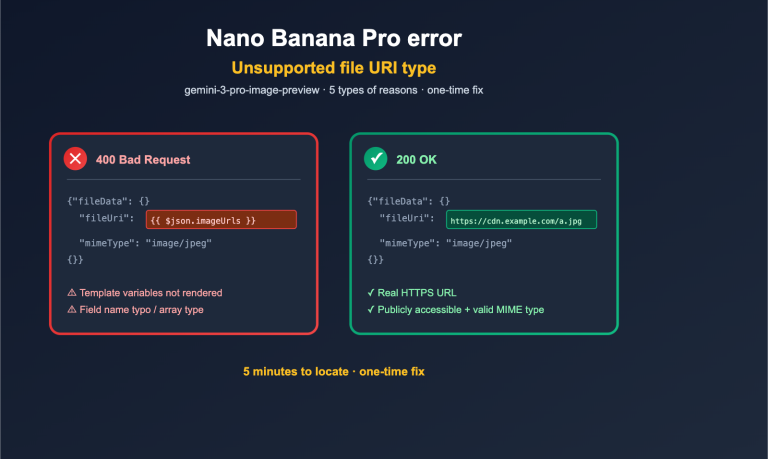
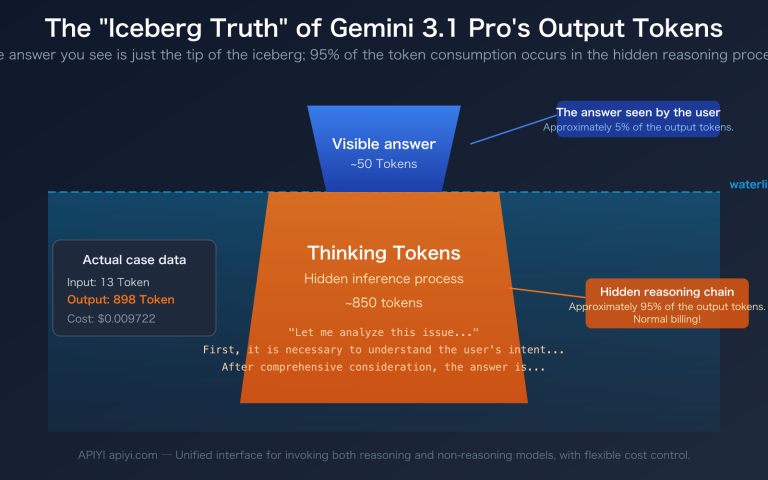
Author's Note: An in-depth comparison of the top 3 AI models for math problem-solving in 2026, including authoritative benchmark data from AIME and MATH, to help you find the most suitable mathematical reasoning model.
Choosing the right AI model for math problem-solving has always been a key concern for developers and students. This article compares the three latest mathematical reasoning models released in 2026: Gemini 3.1 Pro Preview, Claude Sonnet 4.6, and GPT-5.4. We provide clear recommendations based on benchmark test scores, reasoning capabilities, API pricing, and applicable scenarios.
Core Value: After reading this article, you'll know exactly which AI model to choose for different math problem-solving scenarios and how to use them at optimal cost.
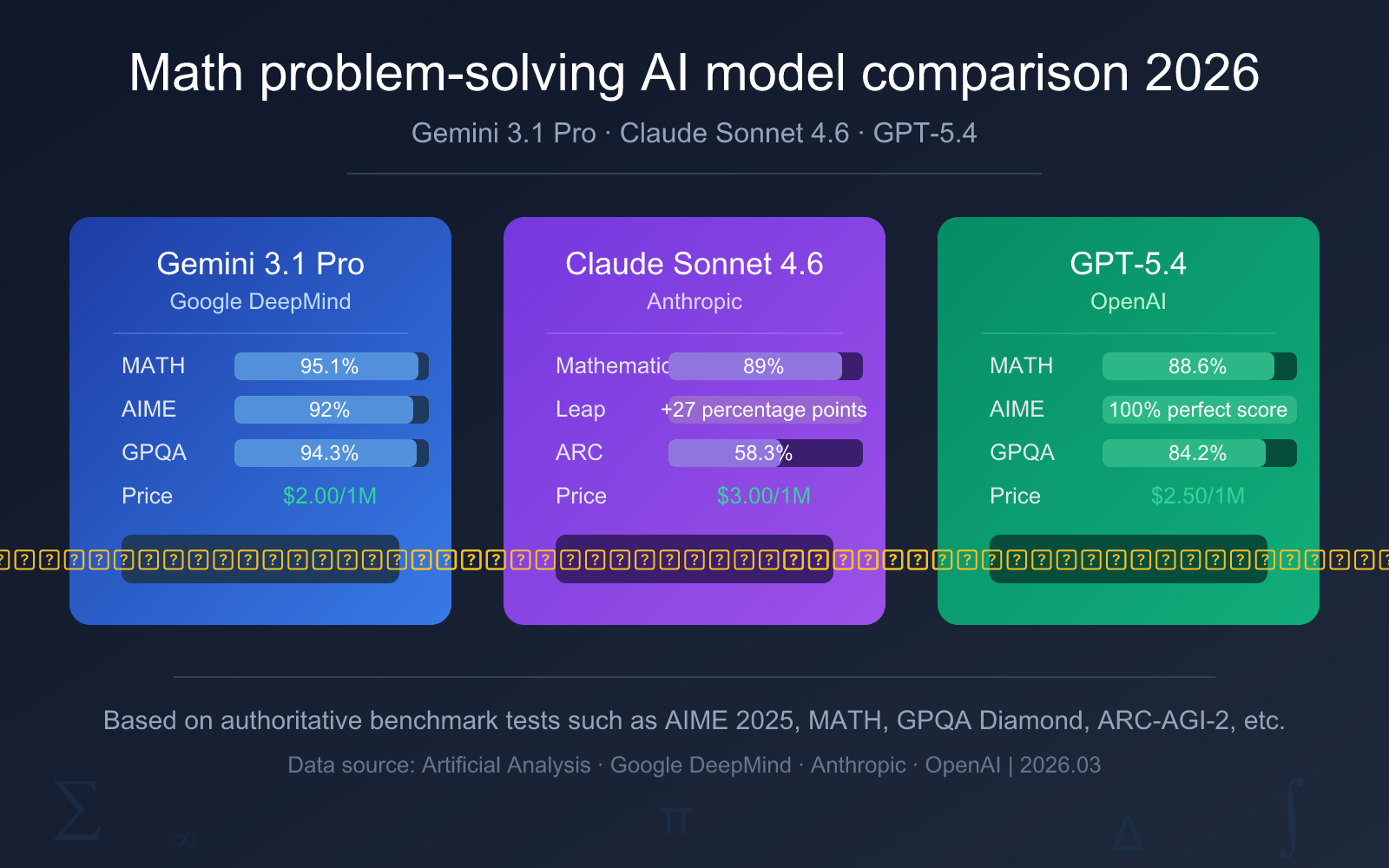
Quick Comparison of Math-Solving AI Models
Before diving into the detailed analysis, here's a core data comparison table to help you quickly understand the key differences between the three math-solving AI models.
| Comparison Dimension | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Release Date | February 19, 2026 | Early 2026 | March 6, 2026 |
| AIME 2025 | 92% (no tools) | — | 100% (perfect score) |
| MATH Benchmark | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| Input Price | $2.00 / 1M tokens | $3.00 / 1M tokens | $2.50 / 1M tokens |
| Output Price | $12.00 / 1M tokens | $15.00 / 1M tokens | $15.00 / 1M tokens |
| Overall Recommendation | ⭐ Top Pick | ⭐ Learning Pick | ⭐ Competition Pick |
Recommended Ranking for Math-Solving AI Models
From a comprehensive cost-performance perspective, we suggest the following ranking:
- Top Pick: Gemini 3.1 Pro Preview: Leads with a 95.1% MATH benchmark score, lowest price, and strongest overall math capability.
- Second Pick: Claude Sonnet 4.6: Math ability surged by 27 percentage points, with clear and understandable problem-solving steps, ideal for learning scenarios.
- Competition-Level: GPT-5.4: Achieved a perfect 100% score on AIME 2025, suitable for high-difficulty math competitions and professional research.
🎯 Technical Tip: All three models can be uniformly invoked through the APIYI platform at apiyi.com. It's recommended to test each one on your actual math problems to select the model that best fits your needs.
Detailed Analysis of Gemini 3.1 Pro Preview's Math-Solving Capabilities
Gemini 3.1 Pro Preview is the latest flagship model released by Google DeepMind on February 19, 2026. This is Google's first use of a ".1" version increment (previous mid-cycle updates used ".5"), signaling a targeted upgrade focused on intelligent reasoning capabilities.
Gemini 3.1 Pro Math Benchmark Scores
| Benchmark Test | Score | Description |
|---|---|---|
| MATH | 95.1% | Comprehensive math test covering algebra, geometry, calculus, and more. |
| AIME 2025 (no tools) | 92% | American Invitational Mathematics Examination, high school competition-level difficulty. |
| AIME 2025 (code execution) | 100% | The previous Gemini 3 Pro achieved a perfect score when code execution was enabled. |
| GPQA Diamond | 94.3% | Graduate-level science Q&A, leading all peer models. |
| ARC-AGI-2 | 77.1% | Abstract reasoning capability, doubled compared to the previous 3 Pro. |
| MathArena Apex | Significantly ahead | Improved over 20x compared to the previous generation. |
Among the 18 mainstream benchmark tests officially published by Google, Gemini 3.1 Pro achieved first place in 12 of them. Its performance on the MATH benchmark, at 95.1%, is particularly outstanding, indicating it possesses strong problem-solving abilities across various mathematical subfields like algebra, geometry, probability, and calculus.
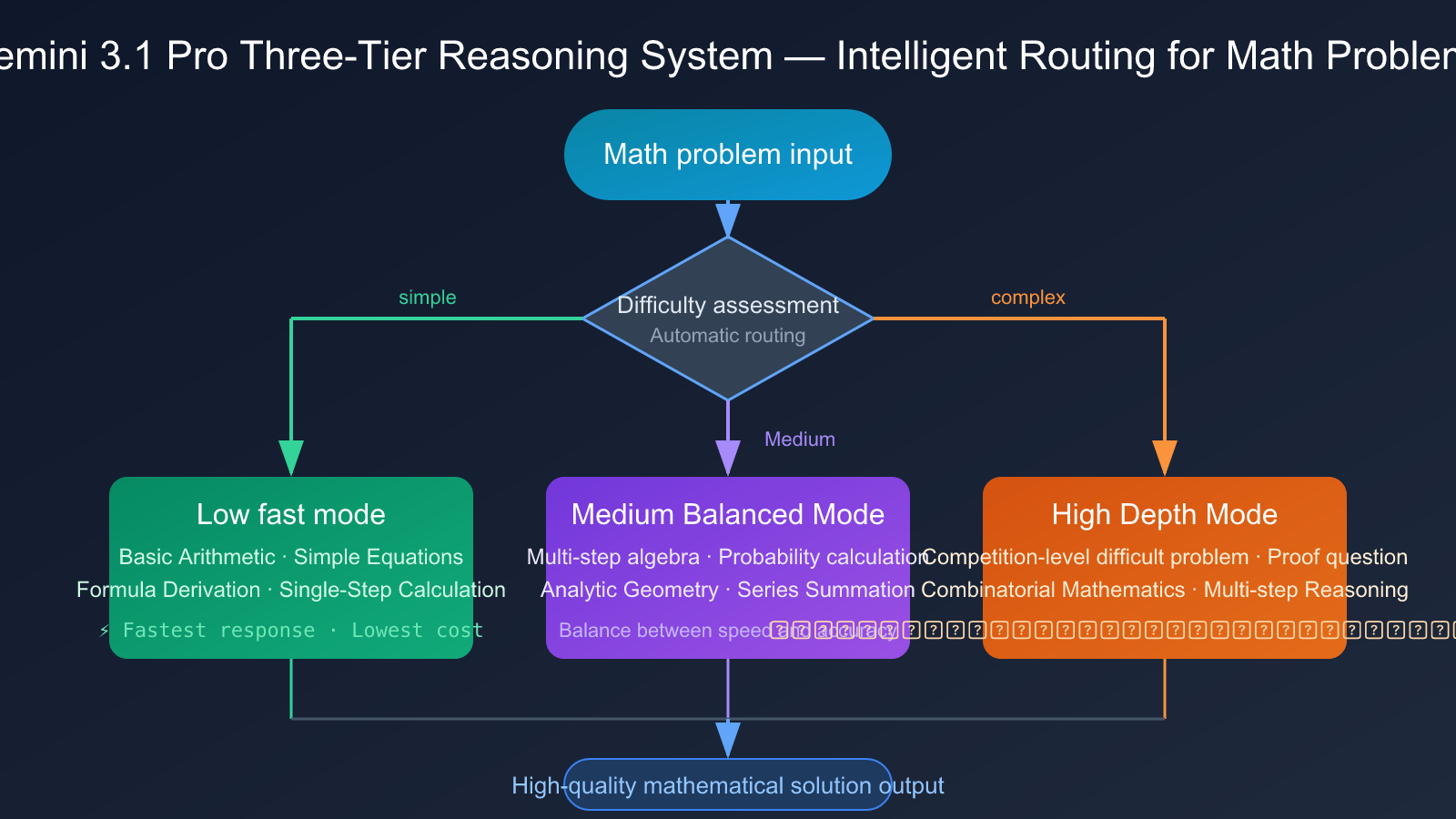
Gemini 3.1 Pro's Three-Tier Thinking System
Gemini 3.1 Pro introduces a key architectural innovation—a three-tier thinking system:
- Low (Fast Mode): Handles simple mathematical calculations and formula derivations with the fastest response speed.
- Medium (Balanced Mode): A new middle layer that handles medium-difficulty math problems, balancing speed and accuracy.
- High (Deep Mode): Handles complex multi-step reasoning problems, such as competition-level math questions.
This three-tier system allows developers to flexibly route queries based on the difficulty of the math problem, eliminating the need to choose between "fast but rough" and "slow but precise." This architectural advantage is especially significant for scenarios involving batch processing of math problems at varying difficulty levels, like adaptive question systems on educational platforms.
Hands-on Experience with Gemini 3.1 Pro for Math Problem-Solving
In practical math problem-solving, Gemini 3.1 Pro Preview's performance can be summarized as "comprehensive and stable":
- Algebra: Almost zero errors on problems involving polynomial operations, equation systems, inequality proofs, etc., thanks to the high 95.1% MATH coverage.
- Geometry: Provides complete reasoning chains for analytic and solid geometry, excelling particularly in calculation problems related to coordinate systems.
- Probability & Statistics: Clear reasoning logic for problems involving conditional probability, permutations, and combinations, correctly handling complex step-by-step calculations.
- Calculus: Accurate in solving definite and indefinite integrals, capable of recognizing and correctly applying common integration techniques.
Gemini 3.1 Pro's achievement of first place in 12 out of 18 mainstream benchmarks is no accident. Its Artificial Analysis Intelligence Index score is 57, tying for first place with GPT-5.4 (xhigh) and far exceeding the median score of 28, demonstrating an all-around advantage in intelligent reasoning.
Claude Sonnet 4.6 Math Problem-Solving Capabilities Explained
Claude Sonnet 4.6 is Anthropic's latest mid-tier model, achieving a qualitative leap in mathematical reasoning—jumping from 62% in the previous Sonnet 4.5 to 89%, a full 27 percentage point increase.
Claude Sonnet 4.6 Math Benchmark Scores
| Benchmark | Sonnet 4.6 | Sonnet 4.5 (Previous) | Improvement |
|---|---|---|---|
| Math Composite | 89% | 62% | +27 percentage points |
| ARC-AGI-2 | 58.3% | 13.6% | 4.3x improvement |
| GPQA Diamond | 74.1% | — | Graduate-level science reasoning |
| Programming Capability | 79.6% | — | Close to Opus 4.6's 80.8% |
| Financial Analysis | 63.3% | — | Best-in-class |
The jump from 62% to 89% in math capability is one of the most striking changes in Sonnet 4.6. This means it has transformed from a model that "occasionally makes mistakes on math problems" into one that "can reliably handle complex calculations."
Claude Sonnet 4.6 Adaptive Thinking Mechanism
Another highlight of Claude Sonnet 4.6 is its Adaptive Thinking mechanism:
- Simple Problems: Quick responses without wasting reasoning resources. Examples: basic arithmetic, simple equation solving.
- Medium Problems: Moderately extended chain-of-thought. Examples: multi-step algebraic operations, probability calculations.
- Complex Problems: Automatically triggers deep reasoning chains. Examples: combinatorics, proof problems, competition-level questions.
The benefit of this adaptive mechanism in practice is that you don't need to manually adjust the reasoning depth. The model automatically judges the difficulty of the math problem and allocates appropriate computational resources, striking an optimal balance between latency and cost.
Claude Sonnet 4.6's Unique Advantage: The Solution Process
In math problem-solving scenarios, Claude Sonnet 4.6 has a widely recognized unique advantage—the clarity of its solution process. Multiple evaluations point out that Claude models perform best at explaining mathematical concepts. Furthermore, Anthropic's Learning Mode is specifically designed to guide a student's reasoning process rather than giving the answer directly.
This makes Claude Sonnet 4.6 particularly suitable for:
- Math education and tutoring scenarios
- Learners who need to understand the solution steps
- Researchers wanting to verify their problem-solving approach
💡 Learning Tip: If your core need is "understanding the math problem-solving process" rather than just getting an answer, Claude Sonnet 4.6 is the best choice. You can experience the detail of its solution process by getting free test credits via APIYI at apiyi.com.
GPT-5.4 Math Problem-Solving Capabilities Explained
GPT-5.4 is OpenAI's latest flagship model, released on March 6, 2026. It's the first OpenAI reasoning model to integrate cutting-edge professional capabilities, programming prowess (from GPT-5.3-Codex), native computer operation, and a 1.05M context window within a single default model.
GPT-5.4 Math Benchmark Scores
| Benchmark | Score | Notes |
|---|---|---|
| AIME 2025 | 100% (Perfect Score) | High school math competition level, perfect performance |
| GSM8K | 99% | Elementary school math word problems, near-perfect |
| MATH | 88.6% | Composite math reasoning benchmark |
| GPQA Diamond | 84.2% (Standard) / 92.8% (High Reasoning) | Graduate-level science reasoning |
| ARC-AGI-2 | 73.3% (Standard) / 83.3% (Pro) | Abstract reasoning capability |
| FrontierMath (Previous 5.2) | 40.3% | New record for expert-level frontier math |
GPT-5.4 achieved a stunning perfect score of 100% on AIME 2025. This means it can flawlessly solve all high-difficulty competition problems from the American Invitational Mathematics Examination. For users needing to solve competition-level math problems, this performance is highly compelling.
It's worth noting that GPT-5.4's score on the MATH benchmark is 88.6%, showing a gap compared to Gemini 3.1 Pro's 95.1%. This indicates that while GPT-5.4 performs perfectly on competition-level hard problems, it isn't the strongest in comprehensive tests covering a wide range of mathematical fields.
GPT-5.4 Reasoning Configuration Options
GPT-5.4 offers multiple reasoning configurations to adapt to different math problems:
- GPT-5.4 Standard: Suitable for daily math calculations and medium-difficulty problems.
- GPT-5.4 Thinking: Enables advanced reasoning, suitable for complex multi-step reasoning and proofs.
- GPT-5.4 Pro: Highest performance configuration, achieving 83.3% on ARC-AGI-2, suitable for the most difficult scenarios.
However, note that GPT-5.4 Pro is priced at $30.00/1M input + $180.00/1M output, a cost far exceeding the standard version. For most math problem-solving scenarios, the standard version is sufficient.
GPT-5.4 Math Problem-Solving Practical Experience
GPT-5.4's performance on competition-level math problems is particularly impressive:
- Competition Math: Near-perfect answers for AMC/AIME-level comprehensive problems in number theory, combinatorics, and geometry. The 100% AIME score is well-deserved.
- Proof Problems: Capable of constructing complete mathematical proof chains with rigorous logic and natural transitions between steps.
- Applied Math: The 99% score on GSM8K shows it's also highly reliable on practical application problems (e.g., engineering calculations, economic modeling).
- Multi-step Reasoning: Thanks to the 1.05M ultra-long context window, it can maintain complete reasoning chains while handling extremely complex multi-step math problems.
A unique advantage of GPT-5.4 is that its predecessor, GPT-5.2, set a new record of 40.3% on FrontierMath (expert-level frontier mathematics). This means the GPT series also possesses a certain exploratory capability for truly cutting-edge, unsolved mathematical problems, a level currently difficult for other models to match.
Interpreting Math Problem-Solving AI Model Benchmarks
Before comparing math problem-solving AI models, it's essential to understand what each benchmark measures and its focus area. This helps you judge a model's capabilities more accurately.
| Benchmark | Full Name | Test Content | Difficulty Level |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | Problems from the actual AIME competition, covering number theory, combinatorics, geometry, etc. | High School Competition Level (Top 5% of students) |
| MATH | Mathematics Aptitude Test of Heuristics | Comprehensive test covering 7 major areas like algebra, geometry, calculus. | High School to Undergraduate Level |
| GSM8K | Grade School Math 8K | 8,000 word problems from elementary to middle school math. | Foundational Level |
| GPQA Diamond | Graduate-Level Google-Proof QA | Graduate-level scientific reasoning questions authored by domain experts. | Graduate/PhD Level |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | Novel logical pattern recognition, testing abstract reasoning. | General Intelligence Level |
| FrontierMath | Frontier Mathematics | Expert-level, frontier mathematics problems involving unsolved or emerging fields. | Expert/Researcher Level |
Key Insight: AIME focuses more on competition-level mathematical techniques and creative thinking, while MATH emphasizes broad coverage across diverse areas. A model that scores perfectly on AIME but not the highest on MATH (like GPT-5.4) indicates it's exceptionally strong on tricky competition-style problems, but its coverage across certain foundational domains might be slightly less comprehensive than a model scoring higher on MATH.
This is precisely why we recommend Gemini 3.1 Pro Preview as the top choice for all-around performance—its 95.1% score on MATH signifies more balanced performance across all mathematical subfields.
It's important to note that the AIME 2025 benchmark is now approaching saturation—multiple top-tier models (especially when paired with code execution) can achieve over 95% or even perfect scores. Therefore, benchmarks like MathArena Apex and FrontierMath, which are more challenging, are better at distinguishing a model's true mathematical prowess. On MathArena Apex, Gemini 3.1 Pro shows a more than 20x improvement over its predecessor, demonstrating a very strong foundation in intrinsic mathematical reasoning.
Another critical dimension to watch is ARC-AGI-2 (Abstract Reasoning). This test evaluates a model's ability to recognize entirely new logical patterns—ones it has never seen during training. Gemini 3.1 Pro Preview leads with 77.1%, suggesting it can not only solve familiar problem types but also possesses stronger generalization and reasoning capabilities, performing better when faced with completely novel types of mathematical challenges.
Hands-on: Calling Math Problem-Solving AI Models via API
Here's a minimal code example to call a math problem-solving AI model via API—you can get it running in just 10 lines:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI unified endpoint
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Can switch to claude-sonnet-4.6 or gpt-5.4
messages=[{"role": "user", "content": "Solve: Given an arithmetic sequence {an} with first term a1=2 and common difference d=3, find the sum of the first 20 terms, S20."}]
)
print(response.choices[0].message.content)
View Complete Math Problem-Solving Code (with Multi-Model Comparison)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
Call an AI model to solve a math problem.
Args:
problem: The description of the math problem.
model: Model name. Supports gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4.
system_prompt: System prompt to specify the problem-solving style.
Returns:
The model's response containing the solution.
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI unified endpoint
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "You are a math problem-solving expert. Please solve the math problem with clear steps, explaining the reasoning behind each step."
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Example usage: Compare three models on the same problem.
problem = "In triangle ABC, given a=5, b=7, C=60°, find the area of the triangle and the length of the third side c."
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"Model: {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
Recommendation: Get free testing credits via APIYI at apiyi.com. With a single API key, you can call all three math-solving models mentioned above and quickly compare their performance on your specific problems.
AI Model Pricing and Cost-Effectiveness Comparison for Math Problem Solving
When choosing an AI model for math problem solving, price is a factor that can't be ignored. Here's a detailed price comparison for three models:
| Price Dimension | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Input Price | $2.00/1M tokens | $3.00/1M tokens | $2.50/1M tokens |
| Output Price | $12.00/1M tokens | $15.00/1M tokens | $15.00/1M tokens |
| Mixed Price (3:1) | $4.50/1M tokens | $6.00/1M tokens | $5.63/1M tokens |
| Long Context Surcharge | >200K tokens doubles | None | >272K tokens doubles |
| Context Window | 1M tokens | Standard window | 1.05M tokens |
| Max Output | 65,536 tokens | Standard output | 128,000 tokens |
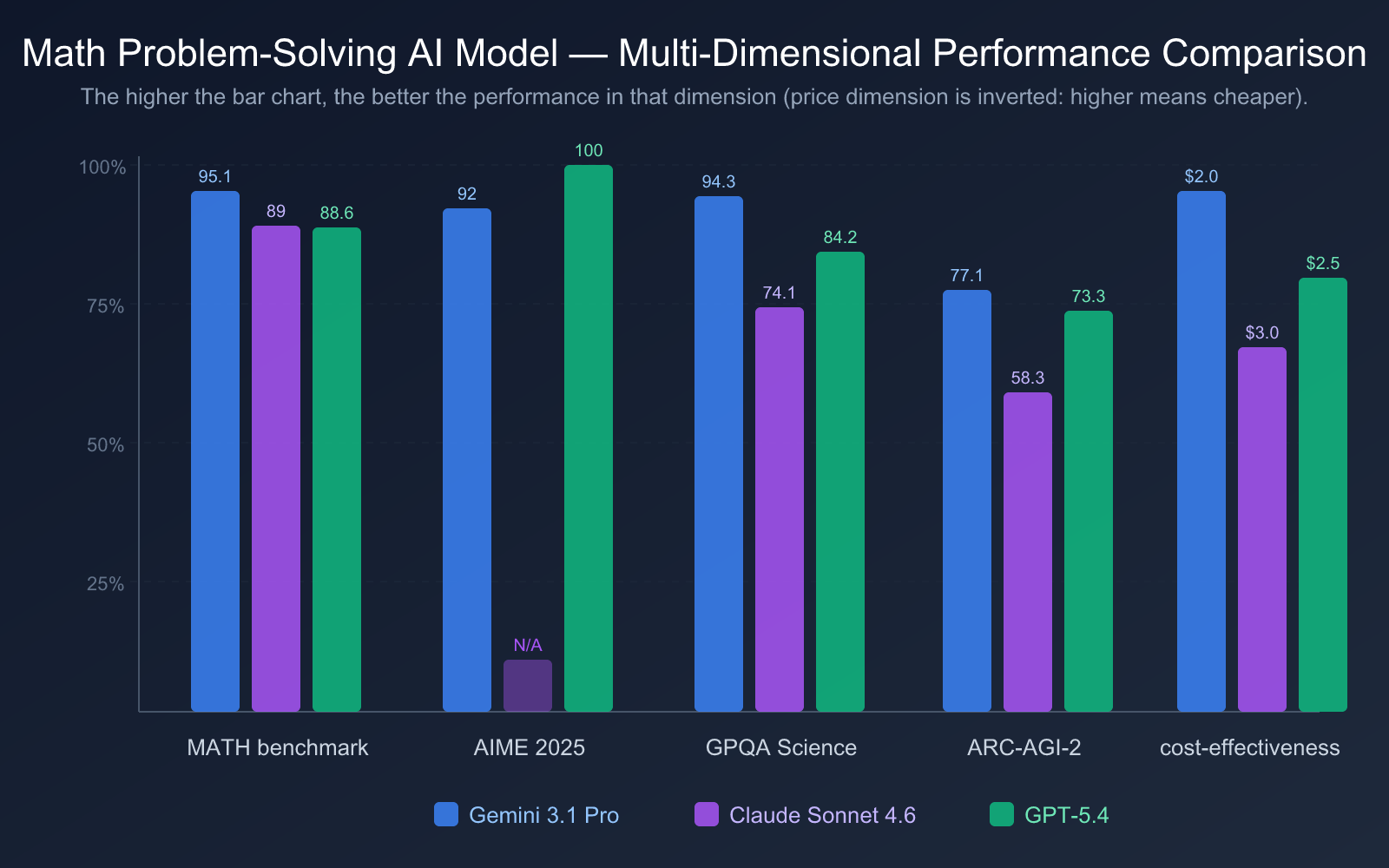
From a cost-effectiveness perspective:
- Gemini 3.1 Pro Preview offers the best value: At just $2.00/1M tokens for input and leading with a 95.1% MATH benchmark score. According to Artificial Analysis, its operational cost is about 1/7.5th of Claude Opus 4.6, yet it matches or even surpasses it in math and programming benchmarks.
- Claude Sonnet 4.6 is moderately priced: The $3.00/$15.00 pricing is the same as the previous Sonnet 4.5, but its math capability has improved by 27 percentage points, offering much better value.
- GPT-5.4 Standard Edition is reasonably priced: At $2.50/$15.00, it's within a reasonable range, but if you use GPT-5.4 Pro ($30/$180), the cost increases significantly.
💰 Cost Recommendation: For daily math problem-solving needs, Gemini 3.1 Pro Preview is recommended for the best cost-effectiveness. If you need to further optimize costs, consider using an API aggregation platform for more flexible top-up options.
Actual Cost Estimation for Math Problem Solving
To help you better understand the cost differences, here's an estimated cost for a typical math problem-solving scenario:
Scenario Assumption: Solving 100 medium-difficulty math problems daily, with each problem averaging 500 input tokens + 1500 output tokens.
| Model | Daily Input Cost | Daily Output Cost | Daily Total Cost | Monthly Cost (30 days) |
|---|---|---|---|---|
| Gemini 3.1 Pro | $0.10 | $1.80 | $1.90 | $57.00 |
| GPT-5.4 | $0.13 | $2.25 | $2.38 | $71.25 |
| Claude Sonnet 4.6 | $0.15 | $2.25 | $2.40 | $72.00 |
| GPT-5.4 Pro | $1.50 | $27.00 | $28.50 | $855.00 |
| DeepSeek R2 | $0.03 | $0.33 | $0.36 | $10.80 |
From this cost estimation, it's clear that:
- Gemini 3.1 Pro Preview is the most economical at about $57/month among the three main models.
- Claude Sonnet 4.6 and GPT-5.4 Standard Edition have similar costs, around $71-72/month.
- GPT-5.4 Pro costs a hefty $855/month, suitable only for scenarios with ample budget and requiring extreme accuracy.
- DeepSeek R2 offers a highly competitive solution at an ultra-low cost of $10.80/month.
AI Model Comprehensive Intelligence Index Comparison for Math Problem Solving
Beyond individual benchmark tests, the comprehensive intelligence index provides a more holistic view of a model's potential for mathematical reasoning. The Artificial Analysis Intelligence Index is one of the most authoritative comprehensive evaluation systems, calculating a model's overall score based on four dimensions: reasoning, knowledge, mathematics, and programming.
| Model | Comprehensive Intelligence Index | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | Overall Assessment |
|---|---|---|---|---|---|---|
| GPT-5.4 (xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | Champion for competition problems, tied for first in comprehensive index |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | Tied for first in comprehensive index, most comprehensive math coverage |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | Top-tier scientific reasoning and explanation capabilities |
| Claude Sonnet 4.6 (max) | 52 | — | 89% | 74.1% | 58.3% | Excellent cost-performance, clearest problem-solving process |
Looking at the comprehensive intelligence index, GPT-5.4 (xhigh) and Gemini 3.1 Pro Preview are tied for first place with 57 points, but they have different strengths:
- GPT-5.4: Performs perfectly (100%) on competition-level problems like AIME, but has a slightly lower score on the comprehensive MATH benchmark (88.6%).
- Gemini 3.1 Pro: Shows more balanced performance on the comprehensive MATH benchmark (95.1%) and the scientific reasoning GPQA Diamond (94.3%).
This means if your math needs lean towards competitions and extremely difficult problems, GPT-5.4 has the edge. If you need stable performance across a wide range of mathematical fields, Gemini 3.1 Pro Preview is the safer choice.
AI Model Recommendations for Math Problem Solving Scenarios
Different mathematical application scenarios place different demands on models. Here are recommendations based on practical use cases:
Scenarios for Choosing Gemini 3.1 Pro Preview
- Comprehensive Math Tutoring Platforms: Covers all areas like algebra, geometry, calculus, etc., with the strongest overall capability (MATH 95.1%).
- High-Volume Math Problem Processing: Lowest cost; its three-layer thinking system can automatically adapt to problem difficulty, reducing processing costs.
- Scenarios Combining Scientific Calculation: With 94.3% on GPQA Diamond for scientific reasoning, it's suitable for problems intersecting physics, chemistry, and math.
- Visual Math Problems: Gemini's multimodal capabilities give it an advantage when handling math problems containing charts, diagrams, or geometric figures.
Scenarios for Choosing Claude Sonnet 4.6
- Math Education and Tutoring: Clearest problem-solving process; its Learning Mode is specifically designed to guide student reasoning, prompting thought rather than giving direct answers.
- Learning Problem-Solving Steps: Best for scenarios where you need to understand why a certain approach is taken. Claude's explanatory ability is widely recognized as top-tier. The 70% user preference for Sonnet 4.6 over the previous 4.5 indicates a qualitative leap in user experience.
- Math Research Assistance: Suitable for researchers who need detailed derivation processes to verify their reasoning; its adaptive thinking depth automatically matches problem complexity.
- Office and Financial Calculations: Best-in-class for financial analysis (63.3%); its office productivity GDPval-AA score of 1633 Elo even surpasses the more expensive Opus 4.6.
- Programming + Math Combination: Programming capability of 79.6% is close to Opus 4.6, making it suitable for developers who need to write mathematical computation programs.
Scenarios for Choosing GPT-5.4
- High-Difficulty Math Competitions: Perfect score (100%) on AIME makes it the first choice for competition-level math problems.
- Long-Context Mathematical Reasoning: With a 1.05M context window, it's ideal for handling complex problems requiring extensive mathematical background information.
- Professional Math Research: Its predecessor, GPT-5.2, set a new record of 40.3% on FrontierMath, indicating strong expert-level, cutting-edge mathematical ability.
- Investment Banking and Quantitative Finance: High score of 87.3% on investment banking modeling tasks makes it suitable for high-end financial mathematics scenarios.
Hybrid Usage Strategy: The Best Model Combination for Math Problem Solving
In real-world production environments, many teams adopt a hybrid usage strategy to achieve optimal results.
Strategy 1: Difficulty-Based Routing
- Basic Problems (arithmetic, simple equations) → Gemini 3.1 Pro Low mode (lowest cost)
- Medium Problems (multi-step reasoning, word problems) → Claude Sonnet 4.6 Adaptive mode (clearest process)
- High-Difficulty Problems (competitions, proofs) → GPT-5.4 Thinking mode (highest accuracy)
Strategy 2: Cross-Verification
- First, use Gemini 3.1 Pro for quick solving (low cost, high speed).
- Then, use GPT-5.4 to double-check critical results (high accuracy).
- Finally, use Claude Sonnet 4.6 to rephrase explanations for users (clear expression).
🚀 Implementation Tip: The hybrid strategies above can be easily implemented via the APIYI apiyi.com platform. You can call all models with a single API key by simply switching the
modelparameter in your code.
AI Model Selection Recommendations for Math Problem Solving
Based on the comprehensive analysis above, here are tailored recommendations for different user groups:
| User Type | Recommended Model | Key Reason |
|---|---|---|
| Students / Self-Learners | Claude Sonnet 4.6 | Clear step-by-step solutions, Learning Mode guides thinking |
| EdTech Platform Developers | Gemini 3.1 Pro Preview | Best overall capability, lowest price, three-tier thinking adapts to difficulty |
| Competition Participants / Coaches | GPT-5.4 | Perfect AIME score, strongest ability for competition-level problems |
| Researchers | Gemini 3.1 Pro Preview | GPQA Diamond 94.3%, leading in science + math cross-disciplinary ability |
| Enterprise Batch Processing | Gemini 3.1 Pro Preview | Best cost-performance, $2.00/1M tokens input price |
| Quantitative Finance Teams | GPT-5.4 | Investment banking modeling 87.3%, strongest in financial math scenarios |
💡 Selection Advice: Which math-solving AI model you choose mainly depends on your specific application scenario. If you're unsure which is best, we recommend testing all three models on the same math problem via the APIYI platform at apiyi.com. Make your final choice based on solution quality and response speed. The platform supports unified API calls, making it easy to quickly compare and switch models.
Other Notable Math Problem-Solving Models
Beyond the three main models discussed, here are a few other AI models worth considering for specific math-solving scenarios:
| Model Name | AIME 2025 | Core Advantage | API Price (Input/Output) | Best For |
|---|---|---|---|---|
| DeepSeek R2 | Beat Gemini 3.1 Pro | Extreme cost-performance | $0.55/$2.19 per 1M | Budget-sensitive batch math processing |
| Claude Opus 4.6 | — | GPQA 91.3%, deepest explanations | $15/$75 per 1M | High-end research & deep reasoning |
| Qwen3-235B | 89.2% | Strongest open-source model | Self-deployment cost | Scenarios requiring private deployment |
| DeepSeek R1 | ~87.5% | Open-source benchmark, 671B MoE | Self-deployment cost | Open-source community research & development |
| MiMo-V2-Flash | 94.1% | Inference cost only 2.5% of Claude's | Extremely low | Ultra-large-scale, low-cost inference |
DeepSeek R2 is particularly noteworthy—it beat Gemini 3.1 Pro Preview on the AIME while costing about a quarter of the price. If your math-solving scenario is extremely budget-sensitive, DeepSeek R2 is a highly competitive choice.
MiMo-V2-Flash scored a high 94.1% on AIME 2025, yet its inference cost is only 2.5% of Claude's. This makes it ideal for EdTech platforms needing large-scale, batch processing of math problems.
Prompt Optimization Tips for Math Problem-Solving AI
Regardless of the model you choose, a good prompt can significantly improve the quality of math solutions. Here are proven prompt engineering techniques:
- Specify the Problem Type: Label the prompt with "This is a combinatorics problem" or "This is an analytic geometry problem" to help the model invoke the correct solving strategy.
- Request Step-by-Step Solutions: Add "Please derive step-by-step, labeling the theorem or formula used in each step" to improve the readability of the solution process.
- Define the Output Format: For example, "Please output mathematical formulas in LaTeX format" or "Mark the final answer with a box."
- Provide Contextual Constraints: Such as "Assume x is a positive integer" or "Solve within the domain of real numbers" to prevent the model from generating unnecessary case analyses.
- Cross-Verify with Multiple Models: For critical results, verify answer consistency using different models to increase confidence.
Frequently Asked Questions
Q1: Are AI model benchmark scores for math problem-solving reliable?
Benchmarks provide a standardized basis for horizontal comparison, but actual performance is also influenced by factors like question type and prompt quality. AIME and MATH are currently the most authoritative benchmarks for mathematical reasoning, widely recognized by both academia and industry. It's recommended to test and validate with your own actual problems while referencing benchmark data.
Q2: I’m a student. Which math problem-solving AI model should I choose?
Claude Sonnet 4.6 is the recommended first choice. Its problem-solving process is the clearest, with explicit reasoning explanations for each step, making it ideal for learning and understanding mathematical problem-solving approaches. Anthropic's Learning Mode feature can also guide you to think for yourself rather than just giving the answer. If you encounter particularly difficult competition problems, you can switch to GPT-5.4 for assistance.
Q3: How can I quickly start testing these math problem-solving AI models?
It's recommended to use an API aggregation platform that supports a unified interface for multiple models:
- Visit APIYI at apiyi.com to register an account.
- Obtain an API key and free testing credits.
- Use the Python code examples provided in this article; simply modify the model parameter to switch between different models.
- Test the three models with the same math problem to compare solution quality and response speed.
Q4: Do these math problem-solving AI models support LaTeX formula output?
All three models support outputting mathematical formulas in LaTeX format. Just add "Please output all mathematical formulas in LaTeX format" to your prompt. Gemini 3.1 Pro and GPT-5.4 have more standardized LaTeX formatting, while Claude Sonnet 4.6 provides more detailed textual explanations between formulas. For scenarios requiring direct copying of formulas into papers, Gemini or GPT is recommended.
Q5: Can math problem-solving AI models handle math problems in images?
Both Gemini 3.1 Pro Preview and GPT-5.4 support multimodal input, allowing you to directly upload images containing math problems for solving. Gemini performs exceptionally well in processing images containing geometric figures and handwritten formulas. Claude Sonnet 4.6 also supports image input but is slightly less capable than Gemini in recognizing complex geometric figures. If your math problems often come in image form (e.g., photo search for problems), Gemini 3.1 Pro Preview is the best choice.
Summary
Key points for choosing a math problem-solving AI model:
- Best Overall: Gemini 3.1 Pro Preview: Leads comprehensively with MATH 95.1%, offers the best price at $2.00/1M tokens, and its three-tier thinking system flexibly adapts to different difficulty levels.
- Best for Learning: Claude Sonnet 4.6: Achieved a 27 percentage point leap in math capability to 89%, provides clear solution steps, and balances cost with quality through adaptive thinking depth.
- Best for Competition Problems: GPT-5.4: Scored a perfect 100% on AIME 2025, features a 1.05M ultra-long context window, and has unparalleled high-difficulty reasoning capabilities.
No single model is the optimal solution for all mathematical scenarios. The competitive landscape for math problem-solving AI models in 2026 can be summarized as follows:
- Comprehensive Coverage: Gemini 3.1 Pro Preview, with its MATH 95.1% score and lowest price, holds the top spot as the comprehensive first choice.
- Education & Learning: Claude Sonnet 4.6, with its 27-point math leap and unparalleled solution explanations, is the best choice for educational scenarios.
- Extreme Competition: GPT-5.4, with its absolute strength of a perfect AIME score, is unrivaled in the high-difficulty math competition domain.
- Budget Priority: DeepSeek R2 offers comparable mathematical reasoning capabilities at less than 1/4 the price of Gemini.
The smartest strategy is to choose the appropriate model based on your actual needs, or even mix and use multiple models for problems of different difficulties to fully leverage each model's unique strengths.
It's recommended to quickly test and compare these models through APIYI at apiyi.com. The platform offers free credits and a unified API interface, allowing you to flexibly call all mainstream mathematical reasoning models with a single integration, easily implementing a multi-model hybrid usage strategy.
📚 References
-
Google DeepMind Gemini 3.1 Pro Model Card: Official benchmark data and technical details
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Description: Contains complete benchmark scores and architecture explanations
- Link:
-
Anthropic Claude Sonnet 4.6 Release Notes: Details on mathematical reasoning improvements
- Link:
docs.anthropic.com - Description: Contains comparison data between Sonnet 4.6 and previous versions, and explanations of the adaptive thinking mechanism
- Link:
-
OpenAI GPT-5.4 Release Announcement: Latest model features and benchmark data
- Link:
openai.com/index/introducing-gpt-5-4/ - Description: Contains complete benchmark test scores and reasoning configuration explanations for GPT-5.4
- Link:
-
Artificial Analysis Model Evaluations: Independent third-party benchmark comparison platform
- Link:
artificialanalysis.ai/evaluations/aime-2025 - Description: Provides independent leaderboards and analysis for benchmarks like AIME 2025
- Link:
-
AIME 2025 Benchmark Leaderboard: Authoritative comparison of mathematical reasoning capabilities
- Link:
vals.ai/benchmarks/aime - Description: Continuously updated AI mathematical reasoning benchmark ranking data
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to share your experience using AI for math problem-solving in the comments. For more model invocation tutorials, visit the APIYI docs.apiyi.com documentation center.