On May 19, 2026, Google officially launched Gemini 3.5 Flash at the I/O 2026 conference. As the first public model in the Gemini 3.5 series, it uses the API ID gemini-3.5-flash directly without a "preview" suffix, signaling that it is already in GA (General Availability) status. On the same day, the APIYI (apiyi.com) platform completed its integration. Developers can now invoke Gemini 3.5 Flash directly in their products using OpenAI-compatible interfaces. New users receive a $0.05 free credit upon registration, allowing for zero-cost integration testing.
What has shocked developers most is the "Flash outperforming Pro" phenomenon: in various agent and coding benchmarks like Terminal-Bench 2.1, MCP Atlas, Finance Agent v2, and GDPval-AA, it has scored higher than the previous flagship, Gemini 3.1 Pro. Meanwhile, its output speed is reportedly about 4 times faster than other cutting-edge models in its class. For teams running coding agents, tool-calling workflows, or processing long documents, this is the most important model upgrade to evaluate this May. We recommend using the free credits on APIYI (apiyi.com) to run your own real-world tasks before deciding whether to switch your production line to the 3.5 version.
What is Gemini 3.5 Flash: Google's Core Positioning for the Official Release
Gemini 3.5 Flash is the first lightweight flagship released by Google DeepMind in the Gemini 3.5 family, positioned as an "Agentic Flash." While retaining the low latency and high throughput of the Flash series, it brings the tool orchestration and multi-step reasoning capabilities previously reserved for the Pro models down to the Flash tier. Google emphasized at the launch that 3.5 Flash is their most powerful agent orchestration model to date, deployed simultaneously across Gemini apps, Google Search's AI Mode, Google Antigravity, Google AI Studio, and enterprise cloud services.
There are four key takeaways from this release. First, the model ID has no "preview" suffix; the internal version is 3.5-flash-05-2026, meaning it is provided as a GA release and bypasses the preview phase. Second, Dynamic Thinking is enabled by default, so the model automatically determines whether a problem requires a chain-of-thought process without requiring developers to manually toggle a thinking budget. Third, tool capabilities are fully enabled, including function calling, structured output, Search-as-a-Tool, and Code Execution, making it ready for complex agents. Fourth, the knowledge cutoff has been extended to January 2026, making it one of the most up-to-date knowledge bases among mainstream closed-source models.
The table below summarizes the core specifications of Gemini 3.5 Flash, with all data sourced from official Google AI for Developers documentation and English-language benchmarks from LLM-Stats and Artificial Analysis.
| Parameter | Gemini 3.5 Flash Value | Notes |
|---|---|---|
| Release Date | May 19, 2026 | Google I/O 2026 Keynote |
| Model ID | gemini-3.5-flash |
Official release, no preview suffix |
| Internal Version | 3.5-flash-05-2026 |
Matches Google AI Studio |
| Positioning | Agentic Flash · Tool Orchestration + Coding | Outperforms 3.1 Pro in multiple agent benchmarks |
| Context Window | 1,048,576 input tokens / 65,536 output tokens | i.e., 1M / 64K |
| Input Modalities | Text + Image + Audio + Video | Output is text-only |
| Dynamic Thinking | Enabled by default | No manual thinking budget configuration needed |
| Tool Capabilities | Function calling / Structured output / Search-as-a-Tool / Code Execution | Full agent tool stack |
| Knowledge Cutoff | January 2026 | Same era as GPT-5.5, Claude Opus 4.7 |
| API Access | OpenAI-compatible / Native Gemini API | APIYI (apiyi.com) supports both methods |
🎯 Integration Advice: The biggest change in Gemini 3.5 Flash is that "lightweight model + tool calling" is now a default capability. Therefore, the most cost-effective way to integrate it isn't just a simple swap, but placing it in the "tool orchestration layer" of your agent workflow. We suggest using the unified interface on the APIYI (apiyi.com) platform to claim your $0.05 free credit, run a regression test by switching your existing GPT-5.5 Instant / Claude Haiku 4.5 / Gemini 3.1 Flash workflows to
gemini-3.5-flash, and then decide whether to move to production.
Gemini 3.5 Flash Pricing and Context Window Specs at a Glance
The pricing of Gemini 3.5 Flash is another major point of contention in this release. Google has bumped up the price of the Flash series from $0.50 / $4 for the 3 Flash Preview to $1.50 / $9 for the 3.5 Flash, bringing it closer to the $2 / $12 price point of Gemini 3.1 Pro. Simon Willison’s take in the English-speaking community is that Google is "testing the price tolerance of API customers." It also suggests that the goal of 3.5 Flash isn't to be cheaper, but to deliver Pro-level intelligence at Flash-tier costs.
The table below compares the official pricing of Gemini 3.5 Flash with other mainstream models in the same tier to help you decide if it's cost-effective for your specific workloads. All prices are in USD per 1 million tokens.
| Model | Input Price | Output Price | Cached Input | Context Window |
|---|---|---|---|---|
| Gemini 3.5 Flash | $1.50 | $9.00 | $0.15 | 1M / 64K Output |
| Gemini 3.1 Pro | $2.00 | $12.00 | $0.20 | 1M / 64K Output |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | $0.025 | 1M / 64K Output |
| GPT-5.5 (Main) | $5.00 | $30.00 | $0.50 | 400K Input |
| Claude Opus 4.7 (1M) | $15.00 | $75.00 | $1.50 | 1M Input |
Keep three key comparison points in mind. First, compared to its sibling Gemini 3.1 Pro, Gemini 3.5 Flash is 25% cheaper but actually performs better in coding and Agent benchmarks, making it a clear "downgrade in price, upgrade in performance" opportunity for Pro users. Second, compared to GPT-5.5, Gemini 3.5 Flash costs less than a third per token while trailing by only 5 points on the Artificial Intelligence Index, making it a great choice for cost-sensitive chat and Agent workloads. Third, compared to Claude Opus 4.7, Gemini 3.5 Flash is only 2 points behind in overall intelligence but costs less than one-tenth per million tokens, which can save you a significant budget in extreme long-context scenarios.
💡 Pricing Optimization Tip: Gemini 3.5 Flash offers a cached input price of $0.15 / 1M, which is perfect for long system prompts and long-document RAG scenarios. We recommend enabling prompt caching on the APIYI (apiyi.com) platform to reuse fixed instructions, knowledge base snippets, and long conversation histories, which can further push your 1M token input costs down to the level of the 3.1 Flash-Lite.
Gemini 3.5 Flash Key Benchmarks: Real-World Comparison with Gemini 3.1 Pro
The most counter-intuitive data point from the Gemini 3.5 Flash release is that "Flash outperforms Pro." Both Google's official model card and independent English-language tests from LLM-Stats confirm this: in tasks like Agents, tool orchestration, coding, and financial analysis, 3.5 Flash actually scores higher than Gemini 3.1 Pro. It only falls slightly behind 3.1 Pro in pure academic reasoning (Humanity's Last Exam) and abstract reasoning (ARC-AGI-2).
The table below summarizes the key benchmark comparisons between Gemini 3.5 Flash and Gemini 3.1 Pro, with data sourced from official Google reports and public third-party evaluations.
| Benchmark | Gemini 3.5 Flash | Gemini 3.1 Pro | Gap | Focus Area |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 70.3% | +5.9 | Terminal Coding Agent |
| MCP Atlas | 83.6% | 78.2% | +5.4 | MCP Tool Invocation |
| Finance Agent v2 | 57.9% | 43.0% | +14.9 | Financial Document Agent |
| GDPval-AA (Elo) | 1656 | 1314 | +342 | General Agent Capability |
| CharXiv Reasoning | 84.2% | — | — | Chart Reasoning |
| Humanity's Last Exam | 40.2% | 44.4% | -4.2 | Pure Academic Reasoning |
| ARC-AGI-2 | 72.1% | 77.1% | -5.0 | Abstract Pattern Reasoning |
| Output Speed | ~284 token/s | Slower | — | Real-time Response |
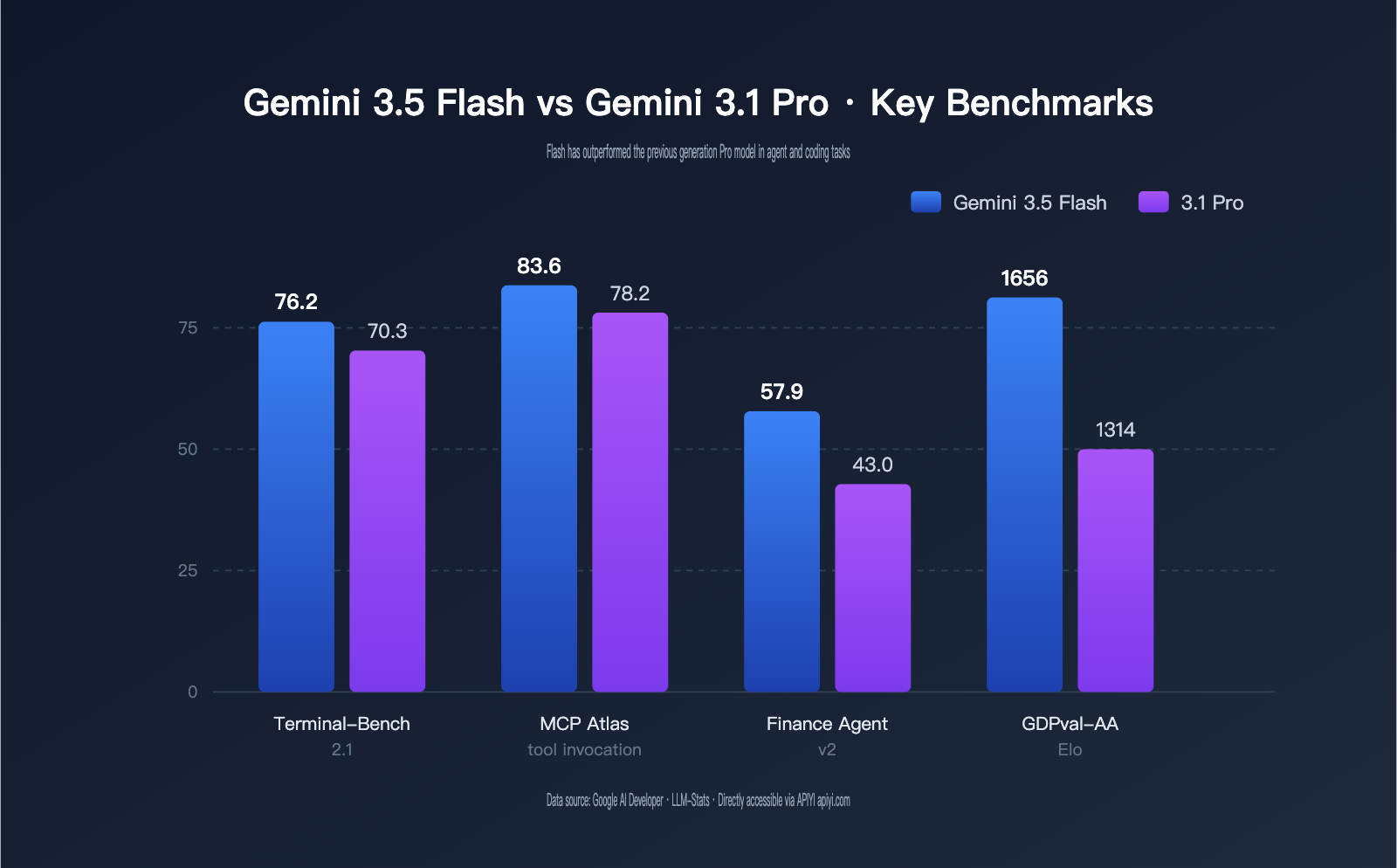
This data sends three clear signals. First, the "outperformance" of Gemini 3.5 Flash is concentrated in tool invocation and Agent tasks, with a +14.9 gain in Finance Agent v2 and a +342 Elo jump in GDPval-AA being quite significant. Second, pure static knowledge and abstract reasoning remain the strong suits of the Pro model; if your workload leans toward math competitions, academic reasoning, or long-chain logic puzzles, Gemini 3.5 Flash might not be the optimal solution. Third, Google is effectively using the Flash model to "re-segment the model lineage." According to reports, Gemini 3.5 Pro is expected to be released next month, which will further push the ceiling for the Pro tier.
It's worth highlighting the Artificial Intelligence Index. Gemini 3.5 Flash scored 55 points on this cross-benchmark composite index, trailing Claude Opus 4.7 by only 2 points and GPT-5.5 by only 5 points. Considering that 3.5 Flash's input price is one-tenth that of Claude Opus 4.7 and less than one-third of GPT-5.5, it is currently one of the most cost-effective "near-top-tier" models available. We recommend using it as your default Agent model on the APIYI (apiyi.com) platform to significantly reduce the operational burden of routing between different vendors.
Gemini 3.5 Flash Impact Analysis: What It Means for Developers
This release isn't just about having another model to choose from; Google has delivered a powerhouse on the "Flash + Agent" track that effectively rivals GPT-5.5 and Claude Opus 4.7. It’s set to reshape several key workflows over the next 1-2 quarters.
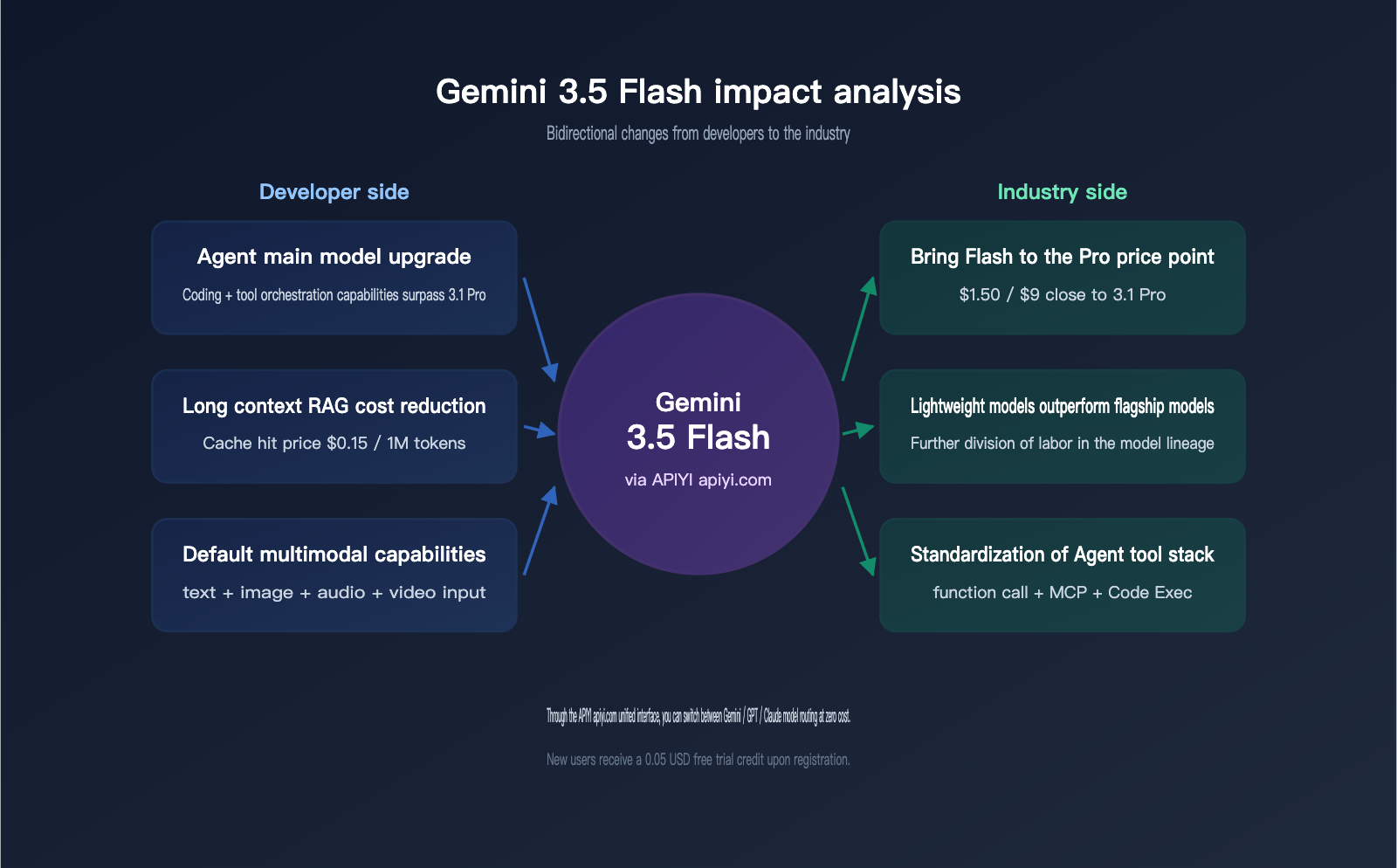
Direct Impact on Agent Developers
Agent teams are the biggest beneficiaries of Gemini 3.5 Flash. Based on benchmarks, the improvements in both Terminal-Bench 2.1 and MCP Atlas mean that traditional bottlenecks like "multi-step tool invocation + error recovery" have been addressed. The +14.9 gain in Finance Agent v2 shows significant progress in structured document processing. Global companies like Shopify, Macquarie Bank, Salesforce, Ramp, Xero, and Databricks are already listed by Google as early partners, covering use cases like data analysis, financial documents, enterprise automation, invoice OCR, tax workflows, and dataset monitoring. If your product features a "read document → call tool → output structured result" workflow, Gemini 3.5 Flash is a candidate you should evaluate immediately.
Impact on Long-Context RAG Applications
Gemini 3.5 Flash retains the 1M input + 64K output context window. Combined with the $0.15 / 1M cache-hit input price, it effectively brings "million-token long-context RAG" costs down to a level affordable for consumer-grade SaaS. A common benchmark: a 500k token fixed knowledge base prefix + 50k token user query results in an input cost of less than $0.10 per inference after cache hits—far cheaper than splitting the same context across GPT-5.5 or Claude Opus 4.7. We recommend routing your long-context RAG chains to gemini-3.5-flash via APIYI (apiyi.com); you can reuse your existing Gemini interface implementation for caching strategies.
Impact on Multi-Model Routing Strategies
With the launch of Gemini 3.5 Flash, mainstream multi-model routing strategies need a redesign. The old division of labor—"GPT for chat, Claude for code, Gemini for multimodal"—is obsolete because Gemini 3.5 Flash is now competitive in coding agents, tool invocation, and multimodal input simultaneously. We suggest using gemini-3.5-flash as your new "general-purpose tool model," while keeping GPT-5.5 Instant, Claude Opus 4.7, and Gemini 3.1 Pro as specialized backups. You can switch model routing at zero cost using the unified interface at APIYI (apiyi.com).
How to Access Gemini 3.5 Flash on APIYI and Get a Free Trial
Accessing Gemini 3.5 Flash on the APIYI (apiyi.com) platform is fully compatible with OpenAI, so developers don't need to rebuild their authentication or routing logic. New users receive a $0.05 trial credit upon registration, which is enough to run through official examples and complete a full regression test of your agent workflow.
Simple Invocation Example
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
response = client.chat.completions.create(
model="gemini-3.5-flash",
messages=[
{"role": "system", "content": "You are an agent orchestration engineer."},
{"role": "user", "content": "Please plan a toolchain that pulls issues from GitHub and generates a weekly report."},
],
)
print(response.choices[0].message.content)
View full invocation with function calling
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
tools = [
{
"type": "function",
"function": {
"name": "fetch_github_issues",
"description": "Fetch the list of issues for a specified repository",
"parameters": {
"type": "object",
"properties": {
"repo": {"type": "string", "description": "owner/repo"},
"state": {"type": "string", "enum": ["open", "closed", "all"]},
},
"required": ["repo"],
},
},
}
]
response = client.chat.completions.create(
model="gemini-3.5-flash",
messages=[
{"role": "user", "content": "Help me check the new issues opened this week in the anthropics/anthropic-cookbook repository"},
],
tools=tools,
tool_choice="auto",
)
print(response.choices[0].message)
💡 Trial Tip: At the $1.50 / $9 pricing for Gemini 3.5 Flash, your $0.05 credit covers roughly 30k-40k input tokens or 5,000 output tokens—plenty to replay your existing prompts on APIYI (apiyi.com). We recommend using the free credit to run a set of real-world tasks rather than just testing official examples; this will give you a more accurate sense of whether "Flash truly outperforms Pro" for your specific business needs.
Three Steps to Get Started
- Register an account at APIYI (apiyi.com) and complete the new user verification to claim your $0.05 free credit.
- Generate an API Key in the console, update your OpenAI SDK
base_urltohttps://api.apiyi.com/v1, and set themodelfield togemini-3.5-flash. - Reuse your existing prompts from GPT-5.5 Instant or Gemini 3.1 Pro Preview to compare response quality, latency, and token consumption side-by-side.
Gemini 3.5 Flash FAQ
Q1: Which is actually better: Gemini 3.5 Flash or Gemini 3.1 Pro Preview?
It really depends on your use case. In agentic and coding tasks—like Terminal-Bench 2.1, MCP Atlas, Finance Agent v2, and GDPval-AA—Gemini 3.5 Flash consistently outperforms Gemini 3.1 Pro. However, for pure academic reasoning (Humanity's Last Exam) and abstract reasoning (ARC-AGI-2), it falls slightly behind the 3.1 Pro. The takeaway: teams focused on agents, tool calling, coding, and long-document RAG should prioritize Gemini 3.5 Flash, while those focused on static reasoning or academic benchmarks might want to stick with 3.1 Pro. You can run a quick regression test using the free credit at APIYI (apiyi.com).
Q2: Why doesn’t Gemini 3.5 Flash have a “preview” suffix anymore?
This reflects Google's updated release strategy for the 3.5 series. 3.5 Flash is launching directly as GA (General Availability) with the model ID gemini-3.5-flash and internal version 3.5-flash-05-2026. This means it has passed full security evaluations and comes with a production-grade SLA. Unlike the phased rollout of the previous Gemini 3.1 Pro Preview, you can confidently integrate this into your production code without worrying about it being swapped out or deprecated unexpectedly.
Q3: How many Gemini 3.5 Flash requests can I run with $0.05 in free credits?
With pricing at $1.50 per 1M input tokens and $9 per 1M output tokens, $0.05 covers roughly 30,000 input tokens and 1,500 output tokens. That’s about 30–50 medium-length conversational calls—plenty to test your existing prompts against real tasks on APIYI (apiyi.com). If you enable prompt caching, cached hits are billed at just $0.15 per 1M tokens, which stretches your free credit even further.
Q4: Does Gemini 3.5 Flash support video and audio input?
Yes, it does. Gemini 3.5 Flash supports text, image, audio, and video inputs, with text-only output. Keep in mind that video and audio are billed based on their tokenized input costs. APIYI (apiyi.com) has already fully exposed these multimodal parameters in our API, so you can reuse your existing Gemini 3.x multimodal invocation code without any changes.
Summary: Gemini 3.5 Flash is the most worthwhile model upgrade to evaluate this May
To circle back to the most counterintuitive point: Gemini 3.5 Flash has surpassed the previous-generation Gemini 3.1 Pro in agentic and coding tasks, all while costing 25% less, featuring a knowledge cutoff updated to January 2026, and delivering output speeds that are reportedly 4x faster than other leading models in its class. For teams running agents, tool calling, long-document RAG, or enterprise automation workflows, this is the most important Google model upgrade to evaluate in the first half of 2026.
Gemini 3.5 Flash is now live on the APIYI (apiyi.com) platform. New users receive $0.05 in free credits upon registration, allowing you to complete your integration testing at zero cost. We recommend prioritizing it for the tool-scheduling layer of your agent workflows. By connecting via the OpenAI-compatible interface on APIYI (apiyi.com), you not only get first-hand access to Google's latest model upgrades but also the flexibility to route between models like Claude Opus 4.7, GPT-5.5 Instant, and Gemini 3.1 Pro.
Author: APIYI Technical Team · apiyi.com
Published: May 20, 2026
References: Google AI for Developers, LLM-Stats, Artificial Analysis, Simon Willison Blog, Interesting Engineering, 9to5Google