With the Google I/O 2026 keynote just a day away, Google can no longer keep its secrets under wraps. On May 5, developers managed to extract Gemini 3.2 Flash from the iOS Gemini app and Google AI Studio, while the "Liquid Glass" interface for the web version was also leaked ahead of schedule. The most impressive scenarios captured by overseas testers include generating 2,200 lines of functional code from a single prompt and crafting an interactive Windows 98 desktop demo using just a few lines of instructions. In several coding tasks, it has even managed to outperform the flagship Gemini 3.1 Pro.
This article is based on English-language sources available as of May 18, 2026. We’ll break down the key intelligence from this leak across five dimensions: core specifications, coding capabilities, pricing strategy, interface and agentic signals, and developer impact, while providing recommendations for your migration strategy.
Core Value: A 3-minute deep dive into the real-world power and pricing disruption of Gemini 3.2 Flash, and whether you should prepare your engineering plans before the I/O announcement.

Gemini 3.2 Flash: Core Specs at a Glance
Before Google released any official blog posts, the leaked version had already been thoroughly tested by developers. The table below summarizes all cross-verifiable key facts as of May 18, 2026, which we will expand upon in the following sections.
| Feature | Details |
|---|---|
| Leak Discovery Date | May 5, 2026, spotted in iOS Gemini App + Google AI Studio A/B testing |
| Expected Launch | Google I/O 2026, May 19–20 Keynote |
| Model Positioning | Mid-tier Flash series, targeting the coding capabilities of Gemini 3.1 Pro |
| Input Price | $0.25 / million tokens (on par with Gemini 3.1 Flash-Lite) |
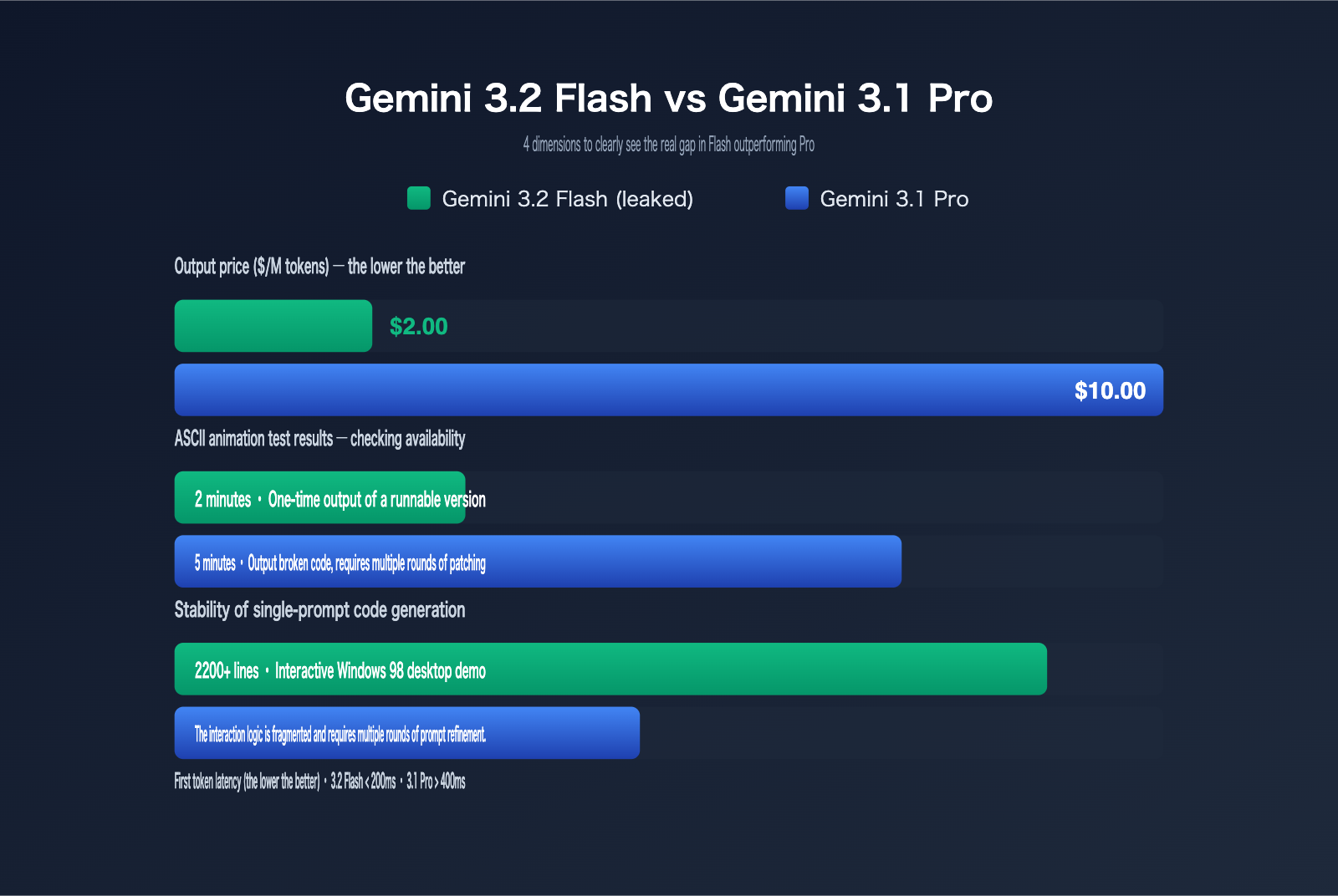
| Output Price | $2.00 / million tokens (33% lower than Gemini 3 Flash's $3.00) |
| Context Window | Expected 1M tokens (not officially confirmed) |
| Knowledge Cutoff | Estimated update to January 2026 |
| Latency | Some prompts under 200 ms |
| UI | "Liquid Glass" interface, pill-shaped input box |
| New Feature Signals | "Agents (Beta)" tab appeared in iOS |
The two most notable figures in this table are the output price, which has been slashed, and the performance target, which isn't the previous generation of Flash, but the 3.1 Pro. Together, these two factors determine the scale of the impact this will have on your developer tech stack.
🎯 Quick Validation Tip: Before the official API is opened, we recommend reserving your Gemini access slots on APIYI (apiyi.com). By standardizing your
base_url, you can switch between different Gemini versions simply by changing themodelfield. This will allow you to stress-test Gemini 3.2 Flash with your real-world business scenarios the very night of the I/O announcement.
Gemini 3.2 Flash Coding Capabilities: A Leap Forward
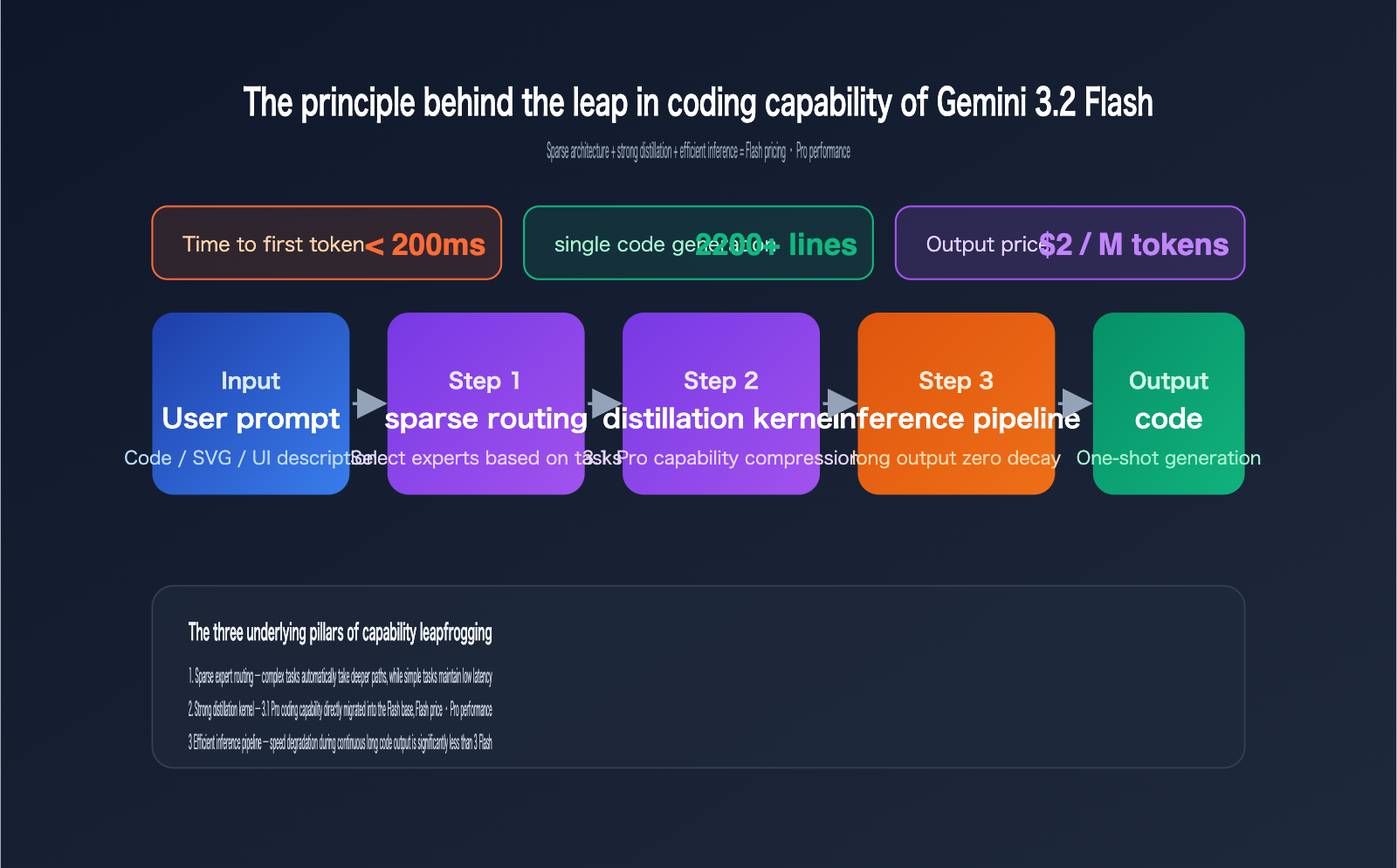
The most disruptive aspect of this leak, which has caught developers off guard, is the "punching above its weight" performance of the Flash-tier model in coding tasks. The overseas community has conducted extensive blind tests using AI Studio's Canvas mode, and the conclusions are remarkably consistent: in generative UI, complex SVG, and HTML Canvas scenarios, Gemini 3.2 Flash now consistently outperforms Gemini 3.1 Pro.
Gemini 3.2 Flash: Three Coding Scenarios Compared
The table below summarizes the three most cited comparative test results from the overseas community, all derived from anonymous LM Arena and public AI Studio samples.
| Test Task | Gemini 3 Flash | Gemini 3.1 Pro | Gemini 3.2 Flash |
|---|---|---|---|
| Full-screen HTML ASCII City Animation | Code failed to run | ~5 mins, produced broken code | ~2 mins, produced working version immediately |
| Single-prompt Windows 98 desktop demo | Only completed static shell | Fragmented logic, required multiple fixes | ~2200 lines of code in one go, interactive windows/menus |
| Complex Vector Illustration (SVG) | Messy paths, color misalignment | Visually acceptable, needed manual tweaks | Visually perfect, zero-error output |
These three tasks share a common requirement: the model must complete "structural planning + continuous long-code output" in a single inference pass—exactly the area where Flash-tier models previously struggled most. The stability of 3.2 Flash in these long-output scenarios suggests that its underlying architecture has been significantly strengthened in terms of long-context coherence and code syntax constraints.
Why Gemini 3.2 Flash "Punches Above Its Weight"
Judging by the technical breadcrumbs available, this leap isn't just about scaling up parameters; it's the result of combined engineering optimizations. Overseas analysis generally points to four key areas:
- More Aggressive AI Distillation: Directly distilling the capabilities of 3.1 Pro into the smaller, faster Flash foundation.
- Sparse Architecture Optimization: Finer-grained expert routing, meaning the model doesn't "deploy everyone" during long code generation.
- Improved Internal Routing System: Complex tasks automatically trigger deeper inference paths, while simple tasks maintain low latency.
- Efficient Inference Pipeline: First-token latency is consistently below 200 ms, with significantly less speed degradation during long outputs.
For developers, the most immediate takeaway is this: For writing React/Vue components, running SQL explanations, or generating executable visualization code, Flash can now be your default go-to over Pro. You should only switch back to Pro when you truly need heavy-duty reasoning or complex, multi-step planning.
🚀 Testing Tip: To verify the real-world coding capabilities of 3.2 Flash firsthand, we recommend accessing it via the APIYI (apiyi.com) platform using the OpenAI-compatible interface. We suggest preparing a "heavy-duty prompt" benchmark set (e.g., long HTML, complex SVG, full-page code refactoring) and using a consistent script to compare the output quality and stability of 3.2 Flash against 3.1 Pro.
Gemini 3.2 Flash Pricing Strategy and Cost Analysis
The Flash series has always been Google's go-to weapon for undercutting competitors, and Gemini 3.2 Flash pushes this to a new extreme. With an output price of $2.00 per million tokens, its per-request cost in common coding or long-form generation scenarios is approaching the "mini" level of GPT-5.5 Instant, all while delivering performance that nears the Pro tier.
Gemini 3.2 Flash vs. Gemini Series Pricing
The table below compares the pricing of the current Gemini series visible in AI Studio. All data points are sourced from public pages or leaked metadata, with Pro tier pricing based on standard Vertex AI rates.
| Model | Input ($/M) | Output ($/M) | Use Case |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | 0.25 | 1.50 | High-concurrency, low-cost batch tasks |
| Gemini 3 Flash | 0.50 | 3.00 | Standard chat / Mid-level coding |
| Gemini 3.2 Flash (Leaked) | 0.25 | 2.00 | Long code generation / Complex UI / SVG |
| Gemini 3.1 Pro | 1.25 | 10.00 | Complex reasoning / Multi-step planning |
As you can see, 3.2 Flash matches Flash-Lite on input pricing and slashes the output price of the 3 Flash by a full third, all while competing with the capabilities of the 3.1 Pro, which costs $10 per million output tokens. For the same 1 million tokens of complex code generation, using 3.2 Flash saves about 80% in costs compared to 3.1 Pro. All four models are available via a unified OpenAI-compatible interface on APIYI (apiyi.com), allowing you to dynamically distribute traffic within the same project without needing to re-integrate different SDKs for each tier.
Gemini 3.2 Flash Monthly Cost Estimation Example
To make these numbers more tangible, let's look at a real-world business scenario: Imagine you're building an AI coding assistant that handles 5,000 code generation requests per day, with an average of 1k input tokens and 3k output tokens per request.
| Model Choice | Daily Cost ($) | Monthly Cost ($) | Notes |
|---|---|---|---|
| Gemini 3.1 Pro | 156.25 | 4687.50 | Strong reasoning, but overkill for coding |
| Gemini 3 Flash | 47.50 | 1425.00 | Current mainstream solution |
| Gemini 3.2 Flash (Estimated) | 31.25 | 937.50 | Pro-level performance, lower costs |
💰 Cost Optimization Tip: For budget-sensitive projects, consider calling Gemini series APIs via the APIYI (apiyi.com) platform. It offers pay-as-you-go billing and a unified credit pool, making it perfect for small-to-medium teams to integrate quickly once 3.2 Flash officially launches, without the headache of managing multiple vendor billing systems.
Gemini 3.2 Flash: "Liquid Glass" Interface and Agents Signals
The model itself isn't the only surprise from this leak. Appearing alongside Gemini 3.2 Flash is a new interaction interface dubbed "Liquid Glass" by developers, as well as a hidden "Agents (Beta)" tab. These two elements reveal more about Google's overall strategy for I/O 2026 than the model itself.
Gemini 3.2 Flash Web Interface Highlights
"Liquid Glass" marks a major stylistic shift from the previous flat design, characterized by:
- Pill-shaped prompt input boxes with soft gradient highlights.
- Semi-transparent background layers that pulse with the conversation.
- The model selector has been moved to a dropdown in the top-left corner, emphasizing the "switch model" action.
- Chat bubbles use higher-contrast white space, with long code blocks expanded by default.
This interface puts "model switchability" in the most prominent visual position, essentially laying the groundwork for the matrix-style Gemini series—users are being trained to "choose the model based on the task," which aligns perfectly with the philosophy of multi-vendor aggregation platforms.
Gemini 3.2 Flash and the Agents (Beta) Strategy
What's even more noteworthy for developers is the unfinished "Agents (Beta)" tab that appeared in the Gemini iOS app. Combined with Google's consistent investment over the past year in Gemini CLI, Agent Builder, and Vertex AI Agent, it's reasonable to infer that I/O 2026 will feature a dedicated agentic track. Gemini 3.2 Flash is very likely positioned as the "default brain for Agents": fast enough to handle multi-step loops and cost-effective enough to support high token consumption.
🎯 Architectural Advice: If you're building your own agent framework, I recommend putting the Gemini series behind the same orchestration layer as Claude and GPT models on APIYI (apiyi.com) now. Once 3.2 Flash is officially released, you'll only need to toggle the
modelfield to verify if it outperforms your current solution as an "agent brain," ensuring you aren't locked into a single vendor.
Gemini 3.2 Flash Integration Example and Unified Interface
Although the official API for 3.2 Flash hasn't been released yet, its interface specifications are expected to be fully consistent with the Gemini 3.x series. Below is a minimalist example using the APIYI unified interface, designed so that you'll need almost zero changes when switching to 3.2 Flash in the future.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.2-flash", # Replace with the official model ID once it's officially released
messages=[
{"role": "user", "content": "Create an interactive Windows 98 desktop using a single-page HTML + Canvas"}
],
)
print(response.choices[0].message.content)
View full code with streaming output and error retries
from openai import OpenAI
from openai import APIError, RateLimitError
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
PROMPT = """Create an interactive Windows 98 desktop demo using a single-page HTML + Canvas.
Requirements: Draggable windows, a functional Start menu in the bottom-left corner, and desktop icons that open windows when double-clicked."""
def call_gemini_3_2_flash(prompt: str, retries: int = 3):
for attempt in range(retries):
try:
stream = client.chat.completions.create(
model="gemini-3.2-flash",
messages=[{"role": "user", "content": prompt}],
stream=True,
max_tokens=8192,
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
return
except RateLimitError:
time.sleep(2 ** attempt)
except APIError as e:
print(f"\n[API Error] {e}")
return
if __name__ == "__main__":
call_gemini_3_2_flash(PROMPT)
The key design of this code lies in the decoupling of base_url and model. To switch between Flash and Pro, you only need to change one line in the model field. Your business logic, error handling, and streaming logic remain fully reusable, making it perfect for A/B testing on the night of the I/O event.
Analysis of Gemini 3.2 Flash's Impact on Developers and the Industry
The reason this leak has sparked collective discussion among overseas developer communities isn't just because "another Flash model is out," but because it shatters the long-standing implicit consensus that "Flash is cheap but only for light tasks, while Pro is expensive but necessary for complex coding."
Impact on Independent Developers and Small Teams
For budget-conscious independent developers, 3.2 Flash is essentially a game-changer. Tasks that previously required Pro for stability—like "full-page code generation" or "complex visualization"—can now be handled by Flash, potentially reducing monthly model costs by 50%–80%.
For small and medium-sized teams, the impact is more evident in product design: features like AI programming assistants, low-code visualization platforms, and automated report generators—which were previously scaled back due to high Pro invocation costs—can now be redesigned as always-on, on-demand capabilities.
Impact on Large Teams and Multi-Model Architectures
For large teams that already have multi-model architectures, 3.2 Flash won't immediately replace Pro, but it will force model selection strategies to shift downward. The routing layer will need to dynamically choose between Flash and Pro based on the task type, rather than using a single model for everything. This places higher demands on model gateways, unified billing, and unified logging. Simplified gateways designed for single models will likely need an architectural upgrade after I/O.
Specifically, large teams should plan ahead on three levels: First, establish observable token metering to track Flash and Pro consumption separately. Second, decouple prompts from models by using a template system instead of hard-coding models. Third, prepare a canary release mechanism to migrate business modules gradually when 3.2 Flash is officially released, rather than switching all at once, to reduce production risks.
Impact on Competitors
OpenAI released GPT-5.5 Instant on the same day, focusing on "reducing hallucinations and strengthening factuality." This creates a direct contrast with Google's "price reduction + improved coding capability" strategy: OpenAI is betting on high-value vertical scenarios, while Google is betting on mass-market coding and agent scenarios. Anthropic has yet to respond directly to the leak, but the "coding capability premium" that the Claude series has maintained for so long will face price pressure from the Flash tier.
Gemini 3.2 Flash FAQ
Q1: When will the Gemini 3.2 Flash API be officially released?
Based on leaked information and Google's typical I/O release cadence, Gemini 3.2 Flash is highly likely to be officially announced during the I/O 2026 keynote on May 19–20, with access opening via Vertex AI and AI Studio that same day or the next. Third-party aggregation platforms usually complete integration within 24–48 hours. We recommend keeping an eye on the model update announcements at APIYI (apiyi.com) so you can start testing with a unified interface as soon as it drops.
Q2: Will Gemini 3.2 Flash replace Gemini 3.1 Pro?
Not entirely, at least not in the short term. While 3.2 Flash shows "leapfrog" performance in coding, long-form code generation, and tasks involving SVG/Canvas, the Pro model remains more stable for long-chain reasoning, complex multi-step planning, and financial or legal scenarios that require strict causal chains. A smart strategy is to route by task: use 3.2 Flash for coding and UI, and stick to 3.1 Pro for deep reasoning and high-stakes decisions. You can handle this model distribution at the gateway layer using the same codebase, so there's no need to rewrite your business logic.
Q3: Is the claim about Gemini 3.2 Flash generating 2,200 lines of code true?
The "2,200-line Windows 98 desktop demo" circulating in overseas developer communities comes from real-world tests using the AI Studio Canvas mode. What we can independently verify is that 3.2 Flash's stability in generating ultra-long, functional code within a single prompt is significantly better than both 3 Flash and 3.1 Pro. While full replication requires the official API release, the "long-output stability" upgrade has been confirmed by multiple independent testers.
Q4: What is the context window for Gemini 3.2 Flash?
There isn't a direct figure in the leaked metadata, but based on the specs of the Gemini 3.x series, it's highly likely that 3.2 Flash will maintain a 1M token context window. This is crucial for handling large code repositories, entire documents, and video transcripts, and it serves as the physical foundation for its ability to stably output 2,000+ lines of code.
Q5: How can developers in China access Gemini 3.2 Flash as quickly as possible?
Once it's officially live, the most reliable way for developers in China to access it is through an aggregation platform that is accessible domestically. We recommend using APIYI (apiyi.com) to access Gemini 3.2 Flash. The platform uses an OpenAI-compatible interface, allowing for seamless integration with your existing code. You only need to update the base_url and model fields to call Gemini, Claude, GPT, and other models within the same project, making it easy to perform horizontal evaluations and switch between them.
Summary: What the Early Exposure of Gemini 3.2 Flash Means
To circle back to the point that "the conference hasn't even started, but Google can't keep it hidden anymore": since the silent launch of AI Studio on May 5th, Gemini 3.2 Flash has been thoroughly dissected by the overseas community—from its model ID and Liquid Glass UI to its Agents tags and the 2,200-line code demo. This isn't just a product leak; it signals three clear trends:
- Flash-tier models have officially leveled up: Google is redefining model tiers by combining "low cost" with "high coding capability."
- The Agents strategy is emerging: 3.2 Flash is highly likely to become the default foundation for agentic applications.
- The value of multi-model aggregation is amplified: Whoever can integrate and evaluate models the fastest will capture the early-mover advantage.
For developers, the goal isn't to gamble on the specific details of the I/O announcement, but to prepare your engineering infrastructure for unified integration, evaluation, and billing so you can start stress-testing the moment 3.2 Flash is officially released. We recommend using APIYI (apiyi.com) to quickly verify performance, allowing you to gather real data for your specific business scenarios on the very night the I/O keynote concludes, rather than waiting for community benchmarks.
Author: APIYI Technical Team — Focused on AI Large Language Model API engineering. For more data on the cost and performance of Gemini, Claude, and GPT series models in real-world business scenarios, visit APIYI (apiyi.com) for the latest evaluation reports and free testing credits.