Nota do autor: Fizemos um levantamento detalhado do valor prático do gpt-image-2 em 6 grandes áreas de negócio: e-commerce, UI/UX, publicidade, storyboards, agentes desenvolvedores e localização de conteúdo, para ajudar sua equipe a planejar a implementação assim que a API for liberada.
Se você usa frequentemente a geração de imagens por IA, provavelmente já notou que existe um tipo de demanda que vive "travada" — fotos de produtos com rótulos escritos errados, materiais publicitários que exigem correção manual de texto ou a impossibilidade de criar versões localizadas em vários idiomas de uma só vez. Essas demandas não são um problema de capacidade do modelo, mas sim o teto de vidro dos modelos de imagem anteriores em renderização de texto, resolução e conhecimento de mundo.
Isso parece um problema antigo, mas o gpt-image-2 está quebrando esses limites de forma sistemática. Este artigo detalhará, camada por camada, os cenários de aplicação do gpt-image-2 — fluxos de trabalho reais em 6 áreas de negócio, como integrar a API e o que isso significa para sua equipe.
Valor central: Do cenário ao código de implementação, ao terminar de ler este artigo, você entenderá completamente quais negócios se beneficiarão primeiro do gpt-image-2 e saberá como integrá-lo ao seu pipeline existente logo no primeiro dia de abertura da API.

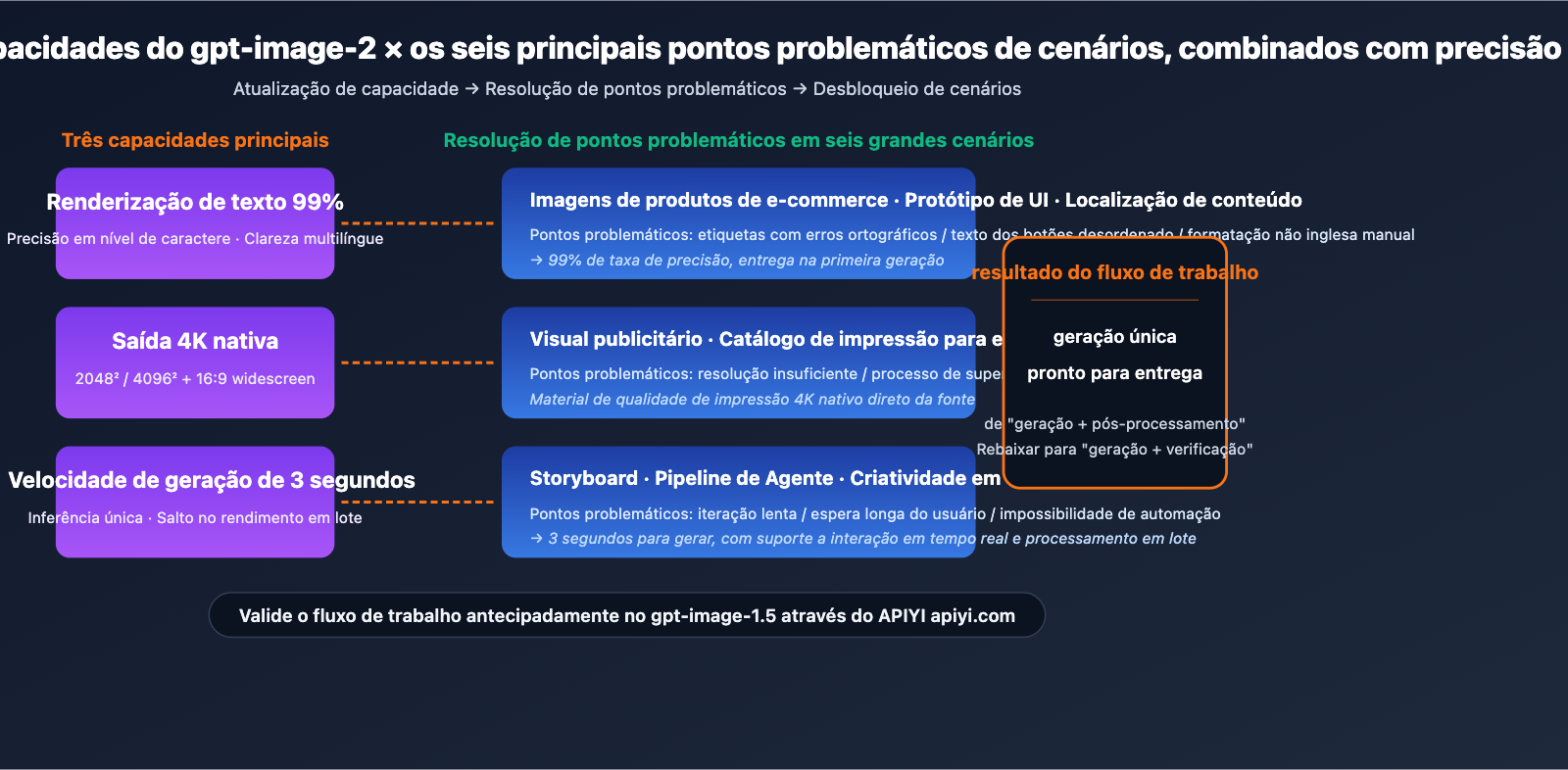
Pontos principais dos cenários de aplicação do gpt-image-2
| Cenário de aplicação | Valor central | Dores dos modelos antigos |
|---|---|---|
| E-commerce e fotografia de produto | Imagens de produto em 4K + texto preciso na embalagem | Etiquetas erradas, resolução insuficiente |
| Protótipos de UI/UX | Mockups de alta fidelidade em segundos | Texto de botões/ícones distorcidos |
| Publicidade e visual principal | Fontes de marca prontas para veiculação + 4K | Necessidade de reparo no Photoshop |
| Storyboards e pré-produção | Iteração em 3 segundos + conhecimento de mundo | Alto custo de refazer cenas |
| Pipeline de Agentes de desenvolvedor | Integração direta sem alterar SDK | Geração instável, difícil de automatizar |
| Localização de conteúdo | Sincronização de CJK/RTL/Latim | Necessidade de diagramação manual para não ingleses |
Pontos em comum dos cenários de aplicação
O que esses 6 cenários têm em comum: O fluxo de trabalho era limitado pelo "teto de desempenho dos modelos de imagem antigos em renderização de texto, resolução e conhecimento de mundo". Os três pilares do gpt-image-2 (99% de precisão de texto, saída nativa em 4K e velocidade de geração de 3 segundos) resolvem exatamente esses gargalos.
O que isso significa: Nesses cenários, o fluxo de trabalho que antes exigia geração por IA + pós-processamento manual pode, com o gpt-image-2, ser simplificado para entrega após uma única geração, reduzindo a intervenção humana de "reparo" para apenas "revisão". A eficiência de produção de imagens da equipe terá um salto qualitativo.
gpt-image-2 Aplicação 1: E-commerce e fotografia de produto
Descrição do cenário
O que mais tira o sono das equipes de e-commerce é a consistência de marca em fotos de produtos em lote: um único produto precisa de dezenas de conteúdos A+ (fotos de prateleira, fotos de cenário, fotos de detalhes, temas sazonais). Antigamente, era preciso contratar fotógrafos ou usar IA e passar horas corrigindo etiquetas e textos nas embalagens.
Como o gpt-image-2 redefine isso
- Etiquetas legíveis e embalagens precisas: Com 99% de precisão de texto, nomes de produtos, especificações e etiquetas de ingredientes saem corretos logo na primeira geração.
- Cenários de prateleira realistas: O conhecimento de mundo garante que o fundo (cafeterias, cozinhas, mesas de escritório) esteja alinhado com a identidade da marca.
- Resolução 4K pronta para impressão: A saída de cada imagem pode ser usada diretamente em catálogos impressos e conteúdos A+ de plataformas de e-commerce, eliminando a necessidade de etapas de upscaling.
Comparação de fluxo de trabalho
| Etapa | IA Tradicional | Fluxo de trabalho gpt-image-2 |
|---|---|---|
| Produção de 1 imagem principal | 3-5 tentativas + correção de texto no PS | 1 geração |
| Geração em lote de 20 variantes | Aprox. 2-3 horas | Aprox. 10 minutos |
| Resolução para impressão | Requer software de upscaling | 4K nativo direto |
| Precisão de etiquetas da marca | Requer revisão manual | ~99% de precisão automática |
Dica de cenário: Equipes de e-commerce podem acessar o gpt-image-1.5 via APIYI (apiyi.com) para se familiarizar com a estrutura de chamadas em lote. No dia do lançamento do gpt-image-2, basta substituir o campo
modelpara aproveitar o upgrade duplo de 4K + 99% de precisão de texto.
gpt-image-2 Cenário de aplicação 2: Protótipos de UI / UX
Descrição do cenário
Gerentes de produto e designers precisam, em estágios iniciais, apresentar rapidamente mockups de interface de aplicação de alta fidelidade para os stakeholders. Abrir o Figma e começar do zero leva horas, e terceirizar o design gera custos altos de comunicação. Em modelos de imagem anteriores, os screenshots de UI gerados apresentavam botões com textos confusos e ícones desalinhados, sendo praticamente inutilizáveis.
Como o gpt-image-2 redefine isso
- Produção de mockups de alta fidelidade em segundos: Geração em 3 segundos + texto preciso, tornando o rascunho conceitual "pronto para uso".
- Precisão em textos, ícones e estrutura de layout: Cópias de botões, etiquetas de navegação e tabelas de dados ficam claras e legíveis.
- Aprovação dos stakeholders antes mesmo de abrir o Figma: Redução drástica no ciclo de tomada de decisão do produto.
Exemplo de comando típico
A modern mobile banking app dashboard screen,
- Top navigation: "Accounts · Transfer · Pay · Invest"
- Account card showing balance "$12,847.50" with "Main Checking"
- Transaction list with 3 items: "Starbucks -$5.40", "Salary +$4,200", "Netflix -$15.99"
- Bottom tab bar: Home, Cards, Rewards, Settings
iOS-style, light mode, Apple system font
Ao inserir este comando no gpt-image-2, os textos acima serão renderizados com precisão literal nos screenshots gerados — algo que nenhum modelo de imagem anterior conseguia fazer.
gpt-image-2 Cenário de aplicação 3: Publicidade e Visual Principal (Key Visual)
Descrição do cenário
Materiais de visual principal para equipes de marketing (pôsteres, banners, capas de redes sociais) precisam atender a um nível de qualidade de veiculação: fontes da marca corretas, integração natural do produto e iluminação de cena adequada. O fluxo tradicional exige a colaboração de fotógrafos, editores de imagem e designers por vários dias.
Como o gpt-image-2 redefine isso
- Fontes da marca corretas: 99% de precisão significa que slogans, nomes de produtos e textos de botões CTA ficam prontos de primeira.
- Integração natural do produto: O conhecimento de mundo permite que o produto apareça em cenários de consumo reais, evitando aquela aparência de montagem "flutuante".
- Iluminação de cena adequada: O avanço no realismo garante que retratos, mãos e reflexos correspondam à iluminação fotográfica real.
- Saída em 4K elimina a etapa de "upscaling": A etapa de super-resolução, essencial na maioria dos fluxos de marketing, pode ser descartada.
Tipos de publicidade mais beneficiados
| Tipo de anúncio | Valor do gpt-image-2 |
|---|---|
| Feed de redes sociais | Imagem quadrada 1:1 + texto CTA preciso |
| Miniaturas do YouTube | Nativo 16:9 + legível em monitores 4K |
| Outdoor / LED | 4096×4096 pronto para telas grandes |
| Pôsteres impressos | Suporte nativo 4K para impressão A3/A2 |
| Cabeçalho de e-mail | Iteração rápida de múltiplas versões para teste AB |
Sugestão de integração: Para fluxos de criação publicitária, recomendamos o uso da interface unificada da APIYI (apiyi.com). No dia do lançamento do gpt-image-2, não será necessário alterar o código do seu negócio, basta alternar o nome do modelo.
gpt-image-2 Cenário de aplicação 4: Storyboard e pré-produção
Descrição do cenário
Diretores de cinema, diretores de criação publicitária e criadores de animação precisam iterar rapidamente em storyboards durante a fase de pré-produção. O fluxo tradicional envolve artistas desenhando manualmente com base no roteiro, o que leva horas por iteração; mesmo com auxílio de IA, os modelos anteriores não eram estáveis o suficiente em termos de "consistência de personagens" e "precisão de cenário".
Como o gpt-image-2 redefine isso
- Iteração rápida de storyboards: A velocidade de geração de 3 segundos permite que o diretor ajuste o ritmo das cenas em tempo real, discutindo cara a cara com roteiristas ou clientes.
- Precisão no ritmo, cenário ou posicionamento: O conhecimento de mundo do modelo permite que cenas complexas, como "estacionamento subterrâneo + noite chuvosa + protagonista sob um poste de luz", sejam geradas corretamente na primeira tentativa.
- Menor custo de retrabalho: Redução da necessidade de tentativas, passando de uma média de 5-6 gerações para apenas 1-2 até obter um resultado utilizável.
Mudanças no fluxo de trabalho
Fluxo de trabalho tradicional de storyboard:
Roteiro → Desenho manual do artista → Revisão do diretor → Alterações → Redesenho (ciclo de 3-5 rodadas)
Tempo gasto: 1-2 semanas / episódio
Fluxo de trabalho com auxílio do gpt-image-2:
Roteiro → Geração pelo gpt-image-2 (3 segundos) → Ajuste de comando em tempo real pelo diretor → Finalização
Tempo gasto: 1-2 dias / episódio
Ganhos de eficiência: O ciclo de pré-produção pode ser reduzido em mais de 80%, liberando tempo para um design de cena mais refinado. Recomendamos o uso da interface em lote da APIYI (apiyi.com) para processar o storyboard de episódios inteiros.
gpt-image-2 Cenário de aplicação 5: Ferramentas de desenvolvedor e pipelines de Agent
Descrição do cenário
Cada vez mais produtos de IA precisam de geração dinâmica de conteúdo visual: Agents educacionais que geram capturas de tela de tutoriais, Agents de jogos que geram conceitos de cenário, ou Agents de documentos que geram ilustrações. Antigamente, integrar modelos de imagem exigia modificar SDKs, lidar com múltiplas contas de fornecedores e adaptar-se a diferentes estruturas de API.
Como o gpt-image-2 redefine isso
- Sem necessidade de modificar o SDK: Integração direta com o que você já possui; a estrutura de parâmetros da API é totalmente compatível com o gpt-image-1.5.
- Ideal para Agents que precisam renderizar interfaces, materiais de tutorial ou conteúdo visual sob demanda dentro dos produtos dos usuários.
- Compatibilidade nativa com OpenAI Agents SDK e AgentKit: O Function Calling pode acionar diretamente a geração de imagens.
Exemplo simplificado de pipeline de Agent
from openai import OpenAI
client = OpenAI(
api_key="SUA_CHAVE_APIYI",
base_url="https://vip.apiyi.com/v1"
)
def agent_generate_image(scene_description: str) -> str:
"""Ferramenta do Agent: gerar imagem de cenário sob demanda"""
response = client.images.generate(
model="gpt-image-1.5", # Mude para "gpt-image-2" após o lançamento
prompt=scene_description,
size="1024x1024",
quality="high"
)
return response.data[0].url
image_url = agent_generate_image(
"Passo 3 do tutorial: o usuário clica no botão 'Conectar chave API' nas configurações"
)
Ver código completo de integração do Agent (incluindo Function Calling)
from openai import OpenAI
import json
client = OpenAI(
api_key="SUA_CHAVE_APIYI",
base_url="https://vip.apiyi.com/v1"
)
tools = [{
"type": "function",
"function": {
"name": "generate_image",
"description": "Gerar uma imagem para o passo atual do tutorial",
"parameters": {
"type": "object",
"properties": {
"prompt": {"type": "string", "description": "Descrição da imagem"},
"size": {"type": "string", "enum": ["1024x1024", "1536x1024"]}
},
"required": ["prompt"]
}
}
}]
def generate_image(prompt: str, size: str = "1024x1024") -> str:
response = client.images.generate(
model="gpt-image-1.5",
prompt=prompt,
size=size,
quality="high"
)
return response.data[0].url
messages = [{"role": "user", "content": "Crie uma imagem de tutorial para a configuração da chave API"}]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools
)
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
image_url = generate_image(**args)
print(f"Imagem produzida pelo Agent: {image_url}")
Dica para desenvolvedores: Use a APIYI (apiyi.com) para integrar de forma unificada ao ecossistema OpenAI. Com uma única chave API, você pode invocar o gpt-image-2, o GPT-4o e todos os outros modelos, evitando a manutenção de múltiplas contas de fornecedores.
gpt-image-2 Caso de uso 6: Localização de conteúdo
Descrição do cenário
O grande desafio para marcas que buscam expansão global e para o e-commerce transfronteiriço é que uma única criação precisa cobrir mercados com múltiplos idiomas: inglês, chinês (simplificado e tradicional), japonês, coreano, árabe, espanhol, entre outros. Antigamente, os textos não ingleses gerados por IA costumavam apresentar erros, exigindo que as equipes de localização fizessem a diagramação manual, um por um.
Como o gpt-image-2 transforma esse processo
- A mesma criação pode gerar versões em CJK, RTL e latim simultaneamente: um único comando + parâmetro de idioma é suficiente para gerar tudo.
- Sem necessidade de diagramação manual: a renderização de textos em vários idiomas é reduzida de dias para minutos.
- Ciclo de localização drasticamente encurtado: o fluxo linear de "aprovação em inglês → fila de tradução → recriação manual" torna-se um processo paralelo e em lote.
Comparação de eficiência na localização
| Tipo de conteúdo | Localização tradicional | Localização com gpt-image-2 |
|---|---|---|
| Design de embalagem de produto | 5-7 dias/idioma | 10 minutos/idioma |
| Anúncios em redes sociais | 2-3 dias/idioma | 5 minutos/idioma |
| Capturas de tela de tutoriais | 1-2 dias/idioma | 3 minutos/idioma |
| Cabeçalho de e-mail | Meio dia/idioma | 2 minutos/idioma |
Exemplo de geração em lote multilíngue
languages = {
"en": "Summer Sale — Up to 50% Off",
"zh": "夏季特惠 — 低至 5 折",
"ja": "サマーセール — 最大 50% オフ",
"ar": "تخفيضات الصيف — خصم حتى 50%"
}
# Itera sobre os idiomas para gerar os banners
for lang, slogan in languages.items():
prompt = f"E-commerce hero banner, product showcase with slogan '{slogan}', modern style"
url = generate_image(prompt, size="1536x1024")
print(f"[{lang}] {url}")
Dica da equipe de localização: Utilize a interface unificada da APIYI (apiyi.com) para processar materiais em vários idiomas em lote. A plataforma oferece créditos de teste gratuitos para validar a renderização em diferentes idiomas.
Comparação de soluções para cenários de aplicação do gpt-image-2
| Cenário | Prioridade de lançamento | ROI esperado | Complexidade de integração |
|---|---|---|---|
| Imagens de produtos e-commerce | ⭐⭐⭐⭐⭐ | Alto (economiza custos de fotografia) | Baixa |
| Protótipos de UI/UX | ⭐⭐⭐⭐⭐ | Alto (comprime o ciclo de decisão) | Baixa |
| Visual principal de anúncios | ⭐⭐⭐⭐ | Alto (elimina pós-produção) | Média |
| Criação de storyboards | ⭐⭐⭐ | Médio (eficiência criativa) | Baixa |
| Pipeline de Agentes | ⭐⭐⭐⭐ | Médio (produtização) | Média |
| Localização de conteúdo | ⭐⭐⭐⭐⭐ | Altíssimo (dias → minutos) | Média |
Sugestões para tomada de decisão de prioridade
Planeje o lançamento imediato (pode ser implementado no dia do lançamento): Imagens de produtos e-commerce, protótipos de UI/UX e localização de conteúdo — esses três cenários dependem mais das três principais atualizações do gpt-image-2 (texto/4K/multilíngue).
Migração a médio prazo (observe por 2-4 semanas): Visual principal de anúncios e pipeline de agentes — recomendamos aguardar a estabilização da API e a definição clara dos limites de taxa antes de colocar em produção em grande escala.
Exploração de oportunidades: Criação de storyboards — ideal para pequenas equipes e criadores independentes, onde a resistência à mudança do fluxo de trabalho tradicional é menor.
Nota de decisão: A prioridade específica depende da estrutura da sua equipe e do ritmo de negócios. Sugerimos testar primeiro com o gpt-image-1.5 na APIYI (apiyi.com) e avaliar o ROI com dados reais de negócio antes de decidir o nível de investimento após o lançamento do gpt-image-2.
Perguntas Frequentes (FAQ)
Q1: Para quais cenários de aplicação o gpt-image-2 é mais adequado?
Existem 6 cenários principais com prioridade máxima: imagens de produtos para e-commerce (4K + rótulos precisos), protótipos de UI/UX (mockups de alta fidelidade), visuais publicitários (qualidade de nível de veiculação), storyboards (iteração rápida), pipelines de agentes para desenvolvedores (sem necessidade de alterar o SDK) e localização de conteúdo (geração multilíngue em uma única etapa). O ponto comum é que as limitações dos modelos anteriores em texto, resolução e conhecimento de mundo restringiam esses cenários, e o gpt-image-2 resolve esses três problemas de forma sistemática.
Q2: Quando as equipes de e-commerce devem começar a se preparar para o gpt-image-2?
Recomendamos começar imediatamente a montar o pipeline de geração em lote no gpt-image-1.5, familiarizando-se com a combinação de modelos de comando, parâmetros de dimensão e níveis de qualidade. No dia do lançamento do gpt-image-2, basta substituir o campo model para aproveitar a resolução 4K e 99% de precisão de texto. As equipes que se prepararem com antecedência podem lançar novas imagens de produtos 1 a 2 semanas antes dos concorrentes.
Q3: Quando o gpt-image-2 estará oficialmente disponível para o ambiente de produção?
Até 17/04/2026, a OpenAI ainda não fez um anúncio oficial, e os modelos da série "tape" no LM Arena ainda estão em testes A/B. Com base no histórico de lançamentos, espera-se que seja disponibilizado entre o final de abril e meados de maio de 2026. O período de lançamento inicial pode ter limites de taxa, por isso recomendamos usar plataformas de serviço proxy de API como a APIYI (apiyi.com) para evitar problemas de cota durante o início da operação.
Q4: O cenário de protótipos de UI/UX pode realmente substituir o Figma?
Não substitui, mas antecipa. O gpt-image-2 é adequado para a fase de prova de conceito antes do Figma — usando mockups de poucos segundos para que os stakeholders tomem decisões rápidas de "Go/No-Go", evitando gastar horas no Figma criando designs de alta fidelidade na direção errada. Uma vez definida a direção, o Figma/Sketch continua sendo a ferramenta de entrega de design real.
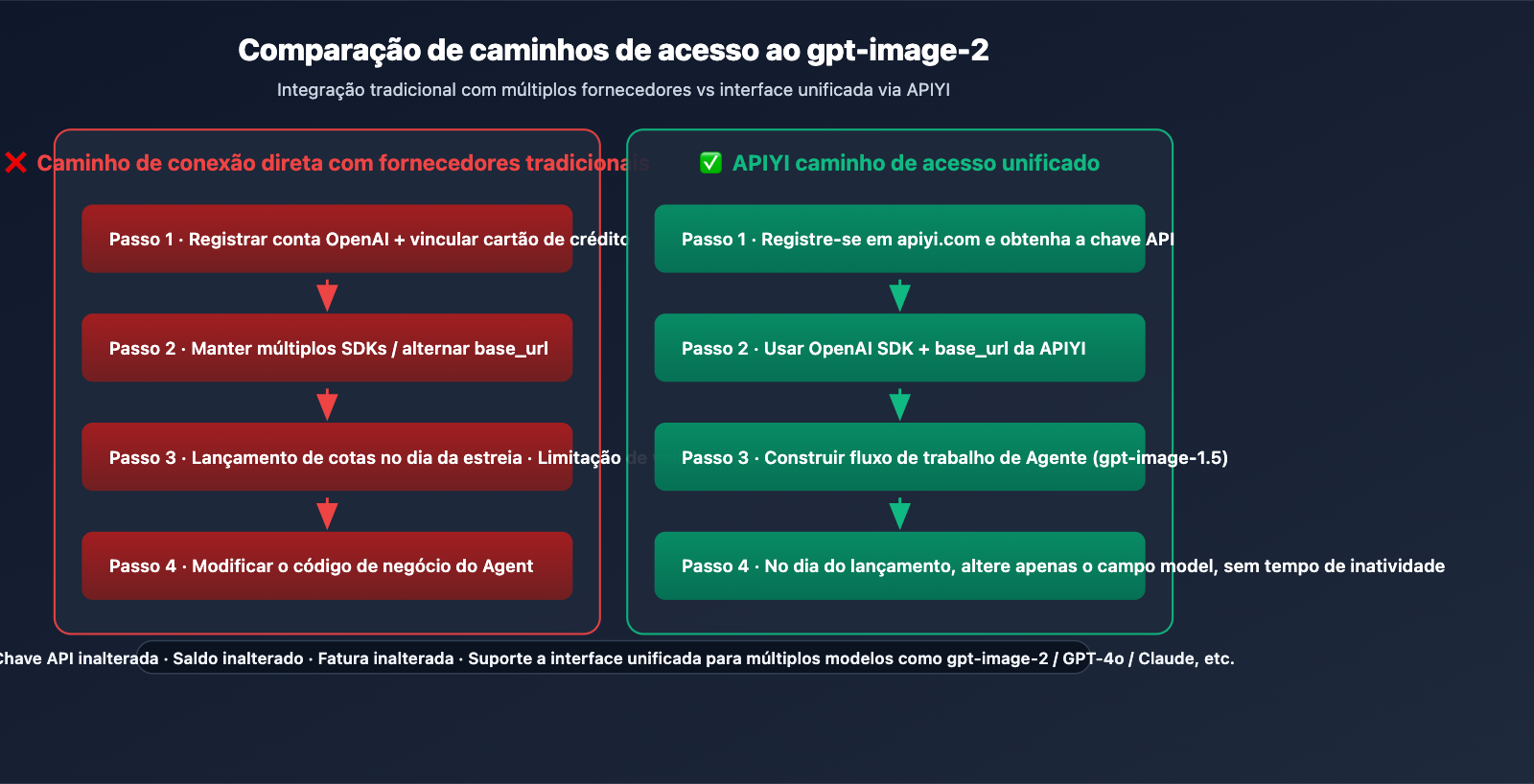
Q5: Como integrar o gpt-image-2 em agentes existentes via API?
Recomendamos a integração via APIYI (apiyi.com) para obter uma transição sem alterações no dia do lançamento do gpt-image-2:
- Acesse apiyi.com, registre uma conta e obtenha sua chave API.
- Defina a
base_urlcomohttps://vip.apiyi.com/v1e utilize o SDK oficial da OpenAI. - Atualmente, construa a chamada de função (Function Calling) do agente usando
model="gpt-image-1.5". - No dia do lançamento do gpt-image-2, basta substituir por
model="gpt-image-2".
A APIYI disponibiliza novos modelos simultaneamente com a OpenAI; sua chave API, saldo e faturas permanecem os mesmos, sem necessidade de registrar novas contas ou trocar de SDK.
Q6: O que deve ser observado no cenário de localização de conteúdo?
Três detalhes cruciais: (1) Forneça o conteúdo do texto no idioma de destino diretamente no comando, em vez de pedir ao modelo para traduzir; (2) Idiomas RTL (da direita para a esquerda), como árabe e hebraico, precisam de uma instrução clara de "layout da direita para a esquerda" no comando; (3) Textos em CJK (chinês, japonês, coreano) podem ficar um pouco borrados em resoluções abaixo de 1536×1024, por isso recomendamos usar a saída 4K para textos críticos (suportada nativamente pelo gpt-image-2).
Q7: Por qual cenário pequenas equipes com orçamento limitado devem começar?
Sugerimos começar pelos cenários de protótipos de UI/UX e iteração de storyboards — ambos exigem baixa complexidade de integração, e algumas dezenas a centenas de invocações por mês podem trazer ganhos de eficiência significativos, com um ROI que pode ser validado rapidamente. Após o crescimento do negócio, você pode expandir para a geração em lote de e-commerce e integração de pipelines de agentes.
Q8: Quais cenários não são adequados para o gpt-image-2?
Aqui estão as limitações em três cenários: (1) Estilo artístico extremo: O Midjourney ainda é mais forte em direções estéticas específicas, enquanto o gpt-image-2 é mais voltado para o realismo; (2) Geração de vídeo: Este é um modelo de imagem; para vídeos, utilize modelos especializados como o Sora; (3) Conteúdo de texto muito longo: A precisão do texto cai em parágrafos com mais de 50 caracteres por imagem; sugerimos gerar em partes e depois unir.
Principais conclusões sobre os cenários de aplicação do gpt-image-2
- 6 cenários principais: Produtos de e-commerce, protótipos de UI, visuais publicitários, storyboards, pipelines de agentes e localização de conteúdo.
- Ponto comum: As dores desses três tipos de cenários (texto/resolução/conhecimento de mundo) correspondem precisamente às três atualizações do gpt-image-2.
- Prioridade máxima: E-commerce, protótipos de UI e localização — são os que mais dependem dessas três capacidades e apresentam o ROI mais significativo.
- Integração sem barreiras: A estrutura da API é totalmente compatível com o gpt-image-1.5, sem necessidade de modificar o SDK nos pipelines de agentes.
- Caminho de adoção: Use a APIYI (apiyi.com) para integrar o gpt-image-1.5 como prévia e faça a transição perfeita no dia do lançamento da versão oficial.
Resumo
Insights fundamentais sobre os cenários de aplicação do gpt-image-2:
- Foco em cenários, não em tecnologia: O valor real não está apenas na "geração de imagens" por IA, mas na remodelação de fluxos de trabalho travados por modelos anteriores — tarefas que antes exigiam várias pessoas e etapas, como imagens de e-commerce, rascunhos de UI e materiais localizados, agora podem ser geradas e entregues de uma só vez.
- Priorização por camadas: Cenários de e-commerce, protótipos de UI e localização oferecem o maior valor imediato; pipelines de publicidade e agentes exigem um planejamento de médio prazo, enquanto storyboards representam uma oportunidade para equipes menores.
- Migração contínua como vantagem principal: A compatibilidade dos parâmetros da API significa que você pode começar a construir seu pipeline com o gpt-image-1.5 hoje mesmo e, no dia do lançamento do gpt-image-2, basta substituir o nome do modelo para aproveitar todas as melhorias.
Para a tomada de decisão da equipe, recomendamos integrar o gpt-image-1.5 via APIYI (apiyi.com) imediatamente para testar 1 ou 2 cenários prioritários, utilizando dados reais de negócio para construir sua biblioteca de comandos e pipelines em lote. Assim, você estará pronto para escalar com vantagem competitiva assim que o gpt-image-2 for lançado.
Leitura Recomendada
Se você se interessa pelos cenários de aplicação do gpt-image-2, recomendamos continuar a leitura:
- 📘 Análise completa das 8 principais atualizações do gpt-image-2 vs gpt-image-1.5 – Entenda os motivos técnicos por trás desse salto de capacidade.
- 📊 Guia completo de invocação da API do gpt-image-1.5 – Domine as melhores práticas do modelo carro-chefe atual.
- 🚀 Otimização de chamadas em lote da API de geração de imagens em ambiente de produção – Explore estratégias de pipeline, concorrência e cache.
📚 Referências
-
Análise de cenários de aplicação do MindStudio: Interpretação das capacidades do GPT Image 2
- Link:
mindstudio.ai/blog/what-is-gpt-image-2 - Descrição: Organização sistemática do gpt-image-2 em cenários como e-commerce, UI, marketing, entre outros.
- Link:
-
Repositório de exemplos do EvoLinkAI GitHub: awesome-gpt-image-2-prompts
- Link:
github.com/EvoLinkAI/awesome-gpt-image-2-prompts - Descrição: Coleção de comandos testados pela comunidade para retratos, pôsteres, mockups de UI e design de personagens.
- Link:
-
Documentação do SDK de Agentes da OpenAI: Construindo pipelines de Agentes de geração de imagens
- Link:
openai.github.io/openai-agents-python - Descrição: Especificações oficiais para a integração de Function Calling com geração de imagens.
- Link:
-
Análise profunda de cenários do ChatIMG: Capturas de tela da Web, modelos para TikTok, mockups de UI
- Link:
chatimg.ai/en/blog/gpt-image-2 - Descrição: Casos de uso específicos voltados para designers e desenvolvedores.
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimentos: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, visite o centro de documentação da APIYI em docs.apiyi.com