Nur noch einen Tag bis zur Keynote der Google I/O 2026, doch Google kann das Geheimnis nicht mehr bewahren. Gemini 3.2 Flash wurde am 5. Mai von Entwicklern aus der iOS Gemini App und dem Google AI Studio extrahiert, und auch die dazugehörige „Liquid Glass“-Oberfläche für Webbrowser ist bereits vorab durchgesickert. Zu den beeindruckendsten Szenarien, die von Testern im Ausland dokumentiert wurden, gehören: die Generierung von 2200 Zeilen ausführbarem Code mit einer einzigen Eingabeaufforderung, die Erstellung einer interaktiven Windows 98-Desktop-Demo durch eine kurze Eingabeaufforderung sowie eine Performance bei Programmieraufgaben, bei der das Modell das bisherige Flaggschiff Gemini 3.1 Pro regelrecht in den Schatten stellt.
Dieser Artikel basiert auf englischsprachigen Quellen vor dem 18. Mai 2026 und analysiert die geleakten Informationen systematisch anhand von fünf Dimensionen: Kernspezifikationen, Programmierfähigkeiten, Preisstrategie, Benutzeroberfläche/Agenten-Signale sowie Auswirkungen auf Entwickler. Zudem geben wir Empfehlungen für eine mögliche Migration.
Kernnutzen: Erfahren Sie in 3 Minuten alles über die tatsächliche Leistungsfähigkeit und die preisliche Disruption von Gemini 3.2 Flash und ob Sie vor der I/O-Veröffentlichung bereits technische Vorkehrungen treffen sollten.

Kurzüberblick: Die wichtigsten Fakten zu Gemini 3.2 Flash
Noch bevor Google einen offiziellen Blogbeitrag veröffentlicht hat, wurde die geleakte Version bereits von Entwicklern umfassend getestet. Die folgende Tabelle fasst alle bis zum 18. Mai 2026 kreuzvalidierten Fakten zusammen; Details folgen in den nächsten Abschnitten.
| Informationspunkt | Details |
|---|---|
| Zeitpunkt des Leaks | 5. Mai 2026, aufgetaucht in der iOS Gemini App + A/B-Tests im Google AI Studio |
| Erwartete Veröffentlichung | Google I/O 2026, Keynote am 19.–20. Mai |
| Modellpositionierung | Mittlere Leistungsklasse der Flash-Serie, zielt auf die Programmierfähigkeiten von Gemini 3.1 Pro ab |
| Eingabepreis | $0,25 / Million Tokens (gleichauf mit Gemini 3.1 Flash-Lite) |
| Ausgabepreis | $2,00 / Million Tokens (33 % günstiger als die $3,00 von Gemini 3 Flash) |
| Kontextfenster | Voraussichtlich 1M Tokens (nicht offiziell bestätigt) |
| Wissensstand | Vermutlich aktualisiert bis Januar 2026 |
| Antwortlatenz | Teilweise unter 200 ms |
| UI-Design | „Liquid Glass“-Oberfläche, pillenförmiges Eingabefeld |
| Neue Funktionen | „Agents (Beta)“-Tab in der iOS-App gesichtet |
Die zwei bemerkenswertesten Zahlen in dieser Tabelle: Erstens die deutliche Senkung des Ausgabepreises und zweitens die Tatsache, dass das Modell nicht die vorherige Flash-Generation, sondern das 3.1 Pro-Modell ins Visier nimmt. Diese beiden Faktoren bestimmen maßgeblich, wie stark das Modell den Technologie-Stack von Entwicklern beeinflussen wird.
🎯 Empfehlung für schnelle Tests: Bevor die offizielle API freigeschaltet wird, empfiehlt es sich, bei APIYI (apiyi.com) bereits einen Platz für die Gemini-Serie zu reservieren. Nach der Vereinheitlichung der
base_urlmüssen Sie für den Wechsel zwischen verschiedenen Gemini-Versionen nur dasmodel-Feld anpassen. So können Sie direkt am Abend der I/O-Konferenz die Leistung von 3.2 Flash mit Ihren realen Anwendungsszenarien testen.
Gemini 3.2 Flash: Überraschende Leistung bei Programmieraufgaben
Das wohl überraschendste Ergebnis für Entwickler bei diesem Leak ist die „überdurchschnittliche“ Leistung des Flash-Modells bei Programmieraufgaben. Die internationale Community hat im Canvas-Modus von AI Studio umfangreiche Blindtests durchgeführt, und das Fazit ist eindeutig: Bei generativen Benutzeroberflächen, komplexen SVGs und HTML-Canvas-Anwendungen kann Gemini 3.2 Flash das Modell Gemini 3.1 Pro mittlerweile stabil übertreffen.
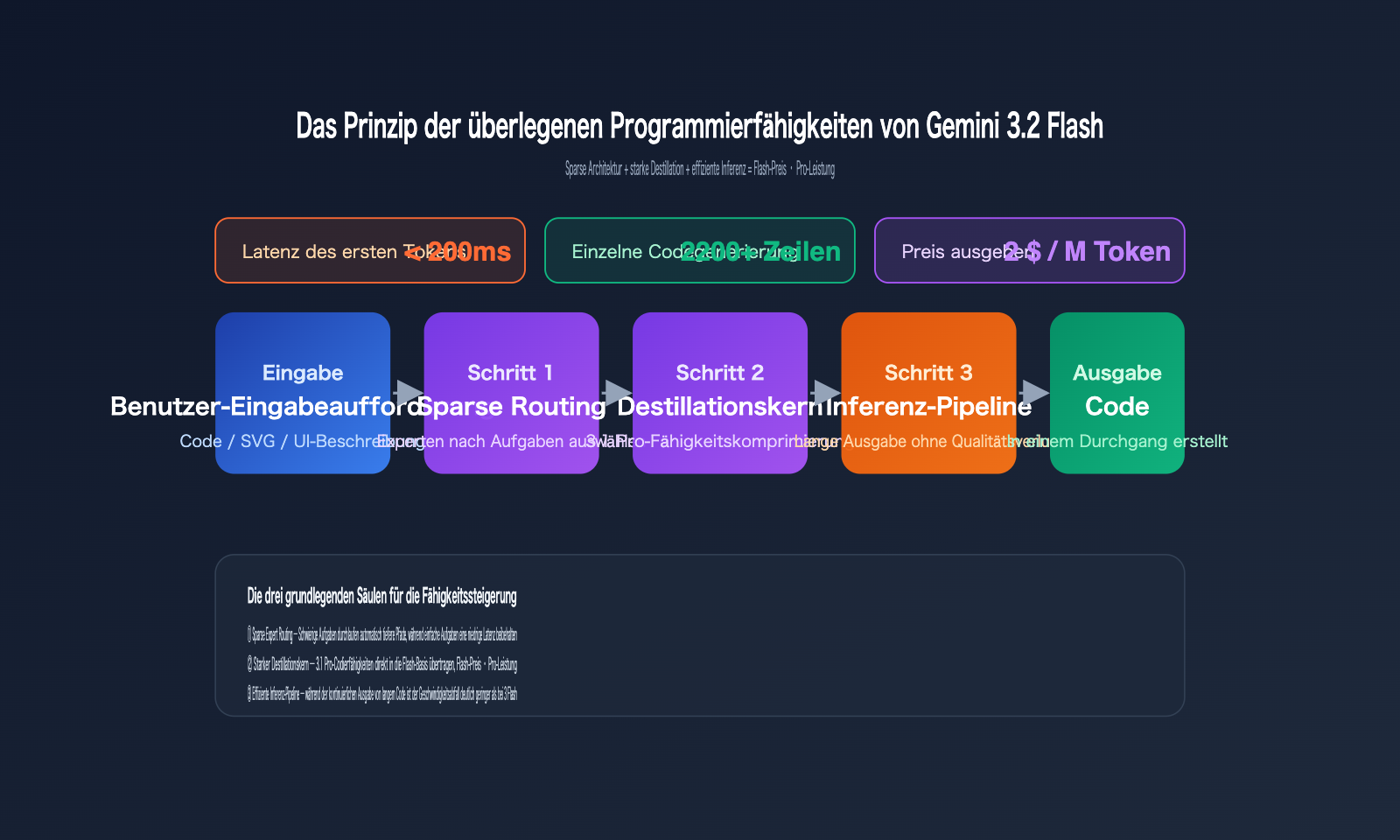
Vergleich der drei wichtigsten Programmierszenarien für Gemini 3.2 Flash
Die folgende Tabelle fasst die am häufigsten zitierten Vergleichstests der internationalen Community zusammen. Alle Ergebnisse stammen aus anonymen LM-Arena-Daten und öffentlichen AI-Studio-Beispielen.
| Testaufgabe | Gemini 3 Flash | Gemini 3.1 Pro | Gemini 3.2 Flash |
|---|---|---|---|
| Vollbild HTML ASCII Stadt-Animation | Code nicht ausführbar | ca. 5 Min., fehlerhafter Code | ca. 2 Min., direkt ausführbar |
| Einmalige Eingabeaufforderung für Windows 98 Desktop-Demo | Nur statisches Grundgerüst | Interaktionslogik lückenhaft, Nachbesserungen nötig | ca. 2200 Zeilen Code in einem Durchgang, voll interaktiv |
| Komplexe Vektor-Illustration (SVG) | Pfade fehlerhaft, Farben falsch | Visuell okay, manuelle Anpassung nötig | Visuell korrekt, fehlerfreie Ausgabe |
Alle drei Aufgaben haben eines gemeinsam: Das Modell muss in einer einzigen Inferenz-Sequenz eine „Strukturplanung sowie eine kontinuierliche Ausgabe von langem Code“ leisten – genau das war bisher die größte Schwachstelle der Flash-Modelle. Die Stabilität von 3.2 Flash bei solch langen Ausgaben deutet darauf hin, dass die zugrunde liegende Architektur bei der Kohärenz des Kontextfensters und der Einhaltung von Programmiersyntax deutlich verbessert wurde.
Warum Gemini 3.2 Flash so stark performt
Den verfügbaren technischen Hinweisen zufolge ist dieser Sprung nicht allein durch mehr Parameter entstanden, sondern durch eine Kombination aus technischer Optimierung. Die Analyse der internationalen Community deutet auf vier Hauptfaktoren hin:
- Aggressivere KI-Destillation: Die Fähigkeiten von 3.1 Pro wurden direkt in das kleinere, schnellere Flash-Fundament destilliert.
- Optimierung der Sparse-Architektur: Das Experten-Routing arbeitet präziser, sodass bei der Generierung von langem Code nicht mehr „alle Ressourcen gleichzeitig“ beansprucht werden.
- Verbessertes internes Routing-System: Schwierige Aufgaben werden automatisch über tiefere Inferenzpfade geleitet, während einfache Aufgaben mit geringer Latenz bearbeitet werden.
- Effiziente Inferenz-Pipeline: Die Latenz bis zum ersten Token liegt stabil unter 200 ms, wobei der Geschwindigkeitsabfall bei langen Ausgaben deutlich geringer ausfällt.
Für Entwickler bedeutet das in der Praxis: Beim Schreiben von React/Vue-Komponenten, dem Ausführen von SQL-Erklärungen oder dem Generieren von ausführbarem Visualisierungscode kann Flash nun standardmäßig das Pro-Modell ersetzen. Nur bei wirklich komplexen, mehrstufigen Planungsprozessen ist der Wechsel zurück auf Pro sinnvoll.
🚀 Testempfehlung: Wenn Sie die tatsächlichen Programmierfähigkeiten von 3.2 Flash selbst testen möchten, empfehlen wir den Zugriff über die Plattform APIYI (apiyi.com) mit der OpenAI-kompatiblen Schnittstelle. Wir raten dazu, eine Reihe von „schweren Eingabeaufforderungen“ (z. B. langes HTML, komplexe SVGs, Umschreiben von ganzseitigem Code) vorzubereiten und mit demselben Skript die Ausgabequalität und Stabilität von 3.2 Flash im Vergleich zu 3.1 Pro zu testen.
Preisstrategie und Kostenkalkulation für Gemini 3.2 Flash
Die Flash-Serie war schon immer Googles schärfste Waffe gegen die Konkurrenz, und mit 3.2 Flash wird diese Strategie auf ein neues Level gehoben. Ein Ausgabepreis von 2,00 $ pro Million Tokens bedeutet, dass die Kosten pro Einheit bei gängigen Szenarien wie Programmierung oder der Generierung langer Texte fast das Niveau eines GPT-5.5 Instant Mini erreichen, während die Leistung der eines Pro-Modells nahekommt.
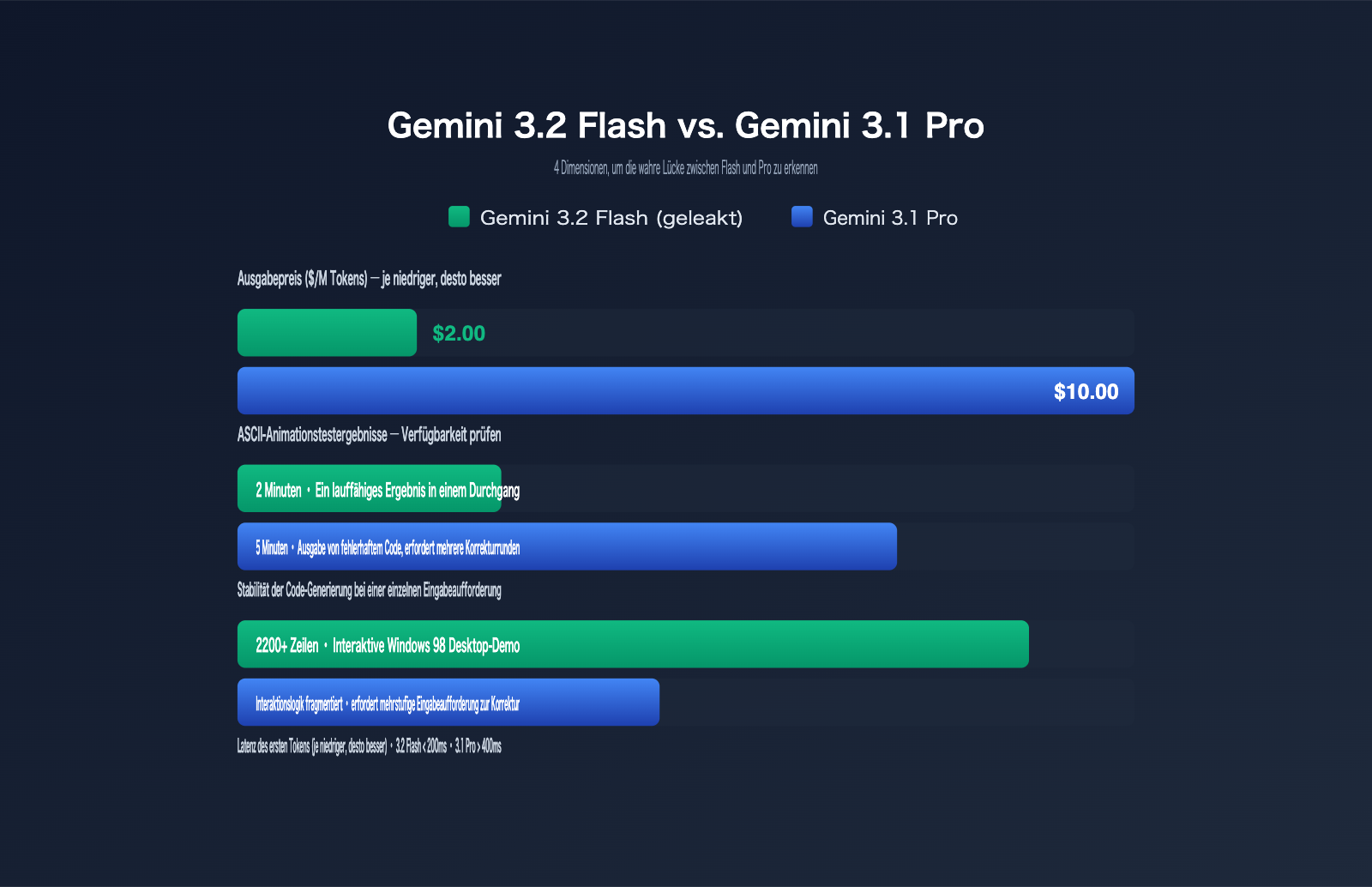
Preisvergleich: Gemini 3.2 Flash vs. Gemini-Serie
Die folgende Tabelle vergleicht die Preise der aktuellen Gemini-Modelle, wie sie im AI Studio einsehbar sind. Alle Daten basieren auf öffentlichen Seiten oder geleakten Metadaten; die Preise für die Pro-Stufe orientieren sich an der Standardpreisgestaltung von Vertex AI.
| Modell | Eingabe ($/M) | Ausgabe ($/M) | Anwendungsbereich |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | 0,25 | 1,50 | Hohe Parallelität, kostengünstige Batch-Aufgaben |
| Gemini 3 Flash | 0,50 | 3,00 | Standard-Chat / Mittelschwere Programmierung |
| Gemini 3.2 Flash (geleakt) | 0,25 | 2,00 | Lange Code-Generierung / Komplexe UI / SVG |
| Gemini 3.1 Pro | 1,25 | 10,00 | Komplexe Schlussfolgerungen / Mehrstufige Planung |
Wie man sieht, liegt 3.2 Flash beim Eingabepreis gleichauf mit Flash-Lite, während der Ausgabepreis im Vergleich zu 3 Flash um ein Drittel gesenkt wurde – bei einer Leistungsfähigkeit, die mit dem 10-Dollar-Modell 3.1 Pro konkurriert. Bei komplexen Programmieraufgaben mit 1 Million Tokens spart man mit 3.2 Flash etwa 80 % der Kosten im Vergleich zu 3.1 Pro. Alle vier Modelle bieten über APIYI (apiyi.com) eine einheitliche, OpenAI-kompatible Schnittstelle. So können Sie den Traffic dynamisch innerhalb desselben Projekts verteilen, ohne für verschiedene Modellstufen das SDK neu anbinden zu müssen.
Beispielrechnung: Monatliche Kosten für Gemini 3.2 Flash
Um die Zahlen greifbarer zu machen, betrachten wir ein reales Szenario: Sie entwickeln ein KI-gestütztes Programmiertool, das täglich 5.000 Code-Generierungsanfragen verarbeitet, mit durchschnittlich 1k Tokens Eingabe und 3k Tokens Ausgabe.
| Gewähltes Modell | Tageskosten ($) | Monatskosten ($) | Anmerkung |
|---|---|---|---|
| Gemini 3.1 Pro | 156,25 | 4687,50 | Starke Logik, aber für Code-Aufgaben überdimensioniert |
| Gemini 3 Flash | 47,50 | 1425,00 | Aktuelle Standardlösung |
| Gemini 3.2 Flash (geschätzt) | 31,25 | 937,50 | Leistung nahe Pro, Kosten deutlich gesenkt |
💰 Tipp zur Kostenoptimierung: Für budgetsensible Projekte empfiehlt es sich, die Gemini-API über die Plattform APIYI (apiyi.com) zu nutzen. Diese bietet nutzungsbasierte Abrechnung und einen zentralen Kontingent-Pool, was ideal für kleine und mittlere Teams ist, um nach dem offiziellen Start von 3.2 Flash schnell zu skalieren, ohne mehrere Abrechnungssysteme verschiedener Anbieter verwalten zu müssen.
Liquid Glass Interface und Agents-Signale für Gemini 3.2 Flash
Das Modell selbst ist nicht das einzige Highlight dieses Leaks. Zusammen mit Gemini 3.2 Flash tauchte eine neue Benutzeroberfläche auf, die von Entwicklern "Liquid Glass" getauft wurde, sowie ein versteckter Reiter für "Agents (Beta)". Diese beiden Punkte verraten mehr über die Gesamtstrategie von Google für die I/O 2026 als das Modell allein.
Highlights des Gemini 3.2 Flash Web-Interfaces
"Liquid Glass" markiert einen bedeutenden Stilwechsel gegenüber dem bisherigen flachen Design:
- Pillenförmiges Eingabefeld für die Eingabeaufforderung mit sanften Verlaufs-Highlights
- Halbtransparente Hintergrundebene, die im Rhythmus des Dialogs pulsiert
- Der Modellauswähler wurde nach oben links in ein Dropdown-Menü verschoben, um den Fokus auf den Modellwechsel zu legen
- Sprechblasen nutzen kontrastreichere Freiräume, lange Code-Blöcke werden standardmäßig ausgeklappt
Dieses Interface rückt die "Modellwahl" visuell in den Vordergrund. Dies bereitet die Nutzer darauf vor, Modelle gezielt nach Aufgaben auszuwählen – ein Konzept, das perfekt zur Philosophie von Multi-Anbieter-Plattformen passt.
Was Gemini 3.2 Flash und Agents (Beta) über die Agenten-Strategie verraten
Besonders spannend für Entwickler ist der unfertige "Agents (Beta)"-Reiter in der Gemini iOS-App. In Anbetracht der Investitionen von Google im letzten Jahr in Gemini CLI, Agent Builder und Vertex AI Agent kann man davon ausgehen, dass die I/O 2026 einen klaren Fokus auf Agenten legen wird. Gemini 3.2 Flash ist dabei der ideale Kandidat als "Standard-Gehirn für Agenten": schnell genug für mehrstufige Schleifen und kosteneffizient genug für einen hohen Token-Verbrauch.
🎯 Architektur-Empfehlung: Wenn Sie ein eigenes Agenten-Framework entwickeln, sollten Sie die Gemini-Serie zusammen mit Claude- und GPT-Modellen hinter einer einheitlichen Steuerungsschicht auf APIYI (apiyi.com) platzieren. Sobald 3.2 Flash offiziell verfügbar ist, müssen Sie nur das
model-Feld anpassen, um zu testen, ob es als "Agenten-Gehirn" besser funktioniert als Ihre bisherige Lösung – so vermeiden Sie eine Abhängigkeit von einem einzigen Anbieter.
Gemini 3.2 Flash Anbindungsbeispiel und einheitliche Schnittstelle
Obwohl die offizielle API für 3.2 Flash noch nicht veröffentlicht wurde, wird erwartet, dass die Schnittstellenspezifikationen vollständig mit der Gemini 3.x-Serie übereinstimmen. Nachfolgend finden Sie ein minimalistisches Beispiel für die Verwendung der einheitlichen APIYI-Schnittstelle, das bei einem zukünftigen Wechsel auf 3.2 Flash nahezu keine Änderungen erfordert.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.2-flash", # Nach der offiziellen Veröffentlichung durch die offizielle Modell-ID ersetzen
messages=[
{"role": "user", "content": "Erstelle einen interaktiven Windows 98-Desktop mit einer einzigen HTML-Datei + Canvas"}
],
)
print(response.choices[0].message.content)
Vollständiger Code mit Streaming-Ausgabe und Fehlerwiederholung anzeigen
from openai import OpenAI
from openai import APIError, RateLimitError
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
PROMPT = """Erstelle einen interaktiven Windows 98-Desktop-Demo mit einer einzigen HTML-Datei + Canvas,
Anforderungen: Fenster sollten verschiebbar sein, das Startmenü unten links sollte aufklappbar sein, Desktop-Symbole sollten per Doppelklick Fenster öffnen."""
def call_gemini_3_2_flash(prompt: str, retries: int = 3):
for attempt in range(retries):
try:
stream = client.chat.completions.create(
model="gemini-3.2-flash",
messages=[{"role": "user", "content": prompt}],
stream=True,
max_tokens=8192,
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
return
except RateLimitError:
time.sleep(2 ** attempt)
except APIError as e:
print(f"\n[API-Fehler] {e}")
return
if __name__ == "__main__":
call_gemini_3_2_flash(PROMPT)
Das entscheidende Design dieses Codes liegt in der Entkopplung von base_url und model: Um zwischen Flash und Pro zu wechseln, muss lediglich eine Zeile im Feld model geändert werden. Der Geschäftslogik-Code, die Fehlerbehandlung und die Streaming-Logik können vollständig wiederverwendet werden, was sich ideal für A/B-Tests direkt nach der I/O eignet.
Analyse der Auswirkungen von Gemini 3.2 Flash auf Entwickler und Industrie
Der Grund, warum dieser Leak in der internationalen Entwickler-Community für Aufsehen sorgte, ist nicht einfach nur die Tatsache, dass ein weiteres "Flash"-Modell erschienen ist. Vielmehr bricht es mit dem langjährigen stillschweigenden Konsens, dass "Flash zwar günstig ist, aber nur für einfache Aufgaben taugt, während Pro teuer ist, aber komplexe Codes schreiben kann".
Auswirkungen von Gemini 3.2 Flash auf unabhängige Entwickler und kleine Teams
Für budgetbewusste unabhängige Entwickler ist 3.2 Flash fast wie ein Quantensprung. Aufgaben wie die Generierung ganzer Codedateien oder komplexe Visualisierungen, für die bisher zwingend ein Pro-Modell erforderlich war, können nun von Flash erledigt werden. Die monatlichen Modellkosten könnten dadurch direkt um 50 % bis 80 % sinken.
Für kleine und mittlere Teams zeigen sich die Auswirkungen eher auf der Produktebene: Funktionen wie KI-Programmierassistenten, Low-Code-Visualisierungsplattformen oder automatisierte Berichtsgeneratoren, die früher aufgrund hoher Pro-Kosten eingeschränkt waren, können nun als standardmäßig aktivierte, bei Bedarf abrufbare Dienste neu konzipiert werden.
Auswirkungen von Gemini 3.2 Flash auf große Teams und multimodale Architekturen
Für große Teams mit bestehenden multimodalen Architekturen wird 3.2 Flash das Pro-Modell nicht sofort ersetzen, aber es wird dazu zwingen, die Modellauswahlstrategie anzupassen: Die Routing-Ebene muss dynamisch je nach Aufgabentyp zwischen Flash und Pro wählen, anstatt ein einziges Modell für alles zu verwenden. Dies stellt höhere Anforderungen an Modell-Gateways, einheitliche Abrechnung und zentrales Logging. Bestehende, für Einzelmodelle entworfene Gateways werden nach der I/O höchstwahrscheinlich ein Architektur-Upgrade benötigen.
Konkret sollten große Teams in drei Bereichen vorsorgen: Erstens den Aufbau eines beobachtbaren Token-Monitorings, um den tatsächlichen Verbrauch von Flash und Pro getrennt zu erfassen; zweitens die Entkopplung von Eingabeaufforderung und Modell durch ein Vorlagensystem anstelle von fest kodierten Modellbindungen; und drittens die Vorbereitung von Gray-Release-Mechanismen, um bei der offiziellen Veröffentlichung von 3.2 Flash eine schrittweise Migration nach Geschäftsmodulen statt einer Komplettumstellung durchzuführen und so das Online-Risiko zu minimieren.
Auswirkungen von Gemini 3.2 Flash auf Wettbewerber
OpenAI veröffentlichte am selben Tag GPT-5.5 Instant mit dem Fokus auf "Reduzierung von Halluzinationen und Stärkung der Faktenlage". Dies steht im direkten Kontrast zu Googles Strategie von "Preissenkung + verbesserte Kodierfähigkeiten": OpenAI setzt auf hochwertige vertikale Szenarien, Google auf massentaugliche Kodierung und Agenten-Szenarien. Anthropic hat noch nicht direkt auf den Leak reagiert, aber die "Kodier-Prämie", die die Claude-Serie lange Zeit innehatte, wird durch das Preisniveau der Flash-Klasse unter Druck geraten.
Häufig gestellte Fragen zu Gemini 3.2 Flash
Q1: Wann wird die API für Gemini 3.2 Flash offiziell freigegeben?
Basierend auf durchgesickerten Hinweisen und dem üblichen Veröffentlichungsrhythmus der Google I/O wird Gemini 3.2 Flash höchstwahrscheinlich während der Keynote der I/O 2026 am 19. oder 20. Mai offiziell angekündigt und noch am selben oder nächsten Tag über Vertex AI und AI Studio verfügbar gemacht. Drittanbieter-Aggregatoren benötigen in der Regel 24 bis 48 Stunden für die Anbindung. Es empfiehlt sich, die Modell-Updates auf APIYI (apiyi.com) zu verfolgen, um das Modell sofort über eine einheitliche Schnittstelle testen zu können.
Q2: Wird Gemini 3.2 Flash das Gemini 3.1 Pro ersetzen?
Kurzfristig wird es kein vollständiger Ersatz sein. 3.2 Flash zeigt bei Aufgaben wie Programmierung, Generierung von langem Code sowie bei SVG/Canvas-Aufgaben eine überlegene Leistung. Bei komplexen Schlussfolgerungen, mehrstufiger Planung oder in Finanz- und Rechtsbereichen, die strikte Kausalketten erfordern, bleibt Pro jedoch stabiler. Eine sinnvolle Strategie ist das aufgabenbasierte Routing: Nutzen Sie 3.2 Flash für Coding und UI, während Sie für tiefgreifende Analysen und risikoreiche Entscheidungen weiterhin auf 3.1 Pro setzen. Dies lässt sich über die Gateway-Ebene steuern, ohne die Geschäftslogik umschreiben zu müssen.
Q3: Ist die Generierung von 2200 Zeilen Code durch Gemini 3.2 Flash real?
Das in internationalen Entwickler-Communities kursierende „Windows 98 Desktop-Demo mit 2200 Zeilen“ stammt aus Praxistests im AI Studio Canvas-Modus. Was sich derzeit unabhängig verifizieren lässt, ist: Die Stabilität von 3.2 Flash bei der Generierung extrem langer, ausführbarer Code-Abschnitte innerhalb einer einzigen Eingabeaufforderung ist deutlich besser als bei 3 Flash und 3.1 Pro. Eine vollständige Reproduktion erfordert die offizielle API-Freigabe, aber der Qualitätssprung bei der „Stabilität langer Ausgaben“ wurde von mehreren unabhängigen Testern bestätigt.
Q4: Wie groß ist das Kontextfenster von Gemini 3.2 Flash?
In den durchgesickerten Metadaten gibt es keine direkte Angabe zum Kontextfenster, aber basierend auf den Spezifikationen der Gemini 3.x-Serie ist es sehr wahrscheinlich, dass 3.2 Flash das 1M-Token-Kontextfenster beibehält. Dies ist entscheidend für die Verarbeitung großer Code-Repositories, vollständiger Dokumente oder Videotranskripte und bildet die physische Grundlage für die stabile Ausgabe von über 2000 Zeilen Code.
Q5: Wie können Entwickler in China Gemini 3.2 Flash am schnellsten integrieren?
Nach dem offiziellen Start ist der stabilste Weg für Entwickler die Nutzung einer Aggregator-Plattform, die aus China erreichbar ist. Wir empfehlen die Anbindung von Gemini 3.2 Flash über APIYI (apiyi.com). Die Plattform verwendet eine OpenAI-kompatible Schnittstelle, die eine nahtlose Wiederverwendung des bestehenden Codes ermöglicht. Sie müssen lediglich die Felder base_url und model anpassen, um in derselben Anwendung Modelle von Gemini, Claude, GPT und anderen Anbietern gleichzeitig aufzurufen – ideal für Vergleiche und schnelle Wechsel.
Fazit: Was bedeutet der vorzeitige Leak von Gemini 3.2 Flash?
Um auf den Satz vom Anfang zurückzukommen: „Die Konferenz hat noch nicht begonnen, aber Google kann es nicht mehr verbergen.“ Seit dem stillen Start im AI Studio am 5. Mai wurde Gemini 3.2 Flash von der internationalen Community in allen Dimensionen – von der Modell-ID über das Liquid Glass UI und Agents-Tags bis hin zur 2200-Zeilen-Code-Demo – komplett analysiert. Dies ist nicht nur ein Leak, sondern sendet drei klare Signale:
- Flash-Modelle steigen in eine höhere Liga auf: Google definiert die Modell-Klassifizierung durch „niedrigen Preis + hohe Coding-Fähigkeit“ neu.
- Die Agents-Strategie wird sichtbar: 3.2 Flash wird höchstwahrscheinlich die Standardbasis für agentische Anwendungen.
- Der Wert von Multi-Modell-Aggregatoren steigt: Wer schneller integrieren und evaluieren kann, sichert sich den Wettbewerbsvorteil.
Für Entwickler geht es nicht darum, auf die Details der I/O-Keynote zu wetten, sondern frühzeitig die technische Infrastruktur für einheitliche Anbindung, Evaluierung und Abrechnung vorzubereiten, um sofort nach der offiziellen Freigabe von 3.2 Flash mit Stresstests zu beginnen. Wir empfehlen, die Performance über APIYI (apiyi.com) schnell zu validieren, damit Sie bereits am Abend nach der I/O-Keynote echte Daten für Ihre Geschäftsszenarien vorliegen haben, anstatt auf Community-Benchmarks zu warten.
Autor: APIYI Technical Team — Spezialisiert auf die Praxis von KI-Großmodell-APIs. Wenn Sie mehr über Kosten- und Leistungsdaten der Gemini-, Claude- und GPT-Modellserien in realen Geschäftsszenarien erfahren möchten, besuchen Sie APIYI (apiyi.com) für aktuelle Bewertungsberichte und kostenlose Testguthaben.