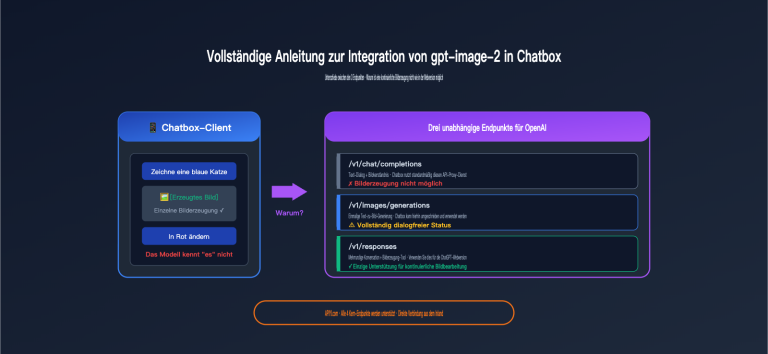
Kürzlich wurde ich von einem Entwickler-Kunden mit einer häufigen Frage konfrontiert: „Warum dauert es über 200 Sekunden, bis gpt-image-2 ein 1024×1024-Bild generiert? Wurde ich gedrosselt?“ Ein Blick in seinen Code verriet die Ursache: Die Standardparameter waren auf quality="high" und size="1536x1024" gesetzt – damit sind 235 Sekunden pro Bild ein völlig normales Verhalten.
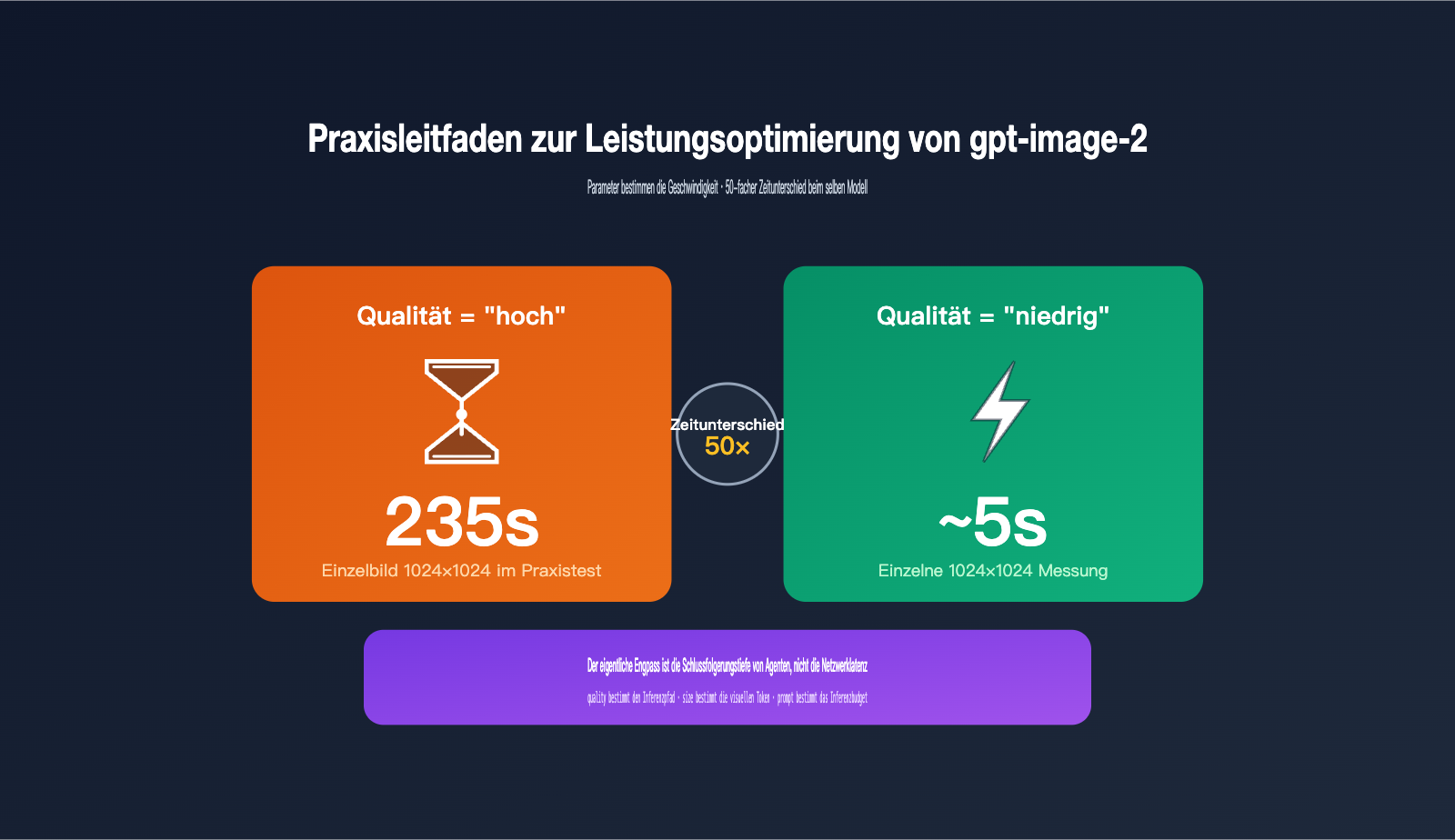
gpt-image-2 ist das am 21. April 2026 von OpenAI veröffentlichte Bildmodell der neuen Generation. Es integriert erstmals die Schlussfolgerungsfähigkeiten der O-Serie (Agentic Reasoning) in den Bilderzeugungsprozess. Das bedeutet, dass Anfragen mit quality="high" die vier Phasen „Verstehen – Planen – Generieren – Überprüfen“ durchlaufen, was 30- bis 50-mal länger dauert als bei quality="low". Basierend auf Erfahrungen aus der Produktion erkläre ich hier die drei wichtigsten Parameter, damit Sie die optimale Balance zwischen Bildqualität und Geschwindigkeit finden.
Kurzübersicht der Kernparameter für den gpt-image-2-Aufruf
Hier das Fazit vorab. Die folgende Tabelle deckt alle wichtigen Parameter von gpt-image-2 im OpenAI Python SDK ab und zeigt deren Einfluss auf Zeit und Kosten. Nutzen Sie diese Tabelle als Referenz für Ihre Optimierungen.
| Parameter | Mögliche Werte | Standardwert | Einfluss auf Zeit | Einfluss auf Kosten |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
Extrem | Extrem |
size |
1024x1024 / 1536x1024 / 1024x1536 / beliebig ≤ 2K |
1024x1024 |
Groß | Mittel |
output_format |
png / jpeg / webp |
png |
Gering | Keine |
output_compression |
0–100 (nur bei jpeg/webp) | 100 | Sehr gering | Keine |
n |
1–10 | 1 | Proportional zu n | Proportional zu n |
background |
transparent / opaque / auto |
auto |
Gering | Keine |
prompt |
String | Erforderlich | Komplexität beeinflusst Zeit | Beeinflusst Eingabe-Token |
Die Kernlogik dieser Tabelle: quality und size sind die entscheidenden Faktoren. Sie bestimmen direkt, welchen Pfad das Modell wählt, wie viele Token generiert werden und wie viel Rechenleistung verbraucht wird. output_format und output_compression betreffen nur die Serialisierung; eine Anpassung dieser Werte führt nicht zu einer Geschwindigkeitssteigerung.
🎯 Wichtige Empfehlung: Wenn es Ihr Anwendungsfall erlaubt, ändern Sie
quality="auto"explizit inlowodermedium. Allein dieser Schritt reduziert die Zeit oft von Minuten auf Sekunden. Bei der Nutzung vongpt-image-2über den API-Proxy-Dienst APIYI (apiyi.com) werden alle diese Parameter nativ durchgereicht, sodass das Verhalten identisch mit dem offiziellen OpenAI-Endpunkt ist.
Die 2 entscheidenden Parameter für die Laufzeit von gpt-image-2: quality und size
Um zu verstehen, warum zwischen „high“ und „low“ ein Faktor von mehreren Dutzend liegen kann, muss man den Ausführungspfad von gpt-image-2 kennen. Hier liegt der grundlegende Unterschied zur Vorgängergeneration gpt-image-1.
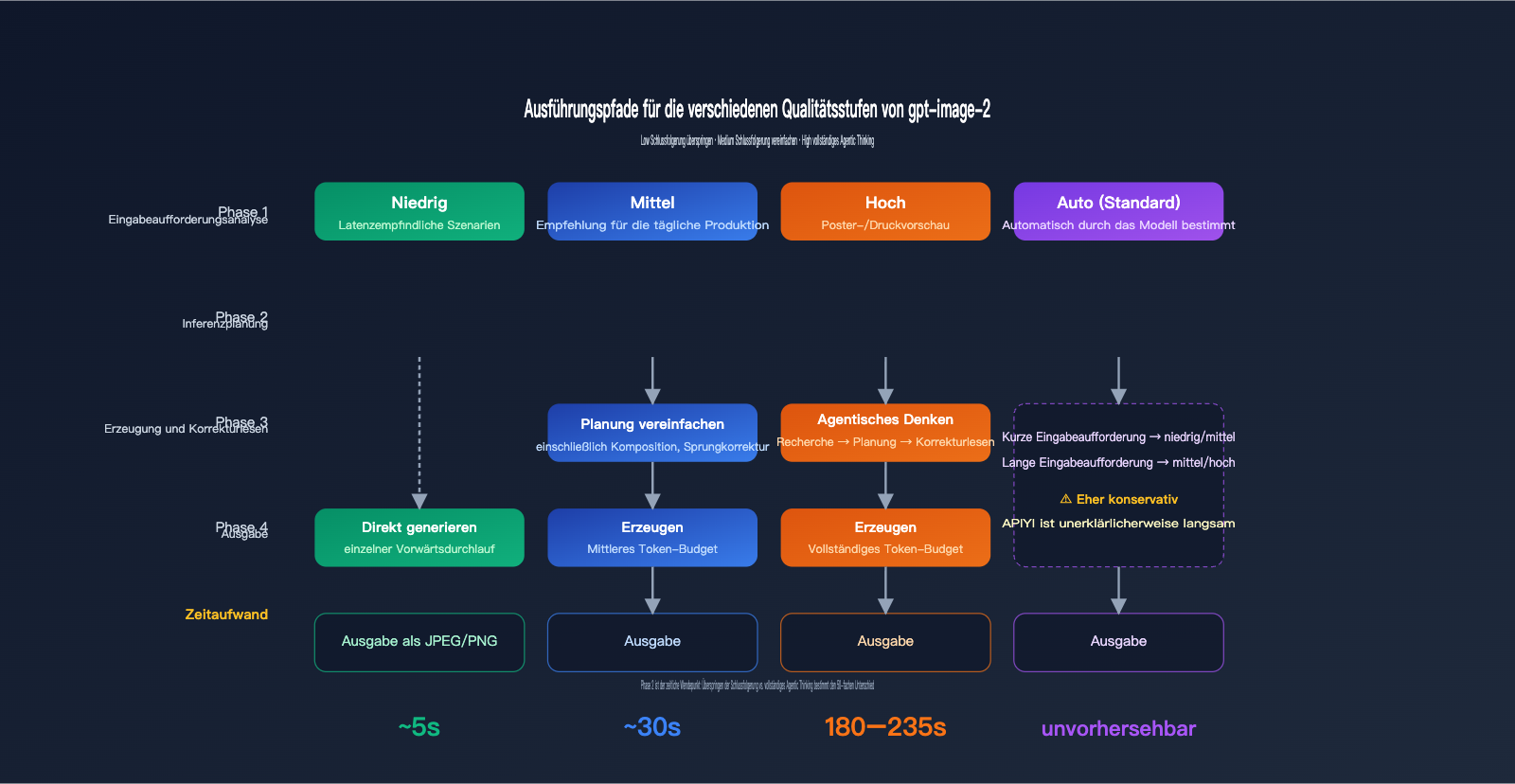
Funktionsweise des quality-Parameters
Die offizielle Dokumentation von gpt-image-2 weist explizit darauf hin, dass quality="low" für latenzkritische Szenarien konzipiert ist und bei akzeptabler visueller Qualität eine Antwort im Sekundenbereich liefert. quality="high" hingegen aktiviert eine vollständige agentische Gedankenkette (Agentic Chain of Thought) – das Modell plant intern zunächst die Komposition, das Textlayout und die Lichtlogik, bevor es mit dem Zeichnen beginnt. Diese Inferenzphase ist für das menschliche Auge unsichtbar, beansprucht jedoch etwa 70–80 % der Gesamtlaufzeit.
quality="medium" ist der Kompromiss: Es behält eine vereinfachte Planung bei, überspringt jedoch die feingranulare Überprüfung. Wenn quality="auto" gewählt wird, entscheidet das Modell basierend auf der Komplexität der Eingabeaufforderung. In der Praxis neigt es jedoch dazu, eher konservativ „medium“ oder „high“ zu wählen – das ist der Grund, warum viele Entwickler fälschlicherweise annehmen, die Standardeinstellung sei grundsätzlich langsam.
Funktionsweise des size-Parameters
gpt-image-2 unterstützt nativ die Standardgrößen 1024x1024, 1536x1024 und 1024x1536 sowie eine automatische Erkennung. Zudem können beliebige Größen übergeben werden, solange die Gesamtzahl der Pixel 2K nicht überschreitet (2560×1440 = ca. 3,69 Millionen Pixel). Jenseits dieser Schwelle bewegt man sich im experimentellen Bereich, wo die Stabilität der Ergebnisse abnimmt.
Die Anzahl der Pixel bestimmt direkt die Anzahl der visuellen Token. 1024×1024 entspricht etwa 1024 visuellen Token, 1536×1024 steigt auf ca. 1536 Token, und bei 1024×1536 verhält es sich analog. Eine Verdoppelung der Token bedeutet eine Verdoppelung der Inferenz- und Generierungszeit sowie eine Verdoppelung der Kosten.
| Standardgröße | Gesamtpixel | Visuelle Token (geschätzt) | Relative Laufzeit | Anwendungsfall |
|---|---|---|---|---|
1024x1024 |
1,05 Mio. | ~1024 | 1,0× | Allgemein, Social Media, Thumbnails |
1536x1024 |
1,57 Mio. | ~1536 | 1,5× | Banner, Artikel-Cover |
1024x1536 |
1,57 Mio. | ~1536 | 1,5× | Poster, vertikale Inhalte |
| Benutzerdef. ≤ 2K | bis 3,69 Mio. | bis ~3686 | 2–3× | Druckvorschau in hoher Auflösung |
🎯 Empfehlung zur Größe: In der Produktion sollten 95 % der Anfragen mit
1024x1024ausgeführt werden. Wechseln Sie nur für spezielle Formate wie Banner oder Poster auf die 1536er-Serie. Über den API-Proxy-Dienst APIYI (apiyi.com) sind beliebige benutzerdefinierte Größen möglich, aber achten Sie zur Stabilität darauf, unter 2K zu bleiben.
Kopplungseffekte der Parameter
quality und size wirken multiplikativ, nicht additiv. Eine Kombination aus „high“ und 1536×1024 ist nicht nur ein paar Mal, sondern dutzende Male langsamer als „low“ mit 1024×1024. Dies ist bei parallelen Anfragen kritisch: Wenn Sie 10 parallele Anfragen starten in der Erwartung, in einer Sekunde Ergebnisse zu erhalten, kann die tatsächliche Dauer 200 Sekunden betragen – der HTTP-Client läuft dann längst in ein Timeout.
Noch subtiler ist die Kopplung zwischen quality und der Komplexität der Eingabeaufforderung. Selbst bei „high“ dauert eine einfache Eingabeaufforderung (z. B. „ein roter Apfel“) etwa 100 Sekunden, während eine komplexe Eingabeaufforderung („Cyberpunk-Stadt in einer regnerischen Nacht, Neonreklamen, Film-Look, 6 interagierende Charaktere“) leicht die 230-Sekunden-Marke überschreiten kann. Das Modell erweitert sein Token-Budget dynamisch basierend auf der Anzahl der Szenenelemente. Je komplexer die Eingabeaufforderung, desto langsamer die „high“-Stufe und desto höher die Kosten.
🎯 Empfehlung für Eingabeaufforderungen: Bei der „high“-Stufe empfiehlt es sich, die Eingabeaufforderung auf unter 200 Wörter zu begrenzen und die Kernelemente in die ersten 50 Wörter zu packen. Weitschweifige Beschreibungen verbessern das Ergebnis nicht zwangsläufig, verlängern aber die Inferenzzeit. Auch bei der Nutzung über APIYI (apiyi.com) gilt diese Regel, da der API-Proxy-Dienst die Eingabeaufforderung vollständig durchreicht und das Modellverhalten dem Original entspricht.
Vergleich von Laufzeit und Kosten für gpt-image-2 Quality-Stufen
Die folgende Tabelle basiert auf Messdaten, die wir auf unserer APIYI-Plattform (apiyi.com) über verschiedene Zeiträume und bei unterschiedlicher Komplexität der Eingabeaufforderungen gesammelt haben. Die Daten können je nach Tageszeit, Eingabeaufforderung und Netzwerklast leicht schwanken, sind aber in ihrer Größenordnung verlässlich.
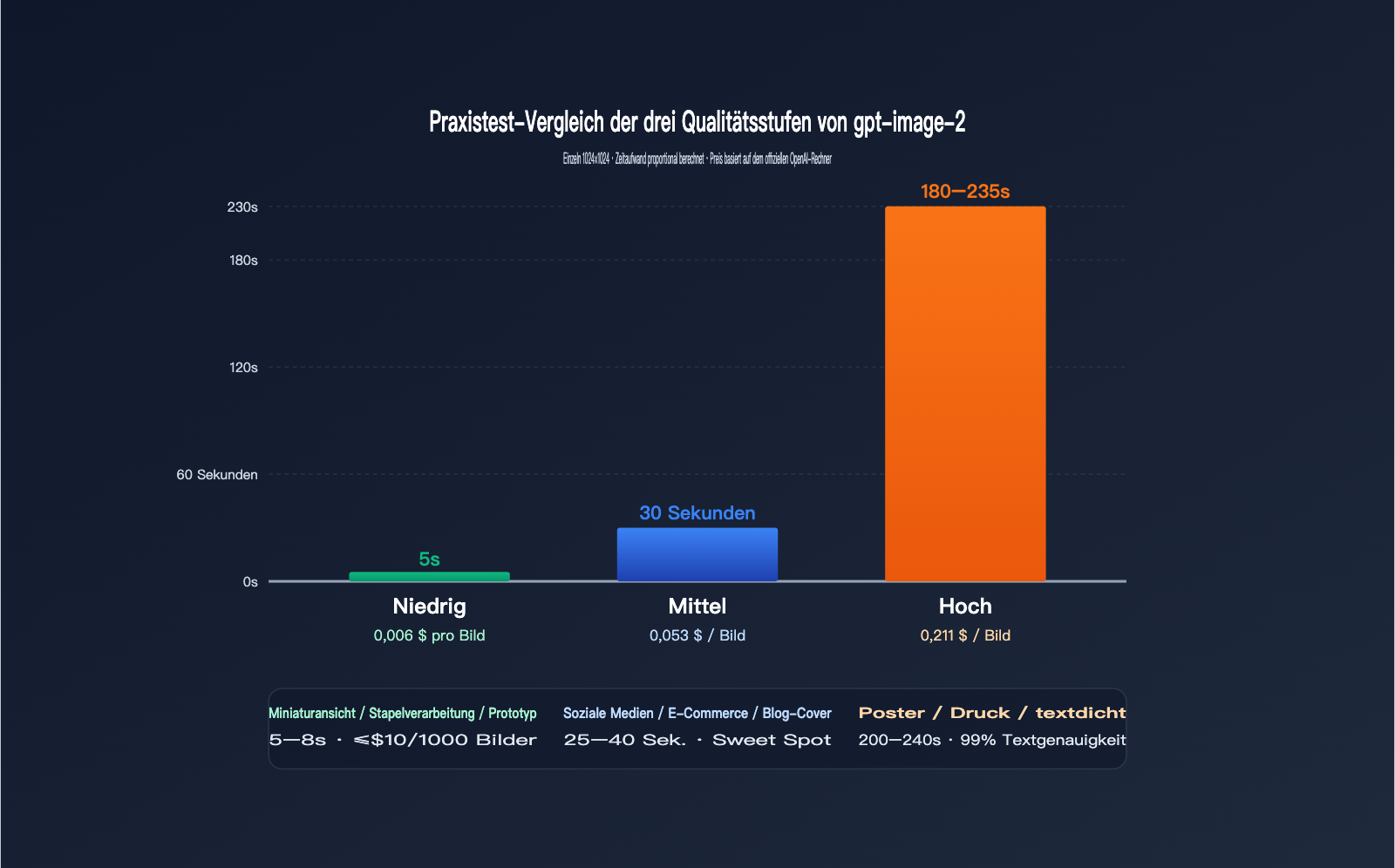
Messdaten für 1024×1024
| Quality | Ø-Laufzeit | Preis (USD/Bild) | Visuelle Präzision | Textpräzision | Anwendungsfall |
|---|---|---|---|---|---|
low |
3–8 Sek. | $0.006 | Mittel | Durchschnittlich | Thumbnails, Batch-Verarbeitung, Prototyping |
medium |
20–40 Sek. | $0.053 | Hoch | Gut | Social Media, E-Commerce, Blog-Cover |
high |
150–235 Sek. | $0.211 | Exzellent | Exzellent (>99%) | Poster, Druck, textintensive Inhalte |
Man erkennt ein deutlich nichtlineares Verhältnis: Von low zu medium steigen die Kosten um das 9-Fache, die Laufzeit jedoch nur um das 5-Fache; von medium zu high steigen die Kosten um das 4-Fache, während die Laufzeit um das 6- bis 7-Fache zunimmt. Mit anderen Worten: Die Grenzkosten für high werden mit "Wartezeit" bezahlt.
Wenn Ihr Anwendungsfall keine 99%ige Textgenauigkeit erfordert (z. B. Illustrationen, abstrakte Designs), ist medium völlig ausreichend und spart Zeit und Geld. Nur für Poster, IP-Design oder Druckvorlagen, bei denen Text und Details kritisch sind, lohnt sich die Wartezeit von 200 Sekunden für high.
🎯 Empfehlung zur Kostenkalkulation: Führen Sie vor dem Produktivstart über APIYI (apiyi.com) jeweils 100 Testläufe für
low/medium/highdurch. Erstellen Sie einen internen A/B-Bericht über Laufzeitverteilung, Kosten und Bildqualität, bevor Sie sich für eine Stufe entscheiden. Die Kosten für diesen Test liegen unter $30, verhindern aber, dass langsame Anfragen nach dem Launch Ihr gesamtes SLA gefährden.
Laufzeitunterschiede: 1024×1024 vs. 1536×1024
Bei der Stufe medium liegt der Durchschnitt bei 25 Sekunden (1024×1024) gegenüber 38 Sekunden (1536×1024). Dieser Unterschied entspricht dem Faktor von 1,5 bei der Anzahl der visuellen Token. Bei high verstärkt sich dieser Effekt jedoch: high + 1024×1024 dauert etwa 180 Sekunden, während high + 1536×1024 leicht die 240-Sekunden-Marke überschreiten kann – zu Stoßzeiten sogar noch länger.
Schwankungsbreite bei der Stufe high
Wichtig: Die Laufzeit bei high ist kein konstanter Wert, sondern unterliegt einer breiten Streuung. Bei 200 Testanfragen mit high + 1024×1024 maßen wir Werte zwischen 145 und 280 Sekunden (Median ca. 195 Sek.). Diese Schwankungen entstehen durch die Komplexität des Prompts (unterschiedliches Inferenz-Budget) und die Auslastung der OpenAI-Backend-Server. Daher sollte high niemals synchron aufgerufen werden – implementieren Sie es als asynchronen Task, bei dem das Frontend eine Task-ID erhält und das Backend per Polling oder Callback informiert.
Ein häufiger Irrtum: Höhere Auflösung bedeutet bessere Bildqualität
Viele Entwickler nehmen intuitiv an, dass eine höhere Auflösung automatisch zu besserer Qualität führt, und wählen standardmäßig die 1536er-Reihe. Das ist ein Trugschluss. Die Bildqualität von gpt-image-2 ist bei 1024×1024 bereits optimal ausgereizt. Der Wechsel zur 1536er-Reihe ändert lediglich das Seitenverhältnis; die tatsächlich auf dem Bildschirm dargestellten Details nehmen nicht zu. Sofern Sie kein spezielles Breitbild- oder Hochformat benötigen, bleibt 1024×1024 die wirtschaftlichste Wahl.
Vollständiges Beispiel für den Aufruf von gpt-image-2 mit dem Python SDK
Im Folgenden finden Sie drei Code-Beispiele, die vom einfachen Aufruf bis zur produktionsreifen Kapselung reichen. Alle Beispiele basieren auf dem offiziellen OpenAI Python SDK, wobei die base_url auf den API-Proxy-Dienst von APIYI (apiyi.com) verweist. Das Verhalten ist identisch mit den offiziellen Endpunkten.
Basis-Beispiel: Einfache Text-zu-Bild-Generierung
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="Cyberpunk-Stadt in einer regnerischen Nacht, Neonreklamen, filmisches Bildformat",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
Dieser Code reicht für einen ersten Test aus, birgt aber eine Falle: quality="high" in Kombination mit dem Standard-Timeout führt fast zwangsläufig zu Fehlern. Das Standard-HTTP-Timeout des OpenAI Python SDK liegt bei 600 Sekunden. Das klingt zwar ausreichend, aber viele Nutzer, die requests oder httpx verwenden und ein eigenes 60-Sekunden-Timeout setzen, erhalten bei massenhaften Anfragen im "high"-Modus häufig ReadTimeout-Fehler.
Produktions-Beispiel: Explizites Timeout und Wiederholungsversuche
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
Praxistipps:
timeout=300ist ein sicherer Wert für den "high"-Modus und deckt 99 % der Anfragen ab. Wenn Sie nur "low" oder "medium" nutzen, können Sie den Wert auf 60 senken.max_retries=2nutzt das integrierte exponentielle Backoff des SDK, was stabiler ist als eine manuelle Implementierung.output_format="jpeg"+output_compression=85reduziert die Dateigröße im Vergleich zu PNG oft um 60–70 %, ohne dass die Bildqualität für das menschliche Auge merklich leidet – besonders empfehlenswert für Web-Vorschaubilder.
🎯 Timeout-Empfehlung: Bei der Nutzung über APIYI (apiyi.com) hat die Plattform bereits Mechanismen zur Aufrechterhaltung der Verbindung bei langwierigen Anfragen implementiert. Dennoch muss das Timeout im Client-SDK zwingend manuell gesetzt werden und darf nicht auf den Standardwerten belassen werden. Für den "high"-Modus werden mindestens 240 Sekunden empfohlen, für den "low"-Modus können Sie auf 30 Sekunden reduzieren, um zu verhindern, dass blockierte Anfragen den Verbindungspool lahmlegen.
Batch-Beispiel: Asynchrone parallele Generierung
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["Katze", "Hund", "Vogel", "Fisch", "Hase"] * 4))
Parallelisierung ist der wichtigste Trick für die massenhafte Bilderzeugung. Im "low"-Modus dauert ein Bild 5 Sekunden; bei 20 Bildern seriell wären das 100 Sekunden, mit 5 parallelen Threads nur 20 Sekunden. Achten Sie jedoch darauf, die Qualität auf "low" oder "medium" zu begrenzen – parallele Anfragen im "high"-Modus führen unweigerlich zu Timeout-Problemen.
Empfohlene Parameter für gpt-image-2 in verschiedenen Geschäftsszenarien
Nach der Theorie folgt die Praxis. Hier sind die optimalen Parameterkombinationen für häufige Anwendungsfälle:
| Geschäftsszenario | quality | size | output_format | Erwartete Dauer | Preis pro Bild |
|---|---|---|---|---|---|
| E-Commerce/Banner | medium | 1024×1024 | jpeg+85 | 25–35s | $0.053 |
| Social Media | medium | 1024×1536 | jpeg+85 | 30–40s | ~$0.06 |
| Blog-Titelbild | medium | 1536×1024 | webp+90 | 30–40s | ~$0.06 |
| Poster/Druckvorschau | high | 1024×1536 | png | 200–240s | ~$0.21 |
| Untertitel/PPT | high | 1536×1024 | png | 200–240s | ~$0.21 |
| Thumbnails/Prototyp | low | 1024×1024 | jpeg+75 | 3–8s | $0.006 |
| Batch-Skizzen | low | 1024×1024 | jpeg+75 | 3–8s × N | $0.006 × N |
| AI-Assistent (sofort) | low | 1024×1024 | webp+85 | 5–10s | $0.006 |
Szenario 1: E-Commerce und Social Media – "medium" ist der Sweet Spot
E-Commerce-Bilder und Social-Media-Content sind zeitkritisch (Nutzer möchten nicht 4 Minuten warten), erfordern aber dennoch eine hohe Qualität. "medium" ist hier die beste Wahl.
Szenario 2: Poster und Druckvorschau – Zeit für "high" investieren
Poster oder Cover mit viel Text und komplexen Layouts erfordern die volle "Agentic"-Denkleistung des Modells. Hier sollten Sie keine Zeit sparen und dem Nutzer eine entsprechende Rückmeldung geben (z. B. "Ergebnis in 3–5 Minuten verfügbar").
Szenario 3: Batch-Verarbeitung und Prototyping – "low" ist Pflicht
Wenn Sie über Nacht 10.000 Skizzen generieren müssen, ist "low" alternativlos. In Kombination mit asynchroner Parallelisierung und JPEG-Kompression erreichen Sie einen hohen Durchsatz.
Szenario 4: Sofortige Nutzerinteraktion – "low" oder "medium"
Bei Chatbots oder KI-Assistenten darf niemals "high" verwendet werden. Ein Nutzer, der 4 Minuten wartet, wird die Seite wahrscheinlich verlassen. Nutzen Sie "low" und eine Ladeanimation, um Ergebnisse in 5–8 Sekunden zu liefern.
Szenario 5: Inhaltsprüfung und Compliance
Wenn eine Anfrage durch die Inhaltsrichtlinien von OpenAI blockiert wurde, testen Sie den neuen Prompt zunächst im "low"-Modus. Erst nach erfolgreicher Prüfung sollten Sie auf "medium" oder "high" für das finale Bild hochstufen.
🎯 Hybrid-Strategie: Viele Produktionssysteme nutzen eine "Zwei-Stufen-Generierung": Zuerst wird im "low"-Modus ein Vorschaubild zur Auswahl erstellt, und erst nach der Auswahl des Nutzers wird das finale Bild im "high"-Modus generiert. Diese Strategie lässt sich auf APIYI (apiyi.com) sehr reibungslos umsetzen, da ein einziger API-Schlüssel alle Qualitätsstufen abdeckt.
Häufig gestellte Fragen (FAQ)
F1: Warum kommt es bei meinen „high“-Anfragen immer zu Timeouts?
Das Standard-Timeout des OpenAI Python SDK beträgt 600 Sekunden. Theoretisch ist das ausreichend, aber viele Frameworks (FastAPI, Flask, Celery) fügen auf ihrer Ebene eigene Timeouts hinzu. Bitte überprüfen Sie die Timeout-Einstellungen in jedem Schritt der gesamten Aufrufkette. Für die „high“-Stufe empfehlen wir ein Zeitlimit von mindestens 300 Sekunden für den gesamten Prozess. Wenn Sie httpx verwenden, denken Sie daran, httpx.Timeout(300.0) explizit zu setzen.
F2: Welcher Wert für output_compression ist am besten?
Bei JPEG ist 85 der „Sweet Spot“ – der Unterschied zu 100 ist mit bloßem Auge kaum erkennbar, aber die Dateigröße reduziert sich um 30–40 %. Bei WebP ist 90 ein gängiger Wert. Werte unter 70 führen zu sichtbaren Artefakten, insbesondere bei Farbverläufen im Hintergrund. Dieser Parameter beeinflusst nicht die Generierungszeit, sondern nur die endgültige Serialisierung der Ausgabe.
F3: Gibt es Unterschiede zwischen dem Aufruf von gpt-image-2 über APIYI (apiyi.com) und dem offiziellen Endpunkt?
Parameter und Verhalten werden vollständig durchgereicht, einschließlich aller Felder wie quality, size, output_format, output_compression, n und background. Der Unterschied besteht darin, dass APIYI (apiyi.com) in China erreichbare Hochgeschwindigkeitsknoten, eine einheitliche Abrechnung und eine nutzungsbasierte Zahlung ohne Mindestumsatz bietet, was für Entwickler in China deutlich komfortabler ist.
F4: Kann der Parameter n mehrere Bilder auf einmal zurückgeben?
Ja, gpt-image-2 unterstützt n=1 bis n=10. Beachten Sie jedoch: Die Gesamtdauer für mehrere Bilder entspricht etwa dem 0,7- bis 0,9-Fachen der Zeit für ein einzelnes Bild multipliziert mit n (es ist keine vollständige Parallelisierung), und der Gesamtpreis wird mit dem Faktor n berechnet. Wenn Sie eine „zusammenhängende Gruppe von Charakteren“ benötigen, ist die Verwendung von n=4 stabiler als vier separate Aufrufe, da gpt-image-2 die Gesichtskonsistenz innerhalb einer einzigen Inferenz besser beibehalten kann.
F5: Welche Stufe wird bei quality="auto" tatsächlich gewählt?
In der Praxis tendiert auto dazu, medium oder high zu wählen, abhängig von der Länge und Komplexität der Eingabeaufforderung. Kurze Eingabeaufforderungen (z. B. „a cat“) führen meist zu low/medium, während lange Eingabeaufforderungen (mit Personen, Szenen, Text, Stil) eher zu high führen. Für Produktionsumgebungen empfehlen wir, den Wert explizit anzugeben, anstatt sich auf die implizite Entscheidung von auto zu verlassen.
F6: Welche Bildqualität ist besser: 1024×1536 oder 1536×1024?
Beide haben die gleiche Gesamtzahl an Pixeln (ca. 1,57 Millionen), die Bildqualität ist also identisch. Der Unterschied liegt lediglich im Seitenverhältnis: Hochformat (1024×1536) eignet sich für Poster, Ganzkörperporträts und mobile Inhalte; Querformat (1536×1024) eignet sich für Banner, Landschaften und PC-Cover. Die Wahl hängt von Ihren Anforderungen an die Komposition ab und beeinflusst weder Geschwindigkeit noch Preis.
F7: Kann ich die Inferenz überspringen und direkt auf das zugrunde liegende Modell zugreifen?
Nein, die agentische Inferenz von gpt-image-2 ist ein fester Bestandteil der Modellarchitektur und kann nicht deaktiviert werden. Wenn Sie lediglich eine schnelle Bilderzeugung im klassischen SD-Stil benötigen und keine Text-Rendering- oder Inferenzfunktionen brauchen, empfehlen wir die low-Stufe, da diese die vollständige Inferenzkette überspringt. Alternativ können Sie sich das Modell nano-banana-pro von Google ansehen; dessen schnelle Stufe ist noch flotter als gpt-image-2 low. APIYI (apiyi.com) hat dieses Modell ebenfalls bereits integriert.
🎯 Empfehlung zur Multi-Modell-Strategie: Professionelle Systeme zur Bilderzeugung nutzen meist nicht nur ein Modell. Wir empfehlen
nano-banana-profür schnelle Vorschauen (Reaktionszeit im 5-Sekunden-Bereich),gpt-image-2 mediumfür den Haupt-Traffic undgpt-image-2 highfür hochwertige Szenen. Alle drei Modelle nutzen bei APIYI (apiyi.com) denselben API-Schlüssel und werden nutzungsbasiert abgerechnet – die wirtschaftlichste Kombination für die Bild-API-Integration im Jahr 2026.
Fazit: Parameter als Leistungsregler, nicht als Dekoration
Das Designkonzept von gpt-image-2 unterscheidet sich grundlegend von der vorherigen Generation von Bildmodellen: Die Inferenz ist ein zentraler Schritt der Bilderzeugung. Daher ist quality kein einfacher Schalter für „gute oder schlechte Qualität“, sondern ein Regler dafür, „wie tief der Inferenzpfad durchlaufen wird“. Wenn Sie dies verstehen, begreifen Sie, warum dieselbe API eine Zeitspanne von 5 bis 235 Sekunden (ein Faktor von 50) abdecken kann.
In der Praxis empfehlen wir, die „Parameterauswahl“ als ersten Schritt des Systemdesigns zu betrachten: Überlegen Sie sich genau, welche Latenz tolerierbar ist, welche Bildqualität benötigt wird und wo das Preislimit liegt. Danach wählen Sie quality und size anhand der Tabellen. Diese Parameter vorab festzulegen ist deutlich stressfreier, als sie nach dem Livegang optimieren zu müssen.
🎯 Abschließende Empfehlung: Wenn Sie mit der Integration von
gpt-image-2beginnen, registrieren Sie sich bei APIYI (apiyi.com) und führen Sie einen Vergleichstest der drei Stufenlow/medium/highdurch. Bewerten Sie die gemessene Zeit und die Bildqualität, bevor Sie sich für die Parameter für Ihren Haupt-Traffic entscheiden. Ein API-Schlüssel für alle drei Stufen, nutzungsbasierte Abrechnung und kein Mindestumsatz – das ist der effizienteste Weg für die Bild-API-Integration im Jahr 2026.
— APIYI Technik-Team | Wir verfolgen kontinuierlich die Dynamik der Bildgenerierungsmodelle. Weitere tiefgehende Tutorials finden Sie im APIYI (apiyi.com) Hilfe-Center.