Pengembang yang pernah menggunakan Qwen3.6-Plus pasti merasakan hal yang sama: saat memanggil model ini melalui OpenRouter, kesalahan 429 Too Many Requests hampir menjadi makanan sehari-hari. Padahal sudah membayar dan bukan pengguna gratis, tapi tetap saja terkena limitasi hingga membuat frustrasi.
Nilai Inti: Artikel ini akan menganalisis secara mendalam penyebab utama kesalahan 429 pada Qwen3.6-Plus, memberikan 3 solusi praktis, dan berbagi cara untuk mencapai pemanggilan model yang stabil dan murah melalui jalur resmi Alibaba Cloud.

Poin Utama Kesalahan 429 Qwen3.6-Plus
| Poin | Penjelasan | Manfaat bagi Pengembang |
|---|---|---|
| Analisis Akar Masalah 429 | Permintaan tinggi + penyalahgunaan tier gratis + strategi alokasi komputasi | Memahami esensi masalah, tidak asal mencoba ulang |
| 3 Solusi | Strategi coba ulang / ganti kanal / jalur resmi | Memilih jalur optimal sesuai skenario |
| Uji Performa | Perbandingan latensi Qwen3.6-Plus antar kanal | Memilih cara akses paling stabil |
| Contoh Kode | Python/Node.js siap pakai | Migrasi selesai dalam 5 menit |
Mengapa Qwen3.6-Plus Begitu Populer
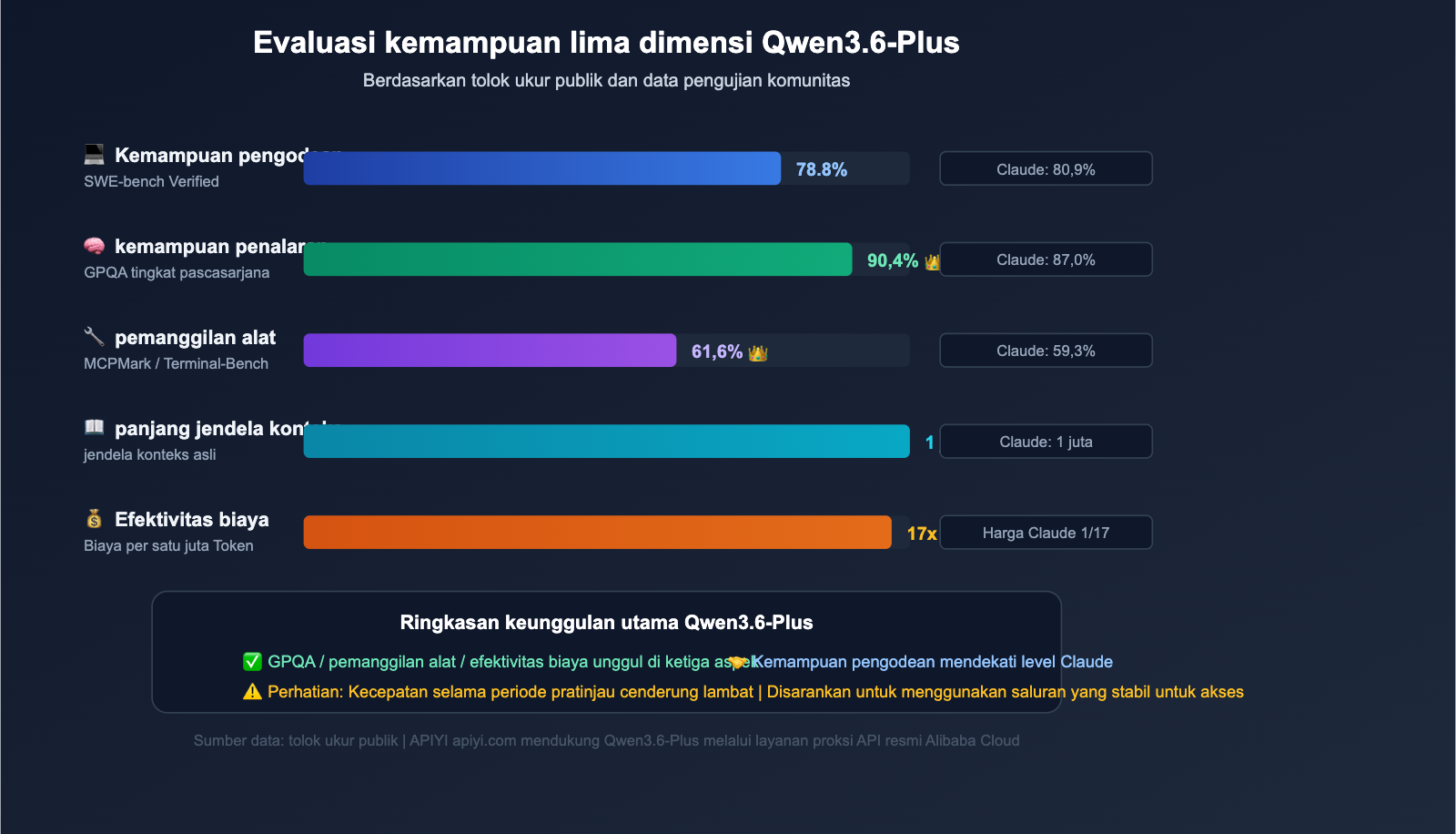
Qwen3.6-Plus adalah Model Bahasa Besar unggulan yang dirilis oleh tim Qwen Alibaba pada April 2026, yang secara langsung menantang Claude Opus 4.5 dan GPT-5.4. Alasan popularitasnya sederhana—performa kuat dan harga murah:
| Tolok Ukur | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78,8% | 80,9% | 76,2% |
| Terminal-Bench 2.0 | 61,6% | 59,3% | 57,8% |
| GPQA (Sains tingkat pascasarjana) | 90,4% | 87,0% | 88,1% |
| MCPMark (pemanggilan alat) | 48,2% | 45,6% | 43,9% |
| Jendela konteks | 1 Juta Token | 1 Juta Token | 256 Ribu Token |
| Output maksimum | 65.536 Token | 32.000 Token | 16.384 Token |
Pada dua tolok ukur utama, Terminal-Bench dan GPQA, Qwen3.6-Plus bahkan melampaui Claude Opus 4.5, sementara harga API resminya hanya sekitar 1/17 dari harga Claude. Rasio harga-performa ini memicu lonjakan permintaan penggunaan oleh pengembang—yang juga menjadi akar penyebab masalah 429.
Analisis Mendalam Error 429 pada Qwen3.6-Plus
Apa Itu Error 429
Kode status HTTP 429 memiliki arti yang sangat jelas: Too Many Requests (Terlalu Banyak Permintaan). Error ini muncul ketika server menerima permintaan yang melebihi kapasitas pemrosesan atau batas yang telah ditentukan dalam jangka waktu tertentu.
Contoh respons error 429 yang umum:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
4 Alasan Utama Seringnya Error 429 pada Qwen3.6-Plus di OpenRouter
Alasan 1: Permintaan Jauh Melampaui Penawaran
Qwen3.6-Plus menawarkan rasio harga-performa yang sangat menarik. Harga API resmi untuk tingkat pemula sekitar $0,29 per juta token input, atau 1/17 dari harga Claude Opus 4.5. Banyak pengembang yang beralih ke sini, sementara OpenRouter sebagai platform perantara memiliki kuota komputasi yang terbatas dari Alibaba Cloud.
Alasan 2: Pengguna Tingkat Gratis Mendominasi
OpenRouter menyediakan model gratis qwen/qwen3.6-plus:free yang menarik banyak pengguna tanpa biaya. Permintaan gratis ini berbagi kumpulan sumber daya backend yang sama dengan permintaan berbayar, sehingga pengguna berbayar pun ikut terkena dampaknya.
Alasan 3: Alokasi Komputasi yang Konservatif Selama Masa Pratinjau
Qwen3.6-Plus saat ini masih dalam tahap Pratinjau (rilis pratinjau 30 Maret, rilis resmi 2 April). Alibaba Cloud biasanya cukup konservatif dalam mengalokasikan komputasi ke platform pihak ketiga selama periode ini, demi memprioritaskan kualitas layanan platform mereka sendiri (DashScope / Bailian).
Alasan 4: Hambatan Kecepatan Inferensi Model Itu Sendiri
Meskipun pengujian komunitas menunjukkan throughput Qwen3.6-Plus sekitar 3 kali lipat dari Claude Opus 4.6, dalam penggunaan nyata, jendela konteks 1 juta token dan arsitektur MoE-nya memiliki latensi respons yang cukup tinggi saat menangani tugas Agen yang kompleks. Artinya, setiap permintaan memakan waktu GPU lebih lama, sehingga total permintaan yang dapat diproses per satuan waktu menjadi lebih sedikit.
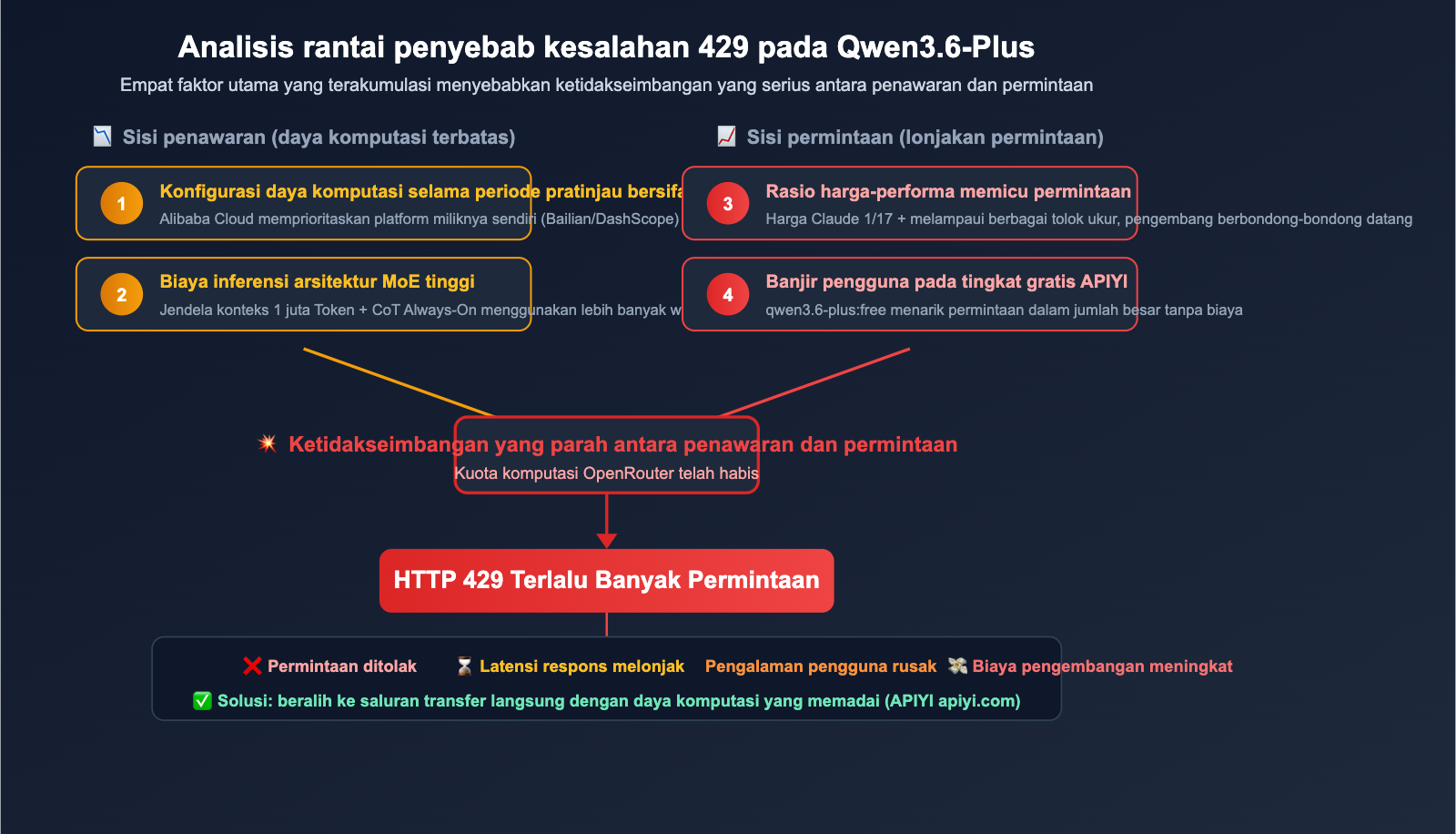
🎯 Wawasan Utama: Error 429 bukan berarti kode Anda bermasalah, melainkan ketidakseimbangan antara penawaran dan permintaan. Solusinya adalah beralih ke saluran dengan pasokan yang memadai, bukan melakukan percobaan ulang tanpa henti. Akses melalui APIYI (apiyi.com) ke saluran langsung resmi Alibaba Cloud dapat membantu Anda menghindari masalah pembatasan laju (rate limit) di OpenRouter.
Solusi 1 Error 429 pada Qwen3.6-Plus: Strategi Percobaan Ulang Cerdas
Percobaan Ulang dengan Eksponensial Backoff
Saat Anda belum bisa beralih saluran, strategi percobaan ulang yang tepat dapat meredakan (meskipun tidak sepenuhnya menyembuhkan) masalah 429:
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI, saluran langsung resmi Alibaba Cloud
)
def call_qwen36_with_retry(messages, max_retries=5):
"""Pemanggilan Qwen3.6-Plus dengan eksponensial backoff"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 limit laju, percobaan ke-{attempt+1}, menunggu {wait_time:.1f} detik...")
time.sleep(wait_time)
# Contoh penggunaan
result = call_qwen36_with_retry([
{"role": "user", "content": "Analisis hambatan performa kode ini"}
])
print(result)
Saran Parameter Strategi Percobaan Ulang
| Parameter | Nilai Rekomendasi | Penjelasan |
|---|---|---|
| Maksimal Percobaan Ulang | 3-5 kali | Lebih dari 5 kali berarti saluran tersebut memang tidak stabil |
| Waktu Tunggu Awal | 1-2 detik | Terlalu singkat tidak efektif, terlalu lama membuang waktu |
| Faktor Backoff | 2x | Eksponensial backoff adalah standar industri |
| Jitter Acak | 0-1 detik | Menghindari "efek kawanan" (thundering herd) |
| Batas Timeout | 30 detik | Tunggu tidak lebih dari 30 detik per permintaan |
Keterbatasan Strategi Percobaan Ulang
Perlu dipahami bahwa: Percobaan ulang hanyalah pereda nyeri, bukan solusi penyembuhan. Ketika backend Qwen3.6-Plus di OpenRouter terus-menerus kelebihan beban, tingkat keberhasilan strategi percobaan ulang akan menurun drastis. Solusi yang lebih mendasar adalah beralih ke saluran API dengan pasokan yang memadai.
Solusi Error 429 Qwen3.6-Plus Bagian 2: Beralih Saluran API
Mengapa beralih saluran lebih efektif daripada mencoba ulang
Penyebab utama error 429 yang sering terjadi di OpenRouter adalah kuota komputasi Qwen3.6-Plus yang tidak mencukupi pada saluran tersebut. Beralih ke saluran yang terhubung langsung dengan komputasi Alibaba Cloud dapat menyelesaikan masalah dari akarnya.
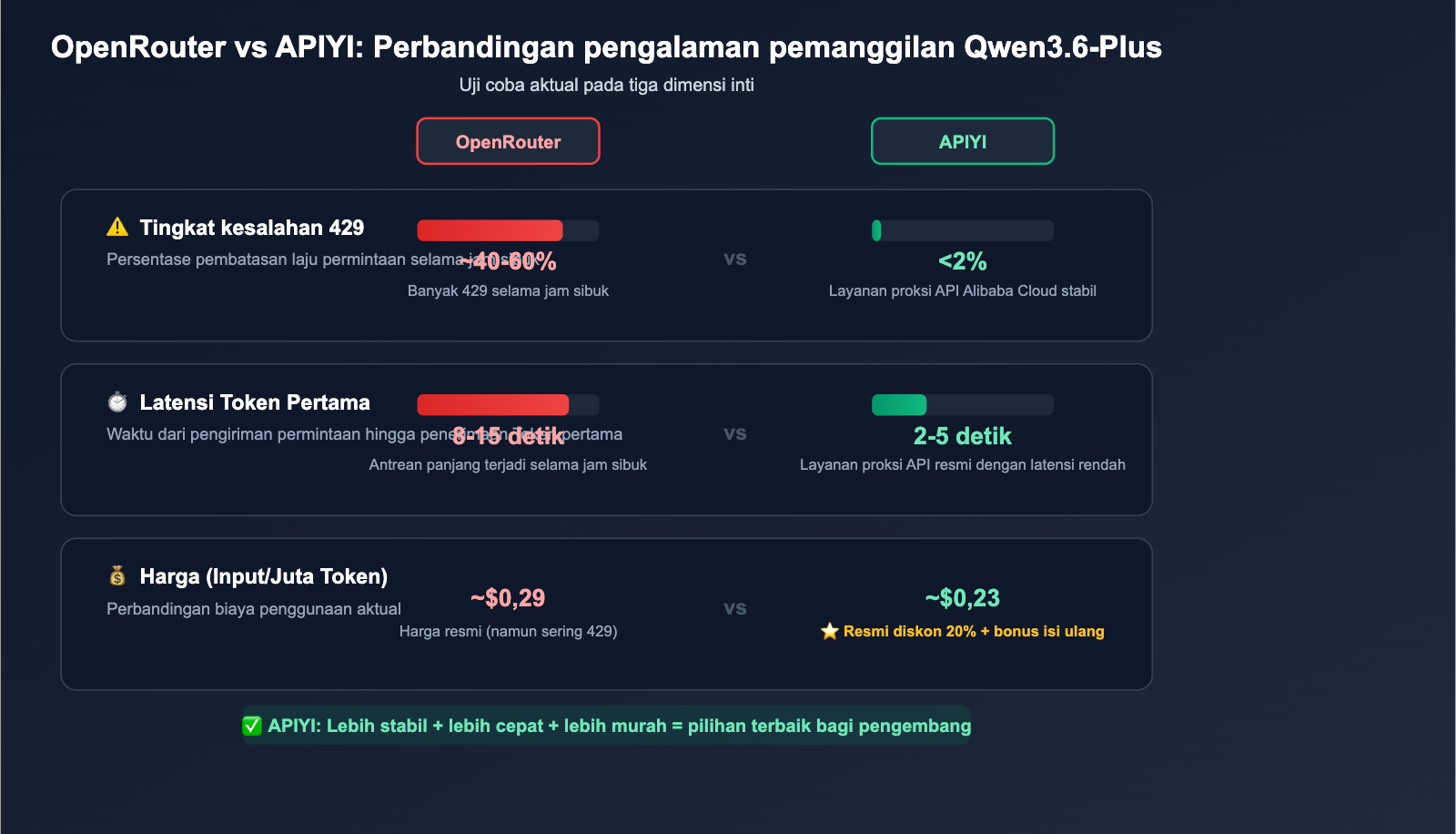
Perbandingan Saluran API Qwen3.6-Plus
| Saluran | Stabilitas | Harga (Input/Juta Token) | Frekuensi 429 | Pengumpulan Data |
|---|---|---|---|---|
| OpenRouter Free | Buruk | Gratis | Sangat Tinggi | Ya (data pelatihan) |
| OpenRouter Paid | Biasa | ~$0.29 | Sering | Ya (masa pratinjau) |
| Alibaba Cloud Bailian | Baik | ¥2.00 | Rendah | Tergantung perjanjian |
| APIYI (Direct Alibaba Cloud) | Baik | Diskon 20% Resmi | Rendah | Tidak |
💡 Saran: Jika aplikasi Anda membutuhkan stabilitas tinggi, kami sarankan untuk mengakses Qwen3.6-Plus melalui APIYI di apiyi.com. Platform ini menggunakan jalur langsung resmi Alibaba Cloud dengan harga hanya 80% dari harga resmi (diskon grup 0.88 + isi ulang 100 USD dapat bonus 10 USD), sekaligus menghindari masalah limitasi dari OpenRouter.
Migrasi dari OpenRouter ke APIYI hanya butuh ubah 2 baris kode
Biaya migrasi sangat rendah, cukup ubah base_url dan api_key:
import openai
# ❌ Sebelumnya: OpenRouter (sering 429)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ Sekarang: APIYI Direct Alibaba Cloud (stabil tanpa 429)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Anda adalah asisten peninjau kode profesional"},
{"role": "user", "content": "Bantu saya mengoptimalkan performa kueri SQL ini"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Versi Node.js:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // Antarmuka terpadu APIYI
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: 'Analisis kompleksitas waktu kode ini' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);
Solusi Error 429 Qwen3.6-Plus Bagian 3: Optimasi Permintaan Lokal
Mengurangi pemanggilan API yang tidak perlu
Selain beralih saluran, mengoptimalkan pola permintaan Anda juga dapat mengurangi kemungkinan terjadinya error 429:
1. Menggabungkan permintaan
# ❌ Tidak efisien: Mengirim satu per satu
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analisis: {item}"}]
)
# ✅ Efisien: Menggabungkan secara batch
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Analisis konten berikut secara berurutan:\n{batch_content}"}],
max_tokens=16384
)
2. Melakukan cache pada respons yang sering diakses
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. Limitasi antrean permintaan
| Strategi Optimasi | Efek | Skenario Penggunaan |
|---|---|---|
| Penggabungan Permintaan | Mengurangi 60-80% volume permintaan | Pemrosesan data batch |
| Cache Respons | Nol pemanggilan API untuk permintaan sama | Skenario kueri berulang |
| Limitasi Antrean | Menghaluskan puncak permintaan | Aplikasi konkuren tinggi |
| Strategi Degradasi | Otomatis beralih ke model kecil saat 429 | Layanan sensitif latensi |
🔧 Saran Teknis: Strategi optimasi lokal di atas bekerja paling baik jika dipadukan dengan saluran API yang stabil. Dengan mengakses Qwen3.6-Plus melalui APIYI di apiyi.com, serta menggabungkan strategi penggabungan permintaan dan cache, Anda dapat menurunkan biaya sekaligus menjaga stabilitas.
Analisis Penyebab Lambatnya Kecepatan Model Qwen3.6-Plus
Mengapa respons Qwen3.6-Plus terkadang terasa lambat
Banyak pengembang melaporkan bahwa meskipun tidak mengalami error 429, kecepatan respons Qwen3.6-Plus terasa "lambat tanpa alasan yang jelas". Ini bukan kasus terisolasi, melainkan ada alasan teknis di baliknya:
1. Overhead inferensi arsitektur MoE
Qwen3.6-Plus menggunakan arsitektur Mixture of Experts (MoE). Meskipun MoE dapat secara signifikan mengurangi biaya pelatihan, pada tahap inferensi, keputusan perutean dan peralihan antar expert menimbulkan overhead tambahan. Terutama saat memproses konteks panjang, efisiensi inferensi arsitektur MoE lebih rendah dibandingkan model Dense dengan jumlah parameter yang sama.
2. Tekanan memori pada jendela konteks 1 juta Token
Jendela konteks 1 juta Token adalah nilai jual utama Qwen3.6-Plus, namun ini juga berarti KV Cache memakan memori GPU yang sangat besar. Ketika banyak pengguna mengirimkan permintaan konteks panjang secara bersamaan, memori GPU menjadi hambatan (bottleneck), sehingga kecepatan inferensi menurun drastis.
3. Sumber daya komputasi terbatas selama periode pratinjau
Qwen3.6-Plus masih dalam tahap pratinjau. Pada tahap ini, Alibaba Cloud biasanya tidak mengalokasikan skala komputasi yang sama dengan saat peluncuran resmi. Pihak resmi mungkin sedang mengamati pola penggunaan aktual sebelum secara bertahap memperluas kapasitas.
4. Konsumsi Token tambahan dari rantai inferensi Always-On
Qwen3.6-Plus mengaktifkan mode inferensi Always-On Chain-of-Thought secara default. Ini berarti model akan menghasilkan proses berpikir internal dalam setiap respons, sehingga jumlah Token yang dihasilkan sebenarnya jauh lebih banyak daripada output akhir. "Token tersembunyi" ini memakan waktu inferensi tambahan.
Referensi pengujian latensi di berbagai saluran
| Saluran | Latensi Token Pertama | Throughput (Token/s) | Catatan |
|---|---|---|---|
| OpenRouter (Puncak) | 8-15s | 15-25 | Sering 429 |
| OpenRouter (Sepi) | 3-5s | 30-50 | Jam dini hari |
| Alibaba Cloud Bailian | 2-4s | 40-60 | Koneksi langsung domestik |
| APIYI (Proksi) | 2-5s | 35-55 | Akses stabil dari luar negeri |
💰 Tips Biaya: Kecepatan Qwen3.6-Plus sangat bervariasi tergantung saluran dan beban. Jika Anda sensitif terhadap latensi, disarankan untuk melakukan pengujian aktual melalui APIYI apiyi.com. Platform ini menyediakan saluran proksi resmi Alibaba Cloud, yang memungkinkan Anda menikmati diskon 20% sekaligus mendapatkan kecepatan respons yang lebih stabil.
Panduan Praktis Memulai Cepat Qwen3.6-Plus
Contoh lengkap pemanggilan Qwen3.6-Plus menggunakan APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Percakapan dasar
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Anda adalah pakar pengembangan Python senior"},
{"role": "user", "content": "Bantu saya menulis kerangka kerja crawler asinkron berkinerja tinggi"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Lihat kode lengkap untuk output streaming
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Output streaming - cocok untuk skenario yang membutuhkan umpan balik real-time
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Anda adalah arsitek senior"},
{"role": "user", "content": "Rancang sistem antrean pesan yang mendukung jutaan konkurensi"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Baris baru
🚀 Mulai Cepat: Disarankan untuk mendapatkan kunci API melalui platform APIYI apiyi.com untuk memanggil Qwen3.6-Plus. Daftar sekarang untuk mencoba, isi ulang 100 USD dapat bonus 10 USD, dan nikmati diskon resmi 20% untuk Qwen3.6-Plus.
Skenario Penggunaan dan Saran Pemilihan Qwen3.6-Plus
Skenario yang Sangat Cocok untuk Qwen3.6-Plus
| Skenario Aplikasi | Alasan Rekomendasi | Alternatif |
|---|---|---|
| Otomatisasi Agen | Unggul 61,6% di Terminal-Bench, pemanggilan alat asli | Claude Opus 4.5 |
| Review/Perbaikan Kode | SWE-bench 78,8%, mendekati level Claude | Claude Opus 4.5 |
| Penalaran Ilmiah | GPQA 90,4%, tertinggi di kelasnya | GPT-5.4 |
| Pemrosesan Dokumen Panjang | Jendela konteks 1 juta Token | Gemini 2.5 Pro |
| Proyek Sensitif Biaya | Harga sekitar 1/17 dari Claude | DeepSeek V3 |
Skenario yang Perlu Diwaspadai
- Aplikasi real-time yang sangat sensitif terhadap latensi: Arsitektur MoE pada Qwen3.6-Plus memiliki latensi yang cenderung lebih tinggi pada konteks panjang.
- Jalur kritis di lingkungan produksi: Model dalam tahap pratinjau mungkin mengalami perubahan perilaku yang tidak terduga.
- Skenario yang memerlukan jaminan SLA ketat: Tidak ada SLA resmi selama masa pratinjau.
🎯 Saran Pemilihan: Untuk proyek yang perlu menggunakan beberapa model sekaligus, kami sarankan untuk mengaksesnya secara terpadu melalui platform APIYI apiyi.com. Platform ini mendukung antarmuka yang kompatibel dengan OpenAI untuk model utama seperti Qwen3.6-Plus, Claude, dan GPT. Cukup dengan satu kunci API, Anda dapat beralih antar model dengan mudah untuk fleksibilitas di berbagai skenario.
Pertanyaan Umum (FAQ) Seputar Error 429 pada Qwen3.6-Plus
Q1: Mengapa saya masih mendapatkan error 429 padahal sudah berlangganan di OpenRouter?
Hal ini terjadi karena pengguna berbayar dan pengguna gratis di OpenRouter berbagi kumpulan komputasi backend yang sama. Meskipun Anda pengguna berbayar, saat total volume permintaan melebihi kuota komputasi yang diperoleh OpenRouter dari Alibaba Cloud, pengguna berbayar pun akan terkena pembatasan laju (rate limit). Solusinya adalah beralih ke saluran dengan pasokan yang lebih memadai, seperti menggunakan saluran langsung resmi Alibaba Cloud melalui APIYI apiyi.com.
Q2: Apakah error 429 pada Qwen3.6-Plus akan membaik?
Seiring dengan peningkatan kapasitas Alibaba Cloud dan perilisan GA (General Availability) model, masalah 429 diperkirakan akan berkurang. Namun, sebagai platform proksi pihak ketiga, alokasi komputasi OpenRouter akan selalu dibatasi oleh pasokan hulu. Jika bisnis Anda memerlukan stabilitas tinggi, disarankan untuk menggunakan saluran yang terhubung langsung ke komputasi Alibaba Cloud, alih-alih bergantung pada platform proksi.
Q3: Apa perbedaan Qwen3.6-Plus di APIYI dengan di OpenRouter?
Perbedaan utamanya terletak pada sumber daya komputasi. Platform APIYI apiyi.com menggunakan saluran langsung resmi Alibaba Cloud, sehingga komputasi berasal dari platform Bailian Alibaba Cloud, bukan dari perantara. Ini berarti tingkat kejadian 429 yang lebih rendah dan kecepatan respons yang lebih stabil. Dari sisi harga, APIYI menawarkan diskon resmi 20% (diskon grup 0,88 + bonus isi ulang), serta kompatibel dengan format antarmuka SDK OpenAI, sehingga biaya migrasi hampir nol.
Q4: Apakah wajar jika Qwen3.6-Plus terasa lambat?
Arsitektur MoE dan jendela konteks 1 juta Token pada Qwen3.6-Plus memang memiliki overhead yang lebih besar saat inferensi dibandingkan model Dense. Ditambah dengan konfigurasi komputasi yang konservatif selama fase pratinjau, kecepatan yang terasa lambat adalah fenomena umum saat ini. Namun, throughput absolutnya tetap mengesankan; disarankan untuk menggunakan output streaming (stream=True) guna meningkatkan pengalaman pengguna.
Q5: Bagaimana cara menggunakan Qwen3.6-Plus di Claude Code?
Qwen3.6-Plus mendukung kompatibilitas ganda dengan protokol Anthropic dan OpenAI. Anda dapat menggunakan Qwen3.6-Plus dengan mengubah konfigurasi endpoint API pada Claude Code. Saat mengakses melalui platform APIYI apiyi.com, cukup gunakan format SDK OpenAI standar. Detail konfigurasi dapat dilihat pada dokumentasi platform.
Ringkasan Solusi Error 429 pada Qwen3.6-Plus
Masalah 429 pada Qwen3.6-Plus pada dasarnya adalah masalah ketidakseimbangan antara penawaran dan permintaan: model yang terlalu canggih, harga yang sangat terjangkau, dan permintaan yang membludak, sementara kuota komputasi OpenRouter tidak mampu memenuhi kebutuhan semua pengguna.
Berikut adalah skenario penggunaan untuk ketiga solusi yang ada:
- Retry Cerdas: Solusi sementara, cocok untuk skenario pemanggilan frekuensi rendah.
- Optimasi Lokal: Mengurangi volume permintaan, cocok untuk semua skenario.
- Pindah Saluran: Solusi mendasar, cocok untuk proyek yang membutuhkan stabilitas tinggi.
Bagi pengembang yang membutuhkan pemanggilan Qwen3.6-Plus yang stabil, kami merekomendasikan untuk mengakses saluran resmi Alibaba Cloud melalui platform APIYI apiyi.com. Anda bisa menikmati diskon 20% dari harga resmi sekaligus mengucapkan selamat tinggal pada kendala limitasi 429, sehingga aplikasi Anda dapat fokus pada logika bisnis alih-alih menangani error.
📝 Penulis: Tim APIYI | Untuk tutorial akses API Model Bahasa Besar lainnya dan panduan menghindari kendala, silakan kunjungi Pusat Bantuan APIYI: help.apiyi.com