規模チームにとってのチャンスとなります。
- シームレスな移行が最大の強み: APIパラメータの互換性により、今日からgpt-image-1.5でパイプラインを構築し、gpt-image-2のリリース当日にモデル名を変更するだけで、すべてのアップグレードを享受できます。
チームの意思決定においては、今すぐ APIYI (apiyi.com) を通じてgpt-image-1.5で1〜2つの主要シーンを試行し、実際の業務データを用いてプロンプトライブラリとバッチ処理パイプラインを構築することを推奨します。そうすれば、gpt-image-2のリリース当日に、万全の体制でスタートダッシュを切ることができます。
延伸阅读 Related Articles
gpt-image-2 の応用シナリオにご興味がある方は、以下の記事もぜひご覧ください。
- 📘 gpt-image-2 vs gpt-image-1.5:8つの主要なアップグレードを徹底解説 – 能力が飛躍的に向上した背景を理解する
- 📊 gpt-image-1.5 API呼び出し完全ガイド – 現在のフラッグシップモデルを使いこなすためのベストプラクティス
- 🚀 画像生成APIのプロダクション環境におけるバッチ処理最適化 – バッチパイプライン、並列処理、キャッシュ戦略を探求する
📚 参考資料
-
MindStudio アプリケーションシナリオ分析: GPT Image 2 の機能解説
- リンク:
mindstudio.ai/blog/what-is-gpt-image-2 - 説明: EC、UI、マーケティングなどの各シナリオにおける gpt-image-2 の活用事例を体系的に整理
- リンク:
-
EvoLinkAI GitHub サンプルライブラリ: awesome-gpt-image-2-prompts
- リンク:
github.com/EvoLinkAI/awesome-gpt-image-2-prompts - 説明: ポートレート、ポスター、UIモックアップ、キャラクターデザインなど、コミュニティで検証済みのプロンプト集
- リンク:
-
OpenAI Agents SDK ドキュメント: 画像生成エージェントパイプラインの構築
- リンク:
openai.github.io/openai-agents-python - 説明: Function Calling を活用した画像生成統合の公式仕様
- リンク:
-
ChatIMG シナリオ詳細分析: Webスクリーンショット、TikTokテンプレート、UIモックアップ
- リンク:
chatimg.ai/en/blog/gpt-image-2 - 説明: デザイナーや開発者向けの具体的な活用事例
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。その他の資料については、APIYI ドキュメントセンター(docs.apiyi.com)をご覧ください。