Tinggal satu hari lagi menuju pidato utama Google I/O 2026, namun Google sudah tidak bisa lagi menyembunyikan rahasianya. Gemini 3.2 Flash ditemukan oleh pengembang pada 5 Mei lalu melalui aplikasi iOS Gemini dan Google AI Studio, bersamaan dengan bocornya antarmuka "Liquid Glass" yang akan hadir di versi web. Skenario paling mencengangkan yang ditemukan oleh penguji luar negeri meliputi: kemampuan menghasilkan 2.200 baris kode siap pakai dalam satu kali prompt, membuat demo desktop Windows 98 yang interaktif hanya dengan satu instruksi, dan dalam berbagai tugas pemrograman, model ini bahkan mengungguli model unggulan mereka sendiri, Gemini 3.1 Pro.
Artikel ini disusun berdasarkan sumber informasi bahasa Inggris hingga 18 Mei 2026, merangkum intelijen kunci dari kebocoran ini melalui lima dimensi: spesifikasi inti, kemampuan pemrograman, strategi harga, sinyal antarmuka dan agentic, serta dampaknya bagi pengembang, sekaligus memberikan saran evaluasi migrasi.
Nilai Inti: Pahami kekuatan nyata, efisiensi harga, dan apakah Anda perlu menyiapkan rencana teknis untuk Gemini 3.2 Flash sebelum peluncurannya di I/O dalam 3 menit.

Sekilas Informasi Inti Gemini 3.2 Flash
Sebelum Google merilis blog resmi, versi bocoran ini sudah diuji secara menyeluruh oleh para pengembang. Tabel di bawah merangkum fakta-fakta kunci yang dapat diverifikasi hingga 18 Mei 2026, yang akan dibahas lebih mendalam di bagian selanjutnya.
| Item Informasi | Detail |
|---|---|
| Waktu Penemuan Kebocoran | 5 Mei 2026, muncul dalam pengujian A/B aplikasi iOS Gemini + Google AI Studio |
| Perkiraan Peluncuran Resmi | Google I/O 2026, pidato utama 19–20 Mei |
| Pemosisian Model | Tingkat menengah seri Flash, menargetkan kemampuan pemrograman Gemini 3.1 Pro |
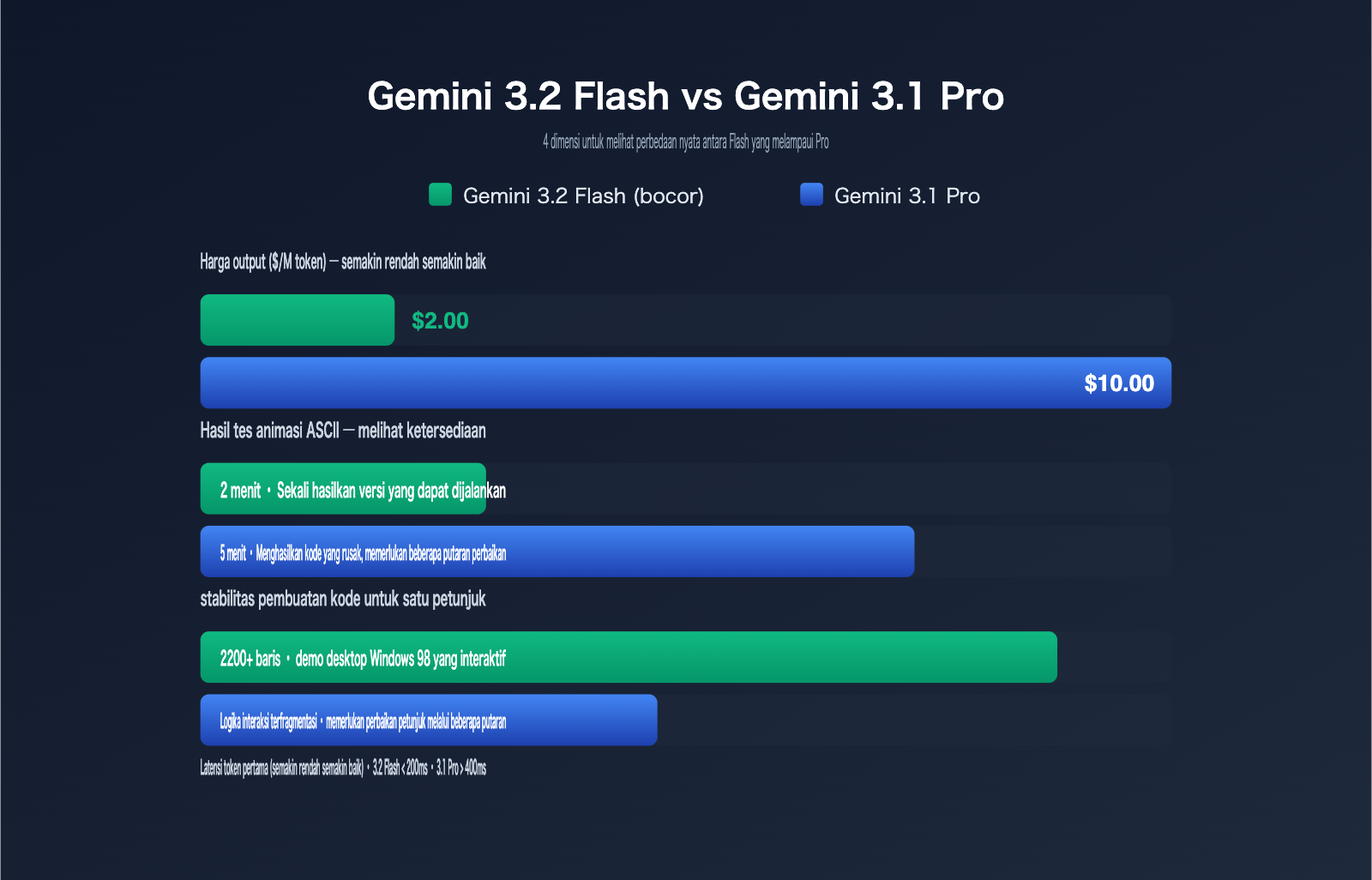
| Harga Input | $0,25 / juta token (setara dengan Gemini 3.1 Flash-Lite) |
| Harga Output | $2,00 / juta token (turun 33% dari $3,00 pada Gemini 3 Flash) |
| Jendela Konteks | Diperkirakan 1M token (belum dikonfirmasi resmi) |
| Batas Pengetahuan | Diperkirakan diperbarui hingga Januari 2026 |
| Latensi Respons | Beberapa petunjuk di bawah 200 ms |
| UI Pendukung | Antarmuka "Liquid Glass", kotak input berbentuk pil |
| Sinyal Fitur Baru | Tab "Agents (Beta)" muncul di iOS |
Dua angka yang paling patut diperhatikan dalam tabel ini: pertama, harga output yang dipangkas drastis, dan kedua, target performa yang bukan ditujukan untuk seri Flash sebelumnya, melainkan seri 3.1 Pro. Kedua poin ini menentukan besarnya dampak model ini terhadap tumpukan teknologi pengembang.
🎯 Saran Verifikasi Cepat: Sebelum API resmi dibuka, disarankan untuk memesan slot akses seri Gemini di APIYI (apiyi.com). Dengan menyamakan
base_url, Anda hanya perlu mengubah kolommodeluntuk beralih antar versi Gemini. Dengan begitu, Anda bisa melakukan stress test pada 3.2 Flash menggunakan skenario bisnis nyata tepat di malam peluncuran I/O.
Uji Coba Kemampuan Coding Gemini 3.2 Flash yang Melampaui Ekspektasi
Bagian yang paling mengejutkan bagi para pengembang dari bocoran kali ini adalah performa model kelas Flash dalam tugas pengkodean yang "melampaui kelasnya". Komunitas global telah melakukan banyak pengujian buta (blind test) menggunakan mode Canvas di AI Studio, dan kesimpulannya sangat konsisten: dalam tiga skenario yaitu UI generatif, SVG kompleks, dan HTML Canvas, Gemini 3.2 Flash kini mampu mengungguli Gemini 3.1 Pro secara stabil.
Perbandingan Tiga Skenario Coding Gemini 3.2 Flash
Tabel di bawah ini merangkum tiga hasil uji perbandingan yang paling sering dikutip oleh komunitas global, di mana semua hasil berasal dari sampel publik LM Arena dan AI Studio yang anonim.
| Tugas Pengujian | Gemini 3 Flash | Gemini 3.1 Pro | Gemini 3.2 Flash |
|---|---|---|---|
| Animasi kota ASCII HTML layar penuh | Kode tidak bisa dijalankan | Sekitar 5 menit, kode rusak | Sekitar 2 menit, langsung bisa dijalankan |
| Demo desktop Windows 98 (satu prompt) | Hanya membuat kerangka statis | Logika interaktif berantakan, butuh banyak perbaikan | Sekitar 2200 baris kode sekali jadi, jendela & menu interaktif |
| Ilustrasi vektor SVG kompleks | Jalur berantakan, warna meleset | Visual oke, butuh penyesuaian manual | Visual oke dan output sekali jadi tanpa error |
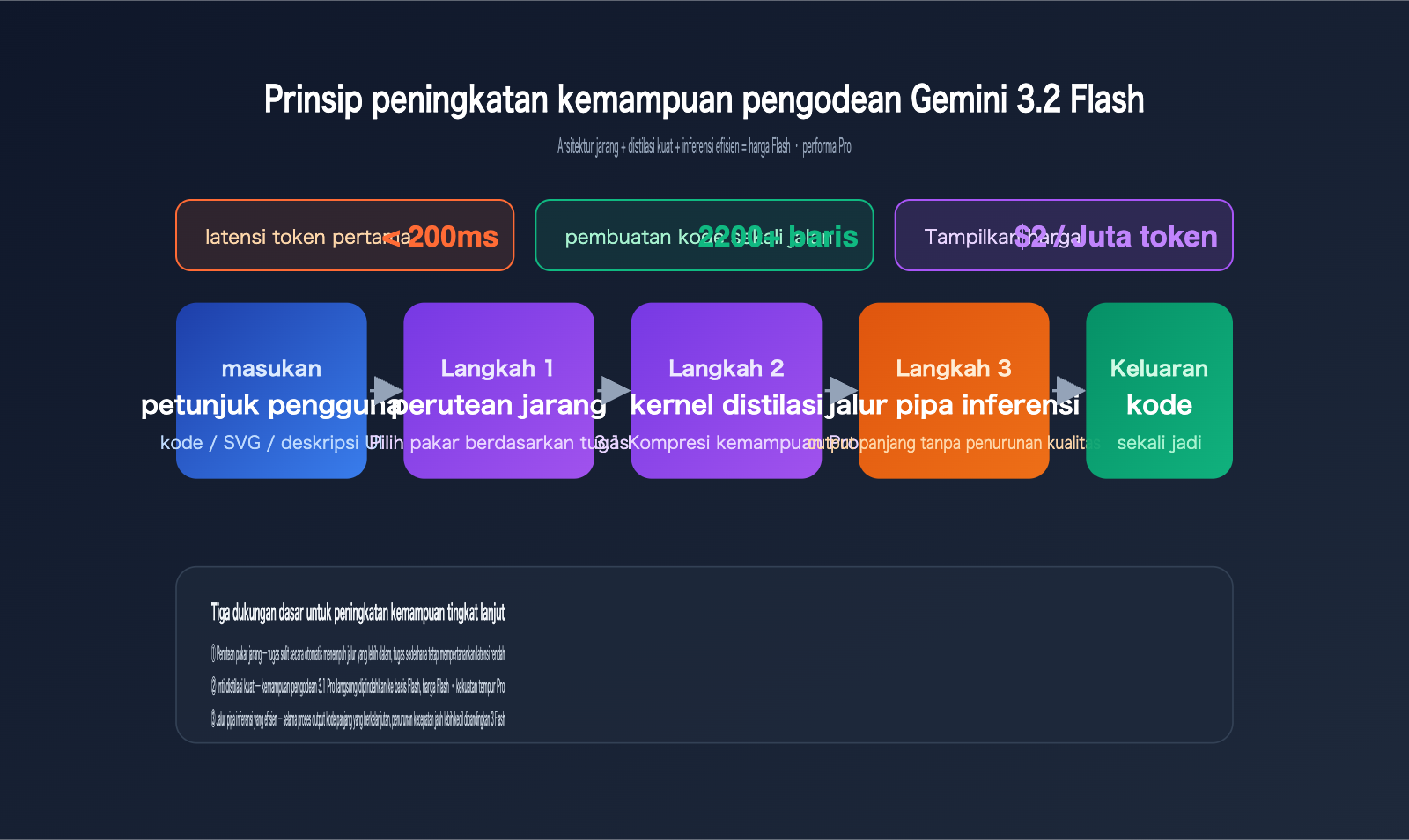
Ketiga tugas ini memiliki satu kesamaan: semuanya memerlukan model untuk menyelesaikan "perencanaan struktur + output kode panjang" dalam satu kali inferensi. Inilah kemampuan yang dulunya paling sering gagal dilakukan oleh model kelas Flash. Stabilitas 3.2 Flash dalam skenario output panjang menunjukkan bahwa fondasi model ini telah diperkuat secara signifikan dalam hal koherensi konteks panjang dan batasan sintaksis kode.
Mengapa Gemini 3.2 Flash Bisa "Melampaui Kelasnya"?
Dilihat dari jejak teknis yang dipublikasikan, lompatan ini bukanlah hasil dari penumpukan parameter, melainkan kombinasi dari optimalisasi teknik. Analisis global umumnya mengarah pada empat poin:
- Distilasi AI yang lebih agresif: Kemampuan 3.1 Pro langsung didistilasi ke dalam basis Flash yang lebih kecil dan cepat.
- Optimalisasi arsitektur jarang (sparse): Perutean pakar (expert routing) yang lebih presisi, sehingga tidak semua bagian model harus "bekerja" saat menghasilkan kode panjang.
- Sistem perutean internal yang ditingkatkan: Tugas sulit secara otomatis menempuh jalur inferensi yang lebih dalam, sementara tugas sederhana tetap mempertahankan latensi rendah.
- Jalur pipa inferensi efisien: Latensi token pertama stabil di bawah 200 ms, dengan penurunan kecepatan yang lebih kecil selama proses output panjang.
Bagi pengembang, pengalaman langsungnya adalah: Untuk menulis komponen React/Vue, menjalankan interpretasi SQL, atau membuat kode visualisasi yang bisa dijalankan, Flash kini bisa menjadi pilihan utama menggantikan Pro, dan hanya kembali menggunakan Pro saat benar-benar membutuhkan penalaran berat atau perencanaan multi-langkah yang kompleks.
🚀 Saran Pengujian: Jika ingin memverifikasi kemampuan coding asli 3.2 Flash secara langsung, disarankan untuk mengaksesnya melalui platform APIYI (apiyi.com) menggunakan antarmuka yang kompatibel dengan OpenAI. Kami menyarankan untuk menyiapkan sekumpulan benchmark "prompt berat" (seperti HTML panjang, SVG kompleks, atau penulisan ulang kode satu halaman penuh), lalu gunakan skrip yang sama untuk membandingkan kualitas dan stabilitas output antara 3.2 Flash dan 3.1 Pro.
Strategi Harga dan Estimasi Biaya Gemini 3.2 Flash
Seri Flash selalu menjadi senjata utama Google untuk menekan harga guna melawan kompetitor, dan Gemini 3.2 Flash membawa strategi ini ke level yang lebih ekstrem. Harga output sebesar $2,00 per juta token berarti, dalam skenario umum seperti pengodean atau pembuatan teks panjang, biaya per unitnya sudah mendekati level mini dari GPT-5.5 Instant, namun dengan kemampuan yang mendekati versi Pro.
Perbandingan Harga Gemini 3.2 Flash dengan Seri Gemini Lainnya
Tabel di bawah ini menyajikan perbandingan harga seri Gemini yang saat ini terlihat di AI Studio. Semua data didasarkan pada halaman publik atau metadata yang bocor, dengan harga tier Pro mengacu pada standar harga Vertex AI.
| Model | Input ($/Juta) | Output ($/Juta) | Skenario Penggunaan |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | 0,25 | 1,50 | Konkurensi tinggi, tugas batch berbiaya rendah |
| Gemini 3 Flash | 0,50 | 3,00 | Chat standar / Kode menengah |
| Gemini 3.2 Flash (Bocor) | 0,25 | 2,00 | Pembuatan kode panjang / UI kompleks / SVG |
| Gemini 3.1 Pro | 1,25 | 10,00 | Penalaran kompleks / Perencanaan multi-langkah |
Dapat dilihat bahwa harga input 3.2 Flash setara dengan Flash-Lite, sementara harga outputnya dipangkas sepertiga dari 3 Flash, padahal kemampuannya menandingi 3.1 Pro yang dihargai 10 dolar per juta output. Untuk tugas kode kompleks dengan output 1 juta token, menggunakan 3.2 Flash menghemat biaya sekitar 80% dibandingkan menggunakan 3.1 Pro. Keempat model di atas semuanya tersedia di APIYI (apiyi.com) melalui antarmuka yang kompatibel dengan OpenAI, sehingga Anda dapat mendistribusikan trafik bisnis secara dinamis dalam satu proyek tanpa perlu melakukan integrasi SDK berulang untuk tier yang berbeda.
Contoh Estimasi Biaya Bulanan Gemini 3.2 Flash
Agar angka-angka ini lebih mudah dipahami, mari kita buat estimasi berdasarkan skenario bisnis nyata: Anda sedang membangun alat bantu pemrograman AI yang menangani 5.000 permintaan pembuatan kode per hari, dengan rata-rata input 1k token dan output 3k token.
| Model yang Dipilih | Biaya Harian (USD) | Biaya Bulanan (USD) | Catatan |
|---|---|---|---|
| Gemini 3.1 Pro | 156,25 | 4687,50 | Penalaran kuat, tapi berlebihan untuk skenario kode |
| Gemini 3 Flash | 47,50 | 1425,00 | Solusi utama saat ini |
| Gemini 3.2 Flash (Estimasi) | 31,25 | 937,50 | Performa mendekati Pro, biaya lebih rendah |
💰 Tips Optimasi Biaya: Untuk proyek yang sensitif terhadap anggaran, pertimbangkan untuk memanggil API seri Gemini melalui platform APIYI (apiyi.com). Platform ini menyediakan sistem bayar sesuai pemakaian (pay-as-you-go) dan kumpulan kuota terpadu, yang sangat cocok bagi tim kecil dan menengah untuk segera terhubung setelah 3.2 Flash resmi dirilis, tanpa perlu mengelola sistem penagihan dari banyak vendor.
Antarmuka Liquid Glass dan Sinyal Agen pada Gemini 3.2 Flash
Model itu sendiri bukanlah satu-satunya kejutan dari kebocoran ini. Bersamaan dengan Gemini 3.2 Flash, muncul pula antarmuka interaksi baru yang diberi nama "Liquid Glass" oleh para pengembang, serta tab "Agents (Beta)" yang tersembunyi. Kedua hal ini lebih mengungkapkan arah strategi Google untuk I/O 2026 dibandingkan model itu sendiri.
Poin Utama Antarmuka Web Gemini 3.2 Flash
"Liquid Glass" merupakan perubahan gaya yang signifikan dibandingkan desain datar sebelumnya, yang diwujudkan dalam:
- Kotak input petunjuk berbentuk pil dengan sorotan gradien yang lembut
- Lapisan latar belakang semi-transparan yang berdenyut mengikuti percakapan
- Pemilih model dipindahkan ke menu drop-down di kiri atas, menonjolkan tindakan "ganti model"
- Gelembung percakapan menggunakan ruang putih dengan kontras lebih tinggi, dan blok kode panjang diperluas secara default
Antarmuka ini menempatkan "kemampuan untuk mengganti model" di posisi visual yang paling mencolok, yang pada dasarnya menyiapkan panggung untuk matriks model seri Gemini—pengguna secara default dididik untuk "memilih model berdasarkan tugas", yang sangat selaras dengan filosofi platform agregasi multi-vendor.
Strategi Agen yang Disiratkan oleh Gemini 3.2 Flash dan Agents (Beta)
Yang lebih menarik bagi pengembang adalah tab "Agents (Beta)" yang belum selesai di aplikasi Gemini iOS. Mengingat investasi Google selama setahun terakhir pada Gemini CLI, Agent Builder, dan Vertex AI Agent, dapat disimpulkan bahwa I/O 2026 akan memiliki alur strategis agen yang independen, di mana Gemini 3.2 Flash kemungkinan besar akan diposisikan sebagai "otak default untuk Agen": cukup cepat untuk mendukung siklus multi-langkah dan cukup hemat biaya untuk menangani konsumsi token yang tinggi.
🎯 Saran Arsitektur: Jika Anda sedang mengembangkan kerangka kerja agen sendiri, disarankan untuk menempatkan seri Gemini di belakang lapisan penjadwalan yang sama dengan model Claude atau GPT melalui APIYI (apiyi.com). Setelah 3.2 Flash resmi dibuka, Anda hanya perlu mengganti kolom model untuk memverifikasi apakah ia lebih unggul sebagai "otak agen" dibandingkan solusi yang ada saat ini, sehingga Anda tidak terjebak pada satu vendor saja.
Contoh Integrasi dan Antarmuka Terpadu Gemini 3.2 Flash
Meskipun API resmi untuk 3.2 Flash belum dirilis secara publik, spesifikasi antarmukanya diperkirakan akan sepenuhnya konsisten dengan seri Gemini 3.x. Berikut adalah contoh minimalis menggunakan antarmuka terpadu APIYI, yang memungkinkan Anda beralih ke 3.2 Flash di masa mendatang tanpa perlu banyak mengubah kode.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.2-flash", # Ganti dengan ID model resmi setelah dirilis
messages=[
{"role": "user", "content": "Buat demo desktop Windows 98 interaktif menggunakan satu file HTML + Canvas"}
],
)
print(response.choices[0].message.content)
Lihat kode lengkap dengan streaming output dan percobaan ulang (retry) saat error
from openai import OpenAI
from openai import APIError, RateLimitError
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
PROMPT = """Buat demo desktop Windows 98 interaktif menggunakan satu file HTML + Canvas,
persyaratan: jendela bisa digeser (drag), menu start di kiri bawah bisa muncul, dan ikon desktop bisa dibuka dengan klik ganda."""
def call_gemini_3_2_flash(prompt: str, retries: int = 3):
for attempt in range(retries):
try:
stream = client.chat.completions.create(
model="gemini-3.2-flash",
messages=[{"role": "user", "content": prompt}],
stream=True,
max_tokens=8192,
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
return
except RateLimitError:
time.sleep(2 ** attempt)
except APIError as e:
print(f"\n[Error API] {e}")
return
if __name__ == "__main__":
call_gemini_3_2_flash(PROMPT)
Desain kunci dari kode ini terletak pada pemisahan antara base_url dan model: untuk beralih antara Flash dan Pro, Anda hanya perlu mengubah satu baris pada kolom model. Kode bisnis, penanganan error, dan logika streaming semuanya dapat digunakan kembali, sangat cocok untuk evaluasi A/B setelah peluncuran.
Analisis Dampak Gemini 3.2 Flash bagi Pengembang dan Industri
Alasan utama mengapa kebocoran ini memicu diskusi di komunitas pengembang global bukan karena "munculnya Flash baru", melainkan karena model ini mendobrak asumsi lama bahwa "Flash murah tapi hanya untuk tugas ringan, Pro mahal tapi untuk kode kompleks".
Dampak bagi Pengembang Independen dan Tim Kecil
Bagi pengembang independen yang sensitif terhadap anggaran, 3.2 Flash adalah perubahan besar. Tugas yang sebelumnya memerlukan model Pro agar stabil—seperti "pembuatan kode satu halaman penuh" atau "visualisasi kompleks"—kini bisa diselesaikan dengan Flash, yang berpotensi menurunkan biaya model bulanan sebesar 50%–80%.
Bagi tim kecil, dampaknya lebih terasa pada bentuk produk: fitur yang dulunya ditekan karena biaya pemanggilan Pro yang tinggi, seperti asisten pemrograman AI, platform visualisasi low-code, atau generator laporan otomatis, kini bisa didesain ulang menjadi kemampuan permanen yang aktif secara default.
Dampak bagi Tim Besar dan Arsitektur Multi-Model
Bagi tim besar yang sudah memiliki arsitektur multi-model, 3.2 Flash tidak akan langsung menggantikan posisi Pro, tetapi akan memaksa strategi pemilihan model untuk diturunkan ke lapisan yang lebih dalam: lapisan perutean (routing) kini harus memilih antara Flash atau Pro secara dinamis berdasarkan jenis tugas, bukan lagi menggunakan satu model untuk segalanya. Hal ini menuntut standar yang lebih tinggi untuk gateway model, penagihan terpadu, dan pencatatan log.
Secara spesifik, tim besar harus bersiap di tiga level: Pertama, membangun metrik token yang dapat diamati untuk memisahkan konsumsi nyata antara Flash dan Pro; Kedua, melakukan pemisahan antara petunjuk (prompt) dan model melalui sistem template; Ketiga, menyiapkan mekanisme peralihan bertahap (canary deployment) agar saat 3.2 Flash resmi dibuka, migrasi bisa dilakukan per modul bisnis untuk mengurangi risiko operasional.
Dampak bagi Kompetitor
OpenAI merilis GPT-5.5 Instant di hari yang sama, dengan fokus pada "pengurangan halusinasi dan penguatan faktualitas". Ini membentuk posisi yang berlawanan dengan strategi Google yang "menekan harga + meningkatkan kemampuan coding": OpenAI bertaruh pada skenario vertikal bernilai tinggi, sementara Google bertaruh pada skenario coding dan agen yang massal. Anthropic belum memberikan tanggapan langsung, namun "premi kemampuan coding" yang selama ini dipertahankan oleh seri Claude akan menghadapi tekanan harga dari kelas Flash.
Pertanyaan Umum Gemini 3.2 Flash
Q1: Kapan API Gemini 3.2 Flash akan resmi dibuka?
Berdasarkan petunjuk yang bocor dan ritme rilis Google I/O sebelumnya, Gemini 3.2 Flash kemungkinan besar akan diumumkan secara resmi pada pidato utama I/O 2026 tanggal 19–20 Mei, dan dibuka melalui Vertex AI serta AI Studio pada hari yang sama atau keesokan harinya. Platform agregator pihak ketiga biasanya akan menyelesaikan integrasi dalam waktu 24–48 jam. Disarankan untuk memantau pengumuman model baru di APIYI apiyi.com agar Anda dapat melakukan pengujian menggunakan antarmuka terpadu sesegera mungkin.
Q2: Apakah Gemini 3.2 Flash akan menggantikan Gemini 3.1 Pro?
Dalam jangka pendek, tidak akan sepenuhnya menggantikan. 3.2 Flash memiliki performa yang melampaui ekspektasi dalam tugas pengkodean, pembuatan kode panjang, serta SVG / Canvas. Namun, untuk penalaran rantai panjang, perencanaan multi-langkah yang kompleks, dan skenario keuangan/hukum yang memerlukan rantai kausalitas ketat, versi Pro tetap lebih stabil. Strategi yang masuk akal adalah perutean berdasarkan tugas: gunakan 3.2 Flash untuk pengkodean dan UI, sementara penalaran mendalam dan pengambilan keputusan berisiko tinggi tetap menggunakan 3.1 Pro. Anda cukup menggunakan kode yang sama di lapisan gateway untuk distribusi model tanpa perlu menulis ulang logika bisnis.
Q3: Apakah benar Gemini 3.2 Flash bisa menghasilkan 2200 baris kode?
"Demo desktop Windows 98 sepanjang 2200 baris" yang beredar di komunitas pengembang luar negeri berasal dari sampel pengujian mode AI Studio Canvas. Fakta yang dapat diverifikasi secara independen saat ini adalah: stabilitas 3.2 Flash dalam menghasilkan kode panjang yang dapat dijalankan dalam satu prompt memang jauh lebih unggul dibandingkan 3 Flash dan 3.1 Pro. Reproduksi penuh perlu menunggu API resmi dibuka, namun kemampuan "stabilitas output panjang" ini telah berulang kali dikonfirmasi oleh banyak penguji independen.
Q4: Berapa jendela konteks Gemini 3.2 Flash?
Dalam metadata yang bocor tidak disebutkan angka jendela konteks secara langsung, tetapi berdasarkan spesifikasi seri Gemini 3.x, kemungkinan besar 3.2 Flash tetap mempertahankan jendela konteks 1M tokens. Hal ini sangat penting untuk pemrosesan repositori kode panjang, dokumen lengkap, dan transkrip video, yang juga menjadi fondasi fisik kemampuannya dalam menghasilkan 2000+ baris kode secara stabil.
Q5: Bagaimana cara tercepat bagi pengembang di Indonesia untuk mengakses Gemini 3.2 Flash?
Setelah resmi diluncurkan, jalur akses paling stabil bagi pengembang di Indonesia adalah melalui platform agregator yang dapat diakses secara lokal. Disarankan untuk menggunakan APIYI apiyi.com untuk mengakses Gemini 3.2 Flash. Platform ini menggunakan antarmuka yang kompatibel dengan OpenAI, sehingga dapat digunakan kembali dengan kode yang ada. Anda hanya perlu mengubah kolom base_url dan model, lalu Anda bisa memanggil berbagai model seperti Gemini, Claude, dan GPT dalam satu rangkaian proyek yang sama, sehingga memudahkan evaluasi dan perpindahan model.
Kesimpulan: Apa Arti dari Kebocoran Awal Gemini 3.2 Flash
Kembali ke pernyataan di awal, "konferensi belum dimulai, tapi Google tidak bisa lagi menyembunyikannya." Sejak peluncuran diam-diam di AI Studio pada 5 Mei hingga hari ini, Gemini 3.2 Flash telah dibedah habis-habisan oleh komunitas luar negeri, mulai dari ID model, UI Liquid Glass, label Agen, hingga demo 2200 baris kode. Ini bukan sekadar insiden kebocoran produk, melainkan memberikan tiga sinyal yang jelas:
- Level Flash resmi naik kelas, Google sedang membentuk ulang klasifikasi model dengan "harga murah + kemampuan pengkodean tinggi".
- Strategi Agen mulai muncul ke permukaan, 3.2 Flash kemungkinan besar akan menjadi basis default untuk aplikasi berbasis agen (agentic).
- Nilai agregasi multi-model semakin meningkat, siapa yang bisa mengakses dan mengevaluasi lebih cepat, dialah yang akan mendapatkan keuntungan lebih awal.
Bagi pengembang, yang perlu dilakukan bukanlah menebak detail rilis pada hari I/O, melainkan mempersiapkan infrastruktur teknik untuk akses terpadu, evaluasi terpadu, dan penagihan terpadu, agar bisa segera melakukan pengujian beban (stress test) saat 3.2 Flash resmi dibuka. Disarankan untuk memverifikasi hasilnya dengan cepat melalui APIYI apiyi.com, sehingga pada malam setelah pidato utama I/O berakhir, Anda sudah memiliki data nyata untuk skenario bisnis Anda sendiri, alih-alih menunggu hasil benchmark dari komunitas.
Penulis: Tim Teknis APIYI — Fokus pada praktik rekayasa API Model Bahasa Besar AI. Jika Anda ingin mengetahui lebih lanjut tentang data biaya dan performa seri Gemini, Claude, dan GPT dalam skenario bisnis nyata, silakan kunjungi APIYI apiyi.com untuk mendapatkan laporan evaluasi terbaru dan kuota pengujian gratis.