Anmerkung des Autors: Tiefgehende Analyse der 5 wichtigsten Durchbrüche von Qwen-Image-2.0, dem vereinheitlichten Modell für Bildgenerierung und -bearbeitung. Zu den technischen Highlights gehören die leichtgewichtige 7B-Architektur, native 2K-Auflösung, lange Eingabeaufforderungen mit bis zu 1000 Token sowie ein Leitfaden für den API-Zugriff und die praktische Anwendung.
Das Tongyi-Team von Alibaba hat am 10. Februar 2026 Qwen-Image-2.0 veröffentlicht. Dies ist ein bedeutendes Upgrade, das Bildgenerierung und Bildbearbeitung in einem einzigen Modell vereint. Besonders beeindruckend ist, dass die Anzahl der Parameter von 20B der Vorgängergeneration massiv auf 7B reduziert wurde, während die Leistung gleichzeitig umfassend gesteigert werden konnte. APIYI ist derzeit autorisierter Partner von Alibaba Cloud und arbeitet aktuell an der Anbindung. Wir gehen davon aus, dass der Dienst bald online geht, wobei wir auch preisliche Vorteile bieten können.
Kernwert: Durch diese detaillierte Analyse erfahren Sie mehr über die 5 wichtigsten Durchbrüche von Qwen-Image-2.0, die realen Unterschiede zu Konkurrenzprodukten und wie Sie das Modell schnell über eine API integrieren können.
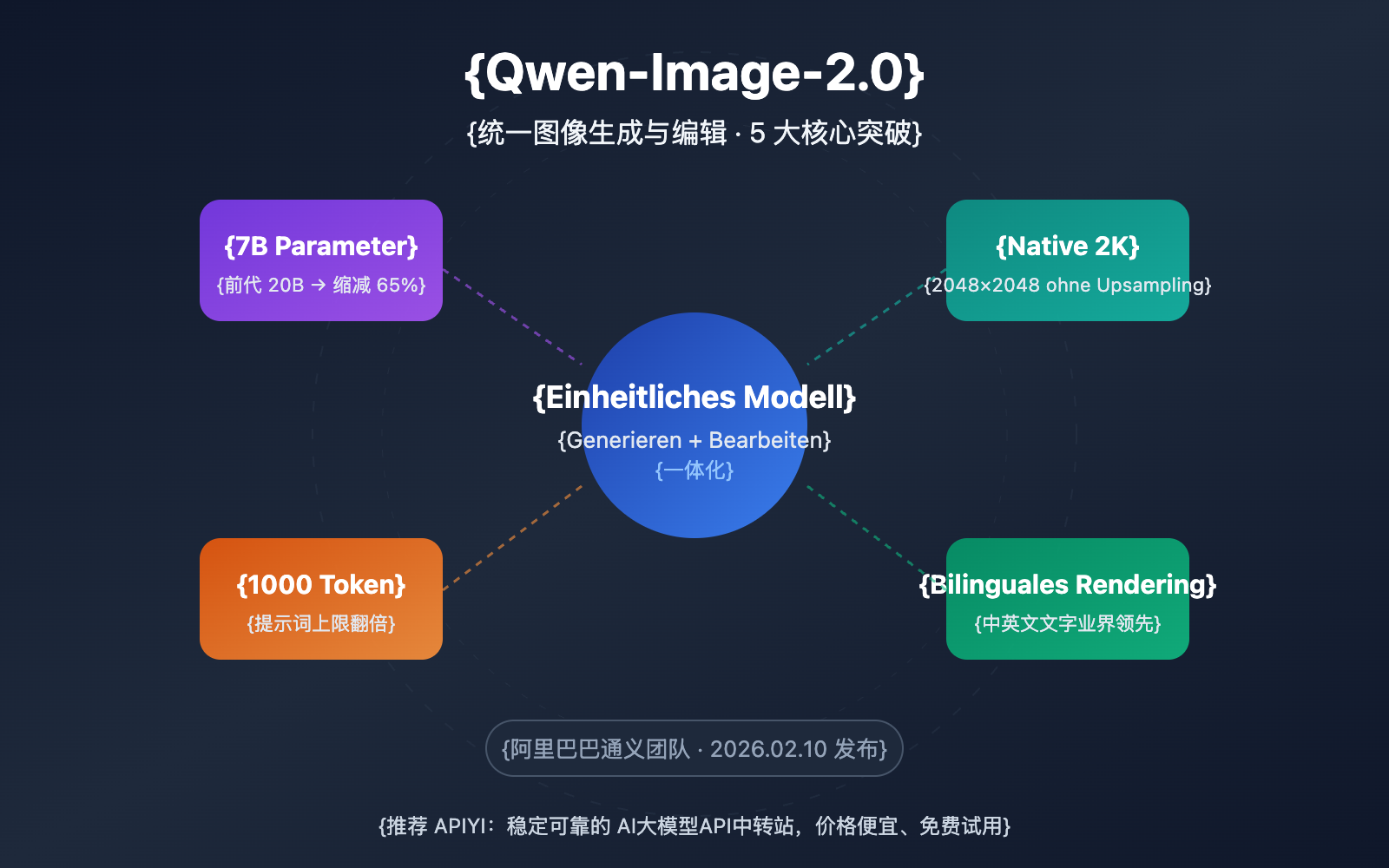
Qwen-Image-2.0 Kernpunkte im Überblick
| Punkt | Beschreibung | Vorteil |
|---|---|---|
| Vereinte Generierung + Bearbeitung | Text-zu-Bild und Bildbearbeitung in einem einzigen 7B-Modell vereint | Kein separates Laden von zwei Modellen nötig, deutlich geringere Bereitstellungskosten |
| 65% Parameter-Reduktion | Von 20B der Vorgängergeneration auf 7B (Diffusion-Decoder) optimiert | Schnellere Inferenz, deutlich geringerer VRAM-Bedarf |
| Native 2K-Auflösung | Unterstützt native Ausgabe von bis zu 2048×2048 Pixeln | Kein Upsampling erforderlich, höhere Detailschärfe |
| 1000 Token Eingabeaufforderung | Verdoppelung des Limits (Vorgänger ca. 500 Token) | Ermöglicht komplexere Szenenbeschreibungen und präzisere Steuerung |
| Bilinguales Text-Rendering | Branchenführende Textgenerierung in Chinesisch und Englisch | Hervorragende Ergebnisse bei Postern, Infografiken und textlastigen Szenarien |
Analyse der Kerntechnologie von Qwen-Image-2.0
Qwen-Image-2.0 nutzt ein völlig neues Dual-Komponenten-Architekturdesign: Das visuelle Sprachmodell Qwen3-VL mit 8B Parametern dient als Konditionierungs-Encoder, während ein MMDiT (Multimodal Diffusion Transformer) mit 7B Parametern als Diffusion-Decoder fungiert. Dieses Design ermöglicht es dem Modell, semantische Informationen aus Text- und Bildmodalitäten tiefgreifend zu verstehen und durch den Diffusionsprozess hochwertige Bilder zu generieren.
Der größte Unterschied zum Vorgänger Qwen-Image-2512 liegt in der vereinheitlichten Trainingsstrategie – Text-zu-Bild (T2I) und Bildbearbeitung (I2I/TI2I) werden in einem gemeinsamen Vorwärtspass kombiniert. Das bedeutet, dass ein einziges Modell Aufgaben erledigen kann, für die zuvor zwei separate Modelle (Qwen-Image für die Generierung und Qwen-Image-Edit für die Bearbeitung) erforderlich waren. Dies reduziert sowohl die Bereitstellungskosten als auch die Komplexität erheblich.
Detaillierte Analyse der fünf zentralen Durchbrüche von Qwen-Image-2.0
Durchbruch 1: Einheitliche Architektur für Generierung und Bearbeitung
Dies ist die markanteste Innovation von Qwen-Image-2.0. Während die Vorgängergeneration separate Modelle für die Text-zu-Bild-Generierung und die Bildbearbeitung pflegen musste, vereint die Version 2.0 beide Funktionen in einem:
| Fähigkeit | Vorgängerlösung | Qwen-Image-2.0 |
|---|---|---|
| Text-zu-Bild | Qwen-Image-2512 (20B) | Einheitliches Modell (7B) |
| Bildbearbeitung | Qwen-Image-Edit-2511 (20B) | Einheitliches Modell (7B) |
| Stilübertragung | Separates Bearbeitungsmodell | Direkt durch einheitliches Modell unterstützt |
| Multi-Bild-Synthese | Separates Bearbeitungsmodell | Direkt durch einheitliches Modell unterstützt |
| Gesamter VRAM-Bedarf | Laden von 2 x 20B Modellen erforderlich | Nur 1 x 7B Modell erforderlich |
In der Praxis bedeutet das: Sie können zuerst mit einer Eingabeaufforderung ein Bild generieren und anschließend direkt dasselbe Bild bearbeiten – etwa den Stil ändern, Objekte hinzufügen oder entfernen oder Posen anpassen –, ohne das Modell wechseln zu müssen.
Durchbruch 2: Leistungsüberholung mit nur 7B Parametern
Die Reduzierung von 20B auf 7B Parameter (beim Diffusion-Decoder) entspricht einer Verringerung der Parameteranzahl um 65 %, doch die Bildqualität ist paradoxerweise gestiegen. Der Schlüssel hierzu liegt in der tiefgreifenden semantischen Verständnisleistung des Qwen3-VL-Encoders. Das visuelle Sprachmodell mit 8B Parametern übernimmt im Schritt des "Bedarfsverständnisses" deutlich mehr Arbeit, sodass sich der Diffusion-Decoder effizienter auf die reine "Bildgenerierung" konzentrieren kann.
Für Entwickler bedeutet dies:
- Höhere Inferenzgeschwindigkeit: API-Aufrufe dauern ca. 5–8 Sekunden pro Bild.
- Geringerer VRAM-Bedarf: Voraussichtlich reichen 24 GB VRAM für den Betrieb aus (der Vorgänger benötigte 48 GB+).
- Reduzierte Bereitstellungskosten: Ein Betrieb auf Consumer-GPUs mit einer Karte ist in greifbare Nähe gerückt.
Durchbruch 3: Natives 2K High-Resolution
Qwen-Image-2.0 unterstützt nativ eine Ausgabeauflösung von 2048×2048, ohne dass zusätzliche Super-Resolution-Upsampling-Schritte erforderlich sind. Es werden 7 Standard-Seitenverhältnisse unterstützt:
| Seitenverhältnis | Auflösung | Empfohlene Szenarien |
|---|---|---|
| 16:9 | 1664×928 | Video-Cover, Blog-Illustrationen (Standard) |
| 1:1 | 1328×1328 | Social-Media-Avatare, Produkt-Hauptbilder |
| 9:16 | 928×1664 | Handy-Hintergrundbilder, Short-Video-Cover |
| 4:3 | 1472×1104 | Klassische Querformat-Anzeige |
| 3:4 | 1104×1472 | Klassische Hochformat-Anzeige |
| 3:2 | 1584×1056 | Querformat im Fotografie-Stil |
| 2:3 | 1056×1584 | Hochformat im Fotografie-Stil |
Durchbruch 4: Lange Eingabeaufforderungen mit bis zu 1000 Token
Das Limit für Eingabeaufforderungen wurde von ca. 500 Token beim Vorgänger auf 1000 Token verdoppelt. Dieser zusätzliche Spielraum ermöglicht es Ihnen, weitaus komplexere Szenen zu beschreiben. In Praxistests erwies sich dies als besonders wertvoll für:
- Professionelle Infografiken: Präzise Steuerung von Layout-Positionen, Textinhalten und Farbkombinationen.
- Szenen mit mehreren Objekten: Gleichzeitige Beschreibung der Positionsbeziehungen und Interaktionsdetails mehrerer Objekte.
- Stil-Fusion: Detaillierte Beschreibung der gewünschten künstlerischen Stile und Texturanforderungen.
Durchbruch 5: Führendes bilinguales Text-Rendering
Qwen-Image-2.0 ist branchenführend bei der Generierung von Text innerhalb von Bildern, insbesondere beim chinesischen Rendering. Es unterstützt verschiedene Schriftstile wie Kaishu, den Shoujin-Stil (Schlanke Gold-Schrift) und Xiaozhuan (Kleine Siegelschrift). Dies bietet klare Vorteile in folgenden Bereichen:
- Design von Marketing-Postern und Werbegrafiken.
- Technische Diagramme mit chinesischen Beschriftungen.
- Bild-Text-Inhalte für soziale Medien.
- Erstellung von Brand Visual Materials.
🎯 Praktischer Hinweis: Qwen-Image-2.0 befindet sich derzeit in der API-Einladungsphase. APIYI (apiyi.com) arbeitet aktiv an der Integration. Sobald verfügbar, wird der Dienst zu einem Preis angeboten, der 20 % unter dem der offiziellen Website liegt, und unterstützt einheitliche Aufrufe im OpenAI-kompatiblen Format. Bleiben Sie gespannt.
Qwen-Image-2.0 Quick Start
Minimalistisches Beispiel
Hier ist die grundlegende Methode zum Aufrufen von Qwen-Image-2.0 über die API zur Bildgenerierung (basierend auf dem DashScope API-Format):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen-image-2.0",
messages=[{
"role": "user",
"content": "Ein Shiba Inu mit Sonnenbrille surft am Strand, sonniges Wetter, hochauflösender Fotografie-Stil"
}]
)
print(response.choices[0].message.content)
DashScope Native API-Aufrufbeispiel anzeigen
from dashscope import MultiModalConversation
import os
response = MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-image-max",
messages=[{
"role": "user",
"content": [{
"text": "Moderner, minimalistischer Schreibtisch mit Laptop und Grünpflanze, weiches natürliches Licht"
}]
}],
size="1328*1328",
prompt_extend=True,
watermark=False
)
image_url = response.output.choices[0].message.content[0]["image"]
print(f"Bild-URL: {image_url}")
# Hinweis: Die URL ist 24 Stunden gültig, bitte rechtzeitig herunterladen und speichern
Empfehlung: APIYI (apiyi.com) integriert derzeit Qwen-Image-2.0. Nach der Freischaltung wird der Aufruf im OpenAI-kompatiblen Format unterstützt. Mit einem einzigen API-Key können Sie dann verschiedene Bildgenerierungsmodelle wie GPT Image 1.5, Gemini 3 Pro Image, FLUX.2 und weitere vergleichen und testen.
Qwen-Image-2.0 im Vergleich mit Wettbewerbern
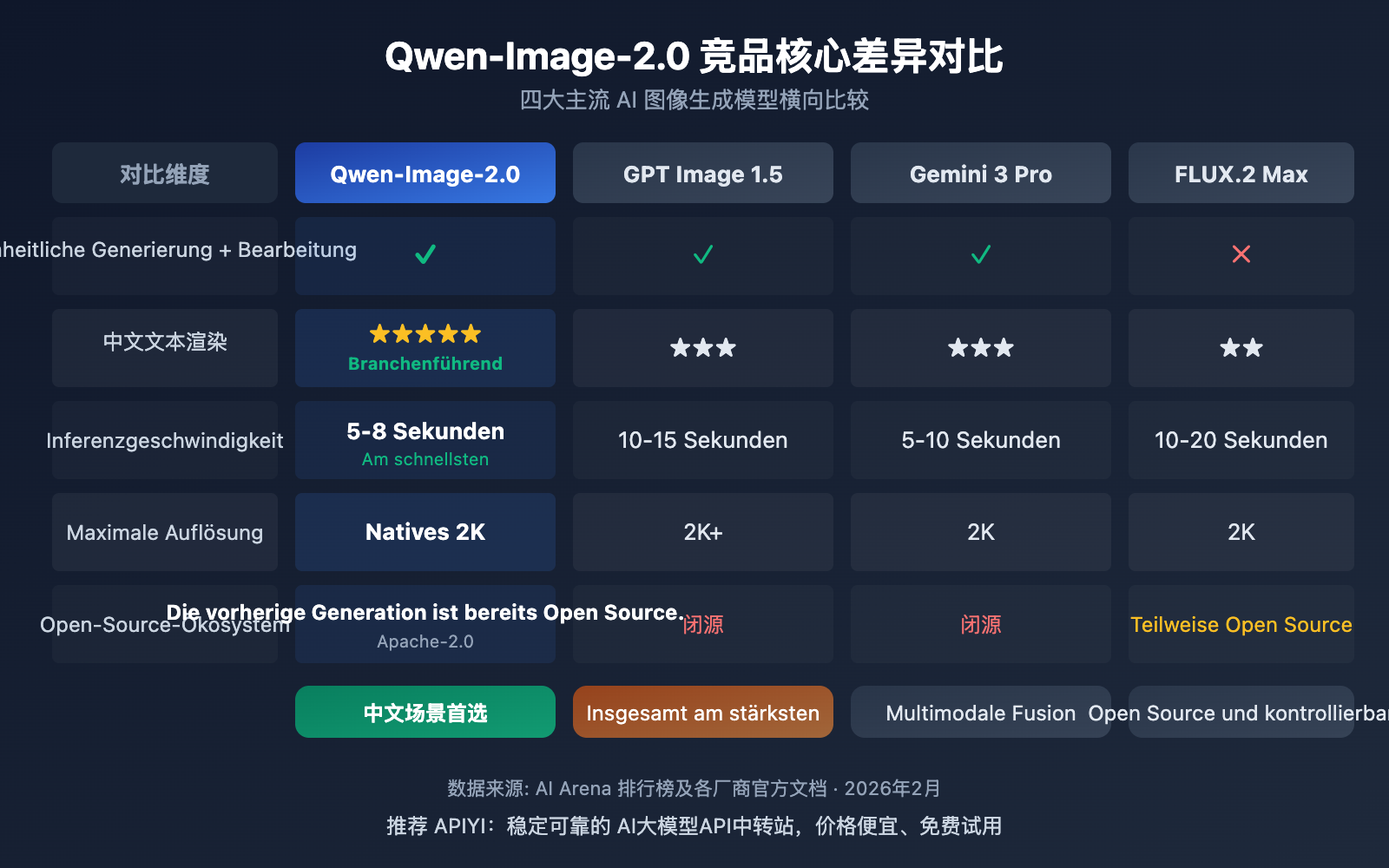
| Vergleichsaspekt | Qwen-Image-2.0 | GPT Image 1.5 | Gemini 3 Pro Image | FLUX.2 Max |
|---|---|---|---|---|
| Entwickler | Alibaba | OpenAI | Black Forest Labs | |
| Unified Generierung + Bearbeitung | ✅ | ✅ | ✅ | ❌ |
| Max. Auflösung | 2K | 2K+ | 2K | 2K |
| Chinesisches Text-Rendering | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| Inferenz-Geschwindigkeit | 5–8 Sek. | 10–15 Sek. | 5–10 Sek. | 10–20 Sek. |
| Open-Source-Ökosystem | Vorgänger bereits Open Source | Closed Source | Closed Source | Teilweise Open Source |
| API-Preisreferenz | Über 20 % günstiger als offiziell (APIYI) | 0,04–0,08 $/Bild | Abrechnung nach Token | 0,04 $/Bild |
Differenzierte Vorteile von Qwen-Image-2.0:
- Stärkste Performance in chinesischen Kontexten: Die branchenführenden zweisprachigen Text-Rendering-Fähigkeiten sorgen dafür, dass chinesische Poster und Infografiken deutlich besser gelingen als bei der Konkurrenz.
- Leichteste Architektur: Mit nur 7B Parametern wird eine Qualität auf Augenhöhe mit GPT Image 1.5 erreicht, was zu deutlich geringeren Inferenzkosten führt.
- Open-Source-Potenzial: Da die gesamte Vorgängerserie unter Apache-2.0 veröffentlicht wurde, ist ein Open-Source-Release der Version 2.0 sehr wahrscheinlich.
- Reichhaltiges Ökosystem: Mit über 2.380 Likes auf HuggingFace, mehr als 484 verfügbaren LoRA-Adaptern und einer äußerst aktiven Community.
Erläuterung zum Vergleich: Die obigen Daten basieren auf öffentlichen technischen Dokumentationen und dem AI Arena Leaderboard. Wir empfehlen, die Performance der verschiedenen Modelle in Ihrem spezifischen Szenario über die Plattform APIYI (apiyi.com) praktisch zu testen.
Empfohlene Anwendungsszenarien für Qwen-Image-2.0
Das Modell eignet sich ideal für die folgenden Szenarien:
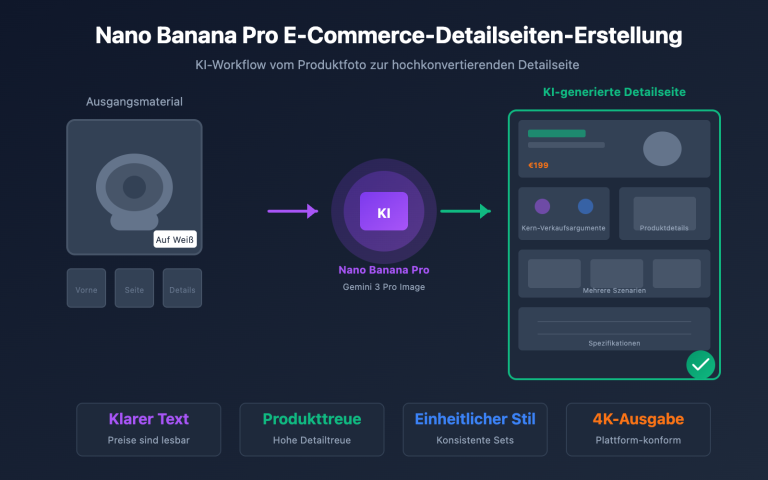
- E-Commerce-Produktbilder: Ein einheitliches Modell für die Generierung von Produktbildern und den Austausch von Hintergründen vereinfacht den Workflow erheblich. Ideal für E-Commerce-Operations und Design-Teams.
- Design von Marketingmaterialien: Poster, Social-Media-Grafiken und Werbemittel – die starke Darstellung chinesischer Schriftzeichen ist hier ein entscheidender Wettbewerbsvorteil. Ideal für Marketing-Teams.
- Kreativdesign: Unterstützt verschiedene Kunststile wie Fotorealismus, Anime, Aquarell, Handzeichnung usw. Lange Eingabeaufforderungen mit bis zu 1000 Token ermöglichen eine präzise Steuerung der kreativen Richtung. Ideal für Designer und Content-Ersteller.
- Erstellung technischer Diagramme: Professionelle Inhalte wie PPT-Folien, Infografiken und Flussdiagramme mit pixelgenauem Layout. Ideal für technische Dokumentationsteams.
🎯 Szenario-Empfehlung: Wenn Ihr Geschäft die Generierung großer Mengen an chinesischen Bild- und Textinhalten umfasst, ist Qwen-Image-2.0 derzeit die beachtenswerteste Wahl. Wir empfehlen, praktische Vergleichstests über die Plattform APIYI (apiyi.com) durchzuführen, um die beste Lösung für Ihre spezifischen Anforderungen zu finden.
Versionsentwicklung und Preisgestaltung von Qwen-Image-2.0
Zeitplan der Versionsentwicklung
Seit der Veröffentlichung der ersten Version im August 2025 hat die Qwen-Image-Serie einen Rhythmus mit hoher Iterationsfrequenz beibehalten:
| Version | Zeitpunkt | Kern-Upgrades |
|---|---|---|
| Qwen-Image v1 | 08.2025 | Erstveröffentlichung 20B MMDiT, Open Source unter Apache-2.0 |
| Qwen-Image-Edit | 08.2025 | Hinzufügen eines speziellen Bearbeitungsmodells |
| Qwen-Image-2512 | 12.2025 | Verbesserte fotorealistische Texturen und Textdarstellung |
| Qwen-Image-2.0 | 02.2026 | Einheitliche Architektur, 7B-Leichtbauweise, natives 2K |
Preisreferenz
| Kanal | Modell | Referenzpreis |
|---|---|---|
| Alibaba Cloud DashScope | qwen-image-max | ¥ 0,50 / Bild |
| Alibaba Cloud DashScope | qwen-image-plus | ¥ 0,20 / Bild |
| Replicate | Qwen Image | $ 0,030 / Bild |
| Fal.ai | Qwen Image Edit | $ 0,021 / Bild |
| APIYI (demnächst) | Qwen-Image-2.0 | Mehr als 20 % Rabatt gegenüber offiziellen Preisen |
💡 Die offizielle Preisgestaltung für die finale Version von Qwen-Image-2.0 wurde noch nicht bekannt gegeben. APIYI (apiyi.com) arbeitet aktiv an der Integration und wird Vorzugspreise anbieten, die mindestens 20 % unter den offiziellen Preisen liegen. Registrieren Sie sich jetzt, um sich ein kostenloses Testguthaben zu sichern. Bleiben Sie gespannt!
Häufig gestellte Fragen
Q1: Was ist der Unterschied zwischen Qwen-Image-2.0 und Qwen-Image-2512?
Der größte Unterschied besteht darin, dass die Version 2.0 Generierung und Bearbeitung in einem einzigen 7B-Parameter-Modell vereint. Die Vorgängerversion 2512 war ein reines Text-zu-Bild-Modell mit 20B Parametern, wobei für die Bildbearbeitung zusätzlich Qwen-Image-Edit geladen werden musste. Die Version 2.0 unterstützt zudem eine native 2K-Auflösung und lange Eingabeaufforderungen von bis zu 1000 Token, bei deutlichen Verbesserungen der Bildqualität und Textdarstellung.
Q2: Ist Qwen-Image-2.0 bereits über eine API verfügbar?
Aktuell befindet es sich in der geschlossenen Beta-Phase für die API; über chat.qwen.ai kann es kostenlos online getestet werden. APIYI (apiyi.com) arbeitet gerade an der Integration. Nach dem Start wird dort ein Preis angeboten, der 20 % unter dem offiziellen Preis liegt. Die API ist OpenAI-kompatibel, sodass mit einem einzigen Key mehrere Bildgenerierungsmodelle verglichen werden können.
Q3: Eignet sich Qwen-Image-2.0 für das lokale Deployment?
Die Gewichte von Qwen-Image-2.0 sind derzeit noch nicht Open Source. Da die Vorgängerversionen jedoch unter der Apache-2.0-Lizenz veröffentlicht wurden, geht die Community davon aus, dass auch die Version 2.0 quelloffen sein wird. Die 7B-Parametergröße bedeutet, dass das Modell voraussichtlich auf Consumer-GPUs (24 GB VRAM) lauffähig sein wird. Während Sie auf die Open-Source-Veröffentlichung warten, empfiehlt es sich, die Ergebnisse vorab schnell via API über APIYI (apiyi.com) zu validieren.
Zusammenfassung
Die Kernpunkte von Qwen-Image-2.0:
- Vereinheitlichte Architektur als Highlight: Ein 7B-Modell erledigt sowohl Generierung als auch Bearbeitung, während die Vorgängergeneration noch zwei 20B-Modelle benötigte.
- Leichtgewicht ohne Qualitätsverlust: Trotz einer Reduzierung der Parameter um 65 % wurden die Bildqualität und der Funktionsumfang umfassend verbessert.
- Unverzichtbar für chinesische Kontexte: Zweisprachige Textdarstellung und Unterstützung verschiedener Schriftarten machen es zur ersten Wahl für die Erstellung chinesischer Bild-Text-Inhalte.
- API-Zugang in Kürze: Derzeit in der Testphase, die offizielle Version folgt bald.
Qwen-Image-2.0 stellt einen bedeutenden Durchbruch für chinesische KI-Bildgenerierungsmodelle dar. Für Teams, die hochwertige chinesische Bild-Text-Inhalte benötigen, ist dies derzeit eines der spannendsten Modelle.
Wir empfehlen, die neuesten Entwicklungen und Vorzugspreise (20 % günstiger als beim Hersteller) über APIYI (apiyi.com) zu verfolgen. Die Plattform bietet kostenloses Guthaben und eine einheitliche Schnittstelle für mehrere Modelle, was den schnellen Vergleich und die Validierung erleichtert.
📚 Referenzen
-
Offizieller Qwen-Blog: Ankündigung zur Veröffentlichung von Qwen-Image-2.0
- Link:
qwen.ai/blog?id=qwen-image-2.0 - Beschreibung: Offizielle technische Analyse und Funktionsvorstellung
- Link:
-
GitHub-Repository: Qwen-Image Projekt-Homepage
- Link:
github.com/QwenLM/Qwen-Image - Beschreibung: Open-Source-Code, technische Dokumentation und Benutzerhandbuch
- Link:
-
AI Arena Leaderboard: Rankings für Text-zu-Bild und Bildbearbeitung
- Link:
arena.ai/leaderboard/text-to-image - Beschreibung: Unabhängige Rankings von Drittanbietern, Daten werden in Echtzeit aktualisiert
- Link:
-
Alibaba Cloud API-Dokumentation: DashScope Bildgenerierungs-API
- Link:
help.aliyun.com/zh/model-studio/qwen-image-api - Beschreibung: Offizielle API-Integrationsdokumentation und Parameterbeschreibung
- Link:
Autor: Technik-Team
Technischer Austausch: Diskussionen im Kommentarbereich sind willkommen. Weitere Informationen finden Sie in der APIYI (apiyi.com) Technik-Community.