Author's Note: Latest assessment from March 2026, comparing 10 lightweight Large Language Models suitable for translation scenarios across three dimensions—speed, translation quality, and cost. Models include Gemini 3 Flash, Claude Haiku 4.5, DeepSeek V3.2, GPT-5 Nano, and more.
{Translation scenario LLM API TOP 10}
Using Large Language Models for translation has become the mainstream approach in 2026. But here's the question: which model should you actually use for translation tasks?
This article focuses exclusively on the translation capabilities of general-purpose Large Language Models (LLMs), excluding specialized translation engines like DeepL and Google Translate. The reason is straightforward—LLM translation excels at contextual understanding, terminology consistency, and style control, capabilities that specialized translation engines struggle to match.
Model selection for translation scenarios hinges on three core considerations:
- Speed matters: Translation tasks are typically batch-processed, and latency directly impacts efficiency
- Quality can't be compromised: Translation quality is non-negotiable—poor translations are worse than no translation
- Costs must be manageable: Translation is often a high-frequency, high-volume task with substantial token consumption
Core Value: After reading this article, you'll know exactly which lightweight LLMs are best suited for translation scenarios in March 2026, and how to make the right choice based on your budget and quality requirements.
Translation Scenario Large Language Model TOP 10 Overview
The following rankings comprehensively consider three dimensions: translation quality, response speed, and API cost, with a focus on lightweight, cost-effective model selection:
| Rank | Model | Input/Output Price (per Million Tokens) | Core Strengths | Recommendation |
|---|---|---|---|---|
| 🥇 1 | Gemini 3 Flash Preview | $0.50 / $3.00 | Highest intelligence lightweight model, excellent translation quality | ⭐⭐⭐⭐⭐ |
| 🥈 2 | Gemini 2.5 Flash | $0.15 / $0.60 | Mature and stable, strong multilingual capabilities | ⭐⭐⭐⭐⭐ |
| 🥉 3 | Claude Haiku 4.5 | $1.00 / $5.00 | Best literary translation quality, strong style control | ⭐⭐⭐⭐⭐ |
| 4 | DeepSeek V3.2 | $0.14 / $0.28 | Extremely low cost, outstanding Chinese translation ability | ⭐⭐⭐⭐ |
| 5 | GPT-5 Nano | $0.05 / $0.40 | Cheapest OpenAI model, extremely fast speed | ⭐⭐⭐⭐ |
| 6 | GPT-4.1 Nano | $0.10 / $0.40 | Proven stable choice | ⭐⭐⭐⭐ |
| 7 | Gemini 2.5 Flash-Lite | $0.10 / $0.40 | Ultra-low latency, ideal for bulk translation | ⭐⭐⭐⭐ |
| 8 | Qwen3 32B | $0.08 / $0.24 | Strongest performance for Asian language translation | ⭐⭐⭐⭐ |
| 9 | Mistral Small 3.2 | $0.06 / $0.18 | Clear advantages in European language translation | ⭐⭐⭐⭐ |
| 10 | Llama 4 Maverick | Open-source self-deployment | Strong multilingual foundation capabilities, suitable for private deployment | ⭐⭐⭐ |
🎯 Selection Recommendation: All the above models can be called through APIYI's unified interface at apiyi.com. With a single API key, you can compare and test different models' translation performance to quickly find the best fit for your scenario.
Core Evaluation Dimensions for Translation Models
Choosing a translation model can't be based on benchmarks alone. We've defined 4 evaluation dimensions based on real translation scenarios:
| Dimension | Weight | Description | Measurement Method |
|---|---|---|---|
| Translation Quality | 40% | Semantic accuracy, natural expression, terminology consistency | COMET score + human review |
| Response Speed | 25% | First token latency and overall throughput | TTFT + TPS |
| API Cost | 25% | Input/output price per million tokens | Official pricing |
| Multilingual Coverage | 10% | Number of supported languages and quality for minor languages | Language pair coverage rate |
Key Insights for Translation Model Selection
The WMT 2025 evaluation results reveal an important trend: traditional machine translation systems still have competitive performance on surface metrics like BLEU, but Large Language Models show stronger performance on semantic evaluation metrics like COMET. This means that while LLM translations might not be the most precise word-for-word matches, they excel at "reading naturally and conveying the intended meaning."
For translation scenarios, lightweight models (Flash, Haiku, Nano, etc.) already deliver sufficiently good translation quality—translation doesn't require complex reasoning capabilities. What matters is language understanding and generation ability, which are precisely the strengths of lightweight models.
Translation Model TOP 10 Detailed Analysis
First Tier: Optimal Translation Quality and Cost-Effectiveness
Gemini 3 Flash Preview is the top recommendation for translation scenarios in March 2026. It scores 71 on the Artificial Analysis Intelligence Index, a 13-point improvement over Gemini 2.5 Flash, while maintaining the Flash series' signature low-latency advantage. In terms of translation quality, Gemini 3 Flash's context understanding capabilities approach Pro-level performance, and its million-token context window excels at handling long document translations.
Gemini 2.5 Flash is a thoroughly validated mature solution. Google explicitly states it excels at "high-frequency, low-latency translation and classification tasks," with even lower latency than 2.0 Flash and pricing at just $0.15/$0.60—the cost-effective choice for large-scale translation projects.
Claude Haiku 4.5 offers unique advantages in translation quality—Anthropic models have always set the industry standard for language style and context handling. Haiku 4.5 translations aren't just accurate; they "read like they were written by a human." At $1.00/$5.00, the pricing is on the higher side for lightweight models, but for scenarios demanding quality like literary translation and marketing copy, this premium is worth it.
Second Tier: Extreme Cost-Effectiveness
DeepSeek V3.2 delivers surprisingly strong translation quality at $0.14/$0.28. The DeepSeek Sparse Attention (DSA) introduced in V3.2 maintains context coherence in long document translations. Supporting 100+ languages, its Chinese translation capabilities are particularly outstanding. Community feedback shows V3.2's multilingual output "consistently maintains target language coherence."
GPT-5 Nano is OpenAI's cheapest model at just $0.05 per million input tokens. Its 200K context window is larger than GPT-4o-mini's 128K, offering clear advantages for translating lengthy documents. Though it's the lightest GPT model, translation and keyword generation are among its strengths.
GPT-4.1 Nano — while OpenAI recommends GPT-5 Nano for new projects, 4.1 Nano has extensive production validation for translation scenarios. If you prioritize predictable output quality, 4.1 Nano remains a reliable choice.
Third Tier: Scenario-Specific Optimizations
Gemini 2.5 Flash-Lite is purpose-built for latency-sensitive tasks, 1.5x faster than 2.0 Flash, with pricing at $0.10/$0.40—nearly the lowest tier. Perfect for real-time translation and user-generated content translation where ultra-low latency is critical.
Qwen3 32B delivers the strongest performance on Asian languages (Chinese, Japanese, Korean, and Southeast Asian languages). It outperforms DeepSeek-V3 and Qwen2.5 on MGSM and MMMLU multilingual benchmarks, with 68% of large Asian enterprises deploying Qwen series models. At $0.08/$0.24, the pricing is highly competitive.
Mistral Small 3.2 excels in European language translation with just 24B parameters. At $0.06/$0.18, it's among the lowest prices across all commercial APIs—ideal for large-scale translation of French, German, Spanish, and other European languages.
Llama 4 Maverick is the strongest multilingual option among open-source solutions, with its 17B active parameters plus 128-expert MoE architecture surpassing GPT-4o in multilingual understanding. Perfect for private deployment translation where data privacy is a requirement.
Practical Recommendation: Paper specifications are just reference points—actual translation performance varies significantly by language pair and content type. We recommend A/B testing through APIYI (apiyi.com) to compare different models' translation results on identical text.
Translation Model Cost Comparison Analysis
Consider a typical translation scenario: translating 1,000 articles monthly, averaging 2,000 characters per article (approximately 3,000 input tokens + 3,000 output tokens), totaling about 6 million tokens:
| Model | Monthly Cost Estimate | Relative Cost | Best For |
|---|---|---|---|
| GPT-5 Nano | $2.70 | 1x (baseline) | Large-scale, cost-sensitive |
| Mistral Small 3.2 | $1.44 | 0.53x | European language batch translation |
| Qwen3 32B | $1.92 | 0.71x | Asian language translation |
| Gemini 2.5 Flash-Lite | $3.00 | 1.11x | Real-time translation |
| DeepSeek V3.2 | $2.52 | 0.93x | General translation, Chinese-first |
| Gemini 2.5 Flash | $4.50 | 1.67x | High-quality general translation |
| GPT-4.1 Nano | $3.00 | 1.11x | Stability-first |
| Gemini 3 Flash Preview | $21.00 | 7.78x | Highest-quality translation |
| Claude Haiku 4.5 | $36.00 | 13.33x | Literary/marketing translation |
| Llama 4 Maverick | Self-deployment cost | Hardware-dependent | Private deployment |
🎯 Cost Optimization Tips: Most translation projects benefit from a tiered strategy—use Claude Haiku 4.5 or Gemini 3 Flash for important content to ensure quality, and DeepSeek V3.2 or GPT-5 Nano for bulk content to control costs. APIYI (apiyi.com) lets you flexibly switch between models without maintaining multiple API keys.
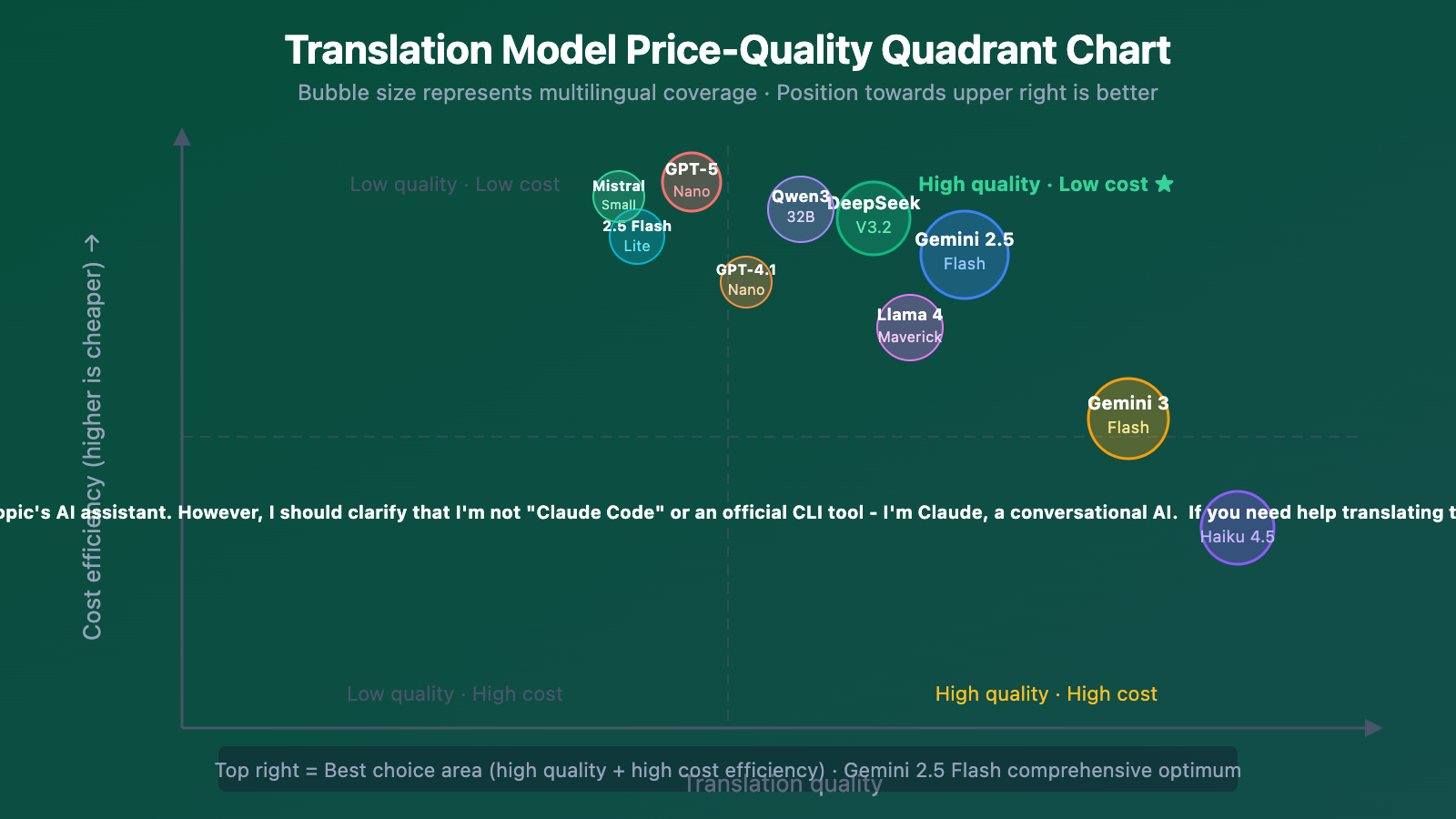
Translation Model FAQs
Q1: Why isn’t it recommended to use flagship models (Claude Opus, GPT-5) for translation?
Translation tasks don't require complex reasoning capabilities. Flagship models excel at multi-step reasoning and complex instruction following, but translation is fundamentally about language understanding and generation—exactly where lightweight models shine. Using Opus for translation costs 10-50x more, runs significantly slower, and the quality improvement is minimal.
Q2: Gemini 3 Flash Preview is still in preview—can I use it in production?
The Preview version performs stably for translation tasks. Translation has lower determinism requirements compared to scenarios like coding, and the Preview version's translation quality already exceeds Gemini 2.5 Pro. If you prioritize stability, you can start with Gemini 2.5 Flash (already GA) and migrate to Gemini 3 Flash once the official version launches.
Q3: How do I quickly compare translation quality across different models?
We recommend using an API aggregation platform that supports multiple models for testing:
- Visit APIYI at apiyi.com and register an account
- Get a unified API key and free credits
- Call different models with the same text segment
- Compare translation results for accuracy, naturalness, and terminology consistency
Summary
The key takeaways for Large Language Model selection in translation scenarios for 2026:
- Gemini Flash series is the optimal solution for translation: Gemini 3 Flash Preview offers the highest quality, Gemini 2.5 Flash provides the best value, and Flash-Lite delivers the lowest latency—Google has a clear advantage in this space
- Claude Haiku 4.5 suits high-quality translation: For scenarios like literary translation and marketing copy where "reading naturally" is critical, Haiku's language style control is worth the premium
- DeepSeek V3.2 and GPT-5 Nano are the go-to choices for cost-sensitive scenarios: For large-scale translation tasks, these two models offer unbeatable value
Choosing a translation model ultimately comes down to finding the right balance in the quality, speed, and cost triangle. We recommend testing and comparing through APIYI at apiyi.com—the platform supports unified API access to all the models mentioned above, helping you quickly find the solution that best fits your needs.
📚 Reference Materials
-
Artificial Analysis Model Leaderboard: Comprehensive LLM performance and pricing comparison data
- Link:
artificialanalysis.ai/leaderboards/models - Description: Provides intelligence scores, latency, and pricing comparisons across models
- Link:
-
WMT 2025 Machine Translation Evaluation: The most authoritative machine translation benchmark
- Link:
aclanthology.org/events/wmt-2025/ - Description: Systematic evaluation results covering 30 language pairs
- Link:
-
LLM API Pricing Comparison: Real-time LLM API pricing data
- Link:
pricepertoken.com - Description: Pricing data for 300+ models with calculator functionality
- Link:
-
Google Gemini 3 Flash Release Announcement: Official technical details for Gemini 3 Flash
- Link:
blog.google/products-and-platforms/products/gemini/gemini-3-flash/ - Description: Includes benchmark scores and pricing information
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to discuss in the comments section. For more resources, visit the APIYI documentation center at docs.apiyi.com