Autorenhinweis: Gemini 3.1 Flash-Lite Preview ist mit einer Ausgabegeschwindigkeit von 380 Tokens/s und extrem niedrigen Kosten von $0,25/M live gegangen. Dieser Artikel analysiert im Detail seine 5 Kernvorteile, Benchmark-Daten, den Vergleich mit Konkurrenzprodukten und die API-Integration.
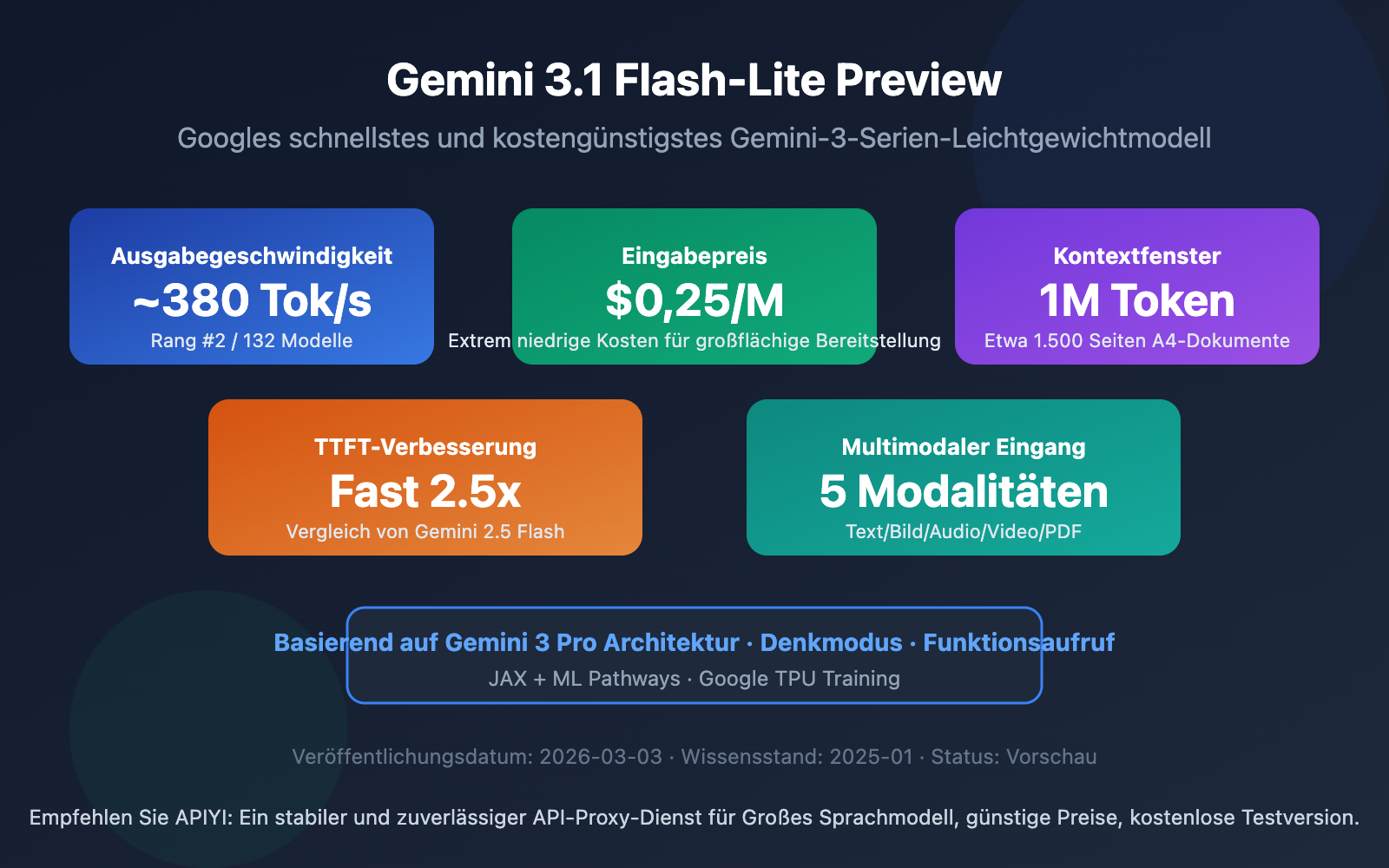
Google DeepMind hat am 3. März 2026 offiziell Gemini 3.1 Flash-Lite Preview veröffentlicht – das schnellste und kostengünstigste Modell der Gemini-3-Serie. Basierend auf der Gemini-3-Pro-Architektur erreicht es eine Ausgabegeschwindigkeit von etwa 380 Tokens/s, was 2,5-mal schneller ist als die erste Token-Antwort von Gemini 2.5 Flash und die Ausgabegeschwindigkeit um 45 % steigert.
Kernwert: Dieser Artikel hilft Ihnen, dieses neu eingeführte, leichtgewichtige Modell anhand von fünf Dimensionen – Leistungsbenchmark, Kostenvergleich, Funktionsmerkmale, Anwendungsszenarien und API-Integration – umfassend zu verstehen und zu beurteilen, ob es für Ihre Geschäftsanforderungen geeignet ist.
Schnellübersicht zu den Kernparametern von Gemini 3.1 Flash-Lite Preview
Hier sind die wichtigsten technischen Parameter, die aus der offiziellen Google-AI-Dokumentation und der DeepMind-Model Card extrahiert wurden:
| Parameter | Gemini 3.1 Flash-Lite Preview | Erläuterung |
|---|---|---|
| Modell-ID | gemini-3.1-flash-lite-preview |
Diese ID wird für API-Aufrufe verwendet |
| Architekturbasis | Gemini 3 Pro | Erbt die multimodale Pro-Architektur |
| Kontextfenster | 1.048.576 Tokens (1M) | Entspricht ca. 1.500 A4-Seiten Text |
| Maximale Ausgabe | 65.536 Tokens (64K) | Unterstützt lange Textgenerierung |
| Ausgabegeschwindigkeit | ~380 Tokens/s | Platz 2 unter 132 Modellen |
| Eingabepreis | $0,25 / Million Tokens | Niedrigster Preis in der Gemini-3-Serie |
| Ausgabepreis | $1,50 / Million Tokens | Ein Achtel des Pro-Modell-Preises |
| Wissensstand | Januar 2025 | Entspricht Gemini 3 Pro |
| Status | Preview | Vorschauversion, finale Version folgt |
Es ist erwähnenswert, dass Gemini 3.1 Flash-Lite Preview auf der Gemini-3-Pro-Architektur aufbaut. Das bedeutet, dass es in einer "komprimierten" Größe die multimodalen Fähigkeiten auf Pro-Niveau beibehält. Google positioniert es als bevorzugtes Modell für "häufige, leichtgewichtige Aufgaben".
🎯 Integrationsempfehlung: Gemini 3.1 Flash-Lite Preview ist bereits auf APIYI apiyi.com verfügbar, zu denselben Preisen wie bei Google. Bei einer Aufladung von 100 USD gibt es 10 USD Bonus, mit Rabatten von bis zu 20 %. Nutzen Sie über 400 Große Sprachmodelle über eine einzige Plattform.
Vorteil 1: Blitzschnelle Inferenz – 380 Tokens/s Ausgabegeschwindigkeit
Gemini 3.1 Flash-Lite Preview erreicht eine Ausgabegeschwindigkeit von etwa 380 Tokens/s. Laut den Benchmark-Daten von Artificial Analysis belegt es damit Platz 2 unter 132 gängigen Modellen. Im Vergleich zum Vorgänger Gemini 2.5 Flash (249 Tokens/s) bedeutet das eine Leistungssteigerung von etwa 45 %.
Besonders beeindruckend ist die Time to First Token (TTFT) – sie ist 2,5-mal schneller als bei Gemini 2.5 Flash. Diese Verbesserung ist für Anwendungen mit hohen Anforderungen an sofortiges Feedback (wie Chatbots oder Echtzeitübersetzung) von großer Bedeutung.
Vorteil 2: Extrem niedrige Kosten – Eingabe nur $0,25/M Tokens
Innerhalb der Gemini-3-Serie ist Flash-Lite nur ein Achtel so teuer wie die Pro-Version. Im Detail:
| Modell | Eingabepreis | Ausgabepreis | Gemischter Satz (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0,25/M | $1,50/M | $0,56/M |
| Gemini 3 Pro | $2,00/M | $12,00/M | $4,50/M |
| Claude 4.5 Haiku | $1,00/M | $5,00/M | $2,00/M |
| GPT-5 mini | $0,15/M | $0,60/M | $0,26/M |
Flash-Lite bietet eine hervorragende Balance zwischen Preis und Leistung. Es ist zwar nicht das absolut günstigste Modell, aber angesichts der Ausgabegeschwindigkeit von 380 Tokens/s und des 1-Millionen-Token-Kontextfensters ist das Preis-Leistungs-Verhältnis ausgezeichnet.
Vorteil 3: Kontextfenster mit einer Million Tokens
Ein Kontextfenster von 1.048.576 Tokens bedeutet, dass Sie in einer einzigen Anfrage verarbeiten können:
- Etwa 1.500 Seiten A4-Text
- Ein komplettes Code-Repository
- Mehrstündige Audio- oder Videoinhalte
Diese Konfiguration ist für ein leichtgewichtiges Modell sehr ungewöhnlich. Zum Vergleich: GPT-5 mini unterstützt nur 128K, Claude 4.5 Haiku 200K.
Vorteil 4: Unterstützung für alle Eingabemodalitäten
Obwohl als leichtgewichtiges Modell positioniert, unterstützt Gemini 3.1 Flash-Lite Preview fünf Eingabemodalitäten:
- Text: Kernfähigkeit
- Bilder: Analyse und Verständnis von Bildinhalten
- Audio: Transkription und Analyse von Sprache
- Video: Verständnis von Videoinhalten
- PDF: Analyse und Zusammenfassung von Dokumenten
Die Ausgabe beschränkt sich auf Text, was für die meisten Datenverarbeitungs- und Analyseaufgaben jedoch völlig ausreichend ist.
Vorteil 5: Unterstützung für den Thinking Mode
Für ein leichtgewichtiges Modell ist es bemerkenswert, dass Gemini 3.1 Flash-Lite Preview den Thinking Mode (erweiterten Denkmodus) unterstützt – das ist in dieser Modellklasse fast einzigartig. Wenn aktiviert, führt das Modell schrittweise Überlegungen durch, was die Genauigkeit bei Aufgaben wie naturwissenschaftlichem Wissen oder mathematischen Berechnungen deutlich erhöht.
🎯 Plattformempfehlung: Möchten Sie die Leistung des Thinking Mode von Gemini 3.1 Flash-Lite Preview schnell testen? Über APIYI (apiyi.com) können Sie es direkt aufrufen. Die Plattform bietet eine einheitliche Schnittstelle für über 400 gängige große Sprachmodelle.
Benchmark-Daten für Gemini 3.1 Flash-Lite Preview
Hier sind die Evaluierungsdaten aus dem Google DeepMind Model Card und von Artificial Analysis:
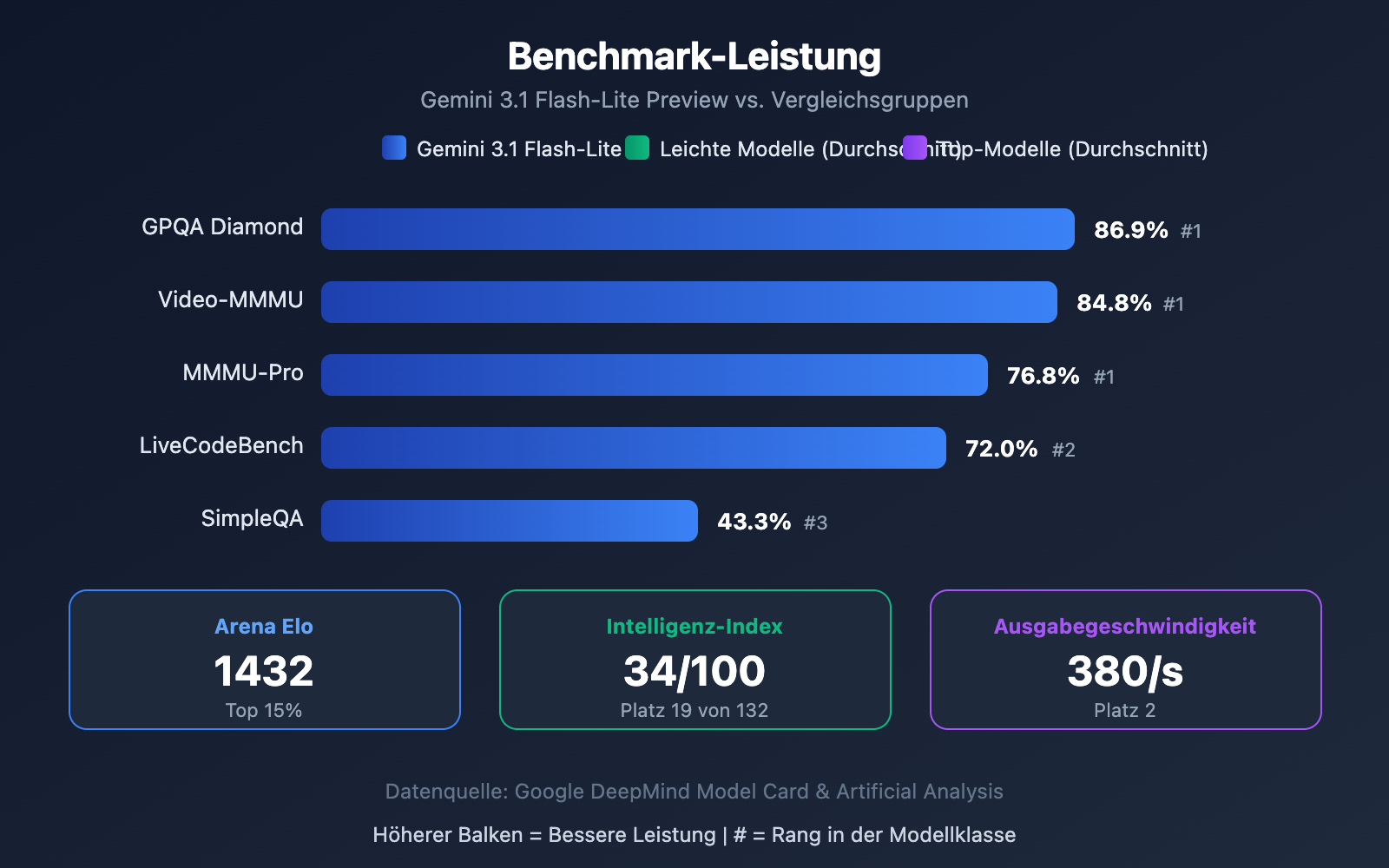
Interpretation der Benchmark-Daten für Gemini 3.1 Flash-Lite Preview
Die Daten zeigen, dass Flash-Lite unter den leichten Modellen sehr gut abschneidet:
- GPQA Diamond 86,9 %: Führend in der Klasse bei wissenschaftlichem Wissensschlussfolgern
- Video-MMMU 84,8 %: Zeigt die Stärken seiner multimodalen Fähigkeiten im Videoverständnis
- MMMU-Pro 76,8 %: Hervorragende Leistung bei multimodaler Schlussfolgerung
- Arena Elo 1432: Hohe Punktzahl auf der Arena.ai-Rangliste, was für eine gute Nutzererfahrung spricht
- Intelligenz-Index 34/100: Deutlich über dem Durchschnitt der Vergleichsgruppe (19), Platz 19 von 132 Modellen
In 11 Benchmark-Tests erzielte Flash-Lite in 6 Tests die beste Leistung seiner Klasse – eine ausgezeichnete Leistung für ein leichtgewichtiges Modell.
🎯 Empfehlung für praktische Tests: Benchmark-Daten dienen nur als Referenz, die tatsächliche Leistung variiert je nach Anwendungsszenario. Es wird empfohlen, reale Tests über APIYI (apiyi.com) durchzuführen. Die Plattform bietet kostenloses Guthaben und unterstützt den schnellen Vergleich mehrerer Modelle.
Gemini 3.1 Flash-Lite Preview im Vergleich zu Mitbewerbern

| Vergleichsdimension | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| Ausgabegeschwindigkeit | ~380 Tok/s ⚡ | ~108 Tok/s | ~71 Tok/s |
| Eingabepreis | $0,25/M | $1,00/M | $0,15/M ⚡ |
| Ausgabepreis | $1,50/M | $5,00/M | $0,60/M ⚡ |
| Kontextfenster | 1M Tokens ⚡ | 200K Tokens | 128K Tokens |
| Multimodale Eingabe | 5 Typen ⚡ | 2 Typen | 2 Typen |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
Vergleichszusammenfassung:
- Geschwindigkeit priorisieren: Flash-Lite mit 380 Tok/s ist 3,5-mal schneller als Haiku und 5,4-mal schneller als GPT-5 mini.
- Kosten priorisieren: GPT-5 mini hat niedrigere absolute Preise, aber der Geschwindigkeitsvorteil von Flash-Lite kann den Kostennachteil ausgleichen.
- Funktionen priorisieren: Flash-Lite ist bei Kontextlänge (1M) und multimodaler Unterstützung (5 Typen) deutlich führend.
🎯 Auswahlempfehlung: Welches leichte Modell Sie wählen, hängt vom konkreten Anwendungsfall ab. Wir empfehlen, über APIYI apiyi.com praktische Vergleichstests durchzuführen. Die Plattform bietet einen einheitlichen Interface für alle oben genannten Modelle, was schnelles Wechseln und Evaluieren erleichtert.
Schnelleinstieg in Gemini 3.1 Flash-Lite Preview
Minimalbeispiel
Hier ist der einfachste Code, um Gemini 3.1 Flash-Lite Preview über die APIYI-Plattform aufzurufen – läuft in nur 10 Zeilen:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "Erkläre Quantencomputing in einem Satz"}]
)
print(response.choices[0].message.content)
Vollständigen Implementierungscode anzeigen (inkl. Thinking Mode)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Ruft Gemini 3.1 Flash-Lite Preview auf
Args:
prompt: Benutzereingabe
system_prompt: System-Eingabeaufforderung
max_tokens: Maximale Anzahl der Ausgabe-Tokens
enable_thinking: Thinking Mode aktivieren
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Fehler: {str(e)}"
# Verwendungsbeispiel
result = call_flash_lite(
prompt="Analysiere die Zeitkomplexität des folgenden Codes und gib Optimierungsvorschläge",
system_prompt="Du bist ein Senior-Algorithmus-Ingenieur"
)
print(result)
Empfehlung: Holen Sie sich über APIYI apiyi.com einen API-Schlüssel und kostenloses Testguthaben, um schnell zu prüfen, wie sich Gemini 3.1 Flash-Lite Preview in Ihrem Anwendungsfall verhält. Bei einer Aufladung von 100 USD gibt es 10 USD geschenkt, mit Rabatten ab 20% auf den Mindestbetrag.
Anwendungsbereiche für Gemini 3.1 Flash-Lite Preview
Empfohlene Anwendungsbereiche
| Szenario | Beschreibung | Warum Flash-Lite? |
|---|---|---|
| Massenübersetzung | Übersetzungsworkflows für mehrsprachige Inhalte | Extrem schnelle Ausgabe (380 tok/s) + niedrige Kosten |
| Content-Moderation | Klassifizierung und Filterung von nutzergenerierten Inhalten | Hohe Aufruffrequenz + kontrollierbare Kosten |
| Datenextraktion | Extraktion und Strukturierung von Daten | Unterstützt JSON Schema-Ausgabe |
| Agent-Routing | Als Routing-Ebene zur Anfrageverteilung | Sehr niedrige Latenz + Function Calling |
| Dokumentenverarbeitung | Analyse und Zusammenfassung von PDFs/langen Dokumenten | 1M Kontextfenster + multimodale Eingabe |
| Audiotranskription | Spracherkennung und -analyse | Native Audioeingabe-Unterstützung |
Nicht empfohlene Szenarien
- Komplexes kreatives Schreiben: Pro-Modelle haben Vorteile bei tiefgreifender Kreation
- Bilder-/Audioerzeugung: Flash-Lite unterstützt nur Textausgabe
- Echtzeit-Streaming-Dialoge: Live-API wird nicht unterstützt
- Szenarien mit höchsten Anforderungen an die Schlussfolgerungsgenauigkeit: Für Szenarien, die maximale Genauigkeit erfordern, wird Gemini 3.1 Pro empfohlen
🎯 Szenario-Empfehlung: Unsicher, welches Modell am besten zu Ihrem Szenario passt? Über APIYI apiyi.com können Sie schnell zwischen Gemini 3.1 Flash-Lite, Claude Haiku und GPT-5 mini wechseln und vergleichen, um die optimale Lösung zu finden.
Häufig gestellte Fragen
F1: Was ist der Unterschied zwischen Gemini 3.1 Flash-Lite Preview und Gemini 2.5 Flash?
Der Kernunterschied liegt in der Architektur und Leistung: Flash-Lite basiert auf der Gemini 3 Pro-Architektur (nicht Gemini 2-Architektur), die Antwortzeit für das erste Token ist 2,5-mal schneller, die Ausgabegeschwindigkeit steigt um 45% auf ~380 tok/s. Gleichzeitig wurden erweiterte Funktionen wie Thinking Mode, Code-Ausführung usw. hinzugefügt.
F2: Wie stabil ist die Preview-Version? Ist sie für den Produktiveinsatz geeignet?
Funktionen und Leistung der Preview-Version können in der finalen Version angepasst werden. Es wird empfohlen, sie zunächst in nicht-kritischen Geschäftsbereichen zu testen; für kritische Bereiche kann ein Fallback-Plan eingerichtet werden. Bei der Nutzung über APIYI apiyi.com können Sie einfach zwischen Modellen wechseln, um eine flexible Fallback-Strategie umzusetzen.
F3: Wie kann ich schnell mit dem Testen von Gemini 3.1 Flash-Lite Preview beginnen?
Empfohlen wird das Testen über eine API-Aggregationsplattform, die mehrere Modelle unterstützt:
- Besuchen Sie APIYI apiyi.com und registrieren Sie ein Konto
- Erhalten Sie einen API-Schlüssel und ein kostenloses Kontingent
- Verwenden Sie die Code-Beispiele in diesem Artikel und setzen Sie das Modell auf
gemini-3.1-flash-lite-preview - Bei einer Aufladung von 100 USD erhalten Sie 10 USD geschenkt, der niedrigste Preis beträgt 20% Rabatt
Zusammenfassung
Die Kernpunkte von Gemini 3.1 Flash-Lite Preview:
- Extreme Geschwindigkeit: Ausgabegeschwindigkeit von ~380 Tok/s, Rang 2 von 132 Modellen, erste Token-Antwort 2,5-mal schneller als 2.5 Flash.
- Hohe Preis-Leistung: Eingabe $0,25/M, Ausgabe $1,50/M, nur 1/8 des Preises von Gemini 3 Pro, ideal für häufige, großvolumige Aufrufe.
- Umfassende Funktionen: 1M Kontextfenster + 5 Eingabemodalitäten + Thinking Mode + Function Calling, die umfassendste Konfiguration unter den Leichtgewichtsmodellen.
- Pro-Gene: Basierend auf der Gemini 3 Pro Architektur, hervorragende Leistung in Benchmarks wie GPQA Diamond (86,9%).
Für KI-Anwendungsszenarien, die große Volumen, niedrige Kosten und hohe Geschwindigkeit erfordern, ist Gemini 3.1 Flash-Lite Preview eines der derzeit bemerkenswertesten Leichtgewichts-Modelle.
Empfohlen wird der schnelle Zugang über APIYI apiyi.com. Die Plattformpreise entsprechen den offiziellen Google-Preisen, bei einer Aufladung von 100 USD gibt es 10 USD geschenkt, mit Rabatten bis zu 20% und einem One-Stop-Shop für über 400 große Sprachmodelle.
📚 Referenzen
-
Offizielle Modelldokumentation von Google AI: Vollständige technische Spezifikationen für Gemini 3.1 Flash-Lite Preview
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - Beschreibung: Offizielle API-Dokumentation mit den neuesten Parametern und Funktionslisten.
- Link:
-
Model Card von Google DeepMind: Benchmark-Daten und Sicherheitsbewertung
- Link:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - Beschreibung: Offizielle Model Card mit detaillierten Benchmark-Ergebnissen und Trainingsinformationen.
- Link:
-
Artificial Analysis Bewertung: Unabhängige Analyse von Leistung und Preis durch Dritte
- Link:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - Beschreibung: Enthält unabhängige Bewertungsdaten zu Ausgabegeschwindigkeit, TTFT, Intelligenzindex usw.
- Link:
-
Offizieller Google Blog: Ankündigung der Veröffentlichung von Gemini 3.1 Flash-Lite
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - Beschreibung: Offizieller Veröffentlichungsartikel, der Produktpositionierung und Kernfunktionen vorstellt.
- Link:
Autor: APIYI Technikteam
Technischer Austausch: Diskussionen sind in den Kommentaren willkommen. Weitere Materialien finden Sie im APIYI Docs Center unter docs.apiyi.com.