“gemini-3.1-flash-lite-image はそもそも推理モードをサポートしているのか?”は、最近 API 呼び出しのコミュニティで最もよく聞かれる質問のひとつです。答えは「はい」です。しかもこれは推測ではありません。Google の公式ドキュメントを参照しつつ、APIYI のゲートウェイ経由で3組の比較実験を行い、実際の token 消費量と遅延データを取得しました。この記事では、パラメータ構造、実測データ、課金ルールの3つの観点から、thinkingLevel というスイッチをわかりやすく解説します。
核心価値: この記事を読めば、gemini-3.1-flash-lite-image の推理モードをどう有効化するのか、有効化するとどれくらい token が増えるのか、そしてどんな場面ならその遅延を払ってでも使う価値があるのかが明確になります。

gemini-3.1-flash-lite-image 推理モードの核心結論
先に結論を述べ、そのあとで細部を見ていきます。Google の公式ドキュメントには、gemini-3.1-flash-image と gemini-3.1-flash-lite-image を使うことで、モデルが使用する思考量を制御できると明記されています。つまり、flash-lite も推理能力を内蔵しており、フラッグシップモデルだけの機能ではありません。ただし、すべての画像モデルがこのパラメータをサポートしているわけではないため、下表で主要な3つの Gemini 画像モデルの対応状況を比較します。
| モデル | thinkingLevel のサポート | 調整可能な段階 | デフォルト段階 | 備考 |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ 対応 | minimal / high | minimal | 公式ドキュメントに明記 |
| gemini-3.1-flash-lite-image | ✅ 対応 | minimal / high | minimal | flash-image と同じ thinkingConfig を共有 |
| gemini-3-pro-image | ⚠️ パラメータ無効 | 固定で調整不可 | 内部固定 | high を渡してもエラーにはならないが、実測では変化なし |
特に注意したいのは、thinkingLevel は2段階しか選べないことです。テキストモデルのように、連続的に思考予算を調整できるわけではありません。公式原文では「minimal の思考は、モデルがまったく考えないことを意味しない」とされています。つまり、デフォルト段階でもモデル内部ではある程度の基礎推論が行われますが、high のように複数回の構図検証までは行わない、ということです。
これは業界動向としても注目に値します。以前の世代の画像生成モデルでは、nano banana であれ初期の flash-image であれ、公式 API がこうした思考レベルのパラメータを公開していませんでした。モデルは固定戦略で画像を生成するか、あるいは完全にプロンプト設計で構図の弱点を補うしかありませんでした。3.1 世代では、Google が「先に計画し、あとで生成する」という推理メカニズムを flash 系に開放しています。これは、これまでテキストモデルで検証されてきた思考のパラダイムを、画像生成シーンへ移植したものだと言えます。この背景を理解しておくと、今後ほかのベンダーの画像モデルも同じ方向へ進むのかを判断しやすくなります。
🎯 技術的な提案: APIYI apiyi.com 経由で Gemini 画像系モデルを呼び出しているなら、まずはデフォルトの minimal 段階で業務フローを動かし、実際の画像品質を見ながら high に切り替えるべきか判断するのがおすすめです。このプラットフォームでは統一 API を提供しているため、gemini-3.1-flash-image、flash-lite-image、pro-image を同じコードで切り替えられ、A/B 比較もしやすくなっています。
thinkingLevel パラメータの詳細と呼び出し方法
thinkingLevel は独立したパラメータではなく、generationConfig の下にある thinkingConfig オブジェクト内にネストされていて、includeThoughts と組み合わせて使います。includeThoughts は、モデルの思考要約を呼び出し元に返すかどうかを決めるもので、thinkingLevel は思考の「強さ」を決めます。両者は分離された2つのスイッチなので、混同しないようにしてください。

下の表は、thinkingConfig オブジェクト内の2つの重要なフィールドの型と取りうる値をまとめたものです。
| フィールド | 型 | 値の候補 | デフォルト値 | 役割 |
|---|---|---|---|---|
| thinkingLevel | 列挙型文字列 | minimal / high |
minimal |
モデルの推論強度を制御。flash 系画像モデルでのみ有効 |
| includeThoughts | 真偽値 | true / false |
false |
応答に思考プロセスの要約を含めるかどうかを指定。課金には影響しない |
実際の呼び出しでは、主要な3言語とも書き方の構造はまったく同じで、config に thinkingConfig オブジェクトを入れるだけです。Python の例を示します。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI の統一ゲートウェイ経由で呼び出し
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "雪山のふもとでコーヒーを飲む猫を描いて"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
REST の生の呼び出し例を表示
{
"contents": [{"parts": [{"text": "雪山のふもとでコーヒーを飲む猫を描いて"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
対応する JavaScript SDK でも構造は同じで、REST の snake 表記を camelCase の thinkingConfig オブジェクトに置き換えるだけです。それ以外のフィールド名は変わりません。3言語の呼び出しロジックに本質的な違いはないので、「thinkingConfig は generationConfig の下にだけ置く」というルールだけ覚えておけば十分です。
ひとつ注意点があります。thinkingLevel の値は大文字・小文字を区別する文字列列挙ですが、公式サンプルでは "High" と "high" の両方が混在していました。実際に試すと、どちらもゲートウェイ側で正しく認識されて動作します。ただし、ドキュメント外の互換動作に依存しないためにも、業務コードでは小文字の "high" と "minimal" に統一しておくことをおすすめします。そうしておけば、将来的に上流側の大文字・小文字チェックが厳格化されても、本番呼び出しに影響しません。
おすすめ: APIYI apiyi.com で無料テスト枠を取得し、ゲートウェイ側で thinkingConfig が正しく透過されるかを直接確認すると、公式キーを別途申請してデバッグするよりずっと手軽です。
APIYI の実測データ:thinkingLevel が token と遅延に与える実際の影響
仕様書を読むだけでなく、実データを見ると理解がぐっと早くなります。同じプロンプトを使って、1K 解像度のテキストから画像生成を対象に、APIYI のゲートウェイ経由で gemini-3.1-flash-image の minimal 案、high 案、さらに gemini-3-pro-image に high パラメータを強制的に渡した場合の3パターンを測定しました。
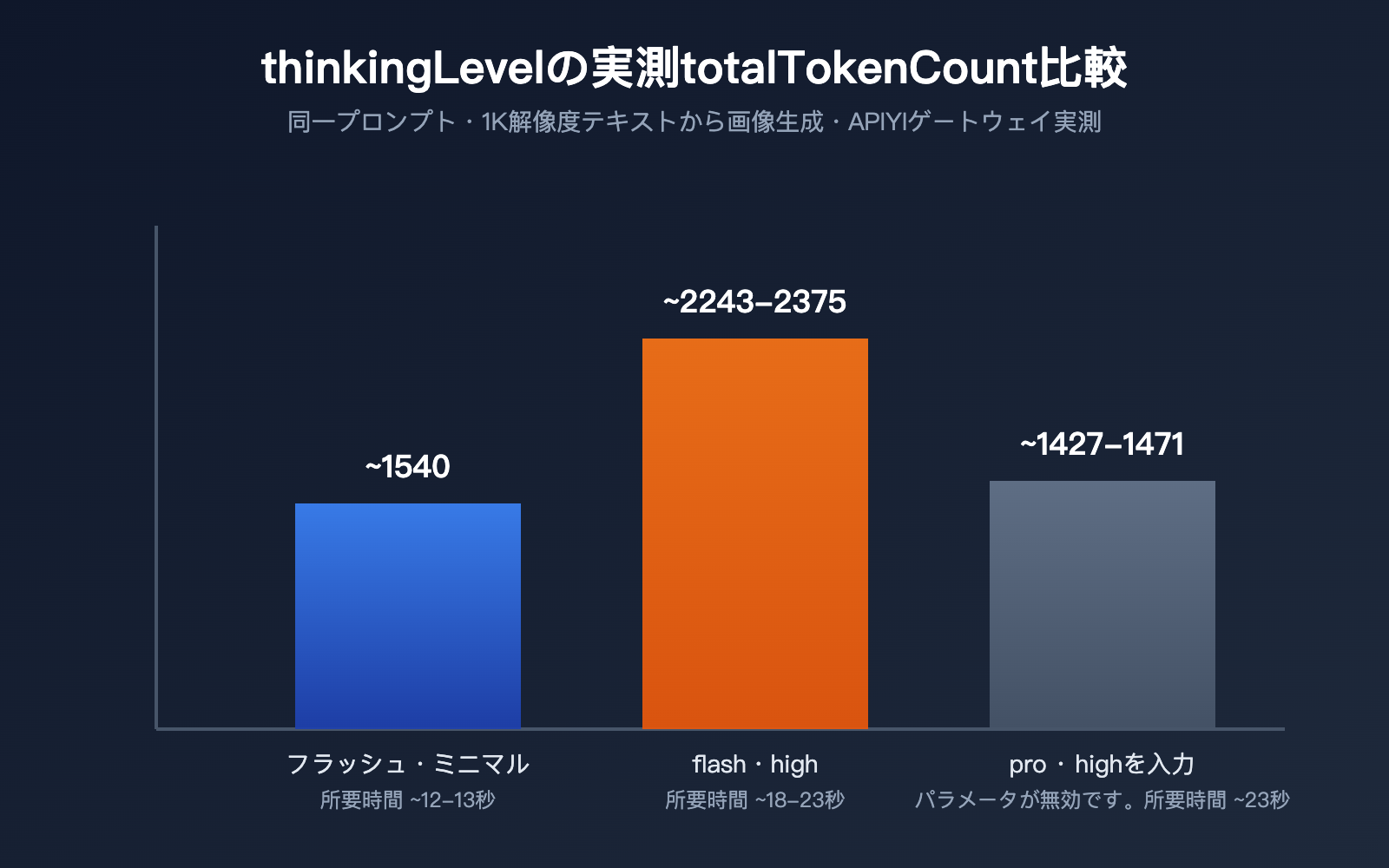
| モデル / 設定 | thoughtsTokenCount | 画像 tokens | totalTokenCount | 所要時間 |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal(デフォルト) | 該当フィールドなし | 1120 | 約 1540 | 約 12〜13 秒 |
| gemini-3.1-flash-image · high | 700〜792 | 1120 | 約 2243〜2375 | 約 18〜23 秒 |
| gemini-3-pro-image · high を指定 | 181〜214(デフォルトとほぼ同じ) | 1120 | 約 1427〜1471 | 約 23 秒 |
このデータから、3つの重要な傾向が読み取れます。第一に、thinkingLevel を high にすると、thoughtsTokenCount はデフォルトの 0 から一気に 700〜800 台まで増え、総 token 消費も約50%増加します。応答遅延も 12〜13 秒から 18〜23 秒へ伸びるので、思考には実際にコストと時間がかかることが分かります。第二に、minimal でも high でも、最終出力画像の token 数は常に 1120 のままで、thinkingLevel はモデルが「どう考えるか」だけに影響し、画像の解像度や画像自体の課金には影響しません。第三に、gemini-3-pro-image に high を渡してもエラーにはならず、181〜214 の思考 token はデフォルトとほぼ同じで、これは公式ドキュメントにある「pro-image は思考挙動が固定で、外部から調整できない」という説明と一致します。
つまり、業務ロジックで thinkingConfig を共通化して flash、flash-lite、pro の3モデルにまとめて渡しても、pro-image はそのパラメータを静かに無視するだけで、エラーで処理が止まることはありません。ただし、期待どおりに思考強度が変わるわけでもありません。
補足すると、上記のデータは単発測定ではなく、同じプロンプトを各設定で複数回実行した結果から得たレンジです。そのため、high 案の thoughtsTokenCount が 700〜792 のように幅を持っています。思考系のタスクには一定のランダム性があり、モデルごとの中間推論経路が毎回完全に同じになるわけではないため、token 消費にも多少の揺れが出ます。ただし、量的な傾向と遅延の増加傾向は安定して再現できるので、high が minimal より速くなったり、思考 token が数千まで跳ね上がったりするような異常挙動は基本的に起きません。
画像モデルの思考 token と課金ルール
多くの開発者は、thoughtsTokenCount というフィールドを初めて見たとき、ついテキストモデルの思考コストと同じ感覚で捉えがちです。ですが、画像モデルの思考メカニズムは実際には2つに分かれて課金されるため、この点を理解しておくことがコスト管理ではとても重要です。
| 维度 | テキストモデルの思考 | 画像モデルの思考 |
|---|---|---|
| 思考成果の形式 | 純テキストの推論チェーン | テキスト要約 + 最大2枚の一時的な構図スケッチ |
| 思考テキストの token 規模 | 数千に達することもある | Pro プランでは 400 を超えず、Flash high プランでは約 700〜800 |
| 主なコスト負担フィールド | thoughtsTokenCount |
スケッチは candidatesTokenCount に含まれ、通常の画像 part として課金 |
| 1枚あたりのスケッチ課金基準 | 該当なし | 1K 解像度で約 1120 tokens、約 0.0336 ドル/枚 |
includeThoughts が課金に与える影響 |
影響なし、固定課金 | 影響なし、固定課金 |
公式ドキュメントでは、includeThoughts を true にしても false にしても、思考で発生した token は通常どおり課金されると明記されています。実測でもそれを確認できました。includeThoughts を有効にしても、返却される構造や総課金額に変化はなく、デバッグ用に思考要約テキストが追加されるだけです。言い換えると、includeThoughts は「見るかどうか」のスイッチであり、「支払うかどうか」のスイッチではありません。この点はかなり誤解されやすいところです。
さらに重要なのは、画像モデルの思考コストの大部分が thoughtsTokenCount にあるわけではなく、推論中に生成される一時的な構図画像にあるということです。公式文書によると、モデルは思考段階で最大2枚の一時画像を生成し、構図や論理の妥当性を試します。これらのスケッチは通常の画像 part として返され、candidatesTokenCount に計上され、出力画像の標準単価で課金されます。つまり、high プランで推論ベースの画像生成を1回行うと、実際には「見えない」スケッチが1〜2枚分、追加で発生している可能性があります。コスト見積もりではここを見落としやすいです。
具体的に計算すると、よりイメージしやすくなります。たとえば 1K 解像度の画像生成リクエストを high プランで実行し、思考テキストが約 750 tokens 消費されたとします。さらに、モデルが推論中に実際に2枚の一時スケッチを生成し、最終生成画像も含めると、理論上は3枚の画像 part が発生します。1枚あたり 1120 tokens、約 0.0336 ドルとして計算すると、3枚分の出力コストだけで 0.1 ドル近くになり、そこに思考テキスト分の費用が加わります。全体のコストは minimal プランの 2〜3倍になる可能性があります。なお、実際に2枚のスケッチが必ず出るわけではなく、モデルがその時のプロンプトをどう判断するかに依存します。そのため、high プランを使ったときの総 token 数が 2243〜2375 のような幅を持つのも自然です。きっちり2倍になるわけではありません。
💰 コスト最適化: token コストに敏感なチームでは、まず APIYI apiyi.com の呼び出しログで実際の
totalTokenCountを確認し、そのうえで high プランを恒常的に使うか判断するのがおすすめです。スケッチ課金を見落として予算超過するのを防げます。
どんな場面で high を使い、どんな場面でデフォルトの minimal を使うべきか
実測データを踏まえて、簡単な判断基準をまとめます。

| 業務シーン | 推奨プラン | 理由 |
|---|---|---|
| マーケティング用画像を大量生成し、構図精度の要求が高くない | minimal(デフォルト) | レイテンシーが低く、token コストも抑えやすい。日常的な画像生成には十分 |
| 複雑な複数主体の構図、文字レイアウトや空間関係を正確に守る必要がある | high | 追加の思考で構図精度が上がるため、品質に投資する価値がある |
| EC 詳細ページ、バナーなど、細部の許容範囲が狭い場面 | high | 再生成や修正の回数を減らせるため、総コストではむしろ安くなることがある |
| 応答速度がシビアなリアルタイム対話シーン | minimal | high プランはレイテンシーが 5〜10 秒伸びるため、強い対話体験には不向き |
gemini-3-pro-image を呼び出す |
設定不要 | このモデルは思考挙動が固定で、パラメータを渡しても反映されない |
要するに、high プランは「出力速度」より「一発で仕上がること」が重要な場面に向いています。もしアプリ側で何度も再試行したり、プロンプトを調整し続けてようやく納得のいく構図にたどり着くようなら、最初から high を使ったほうが、少し単価が高くても総合的には得になることが多いです。
実運用では、thinkingLevel をコードに固定値で埋め込まず、設定可能にしておくのが無難です。たとえば、API呼び出し元から渡される業務種別に応じて自動ルーティングする形です。バッチ処理はデフォルトで minimal、精密なレイアウトや複数主体の空間関係が重要なリクエストは high に切り替える、という運用なら、平均コストを抑えつつ重要な場面で品質も落としません。チームで flash、flash-lite、pro の3つのモデル呼び出しロジックを併用している場合は、パラメータのラップ層で一元的に処理し、thinkingLevel をサポートするモデルだけに渡すようにすると、pro-image に無効なパラメータを透過して調査しづらくなる問題を防げます。
🚀 すぐ始める: APIYI apiyi.com を使ってプロトタイプを素早く組むのがおすすめです。同じ
base_urlで minimal と high の両設定を切り替えて比較テストできるので、プランごとに認証情報を別々に設定する必要はありません。
よくある質問
Q1: gemini-3.1-flash-lite-image と gemini-3.1-flash-image の推論性能は同じですか?
両者は同じ thinkingConfig のパラメータ構造を共有しており、対応している段階も minimal と high です。ただし、flash-lite は軽量版として位置づけられているため、実際の思考の深さや最終的な画像の細部は、通常 flash-image より弱くなります。命名の規則から見てもその傾向は分かります。flash-lite 系列のテキストモデルは一貫して「より速く、より安く、精度はやや低め」という位置づけで、画像系列も同じトレードオフを引き継いでいます。high 段階を有効にすると、軽量モデルが複雑な構図で抱えやすい弱点をある程度補えますが、flash-image の性能に完全に追いつくのは難しいです。定量比較を行うなら、APIYI apiyi.com プラットフォームで両モデルを同時に呼び出し、同じプロンプトを使って thoughtsTokenCount と画像の仕上がりを直接比較するとよいでしょう。
Q2: gemini-3-pro-image に thinkingLevel パラメータを渡すとエラーになりますか?
エラーにはなりません。実測では、high パラメータを渡してもリクエストは正常に返り、thoughtsTokenCount は 181〜214 の範囲にとどまりました。パラメータを渡さない場合とほぼ同じなので、このモデルの内部的な思考挙動は固定されており、外部から調整できないことが分かります。複数モデルをまとめて呼び出す場合は、業務コード側でモデル名を個別に判定し、パラメータが有効になったと誤解しないようにするのがおすすめです。
Q3: high 段階を有効にした後、画像の解像度や品質パラメータも一緒に調整する必要がありますか?
必要ありません。実測データでは、minimal と high の両段階で画像 token は安定して 1120 でした。つまり、thinkingLevel はモデルの内部推論プロセスにのみ作用し、出力画像の解像度設定は変えません。解像度は引き続き imageConfig のサイズパラメータで個別に制御され、思考段階とは無関係です。言い換えると、thinkingLevel と解像度パラメータは互いに干渉しない 2 本の調整軸です。1 つは「どれだけ十分に考えるか」を、もう 1 つは「どれだけ大きく細かく描くか」を担当しており、自由に組み合わせられます。排他関係も連動関係もありません。
まとめ
gemini-3.1-flash-lite-image が推論モードに対応していることは、公式ドキュメントと APIYI の実測データの両方で確認済みです。thinkingLevel は minimal と high の 2 段階のみ選択でき、high を有効にすると思考 token は 700 以上に増え、総所要時間も約 5〜10 秒長くなりますが、最終画像の token 消費は変わりません。一方、gemini-3-pro-image はこのパラメータを受け付けてもエラーにはなりませんが、実際には効果がありません。「思考テキストは thoughtsTokenCount、構図の下書きは candidatesTokenCount で計上される」という 2 系統の課金ロジックを理解することが、画像生成コストを抑えるうえで重要です。複数の Gemini 画像モデルを素早く切り替えて検証したい場合は、APIYI apiyi.com の統一ゲートウェイを使ってテストするのがおすすめです。モデルごとに個別の APIキーを取得したり、呼び出しコードを維持したりする手間を減らせます。
本文データは APIYI 技術チームの実測に基づいています。Gemini 画像モデルのより詳しい呼び出し方法について相談したい場合は、APIYI apiyi.com から技術サポートまでお問い合わせください。
参考資料
- Gemini API 公式ドキュメント – 画像生成: 思考レベル(thinking levels)パラメータの説明
- リンク:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- リンク: