هل تستخدم OpenClaw في سير عملك اليومي، ولكنك تشعر بضيق في صدرك كلما رأيت فاتورة API في نهاية الشهر؟ 300 دولار، 500 دولار، أو ربما أكثر من 600 دولار؟
هذه ليست مشكلتك، بل هي نتيجة لـ تصميم بنية OpenClaw. فنسخة OpenClaw غير المحسنة ترسل كميات هائلة من "المحتوى غير الضروري" إلى نموذج الذكاء الاصطناعي مع كل مهمة، مما يستهلك التوكنات (Tokens) دون داعٍ.
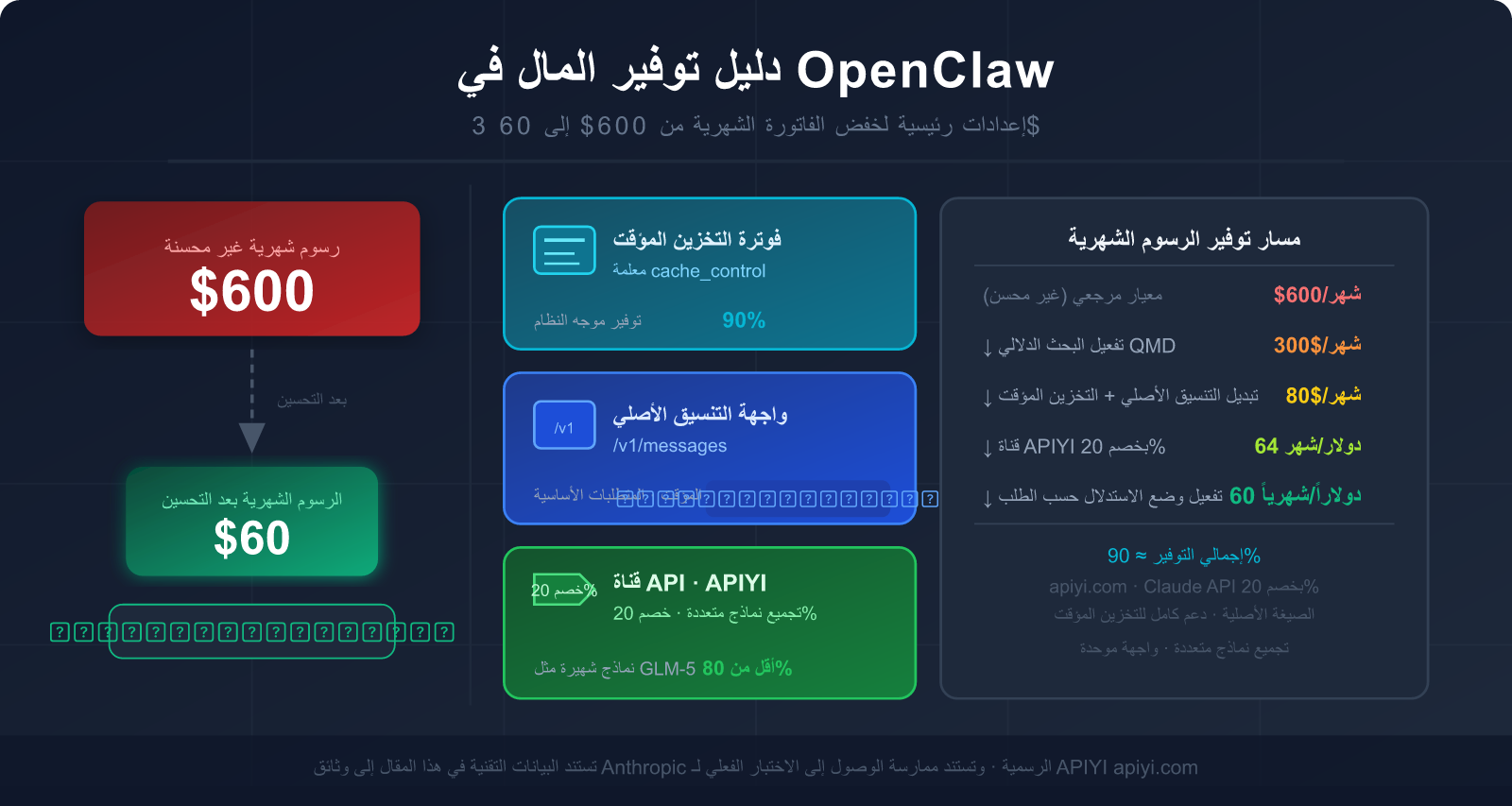
الخبر السار هو: بضع إعدادات رئيسية يمكن أن تخفض فاتورتك بنسبة 80-90%، والأهم من ذلك أن معظم الناس لا يعرفون الحيلة الأكثر فعالية: استخدام واجهة تنسيق Claude الأصلية بدلاً من وضع توافق OpenAI.
في هذا المقال، سنحلل بعمق الأسباب الجذرية للاستهلاك العالي للتوكنات في OpenClaw، وسنشرح لك خطوة بخطوة كيفية استخدام الواجهات الصحيحة، وتكوين التخزين المؤقت (Caching)، واختيار قنوات API المناسبة، لتحويل فاتورتك الشهرية من 600 دولار إلى 60 دولاراً فقط.
أولاً، لماذا يستهلك OpenClaw الكثير من الـ Tokens: 3 أسباب جوهرية
السبب 1: إرسال سجل المحادثة بالكامل مع كل طلب
هذا هو السبب الأكثر تجاهلاً، ولكنه الأكبر تأثيراً.
يعتمد تصميم OpenClaw على مبدأ "السياق الكامل": في كل مرة يتم فيها إرسال طلب إلى نموذج الذكاء الاصطناعي، يتم إرسال جميع الرسائل السابقة منذ بداية المحادثة. بهذه الطريقة فقط يستطيع النموذج "تذكر" ما تم فعله أو قوله سابقاً.
إليك مثالاً توضيحياً:
الجولة 1: يرسل المستخدم 50 tokens، يرد الذكاء الاصطناعي بـ 200 tokens ← الإجمالي المرسل في هذه المرة 250 tokens
الجولة 2: يرسل المستخدم 50 tokens، يرد الذكاء الاصطناعي بـ 200 tokens ← الإجمالي المرسل 500 tokens (بما في ذلك الجولة 1)
الجولة 3: يرسل المستخدم 50 tokens، يرد الذكاء الاصطناعي بـ 200 tokens ← الإجمالي المرسل 750 tokens (بما في ذلك الجولتين 1 و 2)
...
الجولة 10: فعلياً تمت إضافة 250 tokens فقط في هذه الجولة، لكن حجم الإرسال وصل إلى 2,500 tokens
في سير عمل OpenClaw الذي يعالج مهاماً معقدة، يؤدي "تأثير كرة الثلج" هذا إلى نمو استهلاك الـ Tokens بشكل هندسي. عادةً ما يمثل سجل السياق ما بين 40-50% من إجمالي استهلاك الـ Tokens.
السبب 2: إعادة إرسال الموجه النظامي (System Prompt) في كل مرة
يحدد الموجه النظامي (System Prompt) في OpenClaw هوية العميل (Agent)، وحدود قدراته، وقائمة الأدوات المتاحة، ومعايير السلوك، وغيرها من المحتويات الأساسية، وعادة ما يتراوح حجمه بين 5,000 إلى 10,000 tokens.
المشكلة الأساسية: يتم إرسال هذا الموجه النظامي الضخم بالكامل مع كل استدعاء لـ API.
افترض أنك تستخدم OpenClaw لمعالجة 50 مهمة يومياً، وكان حجم الموجه النظامي 8,000 tokens:
الاستهلاك اليومي للموجه النظامي = 50 × 8,000 = 400,000 tokens
الاستهلاك الشهري ≈ 12,000,000 tokens (للموجه النظامي فقط!)
بناءً على سعر الإدخال لنموذج Claude Sonnet 4.6 (وهو 3 دولارات لكل مليون tokens)، ستكلفك بند الموجه النظامي وحده حوالي 36 دولاراً شهرياً، وهذا دون احتساب محتوى المحادثة أو المخرجات.
السبب 3: نمط الاستنتاج يزيد الاستهلاك بمقدار 10-50 ضعفاً
عندما يواجه OpenClaw مهاماً معقدة، فإنه يقوم بتفعيل "سلسلة الأفكار" أو "نمط الاستنتاج" (Thinking/Reasoning). هذا النمط يجعل الذكاء الاصطناعي "يفكر بوضوح قبل الرد"، مما يرفع جودة المخرجات، ولكن الثمن هو زيادة هائلة في استهلاك الـ Tokens.
خصائص استهلاك tokens الاستنتاج:
- تولد عملية التفكير كمية كبيرة من الـ Tokens الوسيطة (غالباً ما تكون غير مرئية للمستخدم ولكن يتم احتساب تكلفتها).
- قد تنتج عملية الاستنتاج للمهام المعقدة ما بين 10,000 إلى 50,000 tokens.
- إذا لم يتم ضبط الأمر، يمكن لبضع مهام معقدة أن تستنفد ميزانية اليوم بالكامل.
| سيناريو استهلاك الـ Tokens | النمط العادي | نمط الاستنتاج | فارق التضاعف |
|---|---|---|---|
| مهمة سؤال وجواب بسيطة | ~500 tokens | ~2,000 tokens | 4 أضعاف |
| عملية معالجة بريد إلكتروني | ~2,000 tokens | ~15,000 tokens | 7.5 ضعف |
| مهمة تحليل كود برمجي | ~5,000 tokens | ~80,000 tokens | 16 ضعفاً |
| بحث معقد متعدد الخطوات | ~10,000 tokens | ~200,000 tokens | 20 ضعفاً+ |
🎯 تشخيص سريع: إذا كانت فاتورة OpenClaw الخاصة بك مرتفعة بشكل غير طبيعي، فافحص أولاً سجلات الـ Tokens لمعرفة مدى استخدام نمط الاستنتاج.
إيقاف نمط الاستنتاج للمهام غير الضرورية هو أحد أسرع الوسائل لتوفير التكاليف.
كما أن الانتقال إلى نموذج أكثر ملاءمة يمكن أن يقلل التكاليف بشكل كبير – يمكنك التبديل بسرعة بين النماذج المختلفة واختبارها عبر APIYI (apiyi.com).
توزيع نسب الاستهلاك للأسباب الثلاثة الكبرى
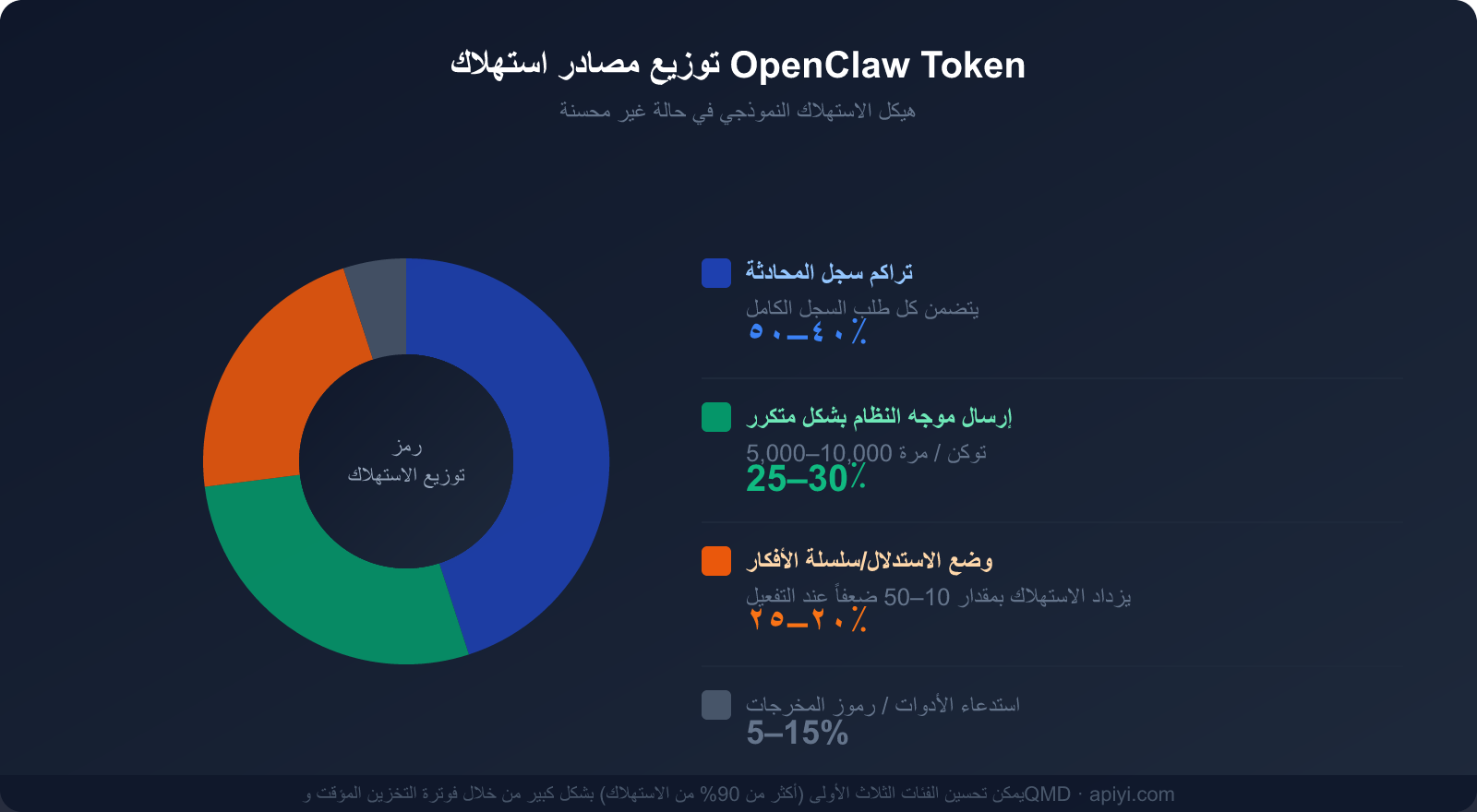
إن فهم هذه المصادر الثلاثة للاستهلاك هو الخطوة الأولى لوضع استراتيجية لتوفير المال:
| مصدر الاستهلاك | نسبة الاستهلاك الإجمالي | هل يمكن تحسينه؟ | وسائل التحسين الرئيسية |
|---|---|---|---|
| سجل المحادثة (تراكم السياق) | 40-50% | ✅ قابل للتحسين بشكل كبير | التخزين المؤقت، التنظيف الدوري، تقنية QMD |
| تكرار إرسال الموجه النظامي | 25-30% | ✅ قابل للتحسين بشكل كبير | فوترة التخزين المؤقت (توفر حتى 90%) |
| نمط الاستنتاج/سلسلة الأفكار | 20-25% | ✅ حسب الحاجة | تفعيله للمهام المعقدة فقط |
| استدعاء الأدوات والمخرجات | 5-15% | ⚡ تحسين محدود | تبسيط أوصاف الأدوات |
ثانياً، الأداة الأكثر إهمالاً لتوفير المال: فوترة التخزين المؤقت في Claude
ما هي فوترة التخزين المؤقت في Claude
تعد خاصية "التخزين المؤقت للموجهات" (Prompt Caching) ميزة أصلية أطلقتها Anthropic في أواخر عام 2024. المنطق الأساسي لها هو: تخزين المحتوى الذي يتم إرساله بشكل متكرر على جانب الخادم، بحيث يتم قراءته مباشرة من التخزين المؤقت في الاستدعاءات اللاحقة بدلاً من إعادة معالجته.
سعر قراءة التخزين المؤقت: 10% فقط من سعر الإدخال العادي (توفير 90%)
هذا يعني: في كل مرة ترسل فيها موجه نظام (System Prompt) بحجم 8,000 توكن، وبعد تفعيل التخزين المؤقت، ستتم المحاسبة على 800 توكن فقط عند حدوث مطابقة (Hit). بالنسبة لمستخدمي OpenClaw الذين يرسلون عشرات الطلبات يومياً، يمكن لهذا التحسين وحده توفير مئات الدولارات شهرياً.
نظام الأسعار الكامل للتخزين المؤقت
| نوع التخزين المؤقت | مضاعف التكلفة | مدة الصلاحية | سيناريو الاستخدام |
|---|---|---|---|
| توكنات الإدخال العادية | 1× السعر الأساسي | لا يتم التخزين | إعادة المعالجة في كل مرة |
| كتابة التخزين المؤقت (لأول مرة) | 1.25× | 5 دقائق (TTL) | إنشاء التخزين المؤقت |
| كتابة التخزين المؤقت (طويل الأمد) | 2× | ساعة واحدة (TTL) | سيناريوهات الاستدعاء المتكرر |
| قراءة التخزين المؤقت (عند المطابقة) | 0.1× (توفير 90%) | ضمن فترة الصلاحية | الطلبات المتكررة |
مثال على حساب التوفير الفعلي:
السيناريو: موجه نظام OpenClaw بحجم 8,000 توكن
50 استدعاء يومياً، منها 48 استدعاء تطابق التخزين المؤقت
بدون استخدام التخزين المؤقت: 50 × 8,000 = 400,000 توكن
التكلفة = 400,000 × $3/1M = $1.20/يومياً = $36/شهرياً
باستخدام التخزين المؤقت: مرتان كتابة: 2 × 8,000 × 1.25 = 20,000 توكن = $0.06
48 مرة مطابقة: 48 × 8,000 × 0.1 = 38,400 توكن = $0.12
التكلفة اليومية ≈ $0.18 ← شهرياً ≈ $5.40
التوفير: $36 - $5.40 = $30.60/شهرياً (لموجه النظام وحده)
نسبة التوفير: 85%
كيفية تفعيل فوترة التخزين المؤقت في OpenClaw
هناك شرط أساسي لتفعيل فوترة التخزين المؤقت: يجب استخدام واجهة تنسيق Anthropic الأصلية (/v1/messages) بدلاً من وضع التوافق مع OpenAI (/v1/chat/completions).
طريقة التكوين الصحيحة (مثال باستخدام Python SDK):
import anthropic
# يجب استخدام SDK الأصلي لـ Anthropic، لا يمكن استخدام SDK الخاص بـ OpenAI
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # يدعم APIYI تنسيق Anthropic الأصلي
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "أنت مساعد ذكاء اصطناعي محترف... [موجه نظام بحجم 8000 توكن]",
"cache_control": {"type": "ephemeral"} # ← مفتاح الحل: تحديد هذا المحتوى كمرشح للتخزين المؤقت
}
],
messages=[
{"role": "user", "content": "ساعدني في تنظيم رسائل البريد الإلكتروني اليوم"}
]
)
القيود التقنية للتخزين المؤقت:
- يمكن تعيين 4 نقاط توقف للتخزين المؤقت كحد أقصى (باستخدام علامة
cache_control). - سلسلة Sonnet: الحد الأدنى للمحتوى القابل للتخزين المؤقت ≥ 1,024 توكن.
- Opus / Haiku 4.5: الحد الأدنى للمحتوى القابل للتخزين المؤقت ≥ 4,096 توكن.
- النماذج التي تدعم التخزين المؤقت: Claude Opus 4، Sonnet 4.6، Sonnet 4.5، Sonnet 4، Sonnet 3.7، Haiku 4.5، Haiku 3.5، Haiku 3 وغيرها.
🎯 ملاحظة هامة: يدعم APIYI (apiyi.com) بشكل كامل استدعاءات تنسيق Anthropic الأصلي،
بما في ذلك معلمةcache_control. عند استخدام التنسيق الأصلي لاستدعاء نماذج Claude في APIYI،
يمكنك الاستمتاع بـ فوترة التخزين المؤقت (توفير حتى 90%) + خصم 20% من APIYI، مما يحقق نتائج توفير مذهلة.
ثالثاً، إدراك جوهري: لماذا لا يمكن لوضع التوافق مع OpenAI توفير التوكنات
هذا هو الفخ الأكثر شيوعاً الذي يقع فيه معظم مستخدمي OpenClaw.
الاختلاف الجوهري بين تنسيقي الواجهة
توفر العديد من أدوات الذكاء الاصطناعي وخدمات الوكيل التابعة لجهات خارجية وضع التوافق مع OpenAI لتسهيل الأمر على المستخدمين، أي استخدام تنسيق واجهة /v1/chat/completions الخاص بـ OpenAI لاستدعاء نماذج غير تابعة لـ OpenAI مثل Claude.
ظاهرياً، يتيح ذلك للمستخدمين "استخدام كود واحد لاستدعاء جميع النماذج". لكن هناك عيب قاتل:
لا يوجد مكان لمعلمة cache_control في تنسيق واجهة /v1/chat/completions – لأن هذه ميزة أصلية حصرية لـ Anthropic.
عندما تستدعي Claude عبر تنسيق متوافق مع OpenAI:
- يتم تحويل طلبك إلى تنسيق OpenAI.
- تقوم خدمة الوكيل بتحويله مرة أخرى إلى تنسيق Anthropic الأصلي.
- لكن معلومات
cache_controlتكون قد فُقدت بالفعل في الخطوة الأولى. - يتلقى خادم Claude طلباً بدون علامة تخزين مؤقت، فتتم المحاسبة على التوكنات بالكامل في كل مرة.
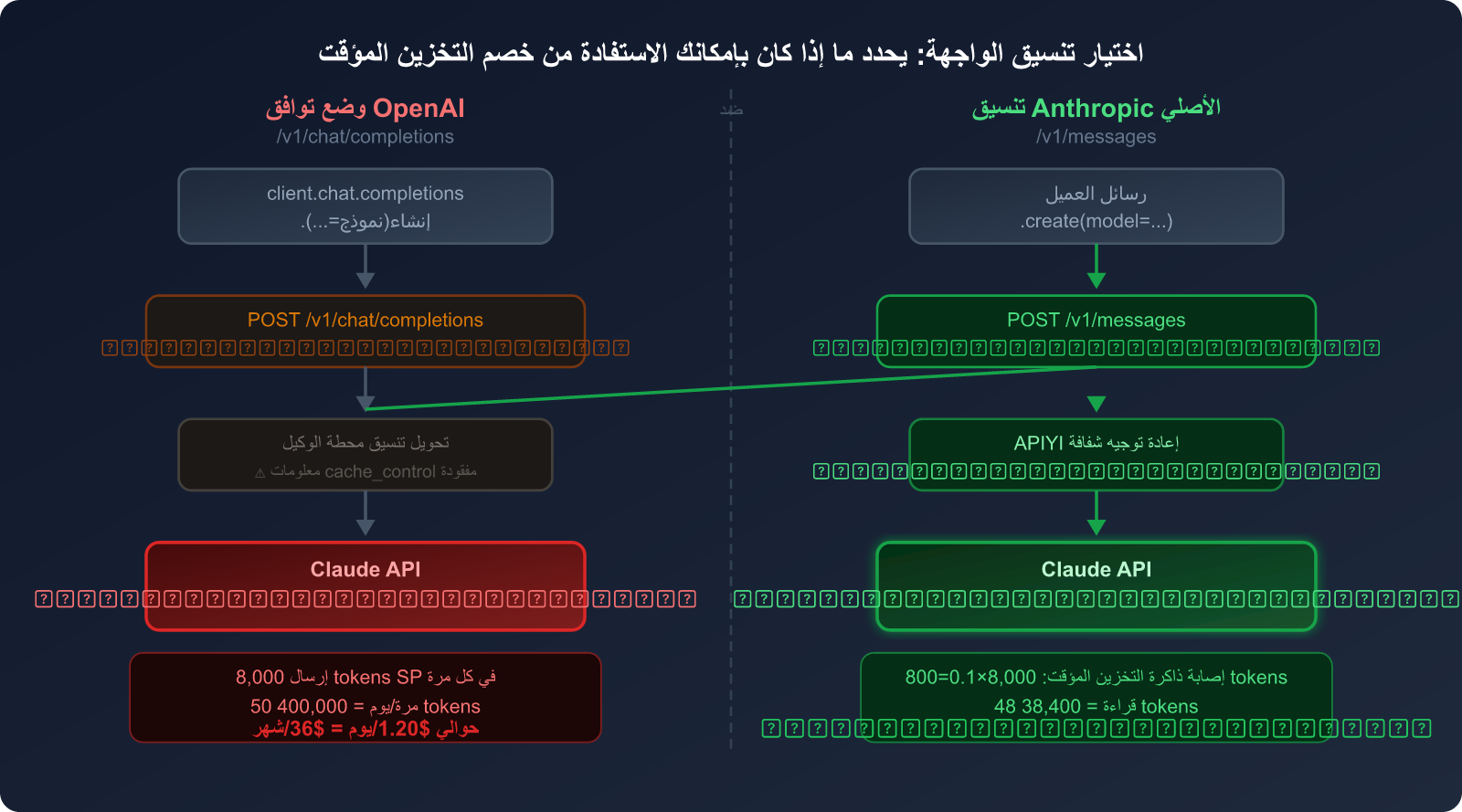
مقارنة بين وضع التوافق مع OpenAI وتنسيق Anthropic الأصلي
| وجه المقارنة | وضع التوافق مع OpenAI | تنسيق Anthropic الأصلي |
|---|---|---|
| مسار الواجهة | /v1/chat/completions |
/v1/messages |
| دعم تخزين Claude المؤقت | ❌ غير مدعوم | ✅ مدعوم بالكامل |
معلمة cache_control |
❌ لا يوجد هذا الحقل | ✅ يدعم 4 نقاط توقف |
| فوترة موجه النظام في كل مرة | 💸 السعر كاملاً (1×) | 💰 قراءة التخزين المؤقت (0.1×) |
| تعقيد الكود | منخفض (كود عام) | متوسط (يتطلب SDK الخاص بـ Anthropic) |
| تأثير توفير المال (في الاستخدام المكثف) | 0% | يصل إلى 90% |
مشاكل إضافية في النشر عبر غير المصدر الأصلي
بالإضافة إلى مشكلة تنسيق الواجهة، هناك حالة أخرى تسبب الارتباك: النماذج التي تحمل "نفس الاسم" والمنشورة عبر مزودي السحابة لا تعني أنها مطابقة للمصدر الأصلي.
بأخذ GLM-5 (من Zhipu AI) كمثال:
- API المصدر الأصلي من موقع z.ai: يدعم ميزة فوترة التخزين المؤقت التي طورتها Zhipu.
- GLM-5 المنشور على Alibaba Cloud / Tencent Cloud وغيرهما: يستخدم بوابة API الخاصة بمزود السحابة، ولا يتوفر على ميزة فوترة التخزين المؤقت الأصلية.
هذه ليست مشكلة في GLM-5 نفسه، بل هي مشكلة شائعة في النشر عبر غير المصدر الأصلي: عند استضافة النماذج، عادةً ما يكشف مزودو السحابة فقط عن واجهات API القياسية للمحادثة، ولا يمررون الخصائص الخاصة بالمصدر الأصلي للنموذج (مثل فوترة التخزين المؤقت).
تشبيه: الأمر يشبه شراء منتج عبر وكيل، حيث قد لا تحصل على خدمات ما بعد البيع الخاصة التي تقدمها الشركة المصنعة الأصلية.
التأثير الفعلي:
السيناريو: 50 استدعاء يومياً، موجه نظام بحجم 6,000 توكن
API المصدر الأصلي (يدعم التخزين المؤقت):
كتابة: مرتان × 6,000 × 1.25 = 15,000 توكن
قراءة: 48 مرة × 6,000 × 0.1 = 28,800 توكن
الاستهلاك المعادل ≈ 43,800 توكن/يومياً
API غير الأصلي (بدون تخزين مؤقت):
السعر الكامل: 50 مرة × 6,000 = 300,000 توكن/يومياً
الفجوة: الاستهلاك بدون تخزين مؤقت يعادل 6.85 أضعاف الاستهلاك مع التخزين المؤقت.
رابعاً: مقارنة بين واجهات برمجة التطبيقات (API) الأصلية: كيف تختار الحل الأنسب لـ OpenClaw
مقارنة بين أربعة خيارات للاتصال
| خيار الاتصال | السعر (مقارنة بالسعر الأصلي) | دعم التخزين المؤقت (Caching) | دعم نماذج متعددة | سيناريوهات الاستخدام |
|---|---|---|---|---|
| واجهة Anthropic الرسمية | 100% (السعر الأصلي) | ✅ كامل | ❌ Claude فقط | ميزانية كافية، مستخدمو Claude فقط |
| APIYI (تنسيق Anthropic الأصلي) | 80% (خصم 20%) | ✅ كامل | ✅ نماذج متعددة | موصى به: توفير المال + مرونة في التبديل |
| محطات الوكيل العامة (متوافقة مع OpenAI) | تتراوح بين 85-95% | ❌ غير مدعوم | ✅ نماذج متعددة | عند عدم استخدام تخزين Claude المؤقت |
| عمليات نشر غير أصلية من مزودي السحاب | تتراوح بين 90-110% | ❌ غير مدعوم | ❌ نموذج واحد | سيناريوهات متطلبات الامتثال للمؤسسات |
منطق توفير المال المزدوج في APIYI
تكمن ميزة APIYI في نماذج Claude في: دعم تنسيق Anthropic الأصلي مع سعر مخفض بنسبة 20% في آن واحد.
اجتماع هاتين النقطتين يعني ما يلي:
المستخدم العادي (السعر الأصلي + توافق OpenAI، بدون تخزين مؤقت):
استهلاك توكنات موجه النظام (System Prompt) شهرياً: 12,000,000 توكن
التكلفة = 12,000,000 × $3/1M = $36
مستخدم APIYI (خصم 20% + التنسيق الأصلي + تخزين مؤقت):
التوكنات المحاسب عليها فعلياً ≈ 1,440,000 توكن (بعد التخزين المؤقت)
التكلفة = 1,440,000 × $3×0.8/1M = $3.46
إجمالي التوفير = ($36 - $3.46) / $36 ≈ 90%
🎯 نصيحة للاختيار: إذا كنت تستخدم OpenClaw وتختار Claude كنموذج أساسي،
فنحن نوصي بشدة بالاتصال عبر APIYI (apiyi.com) باستخدام تنسيق Anthropic الأصلي.
السعر الأساسي المخفض + توفير 90% من التخزين المؤقت، هذا المزيج المزدوج يمكن أن يقلل فاتورتك بنسبة 85-90%.
كما يدعم APIYI نماذج متعددة مثل GLM-5 وGPT، مما يسهل عليك التبديل ومقارنة النتائج في أي وقت.
خامساً: الدليل الشامل لتوفير المال في OpenClaw: 5 خطوات قابلة للتنفيذ فوراً
الخطوة 1: التبديل إلى واجهة تنسيق Anthropic الأصلي
هذه هي الخطوة الأهم، فهي تحدد مباشرة ما إذا كان بإمكانك الاستفادة من محاسبة التخزين المؤقت (Caching).
طريقة تكوين OpenClaw:
في ملف تكوين النماذج (config.json) الخاص بـ OpenClaw، ابحث عن حقل models.providers وأضف APIYI كمزود بالتنسيق التالي. النقطة الجوهرية هي ضبط حقل api على "anthropic-messages"، لتمكين استخدام تنسيق Anthropic الأصلي ودعم محاسبة التخزين المؤقت:
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "ضع-مفتاح-API-هنا",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
توضيح نقاط التكوين:
"api": "anthropic-messages"← الأكثر أهمية، يحدد استخدام التنسيق الأصلي/v1/messagesبدلاً من التنسيق المتوافق/v1/chat/completions."baseUrl": "https://api.apiyi.com"← رابط الأساس لـ APIYI (لا حاجة لإضافة/v1لأن OpenClaw سيقوم بدمجها تلقائياً)."anthropic-version": "2023-06-01"← رأس إصدار API الخاص بـ Anthropic، قد يؤدي نقصه إلى فشل الطلب.contextWindow: 200000← يدعم Claude Sonnet 4.6 نافذة سياق تصل إلى 200 ألف توكن.
التحقق من تفعيل التخزين المؤقت:
تحقق من حقول cache_read_input_tokens و cache_creation_input_tokens في ترويسة استجابة API أو السجلات. إذا كانت هناك قيم، فهذا يعني أن التخزين المؤقت قد تم تفعيله:
# التحقق من استجابة التخزين المؤقت
response = client.messages.create(...)
# فحص حقل الاستخدام (usage)
print(response.usage)
# مثال على المخرجات:
# Usage(
# input_tokens=150, # التوكنات الجديدة المضافة في هذه المرة
# cache_creation_input_tokens=8000, # أول كتابة في التخزين المؤقت (تحاسب بـ 1.25×)
# cache_read_input_tokens=0, # القراءة اللاحقة من التخزين المؤقت (تحاسب بـ 0.1×)
# output_tokens=300
# )
🎯 طريقة الاتصال: بعد التسجيل في APIYI (apiyi.com) والحصول على مفتاح API،
قم بضبطbase_urlإلىhttps://api.apiyi.com/v1لاستخدام تنسيق Anthropic الأصلي،
دون الحاجة لتعديل أي كود آخر، وسيبدأ تفعيل محاسبة تخزين Claude المؤقت فوراً.
الخطوة 2: وضع نقاط توقف التخزين المؤقت بشكل معقول
موقع نقطة توقف التخزين المؤقت (cache_control) أمر حيوي. يجب تخزين المحتوى "الكبير والثابت" مؤقتاً:
# أفضل ممارسة: تخزين موجه النظام + تعريفات الأدوات مؤقتاً
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # موجه النظام الرئيسي (5,000-10,000 توكن)
"cache_control": {"type": "ephemeral"} # نقطة التوقف 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # قائمة الأدوات (عادة ما تكون كبيرة أيضاً)
"cache_control": {"type": "ephemeral"} # نقطة التوقف 2
}
],
messages=conversation_history, # سجل المحادثة (لا يخزن مؤقتاً لأنه يتغير باستمرار)
...
)
نقاط استراتيجية التخزين المؤقت:
- ✅ مناسب للتخزين: موجهات النظام، تعريفات الأدوات، الوثائق الثابتة الكبيرة، محتوى الوثائق المسترجعة عبر RAG.
- ❌ غير مناسب للتخزين: رسائل المستخدم الحالية، المحتوى المولد ديناميكياً، البيانات التي تتغير في كل مرة.
- ⚠️ انتبه للترتيب: التخزين المؤقت يعتمد على مطابقة البادئة (Prefix Matching)، لذا يجب وضع المحتوى الثابت في بداية تسلسل الرسائل.
الخطوة 3: تفعيل QMD لتقليل طول السياق
QMD (قاعدة بيانات الذاكرة السريعة – Quick Memory Database) هي ميزة البحث الدلالي المحلي في OpenClaw. مبدأ عملها:
الطريقة التقليدية:
إرسال [كامل سجل المحادثة] في كل مرة ← يستهلك كمية هائلة من التوكنات
طريقة QMD:
إنشاء قاعدة بيانات متجهة محلية ← البحث عن أكثر أجزاء السجل صلة
إرسال [أكثر 3-5 سجلات صلة] فقط في كل مرة ← يوفر 60-97% من التوكنات
تأثير التوفير الفعلي لـ QMD: وفقاً لوثائق OpenClaw الرسمية، يمكن لـ QMD تحقيق توفير في التوكنات بنسبة 60-97%، وتعتمد النسبة المحددة على حجم سجل المحادثة ونوع المهمة.
طريقة التفعيل (واجهة إعدادات OpenClaw):
- Settings ← Memory ← Enable QMD
- تعيين مسار تخزين QMD (محلي، لا يتم رفع البيانات)
- تعيين عتبة الصلة (يوصى بـ 0.7 أو أكثر لتجنب السجلات غير ذات الصلة)
الخطوة 4: اختيار النموذج المناسب حسب نوع المهمة
ليست كل المهام تتطلب أقوى نموذج. التوزيع الصحيح للنماذج هو مفتاح التحكم في التكلفة:
استراتيجية تصنيف المهام:
المهام البسيطة (تذكيرات المواعيد، تحويل التنسيقات، البحث البسيط)
← استخدم Claude Haiku 4.5 (الأسرع والأرخص)
← سعره حوالي 1/5 من سعر Sonnet
المهام المتوسطة (معالجة البريد الإلكتروني، تنظيم الملفات، مراجعة الكود)
← استخدم Claude Sonnet 4.6 (متوازن)
← نسبة النجاح 86.9% (المركز الأول في PinchBench)
المهام المعقدة (تحليل البنية التحتية، البحث متعدد الخطوات، الاستدلال المعقد)
← استخدم Claude Opus 4.6 (أقوى استدلال)
← قم بتفعيل وضع الاستدلال فقط عند الحاجة الفعلية لذلك
الخطوة 5: تنظيف السياق بشكل دوري
يعد سجل المحادثة أحد أكبر مصادر استهلاك التوكنات (40-50%). نقترح ما يلي:
- ضبط الحد الأقصى لجولات السياق: تلخيص السجل وتنظيفه تلقائياً بعد تجاوز 15-20 جولة.
- التنظيف اليدوي بعد إكمال المهمة: إعادة ضبط السياق قبل بدء مهمة جديدة.
- تفعيل ميزة ضغط الجلسة في OpenClaw: استخدام الذكاء الاصطناعي لضغط السجلات الطويلة إلى ملخصات.
تقدير التأثير الشامل للتحسينات الخمسة
بناءً على مستخدم متوسط لـ OpenClaw (التكلفة الشهرية قبل التحسين حوالي 300-600 دولار)، إليك النتائج المتوقعة بعد تنفيذ الخطوات الخمس:
| خطوة التحسين | مصدر الاستهلاك المستهدف | نسبة التوفير المتوقعة | صعوبة التنفيذ |
|---|---|---|---|
| 1. التبديل لتنسيق Anthropic الأصلي | تكرار محاسبة موجه النظام | توفير 85-90% (جزء SP) | ⭐ منخفضة (تغيير base_url) |
| 2. ضبط نقاط توقف التخزين المؤقت | تعريفات الأدوات + الوثائق الثابتة | توفير 80-90% (جزء الأدوات) | ⭐⭐ منخفضة-متوسطة |
| 3. تفعيل QMD | توكنات سجل المحادثة | توفير 60-97% (جزء السجل) | ⭐⭐ منخفضة-متوسطة |
| 4. تصنيف النماذج حسب المهمة | إجمالي تكلفة التوكنات | توفير 30-70% (فرق سعر النماذج) | ⭐⭐⭐ متوسطة |
| 5. تنظيف السياق دورياً | تأثير كرة الثلج لتراكم السجل | توفير 20-40% (عائد طويل الأمد) | ⭐ منخفضة |
🎯 نصيحة لأولوية التنفيذ: الخطوة 1 (التبديل للتنسيق الأصلي) والخطوة 3 (تفعيل QMD) هما الخطوتان الأعلى عائداً والأسهل تنفيذاً.
ننصح بإكمال هاتين الخطوتين أولاً، حيث يمكنهما عادةً خفض الفاتورة بنسبة 60-80% فوراً.
عند الاتصال بـ Claude عبر APIYI (apiyi.com)، تتطلب الخطوة 1 تعديل سطر واحد فقط في تكوينbase_urlوتستغرق أقل من 5 دقائق.
六、实战配置:OpenClaw + APIYI + Claude 缓存的完整示例
以下是一个完整的、已优化的 OpenClaw 配置示例,适合大多数用户直接复用:
import anthropic
# 通过 APIYI 使用 Anthropic 原生格式
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # APIYI Key(apiyi.com 注册获取)
base_url="https://api.apiyi.com/v1"
)
# 定义系统提示词(大块内容,适合缓存)
SYSTEM_PROMPT = """
你是一个专业的 AI 智能助理,运行在 OpenClaw 平台上。
你的职责包括:管理日程、处理邮件、整理文件、协助代码开发...
[通常有 5,000-10,000 tokens 的详细说明]
"""
# 定义工具列表(也是大块固定内容,适合缓存)
TOOL_DEFINITIONS = """
可用工具:calendar_api, email_api, file_system, code_runner...
[工具详细说明,通常 2,000-5,000 tokens]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""优化后的 OpenClaw API 调用,启用缓存"""
response = client.messages.create(
model="claude-sonnet-4-6", # PinchBench 排名第一
max_tokens=4096,
# 系统提示词:标记缓存断点
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # 缓存断点1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # 缓存断点2
}
],
# 对话历史 + 新消息
messages=[
*conversation_history, # 历史消息(不缓存,每次变化)
{"role": "user", "content": user_message}
]
)
# 打印 Token 使用情况(用于监控优化效果)
usage = response.usage
print(f"输入 Token: {usage.input_tokens}")
print(f"缓存写入: {usage.cache_creation_input_tokens}")
print(f"缓存读取: {usage.cache_read_input_tokens}")
print(f"输出 Token: {usage.output_tokens}")
return response.content[0].text
🎯 快速上手: 将上述代码中的
api_key替换为你在 APIYI apiyi.com 注册后获得的 Key,
无需其他修改,即可立即使用 Anthropic 原生格式 + 缓存计费 + APIYI 八折优惠的组合。
常见问题解答
Q: APIYI 是否真的支持 Anthropic 原生格式(/v1/messages)?
是的,APIYI apiyi.com 同时支持两种接口格式:
- Anthropic 原生格式:
/v1/messages(支持缓存计费) - OpenAI 兼容格式:
/v1/chat/completions(方便通用代码)
对于 Claude 模型,强烈建议使用 Anthropic 原生格式,这样才能享受缓存计费。使用 anthropic Python SDK 并将 base_url 指向 APIYI 即可。
🎯 访问 APIYI apiyi.com 注册账号,控制台中可以看到两种格式的接入示例代码。
Q: 缓存 5 分钟 TTL 够用吗?如何判断是否需要 1 小时 TTL?
这取决于你的调用频率:
- 如果你的 OpenClaw 调用间隔 < 5 分钟(如持续处理任务流),使用默认 5 分钟 TTL 即可
- 如果调用间隔在 5 分钟到 1 小时之间(如处理完一批任务后停顿),考虑 1 小时 TTL(费用为 2× 写入价格,但缓存命中率更高)
- 如果调用间隔 > 1 小时,缓存意义有限,每次重新写入即可
Q: 使用 GLM-5 等国产模型时,有什么省钱建议?
GLM-5 的缓存功能需要通过智谱 AI 官网(z.ai)的原生 API 调用,阿里云等第三方部署无法使用。
APIYI 同样支持 GLM-5 等国产模型,价格在八折以下,方便你在测试阶段用统一接口对比各模型效果。在确定适合场景的模型后,再决定是继续用 APIYI 还是直连原厂。
Q: 我已经在用第三方中转站,迁移到支持原生格式的平台有多难?
迁移成本非常低。唯一需要修改的是代码中的两个参数:
# 迁移前(OpenAI 兼容格式)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="旧中转站地址")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# 迁移后(Anthropic 原生格式,支持缓存)
import anthropic
client = anthropic.Anthropic(
api_key="sk-新APIYIKey", # ← 换成 APIYI 的 Key
base_url="https://api.apiyi.com/v1" # ← 换成 APIYI 的地址
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# 然后在 system 参数中加 cache_control 即可启用缓存
主要工作量在于将 chat.completions.create 改为 messages.create,消息格式有细微差异(role/content 结构一致,但 system 从字符串改为对象列表)。通常半天内可以完成迁移。
Q: 如何验证我的 OpenClaw 实例是否已成功启用缓存?
最直接的方法:在连续调用两次时,观察 API 响应中的 usage 对象:
- 第一次调用:
cache_creation_input_tokens有值(缓存写入) - 第二次调用:
cache_read_input_tokens有值(缓存命中)
如果第二次调用的 cache_read_input_tokens 等于 System Prompt 的 Token 数,说明缓存完全生效。
Q: 推理/思维模式(Extended Thinking)一定要关吗?
不一定要完全关闭,但应该按需使用。建议策略:
- 简单任务(邮件分类、日程安排):关闭推理模式
- 中等任务(代码 review、信息汇总):默认关闭,遇到困难时开启
- 复杂任务(架构决策、多步骤研究):开启,但设置合理的
budget_tokens上限
在 Claude API 中,可以通过 thinking: {"type": "enabled", "budget_tokens": 5000} 限制推理模式的最大 Token 消耗。
الخلاصة: المنطق الجوهري لتوفير المال في OpenClaw
دعونا نلخص جميع وسائل التوفير في رسم توضيحي واحد:
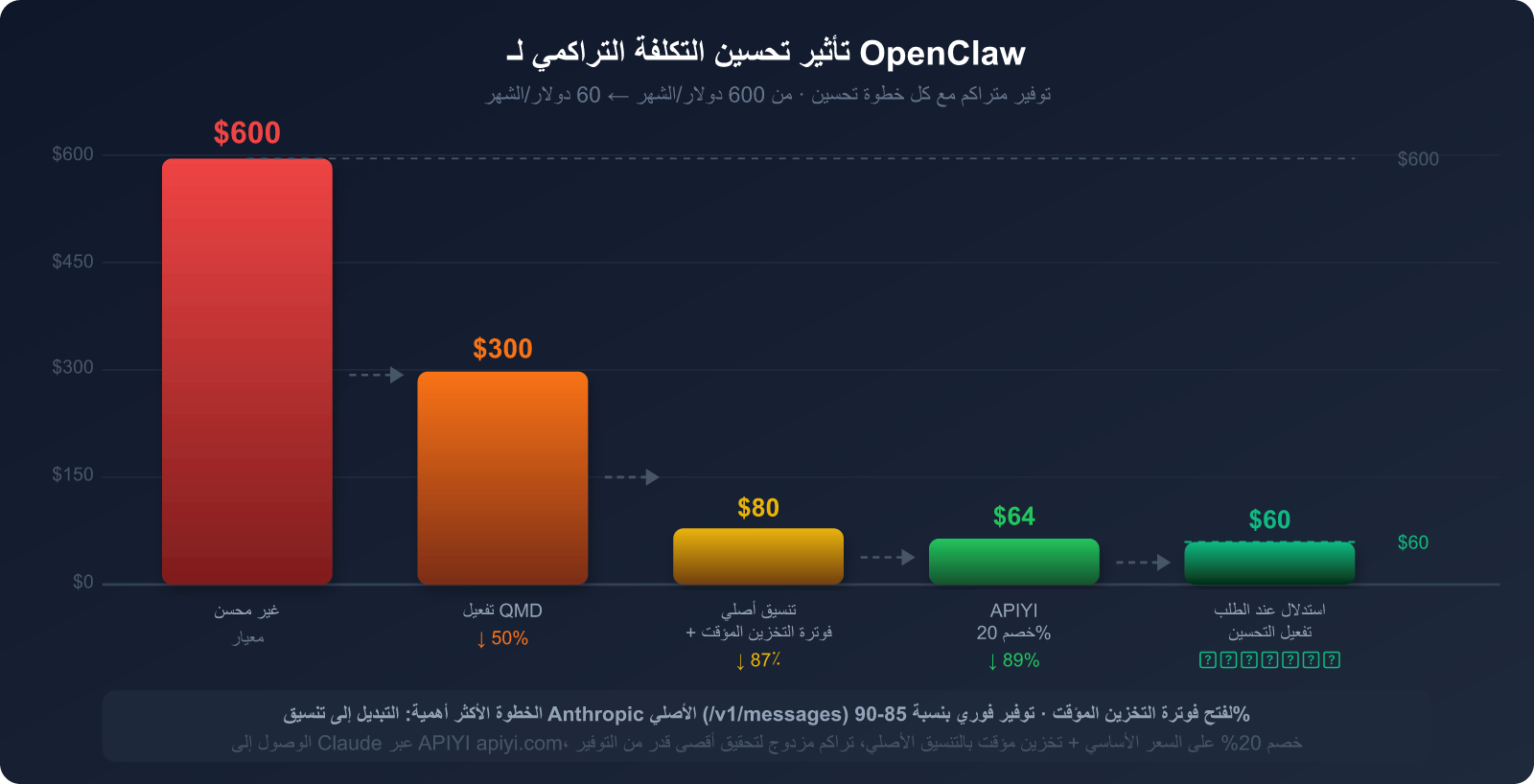
مراجعة للنقاط الجوهرية في هذا المقال:
الأسباب الثلاثة الرئيسية للاستهلاك العالي:
- إعادة إرسال سجل المحادثة بالكامل في كل مرة (يمثل 40-50% من الاستهلاك)
- إعادة إرسال موجه النظام (System Prompt) في كل مرة (يمثل 25-30%)
- الاستخدام غير المنضبط لوضع الاستنتاج (يمثل 20-25%)
أكثر وسائل توفير المال فعالية:
- 🥇 فوترة التخزين المؤقت (Caching) في Claude: توفير يصل إلى 90% (يجب استخدام التنسيق الأصلي لـ Anthropic)
- 🥈 البحث الدلالي المحلي QMD: توفير 60-97% من الـ Tokens في سياق السجل
- 🥉 تصنيف النماذج حسب المهمة: استخدم Haiku للمهام الخفيفة، وSonnet/Opus للمهام الثقيلة
- اختيار قناة الـ API من APIYI: سعر أساسي بخصم 20% + دعم التنسيق الأصلي
أهم معلومة يجب إدراكها:
التنسيق المتوافق مع OpenAI (
/v1/chat/completions) لا يمكنه تمريرcache_control؛
لذا، حتى لو قمت باستدعاء Claude عبر خدمة وكيل API، فلن تستفيد من خصم التخزين المؤقت.
لتوفير المال، يجب عليك استخدام التنسيق الأصلي لـ Anthropic (/v1/messages).
🎯 اتخذ إجراءً الآن: قم بزيارة APIYI (apiyi.com) للتسجيل والحصول على مفتاح API يدعم التنسيق الأصلي لـ Anthropic.
قم بتغييرbase_urlإلىhttps://api.apiyi.com/v1؛ سيستغرق التبديل أقل من 3 دقائق،
وستلاحظ انخفاضاً ملحوظاً في فاتورة الـ Tokens في نفس اليوم. نماذج Claude بخصم 20%، مع واجهة موحدة لعدة نماذج، مما يجعلها الخيار الأمثل لمستخدمي OpenClaw لتقليل التكاليف وزيادة الكفاءة.
تعتمد جميع بيانات أسعار الـ API الواردة في هذه المقالة على المعلومات العامة المتوفرة حتى مارس 2026، ويرجى الرجوع إلى الإعلانات الرسمية لكل منصة لمعرفة الأسعار الفعلية.
المؤلف: فريق APIYI | لمزيد من نصائح استخدام OpenClaw، تفضل بزيارة مركز المساعدة في APIYI على apiyi.com