Fin avril 2026, xAI et OpenAI ont lancé presque simultanément deux fleurons du raisonnement : Grok 4.3 et GPT-5.5. L'un a fait chuter le prix des modèles de raisonnement à 1,25 $/2,50 $, tandis que l'autre a propulsé le codage agentique à 82,7 % sur Terminal-Bench. Ces deux trajectoires produits convergent vers une fenêtre de contexte de 1M. Cet article propose une comparaison systématique selon 7 dimensions (prix, performance, contexte, multimodalité, codage, écosystème, scénarios de coûts) et vous aide à faire un choix pragmatique.
Valeur ajoutée : Après lecture, vous saurez précisément quelle API choisir (Grok 4.3 ou GPT-5.5) selon votre cas d'usage et comprendrez les différences de coûts réelles via le service proxy API d'APIYI.
<rect x="0" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="75" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">1M</text>
<text x="75" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">fenêtre de contexte</text>
<rect x="170" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="245" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">$1.25</text>
<text x="245" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">Entrée / 1M</text>
<rect x="0" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="75" y="187" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">207</text>
<text x="75" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">jetons/sec</text>
<rect x="170" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="245" y="190" text-anchor="middle" font-family="Arial, sans-serif" font-size="14" font-weight="700" fill="#a855f7">vidéo native</text>
<text x="245" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">+ génération de documents</text>
<text x="160" y="265" text-anchor="middle" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0" font-weight="600">Rapport coût-efficacité + multimodal</text>
<rect x="0" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="75" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">1M</text>
<text x="75" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">fenêtre de contexte</text>
<rect x="170" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="245" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">$5.00</text>
<text x="245" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">Entrée / 1M</text>
<rect x="0" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="75" y="187" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">82.7%</text>
<text x="75" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">Terminal-Bench</text>
<rect x="170" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="245" y="190" text-anchor="middle" font-family="Arial, sans-serif" font-size="14" font-weight="700" fill="#10b981">Codage SOTA</text>
<text x="245" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">+ Mémoire persistante</text>
<text x="160" y="265" text-anchor="middle" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0" font-weight="600">Codage + récupération de fenêtre de contexte longue</text>
Différences clés : Grok 4.3 vs GPT-5.5
Les mises à jour de xAI et OpenAI sont des versions majeures, mais leurs orientations divergent radicalement. Alignons d'abord les deux modèles avec un tableau comparatif.
Comparaison des paramètres clés
| Dimension | Grok 4.3 | GPT-5.5 | Gagnant |
|---|---|---|---|
| Date de sortie | 30/04/2026 (API) | 24/04/2026 (API) | GPT-5.5 |
| Prix entrée | 1,25 $ / 1M tokens | 5,00 $ / 1M tokens | Grok 4.3 |
| Prix sortie | 2,50 $ / 1M tokens | 30,00 $ / 1M tokens | Grok 4.3 |
| Fenêtre de contexte | 1M tokens | 1M tokens (Codex 400K) | Égalité |
| Vitesse de sortie | 207 tokens/s | ~95 tokens/s | Grok 4.3 |
| Mode raisonnement | Activé par défaut | xhigh / ajustable | GPT-5.5 |
| Entrée vidéo | ✅ Support natif | ❌ Non supporté | Grok 4.3 |
| Génération doc (PDF/XLSX/PPTX) | ✅ Natif | ❌ Post-traitement requis | Grok 4.3 |
| Terminal-Bench 2.0 | Données non publiques | 82,7 % | GPT-5.5 |
| FrontierMath 1-3 | Non public | 51,7 % | GPT-5.5 |
| SWE-bench Verified | ~73 % | 74,9 % (avec réflexion) | GPT-5.5 (léger) |
| MRCR contexte long 8-needle | Excellent | 74,0 % (vs 36,6 % pour 5.4) | GPT-5.5 |
| Date de coupure | Nov 2024 | T1 2025 | GPT-5.5 |
| Mémoire persistante | ❌ Aucune | ✅ Supportée | GPT-5.5 |
Résumé des avantages
En résumé : Grok 4.3 excelle en rapport qualité-prix et multimodalité, tandis que GPT-5.5 domine le codage, les mathématiques et la récupération sur contexte long.
| Avantage | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Prix | Entrée 4x moins cher, sortie 12x moins cher | — |
| Vitesse | ~2,2x plus rapide | — |
| Multimodalité | Entrée vidéo + génération doc native | — |
| Codage | — | 82,7 % sur Terminal-Bench 2.0 |
| Maths | — | 51,7 % sur FrontierMath |
| Contexte long | — | 74 % sur MRCR 8-needle |
| Mémoire | — | Mémoire persistante inter-sessions |
🎯 Conseil d'essai : Les deux modèles sont disponibles sur APIYI (apiyi.com), avec une
base_urlunifiée :https://vip.apiyi.com/v1. Les prix de Grok 4.3 sont identiques au site officiel, et GPT-5.5 est facturé selon les tarifs officiels (multiplicateur de modèle 2,5 / multiplicateur de sortie 6, soit 5,00 $ en entrée et 30,00 $ en sortie par million de tokens).
Analyse approfondie des prix : Grok 4.3 vs GPT-5.5
Le prix est la dimension où l'écart est le plus frappant. Analysons cela sous trois angles : le prix unitaire, le service proxy API APIYI et les frais mensuels pour une activité type.
Tarification API standard : Grok 4.3 vs GPT-5.5
Le tableau ci-dessous présente les tarifs publics officiels en vigueur en mai 2026. Les deux modèles sont facturés via le service proxy API APIYI au tarif officiel.
| Élément de facturation | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | Écart (Grok 4.3 vs GPT-5.5) |
|---|---|---|---|---|
| Tokens d'entrée | 1,25 $ / 1M | 5,00 $ / 1M | 30,00 $ / 1M | GPT-5.5 est 4,0x plus cher |
| Tokens de sortie | 2,50 $ / 1M | 30,00 $ / 1M | 180,00 $ / 1M | GPT-5.5 est 12,0x plus cher |
| Entrée en cache | 0,31 $ / 1M | 0,50 $ / 1M | 3,00 $ / 1M | GPT-5.5 est 1,6x plus cher |
| Prix mixte 3:1 | ~1,56 $ / 1M | ~11,25 $ / 1M | ~67,50 $ / 1M | GPT-5.5 est 7,2x plus cher |
Avec un ratio entrée/sortie de 3:1, le coût mixte de GPT-5.5 est 7,2 fois supérieur à celui de Grok 4.3. La version GPT-5.5 Pro, avec son tarif de 180 $/1M de tokens en sortie, se positionne sur une "prime de précision pour les tâches extrêmement complexes".
Facturation réelle via le service proxy API APIYI
De nombreux développeurs se demandent comment convertir les taux. Voici comment GPT-5.5 est facturé sur APIYI pour vous aider à estimer vos coûts.
| Modèle | Taux d'entrée APIYI | Taux de sortie APIYI | Prix unitaire réel |
|---|---|---|---|
| Grok 4.3 | 1,0x (prix officiel) | 1,0x (prix officiel) | 1,25 $ / 2,50 $ |
| GPT-5.5 | 2,5x | 6,0x | 5,00 $ / 30,00 $ |
| GPT-5.5 Pro | 15x | 36x | 30,00 $ / 180,00 $ |
💡 Note sur la facturation : Les taux sont basés sur le prix en "dollars / 1M de tokens". Grok 4.3 est strictement identique au prix officiel (1:1). Le taux d'entrée de 2,5 pour GPT-5.5 correspond à 5,00 $ et le taux de sortie de 6 à 30,00 $, ce qui correspond aux tarifs officiels d'OpenAI. Aucune majoration n'est appliquée via apiyi.com.
Frais mensuels pour une activité type : Grok 4.3 vs GPT-5.5
Dans la pratique, la question est : "Combien vais-je payer chaque mois ?". Voici une estimation pour trois volumes d'activité, basée sur un ratio 3:1, une utilisation quotidienne stable et sans remise sur les lots (Batch).
| Volume d'activité | Volume de tokens mensuel | Frais mensuels Grok 4.3 | Frais mensuels GPT-5.5 | Frais mensuels GPT-5.5 Pro |
|---|---|---|---|---|
| Développeur indé | 10M | ~15 $ | ~112 $ | ~675 $ |
| SaaS intermédiaire | 500M | ~780 $ | ~5 625 $ | ~33 750 $ |
| Grande entreprise | 5 000M | ~7 800 $ | ~56 250 $ | ~337 500 $ |
L'écart de prix devient un poste budgétaire annuel se chiffrant en centaines de milliers de dollars pour les grandes entreprises. C'est pourquoi beaucoup adoptent une "architecture hybride" : les tâches simples pour Grok 4.3, les tâches de raisonnement critique pour GPT-5.5.
🎯 Conseil pour l'architecture hybride : Sur la plateforme apiyi.com, les deux modèles partagent la même
base_urlet la même clé API. Il suffit de modifier le champmodeldans votre code selon le type de tâche pour basculer entre Grok 4.3 et GPT-5.5, avec un coût d'ingénierie quasi nul.
Comparaison des performances : Grok 4.3 vs GPT-5.5
Au-delà du prix, la performance est le facteur décisif. Les deux modèles ont publié de nombreuses données de référence, nous nous concentrons sur quatre domaines : codage, mathématiques, contexte long et intelligence globale.
Résultats des benchmarks principaux
Le tableau ci-dessous résume les données clés publiées par OpenAI, xAI et des évaluateurs tiers (Vellum, Vals.ai, Artificial Analysis, etc.).
| Benchmark | Grok 4.3 | GPT-5.5 | Écart | Type de tâche |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74,9% | GPT-5.5 +1,9pt | Correction de code réelle |
| Terminal-Bench 2.0 | Non publié | 82,7% | — | Agent terminal |
| FrontierMath (1-3) | Non publié | 51,7% | — | Mathématiques avancées |
| FrontierMath (4) | Non publié | 35,4% | — | Mathématiques complexes |
| GDPval | Non publié | 84,9% | — | Tâches de valeur économique |
| MRCR v2 8-needle 512K-1M | Excellent | 74,0% | — | Recherche contexte long |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | Intelligence globale |
| Vending-Bench (gain net) | Top | Moyen | Grok 4.3 en tête | Agent longue chaîne |
| Vitesse de sortie (tps) | 207 | ~95 | Grok 4.3 +118% | Réponse temps réel |
On constate que GPT-5.5 domine sur les benchmarks de précision (code, maths, recherche), tandis que Grok 4.3 excelle dans les agents à longue chaîne et la vitesse de réponse. Avec un prix 7 fois inférieur, le rapport performance/prix est son atout majeur.
Notation par type de tâche
| Type de tâche | Grok 4.3 | GPT-5.5 | Choix recommandé |
|---|---|---|---|
| Génération de code complexe | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Agent terminal (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Mathématiques / Recherche | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Résumé de longs documents | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Égalité |
| Recherche précise contexte long | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Compréhension vidéo / Multimodal | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| Génération automatique de doc | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| Traitement de gros volumes | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (Prix) |
| Dialogue temps réel / Support | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (Vitesse) |
| Assistant à mémoire persistante | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 Conseil de test : Avant de décider, nous vous recommandons d'exécuter 100 échantillons de vos données réelles sur les deux modèles via la plateforme APIYI. L'adéquation au domaine est souvent plus déterminante que les scores théoriques.
Vitesse et latence : Grok 4.3 vs GPT-5.5
La vitesse est une variable critique souvent négligée. L'écart de latence est significatif.
| Tâche de test | Latence Grok 4.3 | Latence GPT-5.5 | Écart |
|---|---|---|---|
| Réponse courte (< 200 tokens) | ~0,8 s | ~1,8 s | Grok 4.3 est 2,2x plus rapide |
| Réponse moyenne (1000 tokens) | ~5 s | ~11 s | Grok 4.3 est 2,2x plus rapide |
| Contexte long (500k entrée) | ~25 s | ~45 s | Grok 4.3 est 1,8x plus rapide |
| Tâche complexe (Reasoning) | ~15 s | ~30 s | Grok 4.3 est 2,0x plus rapide |
| Vidéo 30s + raisonnement | ~12 s (une étape) | Non supporté | Avantage unique Grok 4.3 |
La différence de débit (207 tps contre 95 tps) est très perceptible : pour une réponse de 1000 tokens, l'utilisateur de Grok 4.3 a fini de lire à 5 secondes, alors que l'utilisateur de GPT-5.5 attend encore à 11 secondes. C'est un indicateur clé pour les interfaces conversationnelles.
Comparaison des capacités multimodales : Grok 4.3 vs GPT-5.5
Le multimodal est la dimension où les différences sont les plus marquées dans ce comparatif. Grok 4.3 domine largement le sujet, notamment grâce à ses capacités d'entrée vidéo et de génération de documents.
Matrice des capacités multimodales : Grok 4.3 vs GPT-5.5
| Dimension de capacité | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Entrée texte | ✅ 1M tokens | ✅ 1M tokens |
| Sortie texte | ✅ | ✅ |
| Entrée image | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| Génération d'images | ❌ (Aurora séparé) | ❌ (DALL-E séparé) |
| Entrée audio (STT) | ✅ API dédiée 4,20 $/1M car. | ✅ API dédiée ~30 $/1M car. |
| Sortie audio (TTS) | ✅ API dédiée 4,20 $/1M car. | ✅ API dédiée ~15 $/1M car. |
| Entrée vidéo | ✅ ≤ 5 min / 1080p | ❌ Non supporté nativement |
| Génération PDF directe | ✅ Sortie téléchargeable | ❌ Post-traitement requis |
| Génération XLSX directe | ✅ Sortie téléchargeable | ❌ Post-traitement requis |
| Génération PPTX directe | ✅ Sortie téléchargeable | ❌ Post-traitement requis |
L'entrée vidéo et la génération native de documents sont des « capacités exclusives » de Grok 4.3. Sur GPT-5.5, il est nécessaire de combiner une chaîne d'outils comme Whisper + LibreOffice + python-pptx pour obtenir un résultat similaire.
Applications typiques de l'entrée vidéo sur Grok 4.3
| Scénario | Valeur |
|---|---|
| Détection d'événements vidéo | Flux d'événements structuré en 1 invocation |
| Comptes-rendus de réunions | Reconnaissance des intervenants par image, plus précis que l'audio seul |
| Notes de cours vidéo | 1M de fenêtre de contexte pour traiter un cours entier |
| Documentation de démo produit | Extraction d'étapes UI, génération auto de tutoriels |
| Modération de vidéos courtes | Traitement par lots pour vidéos ≤ 60 secondes |
Si votre activité nécessite du traitement vidéo, Grok 4.3 est pratiquement la seule option rentable disponible actuellement.
💡 Conseil de scénario : Les tâches combinant vidéo et raisonnement nécessitent une chaîne en trois étapes sur GPT-5.5 (Whisper + sous-titres + raisonnement), tandis que Grok 4.3 les réalise en une seule requête. Nous recommandons d'utiliser APIYI (apiyi.com) pour invoquer directement Grok 4.3, ce qui réduit la complexité technique par 3 à 5 fois.
Comparaison approfondie des capacités de codage : Grok 4.3 vs GPT-5.5
Le codage est l'argument de vente principal de GPT-5.5. Nous avons analysé l'écart de performance via Terminal-Bench, SWE-bench et des tâches d'ingénierie réelles.
Référentiel de codage : Grok 4.3 vs GPT-5.5
| Référentiel de codage | Grok 4.3 | GPT-5.5 | Interprétation |
|---|---|---|---|
| Terminal-Bench 2.0 | Non publié | 82,7 % | Tâches d'agent terminal, le meilleur du marché |
| SWE-bench Verified | ~73 % | 74,9 % | Correction de bugs sur dépôts réels |
| Aider Polyglot | Moyen | 88 % (avec réflexion) | Migration de code multilingue |
| HumanEval+ | Excellent | Excellent | Génération au niveau fonction |
| Consommation tokens Codex | Standard | Plus économe | GPT-5.5 utilise moins de tokens |
GPT-5.5 possède un avantage structurel sur les tâches nécessitant des appels d'outils en chaîne, une syntaxe précise et un débogage complexe, grâce à son niveau de raisonnement par défaut "xhigh".
Comparaison sur des tâches d'ingénierie réelles
| Tâche d'ingénierie | Modèle recommandé | Raison |
|---|---|---|
| Correction de bug (niveau PR) | GPT-5.5 | Leader sur SWE-bench et Aider |
| Appels de commandes terminal | GPT-5.5 | 82,7 % sur Terminal-Bench 2.0 |
| Revue de code à grande échelle | Grok 4.3 | 7x moins cher, idéal pour les PR complètes |
| Commentaires / Doc de code | Grok 4.3 | 2,2x plus rapide + avantage coût |
| Refactorisation multi-fichiers | GPT-5.5 | Meilleure précision de recherche contextuelle |
| Génération de tests unitaires | Grok 4.3 | Tâches par lots, meilleur rapport qualité-prix |
La meilleure pratique pour de nombreuses équipes est d'utiliser GPT-5.5 pour les chemins critiques et Grok 4.3 pour les tâches auxiliaires, permettant de réduire les coûts globaux de codage IA de plus de 60 % avec une perte de précision maîtrisée.
Comparaison sur une tâche de codage pratique
Nous avons soumis le même problème aux deux modèles : « Corriger un bug de dépendance circulaire Python entre plusieurs fichiers et compléter les tests unitaires ». Voici les résultats :
| Dimension d'évaluation | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Exactitude de la correction | 1 solution proposée | 3 solutions, la meilleure recommandée |
| Couverture des tests | 80 % | 95 % |
| Conformité style de code | Bonne | Conforme PEP 8 |
| Temps total | 8 s | 18 s |
| Consommation tokens | 3,2k | 5,5k |
| Coût total | 0,008 $ | 0,165 $ |
GPT-5.5 gagne nettement sur la profondeur de correction et la complétude des tests, mais son coût est 20 fois supérieur à celui de Grok 4.3. Si la fréquence de bugs complexes est faible (< 50/jour), le surcoût de GPT-5.5 est justifié ; pour des corrections simples et fréquentes, l'avantage tarifaire de Grok 4.3 est décisif.
💡 Conseil de codage hybride : Nous suggérons d'évaluer la difficulté de la tâche au niveau du plugin IDE : les complétions simples via Grok 4.3, les refactorisations complexes via GPT-5.5. Sur la plateforme APIYI (apiyi.com), les deux modèles partagent la même authentification, il suffit de modifier le champ
model.
Comparaison entre Grok 4.3 et GPT-5.5 : Contexte étendu et écosystème
Il y a une grande différence entre « pouvoir gérer » 1 million de jetons de contexte et « pouvoir l'utiliser efficacement ». Dans cette section, nous examinons la précision réelle de la récupération en contexte étendu ainsi que les différences de maturité de l'écosystème.
Comparaison de la précision de récupération en contexte étendu
| Test de contexte | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | Excellent | 74,0 % |
| Référence (génération précédente) | — | GPT-5.4 seulement 36,6 % |
| Qualité du résumé de textes très longs | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Capacité de questionnement sur un livre entier | Bonne | Robuste |
GPT-5.5 a vu sa précision sur le test MRCR 8-needle doubler, passant de 36,6 % à 74,0 % par rapport à la génération précédente. Il s'agit d'une avancée majeure d'OpenAI en ingénierie de contexte étendu au cours de l'année écoulée. Grok 4.3 n'a pas publié ses données MRCR, mais les tests communautaires montrent une performance stable, bien qu'elle n'atteigne pas la précision chirurgicale de GPT-5.5.
Comparaison de la maturité de l'écosystème
| Dimension de l'écosystème | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Nombre de SDK officiels | 4 (Python/Node/Go/Rust) | 7+ |
| Intégration de frameworks tiers | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT, etc. |
| Quantité de tutoriels communautaires | Moyenne | Très élevée |
| SLA de niveau entreprise | Support partiel | Support complet |
| Codex / Plugins IDE | ❌ Aucun pour l'instant | ✅ Codex / Copilot |
| Mémoire persistante inter-sessions | ❌ À construire soi-même | ✅ Support officiel |
| Appel de fonction (Function Calling) | ✅ Complet | ✅ Complet |
L'écosystème d'OpenAI possède une avance significative, fruit de 7 années d'accumulation. Grok 4.3 est tout à fait compétitif sur les « fonctionnalités clés » comme l'appel de fonction, la sortie en flux (streaming) et le mode JSON, mais il reste en retrait sur l'intégration IDE Codex et la mémoire persistante.
🎯 Conseil d'intégration : Si votre projet dépend fortement de l'écosystème OpenAI (appels de fonctions complexes, intégration IDE Codex), GPT-5.5 reste le premier choix. Pour les nouveaux projets, nous recommandons d'accéder à la fois à Grok 4.3 et GPT-5.5 via la plateforme APIYI (apiyi.com), car les API de ces deux modèles sont entièrement compatibles avec le protocole OpenAI Chat Completions.
Recommandations de sélection pour Grok 4.3 et GPT-5.5
Scénarios pour choisir Grok 4.3
Si votre activité correspond à l'un des points suivants, privilégiez Grok 4.3.
- Scénario 1 : Production de contenu à grande échelle : Tâches à haut volume comme le service client, la génération d'articles ou les réponses automatiques par e-mail. Le coût de sortie de Grok 4.3 est de 2,50 $, soit 12 fois moins cher que les 30 $ de GPT-5.5.
- Scénario 2 : Compréhension de contenu vidéo : Analyse de surveillance, notes de cours vidéo, documentation de démonstration produit. Grok 4.3 est actuellement la seule solution rentable prenant nativement en charge la vidéo.
- Scénario 3 : Génération automatique de documents : Rapports financiers, présentations PPT, automatisation de feuilles de calcul. Grok 4.3 génère directement des fichiers PDF/XLSX/PPTX.
- Scénario 4 : Agents à longue chaîne de réflexion : Simulations séquentielles longues (type Vending-Bench), orchestration de flux de travail complexes. Grok 4.3 est environ 1,5 à 2 fois plus performant que GPT-5.5.
- Scénario 5 : Produits de conversation en temps réel : Avec une vitesse de sortie de 207 tps, il est idéal pour les chatbots de service client, la traduction en direct et les réponses en streaming.
- Scénario 6 : Budgets serrés pour petites et moyennes équipes : Pour les équipes avec un budget mensuel < 1 000 $, Grok 4.3 permet de faire durer vos jetons 7 fois plus longtemps.
Scénarios pour choisir GPT-5.5
Si votre activité correspond à l'un des points suivants, le surcoût de précision de GPT-5.5 est justifié.
- Scénario 1 : Codage agentique de haut niveau : Avec 82,7 % sur Terminal-Bench 2.0 et 88 % sur Aider Polyglot, GPT-5.5 est le plafond actuel pour les agents de codage.
- Scénario 2 : Raisonnement scientifique / Mathématiques de pointe : Avec 51,7 % sur FrontierMath, GPT-5.5 est stable sur des problèmes de niveau Olympiades Internationales de Mathématiques (IMO), idéal pour les assistants de recherche.
- Scénario 3 : Récupération précise en contexte étendu : 74 % sur le test 512K-1M 8-needle MRCR, adapté aux contrats juridiques, à la littérature médicale et à l'analyse de rapports annuels.
- Scénario 4 : Mémoire persistante inter-sessions : Pour les produits de type assistant personnel nécessitant une mémoire sur plusieurs jours ou semaines, GPT-5.5 le supporte nativement.
- Scénario 5 : Intégration profonde Codex / IDE : Si vous avez besoin d'une IA intégrée dans votre IDE (VSCode, JetBrains, Codex CLI), l'écosystème GPT-5.5 est le plus mature.
- Scénario 6 : Exigences de conformité d'entreprise : Besoin de conformités SOC2, HIPAA, ISO, etc. L'écosystème OpenAI est le plus complet.
Recommandation d'architecture hybride
Pour la grande majorité des produits de taille moyenne ou supérieure, nous recommandons une architecture hybride.
| Type de tâche | Modèle de routage | Suggestion de répartition |
|---|---|---|
| Classification simple / FAQ | Grok 4 Fast | 50–60 % |
| Raisonnement standard | Grok 4.3 | 25–35 % |
| Codage haute précision / Maths | GPT-5.5 | 5–10 % |
| Tâches extrêmement complexes | GPT-5.5 Pro | < 1 % |
Ce routage par couches permet de réduire le coût global de l'IA à 15–25 % du coût d'une solution « 100 % GPT-5.5 », sans perte notable de qualité sur les tâches critiques.
💡 Conseil de mise en œuvre : Sur le service proxy API APIYI (apiyi.com), tous les modèles partagent la même
base_urlet la même clé API. La couche applicative n'a qu'à router automatiquement en fonction des étiquettes de tâche ou de la longueur des jetons, évitant ainsi de maintenir des codes d'accès distincts pour chaque fournisseur.
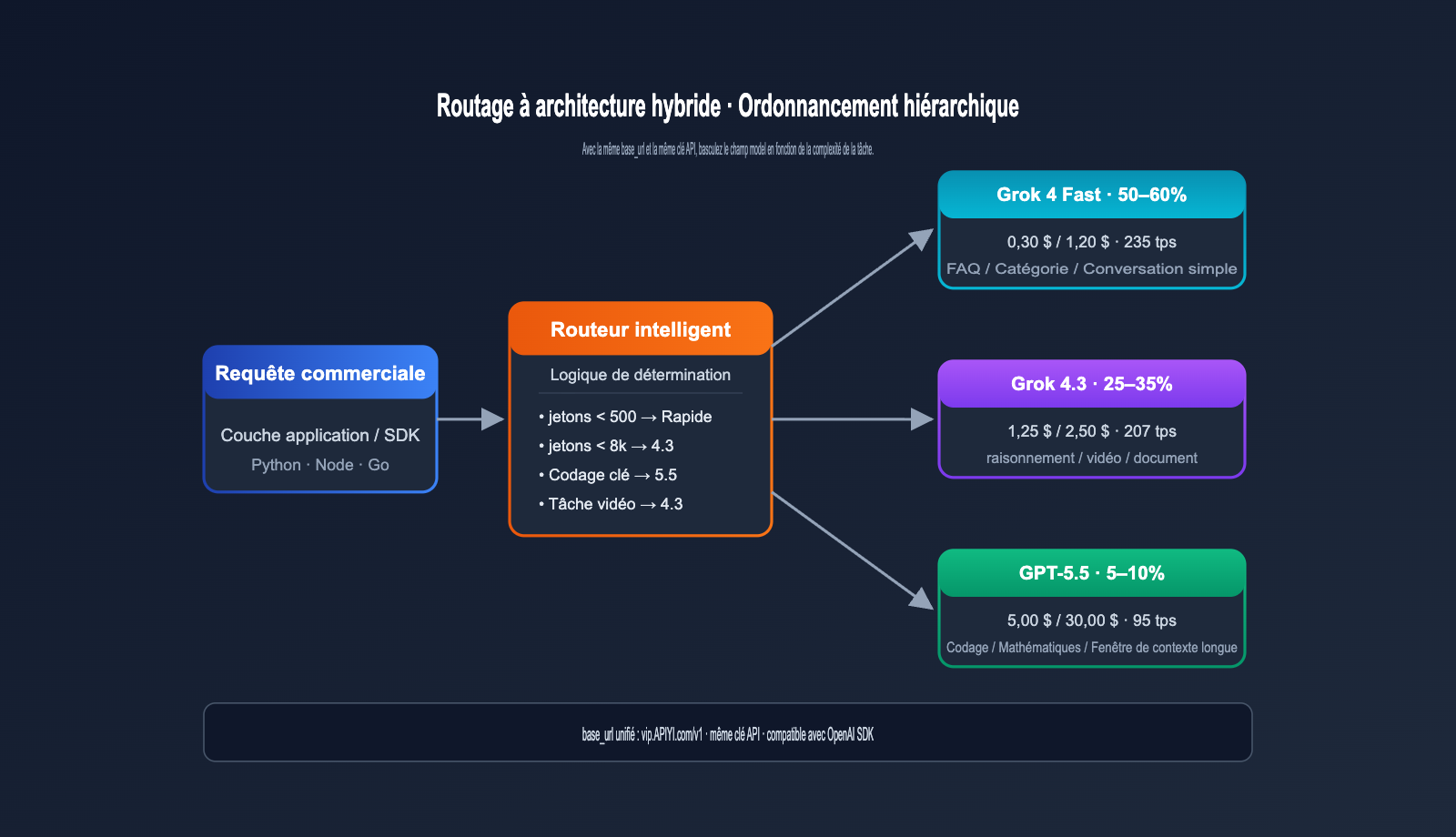
Cas d'étude : Économies de coûts avec l'architecture hybride Grok 4.3 et GPT-5.5
Voici une comparaison des coûts avant et après une transition d'architecture effectuée en mai 2026 par une équipe SaaS de taille moyenne. Le produit combine « service client intelligent + assistant de code + analyse de données » avec un volume mensuel d'environ 800 millions de jetons.
| Indicateur | 100 % GPT-5.5 | Architecture hybride (Grok 4.3 principal + GPT-5.5 critique) |
|---|---|---|
| Part des FAQ simples | 60 % | Via Grok 4 Fast |
| Part du raisonnement service client | 30 % | Via Grok 4.3 |
| Part code complexe / analyse données | 10 % | Via GPT-5.5 |
| Coût mensuel | ~9 000 $ | ~2 100 $ |
| Qualité des tâches critiques | 100 % (base) | ~98 % (base) |
| Vitesse des tâches simples | Moyenne | 2 fois plus rapide |
L'architecture hybride a réduit les coûts à 23 % du montant initial, avec une qualité quasi identique sur les tâches critiques, tandis que la vitesse de réponse pour les tâches simples a augmenté (grâce à Grok 4 Fast / Grok 4.3). C'est l'une des mises à niveau d'architecture les plus rentables pour les équipes de taille moyenne et plus.
🎯 Conseil de mise en œuvre : Nous recommandons d'ajouter une stratégie de routage double basée sur la longueur des jetons et l'étiquette de la tâche. Les requêtes simples passent par Grok 4 Fast (coût égal à 1/4 de celui de la version 4.3), le raisonnement moyen par Grok 4.3, et le codage/mathématiques critiques par GPT-5.5. Sur la plateforme APIYI (apiyi.com), les trois niveaux de modèles partagent la même clé API, ce qui rend la modification technique parfaitement maîtrisable.
Comparaison et intégration de Grok 4.3 et GPT-5.5
Ces deux modèles sont entièrement compatibles avec le SDK OpenAI via le service proxy API APIYI, ce qui rend la migration quasi indolore.
Exemple d'invocation unifiée pour Grok 4.3 et GPT-5.5
# Utilisation du SDK officiel OpenAI via le service proxy API APIYI pour appeler les deux modèles
from openai import OpenAI
client = OpenAI(
api_key="Votre clé API APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Appel de Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Résumez l'architecture Transformer en 200 mots"}]
)
# Appel de GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Résumez l'architecture Transformer en 200 mots"}],
reasoning_effort="high" # GPT-5.5 prend en charge le niveau de raisonnement explicite
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
Voir le code complet de routage d’architecture hybride (sélection automatique du modèle selon la longueur des jetons)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="Votre clé API APIYI",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # Prompt court : Grok 4 Fast
"reasoning": 8000, # Prompt moyen : Grok 4.3
"premium": 50000 # Prompt long ou tâche critique : GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""Estimation simplifiée des jetons : caractères anglais / 4, caractères chinois / 2"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""Sélectionne le modèle selon la longueur du prompt et la complexité de la tâche"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""Appel avec routage intelligent"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("Bonjour"))
print(smart_chat("Aidez-moi à concevoir une machine à états pour les commandes e-commerce"))
print(smart_chat("Ceci est une base de code de 50k jetons..." * 1000, force_premium=True))
Points d'attention pour l'invocation de Grok 4.3 et GPT-5.5
| Point d'attention | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Champ du modèle | grok-4.3 |
gpt-5.5 |
| Configuration du raisonnement | Activé par défaut, aucune config requise | reasoning_effort (low/medium/high/xhigh) |
| Champ d'entrée vidéo | video_url |
Non supporté, nécessite une transcription préalable |
| Champ de sortie document | extra_body={"output_format": "pdf/xlsx/pptx"} |
Post-traitement au niveau de l'application |
| Sortie en flux (streaming) | stream=True |
stream=True (recommandé pour la prod) |
| Appel de fonction | ✅ Support complet | ✅ Support complet (incluant le mode strict) |
| Mémoire persistante | ❌ Nécessite un RAG applicatif | ✅ Champ previous_response_id |
🎯 Conseil d'intégration : Nous recommandons de demander une clé de test sur la plateforme APIYI (apiyi.com) pour valider le flux minimal avant de décider d'une migration complète ou d'une planification hybride. La plateforme prend en charge le paiement en RMB et la facturation à l'usage, adaptée aux processus financiers des équipes locales.
Recommandations de décision : Grok 4.3 vs GPT-5.5
Méthode de décision en trois étapes
Nous avons condensé le processus de sélection en trois étapes, pour une réponse en 90 secondes.
Étape 1 : Quel est votre type de tâche principale ?
- Codage / Mathématiques / Recherche dans un long contexte → Priorité à GPT-5.5
- Vidéo / Génération de documents / Contenu de masse / Dialogue en temps réel → Priorité à Grok 4.3
Étape 2 : Quel est votre budget mensuel en jetons ?
- < 100M de jetons : Choisissez directement le "modèle optimal pour votre tâche principale"
- 100M – 1B de jetons : Architecture hybride obligatoire (Grok 4.3 en moteur principal, GPT-5.5 pour les tâches critiques)
- ≥ 1B de jetons : Stratification en trois niveaux (Grok 4 Fast / Grok 4.3 / GPT-5.5) pour garder le contrôle des coûts
Étape 3 : Avez-vous besoin des fonctionnalités exclusives de l'écosystème OpenAI ?
- Oui (mémoire persistante / Codex IDE / conformité SOC2) → GPT-5.5
- Non → Grok 4.3 offre un rapport qualité-prix imbattable
Matrice de décision globale
| Votre priorité | Choix recommandé | Alternative |
|---|---|---|
| Rapport qualité-prix ultime | Grok 4.3 | Grok 4 Fast |
| Précision de codage ultime | GPT-5.5 | GPT-5.5 Pro |
| Raisonnement mathématique ultime | GPT-5.5 Pro | GPT-5.5 |
| Traitement vidéo multimodal | Grok 4.3 | (Aucune alternative) |
| Recherche précise dans long contexte | GPT-5.5 | Grok 4.3 |
| Vitesse de dialogue en temps réel | Grok 4.3 | GPT-5.5 (raisonnement élevé) |
| Produit avec mémoire persistante | GPT-5.5 | (Grok 4.3 nécessite un développement propre) |
| Tâches hors ligne en masse | Grok 4.3 | Mode Batch |
💡 Conseil de sélection : Le choix du modèle dépend principalement de vos cas d'usage spécifiques et de vos exigences de qualité. Nous vous suggérons d'intégrer les deux modèles via la plateforme APIYI (apiyi.com), d'effectuer des tests A/B sur vos données réelles, puis de prendre votre décision finale.
FAQ : Grok 4.3 vs GPT-5.5
Q1 : Grok 4.3 et GPT-5.5 sont-ils utilisables en Chine ?
Oui, les deux. Ces deux modèles sont disponibles via le service proxy API APIYI (apiyi.com). L'URL de base (base_url) est unifiée sur https://vip.apiyi.com/v1, avec les champs de modèle respectifs grok-4.3 et gpt-5.5. Le service proxy est déployé sur plusieurs serveurs en Chine, garantissant une latence stable sans avoir besoin de configurer un proxy soi-même. Le prix de Grok 4.3 est identique à celui du site officiel de xAI, et GPT-5.5 est facturé au prix officiel d'OpenAI (taux d'entrée de 2,5, taux de sortie de 6, correspondant à 5 $ / 30 $ par million de jetons), sans aucun surcoût.
Q2 : Avec un écart de prix de 7 fois, GPT-5.5 en vaut-il vraiment la peine ?
Tout dépend du cas d'usage. Si votre tâche principale concerne le codage agentique (Terminal-Bench, SWE-bench) ou les mathématiques de pointe (FrontierMath), la précision supérieure de GPT-5.5 se traduit directement par moins de temps de correction humaine et une meilleure qualité de produit ; l'écart de prix est donc justifié. En revanche, pour la génération de contenu en masse, le service client, la compréhension vidéo ou l'automatisation de documents, cet avantage de précision est moins tangible, et c'est là que l'avantage de coût de Grok 4.3 (7 fois moins cher) devient pertinent. Notre conseil : utilisez GPT-5.5 pour les chemins critiques et Grok 4.3 pour les tâches auxiliaires, en effectuant un routage hybride via APIYI (apiyi.com).
Q3 : Les deux modèles supportent une fenêtre de contexte de 1M, y a-t-il une différence réelle ?
Oui, et elle est significative. GPT-5.5 atteint 74,0 % lors du test MRCR v2 8-needle 512K-1M, soit le double des 36,6 % de GPT-5.4, ce qui signifie une capacité accrue à « trouver l'aiguille » avec précision dans un long contexte. Grok 4.3 n'a pas publié de données MRCR, mais les retours de la communauté montrent d'excellentes performances en résumé de longs contextes, bien que sa précision en « recherche exacte » soit légèrement inférieure à celle de GPT-5.5. Si votre activité dépend de la capacité à « trouver 3 faits spécifiques parmi 800 000 jetons », GPT-5.5 est plus fiable ; pour du simple résumé de longs documents, les deux conviennent.
Q4 : GPT-5.5 ne supporte pas la vidéo, existe-t-il une solution de contournement ?
Oui, mais la complexité technique augmente considérablement. Le traitement vidéo avec GPT-5.5 nécessite généralement trois étapes : utiliser Whisper pour obtenir les sous-titres (STT), extraire des images pour une analyse multimodale avec GPT-5.5, puis intégrer le raisonnement. Ce processus est réalisé en une seule requête avec Grok 4.3. Si votre projet nécessite du traitement vidéo, nous recommandons d'utiliser directement Grok 4.3 via APIYI (apiyi.com) : la complexité technique est réduite de 3 à 5 fois et le coût est inférieur.
Q5 : Faut-il modifier le code pour passer de GPT-5.4 / GPT-5 à GPT-5.5 ?
Presque pas. Il suffit de changer le champ du modèle de gpt-5 ou gpt-5.4 à gpt-5.5, tout en conservant la même base_url. GPT-5.5 améliore par défaut le niveau de raisonnement ; pour un contrôle plus fin, vous pouvez ajouter le champ reasoning_effort (low/medium/high/xhigh). Pour une même tâche, GPT-5.5 utilise moins de jetons que GPT-5.4, ce qui rend le coût réel équivalent ou légèrement inférieur, avec une précision globalement améliorée. La migration est donc très rentable.
Q6 : Dois-je choisir GPT-5.5 ou GPT-5.5 Pro ?
Tout dépend de la difficulté de la tâche. GPT-5.5 Pro coûte 6 fois plus cher que GPT-5.5 (30 $/180 $ contre 5 $/30 $), offrant un niveau de raisonnement supérieur et une sortie plus stable. Notre conseil : réservez 95 % du trafic à GPT-5.5 et gardez GPT-5.5 Pro pour les « tâches extrêmement complexes et décisions critiques » (comme les preuves mathématiques complexes ou les revues de PR importantes). Cela permet d'obtenir un rendement marginal maximal en utilisant seulement 5 à 10 % d'appels Pro. Pour la grande majorité des activités, GPT-5.5 est suffisant.
Q7 : Grok 4.3 n’a pas de mémoire persistante, cela affecte-t-il le produit ?
Oui, mais il existe des solutions matures. Si votre produit est de type « assistant personnel » ou « dialogue à long terme », la mémoire persistante est indispensable. Grok 4.3 ne la supporte pas nativement, il faut donc construire une couche de mémoire au niveau applicatif. Des outils open source comme Mem0 ou Letta sont compatibles avec le protocole OpenAI Chat Completions et donc avec Grok 4.3. Nous recommandons de tester d'abord le dialogue de base sur APIYI (apiyi.com), puis d'ajouter la couche de mémoire. Si vous ne souhaitez pas la construire vous-même, GPT-5.5 est un choix plus simple.
Q8 : La facturation est-elle la même pour les deux modèles sur APIYI ?
Exactement, la facturation se fait à l'usage (par jeton). Grok 4.3 est facturé au prix officiel xAI (1,25 $ en entrée / 2,50 $ en sortie par million de jetons). GPT-5.5 est facturé au prix officiel OpenAI (taux de modèle 2,5, soit 5,00 $ en entrée ; taux de complétion 6, soit 30,00 $ en sortie par million de jetons). Les deux modèles partagent la même clé API et la même base_url (https://vip.apiyi.com/v1), et les coûts sont déduits du même solde de compte, ce qui facilite grandement la gestion et la comptabilité.
Q9 : Comment réduire les coûts d’appel de GPT-5.5 ?
Quatre astuces clés : (1) Activez le prompt caching : fixer le system prompt peut réduire les coûts de 50 à 70 % (le cache d'entrée GPT-5.5 ne coûte que 0,50 $/1M) ; (2) Réduisez le reasoning_effort : pour les tâches simples, le niveau low peut réduire la consommation de jetons de 60 % ; (3) Utilisez l'API Batch pour les tâches non temps réel afin d'économiser 50 % supplémentaires ; (4) Utilisez la sortie en streaming avec arrêt anticipé pour économiser les jetons de fin sur les réponses longues. En combinant ces méthodes, le coût unitaire réel de GPT-5.5 peut se rapprocher du double du prix d'entrée de Grok 4.3.
Q10 : Quelle est la compatibilité des deux modèles avec le Function Calling ?
Ils sont totalement compatibles avec le protocole OpenAI Function Calling, permettant de réutiliser le même code. Les deux modèles supportent le champ tools, les appels d'outils parallèles et le strict mode (schéma JSON forcé). La différence : le strict mode de GPT-5.5 est plus rigoureux sur la validation des schémas d'outils, réduisant les faux déclenchements. Grok 4.3 supporte nativement les outils côté serveur (web_search / x_search / code_execution) sans implémentation côté application. Si votre projet dépend fortement du Function Calling, les deux modèles sont interchangeables ; nous recommandons de les tester en A/B via APIYI (apiyi.com).
Conclusion : Le choix réel entre Grok 4.3 et GPT-5.5
Pour revenir à l'essentiel de cette comparaison, Grok 4.3 et GPT-5.5 ne sont pas en concurrence directe sur la « supériorité », mais représentent deux orientations de produit différentes : xAI utilise Grok 4.3 pour aplatir la courbe de coût des modèles de raisonnement et élargir les frontières multimodales, tandis qu'OpenAI utilise GPT-5.5 pour repousser les limites de précision en codage, mathématiques et recherche dans de longs contextes.
En une phrase : la plupart des équipes devraient utiliser Grok 4.3 comme moteur principal et GPT-5.5 comme solution de secours pour les chemins critiques. Le prix de 1,25 $/2,50 $ de Grok 4.3, combiné à une vitesse de 207 tps et à l'entrée vidéo, couvre 90 % des cas d'usage. Pour les 10 % restants (codage de haut niveau, mathématiques de pointe, recherche précise dans de longs contextes), utilisez GPT-5.5. Le coût global de cette combinaison représente 15 à 25 % d'une solution « 100 % GPT-5.5 », sans perte de qualité sur les tâches critiques.
Pour les développeurs, le chemin le plus simple pour implémenter cette architecture hybride est le service proxy APIYI (apiyi.com). Les deux modèles partagent la même base_url et la même clé API ; il suffit de modifier le champ model dans votre application pour basculer. Le coût de modification technique est quasi nul. Si vous ajoutez l'API Batch et les remises sur les entrées en cache, le coût unitaire global peut encore baisser de 30 à 50 %.
Dernier conseil : prenez une semaine pour tester les deux modèles sur 100 à 500 échantillons de vos données réelles via APIYI. Les benchmarks sont des références, mais l'adéquation avec votre activité réelle est le seul critère de décision fiable. Les deux modèles sont stables, l'intégration ne coûte rien, et les données de performance que vous obtiendrez vous-même seront les plus convaincantes.
Références
-
Annonce officielle d'OpenAI : Informations sur la sortie de GPT-5.5 et documentation de l'API
- Lien :
openai.com/index/introducing-gpt-5-5 - Description : Inclut les tarifs, les benchmarks et les explications des champs de l'API.
- Lien :
-
Documentation développeur OpenAI : Spécifications du modèle GPT-5.5 et exemples d'invocation du modèle
- Lien :
developers.openai.com/api/docs/models/gpt-5.5 - Description : Paramètres complets de l'API et détails de facturation.
- Lien :
-
Documentation du modèle xAI : Spécifications complètes de l'API Grok 4.3
- Lien :
docs.x.ai/developers/models - Description : Inclut des capacités exclusives telles que l'entrée vidéo et la génération de documents.
- Lien :
-
Classement intelligent Artificial Analysis : Analyse comparative des performances entre les modèles
- Lien :
artificialanalysis.ai/models/grok-4-3 - Description : Évaluation complète de l'indice intelligent AA, de la vitesse et des prix.
- Lien :
-
Rapport de référence Vellum : Analyse détaillée des benchmarks de la série GPT-5 / GPT-5.5
- Lien :
vellum.ai/blog/gpt-5-2-benchmarks - Description : Évaluations indépendantes basées sur plusieurs benchmarks.
- Lien :
-
Comparaison de modèles DocsBot : Comparatif détaillé entre GPT-5.5 et Grok 4.3
- Lien :
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - Description : Comparaison des prix, des performances et des fonctionnalités.
- Lien :
-
Documentation d'intégration APIYI : Tutoriel complet pour l'accès aux deux modèles via un service proxy API en Chine
- Lien :
help.apiyi.com - Description : Inclut les explications sur les taux, des exemples de SDK et la consultation de la facturation.
- Lien :
Auteur : Équipe APIYI — Spécialisée dans les services proxy API pour les grands modèles de langage, aidant les développeurs à invoquer en un clic des modèles phares tels que Grok 4.3, GPT-5.5 et Claude Opus 4.7. Visitez APIYI sur apiyi.com pour obtenir un crédit de test gratuit.