Anmerkung des Autors: Wir analysieren systematisch den praktischen Nutzen von gpt-image-2 in den sechs Geschäftsbereichen E-Commerce, UI/UX, Werbung, Storyboarding, Entwickler-Agenten und Inhaltslokalisierung, um Teams bei der Planung der Implementierung nach der API-Freigabe zu unterstützen.
Wenn Sie häufig KI-Bilderzeugung nutzen, ist Ihnen sicher aufgefallen, dass bestimmte Anforderungen seit Langem "feststecken" – Produktbilder mit falsch geschriebenen Etiketten, Werbematerialien, bei denen Texte manuell korrigiert werden müssen, oder lokalisierte Kreativinhalte, die nicht in einem Durchgang für alle Sprachen erstellt werden können. Diese Probleme liegen nicht an den Fähigkeiten der Modelle, sondern an den Grenzen früher Bildmodelle bei der Textwiedergabe, Auflösung und dem Weltwissen.
Das klingt nach einem alten Problem, doch gpt-image-2 durchbricht diese Barrieren systematisch. Dieser Artikel analysiert die Anwendungsbereiche von gpt-image-2 – die realen Arbeitsabläufe in sechs Geschäftsbereichen, die API-Anbindung und was das für Ihr Team bedeutet.
Kernnutzen: Von den Szenarien bis zum Implementierungscode – nach der Lektüre dieses Artikels verstehen Sie genau, welche Geschäftsbereiche am stärksten von gpt-image-2 profitieren, und wissen, wie Sie es am ersten Tag der API-Verfügbarkeit in Ihre bestehenden Pipelines integrieren können.

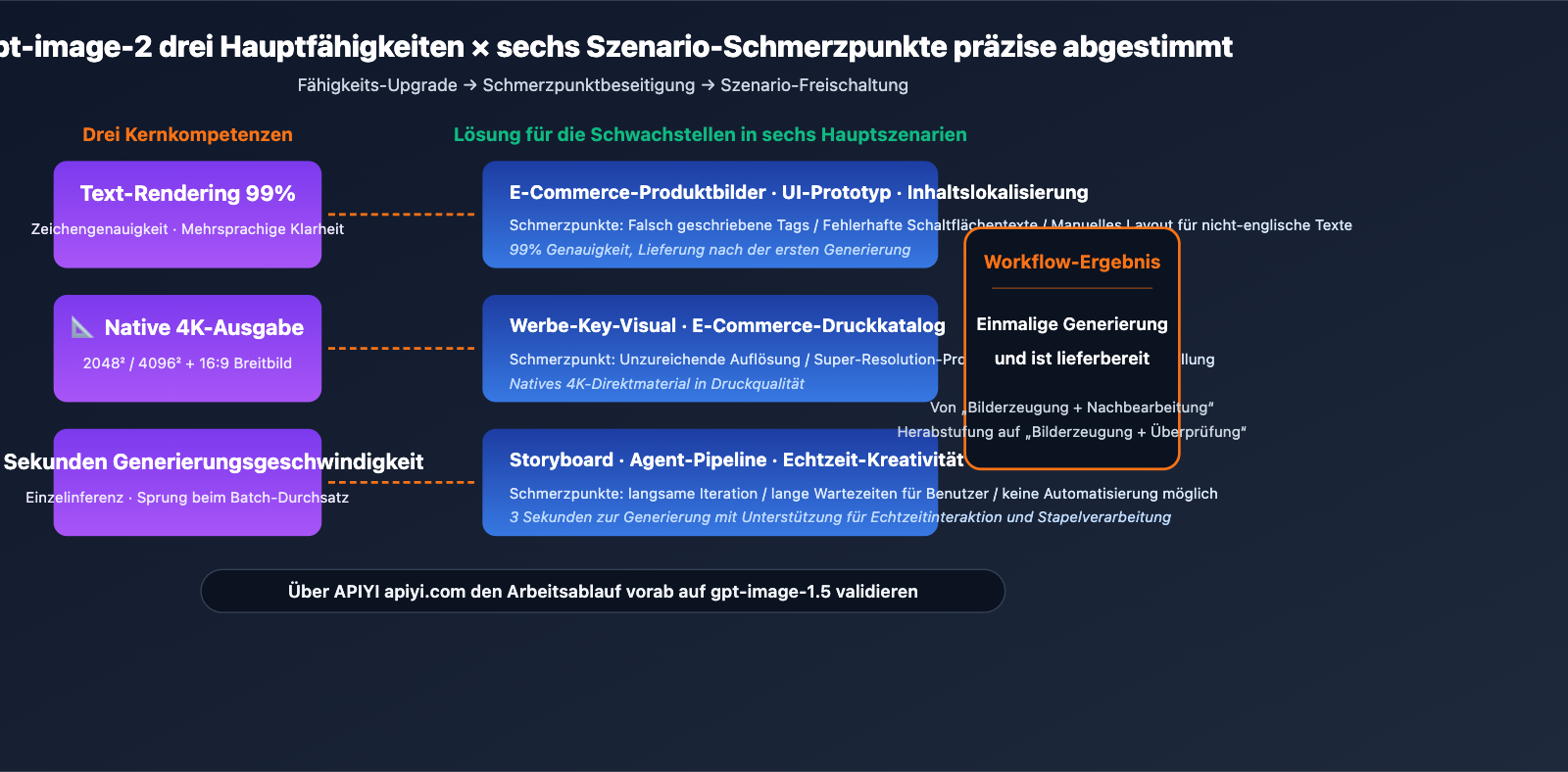
Kernpunkte der Anwendungsbereiche von gpt-image-2
| Anwendungsbereich | Kernnutzen | Schwachstellen früherer Modelle |
|---|---|---|
| E-Commerce & Produktfotografie | 4K-Produktbilder + präziser Verpackungstext | Falsche Etiketten, zu geringe Auflösung |
| UI/UX-Prototyping | High-Fidelity-Mockups in Sekunden | Fehlerhafte Schaltflächentexte/Icons |
| Werbung & Key Visuals | Druckreife Markenschriftarten + 4K | Aufwendige PS-Nachbearbeitung nötig |
| Storyboarding & Pre-Production | 3-Sekunden-Iteration + Weltwissen | Hohe Kosten bei Fehlversuchen |
| Entwickler-Agent-Pipelines | Direkte Integration ohne SDK-Änderung | Instabile Generierung, schwer automatisierbar |
| Inhaltslokalisierung | Synchron für CJK/RTL/Lateinisch | Manuelles Layout bei Nicht-Englisch |
Gemeinsamkeiten der Anwendungsbereiche
Die Gemeinsamkeit dieser 6 Szenarien: Die Workflows wurden bisher durch die "Obergrenze früherer Bildmodelle bei Textdarstellung, Auflösung und Weltwissen" ausgebremst. Die drei harten Kennzahlen von gpt-image-2 (99 % Textgenauigkeit, native 4K-Ausgabe, 3 Sekunden Generierungszeit) adressieren genau diese Engpässe.
Was bedeutet das: Workflows, die früher eine KI-Generierung + manuelle Nachbearbeitung erforderten, können mit gpt-image-2 auf einmalige Generierung bis zur Auslieferung verkürzt werden. Der menschliche Eingriff reduziert sich von "Reparatur" auf "Abnahme". Die Effizienz der Bildproduktion im Team wird einen qualitativen Sprung machen.
gpt-image-2 Anwendungsbereich 1: E-Commerce & Produktfotografie
Szenariobeschreibung
Das größte Kopfzerbrechen bereitet E-Commerce-Teams die Markenkonsistenz bei Produktbildern: Für ein einzelnes Produkt müssen Dutzende A+-Inhalte (Regalbilder, Szenenbilder, Detailaufnahmen, saisonale Themen) erstellt werden. Früher bedeutete dies entweder echte Fotoshootings oder KI-Generierung mit anschließender mühsamer Korrektur von Etiketten und Verpackungstexten.
Wie gpt-image-2 den Prozess neu definiert
- Lesbare Etiketten, präzise Verpackung: Dank 99 % Textgenauigkeit sind Produktnamen, Spezifikationen und Inhaltsstoffe direkt beim ersten Versuch korrekt.
- Realistische Regalszenen: Durch das integrierte Weltwissen passen Hintergründe (Cafés, Küchen, Schreibtische) perfekt zur Markenidentität.
- 4K-Auflösung für den Druck: Die Ausgabe kann direkt für gedruckte Kataloge und E-Commerce-Plattformen verwendet werden, was Upscaling-Schritte überflüssig macht.
Workflow-Vergleich
| Schritt | Traditionelle KI-Generierung | gpt-image-2 Workflow |
|---|---|---|
| Erstellung 1 Hauptbild | 3-5 Versuche + PS-Textkorrektur | 1 Generierung |
| Batch-Generierung 20 Varianten | ca. 2-3 Stunden | ca. 10 Minuten |
| Druckreife Auflösung | Erfordert Upscaling-Software | Native 4K-Ausgabe |
| Markenetiketten-Genauigkeit | Manuelle Korrektur nötig | ca. 99 % automatisch korrekt |
Empfehlung: E-Commerce-Teams können über den API-Proxy-Dienst APIYI (apiyi.com) bereits gpt-image-1.5 integrieren, um sich mit der Struktur der Batch-Aufrufe vertraut zu machen. Am Tag der Veröffentlichung von gpt-image-2 muss lediglich das Feld
modelersetzt werden, um sofort von 4K-Auflösung und 99 % Textgenauigkeit zu profitieren.
gpt-image-2 Anwendungsfall 2: UI/UX-Prototyping
Szenariobeschreibung
Produktmanager und Designer müssen in der frühen Phase schnell High-Fidelity-Mockups von App-Oberflächen präsentieren. Von Grund auf in Figma zu starten, dauert Stunden, während die Beauftragung externer Designer mit hohen Kommunikationskosten verbunden ist. UI-Screenshots, die von früheren Bildmodellen generiert wurden, waren aufgrund von chaotischem Text auf Buttons und falsch platzierten Symbolen kaum zu gebrauchen.
Wie gpt-image-2 die Arbeit transformiert
- High-Fidelity-Mockups in Sekunden: 3 Sekunden Generierungszeit + präziser Text machen Konzeptentwürfe sofort einsatzbereit.
- Präzise Texte, Symbole und Layouts: Button-Beschriftungen, Navigationsmenüs und Datentabellen sind klar und lesbar.
- Stakeholder-Freigabe vor dem Figma-Start: Verkürzt den Entscheidungsprozess für Produkte erheblich.
Beispiel für eine typische Eingabeaufforderung
A modern mobile banking app dashboard screen,
- Top navigation: "Accounts · Transfer · Pay · Invest"
- Account card showing balance "$12,847.50" with "Main Checking"
- Transaction list with 3 items: "Starbucks -$5.40", "Salary +$4,200", "Netflix -$15.99"
- Bottom tab bar: Home, Cards, Rewards, Settings
iOS-style, light mode, Apple system font
Wenn Sie diese Eingabeaufforderung in gpt-image-2 eingeben, wird der Text im generierten Screenshot buchstabengetreu gerendert – eine Leistung, die bisherige Bildmodelle nicht erbringen konnten.
gpt-image-2 Anwendungsfall 3: Werbung und Key Visuals
Szenariobeschreibung
Marketing-Materialien (Poster, Banner, Social-Media-Cover) müssen Qualität auf Kampagnenniveau bieten: korrekte Markenschriftarten, natürliche Produktintegration und stimmige Lichtverhältnisse. Traditionelle Prozesse erfordern tagelange Zusammenarbeit zwischen Fotografen, Bildbearbeitern und Designern.
Wie gpt-image-2 die Arbeit transformiert
- Korrekte Markenschriftarten: Eine Genauigkeit von 99 % bedeutet, dass Slogans, Produktnamen und CTA-Buttons auf Anhieb sitzen.
- Natürliche Produktintegration: Dank umfassendem Weltwissen erscheint das Produkt in realistischen Konsumszenarien statt wie eine "schwebende" Montage.
- Stimmige Lichtverhältnisse: Fortschritte im Realismus sorgen dafür, dass Porträts, Hände und Reflexionen echtem Fotolicht entsprechen.
- 4K-Ausgabe spart Upscaling: Der bei Marketing-Workflows oft notwendige Schritt der nachträglichen Hochskalierung entfällt.
Wer am meisten von diesen Werbeformaten profitiert
| Werbetyp | Mehrwert durch gpt-image-2 |
|---|---|
| Social Media Feed | 1:1 Quadrat-Format + präziser CTA-Text |
| YouTube-Thumbnails | Natives 16:9 + Lesbarkeit auf 4K-Monitoren |
| Outdoor/LED-Werbung | 4096×4096 direkt für Großbildschirme |
| Druckposter | Natives 4K unterstützt A3/A2-Druck |
| E-Mail-Header | Schnelle Iteration für A/B-Tests |
Empfehlung zur Anbindung: Für Werbe-Workflows empfehlen wir die Nutzung der einheitlichen Schnittstelle von APIYI (apiyi.com). Am Tag der Veröffentlichung von gpt-image-2 müssen Sie Ihren Code nicht anpassen – es genügt, einfach den Modellnamen zu ändern.
gpt-image-2 Anwendungsfall 4: Storyboarding und Pre-Production
Szenario-Beschreibung
Regisseure, Creative Directors in Werbeagenturen und Animatoren müssen in der Vorproduktionsphase schnell Storyboards iterieren. Der traditionelle Prozess, bei dem Zeichner Skizzen basierend auf dem Drehbuch anfertigen, dauert pro Iteration Stunden. Selbst mit KI-Unterstützung waren bisherige Modelle bei der "Gesichtskonsistenz" und der "Szenengenauigkeit" oft zu instabil.
Wie gpt-image-2 den Prozess neu definiert
- Schnelle Storyboard-Iterationen: Dank der 3-Sekunden-Generierungsgeschwindigkeit können Regisseure das Kameratempo in Echtzeit anpassen und direkt mit Drehbuchautoren oder Kunden besprechen.
- Präzise Umsetzung von Tempo, Szene und Positionierung: Dank des umfassenden Weltwissens werden komplexe Szenen wie "Tiefgarage + regnerische Nacht + Protagonist unter einer Straßenlaterne" auf Anhieb korrekt umgesetzt.
- Geringere Kosten durch weniger Korrekturschleifen: Die Anzahl der Versuche, bis ein brauchbares Bild vorliegt, sinkt von durchschnittlich 5-6 auf 1-2.
Workflow-Veränderung
Traditioneller Storyboard-Workflow:
Drehbuch → Handzeichnung → Regie-Abnahme → Korrektur → Neuzeichnen (3-5 Runden)
Zeitaufwand: 1-2 Wochen / Folge
gpt-image-2 unterstützter Workflow:
Drehbuch → gpt-image-2 Generierung (3 Sek.) → Regie-Anpassung der Eingabeaufforderung → Finalisierung
Zeitaufwand: 1-2 Tage / Folge
Effizienzgewinn: Die Pre-Production-Phase kann um über 80 % verkürzt werden. Die gewonnene Zeit lässt sich in eine detailliertere Kameraführung investieren. Wir empfehlen die Nutzung der Batch-Schnittstellen von APIYI (apiyi.com) für die Verarbeitung ganzer Folgen.
gpt-image-2 Anwendungsfall 5: Entwicklertools und Agent-Pipelines
Szenario-Beschreibung
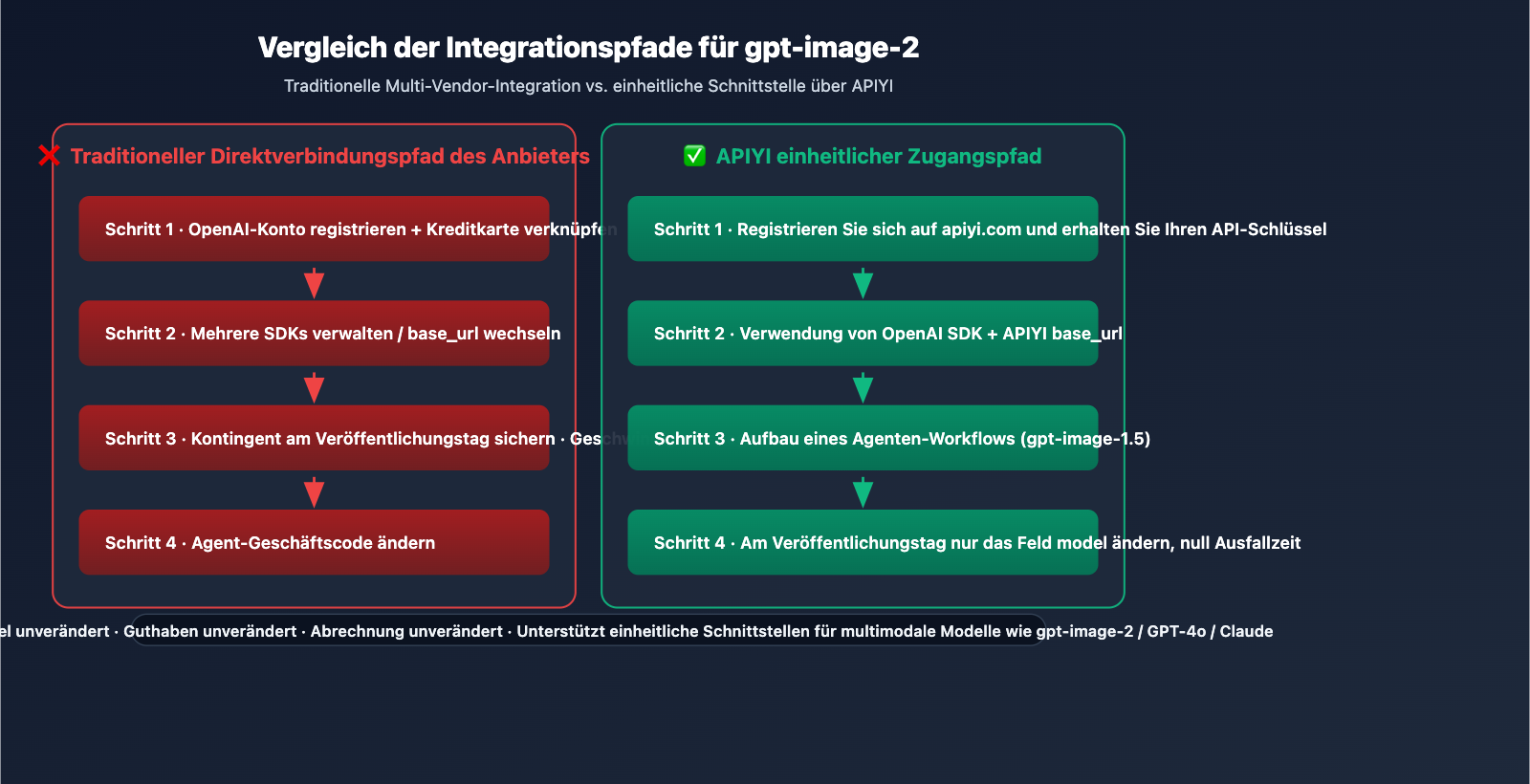
Immer mehr KI-Produkte erfordern die dynamische Generierung visueller Inhalte: Bildungs-Agenten erstellen Tutorial-Screenshots, Gaming-Agenten generieren Szenenkonzepte und Dokumenten-Agenten erstellen Illustrationen. Die Integration von Bildmodellen erforderte bisher das Anpassen von SDKs, die Verwaltung mehrerer Anbieter-Accounts und den Umgang mit unterschiedlichen API-Strukturen.
Wie gpt-image-2 den Prozess neu definiert
- Keine SDK-Anpassungen erforderlich, direkte Integration: Die API-Parameterstruktur ist vollständig kompatibel mit gpt-image-1.5.
- Ideal für Agenten, die UI-Elemente, Tutorial-Materialien oder bedarfsgerechte visuelle Inhalte in Benutzerprodukten rendern müssen.
- Nativ kompatibel mit OpenAI Agents SDK und AgentKit: Funktionsaufrufe (Function Calling) können direkt die Bilderzeugung auslösen.
Minimalistisches Beispiel für eine Agent-Pipeline
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def agent_generate_image(scene_description: str) -> str:
"""Agent-Tool: Szenenbild bei Bedarf generieren"""
response = client.images.generate(
model="gpt-image-1.5", # Nach Veröffentlichung auf "gpt-image-2" umstellen
prompt=scene_description,
size="1024x1024",
quality="high"
)
return response.data[0].url
image_url = agent_generate_image(
"Schritt 3 des Tutorials: Benutzer klickt in den Einstellungen auf die Schaltfläche 'API-Schlüssel verbinden'"
)
Vollständigen Agent-Integrationscode anzeigen (inkl. Function Calling)
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
tools = [{
"type": "function",
"function": {
"name": "generate_image",
"description": "Generiere ein Bild für den aktuellen Tutorial-Schritt",
"parameters": {
"type": "object",
"properties": {
"prompt": {"type": "string", "description": "Bildbeschreibung"},
"size": {"type": "string", "enum": ["1024x1024", "1536x1024"]}
},
"required": ["prompt"]
}
}
}]
def generate_image(prompt: str, size: str = "1024x1024") -> str:
response = client.images.generate(
model="gpt-image-1.5",
prompt=prompt,
size=size,
quality="high"
)
return response.data[0].url
messages = [{"role": "user", "content": "Erstelle ein Tutorial-Bild für die API-Schlüssel-Einrichtung"}]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools
)
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
image_url = generate_image(**args)
print(f"Vom Agent erzeugtes Bild: {image_url}")
Empfehlung für Entwickler: Nutzen Sie APIYI (apiyi.com) für eine einheitliche Anbindung an das OpenAI-Ökosystem. Mit einem einzigen API-Schlüssel können Sie gpt-image-2, GPT-4o und weitere Modelle aufrufen, ohne mehrere Anbieter-Accounts verwalten zu müssen.
gpt-image-2 Anwendungsfall 6: Lokalisierung von Inhalten
Szenario-Beschreibung
Die größte Herausforderung für global agierende Marken und den grenzüberschreitenden E-Commerce besteht darin, dass ein kreatives Konzept für mehrere Sprachmärkte angepasst werden muss: Englisch, Chinesisch (vereinfacht/traditionell), Japanisch, Koreanisch, Arabisch, Spanisch usw. In der Vergangenheit waren KI-generierte Texte in Nicht-Englisch oft fehlerhaft, was eine manuelle Nachbearbeitung durch Lokalisierungsteams erforderte.
Wie gpt-image-2 den Prozess neu definiert
- Ein kreatives Konzept für CJK, RTL und lateinische Schriften: Eine Eingabeaufforderung + Sprachparameter genügen, um alle Versionen auszugeben.
- Kein manuelles Layout erforderlich: Die mehrsprachige Textdarstellung wird von Tagen auf Minuten verkürzt.
- Drastische Verkürzung des Lokalisierungszyklus: Der lineare Prozess von "Englische Endfassung → Übersetzungswarteschlange → manuelle Neuerstellung" wird durch eine parallele Stapelverarbeitung ersetzt.
Vergleich der Lokalisierungseffizienz
| Inhaltstyp | Traditionelle Lokalisierung | gpt-image-2 Lokalisierung |
|---|---|---|
| Produktverpackungsdesign | 5-7 Tage/Sprache | 10 Minuten/Sprache |
| Social-Media-Anzeigen | 2-3 Tage/Sprache | 5 Minuten/Sprache |
| Tutorial-Screenshots | 1-2 Tage/Sprache | 3 Minuten/Sprache |
| E-Mail-Header | 0,5 Tage/Sprache | 2 Minuten/Sprache |
Beispiel für die mehrsprachige Stapelverarbeitung
languages = {
"en": "Summer Sale — Up to 50% Off",
"zh": "夏季特惠 — 低至 5 折",
"ja": "サマーセール — 最大 50% オフ",
"ar": "تخفيضات الصيف — خصم حتى 50%"
}
# Stapelverarbeitung für verschiedene Sprachen
for lang, slogan in languages.items():
prompt = f"E-Commerce Hero-Banner, Produktpräsentation mit Slogan '{slogan}', moderner Stil"
url = generate_image(prompt, size="1536x1024")
print(f"[{lang}] {url}")
Empfehlung für Lokalisierungsteams: Nutzen Sie die einheitliche Schnittstelle von APIYI (apiyi.com) für die Stapelverarbeitung mehrsprachiger Materialien. Die Plattform bietet kostenlose Testguthaben, um die Rendering-Effekte verschiedener Sprachen zu validieren.
Vergleich der Anwendungsszenarien für gpt-image-2
| Szenario | Priorität | Erwarteter ROI | Integrationsaufwand |
|---|---|---|---|
| E-Commerce-Produktbilder | ⭐⭐⭐⭐⭐ | Hoch (spart Fotokosten) | Niedrig |
| UI/UX-Prototypen | ⭐⭐⭐⭐⭐ | Hoch (kürzt Entscheidungszyklen) | Niedrig |
| Werbe-Visuals | ⭐⭐⭐⭐ | Hoch (spart Postproduktion) | Mittel |
| Storyboard-Erstellung | ⭐⭐⭐ | Mittel (kreative Effizienz) | Niedrig |
| Agent-Pipelines | ⭐⭐⭐⭐ | Mittel (Produktisierung) | Mittel |
| Lokalisierung von Inhalten | ⭐⭐⭐⭐⭐ | Extrem hoch (Tage → Minuten) | Mittel |
Empfehlungen zur Priorisierung
Sofortige Planung (Start am Veröffentlichungstag): E-Commerce-Produktbilder, UI/UX-Prototypen, Lokalisierung von Inhalten – diese drei Szenarien profitieren am stärksten von den drei Kern-Upgrades von gpt-image-2 (Textdarstellung/4K/Mehrsprachigkeit).
Mittelfristige Migration (2-4 Wochen Beobachtung): Werbe-Visuals, Agent-Pipelines – es wird empfohlen, auf eine stabile API und klare Ratenbegrenzungen zu warten, bevor ein großflächiger Einsatz erfolgt.
Explorative Ansätze: Storyboard-Erstellung – ideal für kleine Teams und unabhängige Kreative, da der Widerstand gegen die Umstellung traditioneller Workflows hier geringer ist.
Hinweis zur Entscheidungsfindung: Die konkrete Priorität hängt von Ihrer Teamstruktur und Ihrem Geschäftstempo ab. Wir empfehlen, zunächst gpt-image-1.5 über APIYI (apiyi.com) zu testen und den ROI anhand realer Geschäftsdaten zu bewerten, bevor Sie das Investitionsvolumen nach der Veröffentlichung von gpt-image-2 festlegen.
Häufig gestellte Fragen (FAQ)
Q1: Für welche Anwendungsszenarien ist gpt-image-2 am besten geeignet?
Die 6 wichtigsten Szenarien mit höchster Priorität sind: E-Commerce-Produktbilder (4K + präzise Labels), UI/UX-Prototypen (High-Fidelity-Mockups), Werbe-Visuals (Qualität auf Kampagnenniveau), Storyboards (schnelle Iteration), Entwickler-Agent-Pipelines (keine SDK-Anpassung erforderlich) und Inhaltslokalisierung (mehrsprachige Generierung in einem Durchgang). Die Gemeinsamkeit: Frühere Modelle stießen bei Textdarstellung, Auflösung und Weltwissen an ihre Grenzen – gpt-image-2 löst diese drei Probleme systematisch.
Q2: Wann sollten E-Commerce-Teams mit der Vorbereitung auf gpt-image-2 beginnen?
Es wird empfohlen, sofort eine Batch-Generierungs-Pipeline auf Basis von gpt-image-1.5 aufzubauen, um sich mit den Eingabeaufforderungs-Vorlagen, Größenparametern und Qualitätsstufen vertraut zu machen. Am Tag der Veröffentlichung von gpt-image-2 müssen Sie lediglich das Feld model austauschen, um von 4K-Auflösung und 99 % Textgenauigkeit zu profitieren. Teams, die sich vorbereiten, können ihre neuen Produktbilder 1–2 Wochen vor der Konkurrenz veröffentlichen.
Q3: Wann wird gpt-image-2 offiziell für die Produktion verfügbar sein?
Stand 17.04.2026 hat OpenAI noch keine offizielle Ankündigung gemacht; die Modelle der "tape"-Serie befinden sich im LM Arena noch im A/B-Test. Basierend auf dem historischen Rhythmus ist mit einer Veröffentlichung zwischen Ende April und Mitte Mai 2026 zu rechnen. In der Startphase könnte es zu Ratenbegrenzungen kommen; es empfiehlt sich, über einen API-Proxy-Dienst wie APIYI (apiyi.com) zu gehen, um Probleme mit Kaltstart-Kontingenten zu vermeiden.
Q4: Kann gpt-image-2 UI/UX-Prototypen wirklich Figma ersetzen?
Nicht ersetzen, sondern vorgelagert sein. gpt-image-2 eignet sich für die Konzeptprüfungsphase vor Figma – nutzen Sie Mockups in Sekundenschnelle, damit Stakeholder schnell eine Go/No-Go-Entscheidung treffen können. So vermeiden Sie es, Stunden in Figma in High-Fidelity-Entwürfe zu investieren, die in die falsche Richtung gehen. Sobald die Richtung feststeht, bleibt Figma/Sketch das eigentliche Design-Tool für die Auslieferung.
Q5: Wie binde ich gpt-image-2 über eine API in bestehende Agenten ein?
Wir empfehlen die Anbindung über APIYI (apiyi.com), um am Tag der Veröffentlichung von gpt-image-2 ohne Änderungen umschalten zu können:
- Besuchen Sie apiyi.com, registrieren Sie ein Konto und erhalten Sie einen API-Schlüssel.
- Setzen Sie die
base_urlaufhttps://vip.apiyi.com/v1und verwenden Sie das offizielle OpenAI-SDK. - Nutzen Sie aktuell
model="gpt-image-1.5", um das Agent-Function-Calling aufzubauen. - Am Tag der Veröffentlichung von gpt-image-2 ersetzen Sie einfach
model="gpt-image-2".
APIYI stellt neue Modelle zeitgleich mit OpenAI bereit; bestehende Schlüssel, Guthaben und Abrechnungen bleiben unverändert, sodass Sie kein neues Konto registrieren oder das SDK wechseln müssen.
Q6: Was ist bei der Inhaltslokalisierung zu beachten?
Drei wichtige Details: (1) Geben Sie den Textinhalt in der Zielsprache direkt in der Eingabeaufforderung an, anstatt das Modell übersetzen zu lassen; (2) bei Sprachen wie Arabisch oder Hebräisch (RTL) muss in der Eingabeaufforderung explizit ein "right-to-left layout" gefordert werden; (3) CJK-Schriftzeichen (Chinesisch, Japanisch, Koreanisch) können bei Auflösungen unter 1536×1024 leicht verschwommen wirken – für kritische Texte wird eine 4K-Ausgabe empfohlen (wird von gpt-image-2 nativ unterstützt).
Q7: Mit welchem Szenario sollten kleine Teams mit begrenztem Budget beginnen?
Wir empfehlen den Einstieg über UI/UX-Prototypen und Storyboard-Iterationen. Diese Szenarien erfordern eine geringe Integrationskomplexität, und bereits wenige Dutzend bis Hunderte Aufrufe pro Monat führen zu einer deutlichen Effizienzsteigerung, wodurch der ROI schnell validiert werden kann. Nach dem Geschäftswachstum kann die Skalierung auf E-Commerce-Batch-Generierung und Agent-Pipeline-Integration erfolgen.
Q8: Welche Szenarien sind nicht für gpt-image-2 geeignet?
Hier eine objektive Einschätzung der Grenzen: (1) Extremer künstlerischer Stil: Midjourney ist in bestimmten ästhetischen Richtungen nach wie vor stärker, gpt-image-2 ist eher auf Realismus ausgelegt; (2) Videogenerierung: Dies ist ein Bildmodell; für Videos verwenden Sie bitte spezialisierte Modelle wie Sora; (3) Sehr lange Textinhalte: Die Genauigkeit bei Absätzen mit mehr als 50 Wörtern pro Bild sinkt – es wird empfohlen, diese in Abschnitten zu generieren und anschließend zusammenzufügen.
Key Takeaways für gpt-image-2 Anwendungsszenarien
- 6 Top-Szenarien: E-Commerce-Produkte, UI-Prototypen, Werbe-Visuals, Storyboards, Agent-Pipelines, Inhaltslokalisierung.
- Kern-Gemeinsamkeit: Die Schwachstellen der drei Bereiche (Text/Auflösung/Weltwissen) korrespondieren präzise mit den drei Upgrades von gpt-image-2.
- Höchste Priorität: E-Commerce, UI-Prototypen und Lokalisierung – sie sind am stärksten von den drei Kernfähigkeiten abhängig und bieten den deutlichsten ROI.
- Barrierefreier Zugang: Die API-Struktur ist vollständig kompatibel mit gpt-image-1.5; für Agent-Pipelines ist keine SDK-Anpassung nötig.
- Einstiegspfad: Nutzen Sie APIYI (apiyi.com) für die Vorab-Tests mit gpt-image-1.5, um am Tag der offiziellen Veröffentlichung nahtlos zu wechseln.
Zusammenfassung
Die zentralen Erkenntnisse zu den Anwendungsszenarien von gpt-image-2:
- Szenario- statt technologiegetrieben: Der wahre Mehrwert liegt nicht in der bloßen "Bilderzeugung", sondern in der Neugestaltung von Arbeitsabläufen, die bei älteren Modellen feststeckten. Aufgaben wie E-Commerce-Bilder, UI-Entwürfe oder lokalisierte Materialien, die früher mehrere Personen und Schritte erforderten, können nun in einem einzigen Durchgang erstellt werden.
- Priorisierung: E-Commerce, UI-Prototypen und Lokalisierung bieten den höchsten unmittelbaren Mehrwert. Werbung und Agent-Pipelines erfordern eine mittelfristige Planung, während Storyboards eine große Chance für kleine Teams darstellen.
- Nahtlose Migration als Kernvorteil: Die Kompatibilität der API-Parameter bedeutet, dass Sie heute mit dem Aufbau Ihrer Pipeline für gpt-image-1.5 beginnen können. Am Tag der Veröffentlichung von gpt-image-2 müssen Sie lediglich den Modellnamen austauschen, um von allen Upgrades zu profitieren.
Für Entscheidungsträger im Team: Es wird empfohlen, sofort über APIYI (apiyi.com) auf gpt-image-1.5 zuzugreifen, um ein bis zwei Pilotprojekte zu starten. Nutzen Sie reale Geschäftsdaten, um Ihre Bibliothek für Eingabeaufforderungen und Batch-Pipelines aufzubauen, damit Sie beim Release von gpt-image-2 sofort mit einem Wettbewerbsvorteil starten können.
Weiterführende Artikel
Wenn Sie sich für die Anwendungsszenarien von gpt-image-2 interessieren, empfehlen wir Ihnen folgende Lektüre:
- 📘 gpt-image-2 vs. gpt-image-1.5: Die acht wichtigsten Upgrades im Detail – Verstehen Sie die Hintergründe der Leistungssteigerung.
- 📊 Vollständiger API-Aufruf-Leitfaden für gpt-image-1.5 – Meistern Sie die Best Practices für das aktuelle Flaggschiff-Modell.
- 🚀 Optimierung von Batch-Aufrufen in der Produktionsumgebung für Bilderzeugungs-APIs – Entdecken Sie Strategien für Batch-Pipelines, Nebenläufigkeit und Caching.
📚 Referenzmaterialien
-
MindStudio Anwendungsfallanalyse: Interpretation der Fähigkeiten von GPT Image 2
- Link:
mindstudio.ai/blog/what-is-gpt-image-2 - Beschreibung: Systematische Zusammenstellung von GPT-Image-2 für Szenarien wie E-Commerce, UI-Design und Marketing.
- Link:
-
EvoLinkAI GitHub-Beispiel-Repository: awesome-gpt-image-2-prompts
- Link:
github.com/EvoLinkAI/awesome-gpt-image-2-prompts - Beschreibung: Eine von der Community getestete Sammlung von Eingabeaufforderungen für Porträts, Poster, UI-Mockups und Charakterdesign.
- Link:
-
OpenAI Agents SDK Dokumentation: Aufbau einer Pipeline für die Bilderzeugung
- Link:
openai.github.io/openai-agents-python - Beschreibung: Offizieller Standard für die Integration von Function Calling in die Bilderzeugung.
- Link:
-
ChatIMG Szenario-Tiefenanalyse: Web-Screenshots, TikTok-Vorlagen, UI-Mockups
- Link:
chatimg.ai/en/blog/gpt-image-2 - Beschreibung: Konkrete Anwendungsbeispiele für Designer und Entwickler.
- Link:
Autor: APIYI Technisches Team
Technischer Austausch: Diskutieren Sie gerne in den Kommentaren. Weitere Informationen finden Sie im APIYI Dokumentationszentrum unter docs.apiyi.com.