Разработчики, которые использовали Qwen3.6-Plus, наверняка сталкивались с одной и той же проблемой: при вызове этой модели через OpenRouter ошибка 429 Too Many Requests стала практически обыденностью. Вы платите деньги, у вас не бесплатный аккаунт, но вас всё равно ограничивают по количеству запросов так, что опускаются руки.
Ключевая ценность: В этой статье мы глубоко проанализируем первопричины ошибки 429 для Qwen3.6-Plus, предложим 3 практических решения и расскажем, как настроить стабильный и недорогой вызов модели через официальный API-шлюз Alibaba Cloud.
Ключевые аспекты ошибки 429 в Qwen3.6-Plus
| Аспект | Описание | Выгода для разработчика |
|---|---|---|
| Анализ причин 429 | Превышение спроса, злоупотребление бесплатным уровнем, стратегии распределения мощностей | Понимание сути проблемы, отказ от бесполезных повторных попыток |
| 3 решения | Стратегии повтора / смена канала / прямой доступ через API | Выбор оптимального пути в зависимости от задачи |
| Тестирование производительности | Сравнение задержек Qwen3.6-Plus по разным каналам | Выбор наиболее стабильного способа подключения |
| Примеры кода | Готовые решения на Python/Node.js | Миграция за 5 минут |
Почему Qwen3.6-Plus так популярен
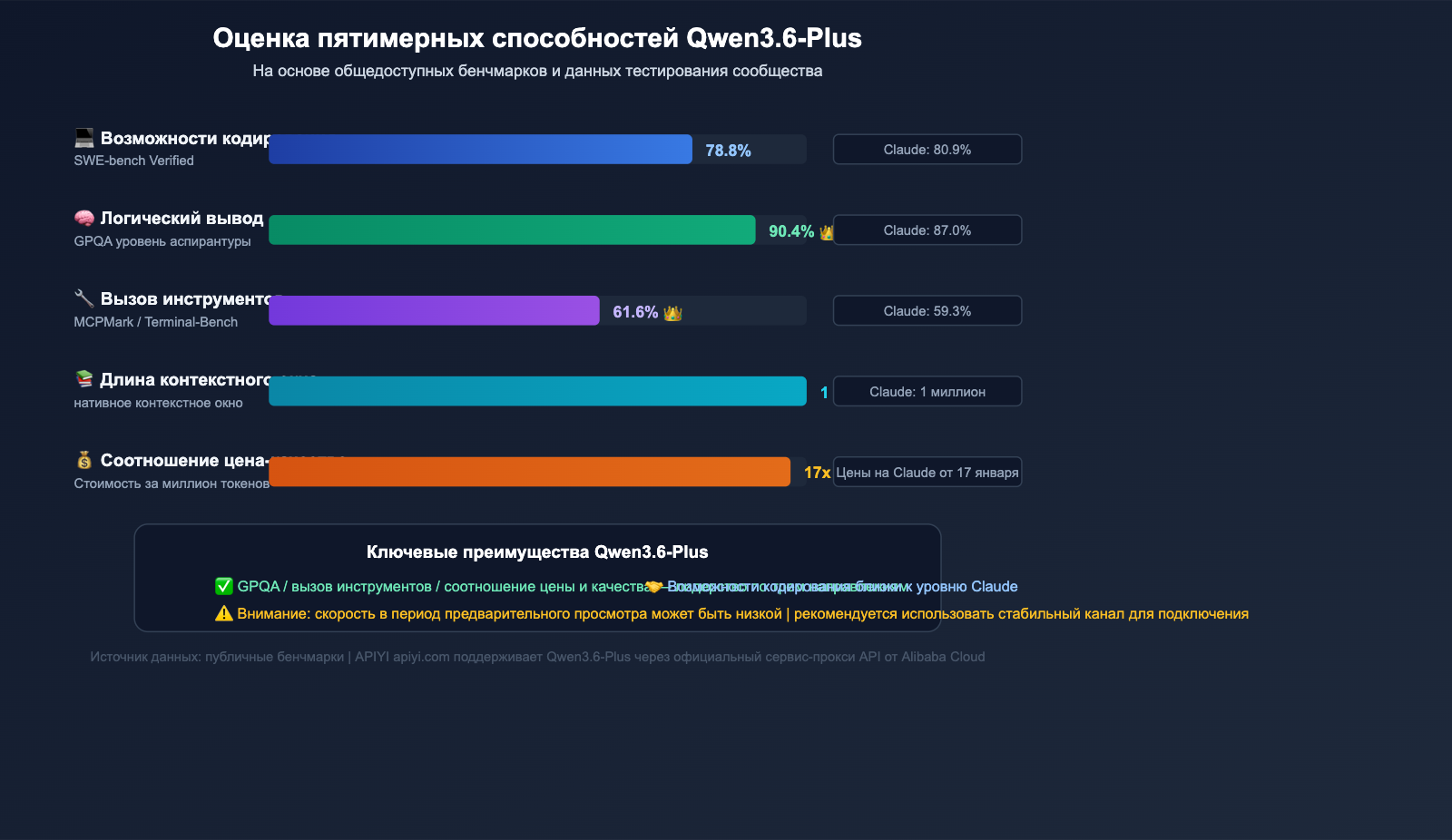
Qwen3.6-Plus — это флагманская Большая языковая модель, выпущенная командой Alibaba Qwen в апреле 2026 года, которая напрямую конкурирует с Claude Opus 4.5 и GPT-5.4. Причина успеха проста: высокая производительность при низкой цене.
| Бенчмарк | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78.8% | 80.9% | 76.2% |
| Terminal-Bench 2.0 | 61.6% | 59.3% | 57.8% |
| GPQA (научный уровень) | 90.4% | 87.0% | 88.1% |
| MCPMark (вызов инструментов) | 48.2% | 45.6% | 43.9% |
| Контекстное окно | 1 млн токенов | 1 млн токенов | 256 тыс. токенов |
| Макс. вывод | 65 536 токенов | 32 000 токенов | 16 384 токенов |
По ключевым показателям Terminal-Bench и GPQA модель Qwen3.6-Plus даже превосходит Claude Opus 4.5, при этом официальная цена API составляет около 1/17 от стоимости Claude. Такое соотношение цены и качества вызвало взрывной рост спроса среди разработчиков, что и стало первопричиной возникновения ошибки 429.
Глубокий анализ ошибки 429 в Qwen3.6-Plus
Что такое ошибка 429
Код состояния HTTP 429 говорит сам за себя: Too Many Requests (слишком много запросов). Когда сервер получает больше запросов в единицу времени, чем может обработать, или превышает установленные лимиты, он возвращает эту ошибку.
Типичный ответ с ошибкой 429:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
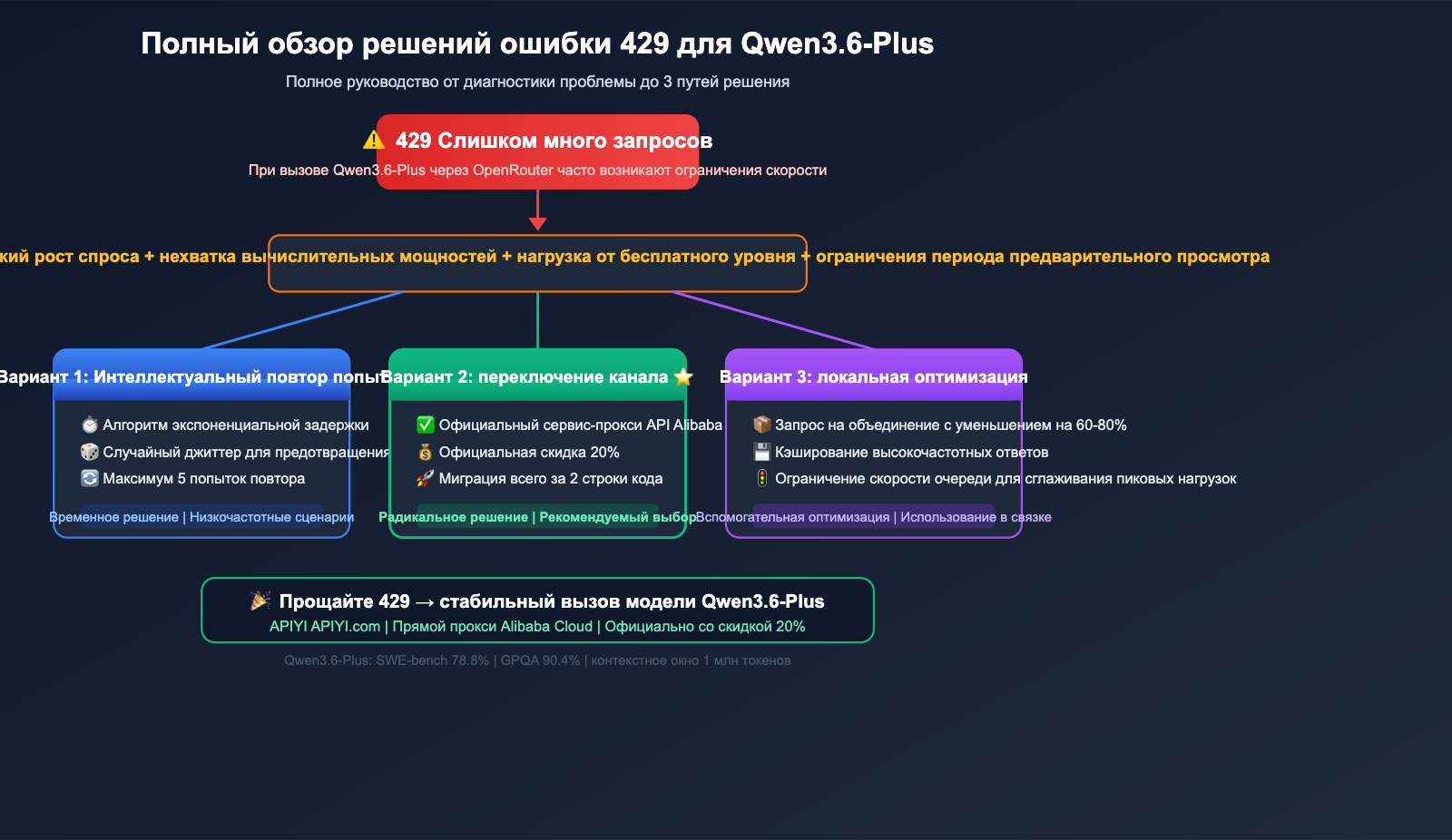
4 основные причины частых ошибок 429 у Qwen3.6-Plus на OpenRouter
Причина 1: Спрос значительно превышает предложение
Qwen3.6-Plus предлагает невероятную выгоду. Официальная цена API начального уровня составляет около $0,29 за миллион входных токенов — это 1/17 цены Claude Opus 4.5. Огромное количество разработчиков хлынуло на платформу, а OpenRouter, как сервис-прокси API, имеет ограниченные квоты вычислительных мощностей, получаемые от Alibaba Cloud.
Причина 2: Массовое использование бесплатного уровня
OpenRouter предоставляет бесплатную модель qwen/qwen3.6-plus:free, что привлекает множество пользователей, не желающих платить. Эти бесплатные запросы делят один и тот же пул ресурсов с платными, из-за чего последние также попадают под ограничения.
Причина 3: Консервативное распределение мощностей в период превью
Qwen3.6-Plus все еще находится на стадии превью (превью-версия вышла 30 марта, официальный релиз — 2 апреля). В этот период Alibaba Cloud обычно более консервативно распределяет мощности для сторонних платформ, отдавая приоритет качеству обслуживания на собственных площадках (DashScope / Bailian).
Причина 4: Узкое место в скорости вывода самой модели
Хотя тесты сообщества показывают, что пропускная способность Qwen3.6-Plus примерно в 3 раза выше, чем у Claude Opus 4.6, на практике из-за контекстного окна в 1 млн токенов и архитектуры MoE задержка ответа при выполнении сложных агентских задач остается высокой. Это значит, что каждый запрос дольше занимает GPU, что снижает общее количество запросов, обрабатываемых в единицу времени.

🎯 Ключевой вывод: Ошибка 429 — это не проблема вашего кода, а дисбаланс спроса и предложения. Решение заключается в переходе на канал с достаточными мощностями, а не в бесконечных повторных попытках. Подключение через APIYI (apiyi.com) к официальному прямому каналу Alibaba Cloud поможет эффективно избежать проблем с лимитами OpenRouter.
Решение ошибки 429 в Qwen3.6-Plus: Способ №1 — Стратегия интеллектуальных повторных попыток
Экспоненциальная задержка при повторных попытках
Если у вас нет возможности переключить канал прямо сейчас, грамотная стратегия повторных попыток поможет смягчить (но не полностью устранить) проблему с ошибкой 429:
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Унифицированный интерфейс APIYI, прямой прокси через Alibaba Cloud
)
def call_qwen36_with_retry(messages, max_retries=5):
"""Вызов Qwen3.6-Plus с экспоненциальной задержкой"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Ошибка 429 (лимит), попытка {attempt+1}, ожидание {wait_time:.1f}с...")
time.sleep(wait_time)
# Пример использования
result = call_qwen36_with_retry([
{"role": "user", "content": "Проанализируй узкие места производительности в этом коде"}
])
print(result)
Рекомендации по параметрам повторных попыток
| Параметр | Рекомендуемое значение | Примечание |
|---|---|---|
| Макс. кол-во попыток | 3-5 раз | Более 5 попыток говорит о нестабильности канала |
| Начальное ожидание | 1-2 сек | Слишком короткое — неэффективно, слишком долгое — трата времени |
| Множитель задержки | 2x | Экспоненциальная задержка — отраслевой стандарт |
| Джиттер (случайность) | 0-1 сек | Помогает избежать «эффекта толпы» |
| Лимит времени | 30 сек | Одно ожидание не должно превышать 30 секунд |
Ограничения стратегии повторных попыток
Важно понимать: повторные попытки — это обезболивающее, а не лечение. Когда бэкенд Qwen3.6-Plus в OpenRouter постоянно перегружен, вероятность успеха при повторных запросах резко падает. Более фундаментальное решение — переключиться на канал с достаточными мощностями.
Решение ошибки 429 в Qwen3.6-Plus: Способ №2 — Смена API-канала
Почему смена канала эффективнее повторных попыток
Частые ошибки 429 в OpenRouter связаны с нехваткой квот на вычислительные мощности для Qwen3.6-Plus. Переход на канал, напрямую подключенный к мощностям Alibaba Cloud, решает проблему в корне.
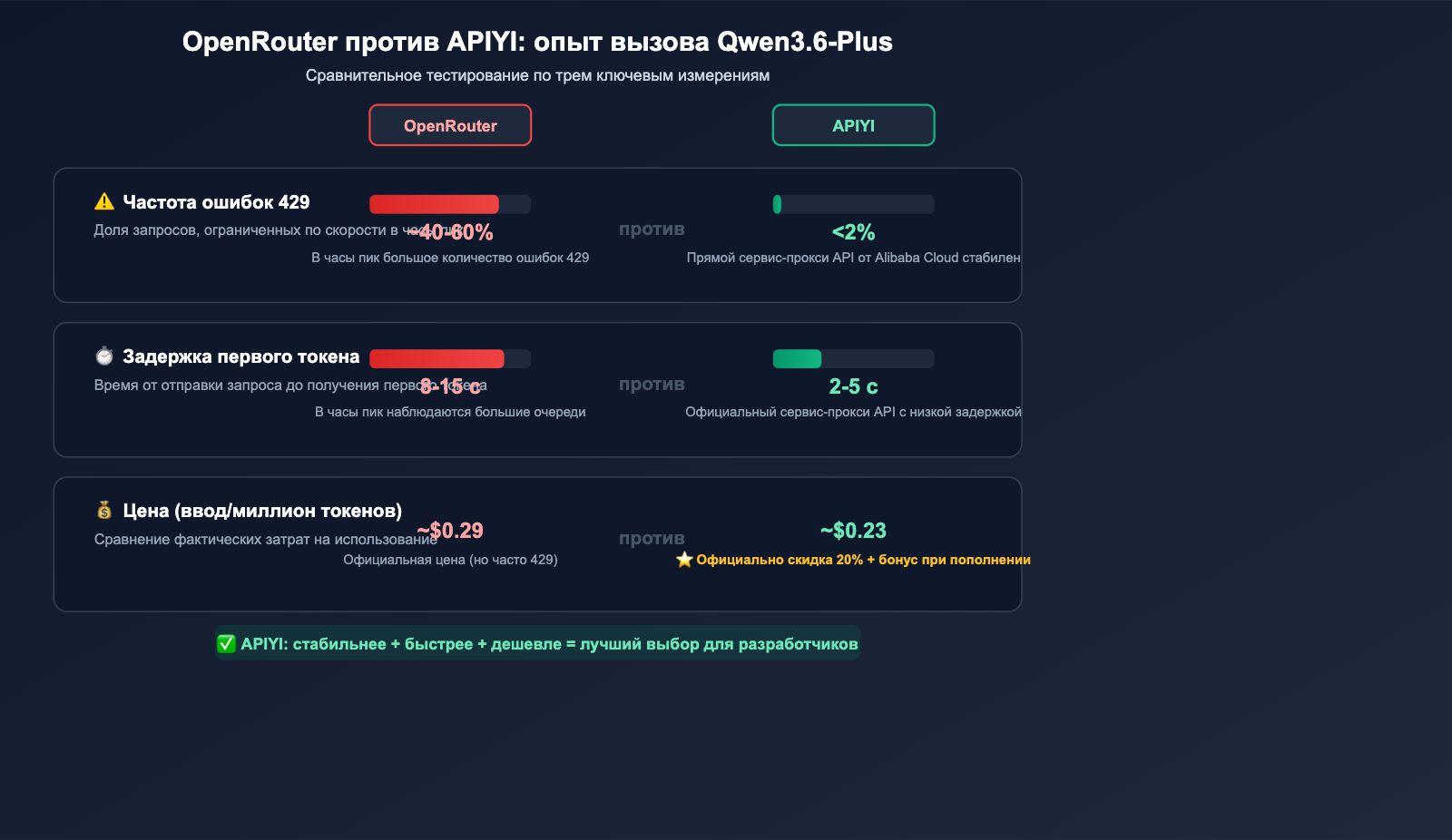
Сравнение API-каналов для Qwen3.6-Plus
| Канал | Стабильность | Цена (вход/млн токенов) | Частота 429 | Сбор данных |
|---|---|---|---|---|
| OpenRouter Free | Низкая | Бесплатно | Очень высокая | Да (обучение) |
| OpenRouter Paid | Средняя | ~$0.29 | Часто | Да (период превью) |
| Alibaba Bailian | Высокая | ¥2.00 | Низкая | Зависит от соглашения |
| APIYI (прямой прокси) | Высокая | Официальная -20% | Низкая | Нет |
💡 Совет по выбору: Если вашему приложению важна стабильность, мы рекомендуем подключаться к Qwen3.6-Plus через APIYI (apiyi.com). Платформа использует официальный прямой канал Alibaba Cloud, цена составляет 80% от официальной (скидка 0.88 + бонус $10 при пополнении на $100), что позволяет избежать ограничений OpenRouter.
Переход с OpenRouter на APIYI требует изменения всего 2 строк кода
Миграция максимально проста, нужно лишь обновить base_url и api_key:
import openai
# ❌ Было: OpenRouter (частые 429)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ Стало: APIYI (прямой прокси Alibaba, стабильно без 429)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Ты профессиональный помощник по проверке кода"},
{"role": "user", "content": "Помоги оптимизировать производительность этого SQL-запроса"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Версия для Node.js:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // Унифицированный интерфейс APIYI
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: 'Проанализируй временную сложность этого кода' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);
Qwen3.6-Plus: решение ошибки 429 часть 3 — оптимизация локальных запросов
Сокращаем количество лишних вызовов API
Помимо смены каналов, оптимизация логики ваших запросов поможет значительно снизить вероятность возникновения ошибки 429:
1. Объединение запросов
# ❌ Неэффективно: отправка по одному
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Проанализируй: {item}"}]
)
# ✅ Эффективно: пакетная обработка
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"Последовательно проанализируй следующее:\n{batch_content}"}],
max_tokens=16384
)
2. Кэширование частых ответов
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. Ограничение частоты запросов (Rate Limiting)
| Стратегия оптимизации | Эффект | Сценарий использования |
|---|---|---|
| Объединение запросов | Снижение нагрузки на 60-80% | Пакетная обработка данных |
| Кэширование ответов | Ноль вызовов API для повторных запросов | Повторяющиеся задачи |
| Ограничение очереди | Сглаживание пиковых нагрузок | Высоконагруженные приложения |
| Стратегия деградации | Автопереключение на малую модель при 429 | Сервисы, чувствительные к задержкам |
🔧 Технический совет: Вышеуказанные методы лучше всего работают в связке со стабильными API-каналами. Подключаясь к Qwen3.6-Plus через APIYI (apiyi.com) и используя объединение запросов с кэшированием, вы сможете обеспечить стабильность и заметно сократить расходы.
Анализ причин низкой скорости работы Qwen3.6-Plus
Почему Qwen3.6-Plus иногда отвечает медленно?
Многие разработчики жалуются, что даже без ошибок 429 модель Qwen3.6-Plus работает «необъяснимо медленно». Это не единичный случай, и у него есть вполне конкретные технические причины:
1. Накладные расходы на архитектуру MoE
Qwen3.6-Plus использует архитектуру «смесь экспертов» (MoE). Хотя MoE значительно снижает затраты на обучение, на этапе инференса маршрутизация и переключение между экспертами создают дополнительные задержки. Особенно это заметно при работе с длинным контекстом, где эффективность MoE ниже, чем у плотных (Dense) моделей аналогичного размера.
2. Нагрузка на память при контексте в 1 млн токенов
Контекстное окно в 1 млн токенов — главная фишка Qwen3.6-Plus, но это также означает колоссальный объем KV-кэша в видеопамяти GPU. Когда несколько пользователей одновременно отправляют запросы с длинным контекстом, видеопамять становится «бутылочным горлышком», и скорость генерации падает.
3. Ограниченные вычислительные ресурсы в период превью
Qwen3.6-Plus все еще находится в стадии предварительного доступа. На этом этапе провайдеры обычно не выделяют такие же мощности, как для полноценного релиза. Вероятно, компания анализирует реальные паттерны использования перед масштабированием ресурсов.
4. Дополнительный расход токенов на цепочку рассуждений (Always-On CoT)
По умолчанию в Qwen3.6-Plus включен режим постоянных рассуждений (Chain-of-Thought). Это значит, что модель каждый раз генерирует внутренний процесс размышления, поэтому реальное количество токенов значительно превышает итоговый ответ. Эти «скрытые токены» требуют дополнительного времени на обработку.
Сравнение задержек по разным каналам
| Канал | Задержка первого токена | Пропускная способность (ток/сек) | Примечание |
|---|---|---|---|
| OpenRouter (пик) | 8-15 с | 15-25 | Часто 429 |
| OpenRouter (ночь) | 3-5 с | 30-50 | В непиковые часы |
| Aliyun Bailian | 2-4 с | 40-60 | Прямое подключение (Китай) |
| APIYI (прокси) | 2-5 с | 35-55 | Стабильный доступ из-за рубежа |
💰 Совет по затратам: Скорость Qwen3.6-Plus сильно зависит от канала и нагрузки. Если вам важна минимальная задержка, рекомендуем протестировать APIYI (apiyi.com). Платформа предоставляет официальный прокси-канал от Alibaba, что позволяет не только сэкономить до 20%, но и получить более стабильный отклик.
Быстрый старт с Qwen3.6-Plus
Полный пример вызова Qwen3.6-Plus через APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Базовый диалог
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Ты — эксперт по разработке на Python"},
{"role": "user", "content": "Помоги мне написать высокопроизводительный асинхронный фреймворк для парсинга"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Посмотреть полный код для потокового вывода (stream)
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Потоковый вывод — подходит для сценариев, где важна обратная связь в реальном времени
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "Ты — опытный архитектор"},
{"role": "user", "content": "Спроектируй систему очередей сообщений, поддерживающую миллионы параллельных запросов"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Перенос строки
🚀 Быстрый старт: Рекомендуем получать API-ключ для вызова Qwen3.6-Plus через платформу APIYI (apiyi.com). Зарегистрируйтесь и начните работу прямо сейчас: при пополнении на 100 долларов вы получаете бонус 10 долларов, а Qwen3.6-Plus доступен со скидкой 20% от официальной цены.
Сценарии использования и рекомендации по выбору Qwen3.6-Plus
Для каких задач лучше всего подходит Qwen3.6-Plus
| Сценарий применения | Почему стоит выбрать | Альтернативы |
|---|---|---|
| Автоматизация агентов | Лидерство в Terminal-Bench (61.6%), нативный вызов инструментов | Claude Opus 4.5 |
| Code Review / Исправление кода | SWE-bench 78.8%, уровень близок к Claude | Claude Opus 4.5 |
| Научные рассуждения | GPQA 90.4% — лучший показатель | GPT-5.4 |
| Работа с длинными документами | Контекстное окно 1 млн токенов | Gemini 2.5 Pro |
| Проекты с ограниченным бюджетом | Цена примерно в 1/17 от Claude | DeepSeek V3 |
Когда стоит проявлять осторожность
- Приложения, критичные к задержкам: Архитектура MoE у Qwen3.6-Plus может давать повышенную задержку при работе с длинным контекстом.
- Критические узлы в продакшене: Модели в стадии превью могут демонстрировать непредсказуемое поведение.
- Сценарии, требующие строгого SLA: На этапе превью официальные гарантии SLA отсутствуют.
🎯 Совет по выбору: Если ваш проект предполагает использование нескольких моделей, рекомендуем подключаться через платформу APIYI (apiyi.com). Платформа поддерживает совместимый с OpenAI интерфейс для Qwen3.6-Plus, Claude, GPT и других популярных моделей. Один API-ключ позволяет легко переключаться между моделями и гибко управлять ими в зависимости от задачи.
Часто задаваемые вопросы об ошибке 429 в Qwen3.6-Plus
Q1: Почему я получаю ошибку 429, даже если оплатил подписку в OpenRouter?
Это происходит потому, что платные и бесплатные пользователи OpenRouter используют общий пул вычислительных мощностей. Даже если у вас есть платная подписка, при превышении общего лимита запросов, который OpenRouter получает от Alibaba Cloud, ограничение скорости (rate limit) применяется ко всем пользователям. Решение — переключиться на канал с более стабильным доступом, например, использовать прямой прокси-сервис API от Alibaba Cloud через APIYI (apiyi.com).
Q2: Исправится ли ситуация с ошибкой 429 в Qwen3.6-Plus?
По мере того как Alibaba Cloud расширяет инфраструктуру и модель официально переходит в стадию GA (General Availability), проблема 429 должна стать менее острой. Однако, поскольку OpenRouter является сторонним агрегатором, распределение мощностей всегда зависит от ограничений вышестоящего поставщика. Если для вашего проекта важна стабильность, рекомендуем использовать каналы с прямым подключением к мощностям Alibaba Cloud, а не полагаться на посредников.
Q3: В чем разница между Qwen3.6-Plus в APIYI и в OpenRouter?
Главное отличие — источник вычислительных мощностей. Платформа APIYI (apiyi.com) использует официальный прямой канал Alibaba Cloud, поэтому мощности поступают напрямую из платформы Bailian, а не через посредников. Это означает гораздо меньшую вероятность возникновения ошибки 429 и более стабильное время отклика. Что касается цен, APIYI предлагает официальную скидку 20% (скидка 0.88 на группу + бонусы при пополнении), а также полную совместимость с форматом API OpenAI, поэтому миграция пройдет практически бесшовно.
Q4: Нормально ли, что Qwen3.6-Plus работает медленно?
Архитектура MoE и контекстное окно в 1 миллион токенов требуют больше ресурсов при инференсе, чем обычные плотные (Dense) модели. Учитывая, что на этапе предварительного просмотра конфигурация мощностей довольно консервативна, низкая скорость — это ожидаемое явление. Тем не менее, общая пропускная способность модели остается высокой, поэтому для улучшения пользовательского опыта рекомендуем использовать потоковую передачу данных (stream=True).
Q5: Как использовать Qwen3.6-Plus в Claude Code?
Qwen3.6-Plus поддерживает оба протокола: Anthropic и OpenAI. Вы можете использовать Qwen3.6-Plus, изменив конфигурацию API-эндпоинта в Claude Code. При подключении через платформу APIYI (apiyi.com) просто используйте стандартный формат SDK OpenAI — подробные настройки можно найти в документации платформы.
Решение проблемы ошибки 429 в Qwen3.6-Plus
Ошибка 429 при работе с Qwen3.6-Plus по своей сути является дисбалансом спроса и предложения: модель слишком мощная, цена слишком низкая, а спрос огромен, из-за чего квоты вычислительных мощностей OpenRouter не справляются с потоком пользователей.
Вот три способа решения, подходящие для разных ситуаций:
- Умные повторные попытки (Smart Retry): временное решение, подходит для сценариев с редкими вызовами.
- Локальная оптимизация: снижение количества запросов, подходит для всех сценариев.
- Смена канала: кардинальное решение, подходит для проектов, где важна стабильность.
Разработчикам, которым нужен стабильный доступ к Qwen3.6-Plus, мы рекомендуем подключаться через официальный прямой канал Alibaba Cloud на платформе APIYI (apiyi.com). Вы получите скидку 20% от официальной цены и забудете о лимитах 429, позволяя вашему приложению сосредоточиться на бизнес-логике, а не на обработке ошибок.
📝 Автор: Команда APIYI | Больше руководств по интеграции API моделей ИИ и советов по решению проблем можно найти в справочном центре APIYI: help.apiyi.com