2026年4月末、xAIとOpenAIはほぼ同時期に、推論能力を極めたフラッグシップモデル「Grok 4.3」と「GPT-5.5」をリリースしました。一方は推論モデルの価格を100万トークンあたり$1.25/$2.50まで引き下げ、もう一方はエージェントによるコーディング性能をTerminal-Benchで82.7%まで押し上げました。両者の製品戦略は、奇しくも同じタイミングで1M(100万)トークンのコンテキストウィンドウへと収束しています。本記事では、価格、性能、コンテキスト、マルチモーダル、コーディング、エコシステム、コストパフォーマンスの7つの観点から両者を徹底比較し、実用的な選定基準を提示します。
核心的価値: 本記事を読めば、あなたのビジネスシーンにおいてGrok 4.3 APIとGPT-5.5 APIのどちらを選択すべきかが明確になり、APIYIの中継サービスを通じた実際のコスト差を理解できるようになります。
<!-- 4 个核心参数 -->
<rect x="0" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="75" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">1M</text>
<text x="75" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">コンテキストウィンドウ</text>
<rect x="170" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="245" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">$1.25</text>
<text x="245" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">入力 / 1M</text>
<rect x="0" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="75" y="187" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">207</text>
<text x="75" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">トークン/秒</text>
<rect x="170" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="245" y="190" text-anchor="middle" font-family="Arial, sans-serif" font-size="14" font-weight="700" fill="#a855f7">ビデオネイティブ</text>
<text x="245" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">ドキュメント生成</text>
<text x="160" y="265" text-anchor="middle" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0" font-weight="600">コストパフォーマンス + マルチモーダル</text>
<rect x="0" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="75" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">100万</text>
<text x="75" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">コンテキストウィンドウ</text>
<rect x="170" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="245" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">$5.00</text>
<text x="245" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">入力 / 1M</text>
<rect x="0" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="75" y="187" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">82.7%</text>
<text x="75" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">Terminal-Bench</text>
<rect x="170" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="245" y="190" text-anchor="middle" font-family="Arial, sans-serif" font-size="14" font-weight="700" fill="#10b981">コーディングSOTA</text>
<text x="245" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">+ 永続的記憶</text>
<text x="160" y="265" text-anchor="middle" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0" font-weight="600">コーディング + 長いコンテキストウィンドウの検索</text>
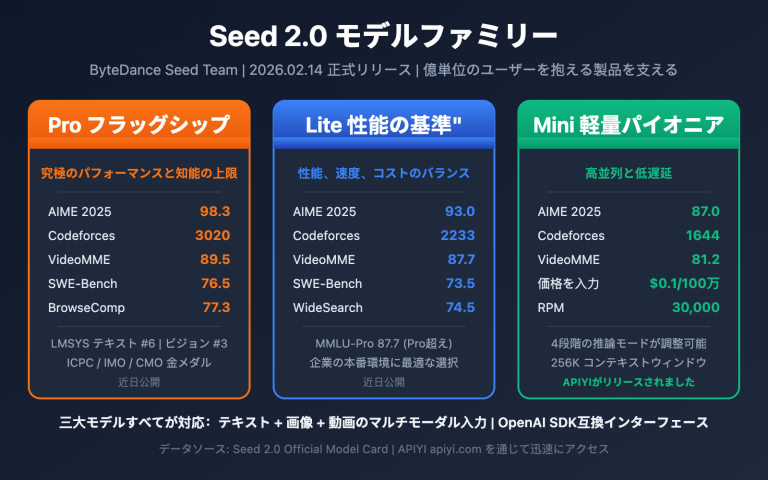
Grok 4.3 vs GPT-5.5 核心差异
xAIとOpenAIによる今回のアップデートは、いずれも「メジャーバージョンアップ」級のリリースですが、その方向性は大きく異なります。まずは、両者の主要パラメータを比較表で整理します。
Grok 4.3 vs GPT-5.5 关键参数对比
| 比較項目 | Grok 4.3 | GPT-5.5 | 勝者 |
|---|---|---|---|
| リリース日 | 2026-04-30 (API全量) | 2026-04-24 (API) | GPT-5.5 |
| 入力価格 | $1.25 / 1M tokens | $5.00 / 1M tokens | Grok 4.3 |
| 出力価格 | $2.50 / 1M tokens | $30.00 / 1M tokens | Grok 4.3 |
| コンテキストウィンドウ | 1M tokens | 1M tokens (Codex 400K) | 引き分け |
| 出力速度 | 207 tokens/秒 | ~95 tokens/秒 | Grok 4.3 |
| 推論モード | デフォルト有効 | xhigh / 調整可能 | GPT-5.5 |
| 動画入力 | ✅ ネイティブ対応 | ❌ 未対応 | Grok 4.3 |
| ドキュメント生成 (PDF/XLSX/PPTX) | ✅ ネイティブ | ❌ 後処理が必要 | Grok 4.3 |
| Terminal-Bench 2.0 | データ非公開 | 82.7% | GPT-5.5 |
| FrontierMath 1-3 | データ非公開 | 51.7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% (思考プロセス含む) | GPT-5.5 (僅差) |
| MRCR 長文脈 8-needle | 優秀 | 74.0% (5.4の36.6%に対し) | GPT-5.5 |
| 知識カットオフ | 2024-11 | 2025-Q1 | GPT-5.5 |
| 持続的記憶 | ❌ なし | ✅ 対応済み | GPT-5.5 |
Grok 4.3 vs GPT-5.5 核心优势速览
上記の表の勝敗データを一言でまとめると、Grok 4.3はコストパフォーマンスとマルチモーダル性能でリードし、GPT-5.5はコーディング、数学、長文脈検索でリードしていると言えます。具体的な差は以下の通りです。
| 優位性 | Grok 4.3 の強み | GPT-5.5 の強み |
|---|---|---|
| 価格 | 入力が4倍、出力が12倍安価 | — |
| 速度 | 出力速度が約2.2倍高速 | — |
| マルチモーダル | 動画ネイティブ入力 + ドキュメントネイティブ生成 | — |
| コーディング | — | Terminal-Bench 2.0 82.7%で業界最高 |
| 数学 | — | FrontierMath 51.7%で圧倒的リード |
| 長文脈 | — | MRCR 8-needle 74%で大幅な優位性 |
| 記憶 | — | セッションを跨ぐ持続的記憶が実装済み |
🎯 クイック試用アドバイス: 両モデルともAPIYI (apiiyi.com) にて利用可能です。ベースURLは
https://vip.apiyi.com/v1に統一されています。Grok 4.3の価格はxAI公式サイトと完全に一致しており、GPT-5.5は公式サイトの価格設定に基づき直接課金されます(モデル倍率2.5 / 出力倍率6、入力$5.00、出力$30.00 / 100万トークン)。
<!-- 7 条放射线: 七边形顶点,角度 -90 起每 51.43° -->
<line x1="0" y1="0" x2="0" y2="-180"/>
<line x1="0" y1="0" x2="140" y2="-112"/>
<line x1="0" y1="0" x2="176" y2="40"/>
<line x1="0" y1="0" x2="78" y2="162"/>
<line x1="0" y1="0" x2="-78" y2="162"/>
<line x1="0" y1="0" x2="-176" y2="40"/>
<line x1="0" y1="0" x2="-140" y2="-112"/>
Grok 4.3 vs GPT-5.5 価格の徹底解剖
今回の比較において、最も顕著な差が見られるのは「価格」です。単価、APIYI(API中継サービス)経由のコスト、そして典型的な業務における月額費用の3つの観点から詳しく見ていきましょう。
Grok 4.3 vs GPT-5.5 標準API価格
以下の表は2026年5月時点の公式公開価格です。いずれもAPIYIの中継チャネルにおいて、公式サイトの価格に基づいた料金設定となっています。
| 課金項目 | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | 差額 (Grok 4.3 vs GPT-5.5) |
|---|---|---|---|---|
| 入力トークン | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5 が4.0倍高価 |
| 出力トークン | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5 が12.0倍高価 |
| キャッシュ入力 | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5 が1.6倍高価 |
| 3:1 混合単価 | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5 が7.2倍高価 |
入力と出力の比率を3:1と仮定して換算すると、GPT-5.5の混合コストはGrok 4.3の7.2倍に達します。GPT-5.5 Proは出力単価を$180/1Mまで引き上げており、「極めて難易度の高いタスクに対する精度プレミアム」という位置付けです。
APIYI 中継チャネルの実際の課金
国内の多くの開発者が気になる「倍率の換算」について、GPT-5.5のAPIYIにおける課金方式をまとめました。コスト試算の参考にしてください。
| モデル | APIYI 入力倍率 | APIYI 出力倍率 | 実際の単価 |
|---|---|---|---|
| Grok 4.3 | 1.0x (公式価格) | 1.0x (公式価格) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 課金に関する説明: 倍率は「ドル / 1Mトークン」を基準としています。Grok 4.3は公式サイトの価格と完全に一致(1:1)しています。GPT-5.5の入力倍率2.5は$5.00、出力倍率6は$30.00に対応しており、OpenAI公式サイトの価格と同一です。APIYI apiyi.com を通じた呼び出しで追加料金が発生することはありません。
Grok 4.3 vs GPT-5.5 典型的な業務の月額費用
実際の業務において最も気になるのは「毎月いくらかかるのか」という点です。3:1の入力/出力比、毎日安定した呼び出し、Batch割引なしという条件で、3つの業務規模別に試算しました。
| 業務規模 | 月間トークン量 | Grok 4.3 月額費 | GPT-5.5 月額費 | GPT-5.5 Pro 月額費 |
|---|---|---|---|---|
| 個人開発者 | 10M | ~$15 | ~$112 | ~$675 |
| 中規模SaaS | 500M | ~$780 | ~$5,625 | ~$33,750 |
| 大規模企業 | 5,000M | ~$7,800 | ~$56,250 | ~$337,500 |
企業規模になると価格差は「年間数十万ドルの予算項目」へと拡大します。これが、多くのチームが「ハイブリッドアーキテクチャ」を検討し始めている理由です。単純なタスクはGrok 4.3に、重要な推論(Reasoning)タスクはGPT-5.5に任せるという手法です。
🎯 ハイブリッドアーキテクチャの提案: APIYI apiyi.com プラットフォームでは、両モデルが同一の base_url と APIキー を共有しています。アプリケーション層でタスクの種類に応じて model フィールドを切り替えるだけで、Grok 4.3 と GPT-5.5 の混合運用が可能になり、エンジニアリング上の改修コストはほぼゼロです。
Grok 4.3 vs GPT-5.5 パフォーマンス比較
価格以外に、選定の決め手となるのはパフォーマンスです。両モデルとも膨大なベンチマークデータを公開していますが、ここでは「コーディング」「数学」「長文コンテキスト」「総合知能」の4つのカテゴリーに注目します。
Grok 4.3 vs GPT-5.5 主要ベンチマーク成績
以下の表は、OpenAI、xAIの公式発表および第三者評価(Vellum、Vals.ai、Artificial Analysisなど)による主要データをまとめたものです。
| ベンチマーク | Grok 4.3 | GPT-5.5 | 差分 | タスクタイプ |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9pt | 実際のコード修正 |
| Terminal-Bench 2.0 | 未公開 | 82.7% | — | ターミナルエージェント |
| FrontierMath (1-3) | 未公開 | 51.7% | — | 最先端数学 |
| FrontierMath (4) | 未公開 | 35.4% | — | 超難問数学 |
| GDPval | 未公開 | 84.9% | — | 経済価値タスク |
| MRCR v2 8-needle 512K-1M | 優秀 | 74.0% | — | 長文コンテキスト検索 |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | 総合知能 |
| Vending-Bench (純利益) | トップ | 中等 | Grok 4.3 領先 | 長い連鎖のAIエージェント |
| 出力速度 (tps) | 207 | ~95 | Grok 4.3 +118% | リアルタイム応答 |
GPT-5.5は「精度重視のベンチマーク」(コーディング、数学、長文検索)でほぼ全面的にリードしていますが、Grok 4.3は「長い連鎖のAIエージェント」や「応答速度」で優位性を保っています。さらに価格が7倍以上安いという点は、Grok 4.3の強力な武器と言えます。
Grok 4.3 vs GPT-5.5 タスク別評価
ベンチマークを実際の業務タスクに置き換えて星評価を行うと、両者の能力分布がより直感的に理解できます。
| タスクタイプ | Grok 4.3 | GPT-5.5 | 推奨モデル |
|---|---|---|---|
| 複雑なコード生成 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| ターミナル Agent (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 最先端数学 / 科学推論 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 長文要約 (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 同等 |
| 長文コンテキストの正確な検索 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 動画理解 / マルチモーダル | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| 文書自動生成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| 大量コンテンツ処理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (価格優位) |
| リアルタイム対話 / カスタマーサポート | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (速度優位) |
| 持続的な記憶を持つアシスタント | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 テストの提案: 最終的な選定を行う前に、APIYI apiyi.com プラットフォームを通じて、実際の業務データで各モデルを100件ずつテストすることをお勧めします。ベンチマークの数値以上に、「ドメインへの適応度」こそが勝敗を分ける鍵となることが多いためです。
Grok 4.3 vs GPT-5.5 速度と遅延の実測
多くのチームが選定時にベンチマークばかりを見て、「速度」という重要な変数を無視しがちです。両モデルには、タスクごとの遅延に大きな差があります。
| テストタスク | Grok 4.3 遅延 | GPT-5.5 遅延 | 差分 |
|---|---|---|---|
| 短い回答 (< 200 tokens 出力) | ~0.8 秒 | ~1.8 秒 | Grok 4.3 が2.2倍速い |
| 中程度の回答 (1000 tokens) | ~5 秒 | ~11 秒 | Grok 4.3 が2.2倍速い |
| 長文コンテキスト (500k 入力) | ~25 秒 | ~45 秒 | Grok 4.3 が1.8倍速い |
| 推論を要する複雑なタスク | ~15 秒 | ~30 秒 | Grok 4.3 が2.0倍速い |
| 動画 30秒 + 推論 | ~12 秒 (1ステップ) | 非対応 (複数ステップ必要) | Grok 4.3 独自の強み |
207 tps と 95 tps という出力速度の差は、ユーザー体験において非常に明白です。同じ1000トークンの回答でも、Grok 4.3なら5秒で読み終えるところ、GPT-5.5では11秒待たされることになります。これはリアルタイム対話、ストリーミング応答、カスタマーサポートの現場においては、核心的な体験指標となります。
Grok 4.3 vs GPT-5.5 マルチモーダル能力の比較
マルチモーダル機能は、今回の比較において最も差が顕著な領域です。Grok 4.3 は、動画入力とドキュメント生成の面で、他を圧倒する「次元の異なる」性能を見せています。
Grok 4.3 vs GPT-5.5 マルチモーダル能力マトリックス
| 能力の次元 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| テキスト入力 | ✅ 1M トークン | ✅ 1M トークン |
| テキスト出力 | ✅ | ✅ |
| 画像入力 | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| 画像生成 | ❌ (Aurora が別途対応) | ❌ (DALL-E が別途対応) |
| 音声入力 (STT) | ✅ 独立 API $4.20/1M 文字 | ✅ 独立 API ~$30/1M 文字 |
| 音声出力 (TTS) | ✅ 独立 API $4.20/1M 文字 | ✅ 独立 API ~$15/1M 文字 |
| 動画入力 | ✅ ≤ 5 分 / 1080p | ❌ ネイティブ非対応 |
| PDF 直接生成 | ✅ チャット内で生成・DL可能 | ❌ 後処理が必要 |
| XLSX 直接生成 | ✅ チャット内で生成・DL可能 | ❌ 後処理が必要 |
| PPTX 直接生成 | ✅ チャット内で生成・DL可能 | ❌ 後処理が必要 |
動画入力とネイティブなドキュメント生成は Grok 4.3 の「独自機能」です。GPT-5.5 で同様の効果を得るには、Whisper + LibreOffice + python-pptx などのツールチェーンを組み合わせる必要があります。
Grok 4.3 動画入力の代表的な活用シーン
| シーン | 価値 |
|---|---|
| 監視カメラのイベント検知 | 1回の呼び出しで構造化されたイベントストリームを出力 |
| 会議の議事録作成 | 動画フレームから話者の切り替わりを認識し、音声のみより高精度 |
| 授業動画のチャプターノート | 1M のコンテキスト + 動画で講義全体を処理可能 |
| 製品デモのドキュメント化 | フレーム抽出でUI操作手順を認識し、図解チュートリアルを自動生成 |
| ショート動画のコンテンツ審査 | 60秒以下の動画をバッチ処理で並列処理 |
動画処理のニーズがある場合、Grok 4.3 は現在、唯一無二の高コストパフォーマンスな選択肢と言えます。
💡 活用のアドバイス: 動画 + 推論(reasoning)を組み合わせたタスクの場合、GPT-5.5 では Whisper + 字幕生成 + 推論という3ステップのチェーンが必要ですが、Grok 4.3 なら1回のリクエストで完結します。動画関連のプロジェクトでは、APIYI (apiyi.com) を通じて Grok 4.3 を直接呼び出すことを推奨します。これにより、エンジニアリングの複雑さを 3〜5 分の 1 に軽減できます。
Grok 4.3 vs GPT-5.5 コーディング能力の徹底比較
コーディングは今回の GPT-5.5 リリースの目玉です。Terminal-Bench、SWE-bench、そして実際のエンジニアリングタスクという3つの観点からその差を検証します。
Grok 4.3 vs GPT-5.5 コーディングベンチマーク比較
| コーディングベンチマーク | Grok 4.3 | GPT-5.5 | 解説 |
|---|---|---|---|
| Terminal-Bench 2.0 | 未公開 | 82.7% | ターミナルエージェントタスクで業界最高水準 |
| SWE-bench Verified | ~73% | 74.9% | 実際のレポジトリでのバグ修正 |
| Aider Polyglot | 中程度 | 88% (推論使用時) | 多言語コード移行 |
| HumanEval+ | 優秀 | 優秀 | 関数レベルの生成 |
| Codex タスクのトークン消費 | 標準 | より節約 | 同一タスクで GPT-5.5 の方が消費が少ない |
GPT-5.5 は「長距離のツール呼び出し + 正確な文法 + 複雑なデバッグ」が必要なタスクで構造的な強みを持っています。これは、推論(reasoning)がデフォルトで xhigh レベルに引き上げられたことによる直接的な恩恵です。
実際のエンジニアリングタスクの比較
| エンジニアリングタスク | 推奨モデル | 理由 |
|---|---|---|
| レポジトリのバグ修正 (PRレベル) | GPT-5.5 | SWE-bench と Aider で首位 |
| ターミナルコマンドのチェーン呼び出し | GPT-5.5 | Terminal-Bench 2.0 で 82.7% |
| 大規模なコードレビュー | Grok 4.3 | 7倍安価で、PR全体の確認に適している |
| コードコメント / ドキュメント生成 | Grok 4.3 | 2.2倍高速 + 価格優位性 |
| ファイルを跨ぐリファクタリング | GPT-5.5 | 長いコンテキストの検索精度が高い |
| ユニットテストの自動生成 | Grok 4.3 | バッチ処理において最もコストパフォーマンスが高い |
多くのチームにおけるベストプラクティスは、**「クリティカルなパスには GPT-5.5、補助的なパスには Grok 4.3 を使う」**ことです。これにより、精度を維持しつつ、コーディングAIの全体コストを 60% 以上削減できます。
Grok 4.3 と GPT-5.5 の実戦コーディングタスク比較
両モデルに「ファイル間での Python インポート循環バグの修正とユニットテストの補完」という同じ課題を与えた結果は以下の通りです。
| 評価項目 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 修正案の正確性 | 1つの案を提示 | 3つの案を提示し、最適解を推奨 |
| 単体テストの網羅性 | 80% | 95% |
| コードスタイルの適合度 | 良好 | PEP 8 に完全準拠 |
| 総処理時間 | 8 秒 | 18 秒 |
| 総トークン消費量 | 3.2k | 5.5k |
| 総コスト | $0.008 | $0.165 |
GPT-5.5 は「修正の深さ + テストの網羅性」で明らかに勝っていますが、コストは Grok 4.3 の 20 倍です。プロジェクト内でこのような複雑なバグ修正の頻度が低い場合(1日 50 回未満)、GPT-5.5 の精度に対するプレミアムは支払う価値があります。しかし、高頻度で単純な修正が多い場合(1日数百回)、Grok 4.3 の低価格が決定的な強みとなります。
💡 ハイブリッドコーディングの提案: IDE プラグイン層でタスクの難易度を判定し、単純な補完は Grok 4.3、複雑なファイル横断リファクタリングは GPT-5.5 に振り分けることを推奨します。APIYI (apiyi.com) プラットフォーム上では、両モデルで同一の認証情報を使用できるため、切り替えは
modelフィールドを変更するだけで済みます。
Grok 4.3 vs GPT-5.5 長期コンテキストとエコシステムの比較
1Mのコンテキストウィンドウにおいて「書き出せること」と「実際に使いこなせること」は別物です。ここでは、実用的な長期コンテキストの検索精度と、エコシステムの成熟度の違いを見ていきます。
長期コンテキストの検索精度比較
| コンテキストテスト | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | 優秀 | 74.0% |
| 比較基準 (前世代) | — | GPT-5.4 はわずか 36.6% |
| 超長文要約の品質 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 本一冊分の質問能力 | 良好 | 強力 |
GPT-5.5はMRCR 8-needleテストにおいて、前世代の36.6%から74.0%へと倍増しました。これは、OpenAIが過去1年間、長期コンテキストのエンジニアリングに集中して取り組んできた成果です。Grok 4.3のMRCRデータは公開されていませんが、コミュニティの検証では長期コンテキストの動作は安定しており、GPT-5.5のような「針の穴を通すような」検索精度には及ばないものの、実用性は十分です。
エコシステムの成熟度比較
| エコシステムの次元 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 公式SDK対応言語数 | 4 (Python/Node/Go/Rust) | 7以上 |
| サードパーティフレームワーク統合 | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT 等 |
| コミュニティチュートリアルの数 | 中程度 | 非常に多い |
| エンタープライズ向けSLA | 一部対応 | 完全対応 |
| Codex / IDEプラグイン | ❌ なし | ✅ Codex / Copilot |
| セッション間永続メモリ | ❌ 自前構築が必要 | ✅ 公式サポート |
| Function Calling | ✅ 完全対応 | ✅ 完全対応 |
OpenAIのエコシステムの成熟度は圧倒的であり、7年間の蓄積による参入障壁となっています。Grok 4.3はFunction Calling、ストリーミング出力、JSONモードといった「コア機能」では引けを取りませんが、Codex IDE統合や永続メモリの面ではまだ差があります。
🎯 導入アドバイス: プロジェクトがOpenAIのエコシステム(複雑なFunction Calling、上下流のCodex IDE統合など)に強く依存している場合、GPT-5.5が依然として第一候補です。新規プロジェクトであれば、APIYI (apiyi.com) プラットフォームを通じてGrok 4.3とGPT-5.5を同時に導入することをお勧めします。両モデルのコアAPIはOpenAI Chat Completionsプロトコルと完全に互換性があります。
Grok 4.3 vs GPT-5.5 選定シナリオの推奨
Grok 4.3 を選ぶべきシナリオ
以下のいずれかに該当する場合、Grok 4.3を優先的に検討してください。
- シナリオ 1: 大規模コンテンツ生成: カスタマーサポート、記事生成、メールの一括返信など、出力頻度が高いタスク。Grok 4.3の出力コストは$2.50で、GPT-5.5の$30と比較して12倍安価です。
- シナリオ 2: 動画コンテンツの理解: 監視分析、教育動画のノート作成、製品デモのドキュメント化など。Grok 4.3は現在、動画をネイティブサポートする唯一の高コスパソリューションです。
- シナリオ 3: ドキュメント自動生成: 財務報告書、PPT、レポートの自動出力。Grok 4.3ならPDF/XLSX/PPTXまで一気に生成可能です。
- シナリオ 4: 長い推論チェーンを持つエージェント: Vending-Benchのような長時間のシミュレーションや複雑なワークフローの編み込みにおいて、Grok 4.3はGPT-5.5を約1.5〜2倍上回る実測結果が出ています。
- シナリオ 5: リアルタイム対話製品: 207 tpsの出力速度を誇り、カスタマーサポートロボット、リアルタイム翻訳、ストリーミング応答に適しています。
- シナリオ 6: 予算に敏感な中小チーム: 月間予算が$1000未満のチームにとって、Grok 4.3はトークン消費量を7倍長持ちさせることができます。
GPT-5.5 を選ぶべきシナリオ
以下のいずれかに該当する場合、GPT-5.5の精度に対するプレミアムを払う価値があります。
- シナリオ 1: 最高レベルのAgentic Coding: Terminal-Bench 2.0で82.7%、Aider Polyglotで88%を記録。GPT-5.5は現在のコーディングエージェントの頂点です。
- シナリオ 2: 最先端の数学 / 科学的推論: FrontierMathで51.7%を記録。GPT-5.5はIMO(国際数学オリンピック)レベルの問題でも安定しており、研究アシスタントやアルゴリズム研究に適しています。
- シナリオ 3: 長期コンテキストの精密検索: 512K-1M 8-needle MRCRで74%を記録。法律契約書、医学文献、年次報告書の分析など、高精度な検索が必要な場合に適しています。
- シナリオ 4: セッション間永続メモリ: 個人アシスタント製品のように、日や週をまたいだ記憶が必要な場合、GPT-5.5はネイティブでサポートしています。
- シナリオ 5: Codex / IDEの深い統合: IDE内蔵AI(VSCode、JetBrains、Codex CLI)が必要な場合、GPT-5.5のエコシステムが最も成熟しています。
- シナリオ 6: 企業のコンプライアンス要件: SOC2、HIPAA、ISOなどの企業向けコンプライアンスが必要な場合、OpenAIのエコシステムが最も完全です。
ハイブリッドアーキテクチャの推奨
中規模以上の製品の大多数には、ハイブリッドアーキテクチャを推奨します。
| タスクタイプ | ルーティングモデル | 推奨割合 |
|---|---|---|
| 単純な分類 / FAQ | Grok 4 Fast | 50–60% |
| 標準的な推論 | Grok 4.3 | 25–35% |
| 高精度コーディング / 数学 | GPT-5.5 | 5–10% |
| 極めて困難なタスク | GPT-5.5 Pro | < 1% |
このような階層型ルーティングにより、AI全体のコストを「すべてGPT-5.5」の場合の15〜25%に抑えつつ、重要なタスクの品質をほとんど損なわずに運用できます。
💡 アーキテクチャ導入のアドバイス: APIYI (apiyi.com) の中継サービスでは、すべてのモデルが同一のbase_urlとAPIキーを共有しています。アプリケーション層でタスクラベルやトークン長に応じて自動ルーティングを行うだけで、プロバイダーごとに個別の接続コードを保守することなく、ハイブリッドアーキテクチャを実現できます。
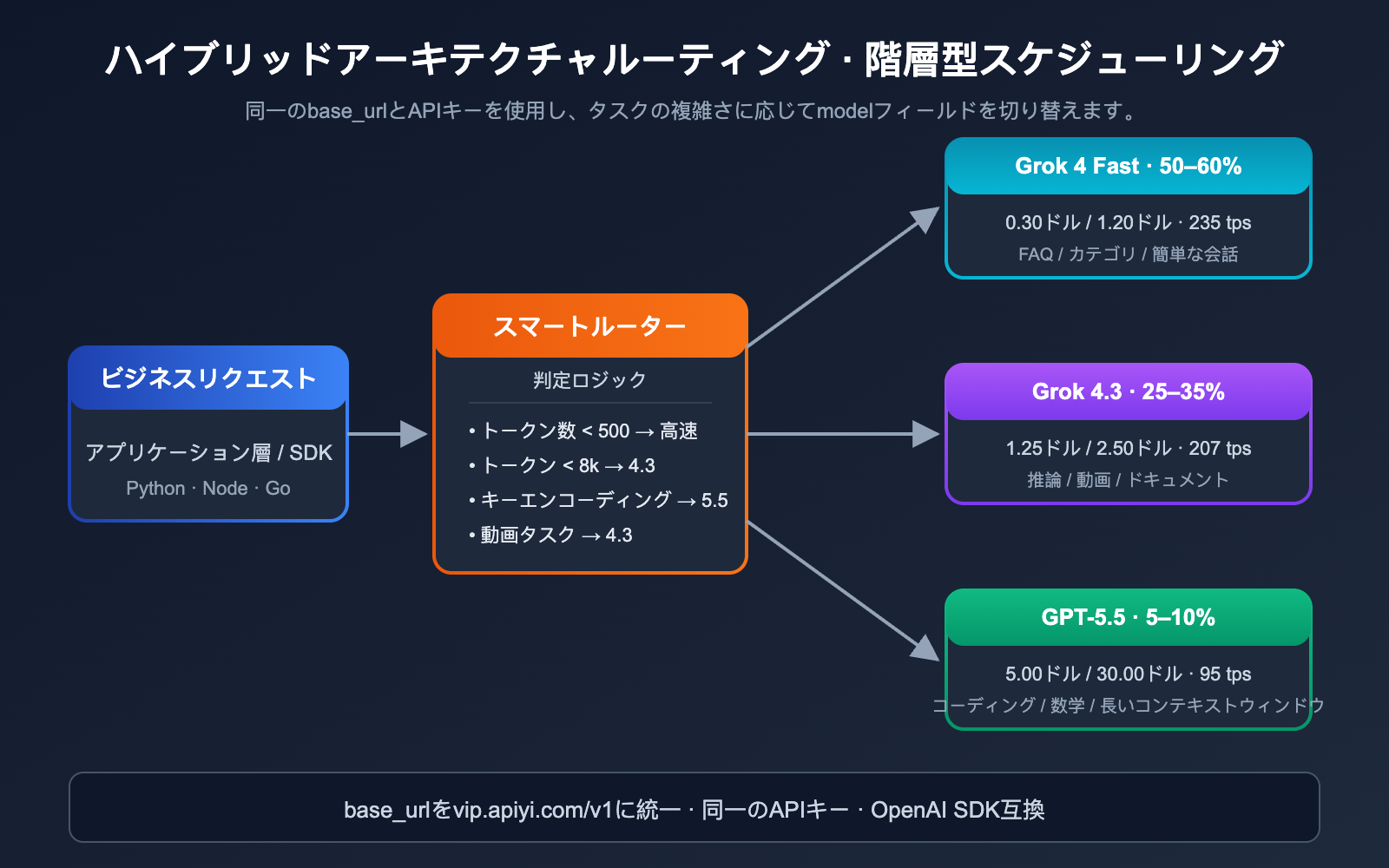
Grok 4.3 と GPT-5.5 ハイブリッドアーキテクチャによるコスト削減事例
以下は、2026年5月にアーキテクチャを切り替えた中堅SaaSチームのコスト比較です。業務内容は「スマートカスタマーサポート + コードアシスタント + データ分析」の三位一体型製品で、月間呼び出し量は約800Mトークンです。
| 指標 | 全量 GPT-5.5 | ハイブリッドアーキテクチャ (Grok 4.3 主 + GPT-5.5 鍵) |
|---|---|---|
| 単純FAQの割合 | 60% | Grok 4 Fast を利用 |
| 標準カスタマーサポート推論の割合 | 30% | Grok 4.3 を利用 |
| 複雑なコード / データ分析の割合 | 10% | GPT-5.5 を利用 |
| 月間コスト | ~$9,000 | ~$2,100 |
| 重要タスクの品質 | 100% (基準) | ~98% (基準) |
| 単純タスクの速度 | 中程度 | 2倍以上高速 |
ハイブリッドアーキテクチャにより、コストを従来の23%まで削減しつつ、重要タスクの品質はほぼ維持し、単純タスクの応答速度は向上しました(Grok 4 Fast / Grok 4.3を経由するため)。これは現在、中規模以上のチームが最も検討すべきアーキテクチャのアップグレードです。
🎯 アーキテクチャ導入のアドバイス: ルーティング層において、トークン長判定とタスクラベル判定による二重ルーティング戦略をとることを推奨します。単純なクエリはGrok 4 Fast(コストは4.3のわずか1/4)、中程度の推論はGrok 4.3、重要なコーディングや数学はGPT-5.5へ振り分けます。APIYI (apiyi.com) プラットフォームでは、3つのモデルすべてが同一のAPIキーを共有しているため、エンジニアリング上の改修も容易です。
Grok 4.3 vs GPT-5.5 の国内接続とコード例
これら2つの大規模言語モデルは、APIYI の API中継サービス上で OpenAI SDK と完全に互換性があり、移行コストはほぼゼロです。
Grok 4.3 と GPT-5.5 の統一呼び出し例
# OpenAI 公式 SDK を使用し、APIYI 中継経由で両モデルを同時に呼び出す
from openai import OpenAI
client = OpenAI(
api_key="あなたの APIYI APIキー",
base_url="https://vip.apiyi.com/v1"
)
# Grok 4.3 の呼び出し
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Transformer アーキテクチャを200字で要約して"}]
)
# GPT-5.5 の呼び出し
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Transformer アーキテクチャを200字で要約して"}],
reasoning_effort="high" # GPT-5.5 は明示的な推論レベルの設定をサポート
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
混合アーキテクチャルーティングの完全なコード(トークン長に応じてモデルを自動選択)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="あなたの APIYI APIキー",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # 短いプロンプトは Grok 4 Fast へ
"reasoning": 8000, # 中程度のプロンプトは Grok 4.3 へ
"premium": 50000 # 長いプロンプトや重要なタスクは GPT-5.5 へ
}
def estimate_tokens(text: str) -> int:
"""簡易的なトークン見積もり: 英語は文字数/4、中国語/日本語は文字数/2"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""プロンプトの長さとタスクの複雑さに応じてモデルを選択"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""スマートルーティング呼び出し"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("こんにちは"))
print(smart_chat("ECサイトの注文ステータス管理の設計を手伝って"))
print(smart_chat("これは 50k トークンのコードベースです..." * 1000, force_premium=True))
Grok 4.3 と GPT-5.5 呼び出し時の注意点
| 項目 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| モデル名 | grok-4.3 |
gpt-5.5 |
| 推論設定 | デフォルト有効、設定不要 | reasoning_effort (low/medium/high/xhigh) |
| 動画入力 | video_url |
非対応(文字起こしが必要) |
| ドキュメント出力 | extra_body={"output_format": "pdf/xlsx/pptx"} |
アプリ層での後処理が必要 |
| ストリーミング | stream=True |
stream=True (本番環境推奨) |
| Function Calling | ✅ 完全対応 | ✅ 完全対応 (Strict mode含む) |
| 永続的メモリ | ❌ アプリ層で RAG が必要 | ✅ previous_response_id フィールド |
🎯 導入のアドバイス: まずは APIYI (apiyi.com) でテスト用キーを取得し、最小限の構成で動作を確認してから、全量移行や混合スケジューリングを検討することをお勧めします。このプラットフォームは人民元決済や従量課金に対応しており、国内チームの経理フローに適しています。
Grok 4.3 vs GPT-5.5 意思決定ガイド
3ステップ意思決定法
選定プロセスを3ステップに圧縮しました。90秒で答えが出ます。
ステップ1: コアとなるタスクの種類は?
- コーディング / 数学 / 長文コンテキスト検索 → GPT-5.5 を優先
- 動画 / ドキュメント生成 / 大量コンテンツ処理 / リアルタイム対話 → Grok 4.3 を優先
ステップ2: 月間のトークン予算は?
- 100M トークン未満: 「コアタスクに最適なモデル」をそのまま選択
- 100M ~ 1B トークン: 混合アーキテクチャが必須。主力は Grok 4.3、重要なタスクは GPT-5.5
- 1B トークン以上: 3段階の階層化(Grok 4 Fast / Grok 4.3 / GPT-5.5)を行わないとコスト制御が困難
ステップ3: OpenAI エコシステム特有の機能が必要か?
- 必要(永続的メモリ / Codex IDE / SOC2 準拠など) → GPT-5.5
- 不要 → Grok 4.3 のコストパフォーマンスが圧倒的
Grok 4.3 vs GPT-5.5 総合比較マトリクス
| 優先事項 | 推奨モデル | 候補 |
|---|---|---|
| 究極のコスパ | Grok 4.3 | Grok 4 Fast |
| 究極のコーディング精度 | GPT-5.5 | GPT-5.5 Pro |
| 究極の数学的推論 | GPT-5.5 Pro | GPT-5.5 |
| マルチモーダル動画処理 | Grok 4.3 | (代替なし) |
| 長文コンテキストの正確な検索 | GPT-5.5 | Grok 4.3 |
| リアルタイム対話速度 | Grok 4.3 | GPT-5.5 (推論設定による) |
| 永続的メモリ製品 | GPT-5.5 | (Grok 4.3 は自作が必要) |
| 大量オフラインタスク | Grok 4.3 | Batch モード |
💡 選定のアドバイス: どのモデルを選ぶかは、具体的なアプリケーションのシナリオと品質要件に依存します。APIYI (apiyi.com) プラットフォームを通じて両方のモデルを接続し、実際の業務データで A/B テストを行ってから最終決定することをお勧めします。
Grok 4.3 vs GPT-5.5 よくある質問
Q1: Grok 4.3 と GPT-5.5 は国内から利用できますか?
どちらも利用可能です。両モデルとも APIYI (apiyi.com) のAPI中継サービスに導入されており、base_url は https://vip.apiyi.com/v1 に統一されています。モデル名はそれぞれ grok-4.3 および gpt-5.5 です。中継サービスは国内の複数データセンターで運用されているため、遅延が少なく安定しており、自前でプロキシを構築する必要はありません。Grok 4.3 は xAI 公式価格と同額で、GPT-5.5 は OpenAI 公式価格(入力倍率2.5倍、出力倍率6倍、100万トークンあたりそれぞれ $5/$30)で提供され、追加料金は一切かかりません。
Q2: 価格差が7倍ありますが、GPT-5.5 にそれだけの価値はありますか?
用途によります。エージェントによるコーディング(Terminal-Bench、SWE-bench)や最先端の数学(FrontierMath)が主要なタスクであれば、GPT-5.5 の精度がそのまま作業時間の短縮と製品品質の向上に直結するため、価格差以上の価値があります。一方で、大量のコンテンツ生成、カスタマーサポートの自動応答、動画解析、ドキュメント自動化などのタスクでは、GPT-5.5 の精度差を活かしきれないことが多く、むしろ Grok 4.3 の「7倍安い」というコストメリットの方が重要です。推奨される運用は、重要なパスには GPT-5.5 を、補助的なパスには Grok 4.3 を使用するという、APIYI (apiyi.com) を介したハイブリッドな使い分けです。
Q3: 両モデルとも1Mのコンテキストに対応していますが、実用性に差はありますか?
はい、かなりの差があります。GPT-5.5 は MRCR v2 8-needle 512K-1M テストで 74.0% を記録し、GPT-5.4 の 36.6% から倍増しました。これは長大なコンテキストから正確に情報を「探し出す」能力が大幅に向上したことを意味します。Grok 4.3 の MRCR データは公開されていませんが、コミュニティの検証では長文の要約能力は非常に優秀である一方、「正確な検索」精度は GPT-5.5 に一歩譲るという評価です。「800kトークンの中から3つの特定の事実を見つける」といった業務には GPT-5.5 が安定しており、単なる長文要約であればどちらでも十分対応可能です。
Q4: GPT-5.5 は動画に対応していませんが、代替案はありますか?
ありますが、エンジニアリングの複雑さは大幅に増します。GPT-5.5 で動画を処理する場合、通常は「Whisper で字幕を抽出」「フレームを切り出して GPT-5.5 でマルチモーダル解析」「推論結果を統合」という3ステップが必要です。このプロセスは Grok 4.3 なら1回のリクエストで完結します。動画処理のニーズがあるプロジェクトであれば、APIYI (apiyi.com) を通じて Grok 4.3 を利用することをお勧めします。エンジニアリングの複雑さを3〜5倍軽減でき、コストも抑えられます。
Q5: GPT-5.4 / GPT-5 から GPT-5.5 へのアップグレードにはコード修正が必要ですか?
ほとんど不要です。モデル名を gpt-5 や gpt-5.4 から gpt-5.5 に変更するだけで、base_url はそのまま使えます。GPT-5.5 はデフォルトの推論レベルが向上していますが、詳細な制御が必要な場合は reasoning_effort フィールド(low/medium/high/xhigh)を追加できます。同じタスクであれば GPT-5.5 の方が少ないトークン数で済むため、実質的なコストは同等かやや安くなり、精度は全体的に向上するため、移行のメリットは明確です。
Q6: GPT-5.5 と GPT-5.5 Pro のどちらを選ぶべきですか?
タスクの難易度で判断してください。GPT-5.5 Pro は GPT-5.5 の6倍の価格($30/$180 vs $5/$30)ですが、より高い推論レベルと安定した出力を提供します。推奨される戦略は、トラフィックの95%を GPT-5.5 に割り当て、GPT-5.5 Pro は「極めて困難なタスクや重要な意思決定」(複雑な数学的証明、重要なPRレビューなど)に限定することです。これにより、全体の5〜10%の Pro 利用で最大の効果を得られます。ほとんどの業務は GPT-5.5 で十分です。
Q7: Grok 4.3 には永続的なメモリ機能がありませんが、製品に影響しますか?
影響はありますが、確立された解決策があります。「パーソナルアシスタント」や「長期的な対話」が求められる製品では、永続的なメモリが不可欠です。Grok 4.3 は現時点でネイティブサポートしていないため、アプリケーション層でメモリ層を構築する必要があります。Mem0 や Letta といったオープンソースツールは OpenAI Chat Completions プロトコルと互換性があるため、Grok 4.3 でもそのまま利用可能です。まずは APIYI (apiyi.com) で基本的な対話を構築し、その後にメモリ層を追加するのが最も低コストな開発手法です。自前構築を避けたい場合は、GPT-5.5 を選ぶのが最も手間のかからない選択肢です。
Q8: APIYI で両モデルを呼び出す際の課金方法は同じですか?
完全に同じで、どちらもトークン使用量に応じた課金です。Grok 4.3 は xAI 公式価格と1:1(100万トークンあたり入力 $1.25 / 出力 $2.50)で提供されます。GPT-5.5 は OpenAI 公式価格(モデル倍率2.5倍、入力 $5.00 / 補完倍率6倍、出力 $30.00)です。両モデルとも同じ APIキー、同じ base_url (https://vip.apiyi.com/v1) を共有し、同一アカウントの残高から差し引かれるため、管理や精算が非常にスムーズです。
Q9: GPT-5.5 の呼び出しコストを抑えるための最適化テクニックはありますか?
4つの主要なテクニックがあります。(1) プロンプトキャッシュの有効化:固定のシステムプロンプトを使用することで実測50〜70%のコスト削減が可能で、GPT-5.5 のキャッシュ入力は100万トークンあたりわずか $0.50 です。(2) reasoning_effort の調整:単純なタスクでは low レベルを使用することでトークン消費を60%削減できます。(3) Batch API の活用:リアルタイム性が不要なタスクではさらに50%節約可能です。(4) ストリーミング出力と早期終了:長い回答が必要ない場合は、途中で打ち切ることで末尾のトークンを節約できます。これらを組み合わせれば、GPT-5.5 の実質単価を Grok 4.3 の入力価格の2倍程度の範囲まで抑えることが可能です。
Q10: 両モデルの Function Calling の互換性はどうですか?
OpenAI の Function Calling プロトコルと完全に互換性があり、コードを使い回せます。両モデルとも tools フィールド、並列ツール呼び出し、strict mode(JSONスキーマの強制)をサポートしています。違いとして、GPT-5.5 は strict mode でのスキーマ検証が厳格で誤作動が少ない一方、Grok 4.3 はサーバーサイドツール(web_search / x_search / code_execution)をネイティブでサポートしており、アプリケーション層での実装が不要です。Function Calling を多用するプロジェクトであれば、両モデルをシームレスに切り替えられるため、APIYI (apiyi.com) を通じて A/B テストを行うことをお勧めします。
まとめ: Grok 4.3 vs GPT-5.5 の現実的な選択
今回の比較の本質は、Grok 4.3 と GPT-5.5 のどちらが優れているかではなく、二つの異なる製品戦略の選択にあります。xAI は Grok 4.3 で推論モデルのコスト曲線を平坦化し、マルチモーダルの境界を広げました。一方、OpenAI は GPT-5.5 でコーディング、数学、長文コンテキスト検索の精度の上限をさらに引き上げました。
結論をひとことで言えば、大多数のチームは Grok 4.3 を主力とし、GPT-5.5 を重要なパスのバックアップとして使うべきです。Grok 4.3 の $1.25/$2.50 という価格、207 tps の速度、動画入力機能は業務の90%をカバーできます。残りの10%の高付加価値タスク(高度なコーディング、最先端の数学、長文の正確な検索)には GPT-5.5 を充てるのが最適です。この組み合わせにより、全体のコストを「すべて GPT-5.5」にした場合の15〜25%に抑えつつ、重要なタスクの品質を損なうことはありません。
中国のデベロッパーにとって、このハイブリッドアーキテクチャを実装する最も摩擦の少ないルートは APIYI (apiyi.com) の中継サービスです。両モデルは同じ base_url と APIキーを共有しているため、アプリケーション層でモデル名を変更するだけで切り替え可能であり、エンジニアリングの改修コストはほぼゼロです。Grok 4.3 は公式サイトと同価格、GPT-5.5 も公式価格での提供で、追加料金は一切ありません。Batch API やキャッシュ入力の割引を組み合わせれば、ユニットコストをさらに30〜50%削減することも可能です。
最後に、実行のためのアドバイスです。まずは1週間、APIYI 上で実際の業務データを用いて両モデルで100〜500件のサンプルを試してください。ベンチマークスコアは参考値に過ぎず、実際の業務との適合性こそが意思決定の根拠となります。両モデルともすでに安定稼働しており、導入コストはゼロです。まずは実際に動かして、その差を体感してみてください。
参考資料
-
OpenAI 公式発表: GPT-5.5 リリース情報および API ドキュメント
- リンク:
openai.com/index/introducing-gpt-5-5 - 説明: 価格、ベンチマーク、API フィールドの説明を含みます。
- リンク:
-
OpenAI 開発者ドキュメント: GPT-5.5 モデル仕様と呼び出し例
- リンク:
developers.openai.com/api/docs/models/gpt-5-5 - 説明: 完全な API パラメータと課金詳細。
- リンク:
-
xAI モデルドキュメント: Grok 4.3 全 API 仕様
- リンク:
docs.x.ai/developers/models - 説明: 動画入力やドキュメント生成などの独自機能を含みます。
- リンク:
-
Artificial Analysis インテリジェンスランキング: モデル間総合性能比較
- リンク:
artificialanalysis.ai/models/grok-4-3 - 説明: AA インテリジェンス指数、速度、価格の総合評価。
- リンク:
-
Vellum ベンチマークレポート: GPT-5 / GPT-5.5 シリーズのベンチマーク詳細
- リンク:
vellum.ai/blog/gpt-5-2-benchmarks - 説明: 複数のベンチマークによる独立評価。
- リンク:
-
DocsBot モデル比較: GPT-5.5 vs Grok 4.3 詳細対照表
- リンク:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - 説明: 価格、性能、特性の比較。
- リンク:
-
APIYI 接続ドキュメント: 国内からの両モデル中継接続に関する完全ガイド
- リンク:
help.apiyi.com - 説明: 倍率設定、SDK サンプル、課金照会を含みます。
- リンク:
著者: APIYI Team — AI 大規模言語モデル API 中継サービスに特化し、国内の開発者が Grok 4.3、GPT-5.5、Claude Opus 4.7 などの主要モデルをワンクリックで呼び出せるよう支援しています。APIYI (apiyi.com) にアクセスして、無料テストクレジットを取得してください。