Die Eingabeaufforderung-Zwischenspeicherung (Prompt Caching) ist im Jahr 2026 zu einem entscheidenden Kostenfaktor für alle Nutzer von Großes Sprachmodell-APIs geworden. Bei einer RAG-Anwendung, die beispielsweise eine 8K-System-Eingabeaufforderung verwendet, kann der Unterschied zwischen aktivierter und deaktivierter Zwischenspeicherung die monatliche Rechnung um mehr als das Zehnfache variieren. Viele Entwickler, die zwischen OpenAI und Anthropic wechseln, stolpern jedoch über ein verstecktes Detail: Die Abrechnungsmodelle für die Zwischenspeicherung unterscheiden sich grundlegend.

Der entscheidende Unterschied lässt sich in einem Satz zusammenfassen: Bei der GPT-Serie wird das Schreiben in den Cache zum Basispreis (1x) ohne Aufschlag berechnet, während bei der Claude-Serie für das Schreiben ein Aufschlag von 1,25x (5 Minuten) oder 2x (1 Stunde) erhoben wird. Dieser Unterschied scheint gering, beeinflusst aber bei realem Geschäftsvolumen den Break-Even-Punkt erheblich. Dieser Artikel basiert auf einem Abgleich der offiziellen Dokumentationen beider Anbieter und erläutert Abrechnungsregeln, Auslösebedingungen, Leserabatte, TTL-Strategien und Rentabilitätsberechnungen, um Ihnen eine präzisere Kostenschätzung zu ermöglichen.
Die 5 Kernunterschiede bei der Zwischenspeicherung von Eingabeaufforderungen zwischen GPT und Claude
Hier direkt das Fazit. Die folgende Tabelle ist der wichtigste Teil dieses Artikels; sie fasst die 5 am häufigsten übersehenen Punkte beim Caching zusammen, um einen direkten Vergleich zu ermöglichen.
| Dimension | OpenAI GPT | Anthropic Claude |
|---|---|---|
| Schreibkosten | 1x Basispreis, kein Aufschlag | 5 Min: 1,25x; 1 Std: 2x |
| Lesekosten | ca. 0,1x (bis zu 90% Rabatt) | 0,1x (Preis nach 10% Rabatt) |
| Auslöser | Vollautomatisch, kein Code-Update | Explizites Opt-in, erfordert cache_control |
| Mindest-Token-Schwelle | Einheitlich 1024 Token | 1024 / 2048 / 4096 (modellabhängig) |
| Cache TTL | Standard 5–10 Min. Leerlauf, max. 1 Std.; erweiterter Modus 24 Std. | Standard 5 Minuten, optional 1 Stunde (2x Schreiben) |
Das Verständnis dieser Tabelle hängt von der Zeile "Schreibkosten" ab. Die Logik von OpenAI lautet: Das Caching ist für Sie kostenlos; der erste Schreibvorgang wird zum Basispreis berechnet, und jeder Treffer ab dem zweiten Mal gewährt einen Rabatt. Sobald also ein Treffer erzielt wurde, befinden Sie sich sofort im Gewinnbereich. Die Logik von Claude lautet: Für das Schreiben muss zuerst ein Aufschlag gezahlt werden, der bei Treffern durch Rabatte erstattet wird – es sind also "ausreichend viele Treffer" erforderlich, um den Aufschlag zu amortisieren.
🎯 Konfigurationsempfehlung: Wenn Ihr Geschäftsvolumen unvorhersehbar ist und die Trefferquote instabil bleibt, empfiehlt es sich, das automatische Caching von GPT zu bevorzugen, um Risiken zu minimieren. Wenn die Trefferquote sehr stabil ist (z. B. bei Kundenservice, Agenten oder der Analyse langer Dokumente), kann die explizite Steuerung von Claude höhere Rabatte erzielen. Beide Modell-APIs sind über APIYI (apiyi.com) verfügbar; Sie können Vergleichstests mit demselben Token durchführen, ohne mehrere Konten eröffnen zu müssen.
Detaillierte Erläuterung des Abrechnungsmechanismus für OpenAI GPT Prompt Caching
Die offizielle Dokumentation von OpenAI beschreibt das Prompt Caching sehr direkt: „Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature.“ Übersetzt bedeutet das: Automatische Aktivierung, keine zusätzlichen Kosten, keine einzige Zeile Code muss geändert werden.
Abrechnung von GPT-Cache-Schreib- und Lesevorgängen
Die GPT-Serie erhebt keinen Aufpreis für das Schreiben in den Cache. Wenn Sie zum ersten Mal eine 8K-System-Eingabeaufforderung senden, wird der Basis-Eingabepreis berechnet – genau wie ohne aktiviertes Caching. Ab dem zweiten Mal erkennt das System, dass dieser Präfix bereits zwischengespeichert wurde, und berechnet den Trefferanteil mit einem Rabatt von etwa 90 % gegenüber dem Basispreis.
| Projekt | Abrechnungsmodus | Verhältnis zum Basispreis |
|---|---|---|
| Erstmaliges Schreiben | Basis-Eingabepreis | 1x (kein Aufpreis) |
| Cache-Treffer (Lesen) | Cache-Treffer-Rabatt | ca. 0,1x |
| Aktivierungsgebühr | Komplett kostenlos | 0 |
| Code-Anpassungen | Null | Keine erforderlich |
Der tatsächliche Rabatt wird offiziell mit „bis zu 90 %“ angegeben und variiert je nach Modell und Preisliste leicht. Zum Beispiel liegt der Basis-Eingabepreis für GPT-5.4 bei 2 $/1M Token, während der Preis bei einem Cache-Treffer 0,20 $/1M Token beträgt, was exakt 10 % entspricht. Auch GPT-4.1, GPT-4o und andere unterstützte Modelle folgen im Wesentlichen diesem Verhältnis.
🎯 Preisprüfung: Da OpenAI seine Modelle häufig aktualisiert, gelten für den tatsächlichen Trefferrabatt die offiziellen Preislisten. Es wird empfohlen, die aktuell gültigen Preise direkt im Modell-Marktplatz von APIYI (apiyi.com) zu prüfen. Die Plattform synchronisiert offizielle Anpassungen in Echtzeit und erhebt keine zusätzlichen Vermittlungsgebühren; Entwickler rechnen einfach nach dem tatsächlichen Token-Verbrauch ab.
Bedingungen für GPT-Cache-Treffer
Damit ein Cache-Treffer ausgelöst wird, müssen zwei Bedingungen gleichzeitig erfüllt sein:
- Die Länge der Eingabeaufforderung beträgt ≥ 1024 Token (kürzere Eingaben werden nicht zwischengespeichert).
- Der Präfix der Eingabeaufforderung muss exakt mit der vorherigen Anfrage übereinstimmen; Treffer werden in 128-Token-Schritten verarbeitet.
OpenAI legt die kleinste Granularität für Cache-Treffer auf 128 Token fest. Das bedeutet, dass bei einem stabilen Präfix von 1500 Token, solange die ersten 1024 Token identisch sind, der Rest in 128er-Schritten schrittweise zwischengespeichert wird. Der Nachteil dieses automatisierten Designs ist die geringere Kontrolle – Entwickler können nicht explizit festlegen, „welcher Teil unbedingt zwischengespeichert werden soll“, sondern müssen alle stabilen Inhalte an den Anfang stellen.
TTL-Verhalten beim GPT-Cache
OpenAI macht eine entscheidende Angabe zur TTL (Time-to-Live): Cache-Präfixe werden normalerweise nach 5–10 Minuten Inaktivität gelöscht und maximal 1 Stunde aufbewahrt. Neuere Modelle wie GPT-5 und GPT-4.1 unterstützen zudem eine „erweiterte Aufbewahrung“ (extended retention) von bis zu 24 Stunden.
🎯 Nutzungshinweis: Bei der Anbindung der GPT-Serie über APIYI (apiyi.com) ist die automatische Caching-Strategie von OpenAI für den API-Proxy-Dienst transparent; die Trefferquote ist identisch mit der direkten Verbindung zum offiziellen Endpunkt. Das bedeutet, Sie können die Abrechnung und Token-Verwaltung für OpenAI und Claude über APIYI zentralisieren, ohne zusätzliche Kosten zu verursachen.
Detaillierte Erläuterung des Abrechnungsmechanismus für Anthropic Claude Prompt Caching
Die Designphilosophie von Claude ist das genaue Gegenteil von OpenAI – Caching wird als „aktiv konfigurierbare Optimierungsfunktion“ betrachtet. Entwickler müssen explizit deklarieren, welche Inhalte wie lange zwischengespeichert werden sollen. Der Preis dafür ist ein Aufschlag beim Schreiben, der Vorteil ist eine extrem hohe Kontrollgranularität.
Schreibaufschlag und Leserabatt beim Claude-Cache
| Projekt | Abrechnungsfaktor | Erläuterung |
|---|---|---|
| 5 Minuten Schreiben | 1,25x Basis-Eingabepreis | Standard-TTL, deckt die meisten Szenarien ab |
| 1 Stunde Schreiben | 2x Basis-Eingabepreis | Geeignet für lange Sitzungen, Agenten usw. |
| Cache-Treffer (Lesen) | 0,1x Basis-Eingabepreis | 90 % Rabatt |
| Aktivierungsgebühr | 0 | Keine zusätzliche Einrichtungsgebühr |
| Konfigurationsänderung | cache_control erforderlich |
Explizites Opt-in |
Ein anschauliches Beispiel: Der Basis-Eingabepreis für Claude Opus 4.7 liegt bei 5 $/1M Token. Das Schreiben mit 5 Minuten TTL kostet 6,25 $/1M, mit 1 Stunde TTL 10 $/1M, während der Cache-Treffer nur 0,50 $/1M kostet. Diese Preisliste ist in der offiziellen Dokumentation von Anthropic verankert und seit mehreren Quartalen stabil.
Minimale Token-Schwelle für Claude-Cache
Die minimale Anzahl an Token, die für Claude zwischengespeichert werden können, variiert je nach Modell – eine häufige Fehlerquelle.
| Modell | Minimale Cache-Token |
|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 |
| Claude Haiku 4.5 | 4096 |
| Claude Sonnet 4.6 | 2048 |
| Claude Sonnet 4.5 / Opus 4.1 / Sonnet 4 | 1024 |
Wenn Ihr stabiler Präfix unter der Mindestschwelle des Modells liegt, wird er selbst bei hinzugefügtem cache_control nicht in die Cache-Ebene aufgenommen. Die Anfrage wird stillschweigend als Nicht-Cache-Pfad behandelt – es gibt keine Fehlermeldung, aber das Caching findet faktisch nicht statt. Dies ist besonders bei Opus 4.7 wichtig: 4096 Token sind eine hohe Hürde, die bei kurzen Dialogen kaum erreicht wird.
🎯 Empfehlung zur Modellauswahl: Wenn die Kontextlänge Ihres Geschäftsmodells instabil ist, empfiehlt sich Claude Sonnet 4.5 oder 4.6, da diese eine niedrigere Mindestschwelle haben und Treffer leichter zu erzielen sind. Über APIYI (apiyi.com) können Sie per Klick zwischen Sonnet und Opus wechseln, um zu vermeiden, dass das Caching aufgrund von Modellschwellenwerten wirkungslos bleibt.
Breakpoints und Nebenläufigkeitsbeschränkungen beim Claude-Cache
Claude erlaubt das Setzen von bis zu 4 Cache-Breakpoints in einer einzigen Anfrage, wobei für jeden Breakpoint eine unterschiedliche TTL festgelegt werden kann. Dies ist die stärkste Funktion, die Claude von GPT unterscheidet – Sie können die „System-Eingabeaufforderung“ für 1 Stunde, „Wissensdatenbank-Fragmente“ für 5 Minuten und den „Benutzerkontext“ gar nicht zwischenspeichern lassen. Alle drei Teile werden unabhängig voneinander abgerechnet und laufen unabhängig ab.
Bei gleichzeitigen Anfragen (Concurrency) ist ein Punkt besonders wichtig: Cache-Einträge von Claude werden erst wirksam, nachdem die erste Antwort zu fließen beginnt. Wenn Sie N Anfragen mit identischem Präfix parallel senden, wird nur die erste in den Cache geschrieben, während die restlichen N-1 Anfragen zum Basispreis abgerechnet werden (kein Trefferrabatt). Bei Batch-Aufrufen ist es daher ratsam, zuerst eine einzelne Anfrage zu senden, um den Cache-Schreibvorgang auszulösen, und erst danach die restlichen Anfragen parallel zu starten.
🎯 Empfehlung für Batch-Aufrufe: Wenn Sie Claude über APIYI (apiyi.com) aufrufen, empfiehlt es sich, vor dem Start paralleler Batches eine einzelne „Aufwärm“-Anfrage zu senden, um den Cache-Schreibvorgang zu initiieren. Sobald die Antwort beginnt, können Sie die parallelen Anfragen starten. Dies vermeidet unnötige Schreibaufschläge und schont Ihr Budget erheblich.
Auswirkungen von Schreibaufschlägen auf die tatsächliche Rechnung: Berechnung des Break-Even-Punkts
In diesem Abschnitt rechnen wir die abstrakten Faktoren in konkrete Geldbeträge um. Wir nehmen eine stabile System-Eingabeaufforderung von 10.000 Token an, die innerhalb eines 1-Stunden-Fensters N-mal angefragt wird, wobei die Ausgabe einheitlich 500 Token beträgt. Wir vergleichen die Gesamtkosten beider Anbieter bei unterschiedlichem N.
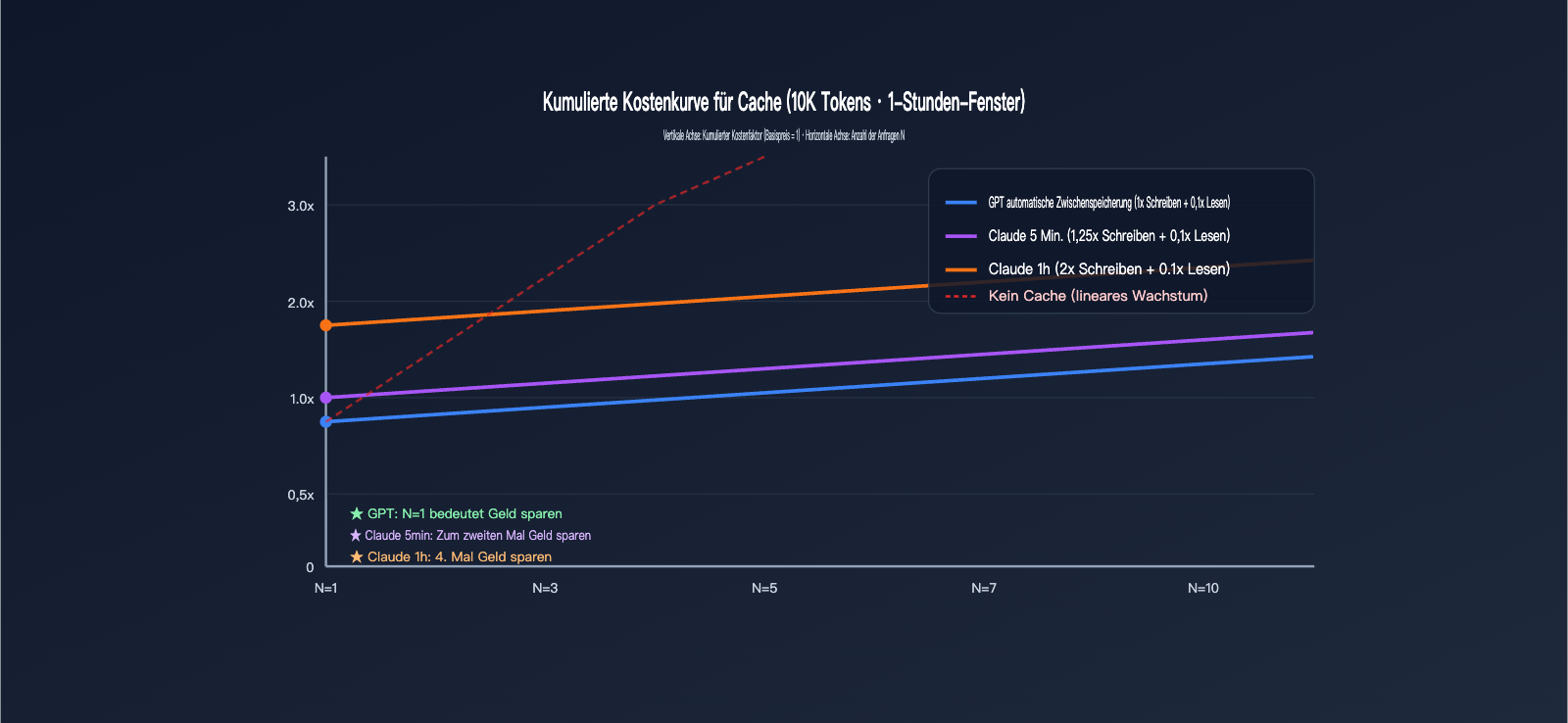
Zum Vergleich nehmen wir an, dass die Basis-Eingabepreise beider Anbieter auf $X/1M Token normalisiert sind. Die Basiskosten für 10.000 Token pro Anfrage betragen = 10 × $X / 1000 = $0,01X. Im Folgenden betrachten wir nur den Teil der Eingabecache-Abrechnung und ignorieren die Ausgabe (diese wird nach den jeweiligen Preisen der Anbieter berechnet).
| Anzahl der Anfragen N | GPT Automatischer Cache | Claude 5-Min-Cache | Claude 1-Std-Cache |
|---|---|---|---|
| N=1 (Erstes Schreiben) | $0,01X | $0,0125X | $0,02X |
| N=2 | $0,011X | $0,0135X | $0,021X |
| N=5 | $0,014X | $0,0165X | $0,024X |
| N=10 | $0,019X | $0,0215X | $0,029X |
| Ohne Cache (Referenz) | $0,01X × N | $0,01X × N | $0,01X × N |
| Erforderliche Lesevorgänge für Break-Even | 0-mal (spart ab dem ersten Mal) | 1-mal (spart ab dem 2. Mal) | 3-mal (spart ab dem 4. Mal) |
Ein entscheidender Fakt wird deutlich: GPT-Caching ist bereits bei N=1 rentabel – da das Schreiben mit 1x berechnet wird und bei einem Treffer ein Rabatt gewährt wird, ist es immer ein Gewinn. Der 5-Minuten-Cache von Claude benötigt mindestens einen Treffer, um den Schreibaufschlag von 0,25x auszugleichen, der 1-Stunden-Cache benötigt drei Treffer. Wenn Ihr stabiler Präfix nur einmal am Tag abgerufen wird, ist der 1-Stunden-Cache von Claude teurer als gar kein Caching.
Wie wählt man die TTL im realen Geschäftsbetrieb?
Diese Berechnung liefert klare praktische Empfehlungen:
- Niedrige, unregelmäßige Frequenz: Bevorzugen Sie den automatischen GPT-Cache, das spart ohne Aufwand.
- Hohe Frequenz, mehrere Treffer innerhalb von 5 Minuten (z. B. Kundenservice-Chats, Web-Apps): Der 5-Minuten-Cache von Claude maximiert den Nutzen – geringer Schreibaufschlag, hohe Rabatte beim Lesen.
- Lange Aufgaben, mehrfache Wiederverwendung über eine Stunde hinweg (z. B. Coding Agent, Dialoge über lange Dokumente): Der 1-Stunden-Cache von Claude lohnt sich, erfordert aber mindestens 3 Treffer.
- Unsichere Trefferquote: Fangen Sie immer mit 5 Minuten an und ziehen Sie erst nach erfolgreichem Test eine Verlängerung auf 1 Stunde in Betracht.
🎯 Berechnungsempfehlung: Das Backend von APIYI (apiyi.com) bietet Statistiken zum Feld
cached_tokenspro Anfrage, mit denen Sie Ihre tatsächliche Trefferquote direkt ablesen können. Es empfiehlt sich, die Produktionsdaten eine Woche lang zu beobachten, bevor Sie die TTL aggressiv auf 1 Stunde erhöhen.
Empfohlene Caching-Strategien für verschiedene Geschäftsszenarien
Nachdem die Abrechnungsunterschiede verstanden sind, können wir sie auf konkrete Szenarien anwenden. Hier sind die gängigen Szenarien nach empfohlenen Strategien kategorisiert.
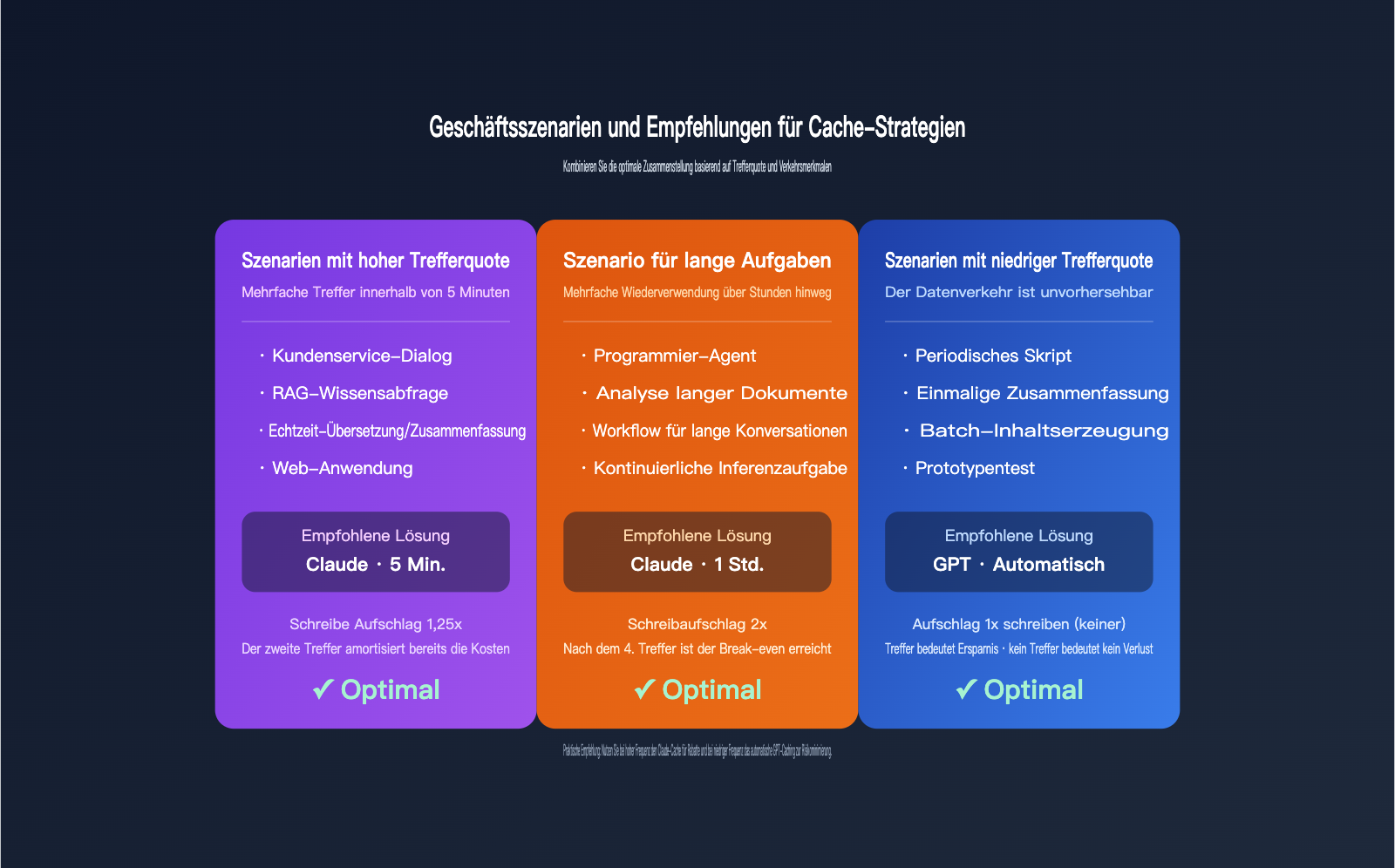
Szenario 1: Hochfrequentes RAG und Unternehmens-Wissensdatenbanken
Stabile Präfixe enthalten hier meist System-Prompts und Wissensdatenbank-Fragmente. Innerhalb einer Sitzung gibt es oft mehrere Treffer, und innerhalb von 5 Minuten werden leicht mehr als 10 Anfragen erreicht. Der 5-Minuten-Cache von Claude kann hier die Eingabekosten um über 80 % senken. Bei einstündigen Sitzungen ist der 1-Stunden-Cache zu prüfen.
Szenario 2: Coding Agents und lange Workflows
Bei Coding Agents wie Claude Code oder OpenCode können Aufgaben eine halbe Stunde oder länger dauern, wobei wiederholt auf Projektstrukturen, CLAUDE.md oder frühere Tool-Ergebnisse zugegriffen wird. Hier ist der 1-Stunden-Cache von Claude die beste Wahl, da die Anzahl der Treffer weit über dem Break-Even-Punkt von 3 liegt.
Szenario 3: Niedrige oder unvorhersehbare Anfragen
Bei periodischen Skripten, der Erstellung von SEO-Artikeln in Batches oder einmaligen Zusammenfassungen langer Dokumente liegen die Abstände oft weit über 5 Minuten. Hier empfiehlt sich der GPT-Cache – er ist fehlertoleranter, da er keine explizite Konfiguration erfordert und bei Treffern sofort spart.
Szenario 4: Kostenoptimierte reine Eingabekompression
Wenn das Hauptziel darin besteht, 10K+ Token-Prompts zu minimalen Kosten zu verarbeiten, nutzen Sie Claude Sonnet 4.6 mit 5-Minuten-Cache: Der Schreibaufschlag beträgt nur 25 %, und nach einem Treffer amortisiert sich dies bereits. Die Lesekosten sinken auf $0,075/1M.
| Geschäftsszenario | Empfohlene Modellfamilie | Empfohlene TTL | Grund |
|---|---|---|---|
| Kundenservice/RAG | Claude Sonnet | 5 Minuten | Häufige Treffer, schnelle Amortisation |
| Coding/Agent-Aufgaben | Claude Sonnet/Opus | 1 Stunde | Über 3 Treffer pro Stunde |
| Skripte/Batch-Verarbeitung | GPT-4.1 / GPT-5.x | Automatisch | Instabile Treffer, kein Schreibaufschlag |
| Einmalige Dokumentenanalyse | GPT-5.x | Automatisch | Einmalige Aufgabe, niedrige Trefferquote |
| Kostenoptimierte Szenarien | Claude Sonnet 4.6 | 5 Minuten | Niedrigster effektiver Cache-Preis |
🎯 Empfehlung zur hybriden Architektur: In der Produktion müssen Sie sich nicht zwischen GPT und Claude entscheiden. Nutzen Sie APIYI (apiyi.com) als zentralen Einstiegspunkt und routen Sie Anfragen dynamisch: hohe Trefferwahrscheinlichkeit zu Claude (mit Cache), niedrige zu GPT (automatischer Cache). So lassen sich die Gesamtkosten um über 40 % senken.
Häufig gestellte Fragen (FAQ)
F1: Verlangt GPT wirklich keinen Aufpreis für das Schreiben in den Cache? Ist das in einer anderen Gebühr versteckt?
Ja, die offizielle Dokumentation von OpenAI besagt: „No. Caching happens automatically, with no explicit action needed or extra cost paid to use the caching feature.“ Das Schreiben in den Cache wird zum Standard-Eingabepreis abgerechnet, ohne versteckte Aufschläge. Sie zahlen den reduzierten Preis nur für den Teil, der im Cache gefunden wird (Cache-Hit), und den Standardpreis für den Rest – das Cache-Feature ist also quasi „kostenlos“ dabei.
F2: Bezieht sich der 1,25-fache bzw. 2-fache Schreibaufschlag bei Claude auf die gesamte Eingabeaufforderung oder nur auf den Cache-Teil?
Nur auf den Teil, der mit cache_control explizit für den Cache markiert wurde. Wenn beispielsweise von 10K Token nur 8K als Cache markiert sind, gilt der 1,25-fache Aufschlag nur für diese 8K; die restlichen 2K werden zum 1-fachen Standardpreis abgerechnet. Es empfiehlt sich daher, die Breakpoints präzise zu setzen, um unnötige Inhalte nicht in den Aufschlag einzubeziehen.
F3: Werden die Cache-Gebühren beider Anbieter über den API-Proxy-Dienst von APIYI vollständig durchgereicht?
APIYI (apiyi.com) reicht die Cache-Abrechnung für GPT und Claude nativ durch. Die Rabatte für GPT-Cache-Hits sowie die 1,25x/2x-Schreib- und 0,1x-Lesegebühren bei Claude entsprechen exakt den offiziellen Abrechnungen. Auch das Feld cache_control wird unterstützt, sodass Entwickler ihren offiziellen SDK-Code direkt weiterverwenden können.
F4: Wann ist der 1-Stunden-Cache bei Claude teurer als gar kein Cache?
Wenn die tatsächliche Trefferquote innerhalb des 1-Stunden-Fensters bei weniger als 3 liegt, amortisiert sich der Aufschlag (2x Schreiben) für den 1h-Cache nicht. Wenn eine Eingabeaufforderung beispielsweise nur beim Start und beim Beenden durch den Nutzer aufgerufen wird (also 2-mal am Tag), kostet der 1h-Cache mehr als ohne Cache. In solchen Szenarien sollten Sie entweder auf einen 5-Minuten-Cache umsteigen oder das Caching komplett deaktivieren.
F5: Könnte der automatische Cache von GPT meine Daten aus der Eingabeaufforderung preisgeben?
Die Dokumentation von OpenAI stellt klar, dass der Cache auf Organisationsebene isoliert ist und nicht über Konten hinweg geteilt wird. Claude hat dies seit dem 05.02.2026 auf eine Isolierung auf Workspace-Ebene verschärft. Beide Anbieter verfolgen beim Datenschutz ähnliche Ansätze, sodass Unternehmenskunden sicher sein können. Bei der Nutzung über APIYI (apiyi.com) wird dieser Schutz durch eine zusätzliche Isolierung auf Token-Ebene weiter verstärkt.
F6: Wie kann ich die Cache-Trefferquote überwachen? Bieten beide Anbieter entsprechende Felder an?
OpenAI gibt das Feld cached_tokens im usage-Objekt zurück. Claude liefert im usage-Objekt die Felder cache_creation_input_tokens (geschriebene Cache-Token) und cache_read_input_tokens (Treffer). Es empfiehlt sich, diese Felder in Ihre Geschäftslogs zu schreiben, um ein Dashboard für die Trefferquote zu erstellen und die TTL-Strategie entsprechend anzupassen.
F7: Wie konfiguriere ich die Token, wenn mein Projekt sowohl GPT als auch Claude nutzt?
Wir empfehlen die einheitliche Token-Lösung von APIYI (apiyi.com), bei der ein einziger sk-xxx-Schlüssel sowohl GPT als auch Claude abdeckt. Die Abrechnung im Backend kann pro Modell eingesehen werden, was den Aufwand für separate Konten, Guthabenverwaltung und Buchhaltung erspart. Diese zentrale Anbindung erleichtert zudem A/B-Tests, um die tatsächlichen Kosten beider Modelle für denselben Anwendungsfall zu vergleichen.
Fazit: Das Verständnis des Schreibaufschlags ist der erste Schritt zur Cache-Optimierung
Zurück zum Kernpunkt dieses Artikels: Der wesentliche Unterschied in der Cache-Abrechnung zwischen GPT und Claude liegt im Preismodell für das Schreiben. GPT setzt auf „reibungslose, automatische Aktivierung ohne Schreibaufschlag“, während Claude auf „explizite Kontrolle und einen Schreibaufschlag im Austausch für feinere Rabattmöglichkeiten“ setzt. Beide Ansätze haben ihre Berechtigung; entscheidend ist, welcher zu Ihrem Datenverkehr passt.
Wenn Ihre Anwendung von hoher Trefferquote, stabilem Datenverkehr und präziser Steuerung profitiert, lässt sich der 1,25x/2x-Schreibaufschlag bei Claude durch die hohe Trefferquote leicht amortisieren, wobei die dualen TTL-Optionen (5min/1h) eine Flexibilität bieten, die GPT nicht hat. Wenn Ihre Anwendung hingegen eine niedrige Trefferquote aufweist, unvorhersehbare Lastspitzen hat und „out-of-the-box“ funktionieren soll, ist das automatische Cache-Modell von GPT ohne Aufschlag die sicherste Wahl.
🎯 Abschließende Empfehlung: Die beste Praxis für die Kostenoptimierung ist es, sich nicht auf ein Modell festzulegen. Wir empfehlen, beide Modelle über APIYI (apiyi.com) anzubinden und je nach Szenario zu routen – hochfrequente Anfragen über Claude, um Rabatte zu erzielen, und niederfrequente über GPT, um Risiken zu minimieren. Ein Token, eine Abrechnung, einfacher Vergleich – das ist der effizienteste Weg für technische Teams im Jahr 2026.
— APIYI Technik-Team | Wir verfolgen kontinuierlich die Entwicklungen bei der Abrechnung von Großsprachmodellen. Weitere tiefgehende Vergleiche finden Sie im Hilfe-Center von APIYI (apiyi.com).