作者注:2026 年 3 月最新评估,从速度、翻译质量、成本三个维度对比 10 个适合翻译场景的轻量级大语言模型 API,包括 Gemini 3 Flash、Claude Haiku 4.5、DeepSeek V3.2、GPT-5 Nano 等。

用大语言模型做翻译已经是 2026 年的主流方案。但问题来了:翻译场景到底该用哪个模型?
本文只讨论通用大语言模型(LLM)的翻译能力,不包含 DeepL、Google Translate 等专用翻译引擎。原因很简单——LLM 翻译的优势在于上下文理解、术语一致性和风格控制,这是专用翻译引擎难以匹敌的。
翻译场景的模型选择有三个核心考量:
- 速度要快:翻译任务通常是批量处理,延迟直接影响效率
- 智能不能差:翻译质量是底线,低质量翻译比不翻译更糟
- 成本要可控:翻译往往是高频、大批量任务,Token 消耗大
核心价值: 读完本文,你将明确 2026 年 3 月哪些轻量级 LLM 最适合翻译场景,以及如何根据预算和质量要求做出选择。
翻译场景大语言模型 TOP10 总览
以下排名综合考虑翻译质量、响应速度和 API 成本三个维度,侧重轻量级、高性价比的模型选型:
| 排名 | 模型 | 输入/输出价格(每百万Token) | 核心优势 | 推荐指数 |
|---|---|---|---|---|
| 🥇 1 | Gemini 3 Flash Preview | $0.50 / $3.00 | 智能最高的轻量模型,翻译质量优秀 | ⭐⭐⭐⭐⭐ |
| 🥈 2 | Gemini 2.5 Flash | $0.15 / $0.60 | 成熟稳定,多语言能力强 | ⭐⭐⭐⭐⭐ |
| 🥉 3 | Claude Haiku 4.5 | $1.00 / $5.00 | 文学翻译质量最佳,风格把控强 | ⭐⭐⭐⭐⭐ |
| 4 | DeepSeek V3.2 | $0.14 / $0.28 | 极致低成本,中文翻译能力突出 | ⭐⭐⭐⭐ |
| 5 | GPT-5 Nano | $0.05 / $0.40 | 最便宜的 OpenAI 模型,速度极快 | ⭐⭐⭐⭐ |
| 6 | GPT-4.1 Nano | $0.10 / $0.40 | 经过验证的稳定选择 | ⭐⭐⭐⭐ |
| 7 | Gemini 2.5 Flash-Lite | $0.10 / $0.40 | 极低延迟,大批量翻译首选 | ⭐⭐⭐⭐ |
| 8 | Qwen3 32B | $0.08 / $0.24 | 亚洲语言翻译表现最强 | ⭐⭐⭐⭐ |
| 9 | Mistral Small 3.2 | $0.06 / $0.18 | 欧洲语言翻译优势明显 | ⭐⭐⭐⭐ |
| 10 | Llama 4 Maverick | 开源自部署 | 多语言基座能力强,适合私有化 | ⭐⭐⭐ |
🎯 选型建议: 以上模型均可通过 API易 apiyi.com 统一接口调用,一个 API Key 即可对比测试不同模型的翻译效果,快速找到最适合你场景的模型。
翻译模型核心评估维度
选择翻译模型不能只看跑分。我们从实际翻译场景出发,定义了 4 个评估维度:
| 维度 | 权重 | 说明 | 衡量方式 |
|---|---|---|---|
| 翻译质量 | 40% | 语义准确、表达自然、术语一致 | COMET 评分 + 人工评审 |
| 响应速度 | 25% | 首 Token 延迟和整体吞吐 | TTFT + TPS |
| API 成本 | 25% | 每百万 Token 的输入/输出价格 | 官方定价 |
| 多语言覆盖 | 10% | 支持的语言数量和小语种质量 | 语言对覆盖率 |
翻译模型选型的关键认知
WMT 2025 的评测结果揭示了一个重要趋势:传统机器翻译系统在 BLEU 等表面指标上依然有竞争力,但大语言模型在语义评估指标 COMET 上表现更强。这意味着 LLM 的翻译虽然可能不是逐字对应最精确的,但在「读起来自然、意思到位」方面更胜一筹。
对于翻译场景来说,轻量级模型(Flash、Haiku、Nano 等)的翻译质量已经足够好——翻译不需要复杂推理能力,关键是语言理解和生成能力,而这恰恰是轻量模型的长处。
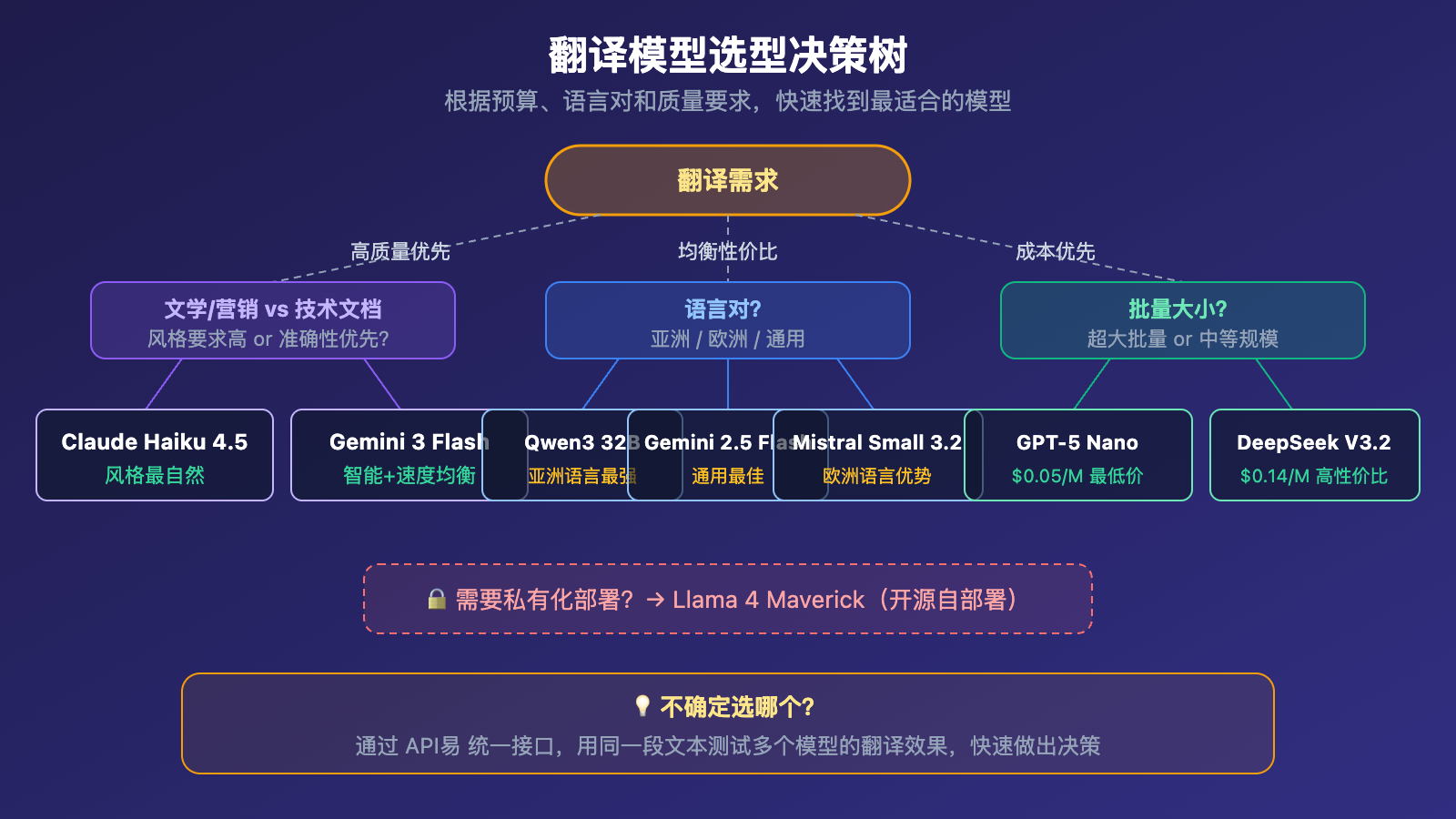
翻译模型 TOP10 详细解析
第一梯队:翻译质量与性价比最优
Gemini 3 Flash Preview 是 2026 年 3 月翻译场景的首选推荐。它在 Artificial Analysis 智能指数上得分 71,比 Gemini 2.5 Flash 提升了 13 分,同时保持了 Flash 系列一贯的低延迟优势。翻译质量方面,Gemini 3 Flash 的上下文理解能力接近 Pro 级别,百万 Token 上下文窗口让它在处理长文档翻译时表现出色。
Gemini 2.5 Flash 是经过充分验证的成熟方案。Google 官方明确表示它擅长「高频、低延迟的翻译和分类任务」,延迟比 2.0 Flash 更低,价格仅 $0.15/$0.60,是大批量翻译的性价比之选。
Claude Haiku 4.5 在翻译质量上有独特优势——Anthropic 模型对语言风格和上下文的把控一直是业界标杆。Haiku 4.5 的翻译不仅准确,而且「读起来像人写的」。$1.00/$5.00 的定价在轻量模型中偏高,但对于文学翻译、营销文案等对质量要求高的场景,这个溢价值得。
第二梯队:极致性价比
DeepSeek V3.2 以 $0.14/$0.28 的价格提供令人惊讶的翻译质量。V3.2 引入的 DeepSeek Sparse Attention(DSA)让它在长文档翻译中保持上下文连贯性。支持 100+ 语言,中文翻译能力尤其突出。社区反馈显示 V3.2 的多语言输出「始终保持目标语言的连贯性」。
GPT-5 Nano 是 OpenAI 最便宜的模型,输入仅 $0.05/百万 Token。200K 上下文窗口比 GPT-4o-mini 的 128K 更大,翻译长文档时优势明显。虽然是最轻量的 GPT 模型,但翻译和关键词生成是它的强项。
GPT-4.1 Nano 虽然 OpenAI 推荐新项目使用 GPT-5 Nano,但 4.1 Nano 在翻译场景的稳定性经过了大量生产验证。如果你追求可预测的输出质量,4.1 Nano 依然是可靠选择。
第三梯队:特定场景优选
Gemini 2.5 Flash-Lite 是专门为延迟敏感任务设计的,比 2.0 Flash 快 1.5 倍,$0.10/$0.40 的定价几乎是最低档。适合实时翻译、用户生成内容翻译等需要极低延迟的场景。
Qwen3 32B 在亚洲语言(中日韩、东南亚语言)翻译上表现最强。MGSM 和 MMMLU 多语言基准测试中超过 DeepSeek-V3 和 Qwen2.5,68% 的亚洲大型企业部署使用了 Qwen 系列。$0.08/$0.24 的定价极具竞争力。
Mistral Small 3.2 以 24B 参数量在欧洲语言翻译中表现优异。$0.06/$0.18 的价格几乎是所有商业 API 中最低的,适合法语、德语、西班牙语等欧洲语言的大批量翻译。
Llama 4 Maverick 是开源方案中多语言能力最强的,17B 活跃参数 + 128 专家的 MoE 架构让它在多语言理解上超过 GPT-4o。适合对数据隐私有要求的私有化翻译部署。
实测建议: 纸面参数只是参考,实际翻译效果因语言对和内容类型差异很大。建议通过 API易 apiyi.com 进行 A/B 测试,用相同的文本对比不同模型的翻译结果。
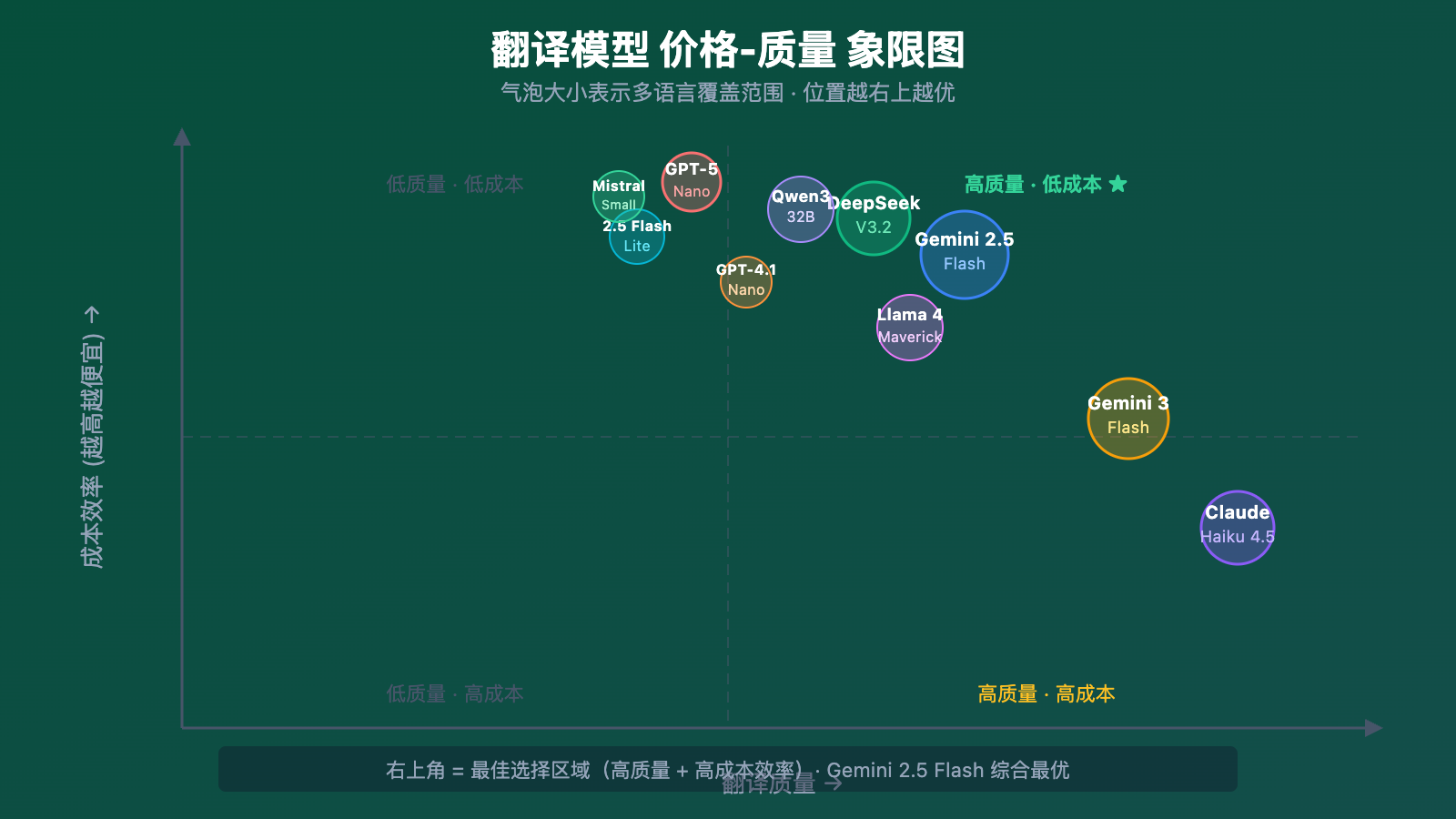
翻译模型成本对比分析
假设一个典型的翻译场景:每月翻译 1000 篇文章,平均每篇 2000 字(约 3000 Token 输入 + 3000 Token 输出),总计约 600 万 Token:
| 模型 | 月度成本估算 | 相对成本 | 适合场景 |
|---|---|---|---|
| GPT-5 Nano | $2.70 | 1x(基准) | 大批量、成本敏感 |
| Mistral Small 3.2 | $1.44 | 0.53x | 欧洲语言批量翻译 |
| Qwen3 32B | $1.92 | 0.71x | 亚洲语言翻译 |
| Gemini 2.5 Flash-Lite | $3.00 | 1.11x | 实时翻译 |
| DeepSeek V3.2 | $2.52 | 0.93x | 通用翻译、中文优先 |
| Gemini 2.5 Flash | $4.50 | 1.67x | 高质量通用翻译 |
| GPT-4.1 Nano | $3.00 | 1.11x | 稳定性优先 |
| Gemini 3 Flash Preview | $21.00 | 7.78x | 最高质量翻译 |
| Claude Haiku 4.5 | $36.00 | 13.33x | 文学/营销翻译 |
| Llama 4 Maverick | 自部署成本 | 视硬件而定 | 私有化部署 |
🎯 成本优化建议: 大多数翻译项目建议采用分层策略——重要内容用 Claude Haiku 4.5 或 Gemini 3 Flash 保证质量,大批量内容用 DeepSeek V3.2 或 GPT-5 Nano 控制成本。通过 API易 apiyi.com 可以灵活切换模型,无需维护多个 API Key。
翻译模型常见问题
Q1: 为什么不推荐用旗舰模型(Claude Opus、GPT-5)做翻译?
翻译任务不需要复杂的推理能力。旗舰模型的优势在于多步推理和复杂指令跟随,而翻译的核心是语言理解和生成——这正是轻量模型的强项。用 Opus 翻译不仅成本高 10-50 倍,速度也慢得多,而翻译质量的提升却非常有限。
Q2: Gemini 3 Flash Preview 还是预览版,生产环境能用吗?
Preview 版本在翻译场景中表现稳定。翻译任务对模型的确定性要求低于编程等场景,Preview 版本的翻译质量已经超过 Gemini 2.5 Pro。如果追求稳定,可以先用 Gemini 2.5 Flash(已 GA),等 Gemini 3 Flash 正式版发布后再迁移。
Q3: 如何快速对比不同模型的翻译效果?
推荐使用支持多模型的 API 聚合平台进行测试:
- 访问 API易 apiyi.com 注册账号
- 获取统一的 API Key 和免费额度
- 用同一段文本分别调用不同模型
- 对比翻译结果的准确性、自然度和术语一致性
总结
2026 年翻译场景大语言模型选型的核心要点:
- Gemini Flash 系列是翻译场景的最优解:Gemini 3 Flash Preview 质量最高,Gemini 2.5 Flash 性价比最优,Flash-Lite 延迟最低——Google 在这个赛道有明显优势
- Claude Haiku 4.5 适合高质量翻译:文学翻译、营销文案等对「读起来自然」有高要求的场景,Haiku 的语言风格把控值得溢价
- DeepSeek V3.2 和 GPT-5 Nano 是成本敏感型首选:大批量翻译任务,这两个模型的性价比无可匹敌
选择翻译模型的本质是在质量、速度、成本三角中找到平衡点。推荐通过 API易 apiyi.com 实际测试对比,平台支持以上所有模型的统一接口调用,帮你快速找到最适合自己场景的方案。
📚 参考资料
-
Artificial Analysis 模型排行榜: 全面的 LLM 性能和价格对比数据
- 链接:
artificialanalysis.ai/leaderboards/models - 说明: 提供各模型的智能指数、延迟和定价对比
- 链接:
-
WMT 2025 机器翻译评测: 最权威的机器翻译基准评测
- 链接:
aclanthology.org/events/wmt-2025/ - 说明: 涵盖 30 个语言对的系统评测结果
- 链接:
-
LLM API 定价对比: 实时更新的 LLM API 价格数据
- 链接:
pricepertoken.com - 说明: 300+ 模型的定价数据,支持计算器功能
- 链接:
-
Google Gemini 3 Flash 发布公告: Gemini 3 Flash 的官方技术细节
- 链接:
blog.google/products-and-platforms/products/gemini/gemini-3-flash/ - 说明: 包含基准测试分数和定价信息
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心