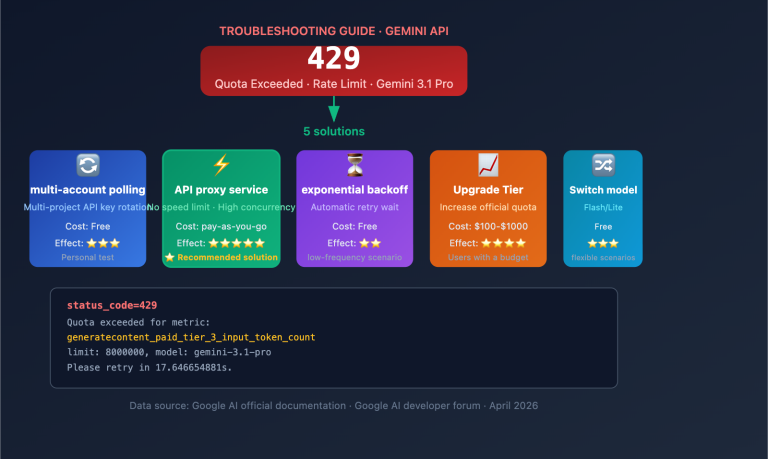
If you've worked with Qwen3.6-Plus, you’ve likely felt the pain: when calling this model via OpenRouter, the 429 Too Many Requests error has become a daily occurrence. Even if you've topped up your account and aren't on a free tier, you're still getting rate-limited to the point of frustration.
Core Value: This article dives deep into the root causes of the Qwen3.6-Plus 429 error, provides three practical solutions, and shares how to achieve stable, low-cost model invocation through the official Alibaba Cloud direct gateway.

Key Takeaways for Qwen3.6-Plus 429 Errors
| Key Point | Description | Developer Benefit |
|---|---|---|
| 429 Root Cause | High demand + free tier abuse + compute allocation strategy | Understand the issue, stop blind retries |
| 3 Solutions | Retry strategies / Switching channels / Official direct gateway | Choose the best path for your scenario |
| Performance Test | Latency comparison across channels | Select the most stable integration method |
| Code Examples | Ready-to-run Python/Node.js | Migrate in 5 minutes |
Why is Qwen3.6-Plus so popular?
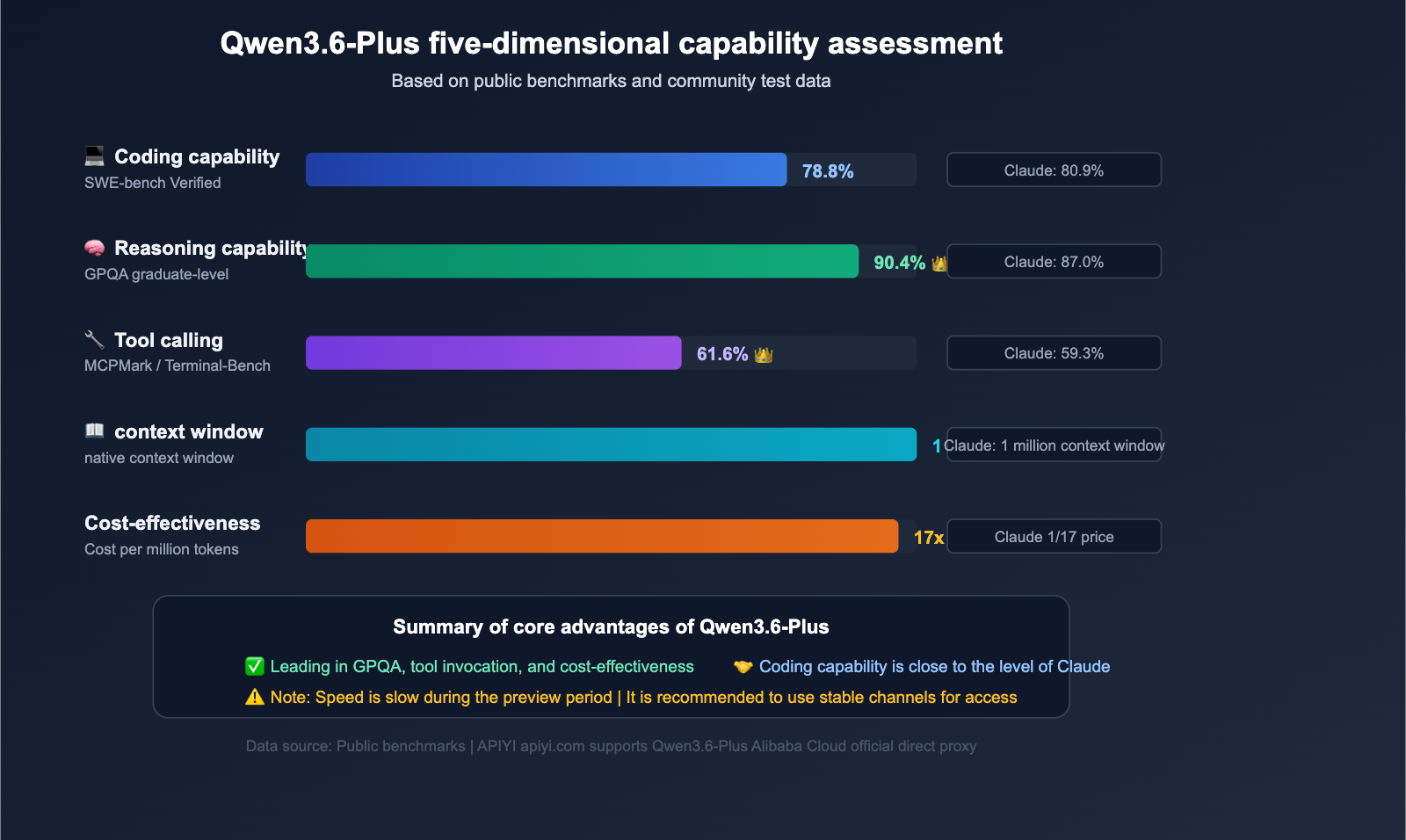
Qwen3.6-Plus is a flagship Large Language Model released by the Alibaba Qwen team in April 2026, directly competing with Claude Opus 4.5 and GPT-5.4. It's popular for a simple reason: high performance at a low price.
| Benchmark | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78.8% | 80.9% | 76.2% |
| Terminal-Bench 2.0 | 61.6% | 59.3% | 57.8% |
| GPQA (Graduate-level Science) | 90.4% | 87.0% | 88.1% |
| MCPMark (Tool Use) | 48.2% | 45.6% | 43.9% |
| Context Window | 1M Tokens | 1M Tokens | 256K Tokens |
| Max Output | 65,536 Tokens | 32,000 Tokens | 16,384 Tokens |
On key benchmarks like Terminal-Bench and GPQA, Qwen3.6-Plus actually outperforms Claude Opus 4.5, while the official API price is only about 1/17th of Claude's. This price-to-performance ratio has triggered a surge in developer demand—which is exactly the root cause of the 429 issues.
Deep Dive into Qwen3.6-Plus 429 Errors
What is a 429 Error?
The HTTP 429 status code is quite clear: Too Many Requests. It means the server has received more requests than it can handle or is willing to allow within a specific timeframe.
A typical 429 error response looks like this:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
4 Main Reasons for Frequent 429 Errors with Qwen3.6-Plus on OpenRouter
Reason 1: Demand Far Exceeds Supply
Qwen3.6-Plus offers incredible value. Its official API entry-level pricing is around $0.29 per million input tokens—that's 1/17th the cost of Claude Opus 4.5. As a result, a massive influx of developers has flooded the platform, and OpenRouter, acting as an API proxy service, has a limited compute quota allocated from Alibaba Cloud.
Reason 2: Heavy Usage by Free-Tier Users
OpenRouter provides a qwen/qwen3.6-plus:free model, which attracts a large number of zero-cost users. These free requests share the same backend resource pool as paid requests, causing paid users to suffer from the congestion.
Reason 3: Conservative Compute Allocation During Preview
Qwen3.6-Plus is still in its preview phase (preview released on March 30, official release on April 2). During this period, Alibaba Cloud typically takes a conservative approach to compute allocation for third-party platforms, prioritizing service quality for its own platforms (DashScope / Bailian).
Reason 4: Bottlenecks in Model Inference Speed
Although community tests show that Qwen3.6-Plus has a throughput roughly 3 times that of Claude Opus 4.6, in real-world usage, its 1 million token context window and MoE architecture still result in higher latency when handling complex agent tasks. This means each request occupies the GPU for longer, reducing the total number of requests that can be processed per unit of time.
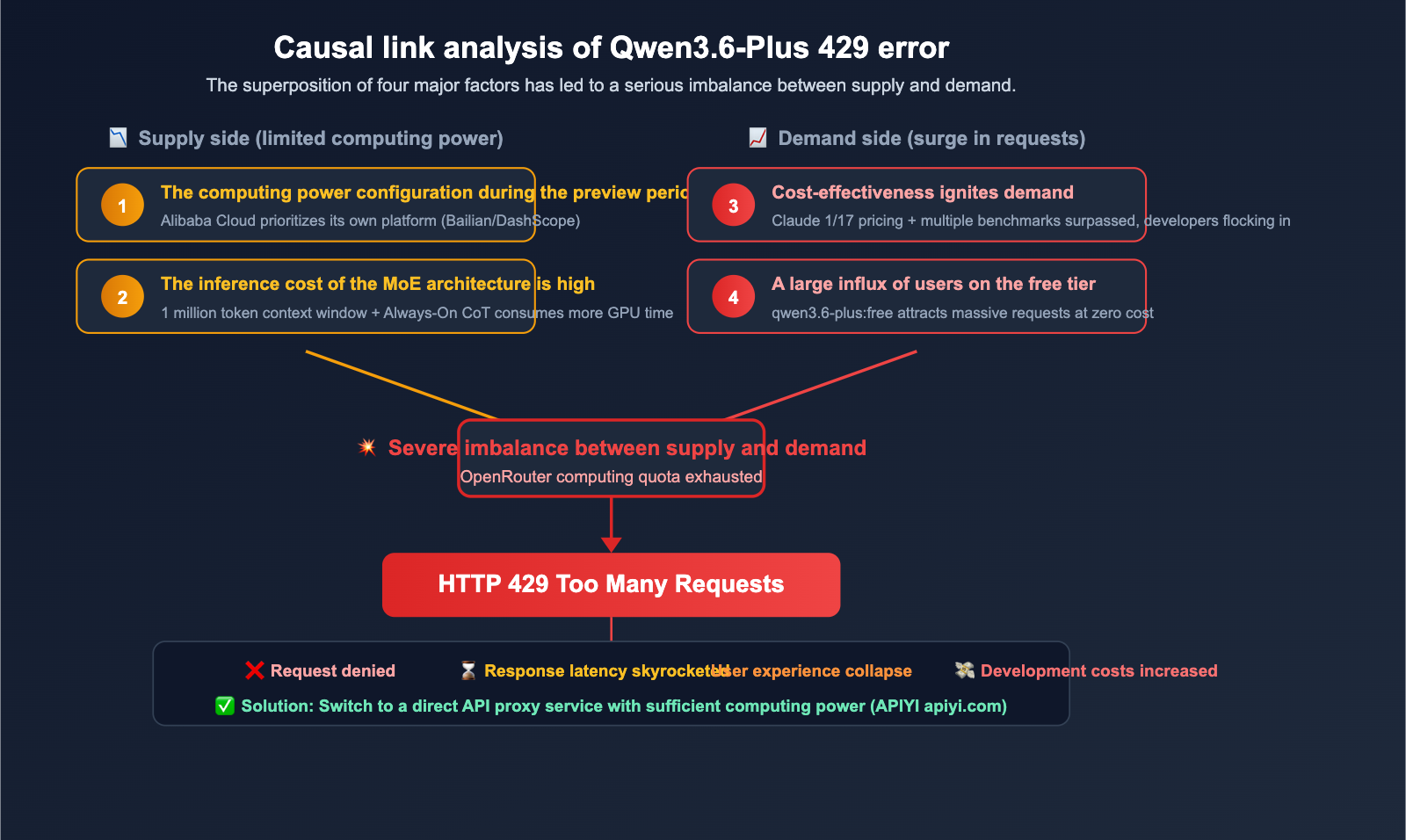
🎯 Core Insight: A 429 error doesn't mean your code is broken; it's a supply-demand imbalance. The best approach is to switch to a channel with sufficient supply rather than retrying indefinitely. By using APIYI (apiyi.com) to access the official Alibaba Cloud direct-transfer channel, you can effectively bypass OpenRouter's rate limits.
Qwen3.6-Plus 429 Error Solution 1: Intelligent Retry Strategy
Exponential Backoff Retry
When you can't switch channels immediately, a sound retry strategy can help mitigate (though not completely solve) 429 issues:
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface, official Alibaba Cloud direct-transfer
)
def call_qwen36_with_retry(messages, max_retries=5):
"""Qwen3.6-Plus invocation with exponential backoff"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 rate limit, retry attempt {attempt+1}, waiting {wait_time:.1f}s...")
time.sleep(wait_time)
# Usage example
result = call_qwen36_with_retry([
{"role": "user", "content": "Analyze the performance bottleneck of this code"}
])
print(result)
Recommended Retry Strategy Parameters
| Parameter | Recommended Value | Description |
|---|---|---|
| Max Retries | 3-5 times | More than 5 retries suggests the channel itself is unstable |
| Initial Wait Time | 1-2 seconds | Too short is ineffective; too long wastes time |
| Backoff Multiplier | 2x | Exponential backoff is the industry standard |
| Jitter | 0-1 seconds | Prevents the "thundering herd" effect |
| Timeout Limit | 30 seconds | Single wait time should not exceed 30 seconds |
Limitations of Retry Strategies
It's important to be clear: retries are a painkiller, not a cure. When the backend for Qwen3.6-Plus on OpenRouter is consistently overloaded, the success rate of retry strategies will drop sharply. The more fundamental solution is to switch to an API channel with sufficient capacity.
Qwen3.6-Plus 429 Error Solution Part 2: Switching API Providers
Why switching providers is more effective than retrying
The root cause of frequent 429 errors on OpenRouter is insufficient compute quota for Qwen3.6-Plus on that specific channel. Switching to a provider that connects directly to Alibaba Cloud's compute resources solves the problem at the source.
Qwen3.6-Plus API Provider Comparison
| Provider | Stability | Price (Input/Million Tokens) | 429 Frequency | Data Collection |
|---|---|---|---|---|
| OpenRouter Free | Poor | Free | Extremely High | Yes (Training data) |
| OpenRouter Paid | Average | ~$0.29 | Frequent | Yes (Preview period) |
| Alibaba Cloud Bailian | Good | ¥2.00 | Low | Subject to terms |
| APIYI (Alibaba Direct) | Good | 20% Off Official | Low | No |
💡 Recommendation: If your application requires high stability, we recommend accessing Qwen3.6-Plus via APIYI (apiyi.com). This platform uses an official Alibaba Cloud direct-access channel, offering prices at 80% of the official rate (0.88x discount on group pricing + $10 bonus for every $100 topped up), while effectively avoiding OpenRouter's rate-limiting issues.
Migrating from OpenRouter to APIYI takes just 2 lines of code
Migration is incredibly simple—just update your base_url and api_key:
import openai
# ❌ Before: OpenRouter (Frequent 429s)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ Now: APIYI Alibaba Direct (Stable, no 429s)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "You are a professional code review assistant"},
{"role": "user", "content": "Help me optimize the performance of this SQL query"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Node.js version:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // APIYI unified interface
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: 'Analyze the time complexity of this code' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);
Qwen3.6-Plus 429 Error Solution Part 3: Local Request Optimization
Reduce unnecessary API calls
Beyond switching providers, optimizing your request patterns can also reduce the probability of triggering 429 errors:
1. Batch requests
# ❌ Inefficient: Sending one by one
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analyze: {item}"}]
)
# ✅ Efficient: Batching
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analyze the following content in order:\n{batch_content}"}],
max_tokens=16384
)
2. Cache high-frequency responses
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. Request queue rate limiting
| Optimization Strategy | Effect | Use Case |
|---|---|---|
| Request Batching | Reduces request volume by 60-80% | Batch data processing |
| Response Caching | Zero API calls for identical requests | Repeated query scenarios |
| Queue Rate Limiting | Smooths out request spikes | High-concurrency applications |
| Fallback Strategy | Automatically switches to smaller models on 429 | Latency-sensitive services |
🔧 Technical Advice: The local optimization strategies above work best when paired with a stable API provider. By accessing Qwen3.6-Plus via APIYI (apiyi.com) and combining it with request batching and caching, you can ensure stability while further reducing costs.
Analysis of Qwen3.6-Plus Latency Issues
Why Qwen3.6-Plus responses can sometimes be slow
Many developers have reported that even without hitting 429 errors, Qwen3.6-Plus responses can feel "mysteriously slow." This isn't an isolated case; there are technical reasons behind it:
1. Inference overhead of the MoE architecture
Qwen3.6-Plus uses a Mixture-of-Experts (MoE) architecture. While MoE significantly reduces training costs, it introduces extra overhead during inference due to routing decisions and expert switching. This is especially noticeable when handling long contexts, where MoE architecture is less efficient than dense models with the same parameter count.
2. Memory pressure from the 1M token context window
The 1-million-token context window is a key selling point for Qwen3.6-Plus, but it also means the KV Cache consumes a massive amount of GPU VRAM. When multiple users initiate long-context requests simultaneously, GPU VRAM becomes a bottleneck, causing inference speeds to drop significantly.
3. Limited compute resources during the preview phase
Qwen3.6-Plus is still in its preview phase. During this stage, Alibaba Cloud typically doesn't deploy the same scale of compute resources as they would for a general release. They are likely monitoring real-world usage patterns before gradually scaling up capacity.
4. Extra token consumption from the Always-On inference chain
Qwen3.6-Plus has the "Always-On Chain-of-Thought" inference mode enabled by default. This means the model generates an internal reasoning process for every response, resulting in a total token count that is much higher than the final output. These "hidden tokens" consume additional inference time.
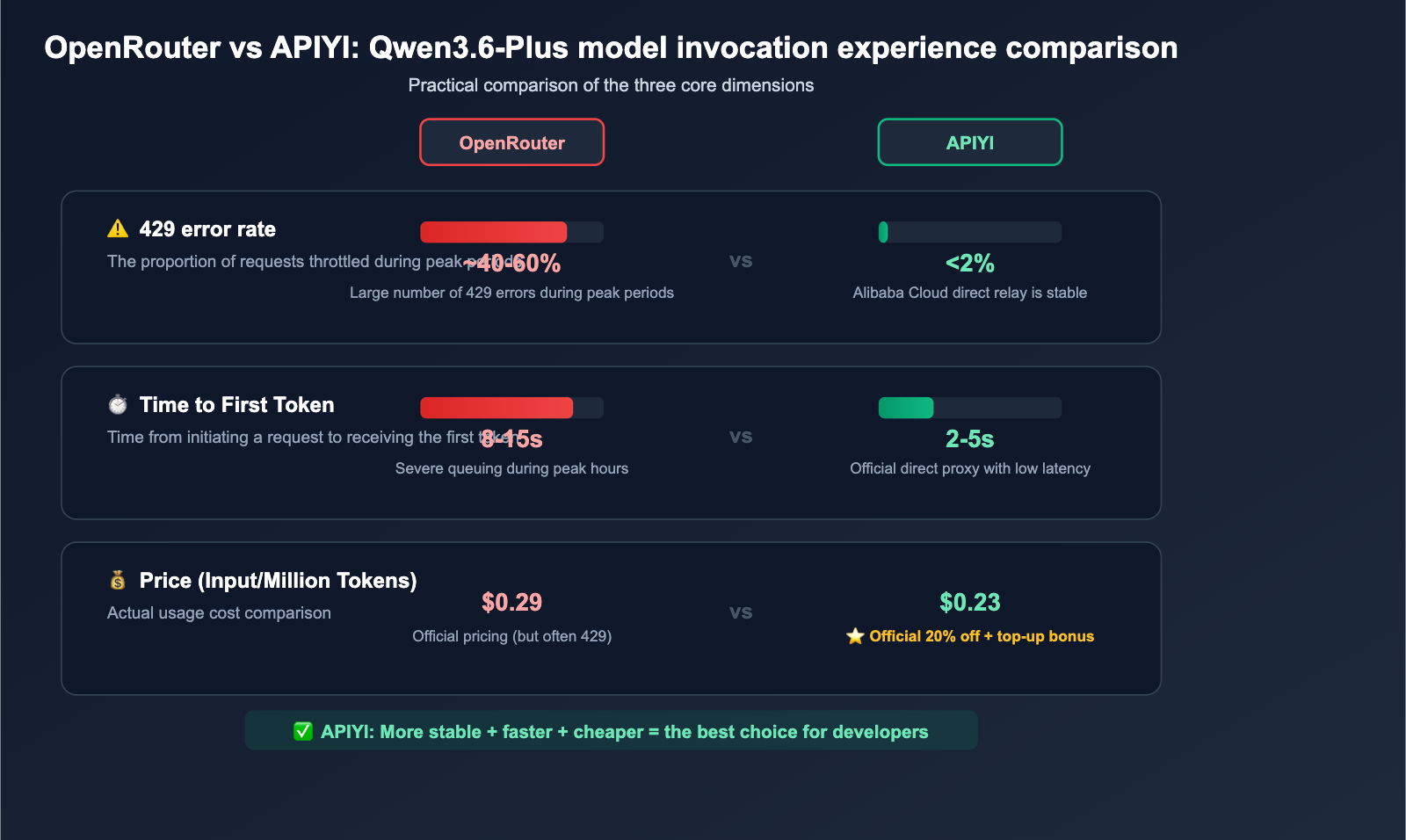
Latency benchmarks across different channels
| Channel | Time to First Token (TTFT) | Throughput (Token/s) | Notes |
|---|---|---|---|
| OpenRouter (Peak) | 8-15s | 15-25 | Frequent 429 errors |
| OpenRouter (Off-peak) | 3-5s | 30-50 | Late night hours |
| Alibaba Cloud Bailian | 2-4s | 40-60 | Direct domestic access |
| APIYI (Direct Proxy) | 2-5s | 35-55 | Stable overseas access |
💰 Cost Tip: Qwen3.6-Plus performance varies significantly across different channels and loads. If you are latency-sensitive, we recommend testing via APIYI (apiyi.com). The platform provides an official Alibaba Cloud direct proxy channel, allowing you to enjoy a 20% discount while achieving more stable response speeds.
Getting Started with Qwen3.6-Plus
Complete example for calling Qwen3.6-Plus via APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Basic chat
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "You are a senior Python development expert."},
{"role": "user", "content": "Help me write a high-performance asynchronous crawler framework."}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
View full code for streaming output
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Streaming output - ideal for scenarios requiring real-time feedback
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "You are a senior architect."},
{"role": "user", "content": "Design a message queue system that supports millions of concurrent requests."}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # New line
🚀 Quick Start: We recommend getting your API key via the APIYI (apiyi.com) platform to call Qwen3.6-Plus. Register to start, and get a $10 bonus when you top up $100. Plus, you'll enjoy a 20% discount on official Qwen3.6-Plus pricing.
Qwen3.6-Plus Use Cases and Selection Guide
When to Use Qwen3.6-Plus
| Use Case | Why Choose It | Alternatives |
|---|---|---|
| Agent Automation | Leads with 61.6% on Terminal-Bench, native tool calling | Claude Opus 4.5 |
| Code Review/Fixing | 78.8% on SWE-bench, near-Claude performance | Claude Opus 4.5 |
| Scientific Reasoning | 90.4% on GPQA, top-tier performance | GPT-5.4 |
| Long Document Processing | 1 million token context window | Gemini 2.5 Pro |
| Cost-Sensitive Projects | Approx. 1/17th the price of Claude | DeepSeek V3 |
When to Exercise Caution
- Latency-Sensitive Real-Time Apps: The MoE architecture of Qwen3.6-Plus can lead to higher latency with long context windows.
- Critical Production Paths: As a preview model, it may undergo unexpected behavioral changes.
- Strict SLA Requirements: There is no formal SLA for this preview model.
🎯 Selection Advice: For projects requiring multiple models, we recommend using the APIYI (apiyi.com) platform for unified access. The platform supports OpenAI-compatible interfaces for Qwen3.6-Plus, Claude, GPT, and other mainstream models. You can switch between models using a single API key, making it easy to manage different scenarios flexibly.
Qwen3.6-Plus 429 Error FAQ
Q1: Why am I still getting 429 errors even after paying for OpenRouter?
This happens because OpenRouter's paid and free users share the same backend compute pool. Even as a paid user, if the total request volume exceeds the compute quota OpenRouter has secured from Alibaba Cloud, you'll be rate-limited. The solution is to switch to a more reliable channel, such as using the official Alibaba Cloud direct-proxy channel via APIYI (apiyi.com).
Q2: Will the 429 errors for Qwen3.6-Plus improve?
As Alibaba Cloud scales its capacity and the model reaches General Availability (GA), 429 issues are expected to subside. However, since OpenRouter is a third-party API proxy service, its compute allocation is always constrained by upstream supply. If your business requires high stability, we recommend using a channel that connects directly to Alibaba Cloud's compute resources rather than relying on a proxy platform.
Q3: What’s the difference between Qwen3.6-Plus on APIYI and OpenRouter?
The core difference is the source of compute. The APIYI (apiyi.com) platform uses the official Alibaba Cloud direct-proxy channel, drawing compute directly from the Alibaba Cloud Bailian platform rather than a third-party proxy. This means fewer 429 errors and more stable response times. In terms of pricing, APIYI offers an official 20% discount (0.88x group discount + top-up bonuses), and because it's compatible with the OpenAI SDK, migration costs are virtually zero.
Q4: Is it normal for Qwen3.6-Plus to be slow?
The MoE architecture and 1 million token context window of Qwen3.6-Plus do require more overhead during inference compared to dense models. Combined with the conservative compute allocation during the preview phase, slower speeds are currently common. However, its absolute throughput remains impressive; we recommend using streaming output (stream=True) to improve the user experience.
Q5: How can I use Qwen3.6-Plus in Claude Code?
Qwen3.6-Plus supports both Anthropic and OpenAI protocols. You can use Qwen3.6-Plus by updating the API endpoint configuration in Claude Code. When connecting via the APIYI (apiyi.com) platform, simply use the standard OpenAI SDK format; you can find specific configuration details in the platform documentation.
Summary of Solutions for Qwen3.6-Plus 429 Errors
The 429 error you're seeing with Qwen3.6-Plus is essentially a supply-demand imbalance: the model is powerful, the price is low, and demand is sky-high, meaning OpenRouter's compute quota just can't keep up with everyone's requests.
Here are three ways to handle it, depending on your needs:
- Smart Retries: A temporary fix, best for low-frequency model invocation.
- Local Optimization: Reducing your request volume, which is a good practice for any scenario.
- Switching Channels: The ultimate solution, perfect for projects that require high stability.
For developers who need reliable access to Qwen3.6-Plus, we recommend using the official Alibaba Cloud direct proxy channel via APIYI (apiyi.com). You'll get 20% off the official price while saying goodbye to 429 rate-limiting headaches, allowing you to focus on your business logic instead of error handling.
📝 Author: APIYI Team | For more AI model API integration tutorials and troubleshooting guides, please visit the APIYI Help Center: help.apiyi.com