Ein Update, das Entwickler auf dem Schirm haben sollten: Die Dola-Basismodellfamilie von ByteDance hat am 28. April 2026 das erste „Omnimodal“-Verständnismodell namens Seed-2.0-lite-260428 veröffentlicht, das nativ die vier Modalitäten Video, Bild, Audio und Text unterstützt. Dies ist das erste Modell der Dola-Seed-Familie, das „sehen und hören“ kann, und bietet zudem Verbesserungen in Bereichen wie Agenten, Coding und GUI-Aufgaben. Dieser Artikel erläutert basierend auf den offiziellen Spezifikationen von BytePlus ModelArk, den öffentlichen Benchmarks von ByteDance sowie Praxistests über APIYI (apiyi.com) die Modellfähigkeiten, Details zum Audioverständnis und typische Anwendungsszenarien.
I. Was ist Seed-2.0-lite-260428: Kernpositionierung und Upgrades
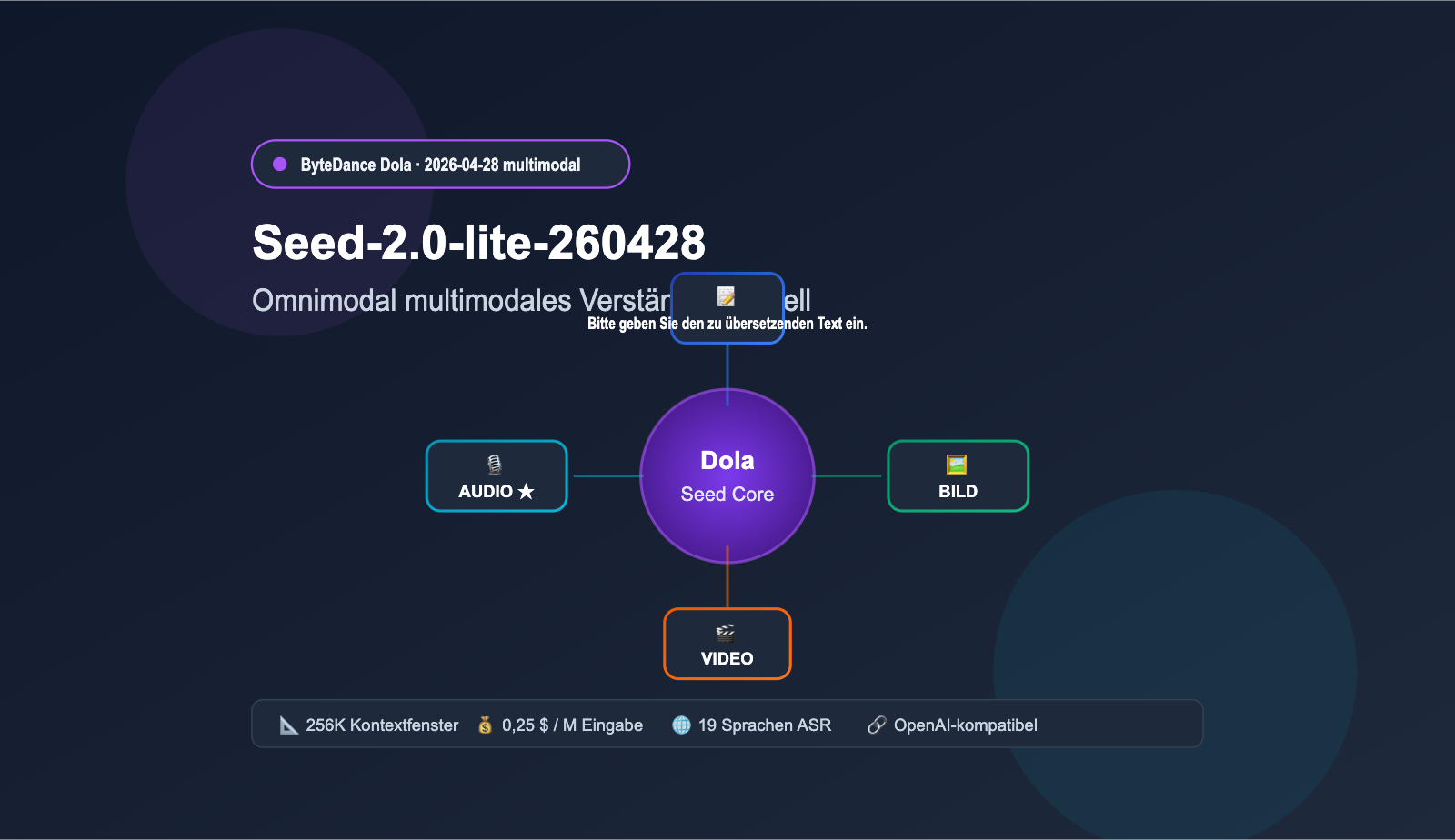
Seed-2.0-lite-260428 ist eine wichtige Iteration von ByteDance Seed, die am 28. April 2026 veröffentlicht wurde. Das Basismodell basiert auf dem Anfang März veröffentlichten Seed-2.0-Lite, führt jedoch erstmals die „Audioeingabe“ als native Fähigkeit ein und hebt diese Produktlinie damit auf die Stufe eines echten „Omnimodalen“ Modells. Die Versionsnummer 260428 im Namen steht für das Veröffentlichungsdatum.
1.1 Das erste omnimodale Modell aus der ByteDance Dola-Familie
In der bisherigen Dola Seed-Familie waren Text- und multimodale Fähigkeiten in verschiedenen Zweigen unterteilt. Seed-2.0-lite-260428 führt Video, Bild, Audio und Text in einem einzigen Modell zusammen. Das bedeutet, es kann gleichzeitig „Videobilder sehen“ und „Audioinhalte hören“, um darauf basierend gemeinsame Schlussfolgerungen zu ziehen und zeitliche Analysen durchzuführen. Diese einheitliche Architektur ist besonders für Agenten-Anwendungen entscheidend, da viele reale Aufgaben (z. B. Video-Moderation, Konferenzzusammenfassungen, Qualitätsprüfung im Kundenservice) von Natur aus eine multimodale Schlussfolgerung erfordern.
1.2 Kurzübersicht der Modellspezifikationen
Die folgende Tabelle fasst die Kernparameter von Seed-2.0-lite-260428 auf BytePlus ModelArk zusammen, damit Sie schnell beurteilen können, ob es Ihren geschäftlichen Anforderungen entspricht.
| Spezifikation | Parameter |
|---|---|
| API-Modell-ID | seed-2-0-lite-260428 |
| Modellfamilie | ByteDance Seed / Dola |
| Veröffentlichungsdatum | 28.04.2026 |
| Kontextfenster | 262.144 Token (ca. 256K) |
| Max. Ausgabe | 131.072 Token (ca. 128K) |
| Eingabemodalitäten | Text + Bild + Video + Audio |
| Eingabepreis | $0,25 / M Token |
| Ausgabepreis | $2,00 / M Token |
| Schnittstellenkompatibilität | OpenAI-kompatible API |
II. Die 4 Kernkompetenzen des multimodalen Verständnisses von Seed-2.0-lite-260428
Die multimodale Leistungsfähigkeit des Modells besteht nicht einfach darin, verschiedene Eingaben zu "kombinieren", sondern durch eine einheitliche Repräsentation eine gemeinsame Schlussfolgerung zu ziehen. Die offizielle Dokumentation fasst die Kernkompetenzen in vier Bereichen zusammen.
2.1 Audio-visuelle gemeinsame Schlussfolgerung und zeitliche Suche
Das Modell kann visuelle und auditive Informationen in Videos gleichzeitig analysieren und präzise beurteilen, ob "gesehene Bilder" und "gehörte Töne" übereinstimmen. So lässt sich beispielsweise feststellen, ob der Gesichtsausdruck einer Person in einem Video mit der emotionalen Stimmung des Gesprochenen korrespondiert oder ob die Bewegungen von Objekten im Bild den korrekten Soundeffekten entsprechen. Diese Fähigkeit zur Audio-Video-Synchronisation ist in Szenarien wie der Videoüberprüfung oder der Erkennung von Deepfakes äußerst nützlich.
2.2 Detaillierte Videozerlegung und Langzeit-Tracking
Für lange Videos unterstützt Seed-2.0-lite-260428 das Extrahieren wichtiger Hinweise über mehrere Zeitabschnitte hinweg, verfolgt kontinuierlich Personen und Ereignisse und führt mehrstufige Schlussfolgerungen zwischen mehreren Frames durch, um Ereignisbeziehungen und Verhaltenskontexte zu rekonstruieren. Im Vergleich zur traditionellen Methode der Frame-für-Frame-Beschreibung eignet sich die Fähigkeit zum "Langzeitverständnis" besser für Aufgaben wie die Überprüfung von Überwachungsvideos oder als Assistenz beim Schnitt von Dokumentarfilmen.
2.3 Verbesserte Agenten- und Kodierungsfähigkeiten
Das Modell verfügt über eine stabile und zuverlässige Ausführungsfähigkeit bei komplexen, langwierigen Aufgaben sowie über fundierte Full-Stack-Entwicklungsfähigkeiten. Das bedeutet, dass Entwickler es in Agenten-Frameworks integrieren können, um einen vollständigen geschlossenen Kreislauf aus Planung, Werkzeugaufruf, Überprüfung historischer Schritte und Code-Generierung auszuführen, ohne die Aufgabe auf mehrere verschiedene Modelle aufteilen zu müssen.
2.4 Einheitliche Schnittstelle für GUI-Verständnis und Aktionsausführung
Die GUI-Fähigkeit ist in dieselbe Schnittstelle integriert. Das Modell kann sowohl Screenshots (Schaltflächen, Formulare, Menüs) verstehen als auch Befehle zur Bedienung ausgeben (Koordinaten anklicken, Text eingeben). Dies stellt ein direktes Upgrade für automatisierte Tests, Desktop-Agenten und RPA-Anwendungen dar.
III. Tiefenanalyse der Audio-Verständnisfähigkeit von Seed-2.0-lite-260428
Audio ist das größte Differenzierungsmerkmal dieses Updates, weshalb wir es separat behandeln. Das Modell hat in mehreren gängigen Audio-Benchmarks beeindruckende Ergebnisse erzielt.
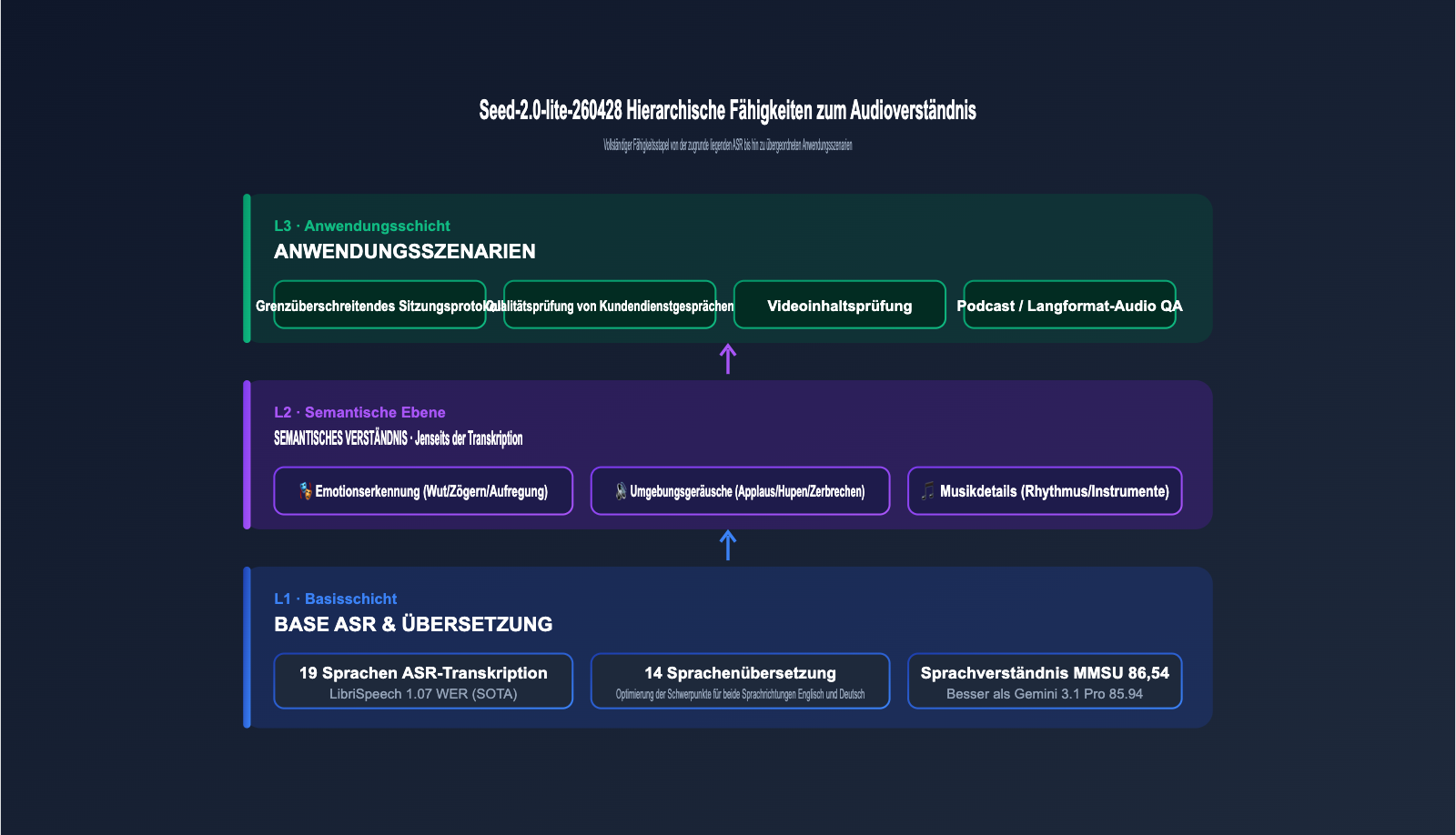
3.1 Messergebnisse in gängigen Audio-Benchmarks
Die folgende Tabelle fasst die von ByteDance Seed offiziell veröffentlichten Benchmark-Ergebnisse zusammen, die die drei Dimensionen Spracherkennung (ASR), gesprochenes Sprachverständnis und Sprachaufnahmen in Außenumgebungen abdecken.
| Benchmark | Aufgabentyp | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | Englisch ASR (sauber) | 1.07 WER |
| LibriSpeech test-other | Englisch ASR (Rauschen) | 2.17 WER |
| WenetSpeech test-net | Chinesisch ASR (Web) | 4.47 WER |
| WenetSpeech test-meeting | Chinesisch Konferenz-ASR | 5.31 WER |
| Fleurs (15 Sprachen) | Mehrsprachige ASR | 74.70 |
| MMSU | Sprachverständnis | 86.54 |
| WildSpeech | Außenumgebung | 75.81 |
Die WER von 1.07 bei LibriSpeech test-clean liegt bereits auf Branchen-Spitzenniveau und übertrifft die vergleichbaren Ergebnisse von Whisper large-v3; die Werte bei MMSU und WildSpeech liegen ebenfalls leicht über den veröffentlichten Daten von Gemini 3.1 Pro, was zeigt, dass das Modell auch auf der Ebene des "Verständnisses" ein führendes Niveau erreicht hat und nicht nur beim reinen "Diktat".
3.2 Transkription in 19 Sprachen und Übersetzung zwischen 14 Sprachen
Laut offizieller Dokumentation unterstützt das Modell die Transkription von 19 Sprachen und die Übersetzung zwischen 14 Sprachen, wobei die bidirektionale Übersetzung zwischen Chinesisch und Englisch als Schwerpunkt hervorgehoben wird. Dies bedeutet, dass das Modell für dieselbe mehrsprachige Konferenzaufnahme Untertitel und Übersetzungen in einer einheitlichen Sprache ausgeben kann, was für grenzüberschreitende Teams oder den Kundenservice im E-Commerce ideal ist.
3.3 Mehr als nur "Transkription": Emotionen, Umgebungsgeräusche und Musikdetails
Der größte Unterschied zu herkömmlichen ASR-Modellen besteht darin, dass Seed-2.0-lite-260428 auch semantische Informationen erfassen kann, die über den "Textinhalt" hinausgehen: emotionale Schwankungen des Sprechers (Wut, Zögern, Aufregung), Hintergrundgeräusche (klirrendes Glas, Applaus, Autohupen) und musikalische Details (Rhythmus, Instrumente, Stil). Diese Dimensionen haben einen direkten Mehrwert für die Qualitätsprüfung im Kundenservice, die Inhaltsüberprüfung und Musikempfehlungen.
🎯 Empfehlung zur Anbindung: Für Szenarien wie grenzüberschreitende Konferenzprotokolle, Qualitätsprüfungen im Kundenservice oder die Überprüfung von Videoinhalten, bei denen eine Synergie aus "Audio + Text" erforderlich ist, empfehlen wir den direkten Aufruf von Seed-2.0-lite-260428 über APIYI (apiyi.com). Mit einer einzigen base_url erhalten Sie sowohl multimodale Schlussfolgerungen als auch die Vorteile des 256K-Kontextfensters, ohne eine eigene Sprach-Pipeline aufbauen zu müssen.
IV. Vergleichsanalyse: Seed-2.0-lite-260428 und führende multimodale Modelle
Um die Position dieses Modells im Jahr 2026 zu bestimmen, ist es am besten, es direkt mit zeitgenössischen Flaggschiff-Modellen wie GPT-4o und Gemini 3 Pro zu vergleichen.
4.1 Leistungsvergleich führender multimodaler Modelle
| Dimension | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| Texteingabe | ✓ | ✓ | ✓ |
| Bildeingabe | ✓ | ✓ | ✓ |
| Videoeingabe | ✓ | ✓ | ✓ |
| Audioeingabe | ✓ | ✓ | ✓ |
| Kontextfenster | 262K | 128K | 1M |
| Preis pro Mio. Input | $0,25 | $2,50 | $1,25 |
| Preis pro Mio. Output | $2,00 | $10,00 | $10,00 |
| Audio-Emotionserkennung | ✓ | ✓ | ✓ |
| Optimierung für chin. Audio | Stark (WenetSpeech-Opt.) | Durchschnittlich | Durchschnittlich |
Wie man sieht, liegt der Kernvorteil von Seed-2.0-lite-260428 in der Kombination aus "Preis + chinesischem Audio + 256K langem Kontextfenster". Dies macht es besonders kosteneffizient bei Aufgaben wie der mehrsprachigen Audio- und Videoverarbeitung oder der Zusammenfassung langer Meetings. GPT-4o und Gemini 3 Pro behalten ihre Stärken in der englischsprachigen Gesamtleistung und der Breite ihres Ökosystems, was sie für allgemeine Anwendungsfälle prädestiniert.
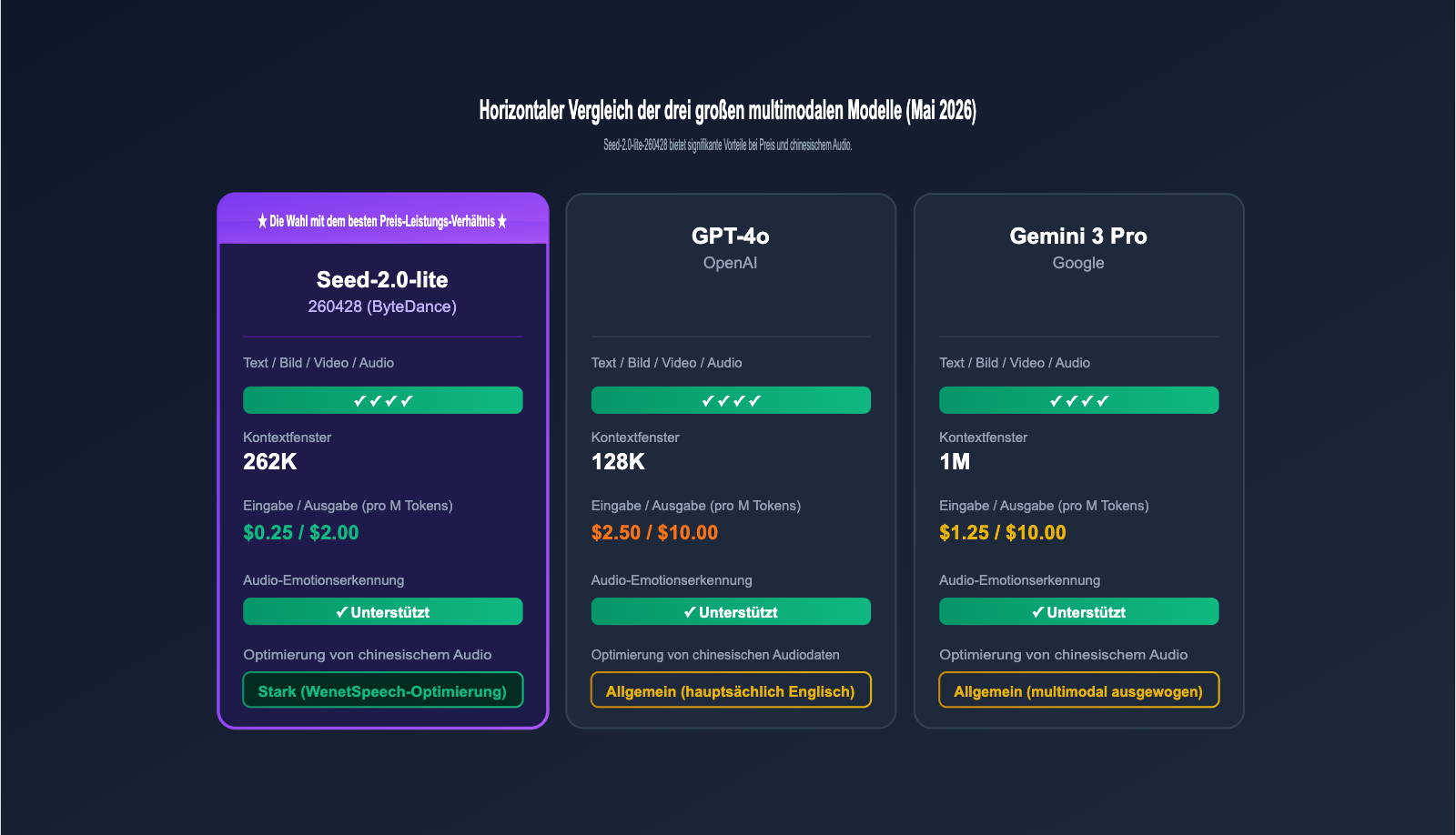
🎯 Auswahlempfehlung: Wenn Ihr Geschäftsschwerpunkt auf der chinesischen Audio- und Videoverarbeitung liegt und Sie preissensibel sind, ist Seed-2.0-lite-260428 aktuell eine äußerst kosteneffiziente Wahl. Wenn Sie jedoch primär Englisch verarbeiten oder komplexe, mehrsprachige kreative Generierungen benötigen, können Sie über das einheitliche Gateway von APIYI (apiyi.com) auf alle drei Flaggschiff-Modelle zugreifen und das Routing je nach Szenario anpassen.
5. Schnelleinstieg: Aufruf von Seed-2.0-lite-260428 über APIYI
Das Modell ist vollständig mit der OpenAI-Schnittstelle kompatibel, was die Migrationskosten extrem niedrig hält. Nachfolgend finden Sie ein minimalistisches Beispiel für den Aufruf, um ein Bild oder eine Audiodatei in eine strukturierte Beschreibung umzuwandeln.
5.1 Minimalbeispiel für die OpenAI-kompatible Schnittstelle
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Bitte beschreibe den Inhalt, die Stimmung und die Hintergrundgeräusche dieser Audiodatei."},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
Indem Sie die base_url auf den einheitlichen Zugangspunkt von APIYI (apiyi.com) richten und das model umschalten, können Sie Seed-2.0-lite-260428 sowie andere multimodale Modelle innerhalb desselben SDK aufrufen, ohne den Code auf Ihrer Seite anpassen zu müssen.
5.2 Typische Anwendungsszenarien für Seed-2.0-lite-260428
Die folgende Tabelle fasst einige typische Szenarien zusammen und zeigt, welche Vorteile diese aus der Eigenschaft „Einheitliche Schlussfolgerung für Audio + Video + Text“ des Modells ziehen können.
| Anwendungsszenario | Kernkompetenz | Geschäftlicher Nutzen |
|---|---|---|
| Protokollierung grenzüberschreitender Meetings | 19 Sprachen ASR + 14 Sprachen Übersetzung + 256K Kontextfenster | Erstellung zweisprachiger Protokolle für mehrsprachige Meetings per Knopfdruck |
| Qualitätsprüfung von Kundengesprächen | Emotionserkennung + Umgebungsgeräuscherkennung + Analyse langer Audios | Automatische Markierung von Wut/Unterbrechungen/Zeitüberschreitungen |
| Video-Content-Moderation | Gemeinsame Audio-Video-Schlussfolgerung + Langzeit-Tracking | Gleichzeitige Erkennung gefährlicher Bilder und verdächtiger Töne |
| Podcast / Langvideo-QA | 256K langes Kontextfenster + Audiotranskription | Direkte Beantwortung von Fragen zu stundenlangen Audioinhalten |
| Desktop-Agent-Automatisierung | GUI-Verständnis + Werkzeugaufruf | Erledigung komplexer Workflows über Anwendungen hinweg |
6. Häufig gestellte Fragen zu Seed-2.0-lite-260428
6.1 Wie sollte das Feld "model" beim API-Aufruf ausgefüllt werden?
Geben Sie einfach seed-2-0-lite-260428 ein. Beachten Sie, dass in der Mitte Bindestriche und keine Unterstriche verwendet werden; das Suffix 260428 ist die Versionsnummer (28.04.2026) und sollte nicht weggelassen werden, da Sie sonst möglicherweise auf eine ältere Version weitergeleitet werden. Die Modellliste finden Sie im APIYI-Dashboard unter apiyi.com, um sicherzustellen, dass sie mit der neuesten Version übereinstimmt.
6.2 Welche Audioformate und -längen werden unterstützt?
Das Modell folgt der Konvention des input_audio-Feldes im OpenAI-Stil; gängige Formate wie MP3, WAV, M4A und FLAC werden unterstützt. Die spezifische maximale Länge und Abtastrate entnehmen Sie bitte der offiziellen ModelArk-Dokumentation. Wir empfehlen, eine Eingabe von 30 Minuten pro Aufruf nicht zu überschreiten, um eine stabile Schlussfolgerung zu gewährleisten. Sehr lange Audios können in Segmente unterteilt und die Ergebnisse anschließend zusammengeführt werden.
6.3 Was ist der Unterschied zur Version ohne das Suffix 260428?
Die Version ohne Suffix ist die am 10. März veröffentlichte erste Generation von Seed-2.0-Lite, die nur Text, Bilder und Videos unterstützt. Die Version 260428 ist das am 28. April veröffentlichte Upgrade für alle Modalitäten, das Audioeingaben und die gemeinsame Audio-Video-Schlussfolgerung hinzufügt. Wenn Ihre Anwendung Audio verwendet, müssen Sie die Version mit Suffix verwenden.
6.4 Erfolgt die Abrechnung nach Token oder nach Audiolänge?
Das Modell wird einheitlich nach Token abgerechnet; Audio wird intern in Token kodiert und fließt so in die Berechnung ein. Die aktuelle Preisgestaltung liegt bei $0,25 / M für Eingaben und $2,00 / M für Ausgaben. Die Anzahl der Token für ein bestimmtes Audio kann in der „Rechnungsübersicht“ im APIYI-Dashboard (apiyi.com) eingesehen werden, was die Kostenschätzung und -optimierung erleichtert.
6.5 Werden Streaming-Ausgabe und Function Call unterstützt?
Ja, vollständig. Seed-2.0-lite-260428 ist mit den Feldern stream=true und tools des OpenAI Chat Completions-Protokolls kompatibel. Es kann direkt in gängige Frameworks wie LangChain, LangGraph oder das OpenAI Agents SDK integriert werden, ohne dass spezielle Anpassungen erforderlich sind.
VII. Fazit: All-Modality-Modelle führen multimodale Anwendungen in die Ära der „einheitlichen Inferenz“
Der Wert von Seed-2.0-lite-260428 liegt nicht nur in der „zusätzlichen Audio-Fähigkeit“, sondern vor allem darin, Video, Bild, Audio und Text in einem einzigen Modell zu vereinen. Für Unternehmen, die von Natur aus auf multimodale Prozesse angewiesen sind (wie Konferenzen, Kundenservice, Content-Moderation, Videoanalyse oder Agent-Automatisierung), bedeutet diese „einheitliche Inferenz“ eine echte Vereinfachung der Architektur: Es ist nicht mehr erforderlich, ASR-, Bild- und Textmodelle miteinander zu verknüpfen, und man muss sich keine Sorgen mehr über den Verlust des Kontexts zwischen verschiedenen Modellen machen.
Hinsichtlich der Kosten und der Anwendung in chinesischsprachigen Szenarien bietet dieses Modell ein hervorragendes Preis-Leistungs-Verhältnis unter den führenden Flaggschiff-Modellen. Der Preis von 0,25 $ pro Million Token für die Eingabe macht die groß angelegte Audio- und Videoverarbeitung technisch machbar, und das Kontextfenster von 256K reicht aus, um mehrstündige Audio- und Videoinhalte abzudecken.
Wenn Sie Seed-2.0-lite-260428 zusammen mit anderen führenden multimodalen Modellen unter einer einheitlichen base_url aufrufen möchten, besuchen Sie die offizielle Dokumentation von APIYI unter apiyi.com, um vollständige Integrationsbeispiele und die Modellliste einzusehen.
Autor: APIYI Team — Wir bieten KI-Entwicklern weltweit kontinuierlich stabile und effiziente API-Proxy-Dienste sowie Multi-Modell-Routing. Weitere Informationen finden Sie unter apiyi.com