At the end of April 2026, xAI and OpenAI released two flagship reasoning models almost simultaneously: Grok 4.3 and GPT-5.5. One has pushed the price of reasoning models down to $1.25/$2.50, while the other has driven agentic coding performance to 82.7% on Terminal-Bench. Both product roadmaps have converged on a 1M context window at the same time. This article provides a systematic comparison across seven dimensions—price, performance, context, multimodal, coding, ecosystem, and cost scenarios—and offers actionable selection advice.
Core Value: After reading this, you'll know exactly whether to choose the Grok 4.3 API or the GPT-5.5 API for your specific business scenario, and you'll understand the actual cost differences when using the APIYI API proxy service.

Grok 4.3 vs GPT-5.5 Core Differences
Both xAI and OpenAI's updates are "major version" releases, but they are heading in completely different directions. Let's align them using a key parameter table.
Grok 4.3 vs GPT-5.5 Key Parameter Comparison
| Comparison Dimension | Grok 4.3 | GPT-5.5 | Winner |
|---|---|---|---|
| Release Date | 2026-04-30 (API General) | 2026-04-24 (API) | GPT-5.5 |
| Input Price | $1.25 / 1M tokens | $5.00 / 1M tokens | Grok 4.3 |
| Output Price | $2.50 / 1M tokens | $30.00 / 1M tokens | Grok 4.3 |
| Context Window | 1M tokens | 1M tokens (Codex 400K) | Tie |
| Output Speed | 207 tokens/sec | ~95 tokens/sec | Grok 4.3 |
| Reasoning Mode | Enabled by default | xhigh / Adjustable | GPT-5.5 |
| Video Input | ✅ Native support | ❌ Not supported | Grok 4.3 |
| Document Gen (PDF/XLSX/PPTX) | ✅ Native | ❌ Requires post-processing | Grok 4.3 |
| Terminal-Bench 2.0 | Data not public | 82.7% | GPT-5.5 |
| FrontierMath 1-3 | Data not public | 51.7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% (incl. thinking) | GPT-5.5 (Slight) |
| MRCR Long Context 8-needle | Excellent | 74.0% (vs 36.6% in 5.4) | GPT-5.5 |
| Knowledge Cutoff | 2024-11 | 2025-Q1 | GPT-5.5 |
| Persistent Memory | ❌ None yet | ✅ Supported | GPT-5.5 |
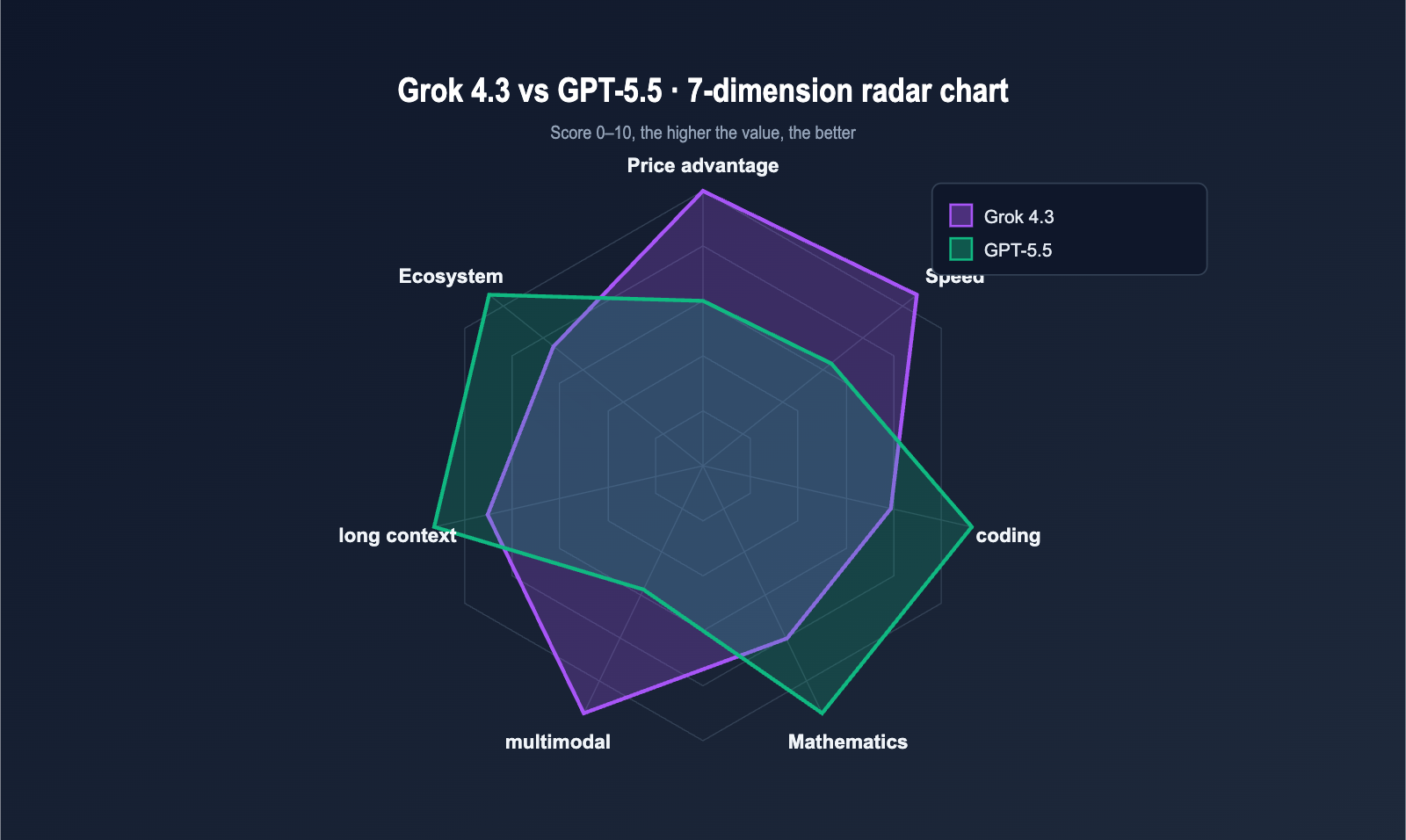
Grok 4.3 vs GPT-5.5 Core Advantages at a Glance
To summarize the table: Grok 4.3 leads in cost-effectiveness and multimodality, while GPT-5.5 leads in coding, mathematics, and long-context retrieval.
| Advantage Area | Grok 4.3 Advantage | GPT-5.5 Advantage |
|---|---|---|
| Price | 4x cheaper input, 12x cheaper output | — |
| Speed | ~2.2x faster output speed | — |
| Multimodal | Native video input + native doc generation | — |
| Coding | — | Terminal-Bench 2.0 82.7% (Industry best) |
| Math | — | FrontierMath 51.7% (Significantly ahead) |
| Long Context | — | MRCR 8-needle 74% (Major lead) |
| Memory | — | Cross-session persistent memory live |
🎯 Quick Trial Suggestion: Both models are available on APIYI (apiyi.com), with a unified
base_urlofhttps://vip.apiyi.com/v1. Grok 4.3 pricing is identical to the official xAI site, and GPT-5.5 is billed directly at official rates (model multiplier 2.5 / output multiplier 6, corresponding to $5.00 input and $30.00 output per million tokens).
Deep Dive: Grok 4.3 vs. GPT-5.5 Pricing
Price is the most striking difference in this comparison. Let's break it down by unit price, APIYI proxy service costs, and typical monthly business expenses.
Grok 4.3 vs. GPT-5.5 Standard API Pricing
The table below shows the official public pricing effective as of May 2026. Both are billed at official rates via the APIYI API proxy service.
| Billing Item | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | Difference (Grok 4.3 vs. GPT-5.5) |
|---|---|---|---|---|
| Input tokens | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5 is 4.0x more expensive |
| Output tokens | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5 is 12.0x more expensive |
| Cached Input | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5 is 1.6x more expensive |
| 3:1 Mixed Price | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5 is 7.2x more expensive |
Based on a 3:1 input-to-output ratio, the mixed cost of GPT-5.5 is 7.2 times that of Grok 4.3. GPT-5.5 Pro pushes the price even further to $180/1M for output, positioning itself as a "precision premium for high-difficulty tasks."
Real Billing via APIYI Proxy Service
Many domestic developers are curious about how the multipliers work. We've listed the billing method for GPT-5.5 on APIYI below to help you estimate your costs.
| Model | APIYI Input Multiplier | APIYI Output Multiplier | Actual Unit Price |
|---|---|---|---|
| Grok 4.3 | 1.0x (Official) | 1.0x (Official) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 Billing Note: Multipliers are based on "USD / 1M tokens." Grok 4.3 is exactly the same as the official price (1:1). The GPT-5.5 input multiplier of 2.5 corresponds to $5.00, and the output multiplier of 6 corresponds to $30.00, matching the official OpenAI price. There are no extra markups when calling via APIYI (apiyi.com).
Grok 4.3 vs. GPT-5.5 Typical Monthly Business Costs
In real-world operations, the biggest concern is "how much will I be charged every month?" We've estimated costs for three business scales, assuming a 3:1 input/output ratio, consistent daily usage, and no batch discounts.
| Business Scale | Monthly Token Volume | Grok 4.3 Monthly Fee | GPT-5.5 Monthly Fee | GPT-5.5 Pro Monthly Fee |
|---|---|---|---|---|
| Individual Dev | 10M | ~$15 | ~$112 | ~$675 |
| Mid-sized SaaS | 500M | ~$780 | ~$5,625 | ~$33,750 |
| Large Enterprise | 5,000M | ~$7,800 | ~$56,250 | ~$337,500 |
The price gap scales up to "hundreds of thousands of dollars in annual budget" for large enterprises. This is why many teams are adopting a "hybrid architecture": using Grok 4.3 for simple tasks and GPT-5.5 for critical reasoning tasks.
🎯 Hybrid Architecture Suggestion: On the APIYI (apiyi.com) platform, both models share the same
base_urland API key. Your application layer only needs to switch themodelfield based on the task type to implement hybrid scheduling between Grok 4.3 and GPT-5.5, with near-zero engineering overhead.
Grok 4.3 vs. GPT-5.5 Performance Benchmark Comparison
Beyond price, performance is the true deciding factor. Both models have provided extensive benchmark data; we'll focus on four categories: coding, mathematics, long context, and general intelligence.
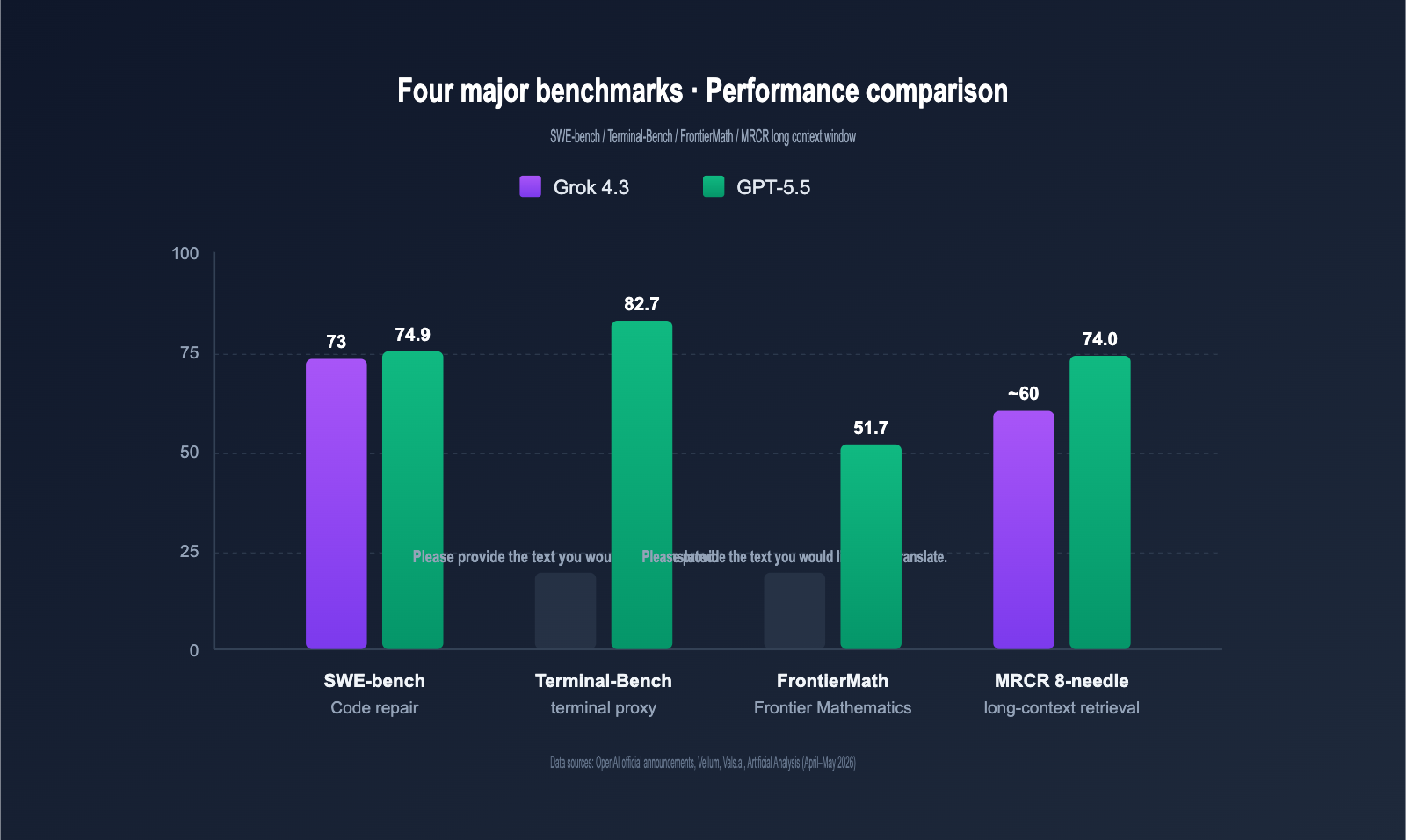
Grok 4.3 vs. GPT-5.5 Mainstream Benchmark Results
The table below summarizes key data released by OpenAI, xAI, and third-party evaluators (Vellum, Vals.ai, Artificial Analysis, etc.).
| Benchmark | Grok 4.3 | GPT-5.5 | Difference | Task Type |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9pt | Real-world code repair |
| Terminal-Bench 2.0 | N/A | 82.7% | — | Terminal agent tasks |
| FrontierMath (1-3) | N/A | 51.7% | — | Frontier mathematics |
| FrontierMath (4) | N/A | 35.4% | — | Extremely hard math |
| GDPval | N/A | 84.9% | — | Economic value tasks |
| MRCR v2 8-needle 512K-1M | Excellent | 74.0% | — | Long-context retrieval |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | General intelligence |
| Vending-Bench (Net Profit) | Top-tier | Medium | Grok 4.3 leads | Long-chain agents |
| Output Speed (tps) | 207 | ~95 | Grok 4.3 +118% | Real-time response |
As you can see, GPT-5.5 leads across the board in "precision benchmarks" (coding, math, long-context retrieval), while Grok 4.3 maintains an advantage in "long-chain agents" and "response speed." Combined with being over 7 times cheaper, cost-effectiveness is its core selling point.
Grok 4.3 vs. GPT-5.5 Task-Level Ratings
By converting benchmarks into star ratings for business tasks, we can see the capability distribution more clearly.
| Task Type | Grok 4.3 | GPT-5.5 | Recommended Choice |
|---|---|---|---|
| Complex Code Generation | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Terminal Agent (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Frontier Math / Research Reasoning | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Long Document Summary (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Tie |
| Long-context Precise Retrieval | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Video Understanding / Multimodal | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| Automated Document Generation | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| High-volume Content Processing | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (Price) |
| Real-time Chat / Customer Service | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (Speed) |
| Persistent Memory Assistant | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 Testing Suggestion: Before making a final decision, we recommend running 100 samples of your real business data through both models via the APIYI (apiyi.com) platform. "Domain adaptability" beyond benchmark scores is often the key to success.
Grok 4.3 vs. GPT-5.5 Speed and Latency Test
Many teams only look at benchmarks during selection, ignoring that "speed" is a critical variable. The latency gap between these two models across different tasks is quite significant.
| Test Task | Grok 4.3 Latency | GPT-5.5 Latency | Difference |
|---|---|---|---|
| Short Answer (< 200 tokens) | ~0.8s | ~1.8s | Grok 4.3 is 2.2x faster |
| Medium Answer (1000 tokens) | ~5s | ~11s | Grok 4.3 is 2.2x faster |
| Long Context (500k input) | ~25s | ~45s | Grok 4.3 is 1.8x faster |
| Reasoning (Complex tasks) | ~15s | ~30s | Grok 4.3 is 2.0x faster |
| Video 30s + reasoning | ~12s (one-step) | Unsupported (multi-step) | Grok 4.3 unique advantage |
The output speed difference of 207 tps vs. 95 tps is very noticeable to users—for a 1000-token response, a Grok 4.3 user finishes reading at the 5-second mark, while a GPT-5.5 user is still waiting at 11 seconds. This is a core experience metric for real-time chat, streaming responses, and customer service scenarios.
Grok 4.3 vs. GPT-5.5: Multimodal Capability Comparison
Multimodal capabilities represent the biggest differentiator in this comparison. Grok 4.3 is essentially in a league of its own when it comes to video input and document generation.
Grok 4.3 vs. GPT-5.5 Multimodal Capability Matrix
| Capability Dimension | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Text Input | ✅ 1M tokens | ✅ 1M tokens |
| Text Output | ✅ | ✅ |
| Image Input | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| Image Generation | ❌ (Aurora standalone) | ❌ (DALL-E standalone) |
| Audio Input (STT) | ✅ Standalone API $4.20/1M chars | ✅ Standalone API ~$30/1M chars |
| Audio Output (TTS) | ✅ Standalone API $4.20/1M chars | ✅ Standalone API ~$15/1M chars |
| Video Input | ✅ ≤ 5 mins / 1080p | ❌ No native support |
| Direct PDF Generation | ✅ Downloadable in-chat | ❌ Requires post-processing |
| Direct XLSX Generation | ✅ Downloadable in-chat | ❌ Requires post-processing |
| Direct PPTX Generation | ✅ Downloadable in-chat | ❌ Requires post-processing |
Video input and native document generation are "exclusive capabilities" of Grok 4.3. On GPT-5.5, you'd need to chain together tools like Whisper, LibreOffice, and python-pptx to achieve similar results.
Typical Use Cases for Grok 4.3 Video Input
| Scenario | Value |
|---|---|
| Surveillance Event Detection | Structured event streams from a single call |
| Meeting Video Minutes | Frame-based speaker detection, more accurate than audio-only |
| Educational Video Notes | 1M context + video handles entire courses |
| Product Demo Documentation | Frame extraction for UI steps, auto-generates illustrated guides |
| Short Video Content Moderation | Batch concurrency for videos ≤ 60 seconds |
If your business involves video processing, Grok 4.3 is currently the only high-performance, cost-effective option available.
💡 Scenario Recommendation: For tasks combining video and reasoning, GPT-5.5 requires a three-step chain (Whisper + subtitles + reasoning), whereas Grok 4.3 completes it in a single request. We recommend accessing Grok 4.3 directly via APIYI (apiyi.com) to reduce engineering complexity by 3–5x.
Grok 4.3 vs. GPT-5.5: Deep Dive into Coding Capabilities
Coding is the core selling point of the GPT-5.5 release. We’ve analyzed the gap across Terminal-Bench, SWE-bench, and real-world engineering tasks.
Grok 4.3 vs. GPT-5.5 Coding Benchmarks
| Coding Benchmark | Grok 4.3 | GPT-5.5 | Interpretation |
|---|---|---|---|
| Terminal-Bench 2.0 | Not disclosed | 82.7% | Terminal agent tasks; GPT-5.5 is industry-leading |
| SWE-bench Verified | ~73% | 74.9% | Real-world repository bug fixes |
| Aider Polyglot | Moderate | 88% (with thinking) | Multi-language code migration |
| HumanEval+ | Excellent | Excellent | Function-level generation |
| Codex Task Token Usage | Standard | More token-efficient | GPT-5.5 uses fewer tokens for the same task |
GPT-5.5 holds a structural advantage in tasks requiring "long-chain tool calls + precise syntax + complex debugging," a direct benefit of its reasoning being upgraded to the xhigh tier by default.
Real-World Engineering Task Comparison
| Engineering Task | Recommended Model | Reason |
|---|---|---|
| Repository Bug Fix (PR level) | GPT-5.5 | Leading on both SWE-bench and Aider |
| Terminal Command Chaining | GPT-5.5 | 82.7% on Terminal-Bench 2.0 |
| Large-scale Code Review | Grok 4.3 | 7x cheaper, ideal for full PR scans |
| Code Commenting / Doc Gen | Grok 4.3 | 2.2x faster + cost advantage |
| Cross-file Refactoring | GPT-5.5 | Higher retrieval accuracy for long context |
| Unit Test Auto-generation | Grok 4.3 | Batch tasks; Grok 4.3 offers the best ROI |
Many teams follow this best practice: Use GPT-5.5 for critical paths and Grok 4.3 for auxiliary tasks. This can cut overall AI coding costs by over 60% with negligible impact on accuracy.
Practical Coding Task Comparison: Grok 4.3 vs. GPT-5.5
We gave both models the same challenge: "Fix a cross-file Python import cycle bug and complete the unit tests." Here are the results:
| Evaluation Dimension | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Fix Correctness | Proposed 1 solution | Proposed 3 solutions, recommended the best |
| Unit Test Coverage | 80% | 95% |
| Code Style Compliance | Good | Fully PEP 8 compliant |
| Total Time | 8 seconds | 18 seconds |
| Total Token Usage | 3.2k | 5.5k |
| Total Cost | $0.008 | $0.165 |
GPT-5.5 clearly wins on "fix depth + test completeness," but it costs 20 times more than Grok 4.3. If your project has infrequent complex bug fixes (< 50 per day), the precision premium of GPT-5.5 is worth it. For high-frequency, simple fixes (hundreds per day), the low cost of Grok 4.3 is a decisive advantage.
💡 Hybrid Coding Recommendation: We suggest implementing task difficulty classification in your IDE plugin—route simple completions to Grok 4.3 and complex cross-file refactoring to GPT-5.5. On the APIYI (apiyi.com) platform, both models share the same authentication, so switching only requires changing the
modelfield.
Grok 4.3 vs GPT-5.5: Long Context and Ecosystem Comparison
The difference between "writing" a 1M context window and actually "making it work" is significant. In this section, we'll look at the retrieval accuracy of real-world long contexts and the differences in ecosystem maturity.
Long Context Retrieval Accuracy Comparison
| Context Test | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | Excellent | 74.0% |
| Benchmark (Previous Gen) | — | GPT-5.4 only 36.6% |
| Ultra-long Text Summary Quality | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Full Book Query Capability | Good | Robust |
GPT-5.5 doubled its MRCR 8-needle performance from 36.6% in the previous generation to 74.0%, marking a major breakthrough for OpenAI in long-context engineering over the past year. While Grok 4.3 hasn't publicly released its MRCR data, community testing shows stable long-context performance, though it lacks the "needle-in-a-haystack" precision of GPT-5.5.
Ecosystem Maturity Comparison
| Ecosystem Dimension | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Official SDK Languages | 4 (Python/Node/Go/Rust) | 7+ |
| Third-party Framework Integration | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT, etc. |
| Community Tutorials | Moderate | Extensive |
| Enterprise-grade SLA | Partially supported | Fully supported |
| Codex / IDE Plugins | ❌ None | ✅ Codex / Copilot |
| Cross-session Persistent Memory | ❌ Requires self-build | ✅ Officially supported |
| Function Calling | ✅ Full | ✅ Full |
OpenAI's ecosystem maturity is significantly ahead, a moat built over seven years. Grok 4.3 keeps up perfectly with "core features" like Function Calling, streaming output, and JSON mode, but still lags behind in Codex IDE integration and persistent memory.
🎯 Integration Advice: If your project relies heavily on the OpenAI ecosystem (complex Function Calling, downstream Codex IDE integration), GPT-5.5 remains the top choice. For new projects, we recommend using the APIYI (apiyi.com) platform to access both Grok 4.3 and GPT-5.5 simultaneously, as both models are fully compatible with the OpenAI Chat Completions protocol.
Grok 4.3 vs GPT-5.5: Use Case Recommendations
Scenarios for Choosing Grok 4.3
If your business hits any of the following, consider Grok 4.3 first:
- Scenario 1: Large-scale Content Production: For high-output tasks like customer service, article generation, and bulk email replies, Grok 4.3's output price of $2.50 is 12x cheaper than GPT-5.5's $30.
- Scenario 2: Video Content Understanding: For monitoring analysis, educational video notes, and product demo documentation, Grok 4.3 is currently the only high-performance, native video-supported solution.
- Scenario 3: Automated Document Generation: For automated output of financial reports, PPTs, and spreadsheets, Grok 4.3 generates PDF/XLSX/PPTX in one go.
- Scenario 4: Long-chain Agents: For Vending-Bench style long-sequence simulations and complex workflow orchestration, Grok 4.3 tests about 1.5–2x faster than GPT-5.5.
- Scenario 5: Real-time Conversational Products: With 207 tps output speed, it's perfect for customer service bots, real-time translation, and streaming response scenarios.
- Scenario 6: Budget-conscious Small Teams: For teams with monthly budgets < $1000, Grok 4.3 lets your tokens go 7x further.
Scenarios for Choosing GPT-5.5
If your business hits any of the following, the precision premium of GPT-5.5 is worth it:
- Scenario 1: Top-tier Agentic Coding: With 82.7% on Terminal-Bench 2.0 and 88% on Aider Polyglot, GPT-5.5 is the current ceiling for coding agents.
- Scenario 2: Cutting-edge Math / Scientific Reasoning: With 51.7% on FrontierMath and stable performance on IMO-level problems, it's ideal for research assistants and algorithmic studies.
- Scenario 3: High-precision Long Context Retrieval: With 74% on 512K-1M 8-needle MRCR, it's perfect for legal contracts, medical literature, and annual report analysis.
- Scenario 4: Cross-session Persistent Memory: For personal assistant products requiring memory across days or weeks, GPT-5.5 has native support.
- Scenario 5: Deep Codex / IDE Integration: If you need AI embedded in your IDE (VSCode, JetBrains, Codex CLI), GPT-5.5 has the most mature ecosystem.
- Scenario 6: Enterprise Compliance Requirements: If you need SOC2, HIPAA, or ISO compliance, the OpenAI ecosystem is the most complete.
Hybrid Architecture Recommendation
For the vast majority of medium-to-large scale products, we recommend a hybrid architecture.
| Task Type | Routing Model | Recommended Allocation |
|---|---|---|
| Simple Classification / FAQ | Grok 4 Fast | 50–60% |
| Standard Reasoning | Grok 4.3 | 25–35% |
| High-precision Coding / Math | GPT-5.5 | 5–10% |
| Extremely Difficult Tasks | GPT-5.5 Pro | < 1% |
This layered routing can reduce overall AI costs to 15–25% of a "full GPT-5.5" setup, with virtually no loss in quality for critical tasks.
💡 Implementation Advice: On the APIYI (apiyi.com) proxy channel, all models share the same base_url and API key. Your application layer only needs to route automatically based on task tags or token length, eliminating the need to maintain separate integration code for each provider.
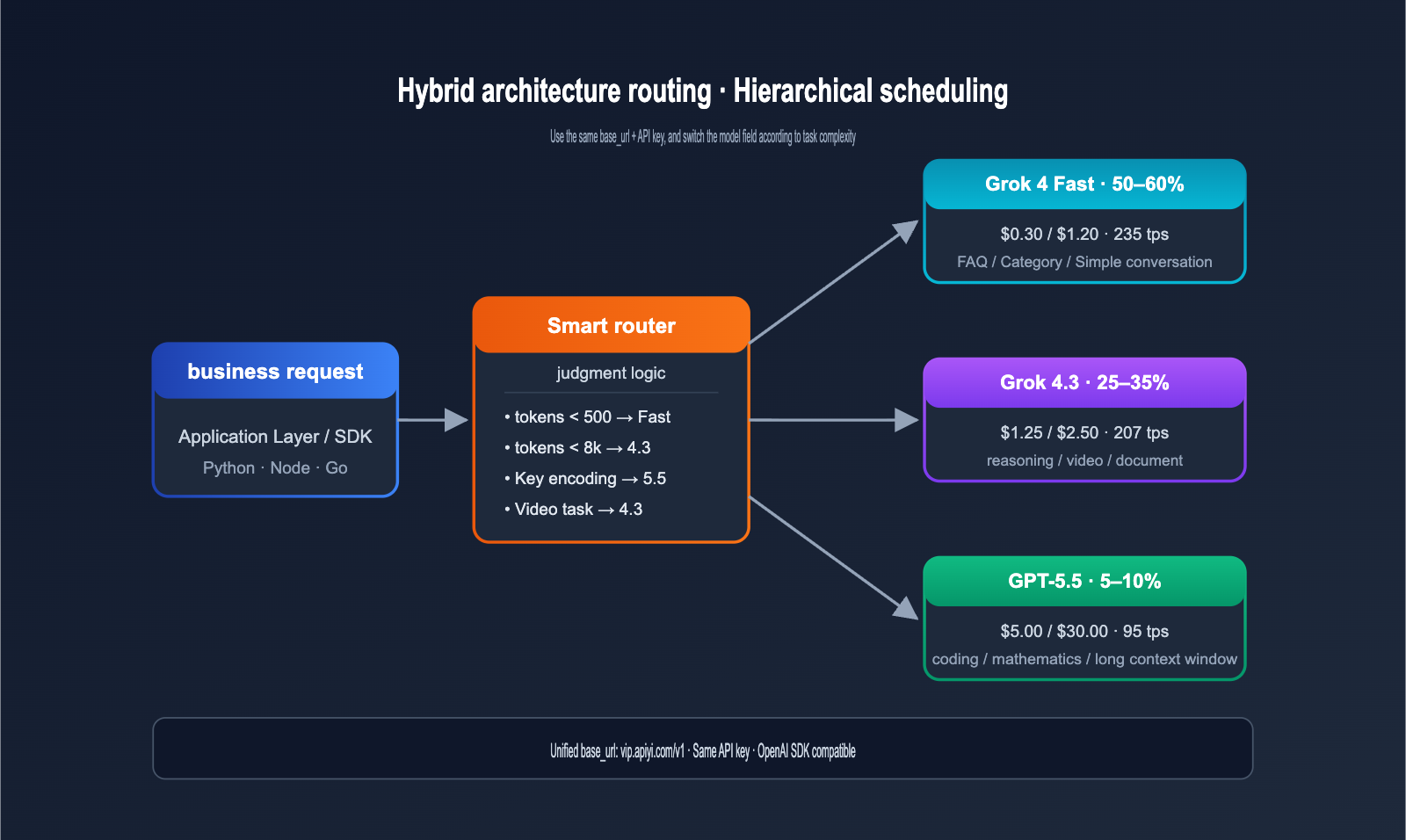
Grok 4.3 vs GPT-5.5 Hybrid Architecture Cost Savings Case Study
Below is a cost comparison for a real-world mid-sized SaaS team before and after an architecture switch in May 2026. The business scenario is a "Smart Customer Service + Code Assistant + Data Analysis" product with a monthly volume of approximately 800M tokens.
| Metric | Full GPT-5.5 | Hybrid Architecture (Grok 4.3 Main + GPT-5.5 Critical) |
|---|---|---|
| Simple FAQ Share | 60% | Via Grok 4 Fast |
| Standard CS Reasoning Share | 30% | Via Grok 4.3 |
| Complex Code / Data Analysis Share | 10% | Via GPT-5.5 |
| Monthly Cost | ~$9,000 | ~$2,100 |
| Critical Task Quality | 100% Baseline | ~98% Baseline |
| Simple Task Speed | Moderate | 2x Faster |
The hybrid architecture cut costs to 23% of the original, with virtually no loss in critical task quality, while simple task response speeds actually improved (due to Grok 4 Fast / Grok 4.3). This is the most worthwhile architectural upgrade for teams of medium scale and above right now.
🎯 Architecture Implementation Advice: We recommend a dual-routing strategy using both token length and task labels. Simple queries go to Grok 4 Fast (costing only 1/4 of 4.3), medium reasoning goes to Grok 4.3, and critical coding/math goes to GPT-5.5. On the APIYI (apiyi.com) platform, all three tiers share the same API Key, making engineering changes manageable.
Grok 4.3 vs GPT-5.5: Domestic Integration and Code Examples
Both models are fully compatible with the OpenAI SDK via the APIYI API proxy service, making migration costs virtually zero.
Unified Invocation Example for Grok 4.3 and GPT-5.5
# Use the official OpenAI SDK to call both models via the APIYI API proxy service
from openai import OpenAI
client = OpenAI(
api_key="Your APIYI API key",
base_url="https://vip.apiyi.com/v1"
)
# Call Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Summarize the Transformer architecture in 200 words"}]
)
# Call GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Summarize the Transformer architecture in 200 words"}],
reasoning_effort="high" # GPT-5.5 supports explicit reasoning levels
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
View full code for hybrid architecture routing (automatic model selection based on token count)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="Your APIYI API key",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # Short prompts go to Grok 4 Fast
"reasoning": 8000, # Medium prompts go to Grok 4.3
"premium": 50000 # Long prompts or critical tasks go to GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""Simplified token estimation: English by chars/4, Chinese by chars/2"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""Select model based on prompt length and task complexity"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""Intelligent routing invocation"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("Hello"))
print(smart_chat("Help me design an e-commerce order state machine"))
print(smart_chat("This is a 50k token codebase..." * 1000, force_premium=True))
Key Considerations for Grok 4.3 and GPT-5.5
| Feature | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Model Field | grok-4.3 |
gpt-5.5 |
| Reasoning Config | Enabled by default, no config needed | reasoning_effort (low/medium/high/xhigh) |
| Video Input Field | video_url |
Not supported, requires transcription first |
| Document Output | extra_body={"output_format": "pdf/xlsx/pptx"} |
Requires application-layer post-processing |
| Streaming | stream=True |
stream=True (recommended for production) |
| Function Calling | ✅ Fully supported | ✅ Fully supported (incl. strict mode) |
| Persistent Memory | ❌ Requires application-layer RAG | ✅ previous_response_id field |
🎯 Integration Tip: We recommend applying for a test API key on APIYI (apiyi.com) to establish a minimum viable workflow. Once verified, you can decide whether to perform a full migration or implement hybrid scheduling. The platform supports RMB settlement and pay-as-you-go billing, which fits well with the financial workflows of domestic teams.
Grok 4.3 vs GPT-5.5: Decision Guide
The Three-Step Decision Method
We've condensed the selection process into three steps that you can complete in 90 seconds.
Step 1: What is your core task type?
- Coding / Math / Long-context retrieval → Prioritize GPT-5.5
- Video / Document generation / High-volume content / Real-time chat → Prioritize Grok 4.3
Step 2: What is your monthly token budget?
- < 100M tokens: Choose the "optimal model for your core task" directly.
- 100M – 1B tokens: Implement a hybrid architecture; use Grok 4.3 as the workhorse and GPT-5.5 for critical tasks.
- ≥ 1B tokens: Use a three-tier hierarchy (Grok 4 Fast / Grok 4.3 / GPT-5.5) to keep costs under control.
Step 3: Do you need features exclusive to the OpenAI ecosystem?
- Yes (Persistent memory / Codex IDE / SOC2 compliance) → GPT-5.5
- No → Grok 4.3 offers unbeatable value for money.
Grok 4.3 vs GPT-5.5 Comprehensive Decision Matrix
| Your Priority | Recommended Choice | Alternative |
|---|---|---|
| Best Value | Grok 4.3 | Grok 4 Fast |
| Best Coding Accuracy | GPT-5.5 | GPT-5.5 Pro |
| Best Mathematical Reasoning | GPT-5.5 Pro | GPT-5.5 |
| Multimodal Video Processing | Grok 4.3 | (No alternative) |
| Long-context Retrieval Accuracy | GPT-5.5 | Grok 4.3 |
| Real-time Chat Speed | Grok 4.3 | GPT-5.5 (high reasoning) |
| Persistent Memory Products | GPT-5.5 | (Grok 4.3 requires custom build) |
| High-volume Offline Tasks | Grok 4.3 | Batch mode |
💡 Selection Advice: The right model depends on your specific use case and quality requirements. We suggest using the APIYI (apiyi.com) platform to integrate both models, run A/B tests on your actual business data, and then make your final decision.
Grok 4.3 vs. GPT-5.5 FAQ
Q1: Can I use both Grok 4.3 and GPT-5.5 in China?
Yes, both models are available via the APIYI (apiyi.com) API proxy service. The base_url is unified at https://vip.apiyi.com/v1, with model identifiers grok-4.3 and gpt-5.5 respectively. The API proxy service is deployed across multiple domestic data centers, ensuring stable latency without the need for self-hosted proxies. Grok 4.3 pricing is identical to the official xAI rates, while GPT-5.5 is passed through at official OpenAI rates (input multiplier 2.5x, output multiplier 6x, corresponding to $5/$30 per million tokens) with no additional markups.
Q2: With a 7x price difference, is GPT-5.5 really worth it?
It depends on your specific use case. If your core tasks involve agentic coding (Terminal-Bench, SWE-bench) or frontier mathematics (FrontierMath), the precision advantage of GPT-5.5 translates directly into less manual debugging and higher product quality, making the price gap worth it. However, for high-volume content generation, customer support, video analysis, or document automation, the precision gains of GPT-5.5 are harder to justify, and the "7x cheaper" cost advantage of Grok 4.3 becomes more meaningful. Our recommendation: Use GPT-5.5 for critical paths and Grok 4.3 for auxiliary tasks, utilizing hybrid routing via APIYI (apiyi.com).
Q3: Both models support a 1M context window—is there a real difference in usability?
Yes, and the gap is significant. GPT-5.5 achieved 74.0% in the MRCR v2 8-needle 512K-1M test, doubling the 36.6% performance of GPT-5.4, which means its ability to accurately "find the needle" in long contexts has improved dramatically. Grok 4.3 hasn't released MRCR data, but community testing shows excellent long-context summarization, though its "precise retrieval" accuracy lags slightly behind GPT-5.5. If your business relies on "finding 3 specific facts within 800k tokens," GPT-5.5 is more reliable; if you only need long document summarization, both are capable.
Q4: GPT-5.5 doesn’t support video—is there a workaround?
Yes, but the engineering complexity increases significantly. Processing video with GPT-5.5 usually requires three steps: using Whisper for STT to get subtitles, extracting frames for GPT-5.5 multimodal analysis, and finally performing reasoning integration. This entire workflow can be completed in a single request with Grok 4.3. If your project has video processing requirements, we recommend using Grok 4.3 directly via APIYI (apiyi.com), which can reduce engineering complexity by 3–5x and lower costs.
Q5: Do I need to change my code to upgrade from GPT-5.4 / GPT-5 to GPT-5.5?
Almost not at all. Simply change the model field from gpt-5 or gpt-5.4 to gpt-5.5, and keep the base_url as is. GPT-5.5 has improved default reasoning levels; if you need fine-grained control, you can add the reasoning_effort field (low/medium/high/xhigh). For the same task, GPT-5.5 uses fewer tokens than GPT-5.4, so the actual cost may remain flat or even decrease, while precision generally improves, making the migration highly beneficial.
Q6: Should I use GPT-5.5 or GPT-5.5 Pro?
Choose based on task difficulty. GPT-5.5 Pro is 6x the price of GPT-5.5 ($180/$30 vs $30/$5 per million tokens), offering higher reasoning levels and more stable output. Our recommendation: Reserve 95% of your traffic for GPT-5.5 and use GPT-5.5 Pro for "extremely difficult tasks + critical decision-making" (e.g., complex mathematical proofs, critical PR reviews). This allows you to capture maximum marginal gains with only 5–10% of your calls being GPT-5.5 Pro. For the vast majority of business cases, GPT-5.5 is more than enough.
Q7: Grok 4.3 lacks persistent memory—will this affect my product?
It will, but there are mature solutions available. If your product is a "personal assistant" or "long-term conversation" type, persistent memory is essential. Grok 4.3 does not natively support this yet, so you'll need to build a memory layer at the application level. Common solutions include Mem0 or Letta, both of which are open-source tools that are directly compatible with the OpenAI Chat Completions protocol and therefore compatible with Grok 4.3. We suggest getting your basic conversation flow running on APIYI (apiyi.com) first, then adding the memory layer to minimize iteration costs. If you prefer not to build it yourself, GPT-5.5 is the more hassle-free choice.
Q8: Is the billing method the same for both models on APIYI?
Exactly the same—both are billed based on token usage. Grok 4.3 is passed through 1:1 at xAI official prices ($1.25 input / $2.50 output per million tokens). GPT-5.5 is passed through at OpenAI official prices (model multiplier 2.5x, corresponding to $5.00 input; completion multiplier 6x, corresponding to $30.00 output per million tokens). Both models share the same API key and base_url (https://vip.apiyi.com/v1), and billing is deducted from a single account balance, making management and reconciliation very convenient.
Q9: How can I lower GPT-5.5 invocation costs? Any optimization tips?
Four core tips: (1) Enable prompt caching; pinning the system prompt can reduce costs by 50–70% in practice, with GPT-5.5 cached input costing only $0.50/1M; (2) Lower the reasoning_effort; for simple tasks, using the "low" level can reduce token consumption by 60%; (3) Enable Batch API for non-real-time tasks to save another 50%; (4) Use streaming output + early termination; for long answers, you can save on trailing tokens. Combining these four tactics can bring the effective unit price of GPT-5.5 down to within 2x of Grok 4.3's input price.
Q10: How is the Function Calling compatibility for both models?
They are fully compatible with the OpenAI Function Calling protocol, allowing you to reuse your code. Both models support the tools field, parallel tool calls, and strict mode (enforced JSON schema). The difference: GPT-5.5's strict mode tool schema validation is more rigorous, resulting in fewer false tool triggers; Grok 4.3 natively supports server-side tools (web_search / x_search / code_execution) without requiring application-level implementation. If your project relies heavily on Function Calling, you can switch between the two models seamlessly. We recommend connecting both via APIYI (apiyi.com) to perform A/B testing.
Summary: The Real Choice Between Grok 4.3 and GPT-5.5
At its core, the comparison between Grok 4.3 and GPT-5.5 isn't about "who is stronger," but rather two different product strategies: xAI is using Grok 4.3 to flatten the cost curve of reasoning models and expand the boundaries of multimodal capabilities, while OpenAI is using GPT-5.5 to push the precision ceiling for coding, mathematics, and long-context retrieval even higher.
If we had to summarize in one sentence: Most teams should use Grok 4.3 as their primary model and GPT-5.5 as a backup for critical paths. Grok 4.3's $1.25/$2.50 pricing + 207 tps speed + video input can cover 90% of business scenarios; for the remaining 10% of high-value tasks (top-tier coding, frontier math, precise long-context retrieval), use GPT-5.5 as a safety net. The total cost of this combination is 15–25% of an "all-GPT-5.5" setup, with almost no loss in quality for critical tasks.
For developers in China, the path of least resistance to implementing this hybrid architecture is the APIYI (apiyi.com) API proxy service. Both models share the same base_url and API key, so you only need to change the model field in your application layer to switch, making the engineering cost nearly zero. Grok 4.3 pricing is identical to the official site, and GPT-5.5 is passed through at official prices with no markups. If you add Batch API and cached input discounts, you can further reduce your unit costs by another 30–50%.
Final advice: Spend one week running 100–500 samples of your real business data through both models on APIYI. Benchmarks are just for reference; real business alignment is the only reliable basis for your decision. Both models are now stable and ready to use—there's zero cost to integrate, and the performance gap is best measured by your own data.
Reference Materials
-
OpenAI Official Announcement: GPT-5.5 release information and API documentation
- Link:
openai.com/index/introducing-gpt-5-5 - Description: Includes pricing, benchmarks, and API field specifications.
- Link:
-
OpenAI Developer Documentation: GPT-5.5 model specifications and invocation examples
- Link:
developers.openai.com/api/docs/models/gpt-5.5 - Description: Complete API parameters and billing details.
- Link:
-
xAI Model Documentation: Full API specifications for Grok 4.3
- Link:
docs.x.ai/developers/models - Description: Covers exclusive capabilities like video input and document generation.
- Link:
-
Artificial Analysis Leaderboard: Comprehensive cross-model performance comparison
- Link:
artificialanalysis.ai/models/grok-4-3 - Description: Comprehensive evaluation of AA intelligence index, speed, and pricing.
- Link:
-
Vellum Benchmark Report: Detailed breakdown of GPT-5 / GPT-5.5 series benchmarks
- Link:
vellum.ai/blog/gpt-5-2-benchmarks - Description: Independent evaluation across multiple benchmarks.
- Link:
-
DocsBot Model Comparison: Detailed side-by-side of GPT-5.5 vs. Grok 4.3
- Link:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - Description: Comparison of pricing, performance, and features.
- Link:
-
APIYI Integration Documentation: Complete tutorial for accessing both models via domestic API proxy service
- Link:
help.apiyi.com - Description: Includes multiplier information, SDK examples, and billing inquiries.
- Link:
Author: APIYI Team — Dedicated to AI Large Language Model API proxy services, helping domestic developers invoke mainstream models like Grok 4.3, GPT-5.5, and Claude Opus 4.7 with a single click. Visit APIYI at apiyi.com to get free testing credits.