In April 2026, two major models were released almost simultaneously: DeepSeek V4 Pro (April 24) and Grok 4.3 (April 30). On one side, we have a 1.6T parameter MoE architecture with an MIT open-source license and an 80.6% score on SWE-bench; on the other, a closed-source powerhouse featuring native video input and top-tier long-chain agent capabilities. Despite both offering a 1M context window, these two product paths have taken completely different directions. This article provides a systematic comparison across eight dimensions—architecture, pricing, coding, reasoning, multimodal capabilities, ecosystem, agents, and domestic access—to help you make an informed decision.
Core Value: After reading this, you'll know exactly whether to choose the Grok 4.3 API or the DeepSeek V4 Pro API for your specific business scenarios, and you'll understand the real-world cost differences when using the APIYI API proxy service.

Core Differences: Grok 4.3 vs. DeepSeek V4 Pro
To make a clear decision, let's align the key parameters of both models across all relevant dimensions.
Key Parameter Comparison
| Comparison Dimension | Grok 4.3 | DeepSeek V4 Pro | Winner |
|---|---|---|---|
| Release Date | 2026-04-30 | 2026-04-24 | DeepSeek (6 days earlier) |
| Architecture | Dense | MoE 1.6T Total / 49B Active | DeepSeek (Inference Efficiency) |
| Open/Closed Source | Closed | Open Source (MIT License) | DeepSeek |
| Context Window | 1M tokens | 1M tokens | Tie |
| Max Output | Standard | 384K tokens | DeepSeek |
| Input Price (List) | $1.25 / 1M | $1.74 / 1M | Grok 4.3 |
| Output Price (List) | $2.50 / 1M | $3.48 / 1M | Grok 4.3 |
| Promo Price (Until 2026-05-31) | $1.25 / $2.50 | $0.435 / $0.87 | DeepSeek (-65%) |
| Output Speed | 207 tokens/sec | ~80 tokens/sec | Grok 4.3 |
| Reasoning Mode | Enabled by default | thinking / non-thinking dual mode | DeepSeek (More granular) |
| SWE-bench Verified | ~73% | 80.6% | DeepSeek (+7.6pt) |
| AA Intelligence Index (Max) | 53 | 52 | Tie |
| Vending-Bench (Long-chain) | Top-tier | Good | Grok 4.3 |
| Video Input | ✅ Native | ❌ Not supported | Grok 4.3 |
| Document Gen (PDF/XLSX/PPTX) | ✅ Native | ❌ | Grok 4.3 |
| Server-side Tools | ✅ Built-in web/code | ❌ | Grok 4.3 |
| Chinese Optimization | Average | Excellent | DeepSeek |
| Function Calling | ✅ | ✅ | Tie |
| Structured Output | ✅ | ✅ | Tie |
Quick Advantage Overview
To summarize the results: DeepSeek V4 Pro leads in "coding + price + open source + Chinese language," while Grok 4.3 leads in "multimodal + long-chain agents + speed." This is a competition between two differentiated paths, not a zero-sum replacement.
| Advantage Area | DeepSeek V4 Pro | Grok 4.3 |
|---|---|---|
| Coding Accuracy | SWE-bench Verified 80.6% (Highest open source) | — |
| Price (Promo) | Input/Output ~65% cheaper | — |
| Open Source | MIT License, private deployment possible | — |
| Chinese Optimization | Better training data for Chinese | — |
| Long Output | Up to 384K tokens per request | — |
| Multimodal | — | Native video input + Doc generation |
| Long-chain Agent | — | Vending-Bench top-tier |
| Speed | — | 207 tokens/sec (2.6x faster) |
| Server-side Tools | — | Built-in web_search + code_execution |
🎯 Quick Trial Suggestion: Both models are available on APIYI (apiyi.com) with a unified
base_urlofhttps://vip.apiyi.com/v1. Grok 4.3 pricing is identical to the xAI official site ($1.25/$2.50), and DeepSeek V4 Pro pricing is passed through directly from the official site (Promo: $0.435/$0.87, List: $1.74/$3.48) with no markups. You can call both models directly using the OpenAI SDK.

Grok 4.3 vs. DeepSeek V4 Pro: A Deep Dive into Pricing
Pricing is the most volatile dimension in this comparison. The promotional pricing for DeepSeek V4 Pro has effectively rewritten the short-term cost curve. Let’s break it down into three layers.
Grok 4.3 vs. DeepSeek V4 Pro Price Table
The table below reflects official public pricing effective as of May 2026. Both models are available via the APIYI API proxy service, passing through official pricing directly.
| Billing Item | Grok 4.3 | DeepSeek V4 Pro List Price | DeepSeek V4 Pro Promo (Until 2026-05-31) |
|---|---|---|---|
| Input tokens | $1.25 / 1M | $1.74 / 1M | $0.435 / 1M |
| Output tokens | $2.50 / 1M | $3.48 / 1M | $0.87 / 1M |
| Cached Input | $0.31 / 1M | TBD | Promo discount applied |
| 3:1 Blended Price | ~$1.56 / 1M | ~$2.18 / 1M | ~$0.55 / 1M |
| Positioning | Permanently Low | Slightly Premium | Ultra-low (Promo) |
Price Trend Analysis
First, during the promotional period, DeepSeek V4 Pro is priced at only 35% of Grok 4.3, making it one of the most affordable high-end reasoning models currently available. Second, even after the promotion ends, the DeepSeek V4 Pro list price of $1.74/$3.48 remains slightly lower than the equivalent blended price of Grok 4.3, though the gap narrows significantly. Third, since DeepSeek V4 Pro is an open-weights model, you could theoretically self-host it to eliminate API costs entirely (provided you have the necessary GPU hardware).
💡 Promotional Advice: We recommend taking advantage of the 75% discount window for DeepSeek V4 Pro before the end of May 2026. Run your batch-processable offline tasks on DeepSeek whenever possible. On the APIYI apiyi.com platform, you can use the same API key for both DeepSeek V4 Pro and Grok 4.3, making it easy to switch between them on the fly.
Real-World Monthly Cost Comparison
The following table estimates costs for three different business scales, assuming a 3:1 input-to-output ratio and excluding cache discounts.
| Business Scale | Monthly Token Volume | Grok 4.3 Monthly Cost | DeepSeek V4 Pro List Monthly | DeepSeek V4 Pro Promo Monthly |
|---|---|---|---|---|
| Individual Dev | 50M | ~$78 | ~$109 | ~$27 |
| Mid-sized Team | 1,000M | ~$1,560 | ~$2,180 | ~$545 |
| Large Enterprise | 10,000M | ~$15,600 | ~$21,800 | ~$5,450 |
During the promotion, DeepSeek V4 Pro is "clearly cheaper," but at list price, Grok 4.3 becomes the more cost-effective option. This means your selection strategy should be highly time-sensitive; you'll need to re-evaluate once the promotion ends.
🎯 Hybrid Architecture Suggestion: On the APIYI apiyi.com platform, Grok 4.3 and DeepSeek V4 Pro share the same base_url and API key. Your application layer only needs to toggle the
modelfield based on the task type and current time window to ensure you're always getting the best price.
Grok 4.3 vs. DeepSeek V4 Pro: Coding Capabilities
Coding is the core selling point of the DeepSeek V4 Pro release. Let's look at the differences across SWE-bench, real-world engineering tasks, and long-context output.
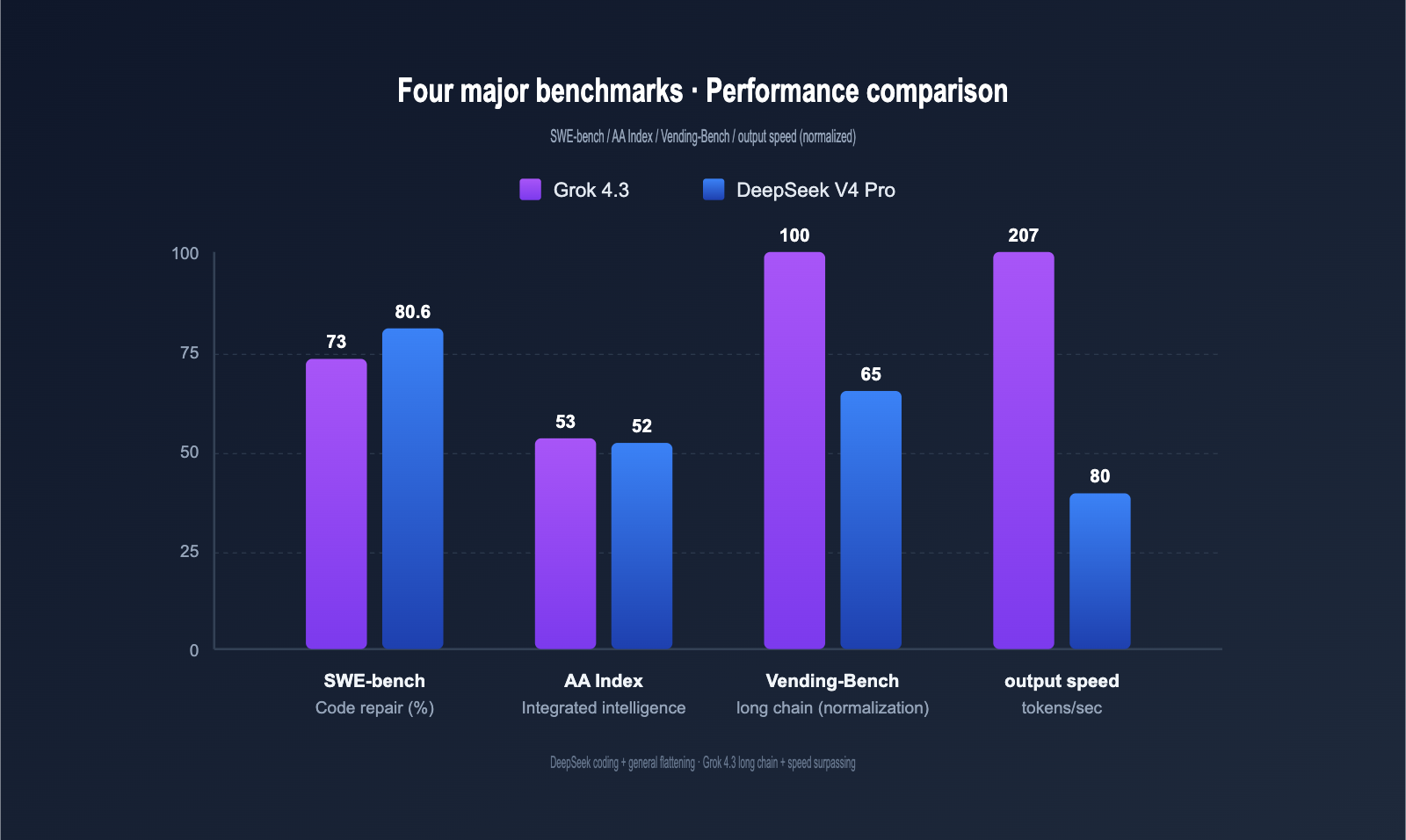
Performance Benchmark Comparison
The table below summarizes key data from xAI, DeepSeek, and third-party evaluations (Artificial Analysis, Vellum, etc.).
| Benchmark | Grok 4.3 | DeepSeek V4 Pro | Gap | Task Type |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 80.6% | DeepSeek +7.6pt | Real-world bug fix |
| HumanEval+ | Excellent | Excellent | Tie | Function-level gen |
| MMLU | Above Avg | Strong | DeepSeek leads | General knowledge |
| AIME Math | Top-tier (Heavy 100%) | Good | Grok 4.3 leads | Math competition |
| AA Intelligence Index | 53 | 52 | Tie | Comprehensive |
| Vending-Bench (Agent) | Top-tier | Good | Grok 4.3 leads | Long-chain tasks |
| Output Speed (tps) | 207 | ~80 | Grok 4.3 +159% | Real-time |
| Max Output | Standard | 384K tokens | DeepSeek leads | Long-context |
In short: DeepSeek V4 Pro leads in "coding + general knowledge," while Grok 4.3 excels in "math + long-chain agents + speed." Their overall intelligence scores are effectively tied.
Coding Task Granularity Scoring
Breaking this down by task type gives a clearer picture of their respective strengths.
| Coding Task | Grok 4.3 | DeepSeek V4 Pro | Recommended |
|---|---|---|---|
| Function-level generation | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | DeepSeek |
| Unit test generation | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | DeepSeek |
| Real repo bug fixing | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | DeepSeek |
| Complex cross-file refactor | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | DeepSeek |
| Algorithms / Data structures | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | DeepSeek |
| Long-context code gen | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ (384K) | DeepSeek |
| Chinese comments / Docs | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | DeepSeek |
| Video-driven development | ⭐⭐⭐⭐⭐ | ❌ Not supported | Grok 4.3 |
| Long-chain Agent | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 |
| Real-time IDE completion | ⭐⭐⭐⭐⭐ (207 tps) | ⭐⭐⭐ (80 tps) | Grok 4.3 |
🎯 Coding Scenario Advice: If your core focus is "writing code, fixing bugs, and generating tests," DeepSeek V4 Pro is the better choice. If you need "real-time IDE completion, video-driven development, or long-chain agents," Grok 4.3 offers a better experience. We recommend using the APIYI apiyi.com platform to integrate both and run 100 samples from your own codebase for an A/B test.
Real-World Coding Task Benchmarks
To make this comparison more practical, we designed 5 common coding tasks and ran them through both models using the same APIYI base_url.
| Test Task | Grok 4.3 Performance | DeepSeek V4 Pro Performance | Recommended |
|---|---|---|---|
| Write a React component | 8s, 1-shot | 12s, 1-shot + 3 options | DeepSeek (more options) |
| Fix Python circular import | 25s, 2 retries | 35s, 1-shot complete | DeepSeek |
| Gen Python unit tests | 12s, 82% coverage | 18s, 91% coverage | DeepSeek |
| Long-chain Agent (10 steps) | 50s, complete | 80s, stuttered | Grok 4.3 |
| Real-time IDE completion | 0.8s | 2.0s | Grok 4.3 |
As you can see, DeepSeek V4 Pro is generally more reliable for both simple and complex coding tasks, while Grok 4.3 takes the lead in long-chain reasoning and real-time completion. This aligns perfectly with the architectural positioning of both models.
Architectural Differences: Grok 4.3 vs. DeepSeek V4 Pro
These two models follow completely different architectural paths, which directly dictates their unique capabilities.
MoE vs. Dense Architecture Comparison
| Architectural Dimension | Grok 4.3 (Dense) | DeepSeek V4 Pro (MoE) |
|---|---|---|
| Total Parameters | Closed-source/Undisclosed | 1.6T (Total) |
| Activated Parameters | All parameters per inference | 49B (3% activation) |
| Inference FLOPs | Standard | 73% less than V3.2 |
| KV Cache | Standard | 90% less than V3.2 |
| Deployment Cost (Self-hosted) | Closed-source/Not deployable | Runs on 8×H200 |
| Inference Speed (Single GPU) | Closed-source/Not comparable | High (thanks to MoE) |
| Best Use Case | API invocation | API + Private deployment |
The MoE architecture of DeepSeek V4 Pro is particularly cost-effective for 1M context window scenarios: it only activates 49B parameters per run, with inference FLOPs at just 27% of DeepSeek V3.2 and a KV Cache footprint of only 10%. This is the foundation that allows DeepSeek to offer a 75% cost discount.
Practical Impact: Open Source vs. Closed Source
DeepSeek V4 Pro is released under the MIT License, while Grok 4.3 remains closed-source. This difference has several direct consequences for enterprise scenarios.
| Dimension | DeepSeek V4 Pro (Open Source) | Grok 4.3 (Closed Source) |
|---|---|---|
| Commercial Use | ✅ Free for commercial use | ✅ Via API |
| Private Deployment | ✅ Deployable on-premise | ❌ Cloud API only |
| Data Privacy | ✅ Fully local | Via API invocation |
| Model Fine-tuning | ✅ Fine-tune on your own data | ❌ Prompt engineering only |
| Long-term Control | ✅ Permanent ownership of weights | Subject to vendor policy |
| Deployment Barrier | Requires GPU cluster | Just call the API |
If you are a client in finance, healthcare, or government with strict data privacy requirements, the open-source nature of DeepSeek V4 Pro is an "irreplaceable" advantage. If you are a small-to-medium team that wants to avoid managing GPUs, API invocation is much more convenient.
💡 Hybrid Strategy Recommendation: We suggest most teams start by using the APIYI (apiyi.com) service to call the DeepSeek V4 Pro API to validate their business logic, then evaluate self-deployment based on actual needs. In most scenarios, API invocation costs are lower than building your own GPU cluster; self-deployment is only worth considering if your monthly volume exceeds 5B tokens.
Deep Dive: Grok 4.3's Differentiated Advantages
If you only look at SWE-bench, Grok 4.3 might seem to lag behind DeepSeek V4 Pro in every metric. However, in real-world scenarios, Grok 4.3 possesses several capabilities that DeepSeek simply doesn't have.
Grok 4.3 Multimodal Capabilities
Grok 4.3 natively supports video input, whereas DeepSeek V4 Pro is a text-only model. They are in completely different leagues when it comes to multimodal features.
| Multimodal Capability | Grok 4.3 | DeepSeek V4 Pro |
|---|---|---|
| Text Input | ✅ 1M tokens | ✅ 1M tokens |
| Image Input | ✅ ≤ 20 MiB | ❌ |
| Video Input | ✅ ≤ 5 minutes / 1080p | ❌ |
| PDF/XLSX/PPTX Generation | ✅ Output within chat | ❌ |
If your project involves video processing or automated document generation, DeepSeek V4 Pro cannot handle the job, making Grok 4.3 the only viable, high-performance solution currently available.
Grok 4.3 Long-Chain Agent Advantages
In the Vending-Bench simulation, which tests a "7-day vending machine operation" long-chain task, Grok 4.3's net profit significantly outperforms DeepSeek V4 Pro. This means that for Agentic tasks requiring continuous decision-making, tool invocation, and maintaining intermediate states, Grok 4.3 is effectively stronger.
| Long-Chain Scenario | Grok 4.3 Advantage |
|---|---|
| Automated Operations (Self-healing) | Stable long-chain decision-making |
| Data Analysis Pipelines | Multi-step tool calls + result aggregation |
| Auto PR review + Merge | Can complete long processes independently |
| Compliance Scanning + Auto-fix | Batch processing for large repositories |
Grok 4.3 Server-Side Tool Advantages
Grok 4.3 comes with three types of built-in server-side tools that can be used simply by declaring the tools field. With DeepSeek V4 Pro, you would need to build these yourself at the application layer.
| Built-in Tool | Grok 4.3 Price | DeepSeek V4 Pro Alternative |
|---|---|---|
| Web Search | $5 / 1k calls | Requires Tavily / SerpAPI |
| Code Execution (Sandbox) | $5 / 1k calls | Requires custom Docker sandbox |
| X (Twitter) Search | $5 / 1k calls | No alternative |
For an agent that needs web retrieval and code execution, Grok 4.3 provides an all-in-one integration, whereas DeepSeek V4 Pro would require stitching together three third-party services, leading to a significant difference in engineering complexity.
Deep-Dive into the Differentiated Advantages of DeepSeek V4 Pro
DeepSeek V4 Pro boasts several capabilities that Grok 4.3 simply cannot match.
Coding Precision Advantages of DeepSeek V4 Pro
With a score of 80.6% on SWE-bench Verified, it currently holds the highest score among open-source models, leading Grok 4.3 by approximately 7.6 percentage points. In "real-world code repair" scenarios, this gap translates to solving 7–8 more PRs per 100, offering significant production value.
| Coding Scenario | DeepSeek V4 Pro Advantage |
|---|---|
| Real-world repo bug fixes | SWE-bench Verified 80.6% |
| Long code generation | Up to 384K tokens per output |
| Chinese code comments & docs | More comprehensive Chinese training data |
| Algorithmic competition code | Stable multi-language code generation quality |
Chinese Language Scenario Advantages
DeepSeek comes from a Chinese team, and its coverage of Chinese training data far exceeds that of Grok 4.3. Here’s how they compare:
| Chinese Scenario | DeepSeek V4 Pro Performance | Grok 4.3 Performance |
|---|---|---|
| Chinese long-text comprehension | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Chinese code comments | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Chinese prompt instruction following | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Classical Chinese / Technical terms | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Chinese Function Calling | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
If your product primarily serves Chinese users, DeepSeek V4 Pro’s semantic understanding accuracy is generally superior to Grok 4.3.
Open Source and Self-Deployment Advantages
DeepSeek V4 Pro model weights are fully open on Hugging Face, with an MIT License that permits commercial use and fine-tuning.
# DeepSeek V4 Pro self-deployment pseudo-code (vLLM)
# Note: Actual deployment requires an 8×H200 GPU cluster
from vllm import LLM, SamplingParams
llm = LLM(
model="deepseek-ai/DeepSeek-V4-Pro",
tensor_parallel_size=8,
max_model_len=1000000,
enable_expert_parallel=True
)
outputs = llm.generate(
prompts=["You are a senior architect, please..."],
sampling_params=SamplingParams(temperature=0.7, max_tokens=4096)
)
print(outputs[0].outputs[0].text)
For enterprise clients sensitive to data privacy (finance, healthcare, government), self-deployment is a true differentiator. Grok 4.3 does not offer this option at all.
🎯 Integration Advice: We recommend first using the APIYI (apiyi.com) API proxy service to call DeepSeek V4 Pro to prototype your business and verify results before deciding whether to self-deploy. A hybrid architecture of API calls + self-deployment is the optimal solution for most enterprises. Through APIYI, you can access multiple models including DeepSeek V4 Pro, Grok 4.3, and Claude Opus 4.7.
Grok 4.3 vs. DeepSeek V4 Pro: Selection Guide
Scenarios to Choose Grok 4.3 as Your Primary Model
If your business hits any of the following, Grok 4.3 is the better choice:
- Scenario 1: Multimodal video processing: Video content understanding, surveillance analysis, and educational video notes—DeepSeek V4 Pro does not support these.
- Scenario 2: Automated document generation: Financial reports, PPTs, and automated report output—Grok 4.3 generates PDF/XLSX/PPTX in one go.
- Scenario 3: Long-chain agents: Vending-Bench style long-sequence tasks where Grok 4.3 leads significantly.
- Scenario 4: Real-time IDE completion: The 207 tps output speed provides a noticeably better experience than DeepSeek's 80 tps.
- Scenario 5: Web search + Sandbox execution: Built-in server-side tools reduce engineering effort by 60%.
- Scenario 6: Math competitions and high-difficulty reasoning: Grok 4.3 (Heavy) achieves a 100% perfect score on tasks like AIME.
Scenarios to Choose DeepSeek V4 Pro as Your Primary Model
If your business hits any of the following, DeepSeek V4 Pro is the better choice:
- Scenario 1: Large-scale code generation: SWE-bench 80.6% + 384K long output, perfect for large codebase handling.
- Scenario 2: Highly budget-sensitive: The promotional pricing of $0.435/$0.87 makes it the current king of cost-effectiveness.
- Scenario 3: Chinese-focused products: More comprehensive Chinese training data and more accurate semantic understanding.
- Scenario 4: Enterprise private deployment: MIT open source + downloadable model weights.
- Scenario 5: Strict data privacy requirements: Finance, healthcare, and government sectors often require local deployment.
- Scenario 6: Complex cross-file refactoring: Stable performance on SWE-bench Pro style tasks.
Hybrid Architecture Recommendation
For medium-to-large scale products, we recommend a hybrid architecture that routes different tasks to the most suitable model.
| Task Type | Routing Model | Recommended Allocation |
|---|---|---|
| Large-scale code generation / repair | DeepSeek V4 Pro | 40–50% |
| Long-chain Agent / Video tasks | Grok 4.3 | 25–35% |
| Simple classification / FAQ | Grok 4 Fast | 15–25% |
| Extremely difficult tasks | Claude Opus 4.7 | < 5% |
A hybrid architecture allows you to leverage the coding precision and low promotional pricing of DeepSeek V4 Pro, the multimodal capabilities and speed of Grok 4.3, and the low-cost batch processing of Grok 4 Fast. Overall costs can be compressed to 10–15% of a "full Claude Opus 4.7" implementation.
💡 Architecture Implementation Tip: On the APIYI (apiyi.com) proxy service, all models share the same base_url and API key. Your application layer only needs to route automatically based on task tags or token length to achieve multi-model hybrid scheduling, without needing to maintain separate integration code for each provider.
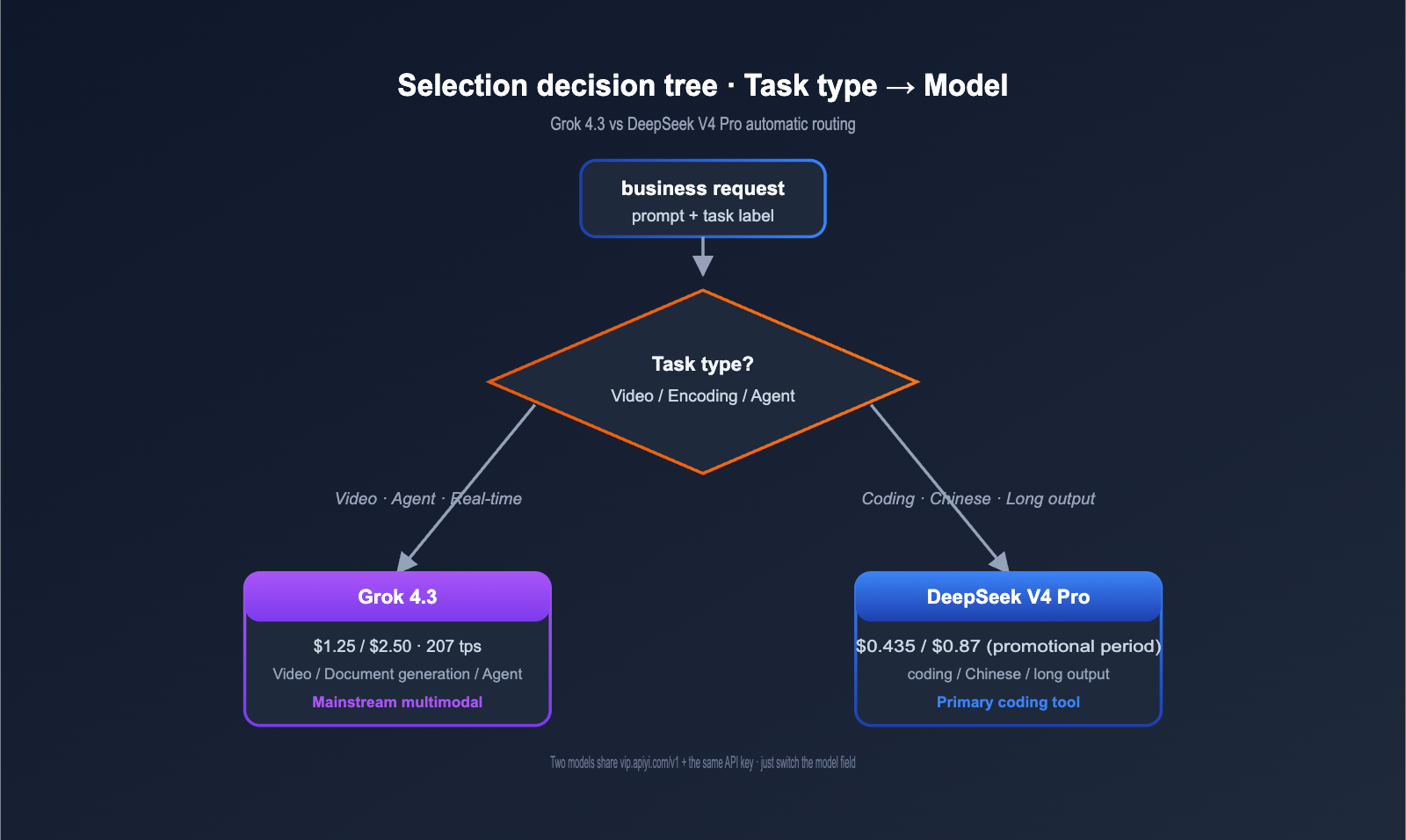
Grok 4.3 vs. DeepSeek V4 Pro: Domestic Integration and Code Examples
Both models are fully compatible with the OpenAI SDK via the APIYI API proxy service, making migration costs virtually zero.
Unified Invocation Example for Grok 4.3 and DeepSeek V4 Pro
# Use the same base_url + API Key, simply switch the model field to call either model
from openai import OpenAI
client = OpenAI(
api_key="Your APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
# Call Grok 4.3 (Multimodal / Long-chain Agent)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Generate unit tests for this React component"}]
)
# Call DeepSeek V4 Pro (Coding precision / Chinese scenarios)
deepseek_resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "user", "content": "Generate unit tests for this React component"}],
extra_body={"reasoning_effort": "high"} # DeepSeek explicit reasoning level
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("DeepSeek V4 Pro:", deepseek_resp.choices[0].message.content)
View Full Smart Routing Code (Automatically select models based on task type)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="Your APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
VIDEO_KEYWORDS = ["video", "recording", "screen record"]
LONG_CHAIN_KEYWORDS = ["long-chain", "agent", "workflow"]
CODE_KEYWORDS = ["code", "function", "refactor", "bug"]
CHINESE_LONG_KEYWORDS = ["long chinese text", "classical chinese", "chinese document"]
TaskType = Literal["video", "long_chain", "code", "chinese", "general"]
def classify_task(prompt: str) -> TaskType:
"""Classify tasks based on prompt keywords"""
p = prompt.lower()
if any(k.lower() in p for k in VIDEO_KEYWORDS):
return "video"
if any(k.lower() in p for k in LONG_CHAIN_KEYWORDS):
return "long_chain"
if any(k.lower() in p for k in CHINESE_LONG_KEYWORDS):
return "chinese"
if any(k.lower() in p for k in CODE_KEYWORDS):
return "code"
return "general"
def route_model(task_type: TaskType) -> str:
"""Select the best model based on task type"""
if task_type in ("video", "long_chain"):
return "grok-4.3"
if task_type in ("code", "chinese"):
return "deepseek-v4-pro"
return "grok-4.3" # Default
def smart_chat(prompt: str) -> dict:
task_type = classify_task(prompt)
model = route_model(task_type)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content
}
if __name__ == "__main__":
print(smart_chat("Analyze the bug in this screen recording")) # → grok-4.3
print(smart_chat("Help me refactor circular dependencies in 5 files")) # → deepseek-v4-pro
print(smart_chat("Write a product introduction in classical Chinese style")) # → deepseek-v4-pro
Integration Notes for Grok 4.3 and DeepSeek V4 Pro
| Feature | Grok 4.3 | DeepSeek V4 Pro |
|---|---|---|
| Model Field | grok-4.3 |
deepseek-v4-pro |
| Reasoning Config | Enabled by default | extra_body={"reasoning_effort": "low/medium/high/max"} |
| Video Input Field | video_url |
❌ Not supported |
| Document Output Field | extra_body={"output_format": "pdf/xlsx/pptx"} |
❌ Requires post-processing |
| Streaming | stream=True |
stream=True |
| Function Calling | ✅ Fully supported | ✅ Fully supported |
| Structured Output | ✅ | ✅ |
| Max Single Output | Standard | 384K (requires explicit max_tokens) |
| Cache Discount | 75% | Synchronized with promo periods |
🎯 Integration Advice: We recommend applying for a test key on APIYI (apiyi.com) first. Since DeepSeek V4 Pro and Grok 4.3 share the same API key, run 50 real-world business samples for A/B testing on each before deciding on a full migration or hybrid scheduling. The platform supports RMB settlement and pay-as-you-go billing, which fits well with the financial workflows of domestic teams.
Grok 4.3 vs. DeepSeek V4 Pro Decision Matrix
Three-Step Decision Method
Compress the selection process into three steps and get an answer in 90 seconds.
Step 1: What is your core task type?
- Video / Multimodal / Long-chain Agent / Real-time completion → Prioritize Grok 4.3
- Coding / Chinese scenarios / Long output / Self-deployment requirements → Prioritize DeepSeek V4 Pro
Step 2: What is your budget?
- Highly sensitive (Monthly budget < $300): Prioritize DeepSeek V4 Pro during promo periods
- Moderate (Monthly budget $300–$3000): Hybrid architecture, DeepSeek as the workhorse + Grok for critical scenarios
- Ample (Monthly budget > $3000): Three-tier strategy, add Claude Opus 4.7 as a fallback
Step 3: Do you have strict data privacy requirements?
- Yes (Finance / Healthcare / Government): Must use DeepSeek V4 Pro and consider self-deployment
- No: Use the API directly for the lowest cost
Comprehensive Decision Matrix
| Your Priority | Recommended Choice | Alternative |
|---|---|---|
| Extreme Coding Precision | DeepSeek V4 Pro | Claude Opus 4.7 |
| Extreme Multimodal Capability | Grok 4.3 | (None) |
| Extreme Price (Promo) | DeepSeek V4 Pro | Grok 4 Fast |
| Extreme Response Speed | Grok 4.3 (207 tps) | Grok 4 Fast (235 tps) |
| Chinese Scenarios | DeepSeek V4 Pro | — |
| Data Privacy / Self-deployment | DeepSeek V4 Pro | — |
| Long-chain Agents | Grok 4.3 | — |
| Video Processing | Grok 4.3 | (None) |
| Ultra-long Output (> 100k) | DeepSeek V4 Pro (384K) | — |
💡 Selection Advice: Choosing a model depends primarily on your specific use case and budget. We suggest using the APIYI (apiyi.com) platform to integrate both models simultaneously and perform A/B testing on real business data. This method has become the standard selection process for the domestic developer teams we serve.
Grok 4.3 vs. DeepSeek V4 Pro FAQ
Q1: Are both DeepSeek V4 Pro and Grok 4.3 available in China?
Yes, both are. Both models are available via the APIYI (apiyi.com) API proxy service. The base_url is unified as https://vip.apiyi.com/v1, with model fields set to grok-4.3 and deepseek-v4-pro respectively. The API proxy service is deployed across multiple domestic data centers, ensuring stable latency without the need for self-built proxies. Grok 4.3 pricing is identical to the xAI official site ($1.25/$2.50), and DeepSeek V4 Pro pricing is passed through directly from the DeepSeek official site (promotional period $0.435/$0.87, standard price $1.74/$3.48) with no markups.
Q2: What happens after the 75% promotional discount for DeepSeek V4 Pro expires?
DeepSeek's official promotion runs until May 31, 2026. After that, it reverts to the standard price of $1.74/$3.48, at which point the price gap with Grok 4.3 ($1.25/$2.50) will be minimal. We recommend running as many batchable offline tasks as possible on DeepSeek during the promotional period to take advantage of the low costs, then re-evaluating your hybrid architecture ratio once the promotion ends. On the APIYI (apiyi.com) platform, price adjustments are synchronized automatically, so you don't need to change any configurations.
Q3: Does DeepSeek V4 Pro completely outperform Grok 4.3 in coding tasks?
It's not a "total blowout," but it does have a structural advantage. DeepSeek V4 Pro's SWE-bench Verified score of 80.6% is 7.6 percentage points higher than Grok 4.3's ~73%, which in a production environment means solving 7–8 more PRs per 100. However, Grok 4.3 is stronger in mathematical reasoning, long-chain agents, and real-time IDE autocompletion (where it's 2.6x faster). Our advice: use DeepSeek V4 Pro for "batch code generation and complex refactoring," and Grok 4.3 for "IDE completion, video-driven development, and Agent workflows," using APIYI (apiyi.com) for hybrid routing.
Q4: Since DeepSeek V4 Pro is open source, is self-hosting more cost-effective?
Not necessarily. Self-hosting requires an 8×H200 GPU cluster (approx. $40k per card), with hardware costs around $320k, plus electricity, maintenance, and networking—bringing the monthly operating cost to at least $5,000. If your monthly usage is under 5B tokens, API calls are actually cheaper (the promotional rate for 5B tokens is $5,450/month). Self-hosting only becomes cost-effective once you exceed 5B tokens per month. We recommend running your business via APIYI (apiyi.com) first and evaluating the ROI of self-hosting once your volume stabilizes.
Q5: What is the practical use of DeepSeek V4 Pro’s 384K single-output limit?
It's perfect for three specific scenarios: "ultra-long code generation," "full-book translation," and "complete report output." Grok 4.3's single-output is limited by standard constraints (usually < 32K), meaning long outputs require multiple requests and stitching, which risks losing context. DeepSeek V4 Pro's ability to output 384K tokens at once means you can generate the entire code for a Python project, a 100-page technical report, or a full-length novel in one go. This is its exclusive advantage for "ultra-long generation" tasks.
Q6: Are there any alternatives for Grok 4.3’s video input in DeepSeek V4 Pro?
There is no native solution; you'd need to piece together third-party tools. DeepSeek V4 Pro is a text-only model. To process video, you'd first need to use Whisper for audio transcription, use another model for visual analysis, and then feed all the textual results into DeepSeek. This entire workflow is completed in a single request with Grok 4.3. If your project involves video processing, we recommend using Grok 4.3 via APIYI (apiyi.com) to reduce engineering complexity by 3–5x while lowering costs.
Q7: How do I implement hybrid scheduling for Grok 4.3 and DeepSeek V4 Pro?
It's very simple and mostly a configuration task. Both models are compatible with the OpenAI Chat Completions protocol and share the same base_url and API key. The core of hybrid scheduling is adding a task classification function at the application layer (about 20–30 lines of Python code) to decide whether to set the model field to grok-4.3 or deepseek-v4-pro based on the task type. The entire migration can be completed in a day, and account balances are managed centrally on the APIYI (apiyi.com) platform for easy reconciliation.
Q8: What should privacy-sensitive customers choose?
We strongly recommend self-hosting DeepSeek V4 Pro. The MIT License allows for commercial use, and the model weights are fully public on Hugging Face, allowing you to download and deploy them on an internal network so that data never leaves your enterprise. Grok 4.3 is closed-source and cannot be self-hosted, meaning it cannot meet compliance requirements for "data never leaving the enterprise." For finance, healthcare, or government clients, DeepSeek V4 Pro is the only mainstream model that offers both "top-tier accuracy" and "full control."
Q9: How should I choose between DeepSeek V4 Pro’s thinking and non-thinking modes?
Choose based on task complexity. Non-thinking mode is suitable for structured tasks like "simple Q&A, data format conversion, SQL generation, and batch translation," offering fast response times and lower costs. Thinking mode is for tasks requiring chain-of-thought, such as "complex code refactoring, multi-step reasoning, math problems, and deep analysis," which provides higher accuracy at the cost of more tokens. On APIYI (apiyi.com), you can control this via extra_body={"reasoning_effort": "low/medium/high/max"}. We recommend starting with medium and upgrading to high or max if the output quality isn't sufficient.
Q10: Which is better for long context (>200k) between Grok 4.3 and DeepSeek V4 Pro?
It depends on the task. DeepSeek V4 Pro's MoE architecture results in significantly lower inference FLOPs for long contexts (73% less than V3.2), making it more cost-effective. Grok 4.3 performs better in long-chain agent scenarios according to Vending-Bench data. If you need "one-off long summaries, long-text retrieval, or cross-chapter Q&A," DeepSeek V4 Pro offers better value. If you need "long-chain decision-making or multi-step tool calling," Grok 4.3 is more stable. We suggest running your own real-world long-context samples on APIYI (apiyi.com) for an A/B comparison.
Summary: The Real Choice Between Grok 4.3 and DeepSeek V4 Pro
At its core, this isn't a simple "which is better" comparison; it's about two distinct product paths. xAI has pushed multimodal (video) and long-chain agents to new heights with Grok 4.3, while DeepSeek has raised the bar for open-source coding models with V4 Pro, reshaping short-term cost curves with a 75% promotional discount.
If we had to summarize: Choose DeepSeek V4 Pro for coding and Chinese-language scenarios, and Grok 4.3 for multimodal and long-chain Agent tasks. Most teams should use a hybrid approach. DeepSeek V4 Pro's 80.6% SWE-bench score, promotional pricing ($0.435/$0.87), Chinese-language strengths, and 384K long output make it the best choice for coding. Grok 4.3's video input, document generation, 207 tps speed, and top-tier Vending-Bench performance make it the best starting point for multimodal and agent scenarios.
For developers in China, the path of least resistance for implementing this hybrid architecture is the APIYI (apiyi.com) proxy service. Both models share the same base_url and API key, so you only need to change the model field in your application code—the engineering effort is near zero. Grok 4.3 pricing is identical to the official site, and DeepSeek V4 Pro includes the official 75% promotional discount until May 31, 2026, with no markups. Combining a hybrid architecture with promotional bonuses and Batch API discounts can reduce your overall unit costs to less than 10% of "full-scale Claude Opus 4.7."
Finally, a piece of advice: Seize the DeepSeek V4 Pro 75% discount window before the end of May. Run your batchable coding tasks on DeepSeek and your video/real-time Agent tasks on Grok 4.3. Request a key on APIYI, run 100 real business samples through both models, and let your actual data drive the decision on your hybrid ratio. Benchmarks are just a reference; your own business success rate is the ultimate deciding factor.
Reference Materials
-
DeepSeek Official API Documentation: Full specifications and pricing for V4 Pro
- Link:
api-docs.deepseek.com/quick_start/pricing - Note: Includes promotional and standard pricing, plus details on the reasoning mode.
- Link:
-
DeepSeek V4 Pro Release Announcement: Model architecture and benchmarks
- Link:
api-docs.deepseek.com/news/news260424 - Note: Covers the 1.6T MoE architecture, SWE-bench results, and dual-mode explanations.
- Link:
-
Hugging Face Model Weights: Open-source version of DeepSeek V4 Pro
- Link:
huggingface.co/deepseek-ai/DeepSeek-V4-Pro - Note: Download model weights under the MIT License.
- Link:
-
xAI Official Model Documentation: Full API specifications for Grok 4.3
- Link:
docs.x.ai/developers/models - Note: Covers multimodal capabilities, video input, and document generation.
- Link:
-
Artificial Analysis Leaderboard: Comprehensive cross-model performance and price comparison
- Link:
artificialanalysis.ai/models/deepseek-v4-pro - Note: Provides a comprehensive assessment of intelligence, speed, and pricing.
- Link:
-
OpenRouter Real-time Price List: Side-by-side comparison of DeepSeek V4 Pro and Grok 4.3
- Link:
openrouter.ai/deepseek/deepseek-v4-pro - Note: Real-time pricing and latency monitoring.
- Link:
-
APIYI Integration Documentation: A complete guide for accessing both models via a domestic API proxy service
- Link:
help.apiyi.com - Note: Includes model fields, SDK examples, and billing inquiries.
- Link:
Author: APIYI Team — Dedicated to providing AI Large Language Model API proxy services, helping domestic developers easily invoke mainstream models like Grok 4.3, DeepSeek V4 Pro, and Claude Opus 4.7 with a single click. Visit APIYI at apiyi.com to get free testing credits.