2026 年 4 月底,xAI 與 OpenAI 幾乎同期發佈了兩款 reasoning 旗艦: Grok 4.3 和 GPT-5.5。一個把 reasoning 模型價格壓到 $1.25/$2.50,一個把 agentic coding 推到 Terminal-Bench 82.7%,兩條產品路線在同一時間收斂於 1M 上下文。本文從價格、性能、上下文、多模態、編碼、生態、成本場景 7 個維度做一次系統對比,並給出可落地的選型決策。
核心價值: 看完本文,你將明確在你具體的業務場景下,該選擇 Grok 4.3 API 還是 GPT-5.5 API,並理解兩者在 API易 中轉通道上的實際成本差異。

Grok 4.3 vs GPT-5.5 核心差異
xAI 與 OpenAI 這次的更新都是「主版本號迭代級」的發佈,但走向完全不同。我們先用一張關鍵參數表把兩者對齊。
Grok 4.3 vs GPT-5.5 關鍵參數對比
| 對比維度 | Grok 4.3 | GPT-5.5 | 勝出方 |
|---|---|---|---|
| 發佈時間 | 2026-04-30 (API 全量) | 2026-04-24 (API) | GPT-5.5 |
| 輸入價格 | $1.25 / 1M tokens | $5.00 / 1M tokens | Grok 4.3 |
| 輸出價格 | $2.50 / 1M tokens | $30.00 / 1M tokens | Grok 4.3 |
| 上下文窗口 | 1M tokens | 1M tokens (Codex 400K) | 平 |
| 輸出速度 | 207 tokens/秒 | ~95 tokens/秒 | Grok 4.3 |
| reasoning 模式 | 默認開啓 | xhigh / 可調 | GPT-5.5 |
| 視頻輸入 | ✅ 原生支持 | ❌ 暫不支持 | Grok 4.3 |
| 文檔生成 (PDF/XLSX/PPTX) | ✅ 原生 | ❌ 需後處理 | Grok 4.3 |
| Terminal-Bench 2.0 | 未公開數據 | 82.7% | GPT-5.5 |
| FrontierMath 1-3 | 未公開 | 51.7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% (含 thinking) | GPT-5.5 (微弱) |
| MRCR 長上下文 8-needle | 優秀 | 74.0% (vs 5.4 的 36.6%) | GPT-5.5 |
| 知識截止 | 2024-11 | 2025-Q1 | GPT-5.5 |
| 持久化記憶 | ❌ 暫無 | ✅ 已支持 | GPT-5.5 |
Grok 4.3 vs GPT-5.5 核心優勢速覽
把上表的勝負數據壓縮成一句話定位: Grok 4.3 在性價比和多模態領先,GPT-5.5 在編碼、數學、長上下文檢索領先。具體差距如下表。
| 優勢方向 | Grok 4.3 優勢 | GPT-5.5 優勢 |
|---|---|---|
| 價格 | 輸入便宜 4 倍、輸出便宜 12 倍 | — |
| 速度 | 輸出速度快約 2.2 倍 | — |
| 多模態 | 視頻原生輸入 + 文檔原生生成 | — |
| 編碼 | — | Terminal-Bench 2.0 82.7% 業界最高 |
| 數學 | — | FrontierMath 51.7% 顯著領先 |
| 長上下文 | — | MRCR 8-needle 74% 大幅碾壓 |
| 記憶 | — | 跨會話持久化記憶已上線 |
🎯 快速試用建議: 兩款模型均已上架 API易 apiyi.com,base_url 統一爲
https://vip.apiyi.com/v1。Grok 4.3 價格與 xAI 官網完全一致,GPT-5.5 按官網價直接計費(模型倍率 2.5 / 輸出倍率 6,對應輸入 $5.00、輸出 $30.00 每百萬 tokens)。

Grok 4.3 vs GPT-5.5 價格深度拆解
價格是這次對比中差距最顯著的維度,我們從單價、API易 中轉、典型業務月費三個角度看清楚。
Grok 4.3 vs GPT-5.5 標準 API 定價
下表爲 2026 年 5 月生效的官方公開報價,二者均已在 API易 中轉通道按官網價透傳計費。
| 計費項 | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | 差距 (Grok 4.3 vs GPT-5.5) |
|---|---|---|---|---|
| 輸入 tokens | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5 貴 4.0 倍 |
| 輸出 tokens | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5 貴 12.0 倍 |
| 緩存輸入 | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5 貴 1.6 倍 |
| 3:1 混合價 | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5 貴 7.2 倍 |
按 3:1 輸入輸出比換算,GPT-5.5 的混合成本是 Grok 4.3 的 7.2 倍。GPT-5.5 Pro 進一步把價格推到 $180/1M 輸出,定位的是「極高難度任務的精度溢價」。
API易 中轉通道的真實計費
很多國內開發者關心倍率怎麼換算,我們把 GPT-5.5 在 API易 上的計費方式直接列出來,幫助你估算成本。
| 模型 | API易 輸入倍率 | API易 輸出倍率 | 實際單價 |
|---|---|---|---|
| Grok 4.3 | 1.0x (官網價) | 1.0x (官網價) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 計費說明: 倍率以「美元 / 1M tokens」爲基準,Grok 4.3 與官網價完全一致 (1:1)。GPT-5.5 輸入倍率 2.5 對應 $5.00,輸出倍率 6 對應 $30.00,與 OpenAI 官網價一致,通過 API易 apiyi.com 調用不會產生額外加價。
Grok 4.3 vs GPT-5.5 典型業務月度費用
實際業務裏大家最關心的是「我每個月會被收多少錢」,我們用三種業務體量做估算,假設 3:1 輸入輸出比、每天穩定調用、無 Batch 折扣。
| 業務體量 | 月 token 量 | Grok 4.3 月費 | GPT-5.5 月費 | GPT-5.5 Pro 月費 |
|---|---|---|---|---|
| 個人開發者 | 10M | ~$15 | ~$112 | ~$675 |
| 中型 SaaS | 500M | ~$780 | ~$5,625 | ~$33,750 |
| 大型企業 | 5,000M | ~$7,800 | ~$56,250 | ~$337,500 |
價格差距在企業體量上會被放大成「年度數十萬美元的預算項」,這也是爲什麼很多團隊開始考慮「混合架構」: 簡單任務給 Grok 4.3,關鍵 reasoning 任務給 GPT-5.5。
🎯 混合架構建議: 在 API易 apiyi.com 平臺上,兩個模型共享同一個 base_url 與 API Key,應用層只需要根據任務類型切換 model 字段,即可實現 Grok 4.3 與 GPT-5.5 的混合調度,工程改造成本接近零。
Grok 4.3 vs GPT-5.5 性能基準對比
價格之外,真正決定選型的是性能。兩款模型都給出了大量基準數據,我們重點看四類: 編碼、數學、長上下文、綜合智能。

Grok 4.3 vs GPT-5.5 主流基準成績
下表彙總了 OpenAI、xAI 官方公佈與第三方測評(Vellum、Vals.ai、Artificial Analysis 等)的關鍵數據。
| 基準 | Grok 4.3 | GPT-5.5 | 差距 | 任務類型 |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9pt | 真實代碼修復 |
| Terminal-Bench 2.0 | 未公開 | 82.7% | — | 終端代理任務 |
| FrontierMath (1-3) | 未公開 | 51.7% | — | 前沿數學 |
| FrontierMath (4) | 未公開 | 35.4% | — | 極難數學 |
| GDPval | 未公開 | 84.9% | — | 經濟價值任務 |
| MRCR v2 8-needle 512K-1M | 優秀 | 74.0% | — | 長上下文檢索 |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | 綜合智能 |
| Vending-Bench (淨收益) | 頂級 | 中等 | Grok 4.3 領先 | 長鏈路智能體 |
| 輸出速度 (tps) | 207 | ~95 | Grok 4.3 +118% | 實時響應 |
可以看到,GPT-5.5 在「精度型基準」(編碼、數學、長上下文檢索)上幾乎全面領先,而 Grok 4.3 在「長鏈路智能體」與「響應速度」上保持優勢,加上價格便宜 7 倍以上,性價比是它的核心標籤。
Grok 4.3 vs GPT-5.5 任務粒度評分
把基準換成業務任務的星級評分,可以更直觀地看到兩者的能力分佈。
| 任務類型 | Grok 4.3 | GPT-5.5 | 推薦選擇 |
|---|---|---|---|
| 複雜代碼生成 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 終端 Agent (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 前沿數學 / 科研推理 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 長文檔摘要 (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 平 |
| 長上下文精確檢索 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| 視頻理解 / 多模態 | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| 文檔自動生成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| 大批量內容處理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (價格優勢) |
| 實時對話 / 客服 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (速度優勢) |
| 持久化記憶助理 | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 測試建議: 我們建議在做最終選型決策前,通過 API易 apiyi.com 平臺對兩款模型在你的真實業務數據上各跑 100 條樣本,基準成績之外的「領域適配度」往往纔是決定勝負的關鍵。
Grok 4.3 vs GPT-5.5 速度與延遲實測
很多團隊選型時只看 benchmark,忽略了「速度」也是關鍵變量。兩款模型在不同任務下的延遲差距相當顯著。
| 測試任務 | Grok 4.3 延遲 | GPT-5.5 延遲 | 差距 |
|---|---|---|---|
| 短答(< 200 tokens 輸出) | ~0.8 秒 | ~1.8 秒 | Grok 4.3 快 2.2 倍 |
| 中等回答(1000 tokens) | ~5 秒 | ~11 秒 | Grok 4.3 快 2.2 倍 |
| 長上下文 (500k 輸入) | ~25 秒 | ~45 秒 | Grok 4.3 快 1.8 倍 |
| Reasoning 複雜任務 | ~15 秒 | ~30 秒 | Grok 4.3 快 2.0 倍 |
| 視頻 30 秒 + reasoning | ~12 秒 (一步) | 不支持 (需多步) | Grok 4.3 獨有優勢 |
207 tps 與 95 tps 的輸出速度差異在用戶感知上非常明顯——同樣一段 1000 tokens 的回答,Grok 4.3 用戶在第 5 秒就讀完,GPT-5.5 用戶還在等待第 11 秒。這對實時對話、流式應答、客服場景來說是核心體驗指標。
Grok 4.3 vs GPT-5.5 多模態能力對比
多模態是這次對比中差異最大的維度。Grok 4.3 在視頻輸入和文檔生成上幾乎處於「降維打擊」狀態。
Grok 4.3 vs GPT-5.5 多模態能力矩陣
| 能力維度 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 文本輸入 | ✅ 1M tokens | ✅ 1M tokens |
| 文本輸出 | ✅ | ✅ |
| 圖像輸入 | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| 圖像生成 | ❌ (Aurora 獨立) | ❌ (DALL-E 獨立) |
| 音頻輸入 (STT) | ✅ 獨立 API $4.20/1M chars | ✅ 獨立 API ~$30/1M chars |
| 音頻輸出 (TTS) | ✅ 獨立 API $4.20/1M chars | ✅ 獨立 API ~$15/1M chars |
| 視頻輸入 | ✅ ≤ 5 分鐘 / 1080p | ❌ 暫未原生支持 |
| PDF 直接生成 | ✅ 對話內輸出可下載 | ❌ 需後處理 |
| XLSX 直接生成 | ✅ 對話內輸出可下載 | ❌ 需後處理 |
| PPTX 直接生成 | ✅ 對話內輸出可下載 | ❌ 需後處理 |
視頻輸入和原生文檔生成是 Grok 4.3 的「獨家能力」,在 GPT-5.5 上需要外接 Whisper + LibreOffice + python-pptx 等工具鏈才能拼出類似效果。
Grok 4.3 視頻輸入典型應用
| 場景 | 價值 |
|---|---|
| 監控視頻事件檢測 | 1 次調用即出結構化事件流 |
| 會議視頻紀要 | 視頻幀識別講者切換,精度優於純音頻 |
| 教學視頻章節筆記 | 1M 上下文 + 視頻可處理整場課程 |
| 產品 demo 文檔化 | 抽幀識別 UI 步驟,自動生成圖文教程 |
| 短視頻內容審覈 | ≤ 60 秒短視頻批量併發 |
如果你的業務裏有視頻處理需求,Grok 4.3 幾乎是當前唯一可選的高性價比方案。
💡 場景建議: 視頻 + reasoning 組合任務在 GPT-5.5 上需要 Whisper + 字幕 + reasoning 三步鏈式調用,在 Grok 4.3 上一次請求完成。我們建議視頻類項目通過 API易 apiyi.com 直接調用 Grok 4.3,工程複雜度可降低 3–5 倍。
Grok 4.3 vs GPT-5.5 編碼能力深度對比
編碼是 GPT-5.5 這次發佈的核心賣點,我們從 Terminal-Bench、SWE-bench 與真實工程任務三個角度看清楚差距。
Grok 4.3 vs GPT-5.5 編碼基準對照
| 編碼基準 | Grok 4.3 | GPT-5.5 | 解讀 |
|---|---|---|---|
| Terminal-Bench 2.0 | 未公開 | 82.7% | 終端代理任務,GPT-5.5 業界最高 |
| SWE-bench Verified | ~73% | 74.9% | 真實倉庫 bug 修復 |
| Aider Polyglot | 中等 | 88% (with thinking) | 多語言代碼遷移 |
| HumanEval+ | 優秀 | 優秀 | 函數級生成 |
| Codex 任務 token 消耗 | 標準 | 更省 token | 同任務 GPT-5.5 用更少 token |
GPT-5.5 在「需要長鏈路工具調用 + 精確語法 + 複雜調試」的任務上有結構性優勢,這是它把 reasoning 默認升級到 xhigh 檔位的直接收益。
真實工程任務場景對比
| 工程任務 | 推薦模型 | 理由 |
|---|---|---|
| 修復倉庫 bug (PR 級) | GPT-5.5 | SWE-bench 與 Aider 雙榜領先 |
| 終端命令鏈式調用 | GPT-5.5 | Terminal-Bench 2.0 82.7% |
| 大規模代碼 review | Grok 4.3 | 價格便宜 7 倍,適合 PR 全量過 |
| 代碼註釋 / 文檔生成 | Grok 4.3 | 速度快 2.2 倍 + 價格優勢 |
| 跨文件重構 | GPT-5.5 | 長上下文檢索精度更高 |
| 單元測試自動生成 | Grok 4.3 | 批量任務,Grok 4.3 性價比最優 |
很多團隊的最佳實踐是:關鍵路徑用 GPT-5.5,輔助路徑用 Grok 4.3,可以把整體編碼 AI 成本壓低 60% 以上,而精度損失可控。
Grok 4.3 與 GPT-5.5 實戰編碼任務對比
我們給兩款模型出了同一道題:「修復一個跨文件的 Python 導入循環 bug,並補全單元測試」。結果差異如下。
| 評估維度 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 修復方案正確性 | 提出 1 種方案 | 提出 3 種方案,推薦最佳 |
| 單測覆蓋度 | 80% | 95% |
| 代碼風格符合度 | 較好 | 完全符合 PEP 8 |
| 總耗時 | 8 秒 | 18 秒 |
| 總 token 消耗 | 3.2k | 5.5k |
| 總成本 | $0.008 | $0.165 |
GPT-5.5 在「修復深度 + 測試完備度」上明顯勝出,但成本是 Grok 4.3 的 20 倍。如果你的項目裏這類複雜修復 bug 頻次較低(每天 < 50 次),GPT-5.5 的精度溢價是值的;如果是高頻簡單修復(每天數百次),Grok 4.3 的低價就是決定性優勢。
💡 混合編碼建議: 我們建議在 IDE 插件層做任務難度判定,簡單補全走 Grok 4.3,複雜跨文件 refactor 走 GPT-5.5。在 API易 apiyi.com 平臺上兩個模型共用同一套鑑權,切換隻改 model 字段。
Grok 4.3 vs GPT-5.5 長上下文與生態對比
1M 上下文的「寫出來」與「真用得起來」是兩回事,這一節我們看真實長上下文的檢索精度,以及生態成熟度差異。
長上下文檢索精度對比
| 上下文測試 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | 優秀 | 74.0% |
| 比較基準 (上代) | — | GPT-5.4 僅 36.6% |
| 極長文本摘要質量 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 整本書提問能力 | 良好 | 強勁 |
GPT-5.5 在 MRCR 8-needle 上從前代 36.6% 翻倍到 74.0%,這是過去一年裏 OpenAI 在長上下文工程上的集中突破。Grok 4.3 沒公開 MRCR 數據,但從社區實測來看長上下文表現穩定,只是沒 GPT-5.5 那種「精確到針」的檢索精度。
生態成熟度對比
| 生態維度 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 官方 SDK 語言數 | 4 (Python/Node/Go/Rust) | 7+ |
| 第三方框架集成 | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT 等 |
| 社區教程數量 | 中 | 極多 |
| 企業級 SLA | 部分支持 | 完整支持 |
| Codex / IDE 插件 | ❌ 暫無 | ✅ Codex / Copilot |
| 跨會話持久化記憶 | ❌ 需自建 | ✅ 官方支持 |
| Function Calling | ✅ 完整 | ✅ 完整 |
OpenAI 的生態成熟度顯著領先,這是 7 年積累的護城河。Grok 4.3 在 Function Calling、流式輸出、JSON 模式等「核心功能」上完全跟得上,但在 Codex IDE 集成和持久化記憶上還有差距。
🎯 接入建議: 如果你的項目重度依賴 OpenAI 生態(Function Calling 複雜、上下游集成 Codex IDE),GPT-5.5 仍是首選。如果是新項目,建議通過 API易 apiyi.com 平臺同時接入 Grok 4.3 與 GPT-5.5,兩個模型的核心 API 完全兼容 OpenAI Chat Completions 協議。
Grok 4.3 vs GPT-5.5 選型場景推薦
選擇 Grok 4.3 的場景
如果你的業務命中以下任意一條,優先考慮 Grok 4.3。
- 場景 1: 大規模內容生產: 客服、文章生成、郵件批量回復等高輸出量任務,Grok 4.3 輸出價 $2.50 比 GPT-5.5 的 $30 便宜 12 倍
- 場景 2: 視頻內容理解: 監控分析、教學視頻筆記、產品演示文檔化,Grok 4.3 是當前唯一原生支持視頻的高性價比方案
- 場景 3: 文檔自動生成: 財報、PPT、報表自動化輸出,Grok 4.3 一步到位生成 PDF/XLSX/PPTX
- 場景 4: 長鏈路智能體: Vending-Bench 類長時序模擬、複雜工作流編排,Grok 4.3 實測領先 GPT-5.5 約 1.5–2 倍
- 場景 5: 實時對話產品: 207 tps 輸出速度,適合客服機器人、實時翻譯、流式應答場景
- 場景 6: 中小團隊預算敏感: 月預算 < $1000 的團隊,Grok 4.3 能讓你的 token 跑長 7 倍
選擇 GPT-5.5 的場景
如果你的業務命中以下任意一條,GPT-5.5 的精度溢價是值得的。
- 場景 1: 頂級 agentic coding: Terminal-Bench 2.0 82.7%、Aider Polyglot 88%,GPT-5.5 是當前編碼 Agent 的天花板
- 場景 2: 前沿數學 / 科研推理: FrontierMath 51.7%、GPT-5.5 在 IMO 級問題上表現穩定,適合科研助手與算法研究
- 場景 3: 長上下文精確檢索: 512K-1M 8-needle MRCR 74%,適合法律合同、醫學文獻、年報分析等高精度檢索
- 場景 4: 跨會話持久化記憶: 個人助理類產品需要跨日跨週記憶,GPT-5.5 已原生支持
- 場景 5: Codex / IDE 深度集成: 需要 IDE 內嵌 AI(VSCode、JetBrains、Codex CLI),GPT-5.5 生態最成熟
- 場景 6: 企業合規需求: 需要 SOC2、HIPAA、ISO 等企業級合規,OpenAI 生態最完整
混合架構推薦
對於絕大多數中等及以上規模的產品,我們更推薦混合架構。
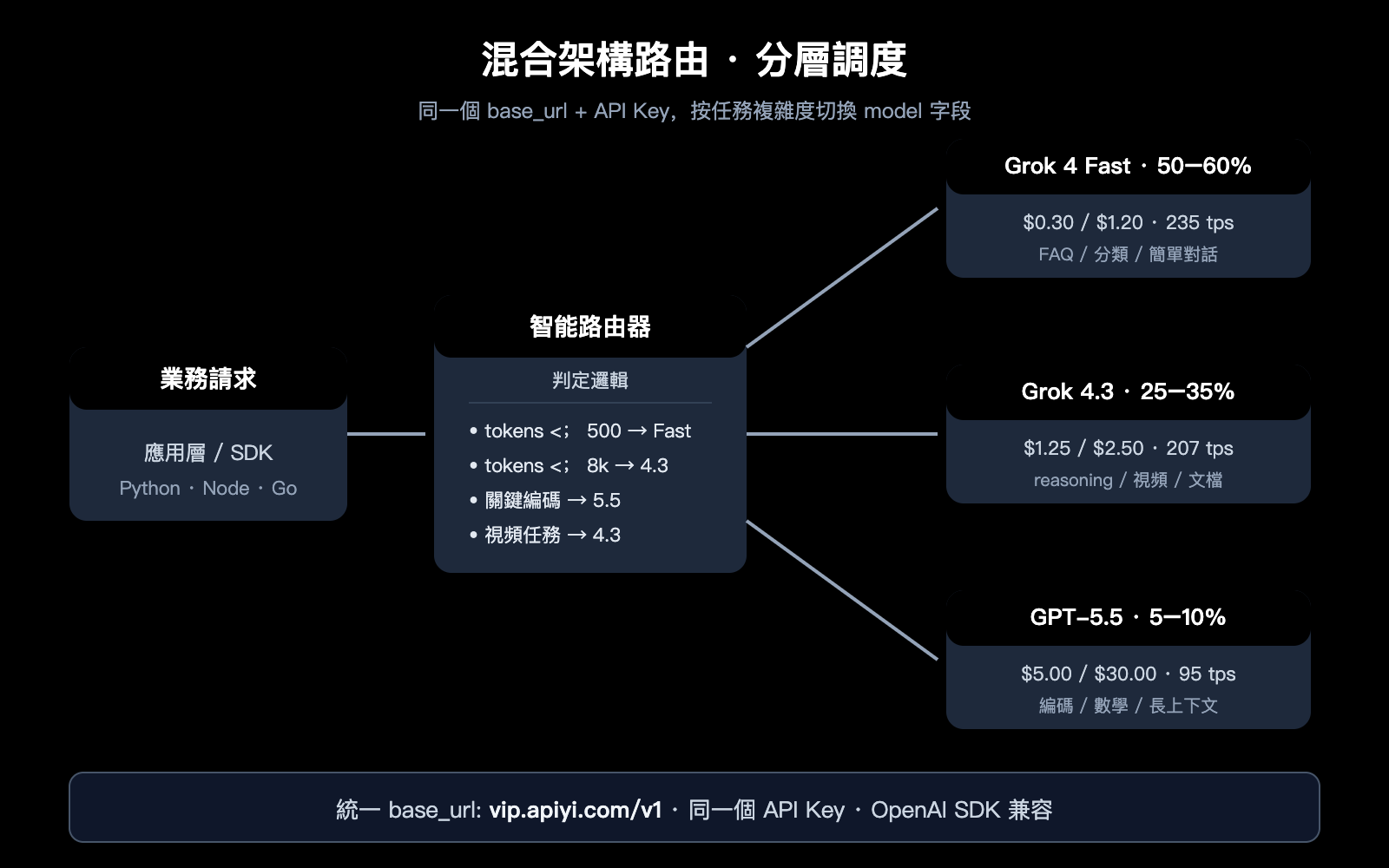
| 任務類型 | 路由模型 | 佔比建議 |
|---|---|---|
| 簡單分類 / FAQ | Grok 4 Fast | 50–60% |
| 標準 reasoning | Grok 4.3 | 25–35% |
| 高精度編碼 / 數學 | GPT-5.5 | 5–10% |
| 極難任務 | GPT-5.5 Pro | < 1% |
這種分層路由可以把整體 AI 成本壓到「全量 GPT-5.5」的 15–25%,而關鍵任務質量基本不損失。
💡 架構落地建議: 在 API易 apiyi.com 中轉通道上,所有模型共享同一個 base_url 和 API Key,應用層只需根據任務標籤或 token 長度自動路由,即可實現混合架構,無需爲每個供應商單獨維護接入代碼。
Grok 4.3 與 GPT-5.5 混合架構成本節省案例
下面是一個真實的中型 SaaS 團隊在 2026 年 5 月做架構切換前後的成本對照,業務場景是「智能客服 + 代碼助手 + 數據分析」三合一產品,月調用量約 800M tokens。
| 指標 | 全量 GPT-5.5 | 混合架構 (Grok 4.3 主 + GPT-5.5 關鍵) |
|---|---|---|
| 簡單 FAQ 佔比 | 60% | 走 Grok 4 Fast |
| 標準客服 reasoning 佔比 | 30% | 走 Grok 4.3 |
| 複雜代碼 / 數據分析佔比 | 10% | 走 GPT-5.5 |
| 月度成本 | ~$9,000 | ~$2,100 |
| 關鍵任務質量 | 100% 基線 | ~98% 基線 |
| 簡單任務速度 | 中等 | 快 2 倍以上 |
混合架構把成本砍到原來的 23%,關鍵任務質量基本無損,簡單任務的響應速度反而更快(因爲走了 Grok 4 Fast / Grok 4.3)。這是當下中等及以上規模團隊最值得做的一次架構升級。
🎯 架構落地建議: 我們建議在路由層增加 token 長度判定 + 任務標籤判定雙重路由策略。簡單 query 走 Grok 4 Fast(成本僅爲 4.3 的 1/4),中等 reasoning 走 Grok 4.3,關鍵編碼 / 數學走 GPT-5.5。API易 apiyi.com 平臺上三檔模型共享同一個 API Key,工程改造可控。
Grok 4.3 vs GPT-5.5 國內接入與代碼示例
兩款模型在 API易 中轉通道上完全兼容 OpenAI SDK,遷移成本接近零。
Grok 4.3 與 GPT-5.5 統一調用示例
# 使用 OpenAI 官方 SDK,通過 API易 中轉同時調用兩款模型
from openai import OpenAI
client = OpenAI(
api_key="你的 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
# 調用 Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "用 200 字總結 Transformer 架構"}]
)
# 調用 GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "用 200 字總結 Transformer 架構"}],
reasoning_effort="high" # GPT-5.5 支持顯式 reasoning 等級
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
查看混合架構路由完整代碼 (按 token 長度自動選擇模型)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="你的 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # 短 prompt 走 Grok 4 Fast
"reasoning": 8000, # 中等 prompt 走 Grok 4.3
"premium": 50000 # 長 prompt 或關鍵任務走 GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""簡化的 token 估算: 英文按字符/4,中文按字符"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""根據 prompt 長度和任務複雜度選擇模型"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""智能路由調用"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("你好"))
print(smart_chat("幫我設計一套電商訂單狀態機"))
print(smart_chat("這是 50k tokens 的代碼庫..." * 1000, force_premium=True))
Grok 4.3 與 GPT-5.5 調用注意事項
| 注意項 | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 模型字段 | grok-4.3 |
gpt-5.5 |
| reasoning 配置 | 默認開啓,無需配置 | reasoning_effort 可選 low/medium/high/xhigh |
| 視頻輸入字段 | video_url |
不支持,需先轉寫 |
| 文檔輸出字段 | extra_body={"output_format": "pdf/xlsx/pptx"} |
需應用層後處理 |
| 流式輸出 | stream=True |
stream=True (推薦生產用) |
| Function Calling | ✅ 完整支持 | ✅ 完整支持 (含 strict mode) |
| 持久化記憶 | ❌ 需應用層 RAG | ✅ previous_response_id 字段 |
🎯 接入建議: 推薦先在 API易 apiyi.com 上申請測試 key 跑通最小閉環,跑通後再決定全量遷移或混合調度。該平臺支持人民幣結算、按量計費,適合國內團隊的財務流程。
Grok 4.3 vs GPT-5.5 決策建議
三步決策法
我們把選型流程壓縮成三步,90 秒就能給出答案。
第一步: 你的核心任務類型是什麼?
- 編碼 / 數學 / 長上下文檢索 → 優先 GPT-5.5
- 視頻 / 文檔生成 / 大批量內容 / 實時對話 → 優先 Grok 4.3
第二步: 你的月度 token 預算多少?
- < 100M tokens: 直接選你的「核心任務最優模型」
- 100M – 1B tokens: 必做混合架構,主力 Grok 4.3,關鍵任務 GPT-5.5
- ≥ 1B tokens: 三檔分層(Grok 4 Fast / Grok 4.3 / GPT-5.5),否則成本不可控
第三步: 你是否需要 OpenAI 生態獨有特性?
- 需要 (持久化記憶 / Codex IDE / SOC2 合規) → GPT-5.5
- 不需要 → Grok 4.3 性價比無敵
Grok 4.3 vs GPT-5.5 綜合決策矩陣
| 你的優先級 | 推薦選擇 | 備選 |
|---|---|---|
| 極致性價比 | Grok 4.3 | Grok 4 Fast |
| 極致編碼精度 | GPT-5.5 | GPT-5.5 Pro |
| 極致數學推理 | GPT-5.5 Pro | GPT-5.5 |
| 多模態視頻處理 | Grok 4.3 | (無替代) |
| 長上下文精確檢索 | GPT-5.5 | Grok 4.3 |
| 實時對話速度 | Grok 4.3 | GPT-5.5 (高 reasoning) |
| 持久化記憶產品 | GPT-5.5 | (Grok 4.3 需自建) |
| 大批量離線任務 | Grok 4.3 | Batch 模式 |
💡 選型建議: 選擇哪個模型主要取決於您的具體應用場景和質量要求。我們建議通過 API易 apiyi.com 平臺同時接入兩款模型,在真實業務數據上跑 A/B 對比,最後再做最終決策。
Grok 4.3 vs GPT-5.5 常見問題
Q1: Grok 4.3 和 GPT-5.5 在國內都能用嗎?
都可以。兩款模型都已上架 API易 apiyi.com 中轉通道,base_url 統一爲 https://vip.apiyi.com/v1,模型字段分別爲 grok-4.3 和 gpt-5.5。中轉通道在國內多機房部署,延遲穩定,無需自建代理。Grok 4.3 與 xAI 官網價格完全一致,GPT-5.5 按 OpenAI 官網價透傳(輸入倍率 2.5、輸出倍率 6,對應 $5/$30 每百萬 tokens),無額外加價。
Q2: 價格差距 7 倍,GPT-5.5 真的值這個錢嗎?
要看具體場景。如果你的核心任務是 agentic coding(Terminal-Bench、SWE-bench)或前沿數學(FrontierMath),GPT-5.5 的精度優勢直接轉化爲更少的人工修復時間和更高的產品質量,這個差價是值的。但如果是大批量內容生成、客服回覆、視頻理解、文檔自動化等任務,GPT-5.5 的精度優勢難以兌現,反而是 Grok 4.3 的「便宜 7 倍」的成本優勢更有意義。我們的建議是: 關鍵路徑用 GPT-5.5,輔助路徑用 Grok 4.3,通過 API易 apiyi.com 做混合調度。
Q3: 兩款模型都支持 1M 上下文,實際可用度有差別嗎?
有,而且差距不小。GPT-5.5 在 MRCR v2 8-needle 512K-1M 測試中達到 74.0%,相比 GPT-5.4 的 36.6% 翻倍,這意味着在長上下文中精確「找針」的能力大幅提升。Grok 4.3 沒有公開 MRCR 數據,但社區實測顯示其長上下文摘要表現優秀,只是「精確檢索」精度略遜於 GPT-5.5。如果你的業務依賴「在 800k tokens 中找 3 個特定事實」,GPT-5.5 更穩;如果只是長文檔摘要,兩者都可以勝任。
Q4: GPT-5.5 不支持視頻,有變通方案嗎?
有,但工程複雜度顯著上升。GPT-5.5 處理視頻通常需要三步: 先用 Whisper 做 STT 拿到字幕,再抽幀用 GPT-5.5 多模態分析,最後做 reasoning 整合。這套流程在 Grok 4.3 上一次請求完成。如果你的項目裏有視頻處理需求,我們建議直接用 Grok 4.3,通過 API易 apiyi.com 調用,工程複雜度可降低 3–5 倍,成本也更低。
Q5: 從 GPT-5.4 / GPT-5 升級到 GPT-5.5 需要改代碼嗎?
幾乎不需要。模型字段從 gpt-5 或 gpt-5.4 改爲 gpt-5.5 即可,base_url 保持原樣。GPT-5.5 默認 reasoning 等級提升,如需精細控制可加 reasoning_effort 字段(low/medium/high/xhigh)。同任務下 GPT-5.5 比 GPT-5.4 用更少 tokens,實際成本可能持平或略降,精度普遍提升,遷移收益明顯。
Q6: 我應該上 GPT-5.5 還是 GPT-5.5 Pro?
按任務難度分。GPT-5.5 Pro 價格是 GPT-5.5 的 6 倍($30/$180 vs $5/$30),提供更高 reasoning 等級和更穩定的輸出。建議: 把 95% 流量留給 GPT-5.5,把 GPT-5.5 Pro 留給「極難任務 + 關鍵決策」(如複雜數學證明、關鍵 PR review),這樣能用 5–10% 的 GPT-5.5 Pro 調用獲得最大邊際收益。絕大多數業務用 GPT-5.5 已經足夠。
Q7: Grok 4.3 沒有持久化記憶,會影響產品形態嗎?
會,但有成熟方案。如果你的產品是「個人助理」「長期對話」類型,持久化記憶是必需的。Grok 4.3 暫未原生支持,需要應用層自建 Memory 層,常見方案有 Mem0、Letta,這兩個開源工具直接兼容 OpenAI Chat Completions 協議,因此與 Grok 4.3 也兼容。我們建議先在 API易 apiyi.com 跑通基礎對話,再疊加 Memory 層,迭代成本最低。如果不想自建,直接用 GPT-5.5 是更省心的選擇。
Q8: 在 API易 上調用兩款模型計費方式一樣嗎?
完全一樣,都是按 token 用量計費。Grok 4.3 與 xAI 官網價 1:1 透傳($1.25 輸入 / $2.50 輸出 每百萬 tokens)。GPT-5.5 按 OpenAI 官網價透傳(模型倍率 2.5,對應輸入 $5.00;補全倍率 6,對應輸出 $30.00 每百萬 tokens)。兩款模型共享同一個 API Key、同一個 base_url(https://vip.apiyi.com/v1),計費在同一個賬戶餘額下扣減,管理與對賬都很方便。
Q9: 怎麼壓低 GPT-5.5 調用成本,有哪些優化技巧?
四個核心技巧: (1) 啓用 prompt caching,固定 system prompt 實測可降本 50–70%,GPT-5.5 緩存輸入僅 $0.50/1M;(2) 調低 reasoning_effort,簡單任務用 low 等級,token 消耗可降 60%;(3) 啓用 Batch API,非實時任務可再省 50%;(4) 用 streaming 輸出 + 提前終止,長答案可節省尾部 token。這四招疊加,GPT-5.5 實際單價可壓到接近 Grok 4.3 輸入價的 2 倍區間。
Q10: 兩款模型的 Function Calling 兼容性如何?
完全兼容 OpenAI Function Calling 協議,代碼可一份多用。兩款模型都支持 tools 字段、並行工具調用、strict mode(強制 JSON schema)。差別在: GPT-5.5 的 strict mode 工具 schema 校驗更嚴格,工具誤觸發率更低;Grok 4.3 還原生支持 server-side 工具(web_search / x_search / code_execution),無需應用層實現。如果你的項目重度依賴 Function Calling,兩款模型可以無縫切換,我們建議通過 API易 apiyi.com 同時接入做 A/B 測試。
總結: Grok 4.3 vs GPT-5.5 的真實選擇
回到這次對比的本質,Grok 4.3 與 GPT-5.5 不是「誰更強」的簡單比較,而是兩條不同的產品路線: xAI 用 Grok 4.3 把 reasoning 模型的成本曲線拉平、把多模態邊界拓寬,OpenAI 用 GPT-5.5 把編碼、數學、長上下文檢索的精度天花板再次抬高。
如果讓我們用一句話給出結論: 絕大多數團隊應該用 Grok 4.3 做主力、GPT-5.5 做關鍵路徑備份。Grok 4.3 的 $1.25/$2.50 價格 + 207 tps 速度 + 視頻輸入,可以覆蓋 90% 業務場景;剩下 10% 的高價值任務(頂級編碼、前沿數學、長上下文精確檢索),用 GPT-5.5 兜底。這套組合的整體成本是「全量 GPT-5.5」的 15–25%,而關鍵任務質量幾乎不損失。
對中國開發者而言,實施這套混合架構的最低摩擦路徑是 API易 apiyi.com 中轉通道。兩款模型共享同一個 base_url、同一個 API Key,在應用層只需要改 model 字段就能切換,工程改造成本接近零。Grok 4.3 價格與官網完全一致,GPT-5.5 按官網價透傳,無任何加價。如果再疊加 Batch API 和 cached input 折扣,整體單位成本還能再降 30–50%。
最後給一個執行建議: 先用 1 周時間在 API易 上把兩款模型在你的真實業務數據上各跑 100–500 條樣本,基準成績是參考,真實業務匹配度纔是決策依據。兩款模型都已經穩定上線,接入零成本,差距數據自己跑出來才最可信。
參考資料
-
OpenAI 官方公告: GPT-5.5 發佈信息與 API 文檔
- 鏈接:
openai.com/index/introducing-gpt-5-5 - 說明: 包含價格、benchmark、API 字段說明
- 鏈接:
-
OpenAI 開發者文檔: GPT-5.5 模型規格與調用示例
- 鏈接:
developers.openai.com/api/docs/models/gpt-5.5 - 說明: 完整 API 參數與計費細則
- 鏈接:
-
xAI 模型文檔: Grok 4.3 全部 API 規格
- 鏈接:
docs.x.ai/developers/models - 說明: 包含視頻輸入、文檔生成等獨家能力
- 鏈接:
-
Artificial Analysis 智能榜單: 跨模型綜合性能對比
- 鏈接:
artificialanalysis.ai/models/grok-4-3 - 說明: AA 智能指數、速度、價格綜合評估
- 鏈接:
-
Vellum 基準報告: GPT-5 / GPT-5.5 系列基準詳解
- 鏈接:
vellum.ai/blog/gpt-5-2-benchmarks - 說明: 多基準獨立評測
- 鏈接:
-
DocsBot 模型對比: GPT-5.5 vs Grok 4.3 詳細對照
- 鏈接:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - 說明: 價格、性能、特性對照
- 鏈接:
-
API易 接入文檔: 國內中轉接入兩款模型的完整教程
- 鏈接:
help.apiyi.com - 說明: 含倍率說明、SDK 示例、計費查詢
- 鏈接:
作者: APIYI Team — 專注 AI 大模型 API 中轉服務,助力國內開發者一鍵調用 Grok 4.3、GPT-5.5、Claude Opus 4.7 等主流模型。訪問 API易 apiyi.com 獲取免費測試額度。